Nicholas Knize, Thermopylae Sciences and Technology
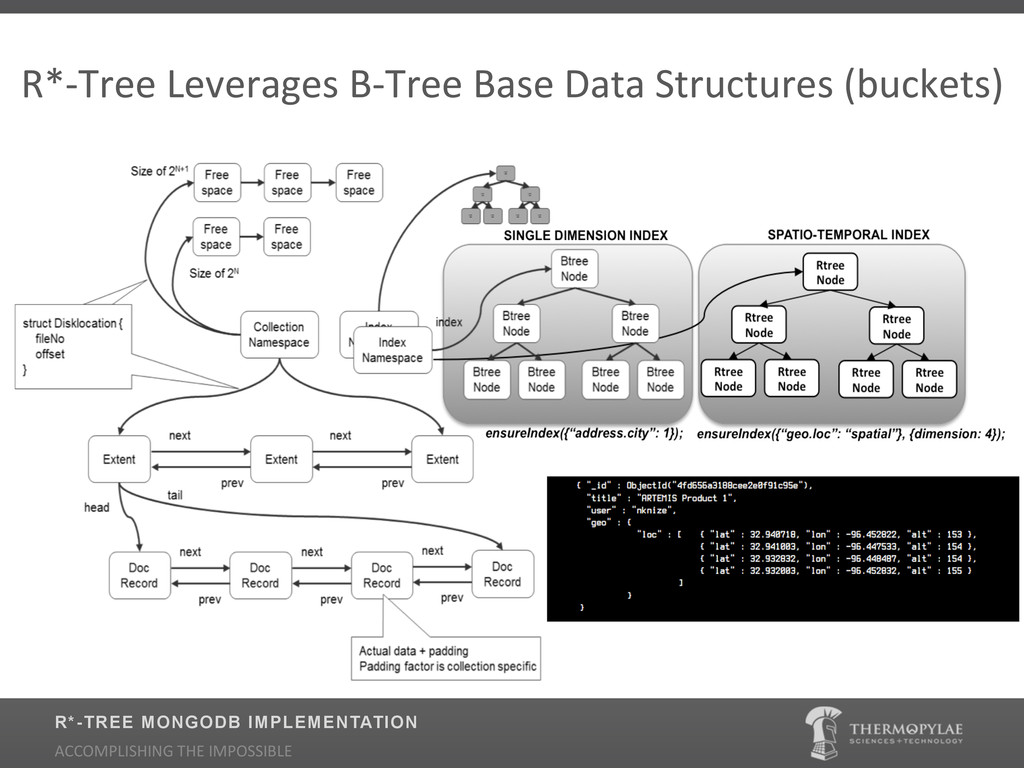
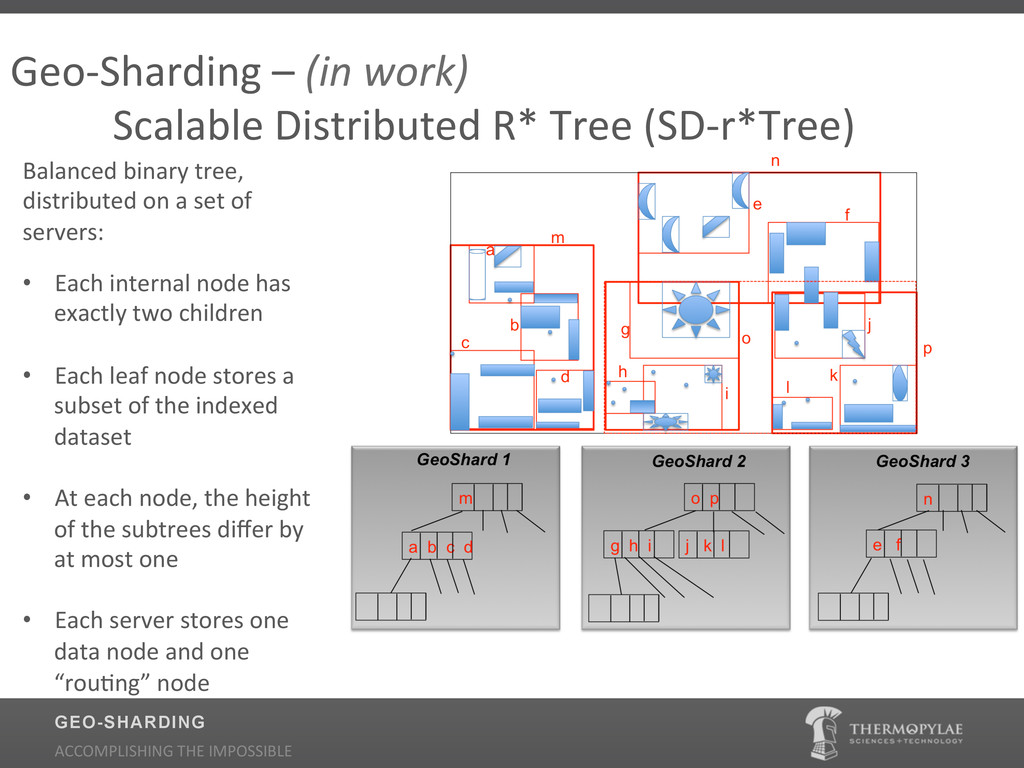
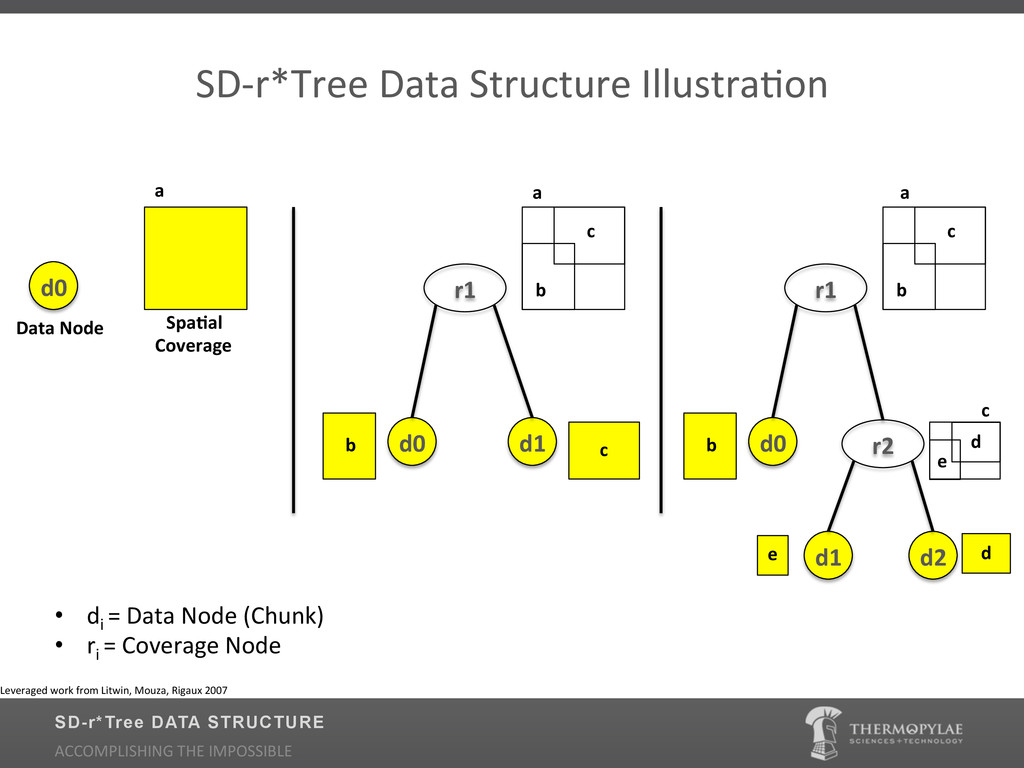
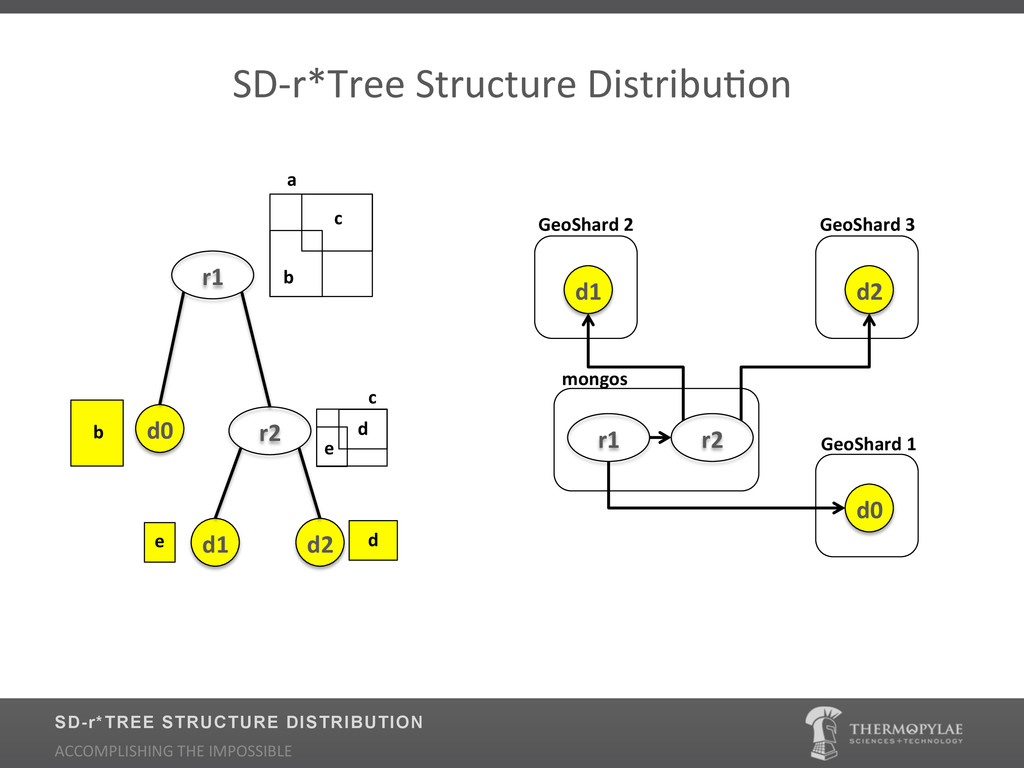
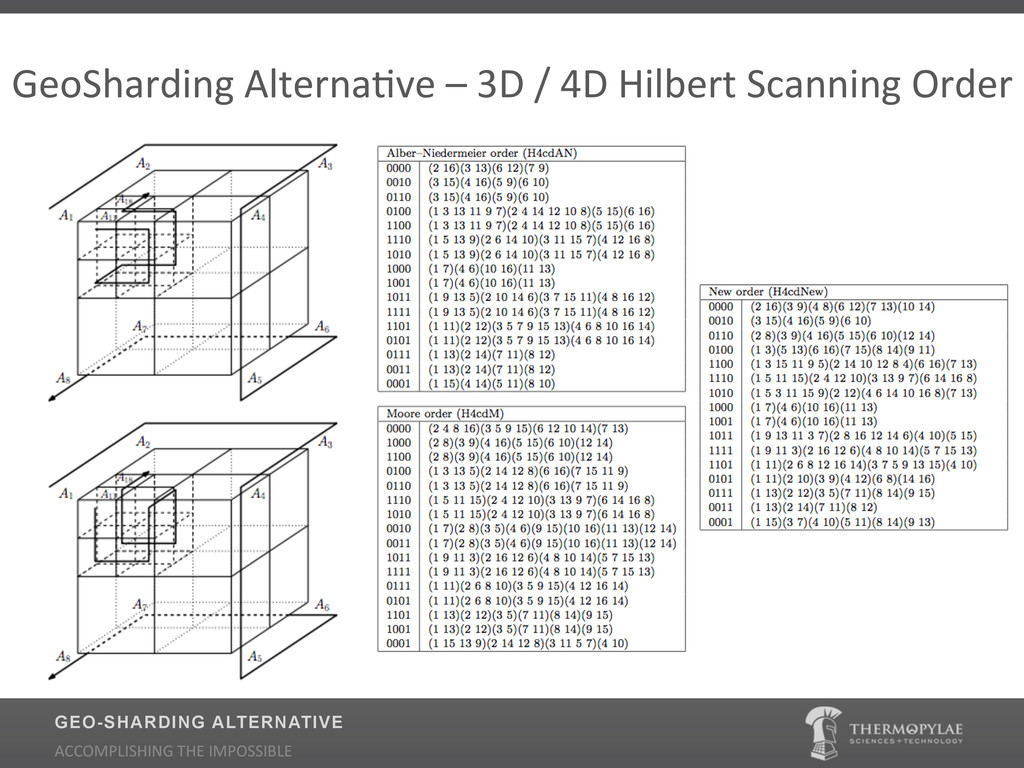
Traditional Geospatial Information Systems (GIS) have heavily depended on the use of Relational Databases (RDBMS) for indexing. Relational Databases place a priority on long running transactions, pre-defined fixed normalized schemas, and large joins which make them ill equipped to support Big Data scenarios of data volume, variability, and velocity. Relational database theory is not optimal for geospatial applications and decent relational geospatial databases are expensive and typically difficult to maintain. Learn how Thermopylae Sciences and Technology applied the non-relational (NoSQL) implementation of MongoDB for tackling dynamic geospatial data at massive scale. During the presentation we will cover: Why NoSQL technology over Relational Databases for scaling geospatial date, why MongoDB (what are the enhancements to the spatial indexer?) and where is it being used.
{kind=link}
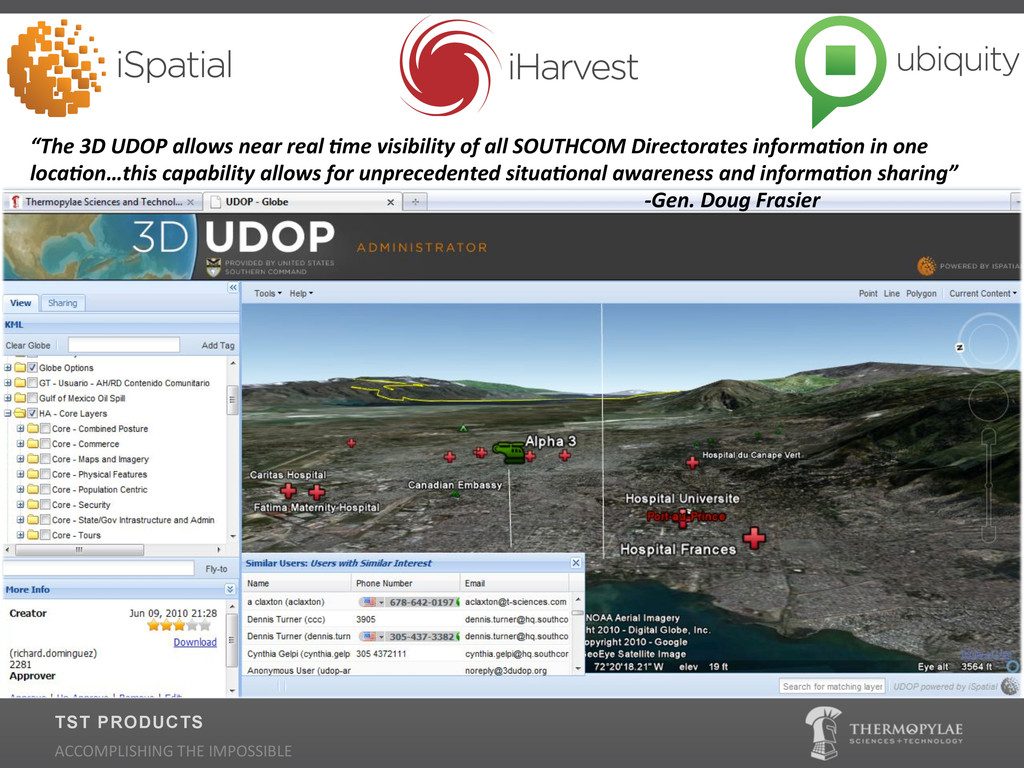{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
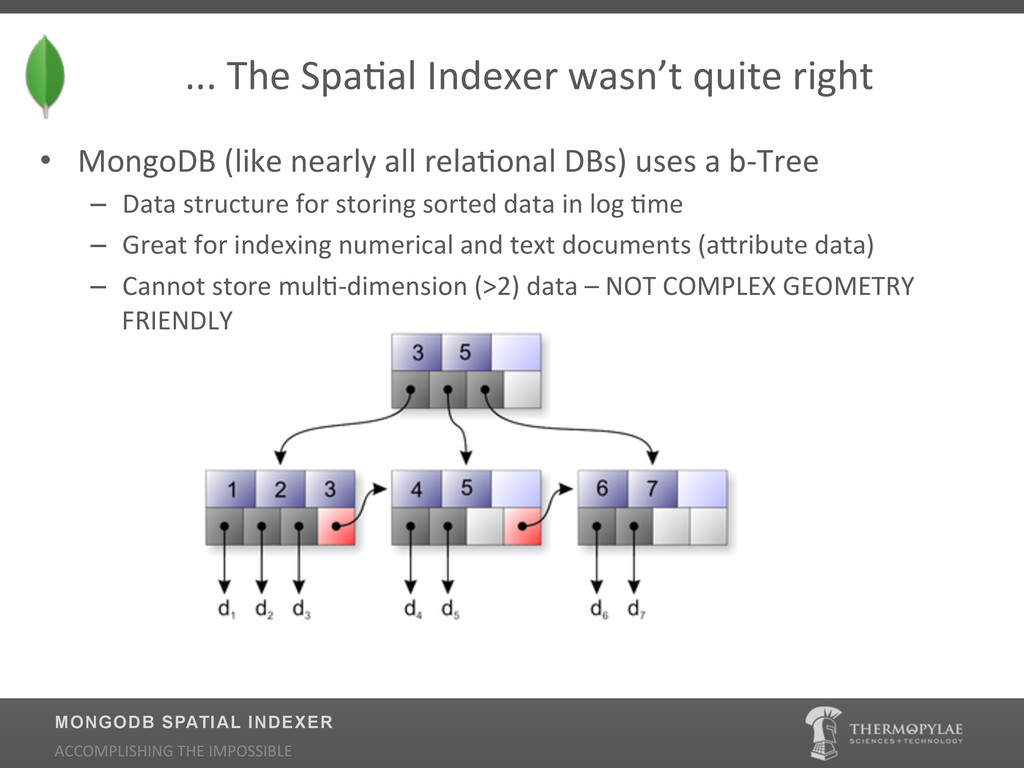{kind=link}
{kind=link}
{kind=link}
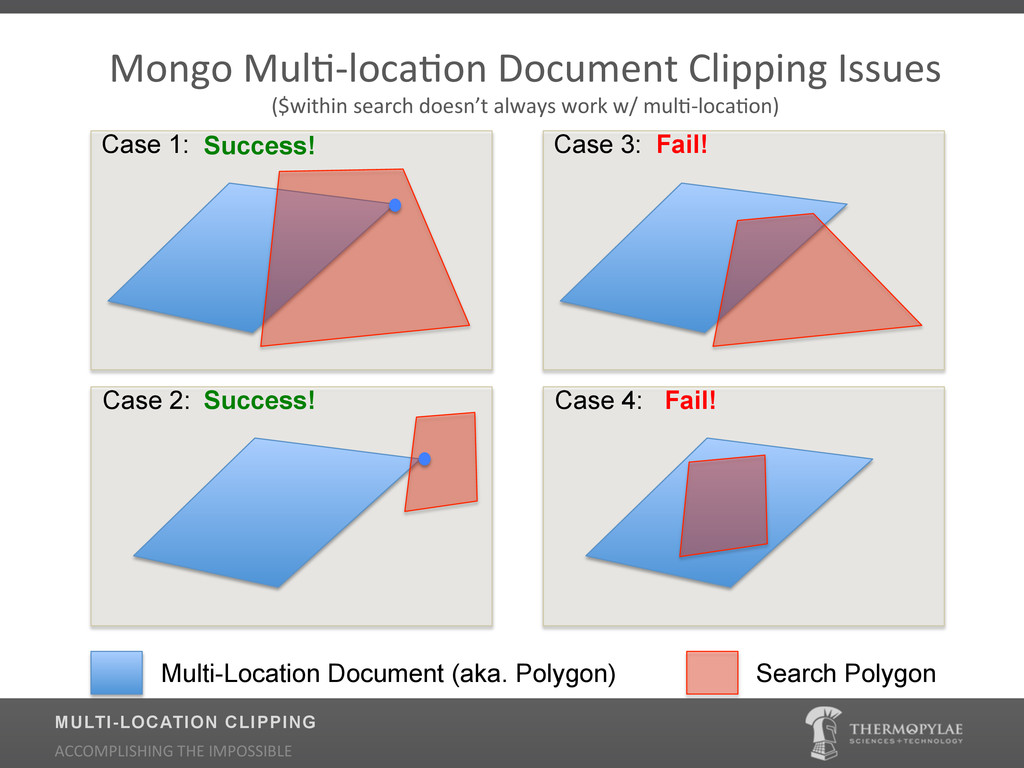{kind=link}
{kind=link}
{kind=link}
{kind=link}
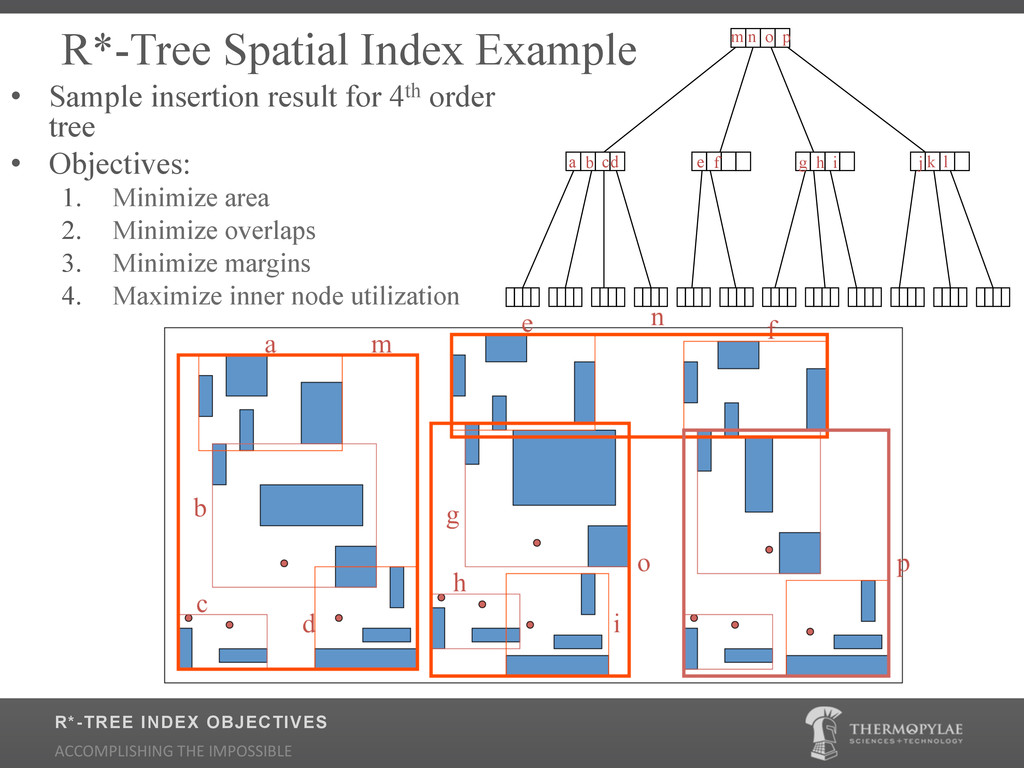{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
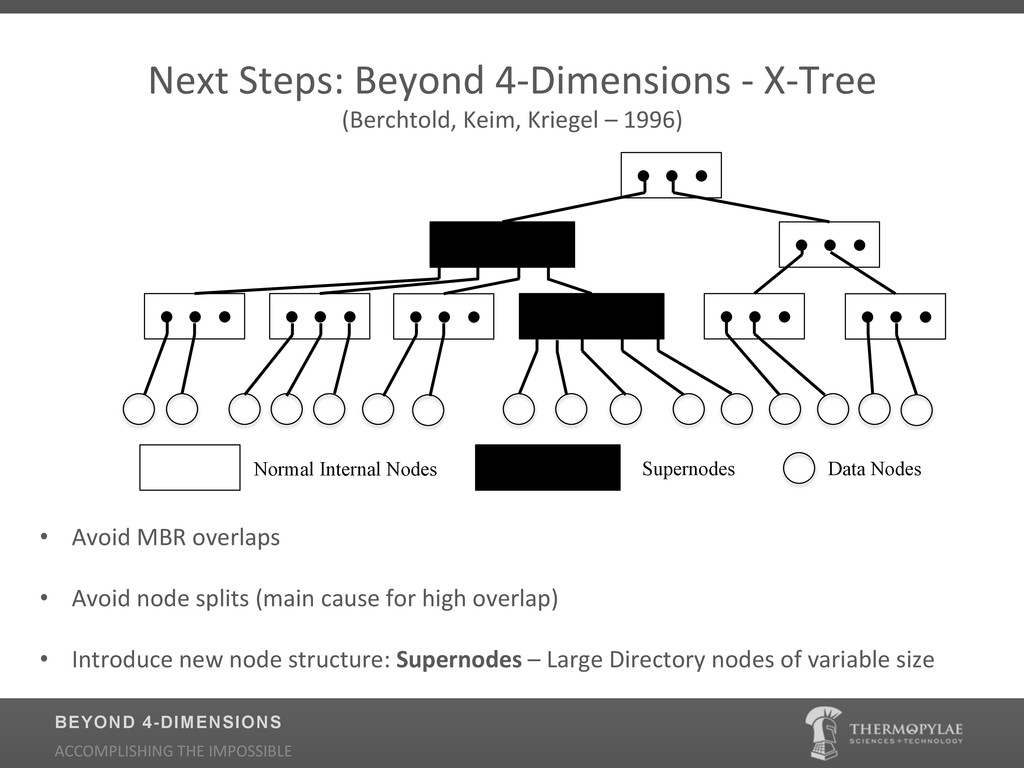{kind=link}
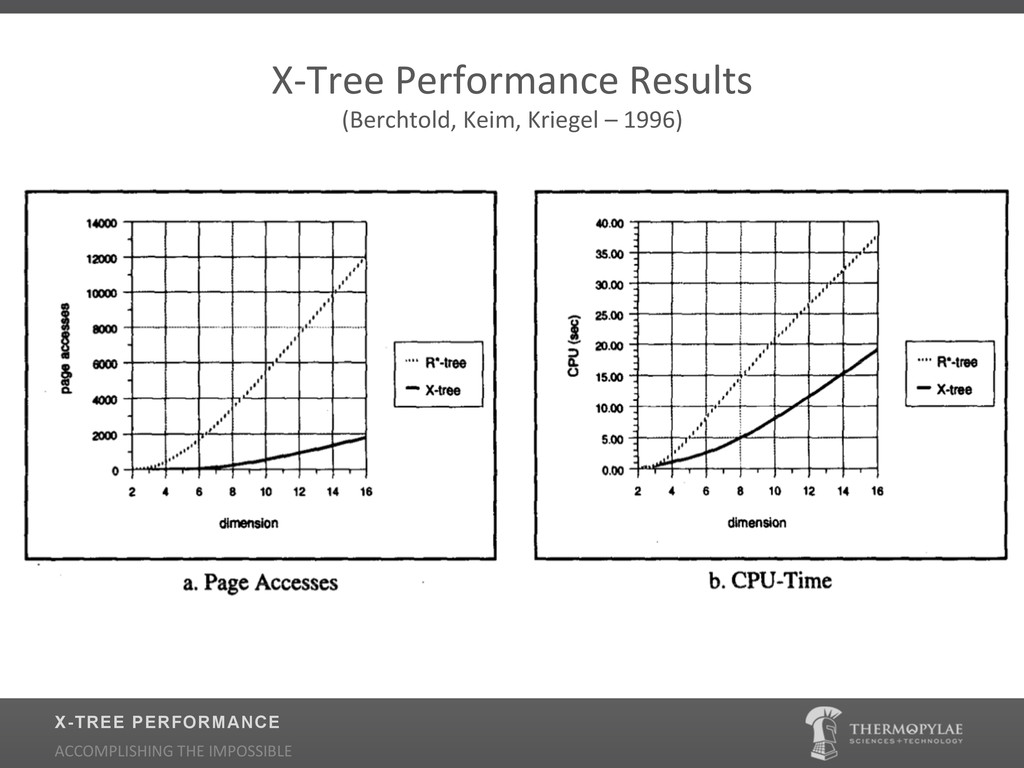{kind=link}
{kind=link}
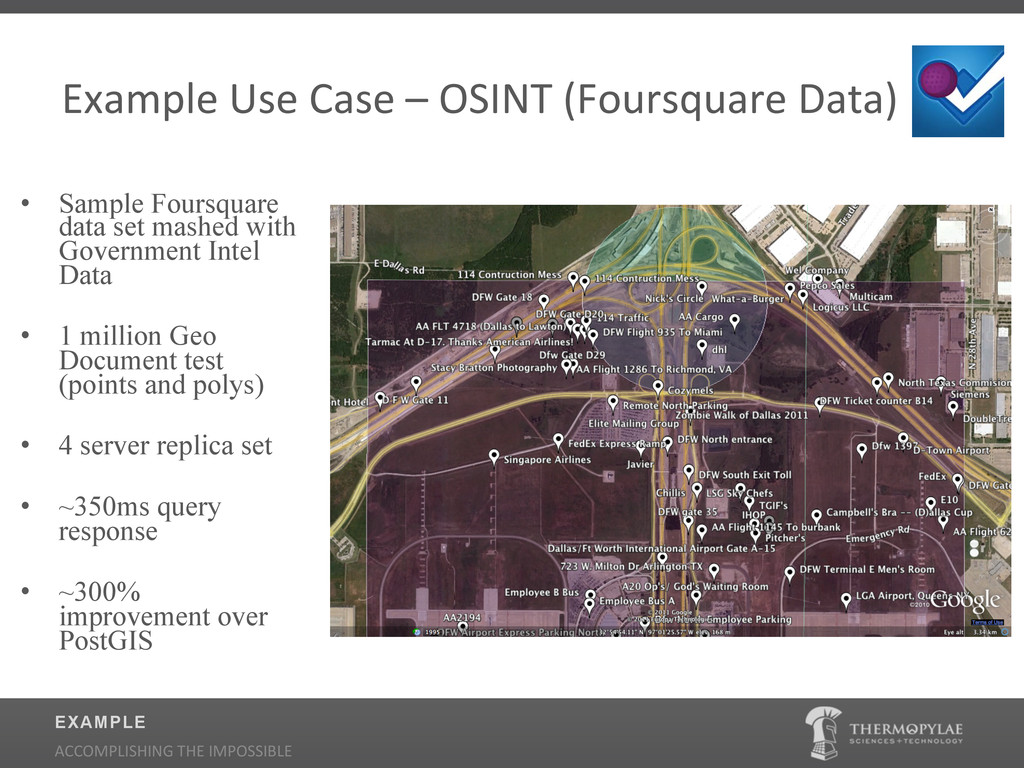{kind=link}
{kind=link}
![$ THANK$YOU$ QuesUons?$ $ Nicholas$Knize$ [email protected]$ THANK YOU ACCOMPLISHING$THE$IMPOSSIBLE$](https://files.speakerdeck.com/presentations/500844d2ded00e000200538c/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}