Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
バグから学習するAIのためのハーネスエンジニアリング
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Nibu
May 31, 2026
88
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
バグから学習するAIのためのハーネスエンジニアリング
LLM Agent Build with AI @Osaka
Nibu
May 31, 2026
More Decks by Nibu
See All by Nibu
【デブサミ2025関西】つくる力をうちから、ダイキンのアジャイル内製改革
morinibu
0
4.1k
RSGT2025 激録・開発密着10ヶ月!!〜拡大したスクラムチームの衝突〜
morinibu
0
2.8k
コードの可読性_人間がすべきことに注力する
morinibu
0
260
開発生産性の未来:大手製造業のアジャイル開発促進
morinibu
0
200
未経験のITエンジニアがアジャイル開発で内製化したら大変な目にあった話
morinibu
0
580
RSGT2024 激録・開発密着10ヶ月!!〜消えたスプリントゴールの行方〜
morinibu
1
1.7k
Featured
See All Featured
Designing Powerful Visuals for Engaging Learning
tmiket
1
470
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
A Soul's Torment
seathinner
6
3.1k
First, design no harm
axbom
PRO
2
1.2k
GraphQLとの向き合い方2022年版
quramy
50
15k
Design in an AI World
tapps
1
270
My Coaching Mixtape
mlcsv
0
180
Six Lessons from altMBA
skipperchong
29
4.4k
Site-Speed That Sticks
csswizardry
13
1.4k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
400
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
190
Transcript
バグから学習するAIのための ハーネスエンジニアリング 森鳰武史 LLM Agent Build with AI @Osaka
本セッションの目的 バグ修正のハーネスの知見をLLMハーネス全般に活かしてもらう LLM Agent Build with AI @Osaka
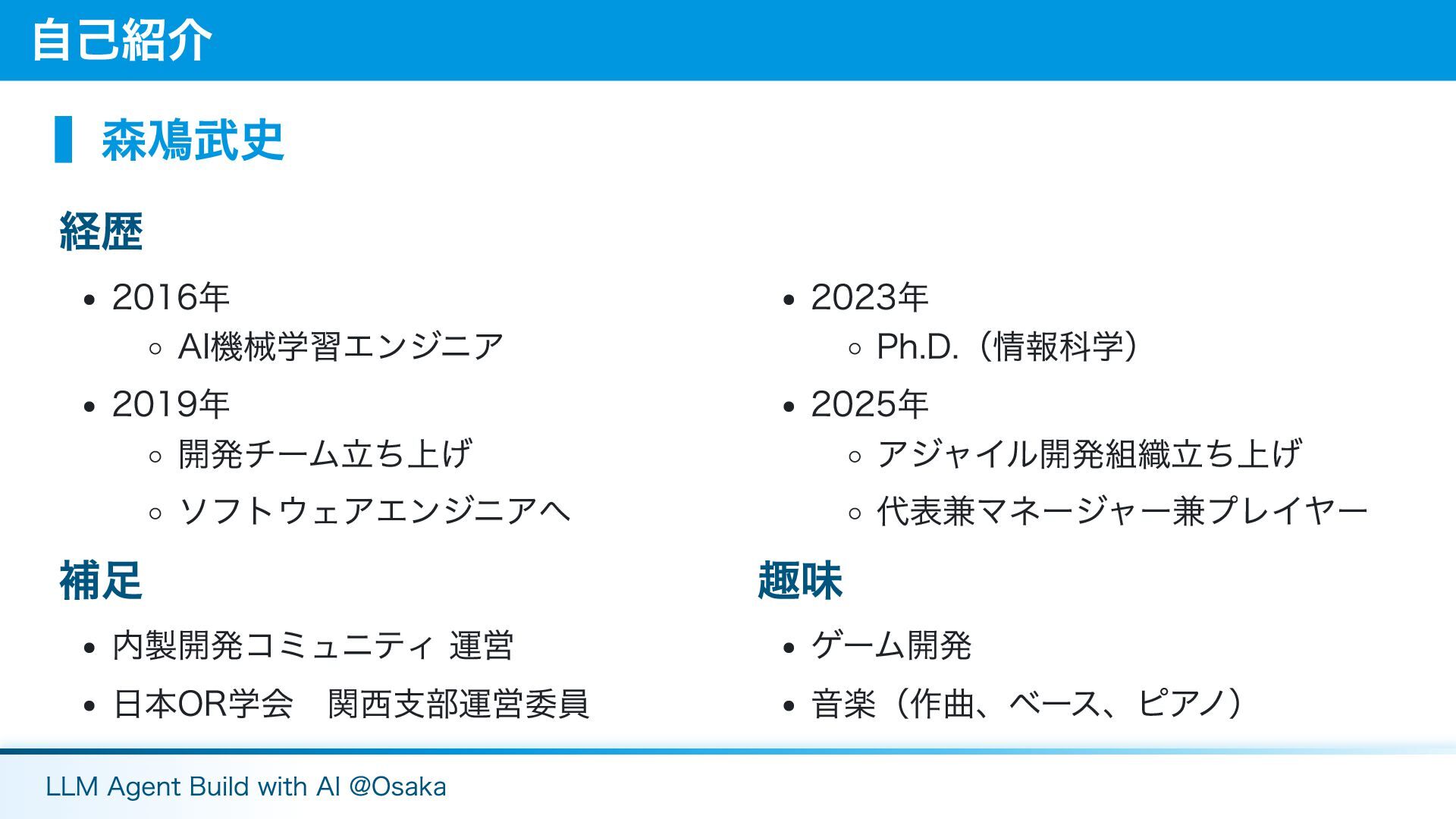
▍森鳰武史 経歴 2016年 AI機械学習エンジニア 2019年 開発チーム立ち上げ ソフトウェアエンジニアへ 補足 内製開発コミュニティ 運営
日本OR学会 関西支部運営委員 2023年 Ph.D.(情報科学) 2025年 アジャイル開発組織立ち上げ 代表兼マネージャー兼プレイヤー 趣味 ゲーム開発 音楽(作曲、ベース、ピアノ) 自己紹介 LLM Agent Build with AI @Osaka
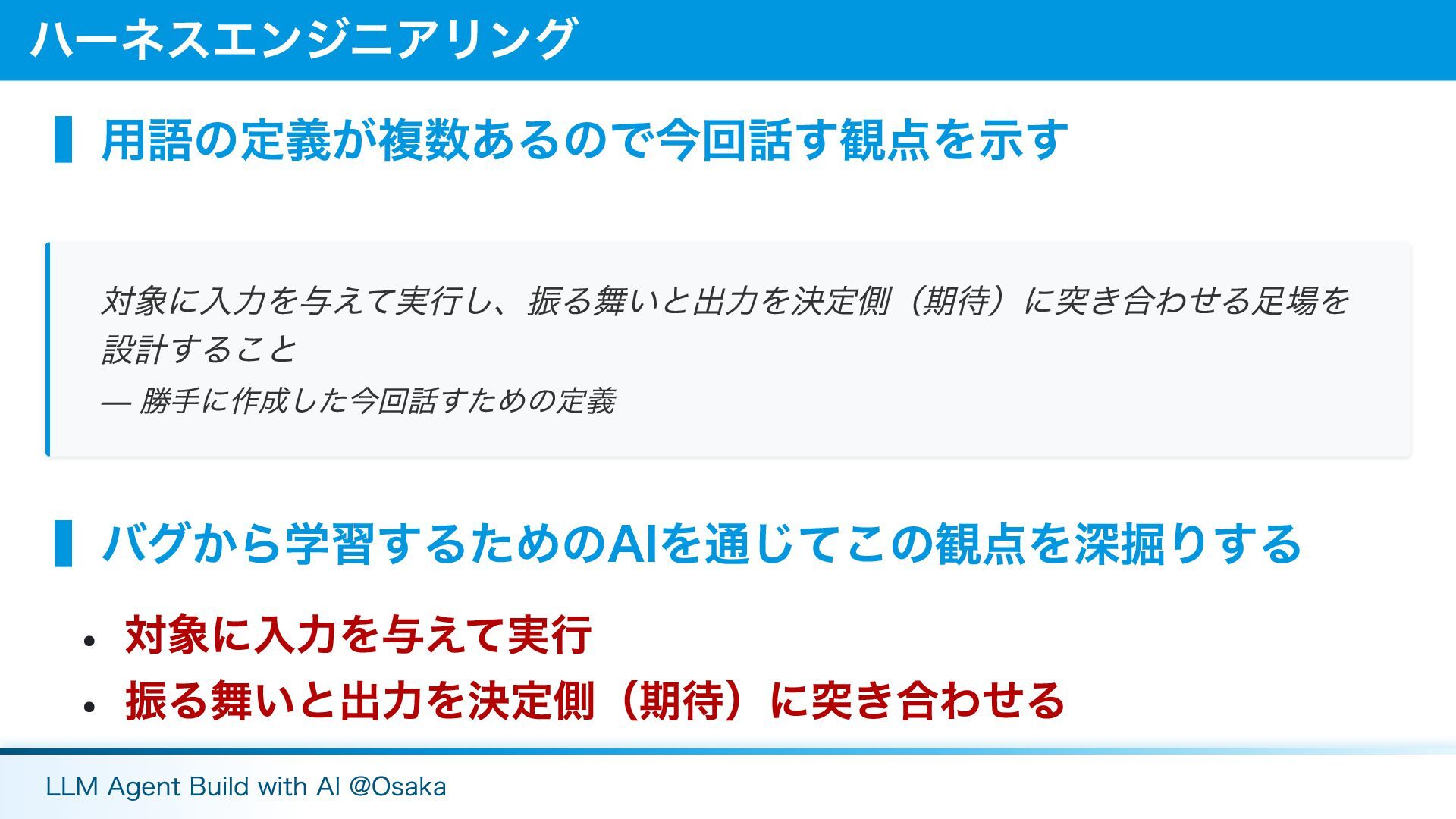
▍用語の定義が複数あるので今回話す観点を示す ▍バグから学習するためのAIを通じてこの観点を深掘りする 対象に入力を与えて実行 振る舞いと出力を決定側(期待)に突き合わせる ハーネスエンジニアリング 対象に入力を与えて実行し、振る舞いと出力を決定側(期待)に突き合わせる足場を 設計すること — 勝手に作成した今回話すための定義 LLM
Agent Build with AI @Osaka
バグを発見、報告されたら何をする? LLM Agent Build with AI @Osaka
▍なぜバグは修正するだけではだめなのか バグ修正だけでは再発は防げない その状況では、機能が増えるほどバグ発生数は増加する 結果、開発がバグ対応に追われる ▍本質的な解決 = 一度起きたバグの再発を抑える仕組みを作る 従来はエンジニアが知見を貯めてプロセスも改善してきた これをAIでどう効果的に実現するか バグから学習する必要性とは
LLM Agent Build with AI @Osaka
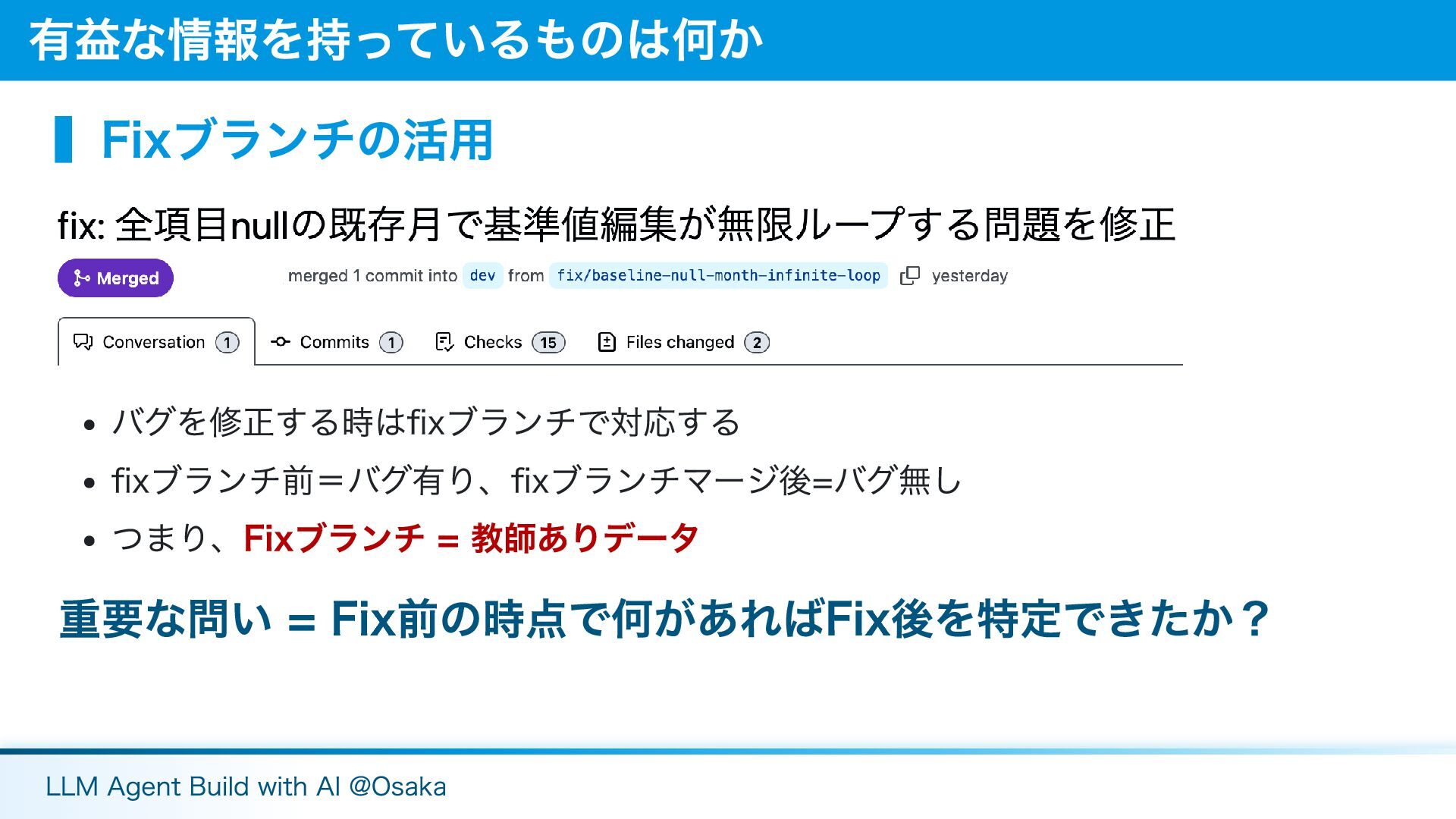
▍Fixブランチの活用 バグを修正する時はfixブランチで対応する fixブランチ前=バグ有り、fixブランチマージ後=バグ無し つまり、Fixブランチ = 教師ありデータ 重要な問い = Fix前の時点で何があればFix後を特定できたか? 有益な情報を持っているものは何か
LLM Agent Build with AI @Osaka
▍Fix前 + 入力(知見) => 修正したバグを発見する FIX PR からバグを見抜くのに必要だった知見を抽出 Fix前 +
入力(知見) => 修正したバグを発見できるか検査 発見できれば有用な知見である ▍修正したバグを発見できるか検査 どうやってLLMの推論を検査するか Fix前後で結果のみ異なる同じテストケースによって検査する 対象に入力を与えて実行 LLM Agent Build with AI @Osaka
▍Fix前に失敗するテストを書けること バグがあるとLLMが推論する 推論が正しいならば、ある条件で期待通りの動作にならない つまり、fix前では失敗するテストケースを作成できるはず ▍そのテストはFix後に成功すること バグを正しく推定しているなら、Fix後は期待通り動作するはず つまり、fix後では作成したテストケースはPASSするはず この二つを満たす時、LLMはバグを正しく推定したと言える Fix前後で結果のみ異なる同じテストケース LLM
Agent Build with AI @Osaka
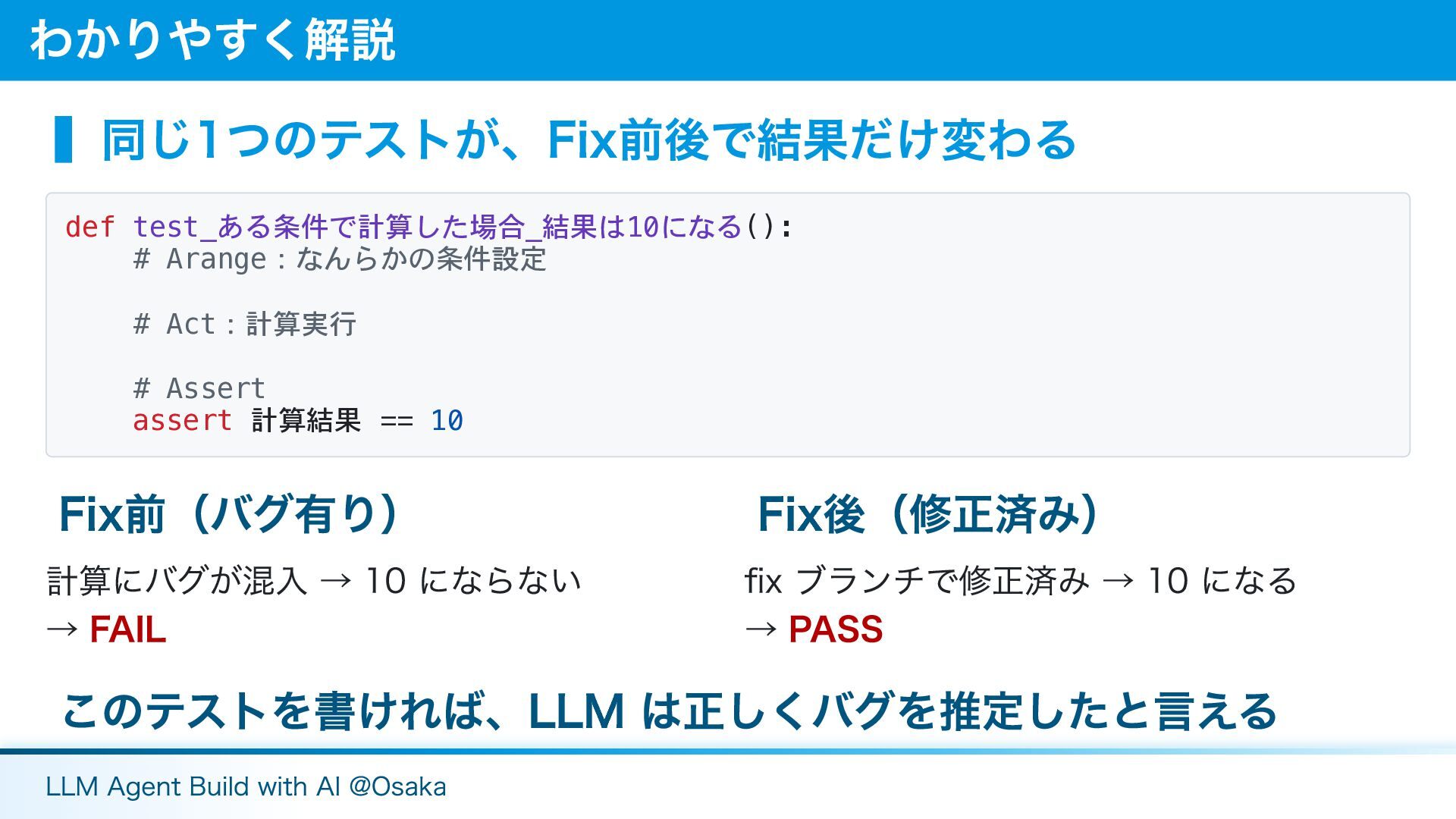
▍同じ1つのテストが、Fix前後で結果だけ変わる def test_ある条件で計算した場合_結果は10になる(): # Arange:なんらかの条件設定 # Act:計算実行 # Assert assert
計算結果 == 10 Fix前(バグ有り) 計算にバグが混入 → 10 にならない → FAIL Fix後(修正済み) fix ブランチで修正済み → 10 になる → PASS このテストを書ければ、LLM は正しくバグを推定したと言える わかりやすく解説 LLM Agent Build with AI @Osaka
bug-hunt LLM Agent Build with AI @Osaka
知見によって事前(PR作成時)にバグを推定するSkill ▍対象に入力を与えて実行 Fix前に知見を与えることでバグを推定できるようにする ▍振る舞いと出力を決定側(期待)に突き合わせる Fix前の状態で、失敗するテストケースが書けたか そのテストはFix後に成功するか これを満たす有用な知見のみをskillに貯めていく bug-huntの仕組み整理 LLM Agent
Build with AI @Osaka
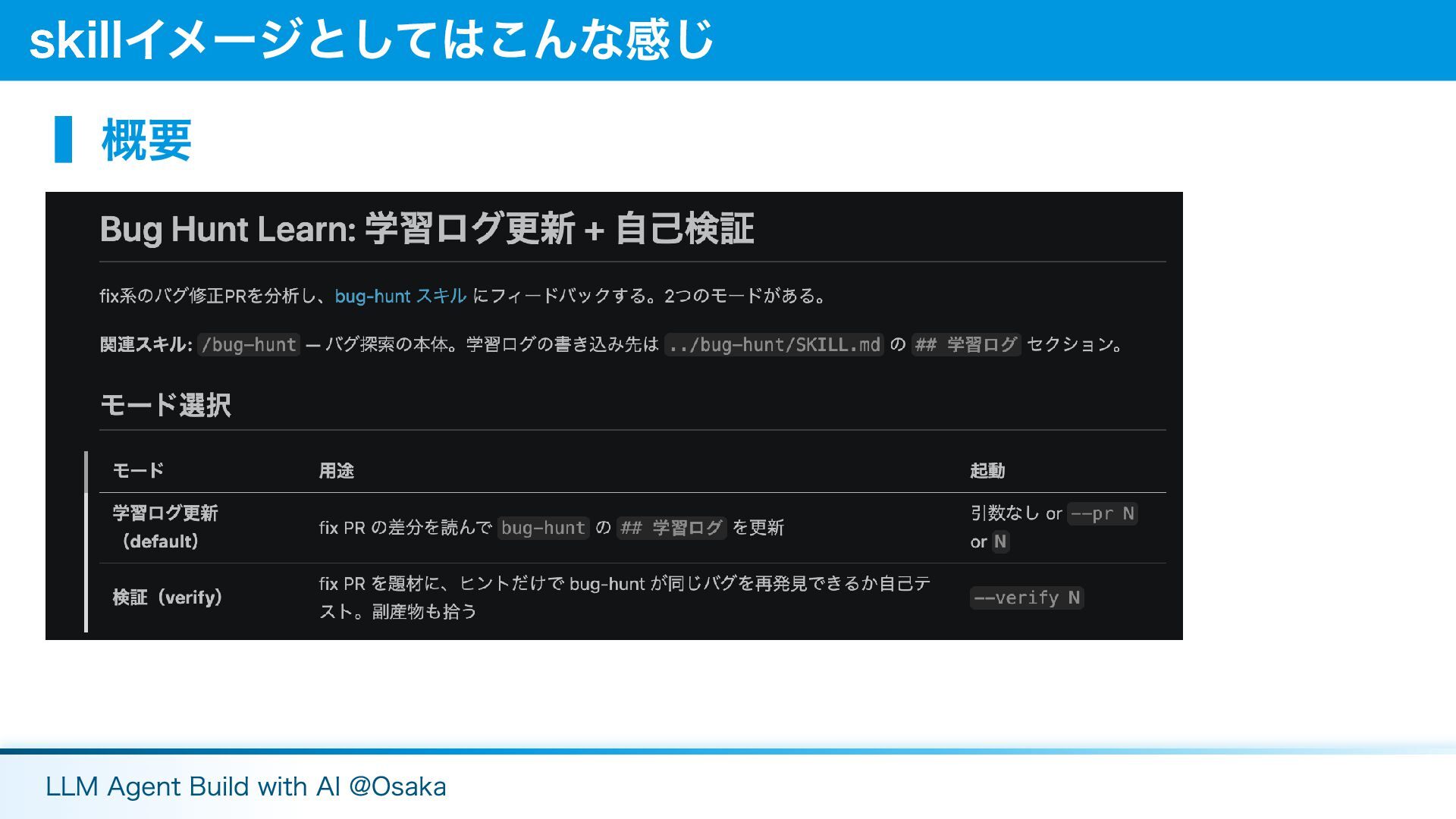
▍概要 skillイメージとしてはこんな感じ LLM Agent Build with AI @Osaka
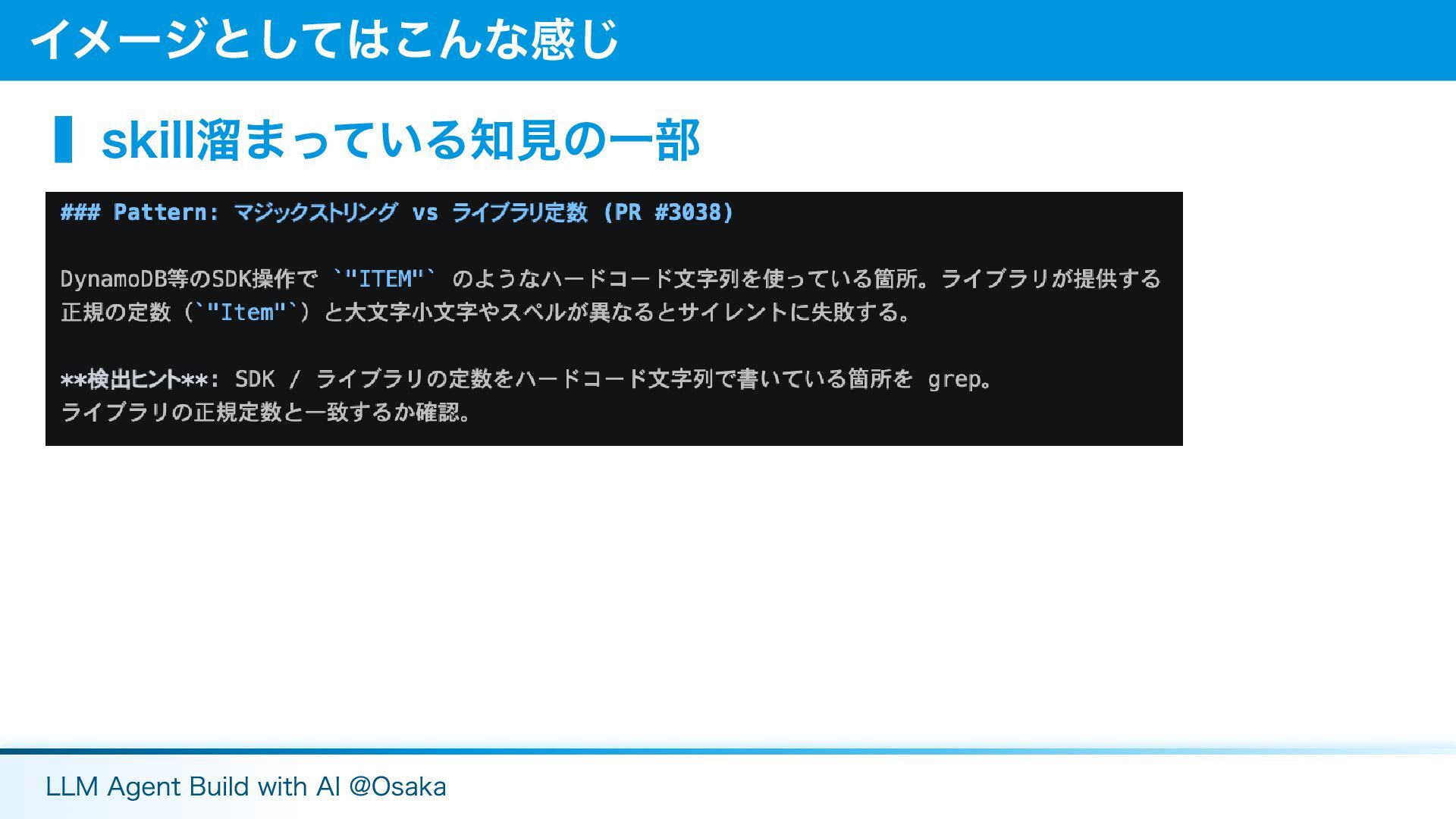
▍skill溜まっている知見の一部 イメージとしてはこんな感じ LLM Agent Build with AI @Osaka
似たようなものあるんじゃないの? LLM Agent Build with AI @Osaka
feature = { entrypoints, ownedFiles, contextFiles, tests, trustBoundaries } →
この bounded context を provider(codex 等)に渡して review heuristic mapper 言語/FW 規約で機械的に切る 細・速・無料・決定論 カバレッジに偏り agent mapper LLM がドメイン凝集で束ねる 広域カバレッジ 粗・遅・LLM コスト clawpatch https://github.com/openclaw/clawpatch
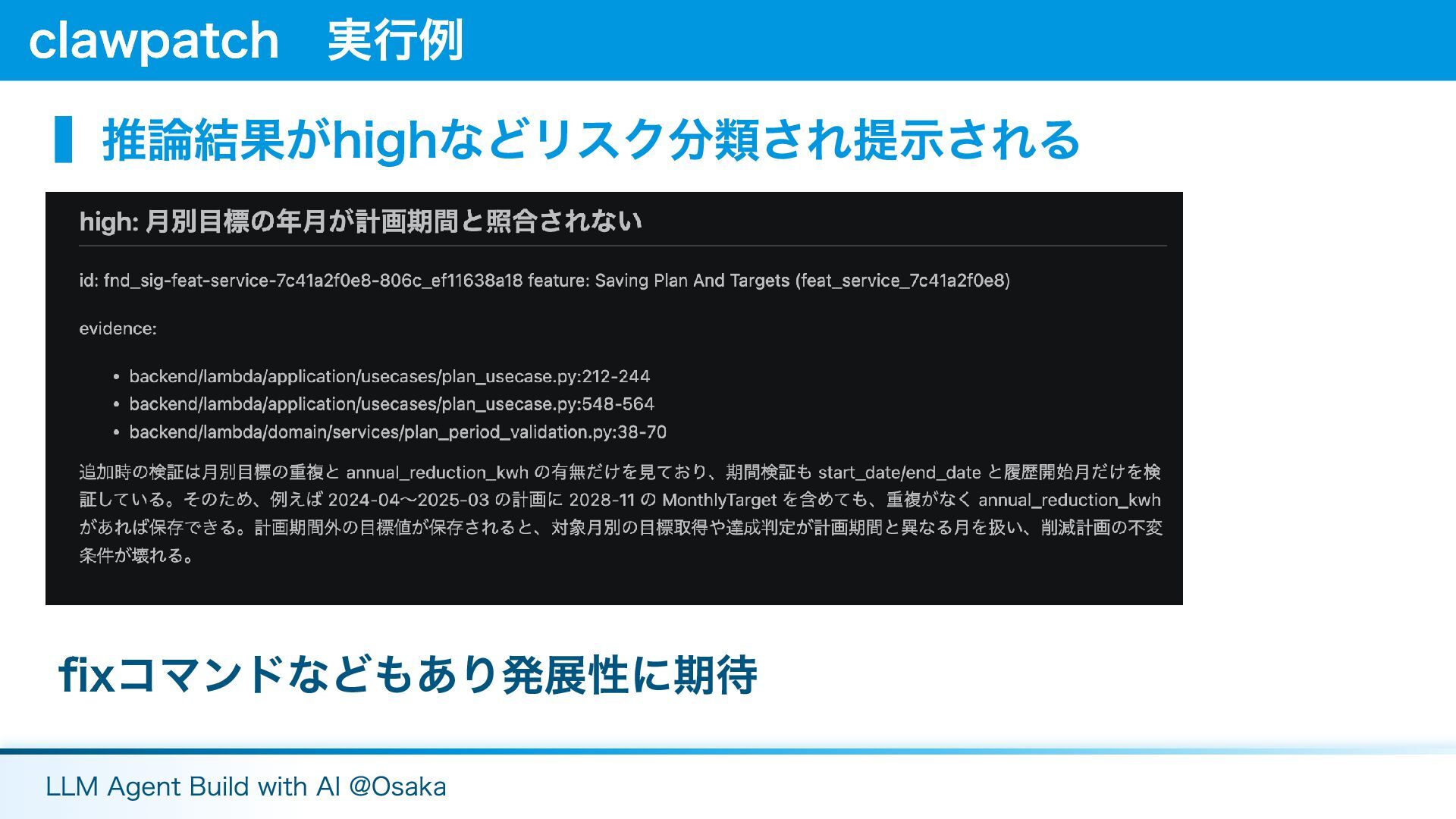
▍推論結果がhighなどリスク分類され提示される fixコマンドなどもあり発展性に期待 clawpatch 実行例 LLM Agent Build with AI @Osaka
No Free Lunch あらゆる問題に最適な単一の探索器は存在しない No Silver Bullet 万能の解決策(銀の弾丸)は無い Wolpert &
Macready 1997 (No Free Lunch) / F. Brooks 1986 (No Silver Bullet) LLM Agent Build with AI @Osaka
▍なので組み合わせて活用する clawpatch(汎用) feature 単位の構造化や探索が得意 汎用的なバグ を発見する プロジェクト固有にチューニングしない bug-hunt(特化) 推論の証明や知見抽出が得意 プロジェクトで実際に起きたバグに特化
知見を貯める必要がある ▍検証したいこと clawpatch単体でこれまでに実際に発生したバグは発見できるか? 万能の探索器は無い LLM Agent Build with AI @Osaka
▍bug-hunt の知見を入れると検出できる Fix PR clawpatch のみ clawpatch + bug- hunt
知見 #3169 — アラート (backend) ✘ 検出できず ✓ 検出 #3350 — 無限ループ (frontend) ✘ 検出できず ✓ 検出 ▍知見注入するのが必ずしも優れているわけではない 特化した知見を入れたら汎用的なバグは見つからなくなる 実 PR 2 件で比較 LLM Agent Build with AI @Osaka
▍役割が補完的なのでUnion で押さえる clawpatchによる探索結果(一般的なバグ) clawpatch + bug-huntによる探索結果(プロジェクト固有ぽいバグ) どちらも実行してfindingsを分析する ▍残る課題 発見したfindingsは全部人間が確認するのか... clawpatch
× bug-huntのシナジー LLM Agent Build with AI @Osaka
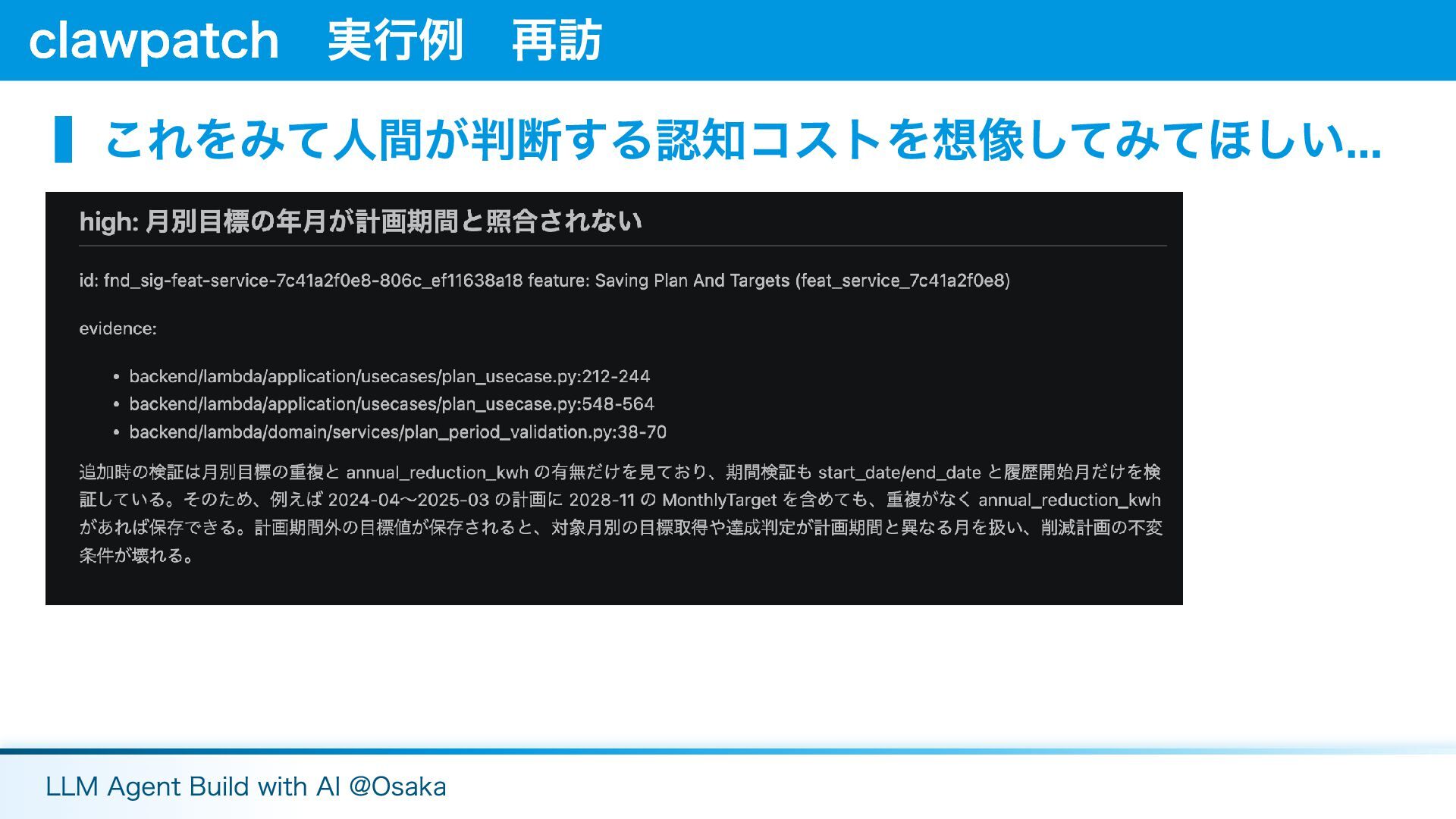
▍これをみて人間が判断する認知コストを想像してみてほしい... clawpatch 実行例 再訪 LLM Agent Build with AI @Osaka
1. 怠惰(Laziness) 2. 短気(Impatience) 3. 傲慢(Hubris) Larry Wall & R.
Schwartz, "Programming Perl" (O'Reilly) LLM Agent Build with AI @Osaka
▍推論の確からしさを3レベルに分ける L1 — LLM 推論(findgins / 非決定) L2 — 観測事実(テストで再現できる
/ 決定的) L3 — 人間判断(意図違反か・直す影響 / 仕様・人間) ▍L1をたくさん発見しても検査が大変 findings(L1) は LLM の推論 にすぎない=偽陽性も混ざる 結局、人間が1件ずつ判断する もう少し賢く解決できないか LLM が見つけた findings について LLM Agent Build with AI @Osaka
▍bug-huntのPROVE機能 fix前の状態でテストケース作成 fix前は落ちてfix後にPASSするならバグの存在を証明したことになる ▍findings(L1) → PROVE → L2 へ格上げする findings(L1)
の情報をもとに 修正させる(clawpatch fix) PROVE = 修正前に落ちて修正後は通るテストが書けるか検査(bug-hunt) 書けたら L2(観測事実)に格上げ / 書けなければ L1 のまま clawpatch(union)で探索、bug-huntでPROVE そこでbug-huntのPROVE機能の再利用 LLM Agent Build with AI @Osaka
▍テストケースを読む = 挙動がわかるので人間が判断できる def test_途中のsaveが失敗した場合_中間計画が永続化されない(): # Arrange: 2022年度の計画 → 2026年まで3年度分の追いつけが必要
prop = _make_property_with_plan(_make_plan("2022-04", "2023-03")) property_repo.save(prop) # 2回目の保存だけを失敗させる(DB障害・タイムアウトを模擬) # monkeypatch → 2回目の save() で RuntimeError # Act: 更新処理は途中で中断する with pytest.raises(RuntimeError): renew_plans_until_registered_month(prop, "2026-02", property_repo) # Assert: 操作が失敗した以上、DBには「元の計画」だけが残るべき saved = property_repo.find_saving_plans(...) assert [p.start_date for p in saved] == ["2022-04-01"] PROVEに成功したテストのサンプル LLM Agent Build with AI @Osaka
▍レビューまたは定期実行時に有用 ① PR レビュー時 L1とL2で扱いをわける → L2は自動修正、L1は再調査 ② 夜間探索 L2
findings を修正させて PR を作成 → 人間が翌日判断、問題なければ merge ▍学習ループに戻る fixブランチがマージされるとactionsでbug-hunt が学習 運用を回すほど発見性も判断効率も複利で強くなる これでバグから学習するAIの仕組みができた L2 findings の利用方法 LLM Agent Build with AI @Osaka
▍本セッションにおけるハーネスの観点 対象に入力を与えて実行する 振る舞いと出力を決定側(期待)に突き合わせる ▍バグから学習するAIを効果的に制御するには 推論を確からしい状態にする = 状況再現(テストを書かせる) 正しいフィードバックで改善する = fix
ブランチを学習源にする 使うほどよくなる複利的な仕組みを作る = fix merge actions自動化 これらはバグ修正AIに限らずLLM 運用全般に適用できる まとめ LLM Agent Build with AI @Osaka
▍ゲームで詰まったときに聞いて解決できるアプリ(開発中) ChatGPT / Claude = 汎用 vs ゲーム攻略 Agent =
特化 推論を確からしい状態にする = ソースと矛盾がないこと、複数ソースで確証度を向上 正しいフィードバックで改善する = 回答が役に立たなかった(失敗)時を学習源に 使うほどよくなる複利的な仕組みを作る = 定期的に貯めた失敗ケースから推論を改善 アプリが利用されるほど改善されていく 参考例:同じ観点を別ドメインに当てる LLM Agent Build with AI @Osaka
ご清聴ありがとうございました ご清聴ありがとうございました LLM Agent Build with AI @Osaka
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}