Доклад с конференции Moscow Python Conf 2016 (http://conf.python.ru)
Видео: https://conf.python.ru/django-orm/
В докладе будут затронуты большинство тем, которые необходимо знать современному python-разработчику, чтобы эффективно использовать функционал Django-ORM для построения высоконагруженных web-проектов.
Поговорим и про классические ошибки при работе с QuerySet’ами и про профилирование и про code style. Выясним как можно сэкономить память и время при выполнении запросов, покажу популярные ошибки при проектировании схемы данных и при использовании миграций, а так же рассмотрим несколько распространенных задач современного веба, которые в Django еще не решены или решены некорректно.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
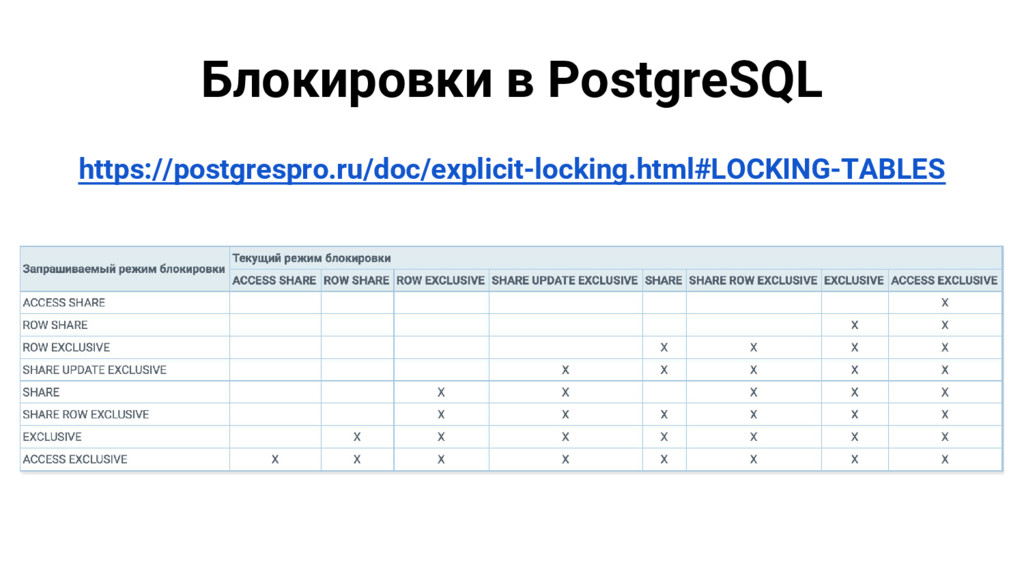{kind=link}
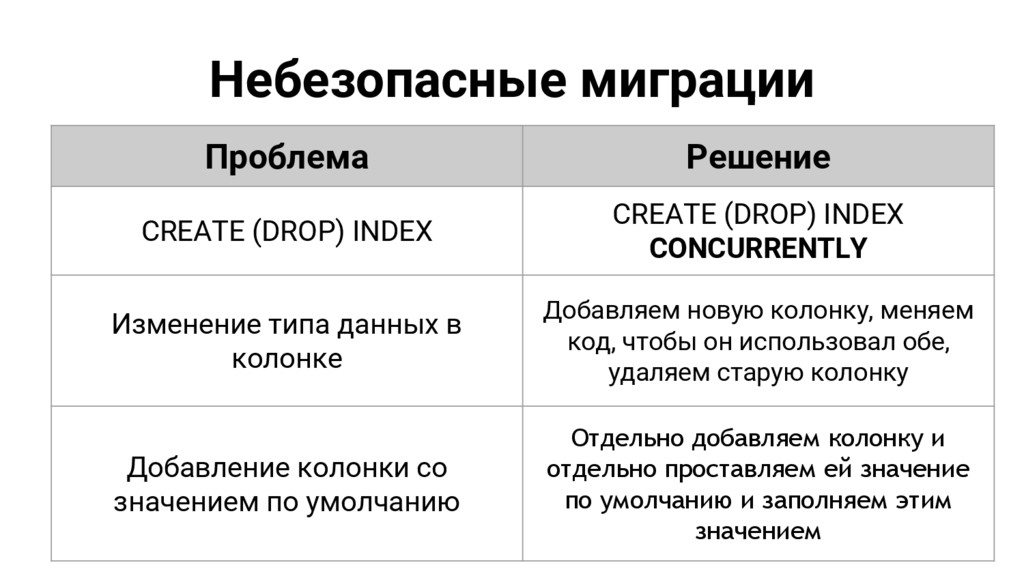{kind=link}
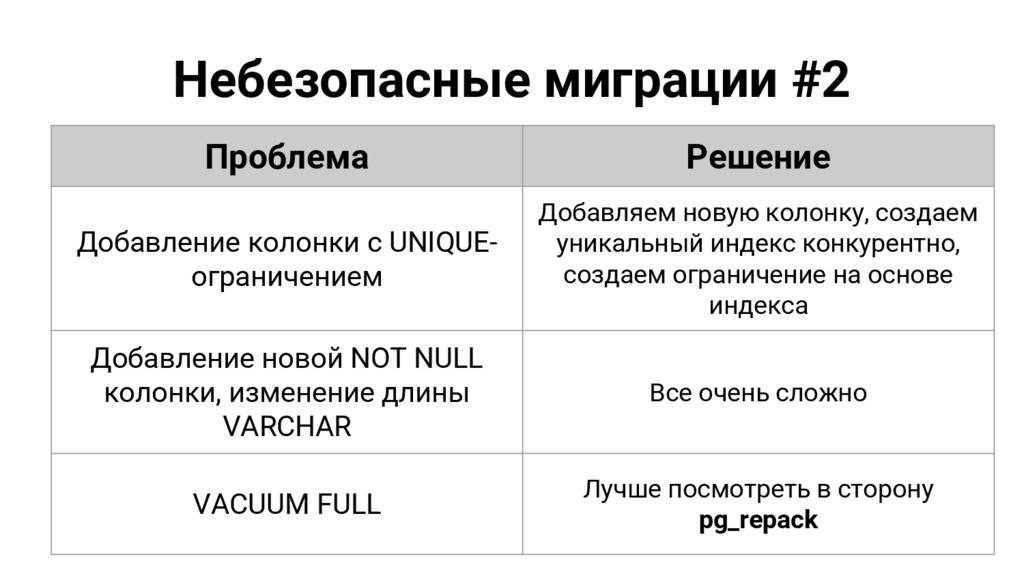{kind=link}
{kind=link}
{kind=link}
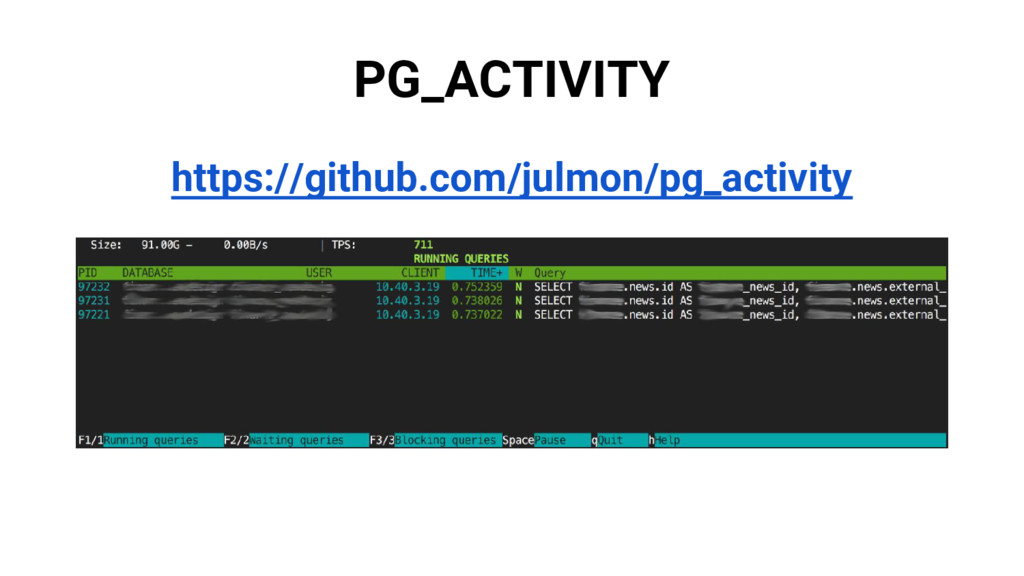{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}