появится на Поклонной горе. Он вошёл в Книгу рекордов Гиннесса в 2016 году в номинации «Самая большая светодиодная скульптура в мире»….” https://www.mos.ru/news/item/18536073/ “Гигантский ёлочный шар с танцплощадкой внутри устанавливают на Поклонной горе. Сборка продлится до середины следующей недели. Шар вошёл в Книгу рекордов Гиннесса в 2016 году в номинации «Самая большая светодиодная скульптура в мире»…” https://www.mos.ru/news/item/13091073/ “II Международный фестиваль фейерверков «Ростех» пройдёт в Москве 23 и 24 июля...” https://www.mos.ru/news/item/11866073/ “23 и 24 июля в столице состоится II Международный фестиваль фейерверков «Ростех»...”
для устранения дублей в поиске мы используем данный метод. Довольно часто на базе одного пресс-релиза появляются “братья по содержанию” 2. При помощи этого алгоритма наш краулер понимает изменился ли контент на странице и нужно ли обновить поисковый индекс 3. Несколько схожим методом мы боремся с дублями изображений
назвать тематическим, но мы будем :) 2. Данным методом нельзя построить антологию, или оценить меру схожести двух документов. Он подходит только для поиска дублей. 3. Дублями мы будем считать те тексты, которые состоят из одинаковых значимых слов 4. Порядок слов не имеет решающего значения
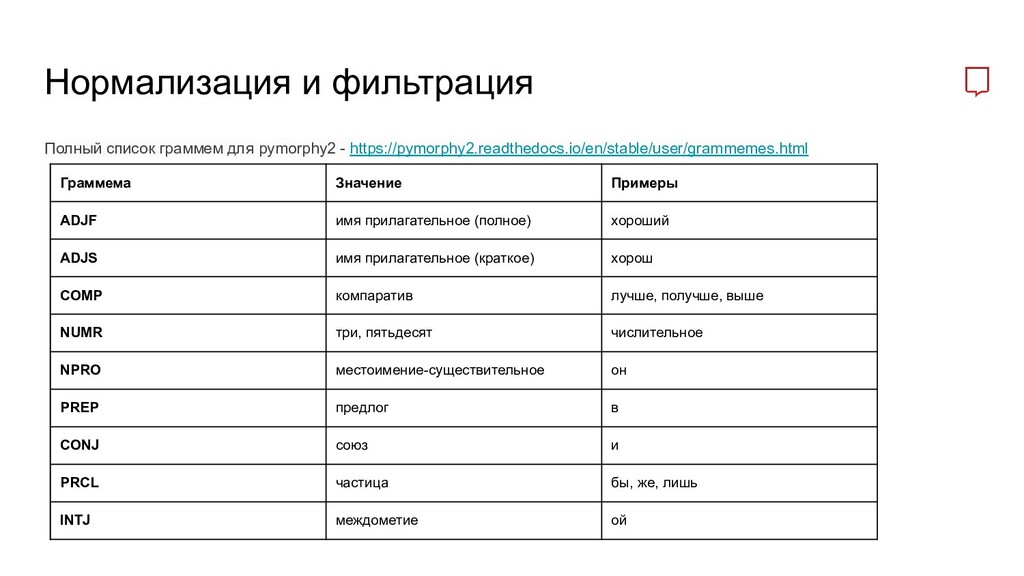
Граммема Значение Примеры ADJF имя прилагательное (полное) хороший ADJS имя прилагательное (краткое) хорош COMP компаратив лучше, получше, выше NUMR три, пятьдесят числительное NPRO местоимение-существительное он PREP предлог в CONJ союз и PRCL частица бы, же, лишь INTJ междометие ой
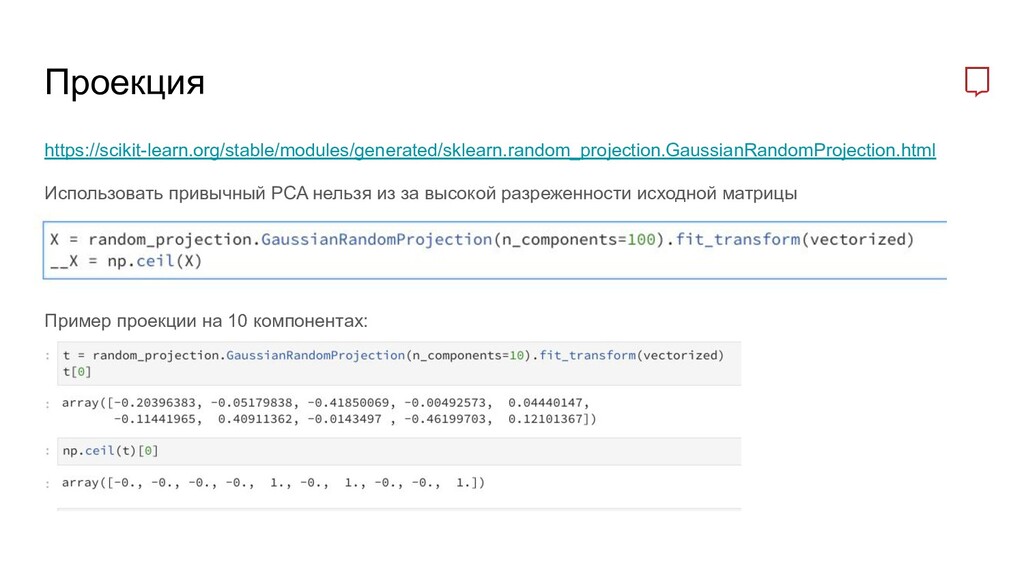
провести их векторизацию. Звучит пугающе, но на самом деле все очень просто – все тексты разбиваются на уникальные слова и кодируются. По сути они преобразуются в большой список и дальше вместо каждого ключевого слова мы размещаем длинную строчку цифр, соответствющую нашему списку всех уникальных слов. Более подробно можно познакомиться тут https://searchengines.guru/ru/articles/36951
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Спасибо за внимание Михаил Жуковец git: github.com/neroslam/doubles_finder mail: [email protected]](https://files.speakerdeck.com/presentations/b6aab1052b1443b5ad81955137f55134/slide_14.jpg){kind=link}