{$match: {author:”bob”}} $match {author: "bob", pageViews:5, title:"Lorem Ipsum..."} {author: "bill", pageViews:3, title:"dolor sit amet..."} {author: "joe", pageViews:52, title:"consectetur adipi..."} {author: "jane", pageViews:51, title:"sed diam..."} {author: "bob", pageViews:14, title:"magna aliquam..."} {author: "bob", pageViews:53, title:"claritas est..."} filtered with: {$match: {pageViews:{$gt:50}} {author:"bob",pageViews:5,title:"Lorem Ipsum..."} {author:"bob",pageViews:14,title:"magna aliquam..."} {author:"bob",pageViews:53,title:"claritas est..."} {author: "joe", pageViews:52, title:"consectetur adipiscing..."} {author: "jane", pageViews:51, title:"sed diam..."} {author: "bob", pageViews:53, title:"claritas est..."} Input: Thursday, March 22, 12
{kind=link}
{kind=link}
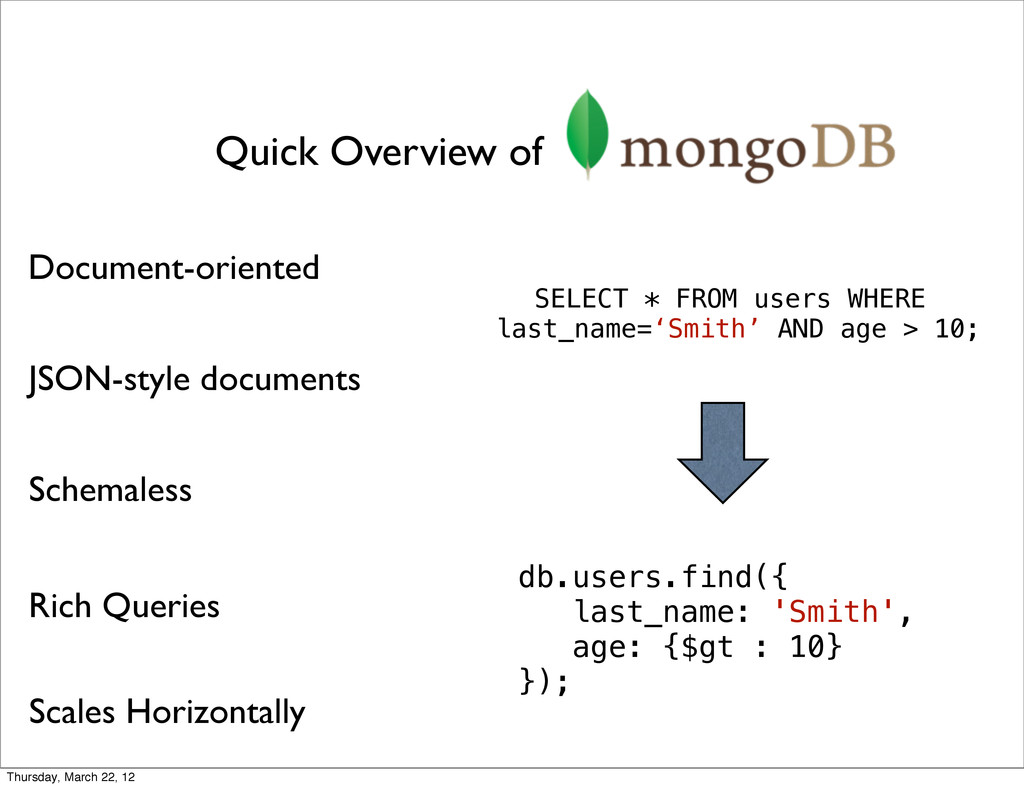{kind=link}
{kind=link}
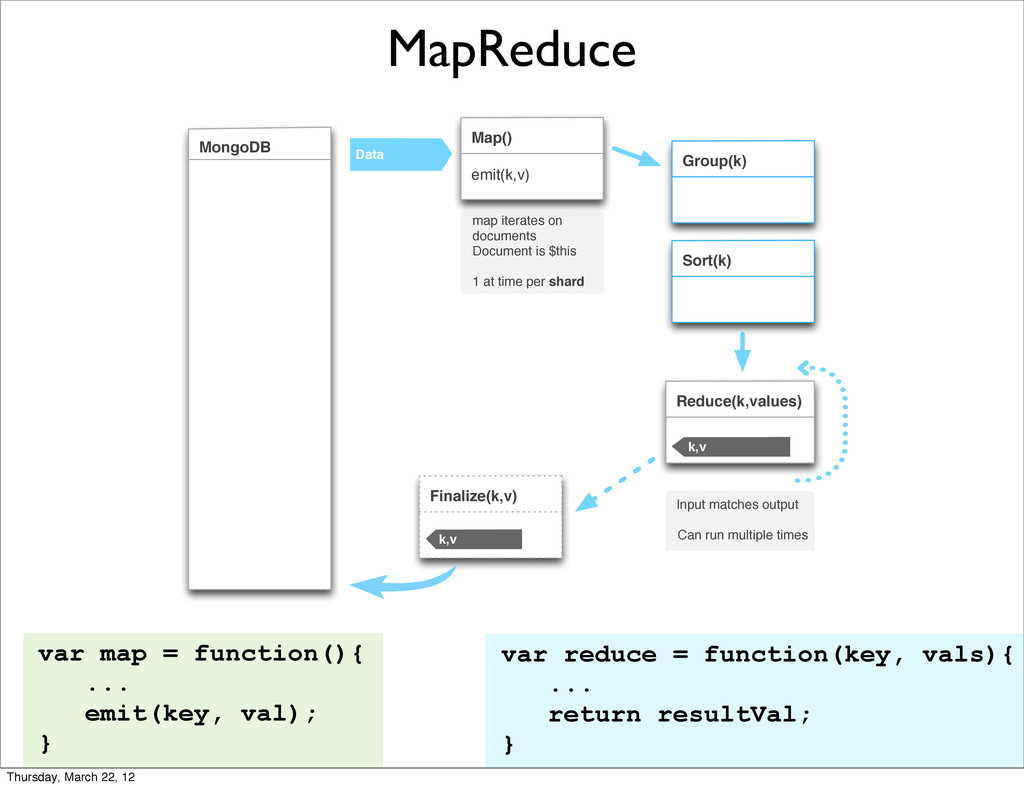{kind=link}
{kind=link}
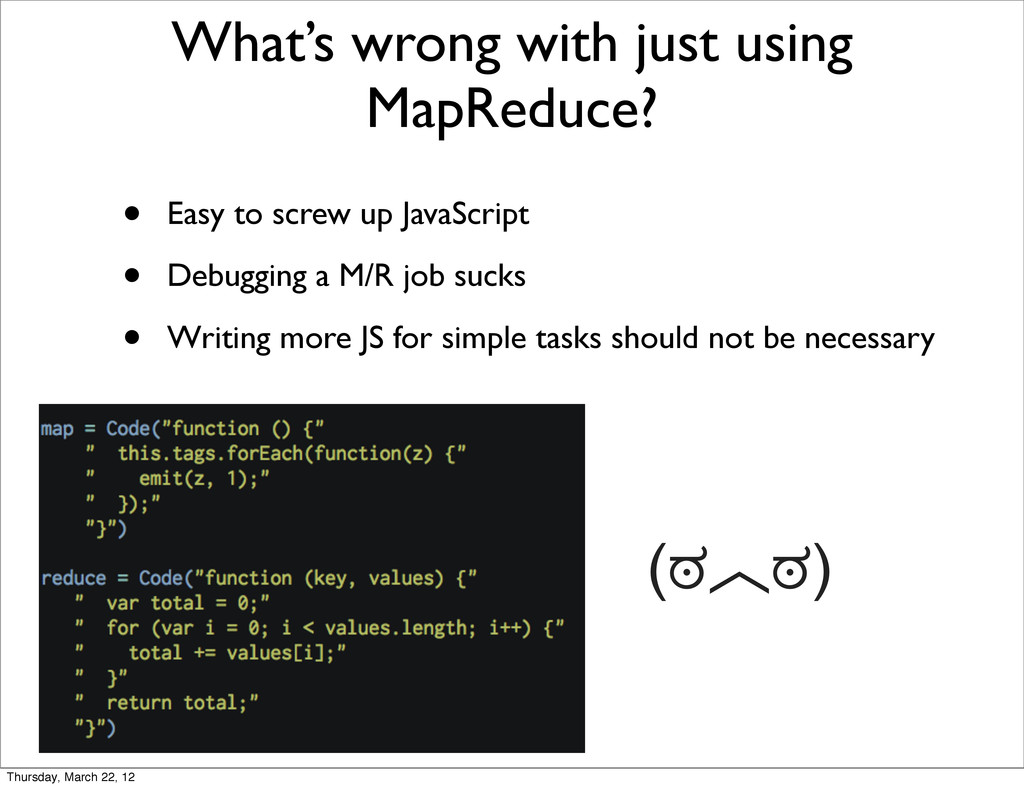{kind=link}
{kind=link}
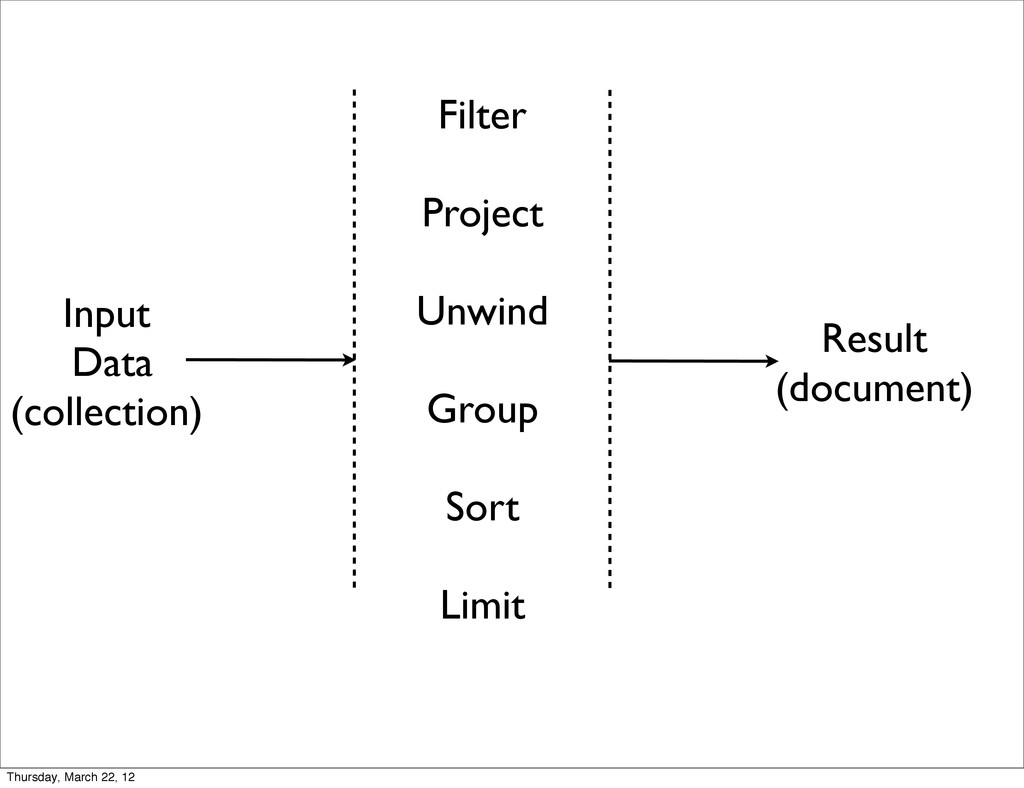{kind=link}
{kind=link}
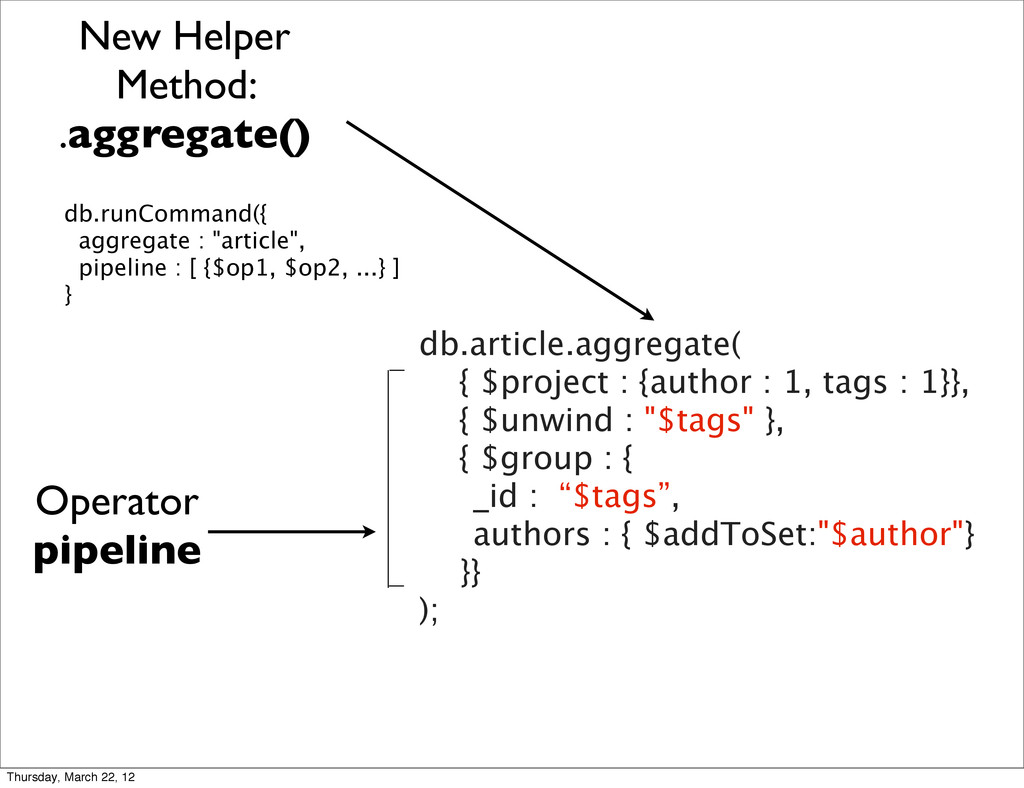{kind=link}
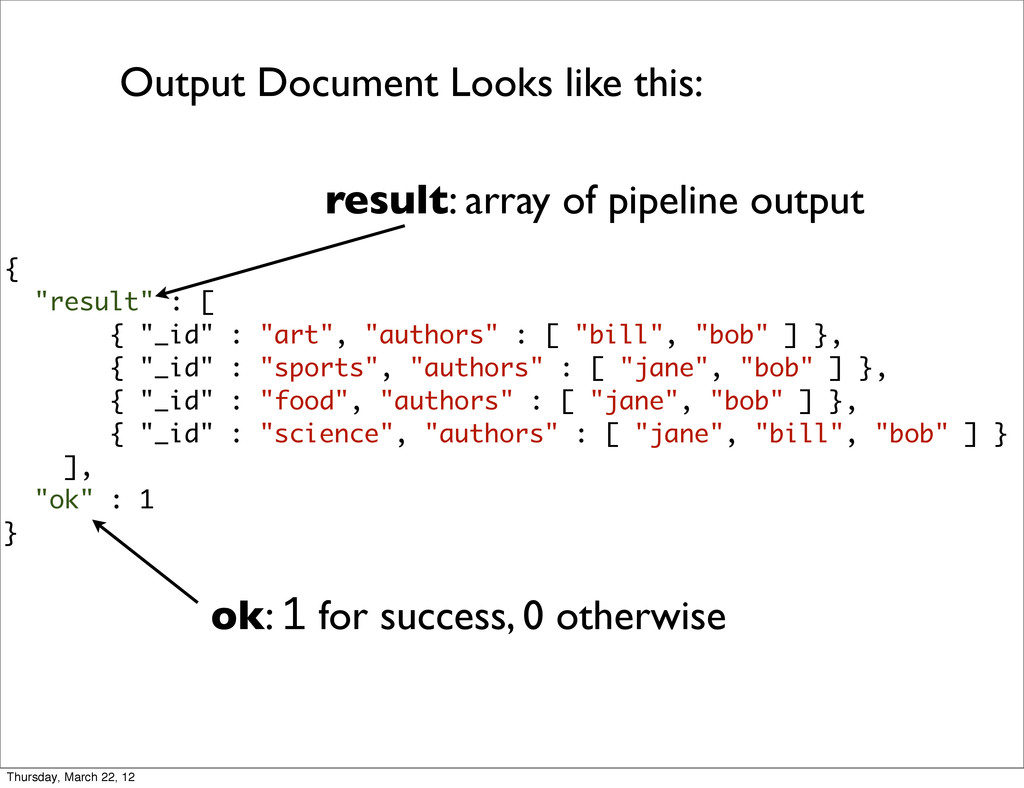{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
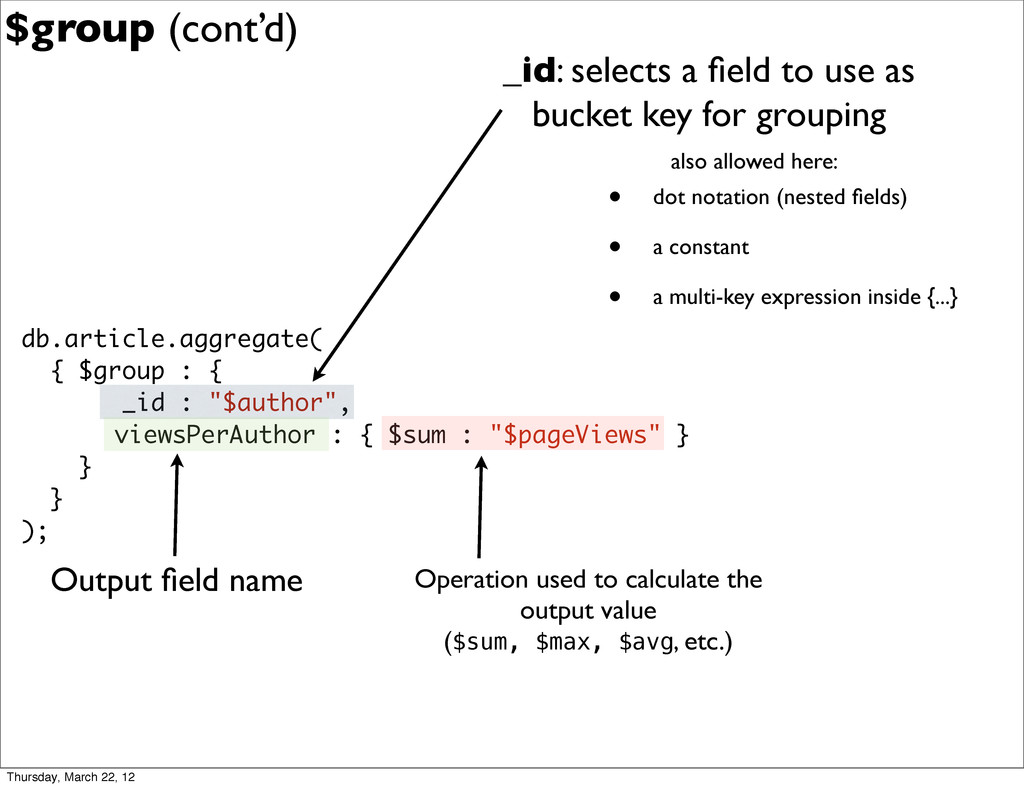{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
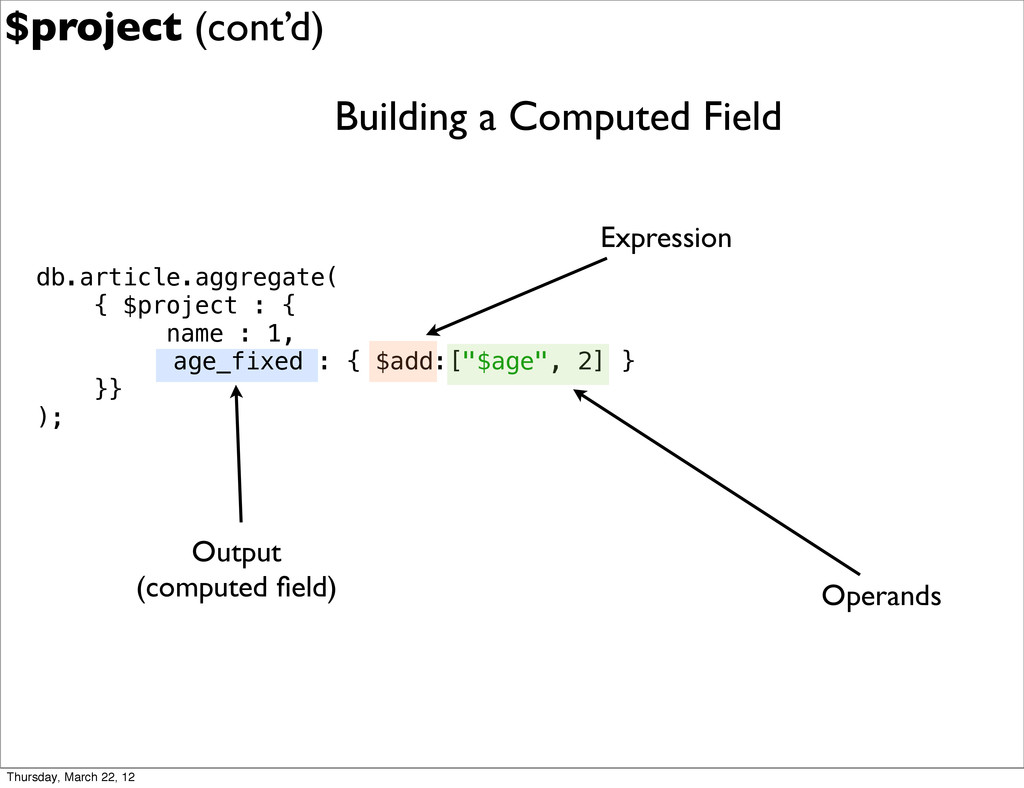{kind=link}
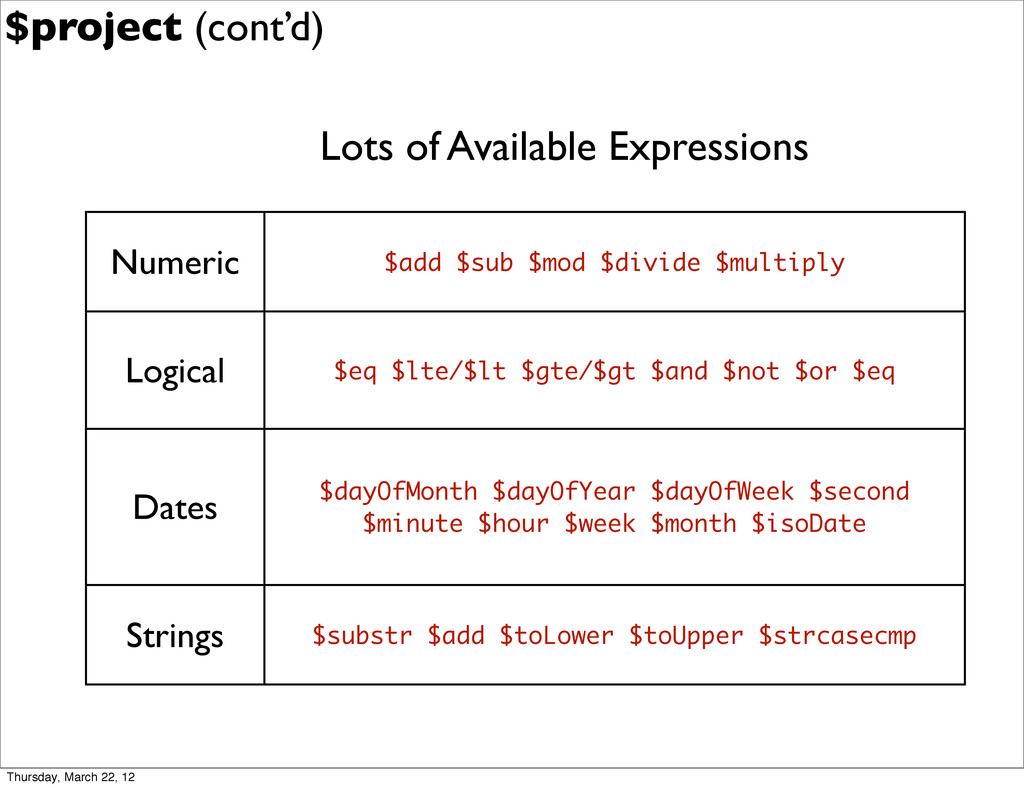{kind=link}
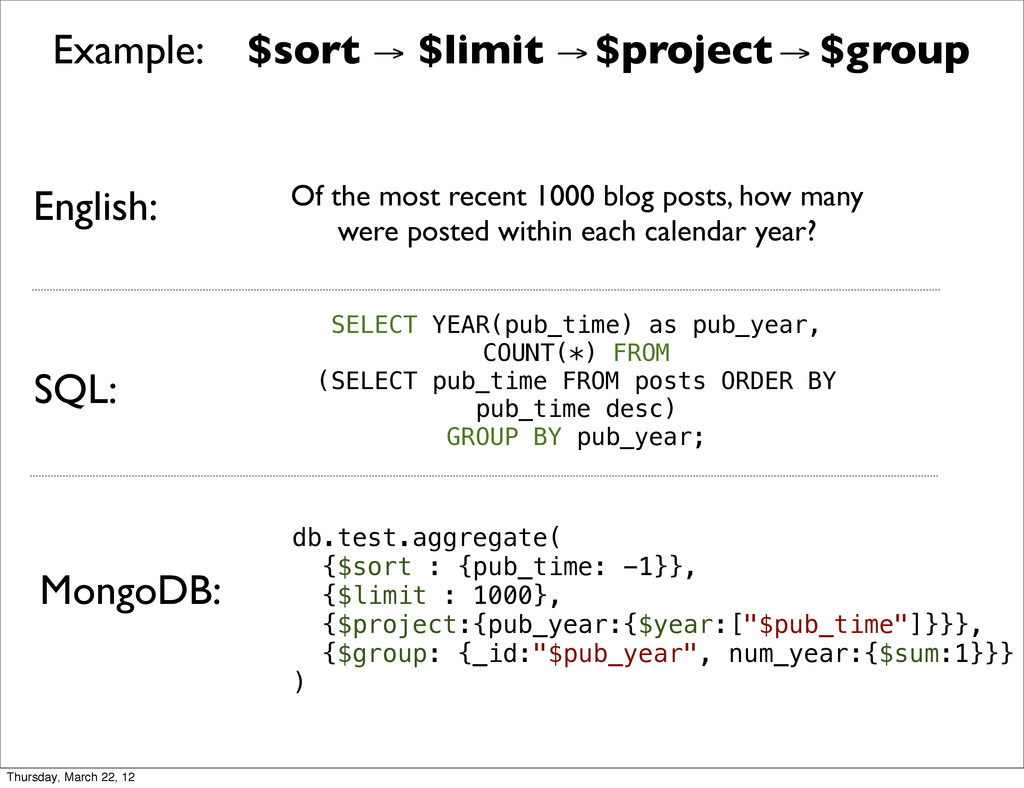{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}