why you want it • The mechanics of how a replica set works • How to set it up • How to handle it with drivers • Some dos + don’ts for deployment Monday, March 12, 12
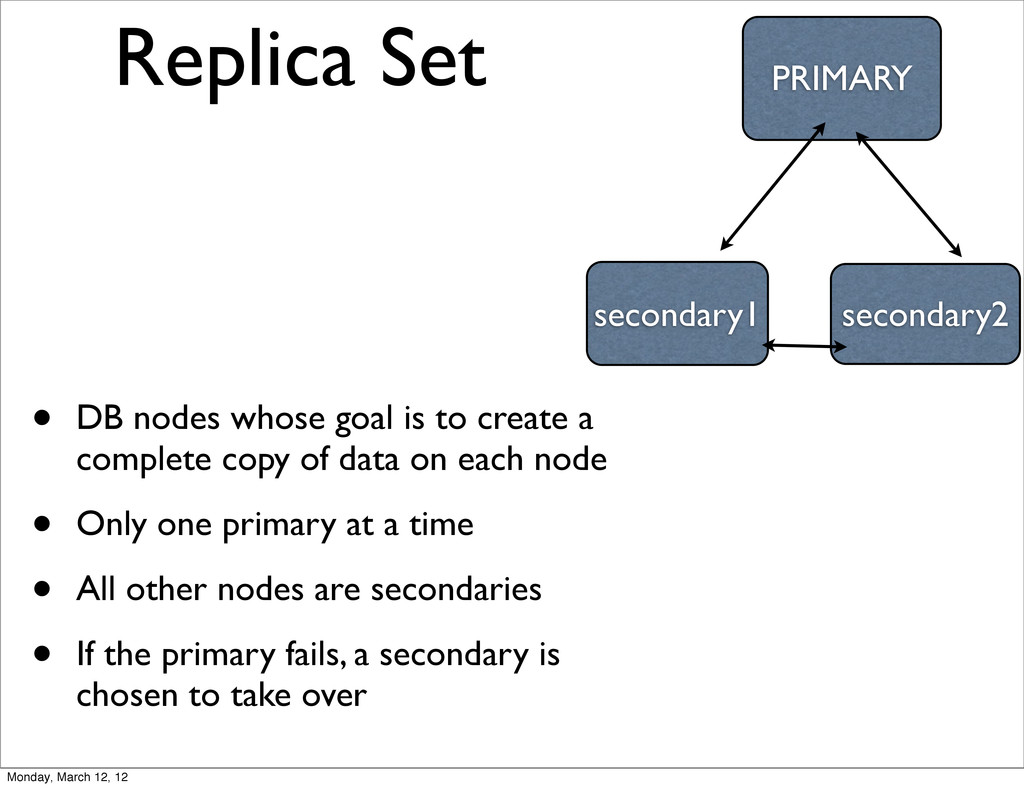
a complete copy of data on each node • Only one primary at a time • All other nodes are secondaries • If the primary fails, a secondary is chosen to take over PRIMARY secondary1 secondary2 Monday, March 12, 12
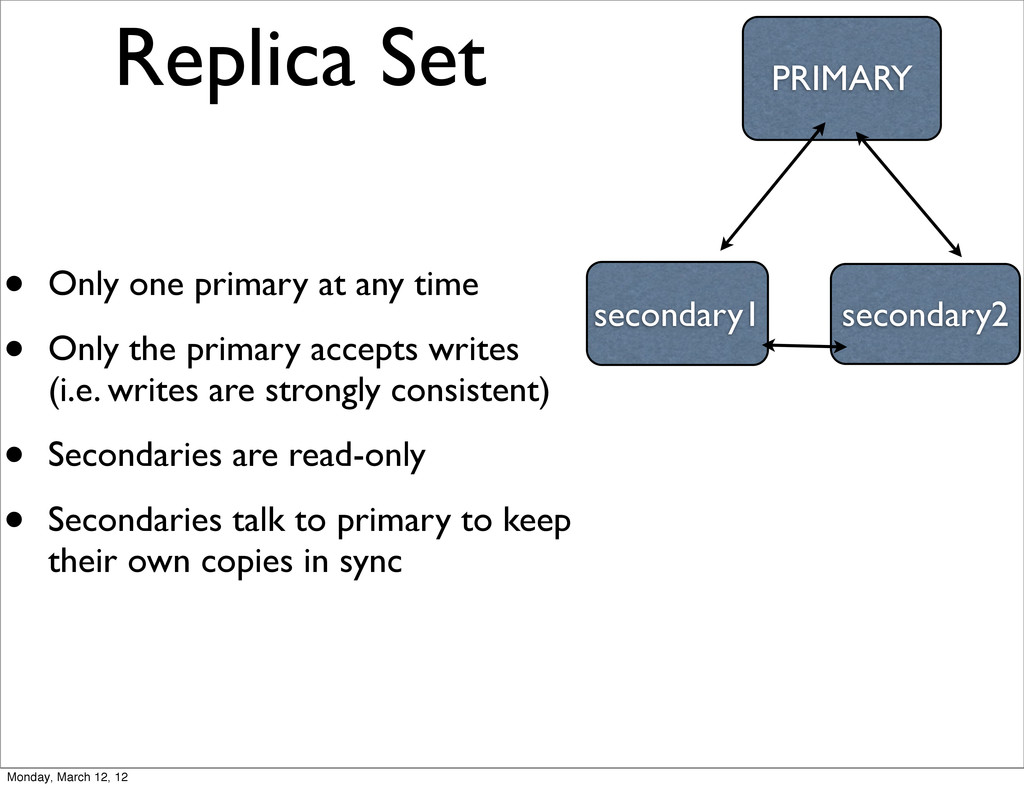
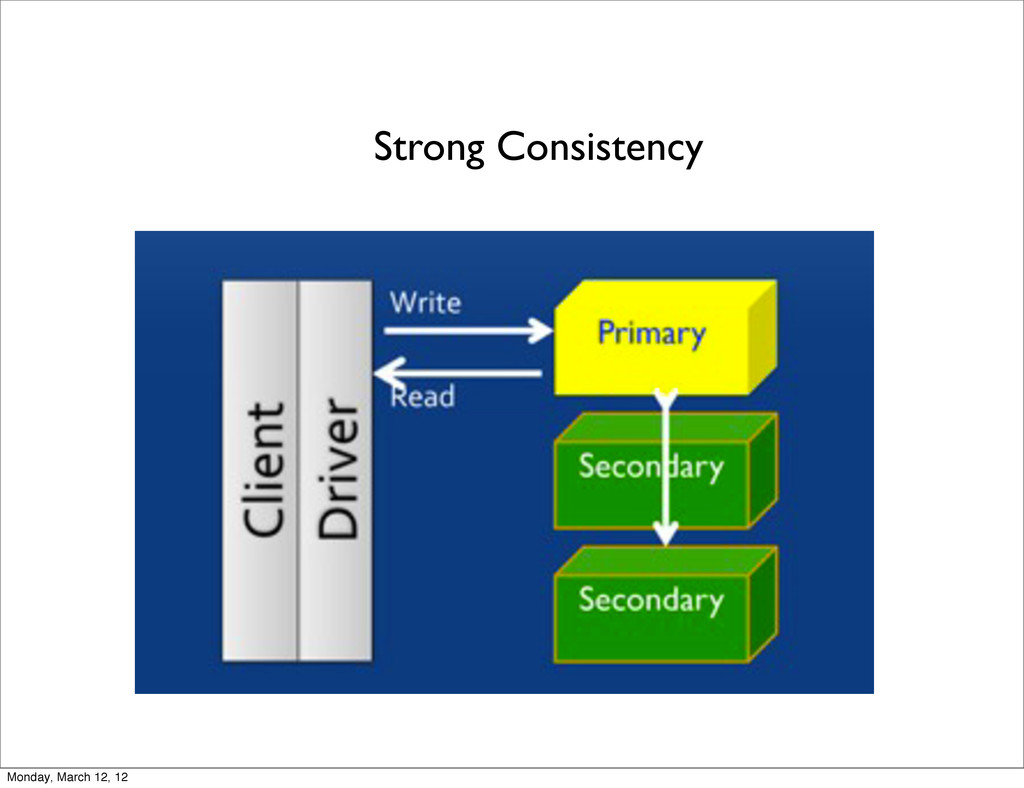
Only the primary accepts writes (i.e. writes are strongly consistent) • Secondaries are read-only • Secondaries talk to primary to keep their own copies in sync PRIMARY secondary1 secondary2 Monday, March 12, 12
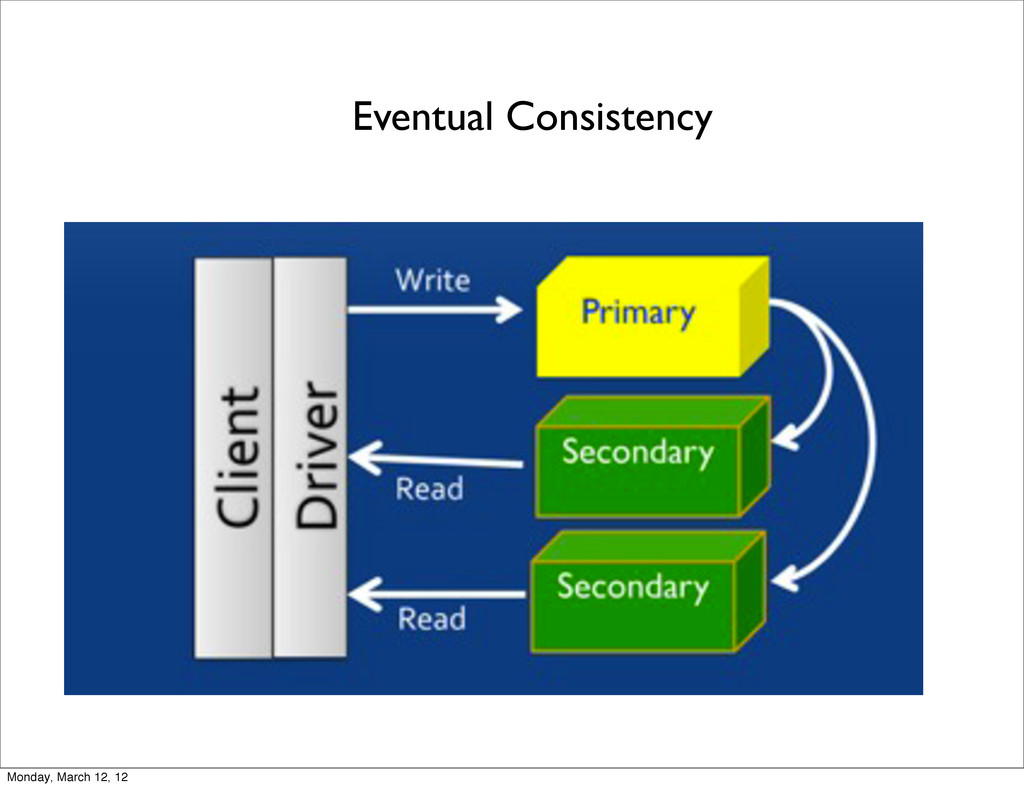
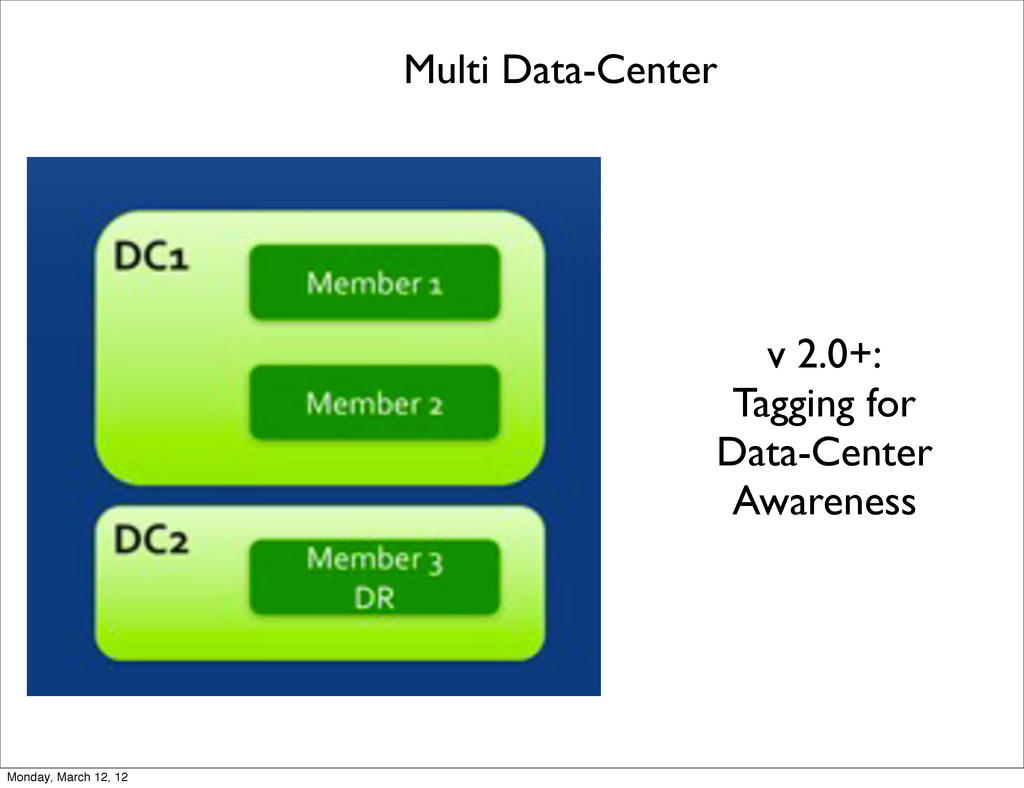
Extra copies of data = redundancy • Scaling Reads: Sending .find() queries to secondaries • Makes backups easier • Use hidden replicas for secondary workload: analytics, integration with other systems, etc. • Data-center awareness: survive an entire data center outage Monday, March 12, 12
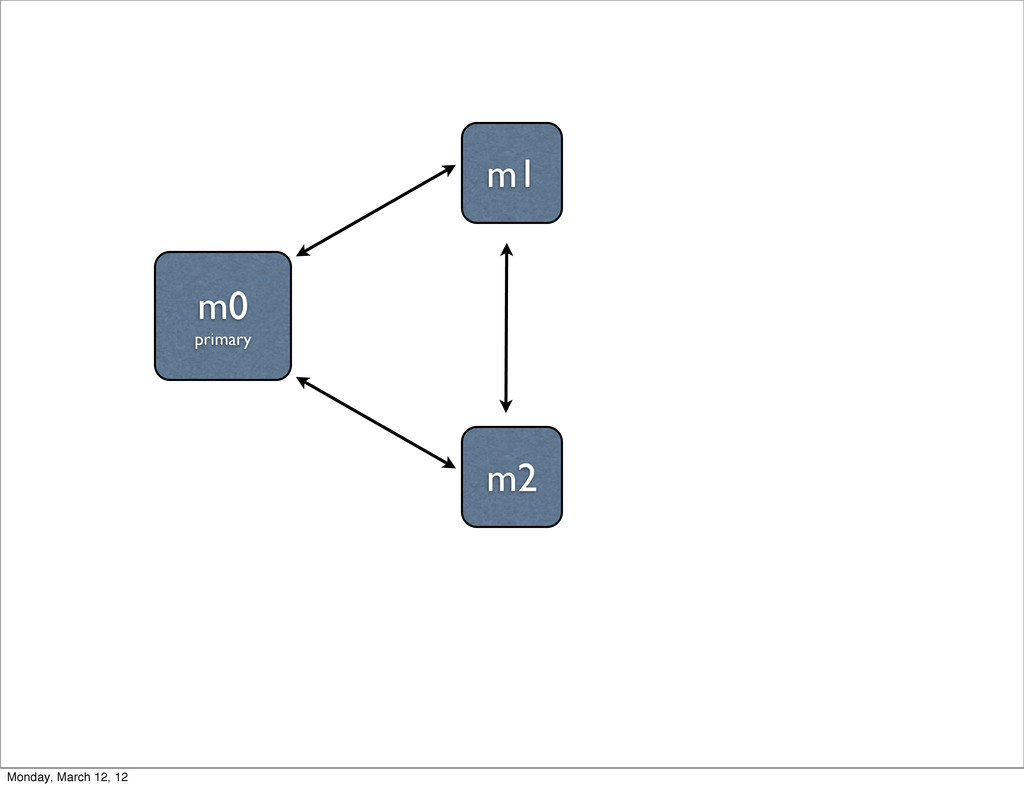
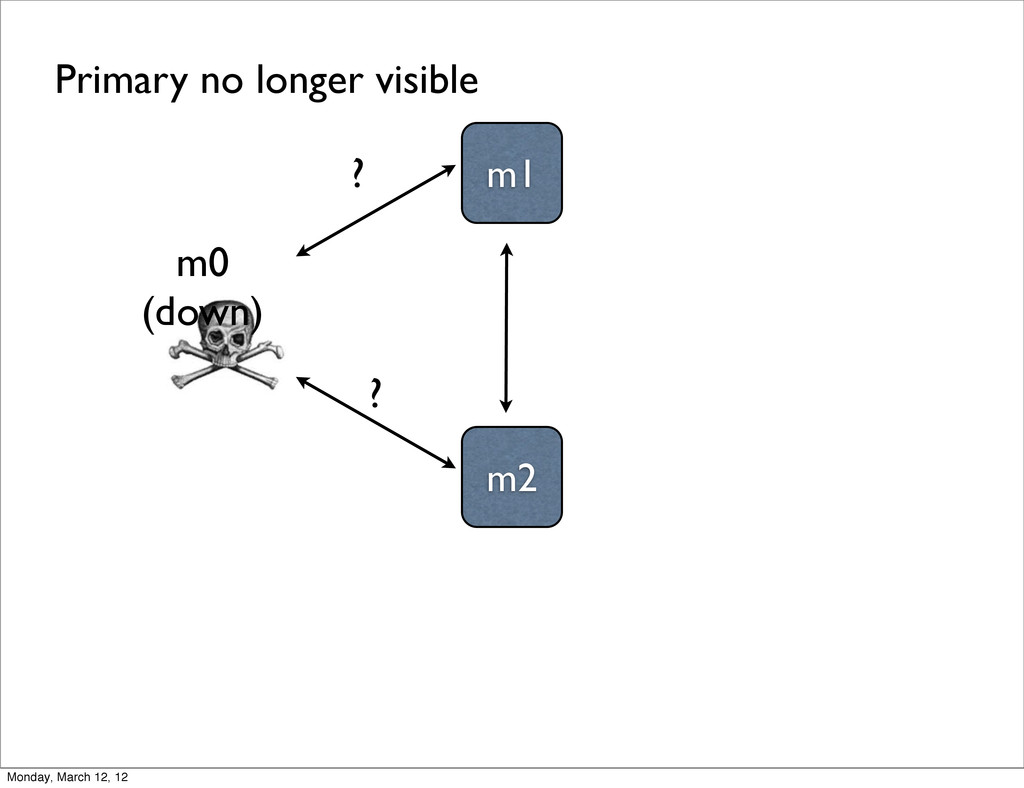
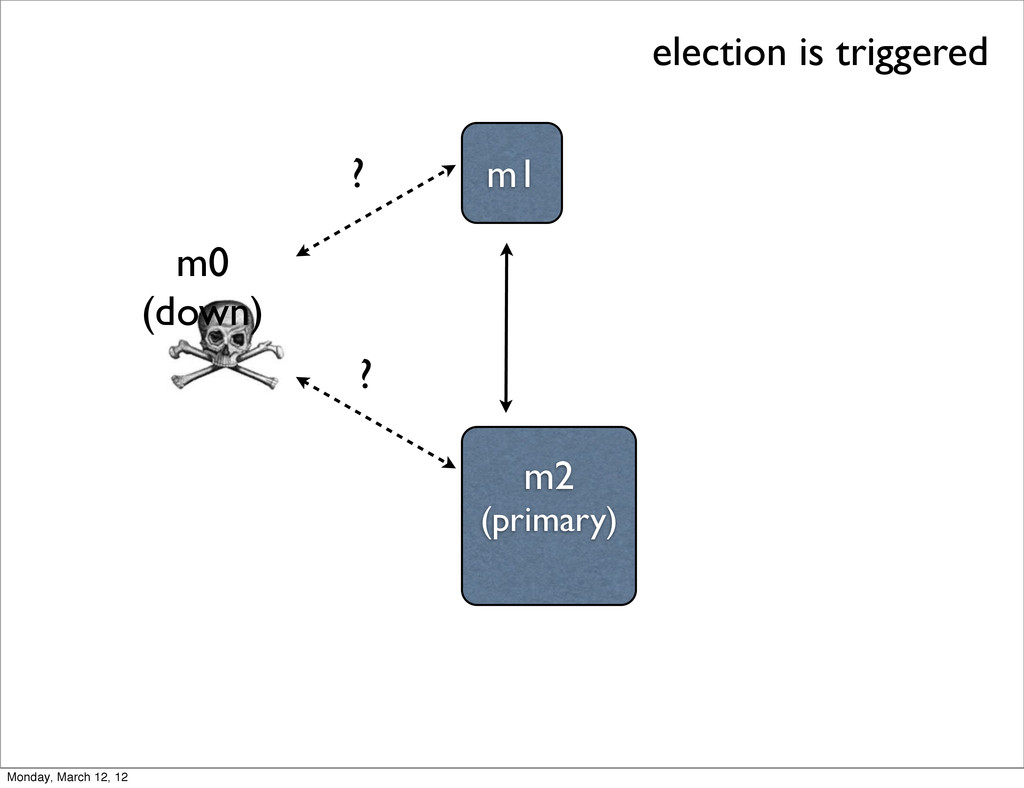
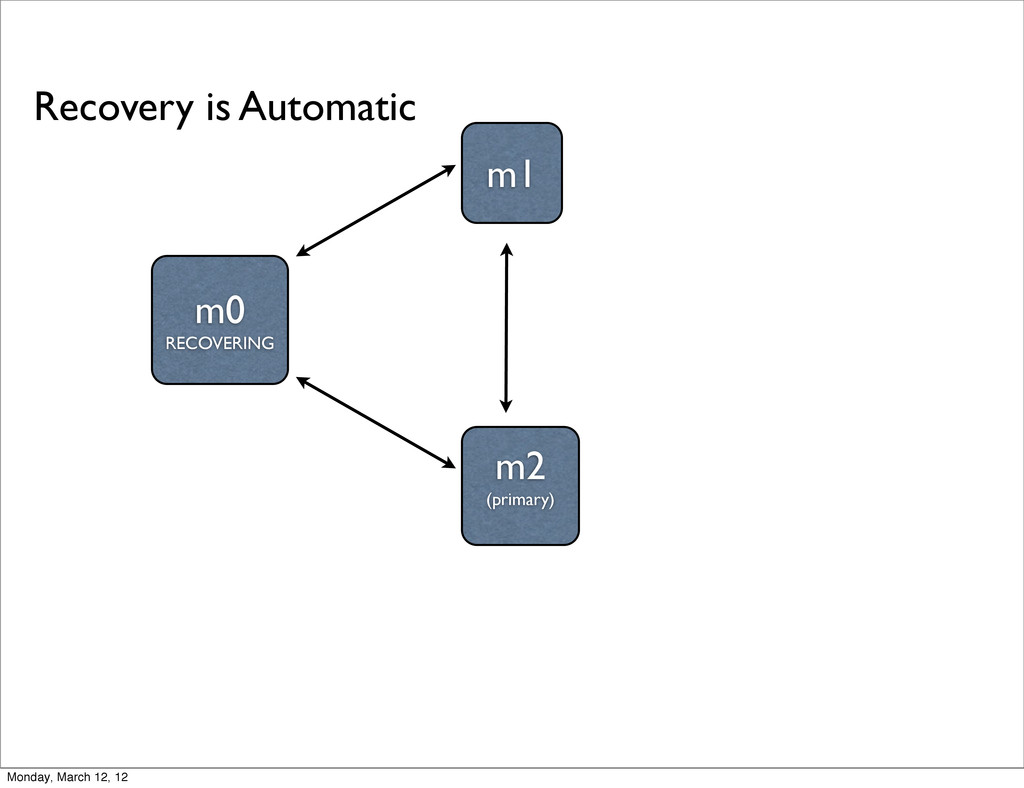
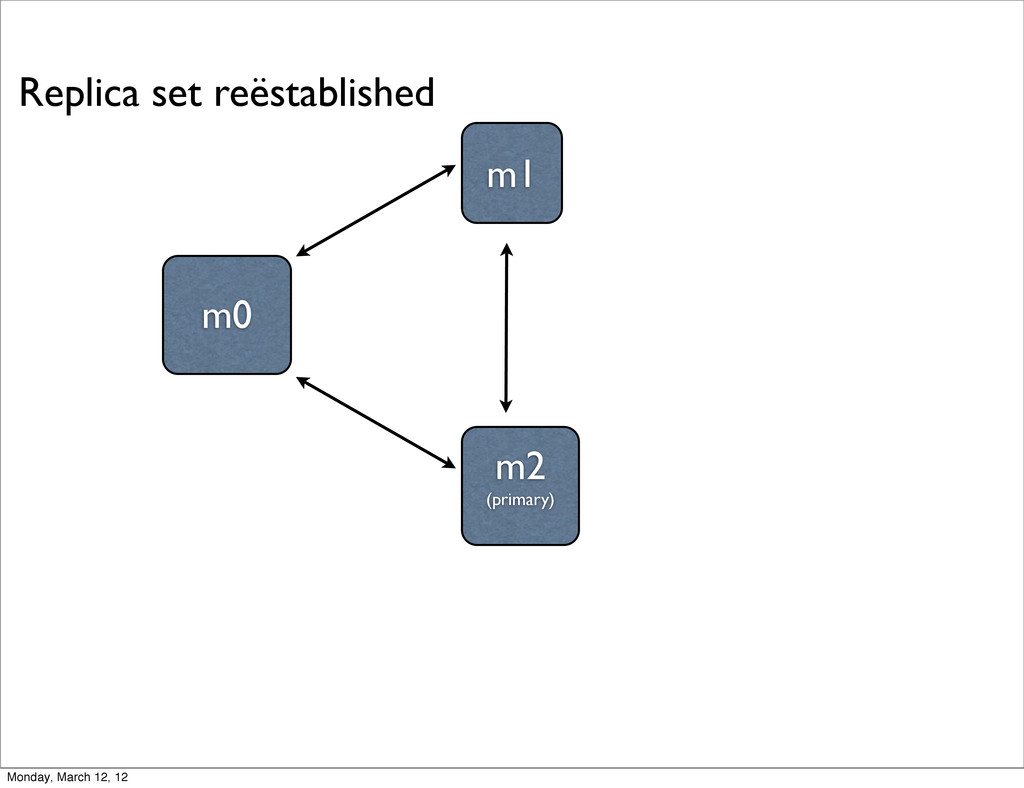
monitor each other with heartbeats - ping every 2 seconds • If the primary can’t be reached, an election is triggered - each node gets a vote and knows the total # available votes • If no node can reach a majority, replica set becomes read-only Monday, March 12, 12
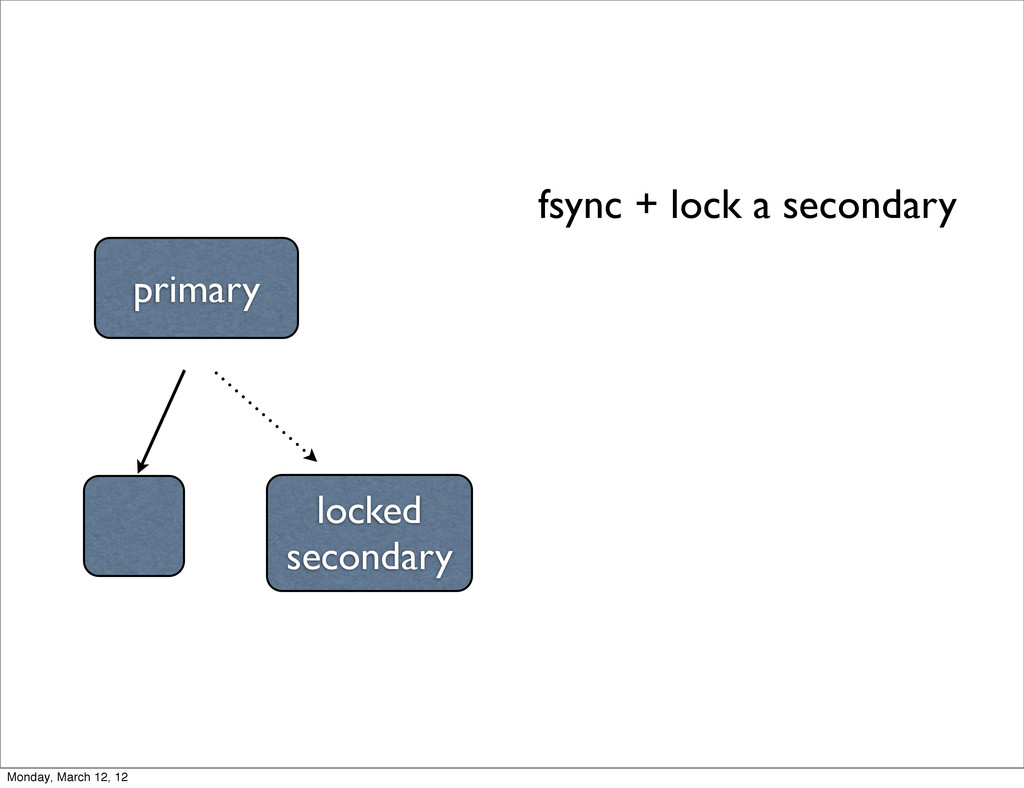
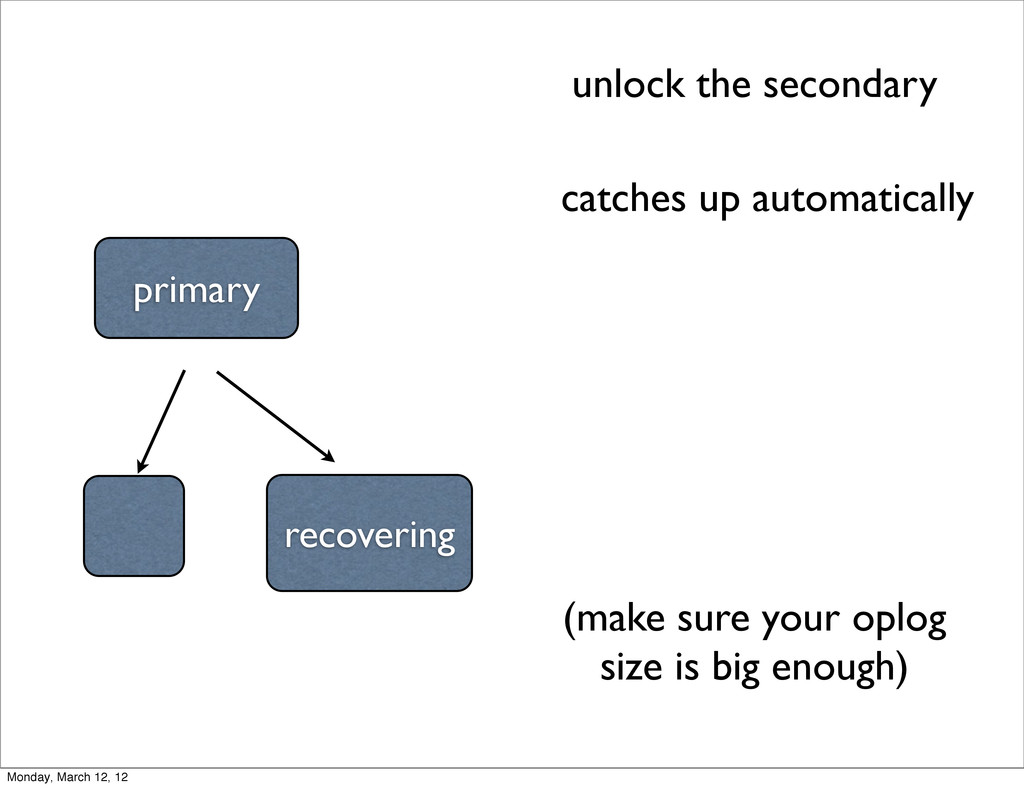
circular queue • defaults to 5% of disk space (on 64 bit) this is usually plenty • eventually it will fill up.... • if a slave falls too far behind, it will need to resync Monday, March 12, 12
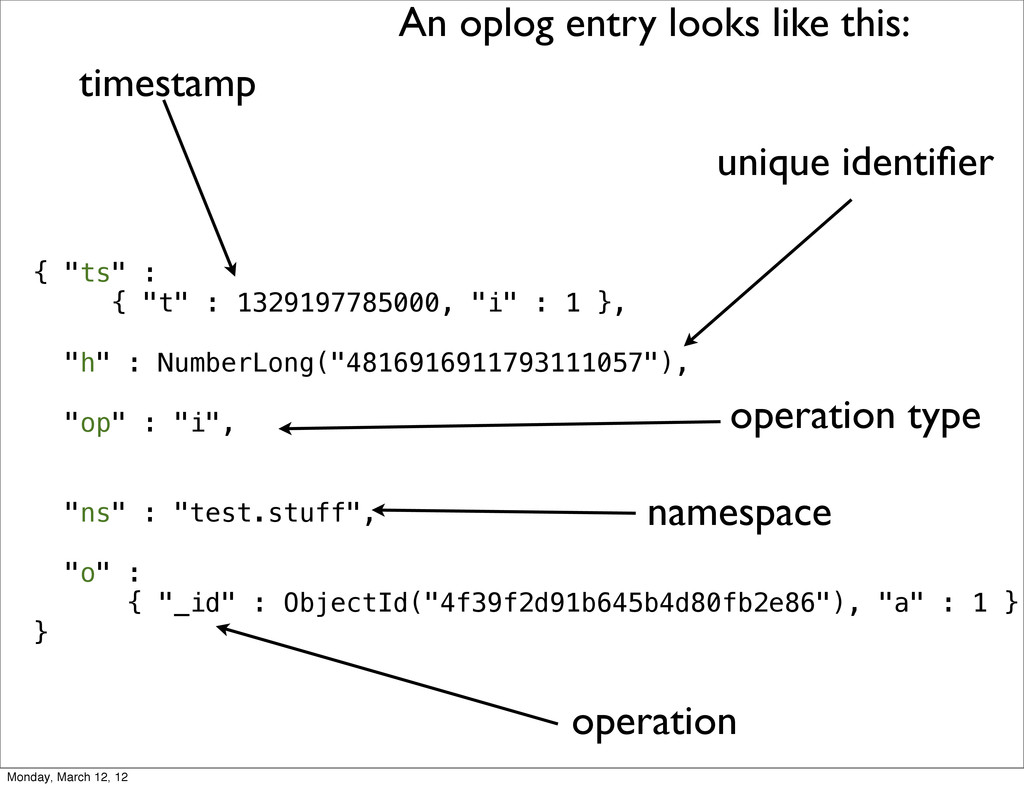
same result update({age:{$lt:5}}, {$inc:{x:1}}) one update cmd multiple oplog entries set x=1 for ObjectId("4f3bf37bdbb51e2beb325867") set x=1 for ObjectId("4f3bf37ddbb51e2beb325868") set x=1 for ObjectId("4f3bf37ddbb51e2beb325869") etc... Monday, March 12, 12
rs.remove(“hostname:port”) - remove a member • rs.status() - get an overview of replica set health • rs.stepDown() - step down as primary • rs.reconfig(config) updates the replicaset config • rs.slaveOk() - on a secondary, enable read queries Monday, March 12, 12
- votes in elections, but stores no data • {priority: p} set a preference for election as primary - priority:0 means node can never become primary useful for backups, reporting, etc. • {slaveDelay : <seconds>} Number of seconds to remain behind primary. Useful for accident recovery, rolling backups, etc. Monday, March 12, 12
can get a guarantee of successful replication from pymongo import ReplicaSetConnection db = ReplicaSetConnection().test db.u.update({“name”:”bob”}, {“$inc”:{“age”:1}}, safe=True, w=2); db.u.update({“name”:”bob”}, {“$inc”:{“age”:1}}, safe=True, w=”majority”); Ensure write on >=2 nodes Ensure write reaches majority of nodes Monday, March 12, 12
secondary nodes • Good for read-heavy situations • Not necessarily helpful for write-heavy situations • This does not increase your working set size (need sharding) Monday, March 12, 12
import ReplicaSetConnection, from pymongo import ReadPreference c = ReplicaSetConnection(read_preference=ReadPreference.SECONDARY) db = c.test db.u.find_one({“name”:”bob”}) These reads are eventually consistent If you need strong consistency, stick with ReadPreference.PRIMARY Monday, March 12, 12
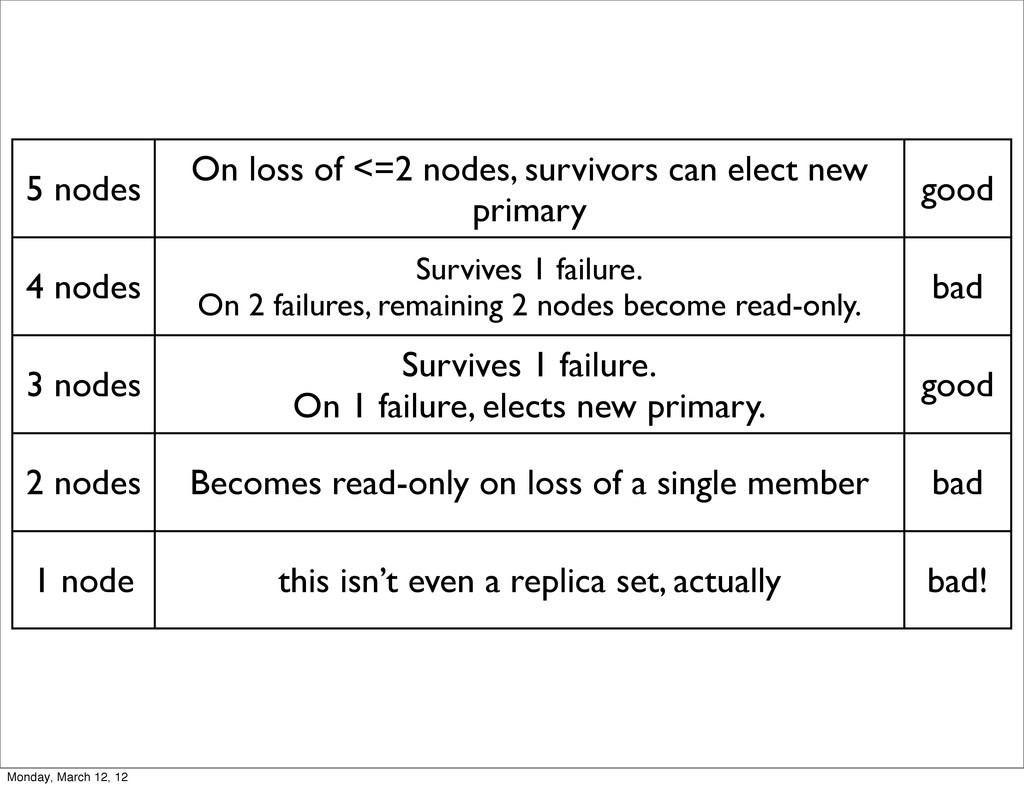
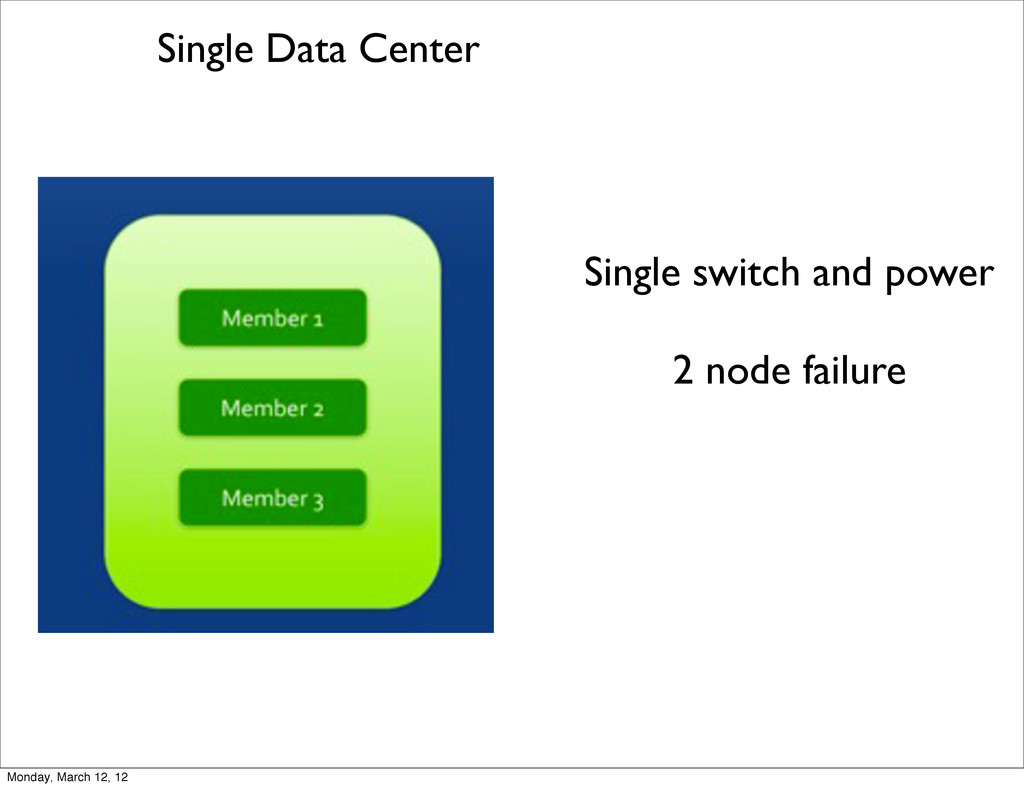
new primary good 4 nodes Survives 1 failure. On 2 failures, remaining 2 nodes become read-only. bad 3 nodes Survives 1 failure. On 1 failure, elects new primary. good 2 nodes Becomes read-only on loss of a single member bad 1 node this isn’t even a replica set, actually bad! Monday, March 12, 12
• Use arbiters for more lightweight setup • If sharding, each shard should be a complete replica set • Up to 12 replica set members, 7 of which are allowed to vote Monday, March 12, 12
secondaries: - shut down the server - restart server as standalone - log in to server and build the index - shut down the server - restart server as a secondary again - step down the primary and repeat (rolling update) Monday, March 12, 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![thanks! questions also, we’re hiring! 10gen.com/jobs [email protected] @mpobrien Monday, March](https://files.speakerdeck.com/presentations/4f5d8df0dfe51b001f00d9b1/slide_33.jpg){kind=link}