2 Scrapy at Glance 3 Writing a Crawler Item Spider Item Pipeline Architecture Middleware Command Line Tools Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 2 / 56
Internet bot which systematically browses the World Wide Web, typically for the purpose of Web indexing. A Web crawler may also be called a Web spider, an ant, an automatic indexer, or a Web scutter. Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 3 / 56
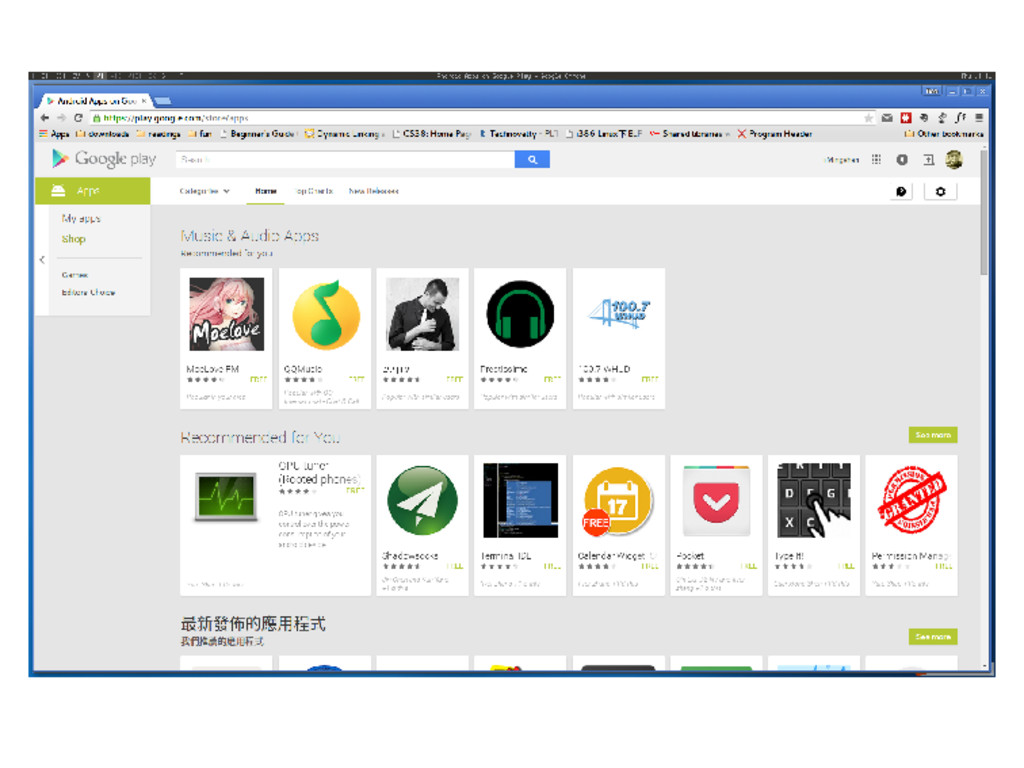
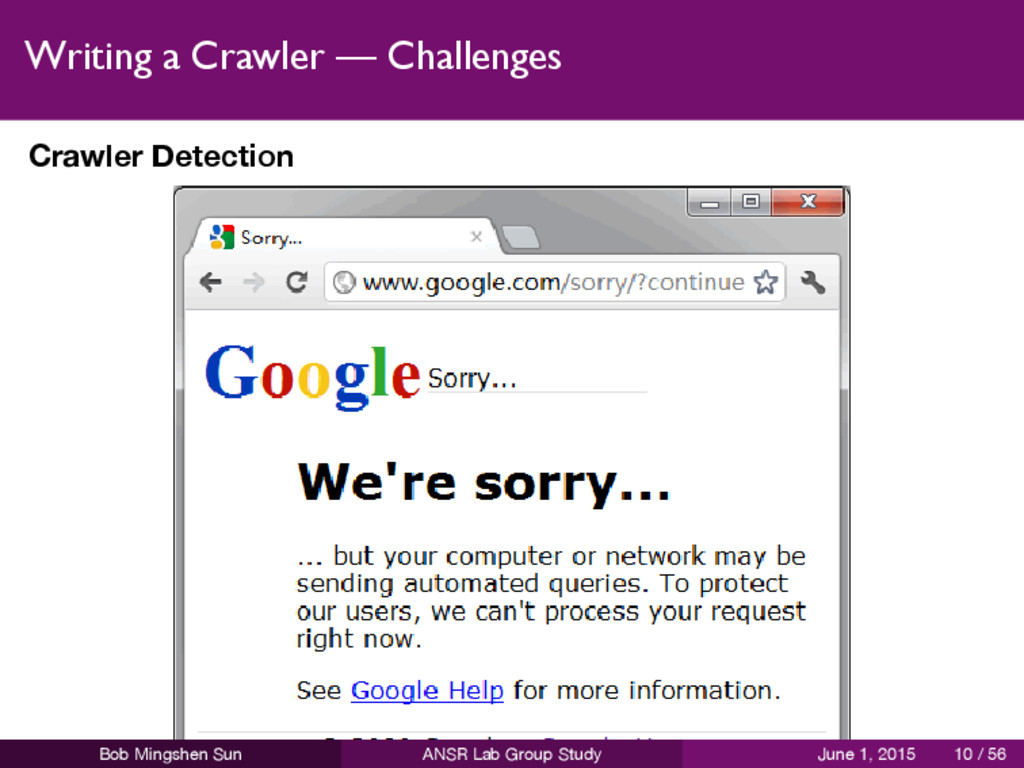
website downloading resources (e.g., Android apps) extracting OSNs information (e.g., Alice follows Bob) harvesting scores or comments for movies or products (e.g., The Godfather scores 9.2 in IMDB) Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 8 / 56
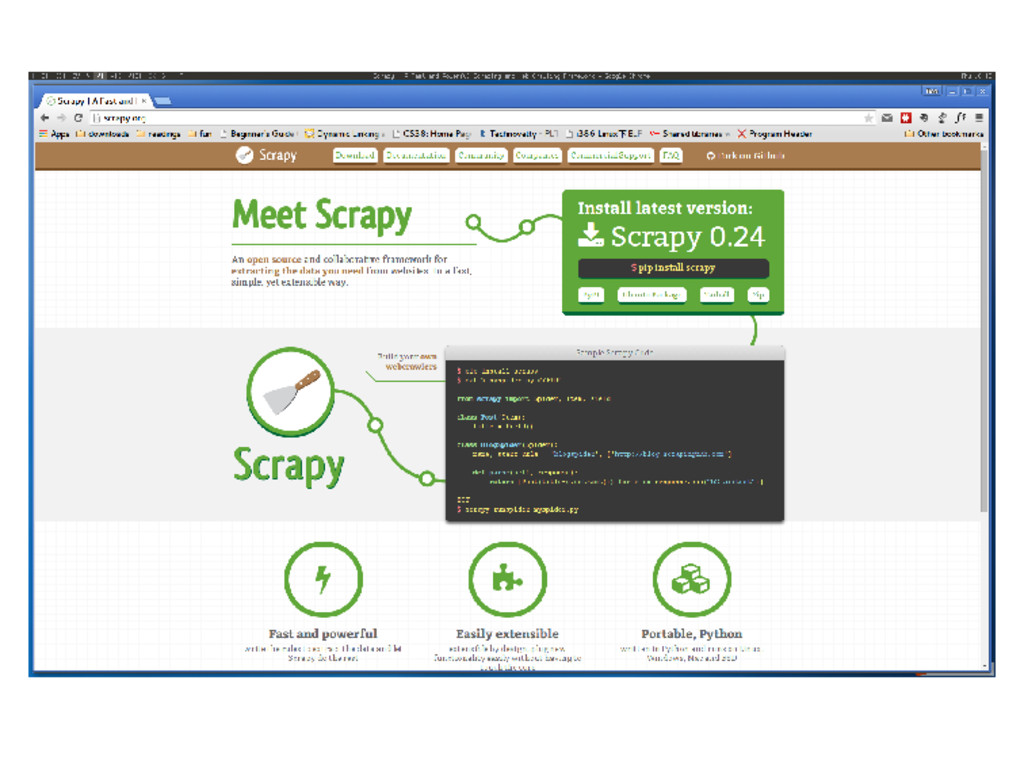
collaborative framework for extracting the data you need from websites. In a fast, simple, yet extensible way. Fast and powerful: write the rules to extract the data and let Scrapy do the rest Easily extensible: extensible by design, plug new functionality easily without having to touch the core Portable, Python: written in Python and runs on Linux, Windows, Mac and BSD Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 15 / 56
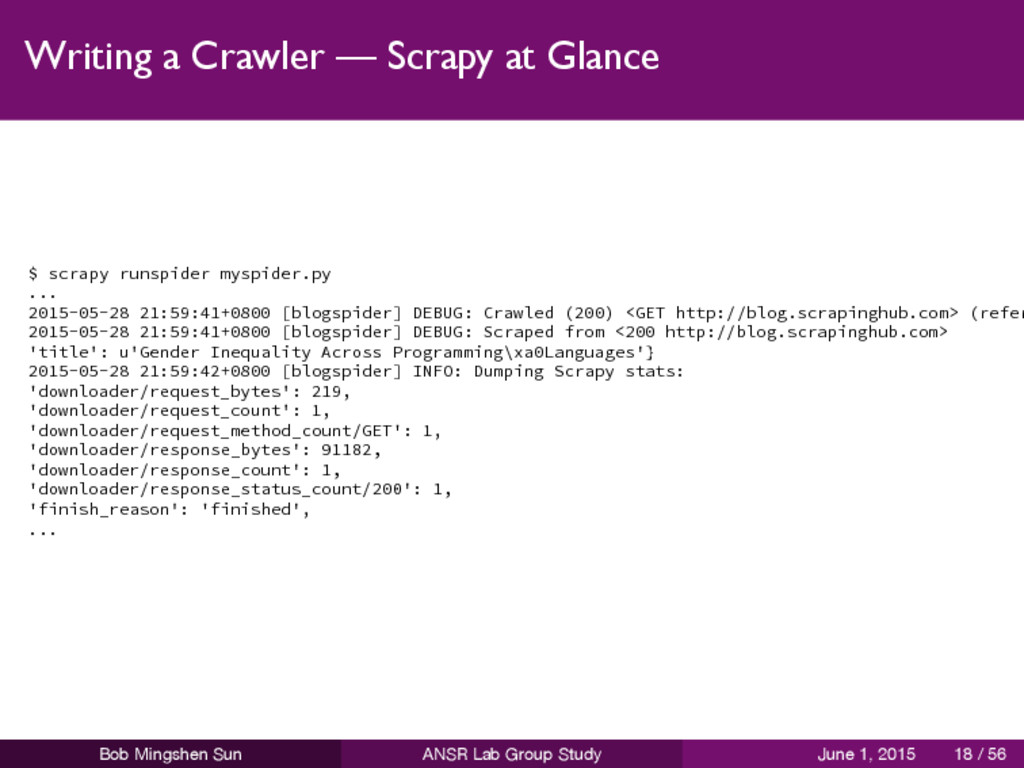
introduction to Python programming language. from scrapy import Spider, Item, Field class Post(Item): title = Field() class BlogSpider(Spider): name, start_urls = 'blogspider', ['http://blog.scrapinghub.com'] def parse(self, response): res = [] for e in response.css("h2 a::text"): res.append(Post(title=e.extract())) return res Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 17 / 56
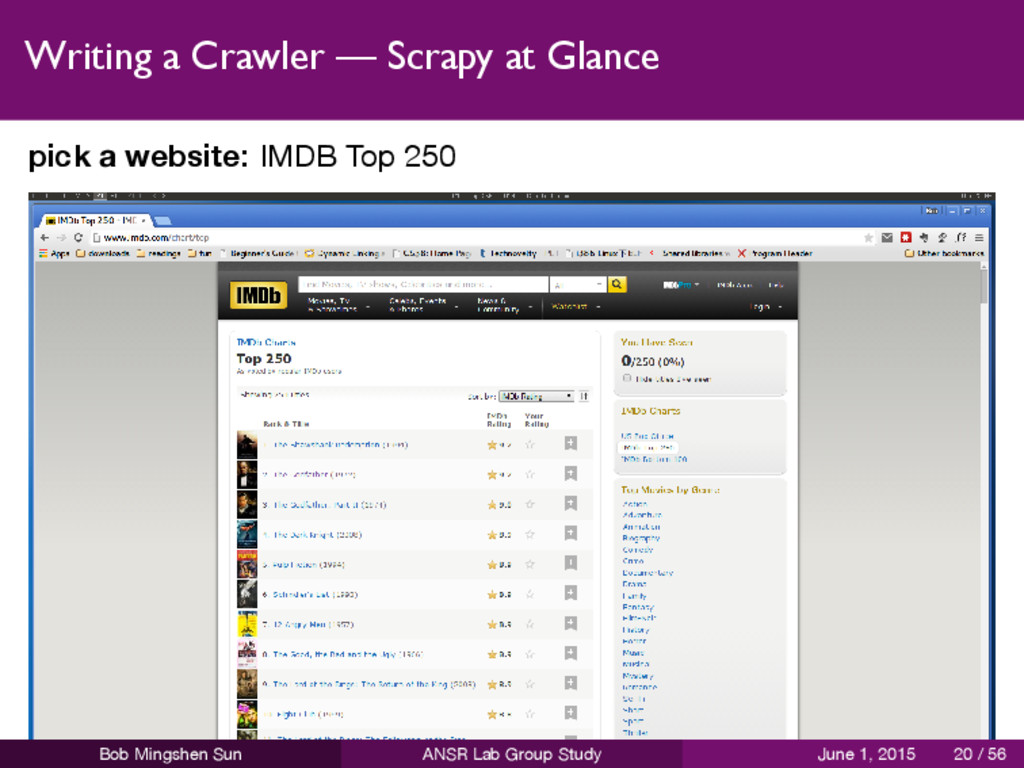
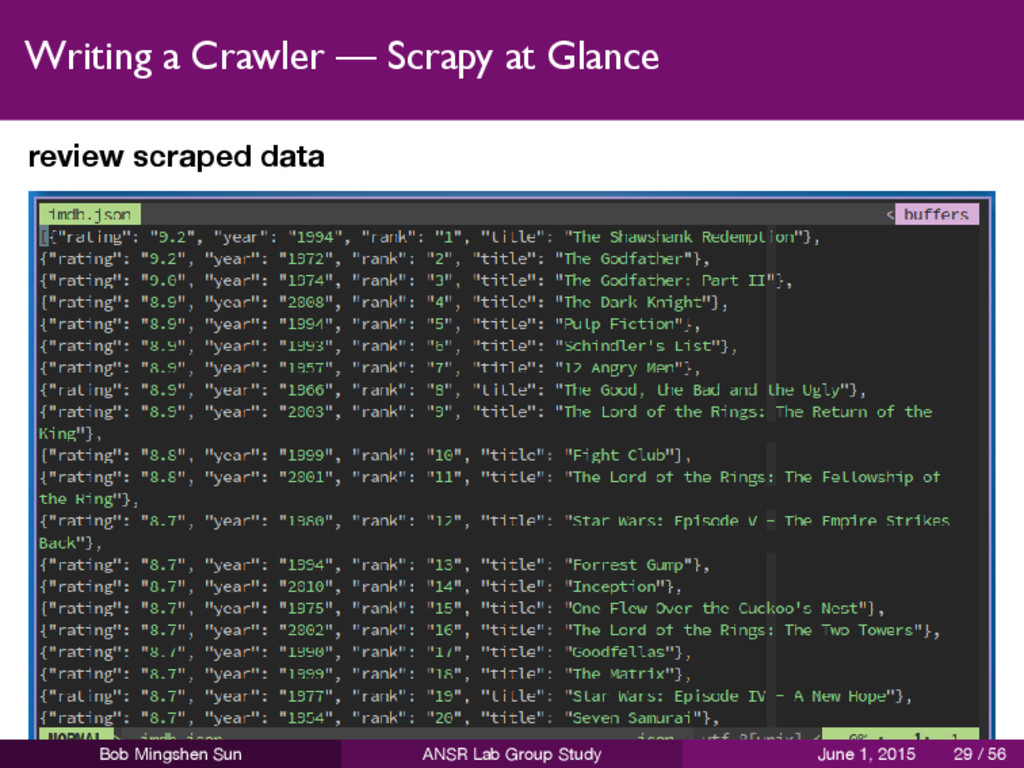
website 2 define the data you want to scrape 3 write a spider to extract the data 4 run the spider to extract the data 5 review scraped data Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 19 / 56
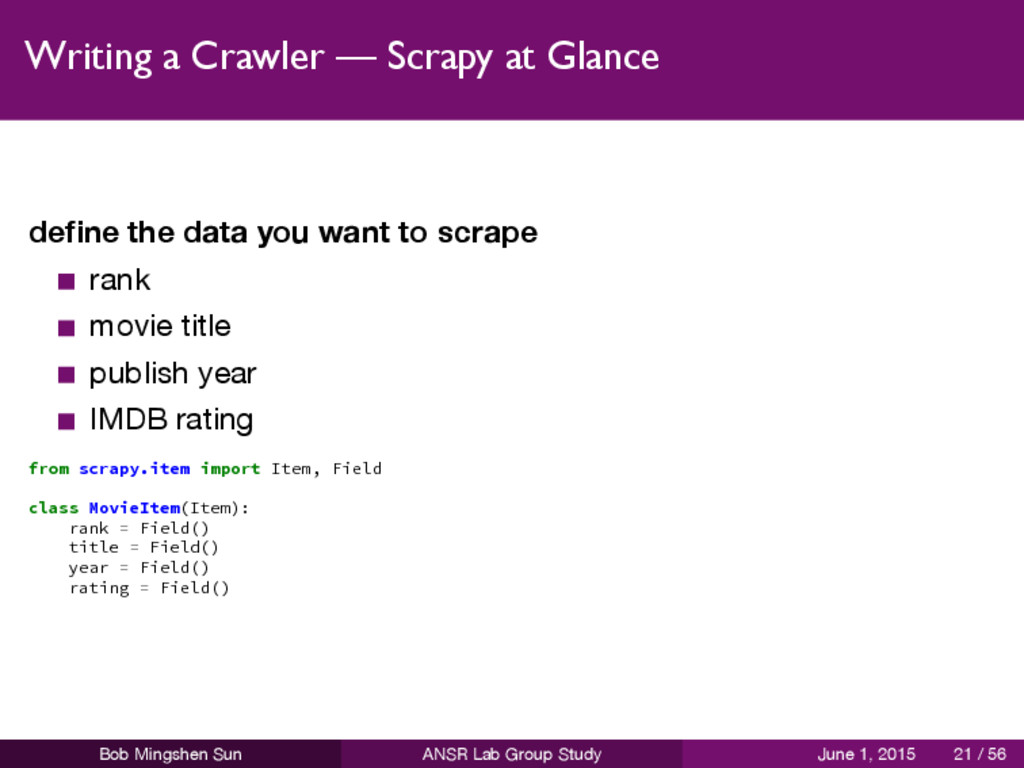
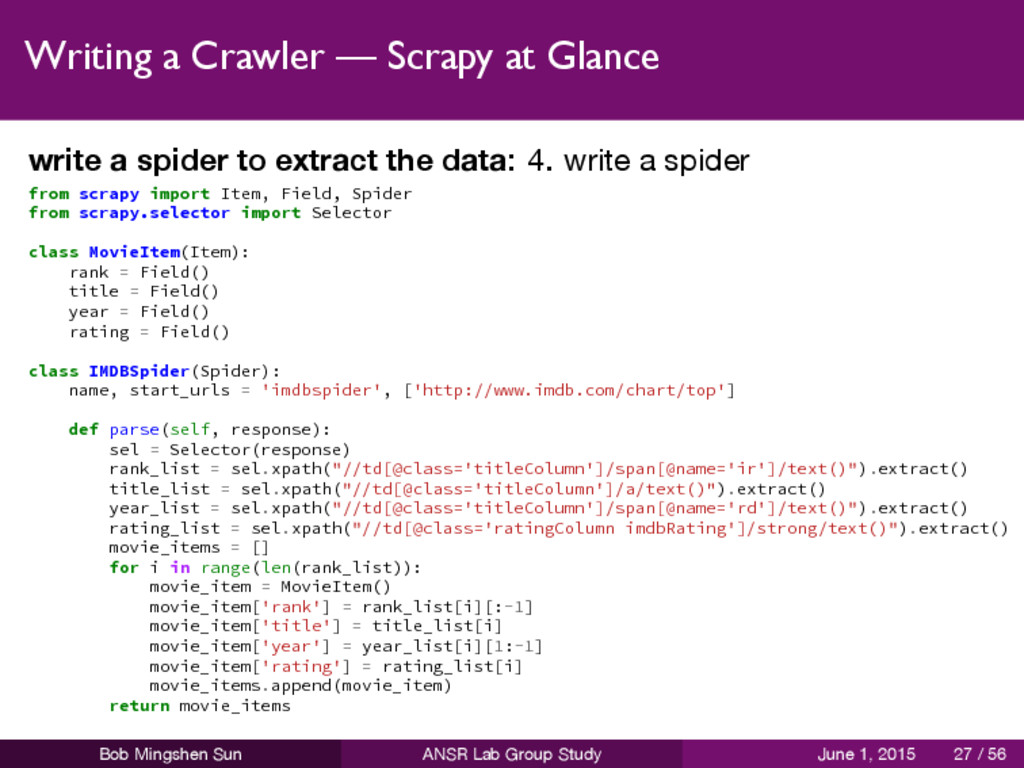
you want to scrape rank movie title publish year IMDB rating from scrapy.item import Item, Field class MovieItem(Item): rank = Field() title = Field() year = Field() rating = Field() Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 21 / 56
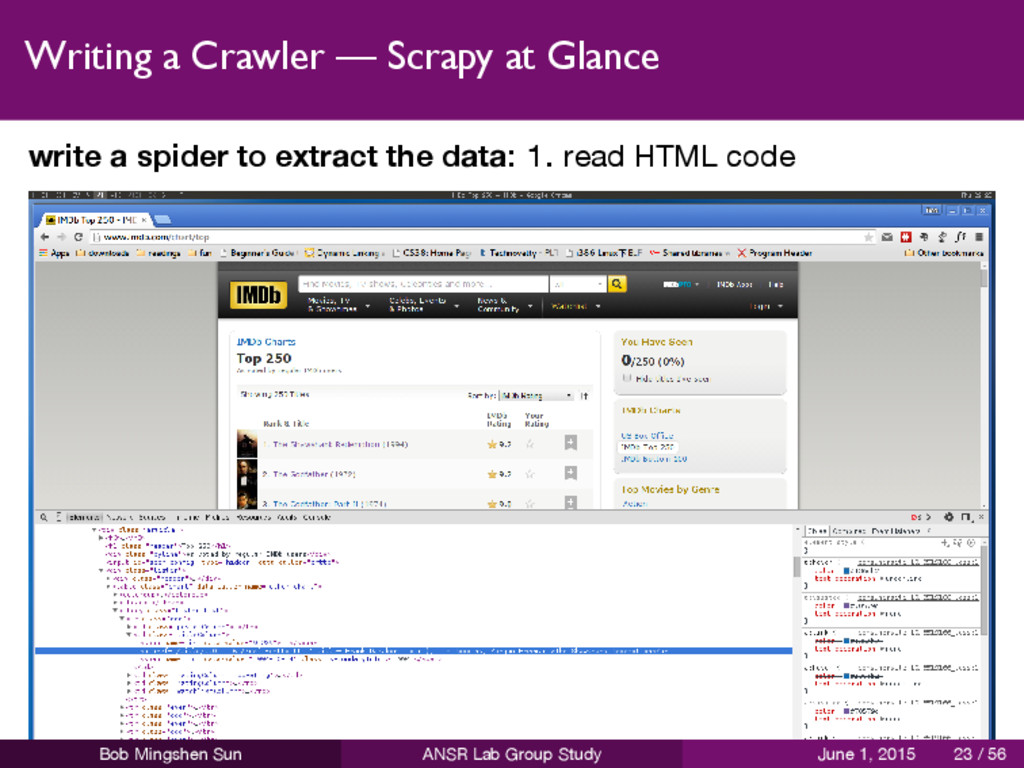
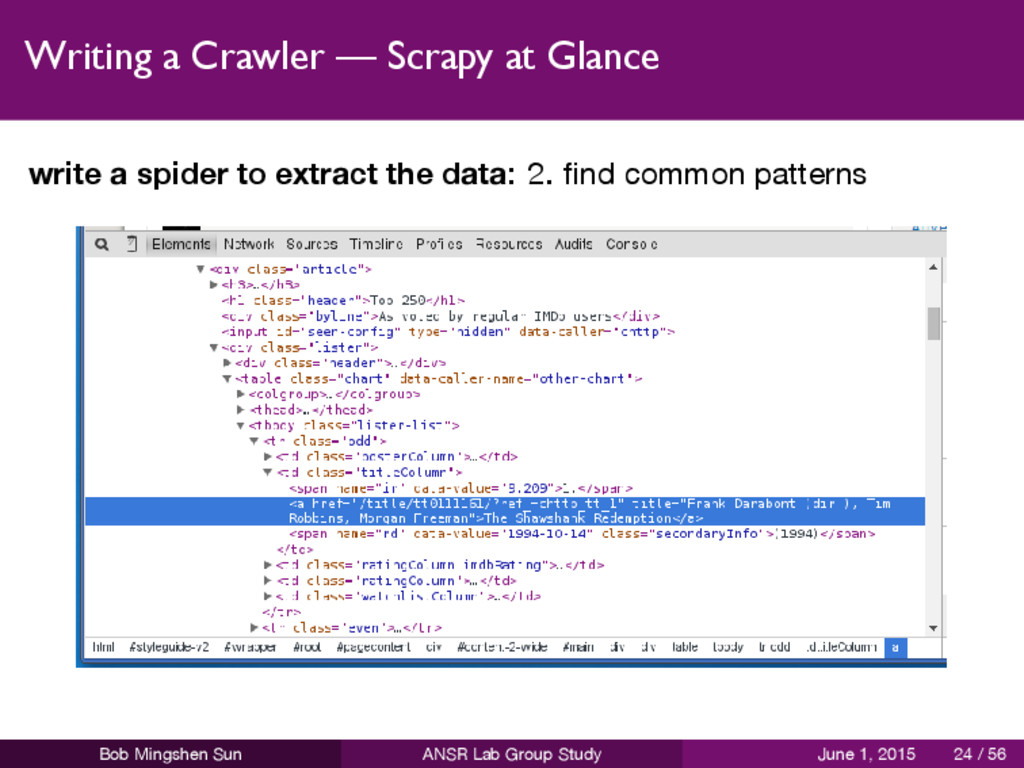
to extract the data 1 read HTML code 2 find common patterns 3 determine XPATH 4 write a spider Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 22 / 56
to extract the data: 3. determine XPATH HTML Preliminaries <div id="logo"></div> <div class="rating"></div> Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 25 / 56
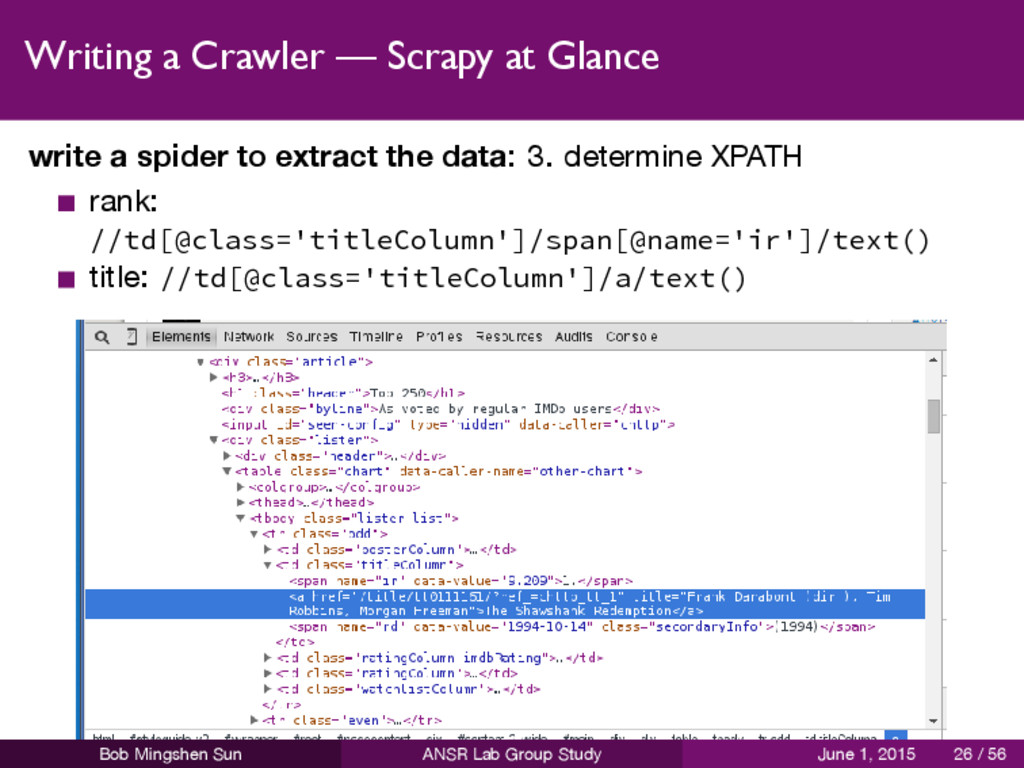
to extract the data: 3. determine XPATH rank: //td[@class='titleColumn']/span[@name='ir']/text() title: //td[@class='titleColumn']/a/text() Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 26 / 56
support for selecting and extracting data from HTML and XML sources JSON, CSV, XML, Storage middleware: user-agent spoofing Interactive shell console Support for creating spiders based on pre-defined templates Service Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 30 / 56
scrapy startproject tutorial scrapy.cfg: configuration file tutorial/: python module, you’ll later import your code from here. tutorial/items.py: items file. tutorial/pipelines.py: pipelines file. tutorial/settings.py: settings file. tutorial/spiders/: a directory where you’ll later put your spiders. tutorial/ scrapy.cfg tutorial/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py ... Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 36 / 56
like simple python dicts but provide additional protection against populating undeclared fields, to prevent typos. from scrapy.item import Item, Field class MovieItem(Item): id = Field() title = Field() year = Field() rating = Field() # ... class ReviewItem(Item): id = Field() star_rating = Field() time = Field() country = Field() review = Field() Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 37 / 56
to scrape information from a domain (or group of domains). Defines an initial list of URLs to download how to follow links how to parse the contents of those pages to extract items Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 38 / 56
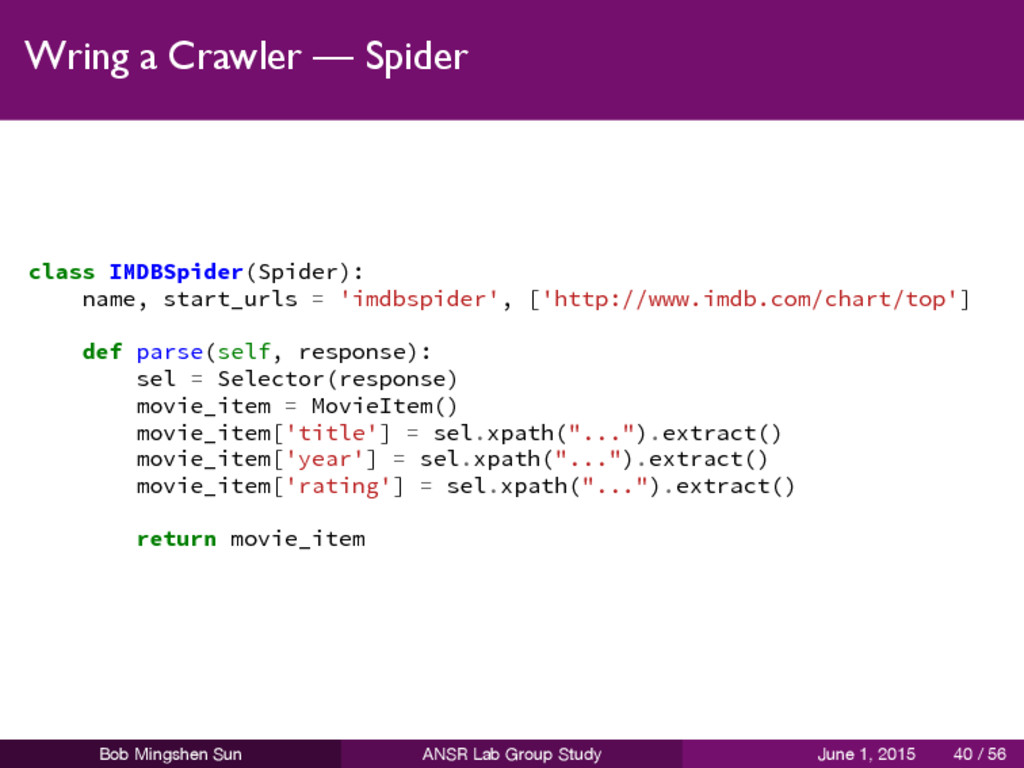
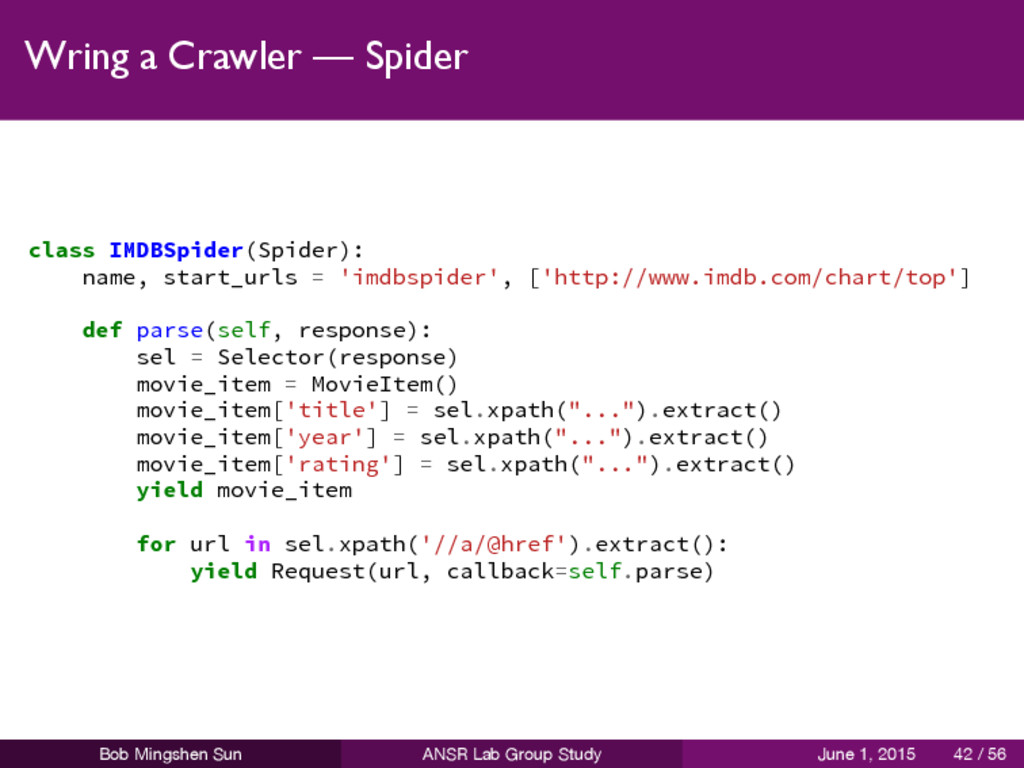
must subclass scrapy.spider.Spider, and define the three main, mandatory, attributes: name start_urls parse() is a method of the spider will be called with the downloaded Response object of each start URL the response is passed to the method as the first and only argument for parsing the response data and extracting scraped data and more URLs to follow Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 39 / 56
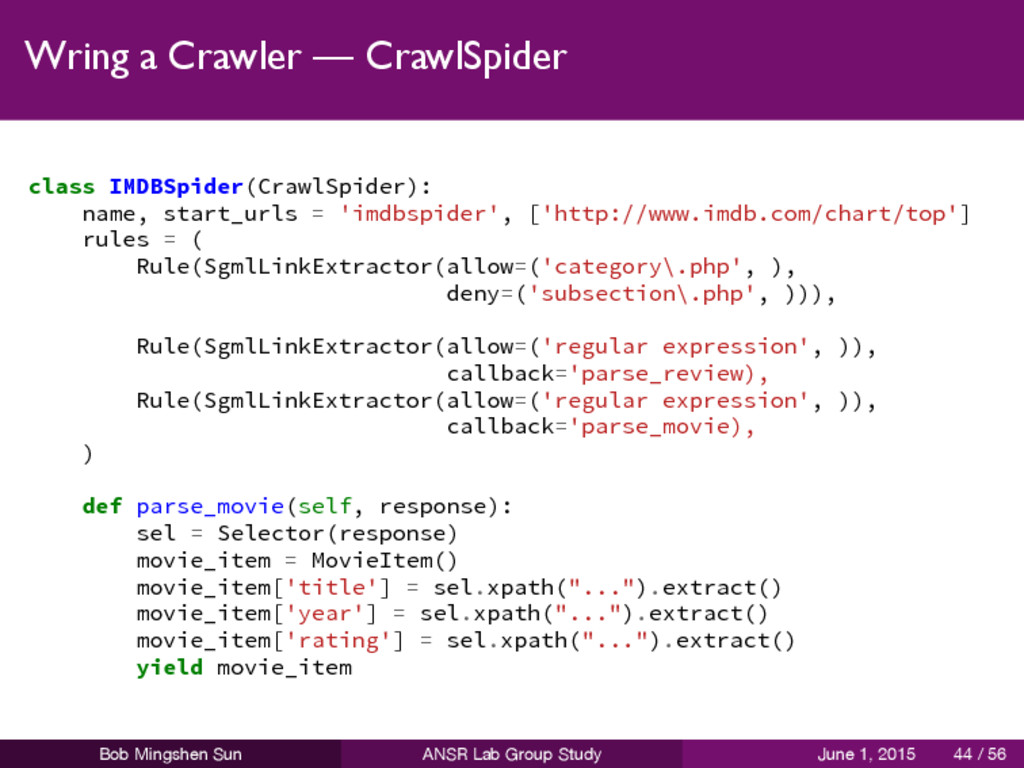
used spider for crawling regular websites it provides a convenient mechanism for following links by defining a set of rules start from it and override it as needed for more custom functionality or just implement your own spider Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 43 / 56
been scraped by a spider, it is sent to the Item Pipeline which process it through several components that are executed sequentially. Each item pipeline component is a Python class that implements a simple method. receive an Item and perform an action over it deciding if the Item should continue through the pipeline or be dropped and no longer processed Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 45 / 56
pipelines are: cleansing HTML data validating scraped data (checking that the items contain certain fields) checking for duplicates (and dropping them) storing the scraped item in a database Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 46 / 56
1.15 def process_item(self, item, spider): if item['price']: if item['price_excludes_vat']: item['price'] = item['price'] * self.vat_factor return item else: raise DropItem("Missing price in %s" % item) Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 47 / 56
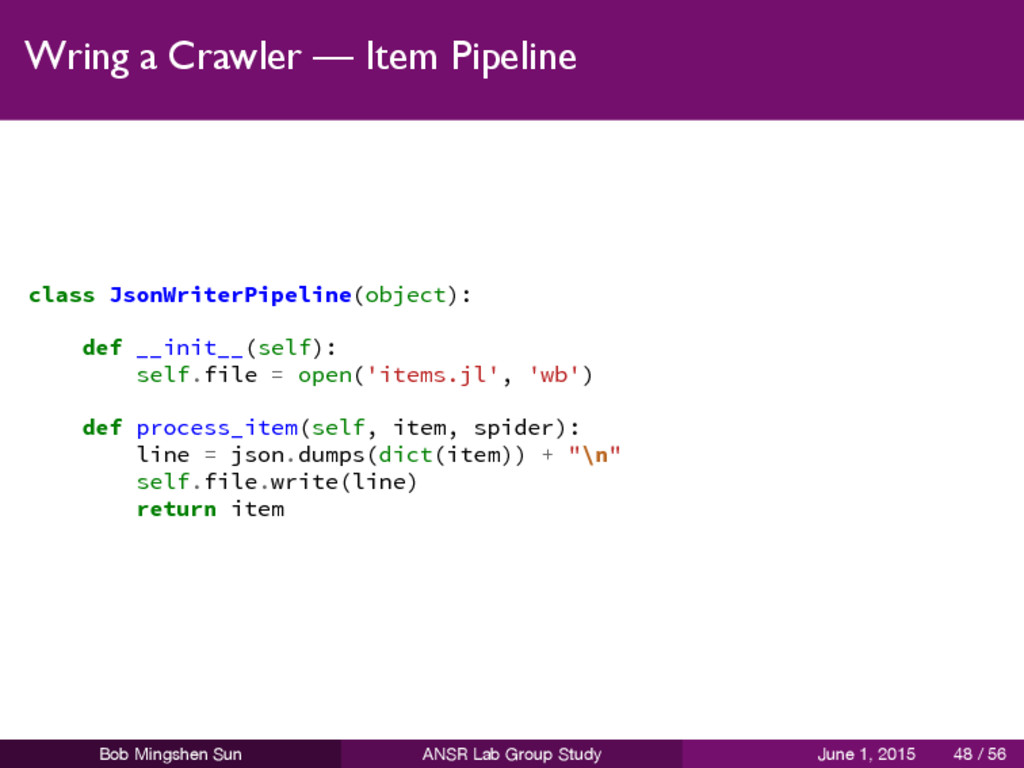
self.file = open('items.jl', 'wb') def process_item(self, item, spider): line = json.dumps(dict(item)) + "\n" self.file.write(line) return item Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 48 / 56
component To activate an Item Pipeline component you must add its class to the ITEM_PIPELINES setting, like in the following example: ITEM_PIPELINES = { 'myproject.pipeline.PricePipeline': 300, 'myproject.pipeline.JsonWriterPipeline': 800, } Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 49 / 56
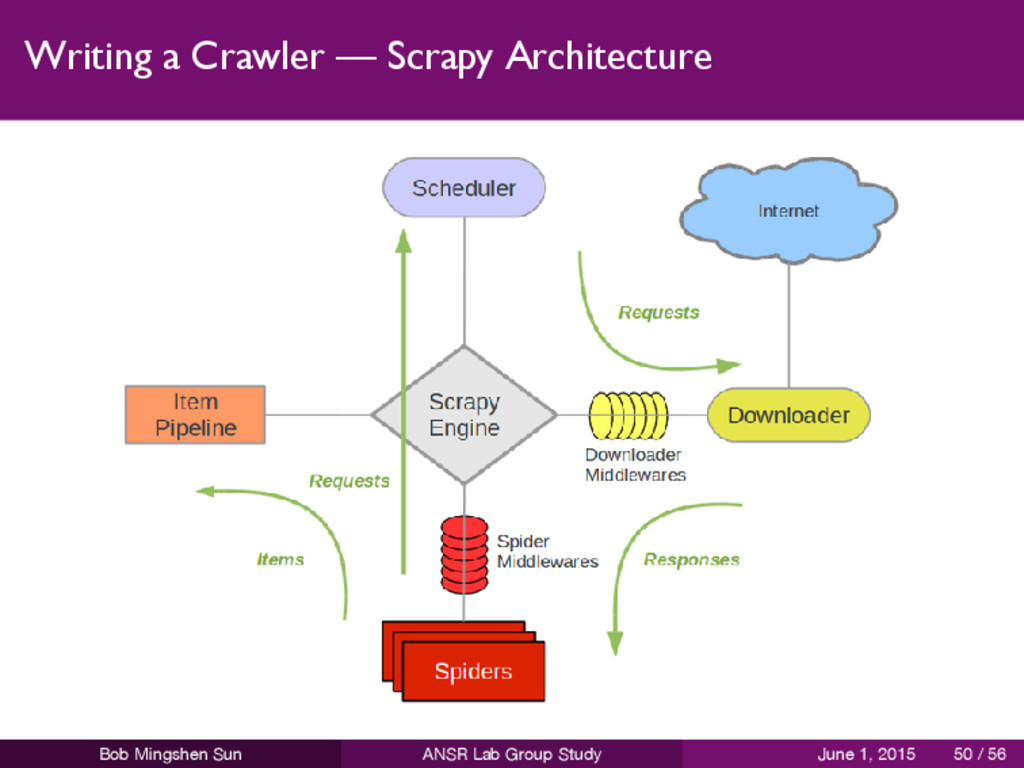
a framework of hooks into Scrapy’s request/response processing. It’s a light, low-level system for globally altering Scrapy’s requests and responses. CookiesMiddleware DefaultHeadersMiddleware DownloadTimeoutMiddleware HttpAuthMiddleware UserAgentMiddleware AjaxCrawlMiddleware Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 51 / 56
a framework of hooks into Scrapy’s spider processing mechanism where you can plug custom functionality to process the responses that are sent to Spiders for processing and to process the requests and items that are generated from spiders. DepthMiddleware HttpErrorMiddleware UrlLengthMiddleware Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 52 / 56
for scrapy create a project: scrapy startproject myproject create a new spider: scrapy genspider mydomain mydomain.com start crawling: scrapy crawl myproject pause and continue: scrapy crawl somespider -s JOBDIR=crawls/somespider-1 Bob Mingshen Sun ANSR Lab Group Study June 1, 2015 53 / 56
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}