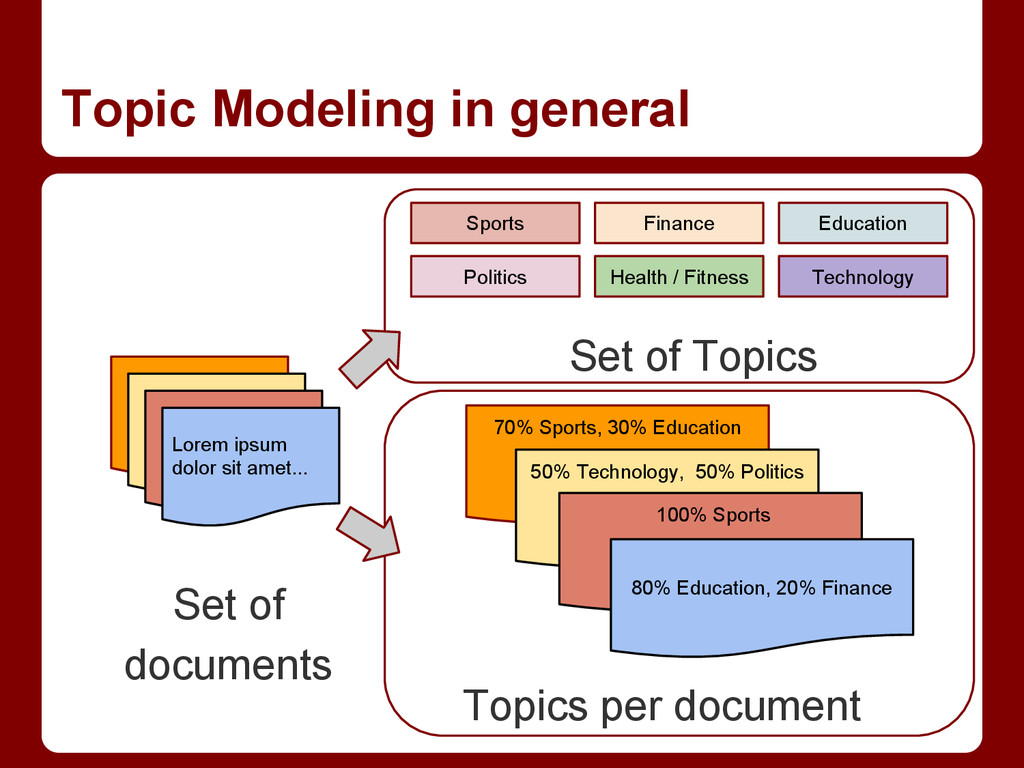
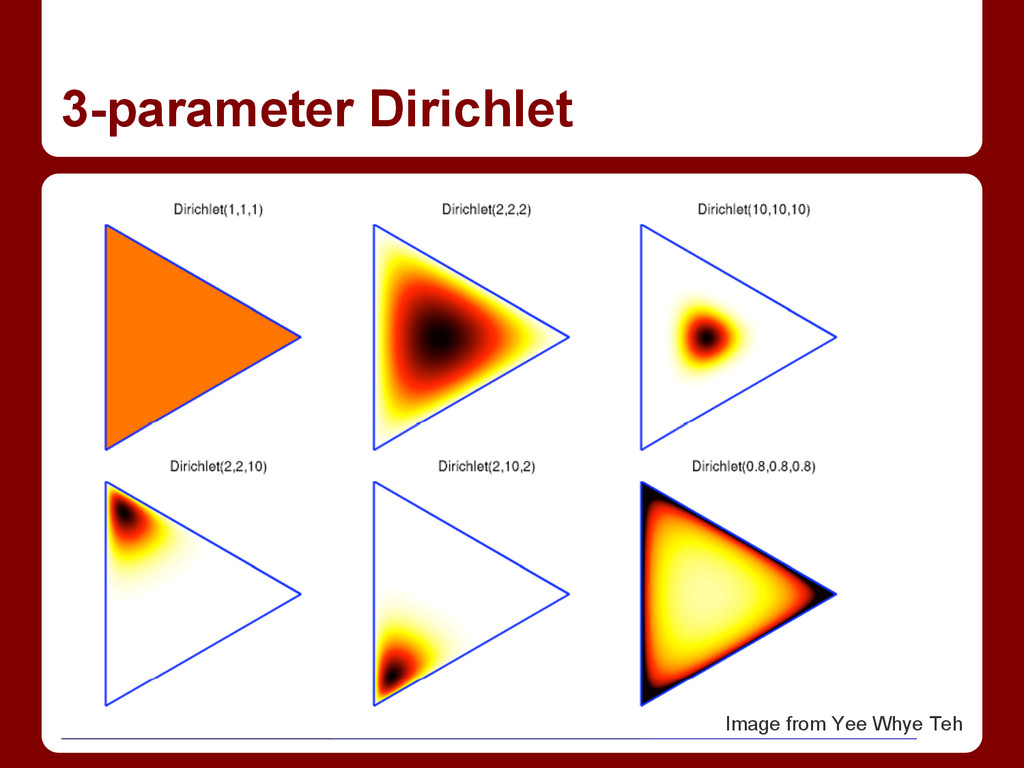
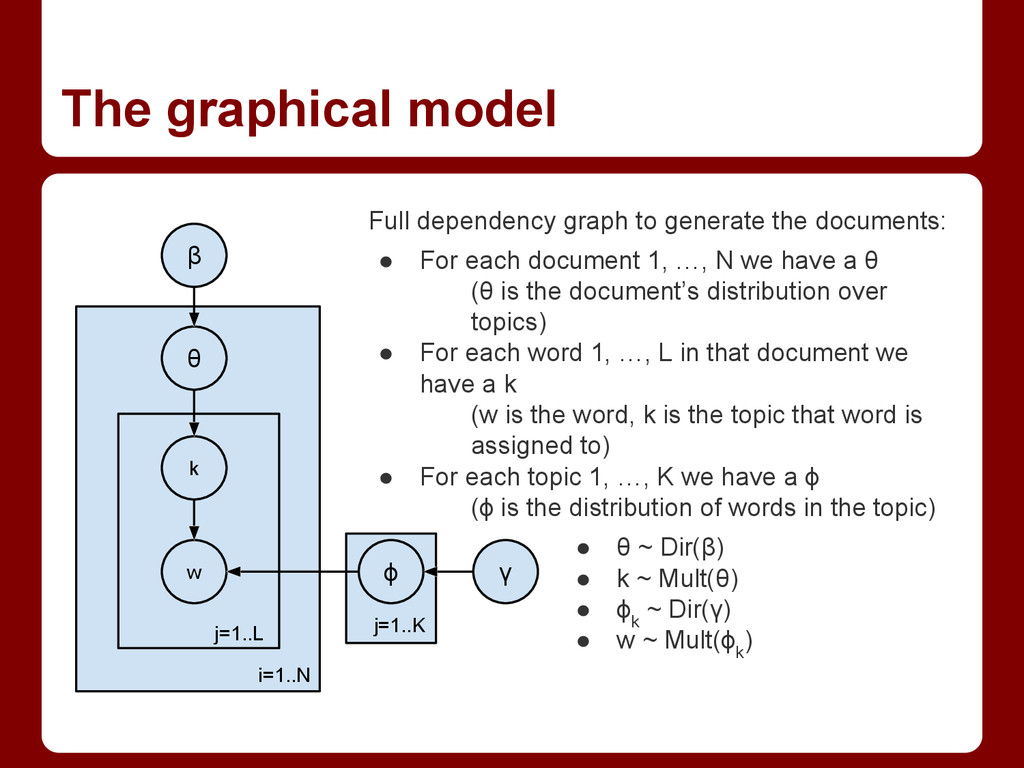
Latent Dirichlet Allocation, typically referred to as Topic Modeling, has proven to be a profoundly useful model in many areas of application. It uncovers latent "topics" in a corpus, leveraging the properties of the Dirichlet distribution to encourage sparseness. This Dirichlet distribution is of fixed size, making the choice of number of topics an important model parameter. By swapping out this fixed-size distribution for the up-to-infinite-sized Dirichlet process, the number of topics will be estimated by the model as well. Although this requires some extra book-keeping, the Gibbs sampling update is not substantially more difficult. At the end of this talk, you should understand why Latent Dirichlet Allocation and the Hierarchical Dirichlet Process have been so effective on so many tasks, and be able to implement them yourself.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}