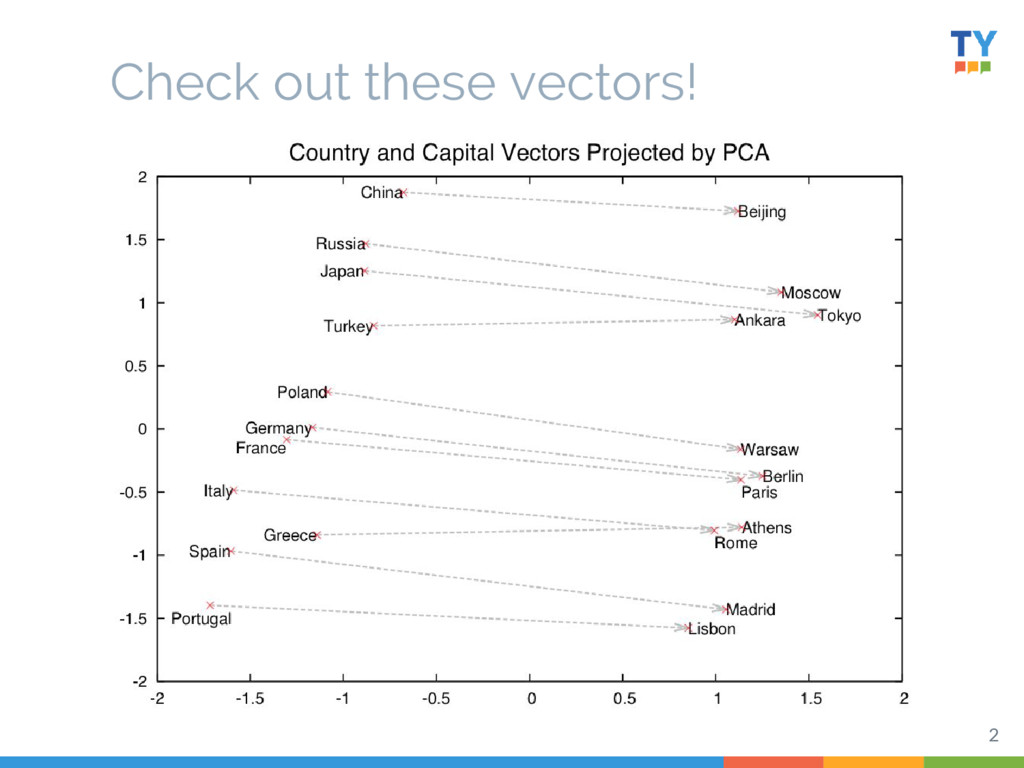
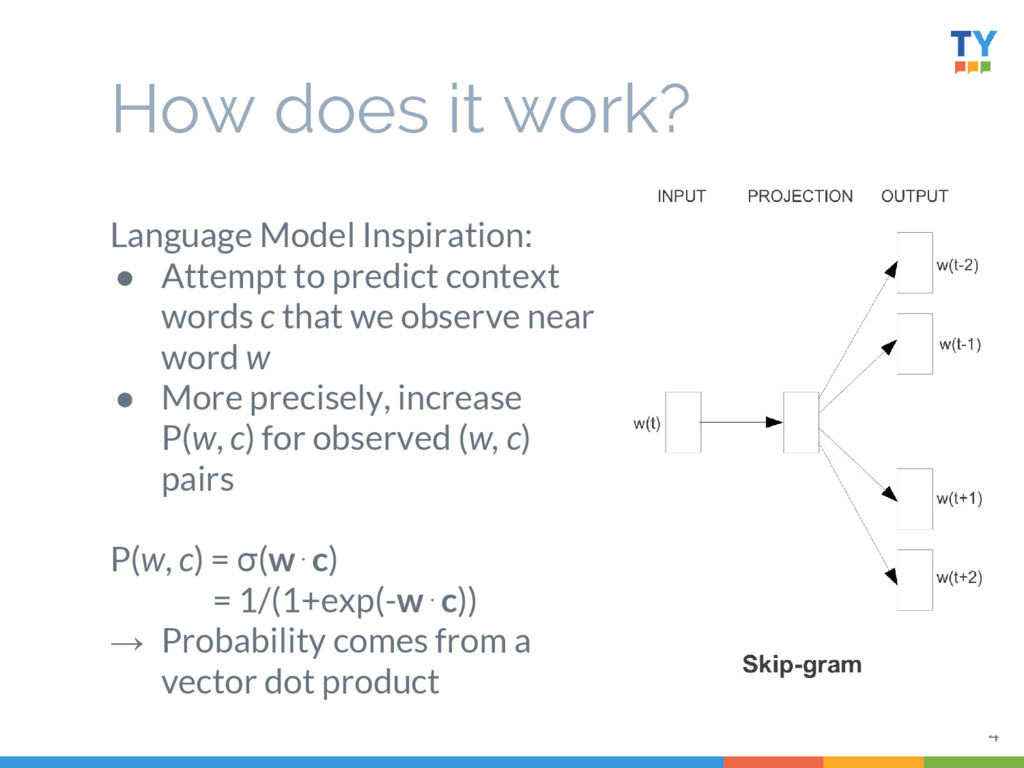
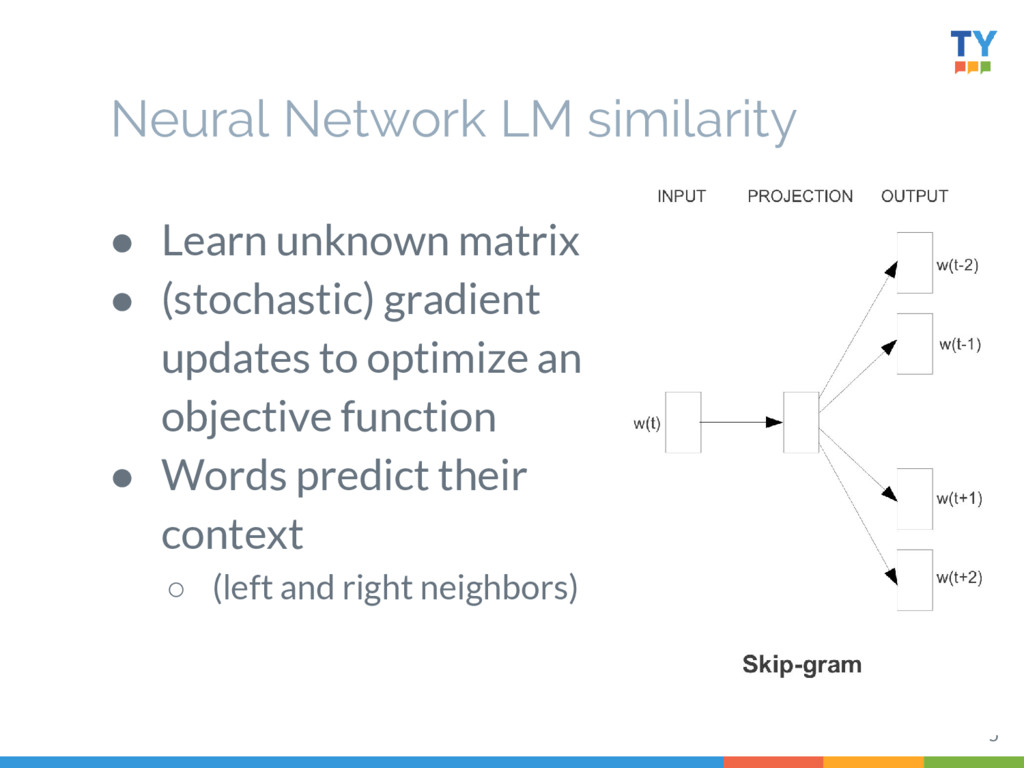
Word2Vec has proven useful at many tasks in NLP, because the vectors learned capture many meaningful relationships. This has spawned a large number of variations suited to accomplishing distinct tasks - not unlike LDA did ten years earlier. In this talk, I'll walk through briefly how Word2Vec functions, its assumptions and shortfalls, and some simple, successful variants.
![UNDERSTANDING AND EXPANDING WORD2VEC[1, 2] Presented by: Daniel Peterson [email protected]](https://files.speakerdeck.com/presentations/107af20de46e4592a085e93121bf096d/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Related Work, as extensions • GloVe[5] ◦ Add bias terms](https://files.speakerdeck.com/presentations/107af20de46e4592a085e93121bf096d/slide_13.jpg){kind=link}
![Questions? [1] Mikolov, Tomas, et al. "Efficient estimation of word](https://files.speakerdeck.com/presentations/107af20de46e4592a085e93121bf096d/slide_14.jpg){kind=link}