Neural Networks COLIEE 2025 Takao Mizuno1 Yoshinobu Kano2 1FRAIM Inc. 2Shizuoka University The 20th International Conference on Artificial Intelligence and Law@Chicago The 12th Competition on Legal Information Extraction and Entailment (COLIEE 2025) June 20, 2025
Neural Networks Background About COLIEE What is COLIEE? Competition on Legal Information Extraction and Entailment (COLIEE) is an annual shared-task series, launched in 2014, that drives research on legal IR and textual entailment. COLIEE 2025 consists of four main tasks and one pilot task: retrieval and entailment for case law (Tasks 1 & 2), retrieval and entailment for statutory law (Tasks 3 & 4), and legal judgment prediction for Japanese civil cases (Pilot Task). In this presentation, we focus on Task 3: Statute Law Retrieval (a.k.a. Statutory Article Retrieval;SAR), which requires identifying all Civil-Code articles relevant to a given legal question. 3 / 32 3 / 32
Neural Networks Background About COLIEE COLIEE Task 3 – Statutory Article Retrieval(SAR) Objective: For a legal question 𝑞 ∈ Q, identify the gold-standard set of relevant articles 𝐴+ 𝑞 ⊆ A that are required to answer it, where A is the set of all Civil-Code articles. Input: Legal question 𝑞, drawn from the Japanese bar exam. Output: A model predicts a candidate set 𝑅𝑞 ⊆ A of articles it deems relevant to question 𝑞. Evaluation Metric Macro-averaged 𝐹2, computed from per-query precision 𝑃(𝑞) and recall 𝑅(𝑞): 𝐹2 (𝑞) = 5 · 𝑃(𝑞) · 𝑅(𝑞) 4 · 𝑃(𝑞) + 𝑅(𝑞) 𝑃(𝑞) = |𝑅𝑞 ∩ 𝐴+ 𝑞 | |𝑅𝑞 | 𝑅(𝑞) = |𝑅𝑞 ∩ 𝐴+ 𝑞 | | 𝐴+ 𝑞 | Final score: macro average of 𝐹2 (𝑞) over all 𝑞 ∈ Q. 4 / 32 4 / 32
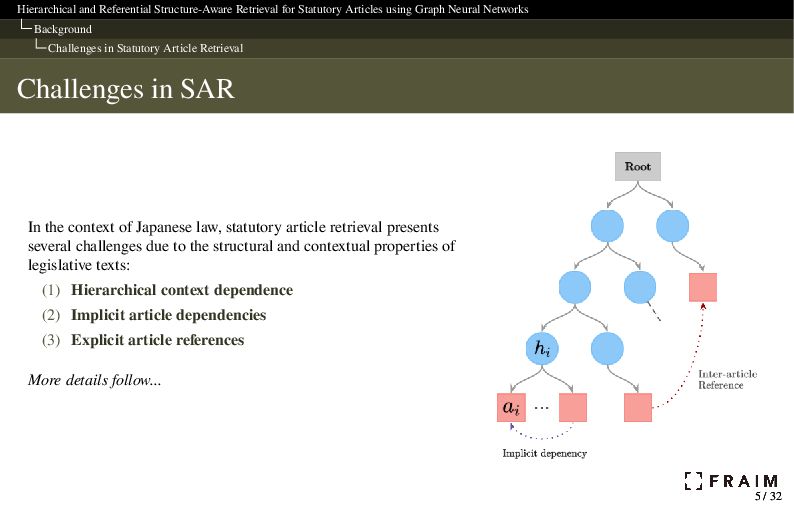
Neural Networks Background Challenges in Statutory Article Retrieval Challenges in SAR In the context of Japanese law, statutory article retrieval presents several challenges due to the structural and contextual properties of legislative texts: (1) Hierarchical context dependence (2) Implicit article dependencies (3) Explicit article references More details follow... 5 / 32 5 / 32
Neural Networks Background Challenges in Statutory Article Retrieval (1) Hierarchical Context Dependence Articles appear at the bottom of a multi-level legal structure. Structural units include parts, chapters, sections, subsections, divisions, and captions. Captions are not formal elements but often convey important topical meaning. Hierarchical context, including structural headings or labels, is crucial for interpreting legal content and guiding retrieval. 6 / 32 6 / 32
Neural Networks Background Challenges in Statutory Article Retrieval (2) Implicit Article Dependencies Some articles rely on concepts defined in nearby provisions. Example: Article 89 uses “natural fruits” defined in Article 88. These dependencies are often not explicitly stated. Ignoring context may lead to missing key provisions. 7 / 32 7 / 32
Neural Networks Background Challenges in Statutory Article Retrieval (3) Explicit Article References Articles often explicitly refer to other provisions. Example: Article 291 refers to Article 166(2) by name. Example: Article 290 refers to the preceding Article (i.e., Article 289). These references create explicit semantic links across distant provisions. Systems must capture these links for accurate retrieval. 8 / 32 8 / 32
Neural Networks Background Challenges in Statutory Article Retrieval Example: Hierarchical Structure in the Civil Code These diagrams illustrate actual hierarchical structures extracted from the Japanese Civil Code dataset used in COLIEE Task 3. Each structural node (e.g., Chapter, Section) may contain multiple article nodes. 1. General Provisions 2. Property Law 3. Law of Obligations 9 / 32 9 / 32
Neural Networks Background Retrieval Methods Retrieval Methods Sparse retrieval (e.g., BM25): Represent queries and documents as high-dimensional sparse vectors based on word frequency Score similarity using lexical overlap Strong for exact matching, but limited in capturing meaning Dense retrieval (Bi-Encoder): Encode queries and articles into fixed-dimensional dense vectors separately This enables semantic matching via cosine similarity or dot product Re-ranking (Cross-Encoder): Jointly encode query and article with full attention Provide accurate scores for top-k candidates Retrieve & Re-Rank — Sentence Transformers documentation (2020). https://sbert.net/examples/sentence_transformer/applications/retrieve_rerank/README.html 10 / 32 10 / 32
Neural Networks Background Design Motivations Design Motivations: Beyond Isolated Article Retrieval Many retrieval models treat each statutory article as an independent unit. But legal interpretation often relies on structural and contextual cues. Problems with Isolated Retrieval: No structural context — hierarchical units and their headings are excluded from article understanding. No neighboring context — links to adjacent provisions are lost. No reference resolution — citations to other articles are not resolved. What Legal Retrieval Needs: Articles must be interpreted in context, not in isolation. Structural elements must serve as topical guides. A retrieval system must capture both explicit and implicit inter-article dependencies. Goal: Build a retriever that reflects the inherent structure of law. 11 / 32 11 / 32
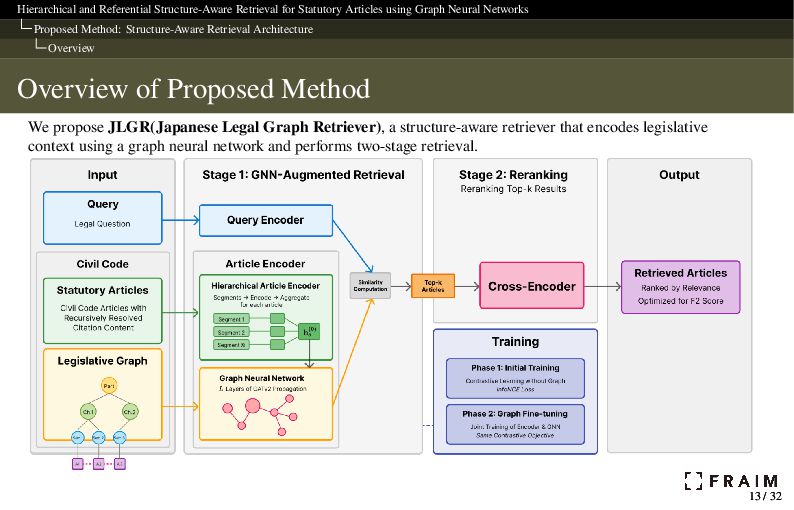
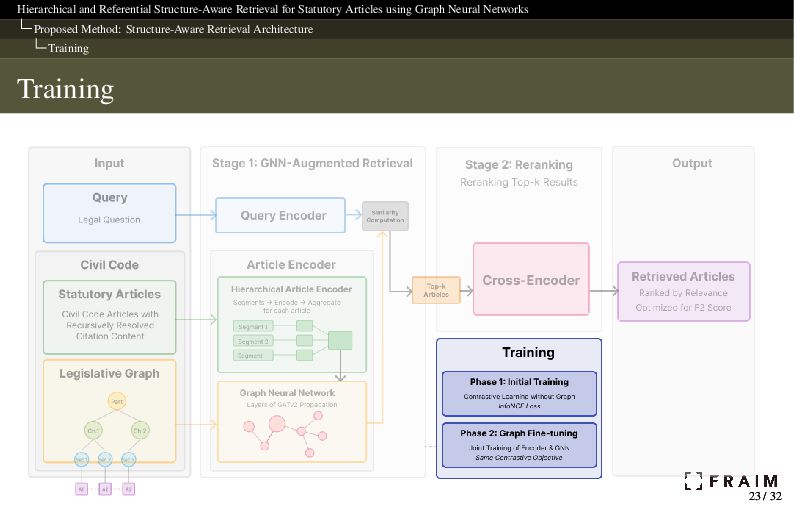
Neural Networks Proposed Method: Structure-Aware Retrieval Architecture Overview Key Technique: Graph Neural Network What is a Graph Neural Network (GNN)? A GNN is a neural network designed to operate on graph-structured data. It encodes information from a node’s local neighborhood by message passing. Formally, a graph is defined as 𝐺 = (𝑉, 𝐸): 𝑉: nodes (e.g., articles, headings) 𝐸: edges (e.g., hierarchical links, citation references) Node representations are updated iteratively: h(𝑙+1) 𝑣 = 𝜎 𝑊 · h(𝑙) 𝑣 + ∑︁ 𝑢∈N(𝑣) h(𝑙) 𝑢 Zonghan Wu et al. (Jan. 2019). “A comprehensive survey on graph neural networks”. In: arXiv [cs.LG]. url: http://dx.doi.org/10.1109/TNNLS.2020.2978386 GNNs could be well-suited to model hierarchical and relational structure in legal texts. 12 / 32 12 / 32
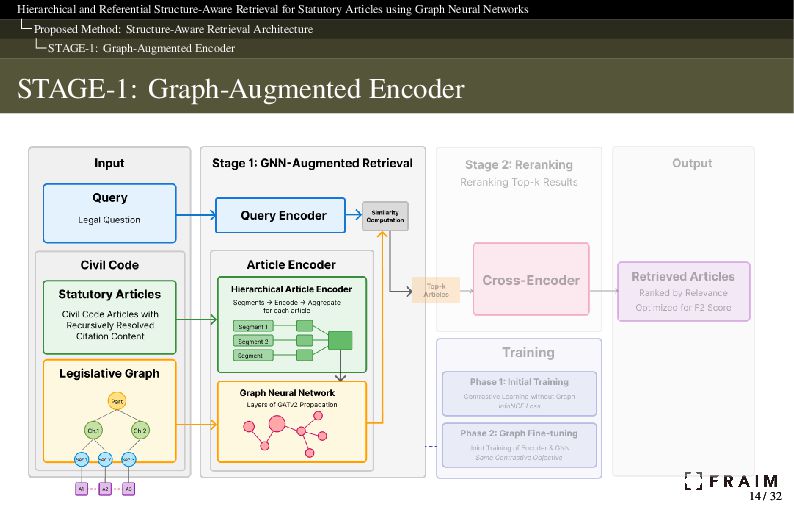
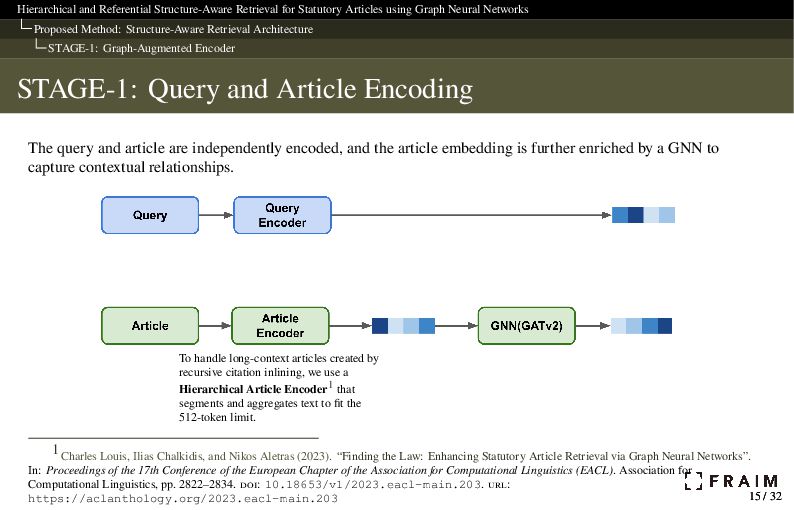
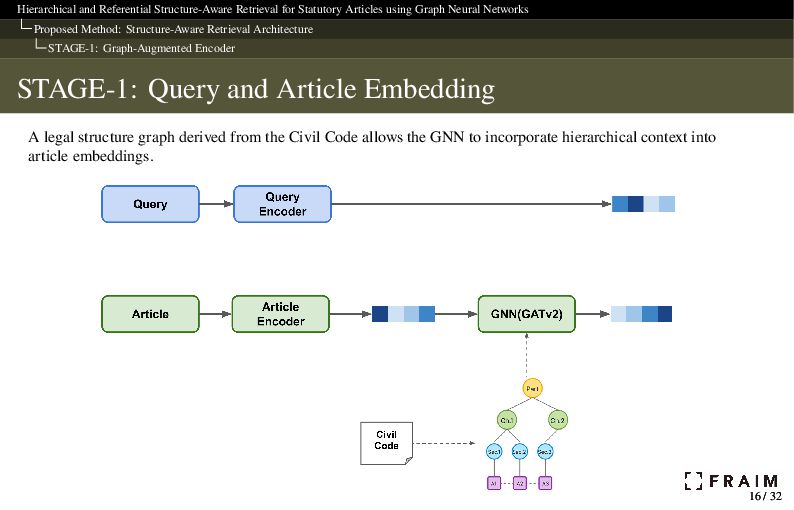
Neural Networks Proposed Method: Structure-Aware Retrieval Architecture STAGE-1: Graph-Augmented Encoder STAGE-1: Query and Article Encoding The query and article are independently encoded, and the article embedding is further enriched by a GNN to capture contextual relationships. To handle long-context articles created by recursive citation inlining, we use a Hierarchical Article Encoder1 that segments and aggregates text to fit the 512-token limit. 1 Charles Louis, Ilias Chalkidis, and Nikos Aletras (2023). “Finding the Law: Enhancing Statutory Article Retrieval via Graph Neural Networks”. In: Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL). Association for Computational Linguistics, pp. 2822–2834. doi: 10.18653/v1/2023.eacl-main.203. url: https://aclanthology.org/2023.eacl-main.203 15 / 32 15 / 32
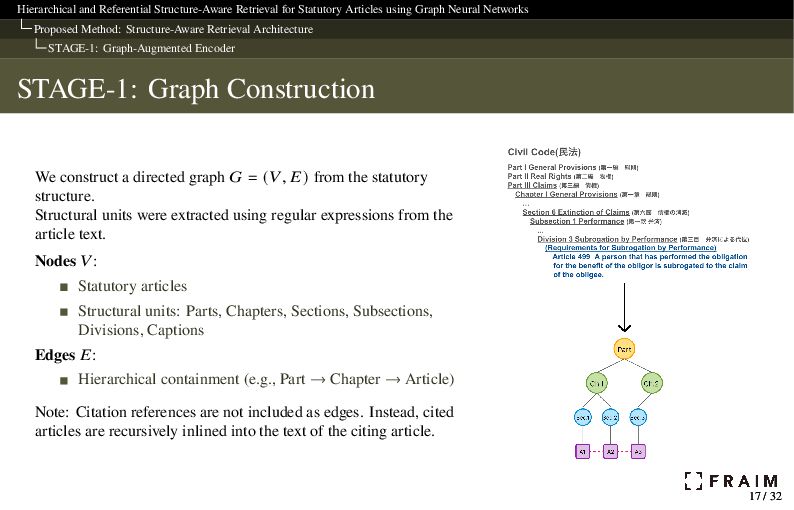
Neural Networks Proposed Method: Structure-Aware Retrieval Architecture STAGE-1: Graph-Augmented Encoder STAGE-1: Graph Construction We construct a directed graph 𝐺 = (𝑉, 𝐸) from the statutory structure. Structural units were extracted using regular expressions from the article text. Nodes 𝑉: Statutory articles Structural units: Parts, Chapters, Sections, Subsections, Divisions, Captions Edges 𝐸: Hierarchical containment (e.g., Part → Chapter → Article) Note: Citation references are not included as edges. Instead, cited articles are recursively inlined into the text of the citing article. 17 / 32 17 / 32
Neural Networks Proposed Method: Structure-Aware Retrieval Architecture STAGE-1: Graph-Augmented Encoder STAGE-1: Citation Handling with Topological Order Legal articles often refer to others, e.g., “in accordance with Article 542” or “as defined in the preceding article.” We recursively inline the full text of cited articles into the citing article’s content. To ensure consistency and avoid cyclic references, we apply a topological sort to the citation dependency graph before inlining. The ability to perform this sort confirms that the citation graph is a directed acyclic graph (DAG). In fact, citation cycles would imply logical inconsistency in legal interpretation. Statutory law is therefore typically designed to be acyclic in structure. Why it matters: Ensures all dependencies are inlined in a valid order Prevents infinite loops from circular citations Preserves logical soundness and enables stable encoding Citing articles are expanded in topological order over citation dependencies. 18 / 32 18 / 32
Neural Networks Proposed Method: Structure-Aware Retrieval Architecture STAGE-1: Graph-Augmented Encoder Example: Citation Dependency Graph from the Civil Code The figure below shows an example portion of a citation dependency graph extracted from the Japanese Civil Code dataset used in COLIEE Task 3. Citation expressions were extracted using regular expressions from article text. Each node corresponds to a statutory article, labeled by its article number (e.g., “400”, “412”, “541”). Edges represent citation references, forming a directed acyclic graph (DAG), which is used for topological sorting and recursive inlining of citation content. 19 / 32 19 / 32
Neural Networks Proposed Method: Structure-Aware Retrieval Architecture STAGE-1: Graph-Augmented Encoder STAGE-1: Graph-Augmented Encoder To integrate structural context into article embeddings, we apply a graph neural network over a legislative graph. Node initialization: h(0) 𝑣 = Encoder(𝑥𝑣 ) where 𝑥𝑣 is the input text of article or heading 𝑣, and Encoder is a bi-encoder trained via contrastive learning on query–article pairs. GNN propagation (GATv2): h(𝑙+1) 𝑣 = 𝜎 ∑︁ 𝑢∈N(𝑣) 𝛼 (𝑙) 𝑢𝑣 𝑊 (𝑙) h(𝑙) 𝑢 After 𝐿 layers, we obtain the structure-aware embedding: z𝑣 = h(𝐿) 𝑣 Petar Veliı ckovic et al. (Oct. 2017). “Graph Attention Networks”. In: arXiv [stat.ML]. url: http://arxiv.org/abs/1710.10903 Shaked Brody, Uri Alon, and Eran Yahav (May 2021). “How Attentive are Graph Attention Networks?” In: arXiv [cs.LG]. url: http://arxiv.org/abs/2105.14491 20 / 32 20 / 32
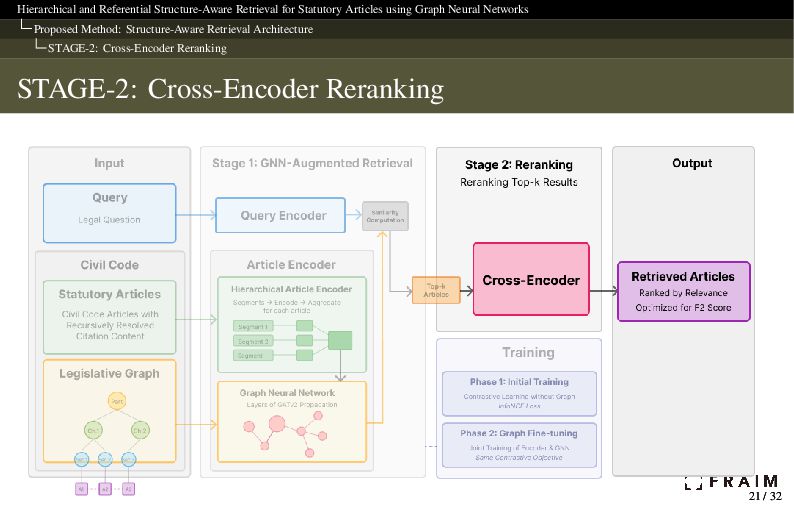
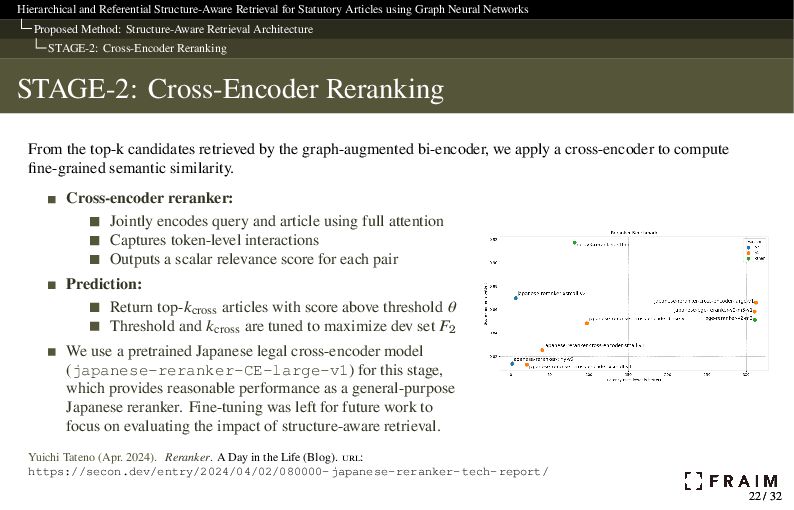
Neural Networks Proposed Method: Structure-Aware Retrieval Architecture STAGE-2: Cross-Encoder Reranking STAGE-2: Cross-Encoder Reranking From the top-k candidates retrieved by the graph-augmented bi-encoder, we apply a cross-encoder to compute fine-grained semantic similarity. Cross-encoder reranker: Jointly encodes query and article using full attention Captures token-level interactions Outputs a scalar relevance score for each pair Prediction: Return top-𝑘cross articles with score above threshold 𝜃 Threshold and 𝑘cross are tuned to maximize dev set 𝐹2 We use a pretrained Japanese legal cross-encoder model (japanese-reranker-CE-large-v1) for this stage, which provides reasonable performance as a general-purpose Japanese reranker. Fine-tuning was left for future work to focus on evaluating the impact of structure-aware retrieval. Yuichi Tateno (Apr. 2024). Reranker. A Day in the Life (Blog). url: https://secon.dev/entry/2024/04/02/080000-japanese-reranker-tech-report/ 22 / 32 22 / 32
Neural Networks Proposed Method: Structure-Aware Retrieval Architecture Training Key Technique: Contrastive Learning Contrastive learning helps models learn to bring relevant pairs closer in the embedding space, while pushing apart irrelevant examples. How it works: A query and its relevant article form a positive pair. Other articles (in-batch or retrieved) are treated as negatives. The encoder learns to map positives closer and negatives further apart. Why it matters: Enables the model to learn semantically aligned representations for retrieval Provides initial embeddings for GNN-based propagation Also used to train the entire GNN-augmented encoder via contrastive loss Florian Schroff, Dmitry Kalenichenko, and James Philbin (Mar. 2015). “FaceNet: A unified embedding for face recognition and clustering”. In: arXiv [cs.CV]. url: http://dx.doi.org/10.1109/CVPR.2015.7298682 Phuc H Le-Khac, Graham Healy, and Alan F Smeaton (Oct. 2020). “Contrastive Representation Learning: A framework and review”. In: arXiv [cs.LG]. url: http://dx.doi.org/10.1109/ACCESS.2020.3031549 24 / 32 24 / 32
Neural Networks Proposed Method: Structure-Aware Retrieval Architecture Training Training Dataset Construction We use past bar-exam questions and their gold-standard article labels provided in COLIEE Task 3. Each question–article pair is classified as: Positive: article is part of the gold label set for the question Negative: article is not included in the gold set Hard negatives: Retrieved using BM25 or from in-batch negatives during contrastive learning Encourage fine-grained semantic discrimination The corpus consists of 1,097 training questions (from 2004 to 2022) and 105 test questions (from 2024 exam). This dataset serves both contrastive pretraining and GNN-based learning. Jiahao Xie et al. (Aug. 2020). “Delving into inter-image invariance for unsupervised visual representations”. In: arXiv [cs.CV]. url: http://arxiv.org/abs/2008.11702 25 / 32 25 / 32
Neural Networks Proposed Method: Structure-Aware Retrieval Architecture Training Training Method JLGR is trained in two stages using contrastive learning: Training Phase 1: Contrastive pretraining (Bi-Encoder Only) Train the encoder to separate relevant and irrelevant article vectors Objective: InfoNCE loss using positive and hard negative pairs Output: semantically meaningful article embeddings Training Phase 2: GNN fine-tuning (Bi-Encoder + GNN) Apply GATv2 over the legislative graph Optimize the same contrastive objective using the updated embeddings GNN layers and the base encoder are trained jointly The same contrastive loss(InfoNCE) is used in both phases. L = − log exp(𝑠bi (𝑞, 𝑎+)/𝜏) exp(𝑠bi (𝑞, 𝑎+)/𝜏) + 𝑎− ∈A− 𝑞 exp(𝑠bi (𝑞, 𝑎− )/𝜏) 26 / 32 26 / 32
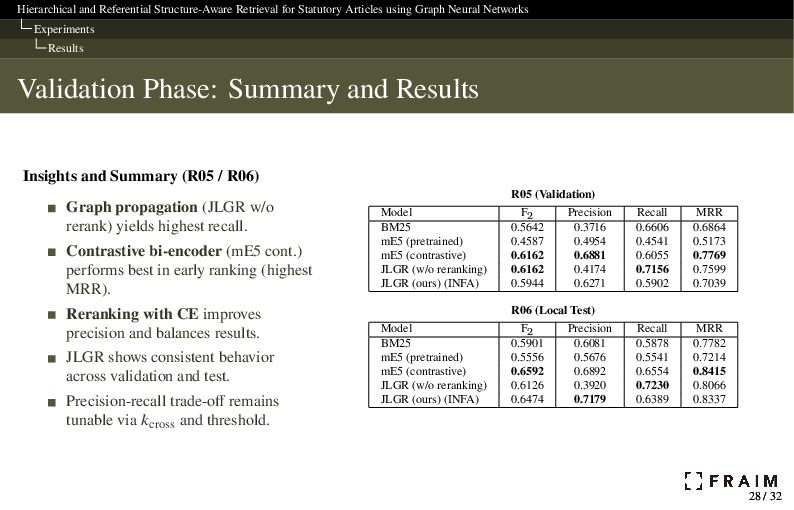
Neural Networks Discussion & Conclusion Discussion GNN-based propagation improves recall: JLGR without reranking achieved the highest recall in both validation and test settings by leveraging structural context, even without lexical overlap. Cross-encoder reranking recovers precision: The reranker effectively reorders top-𝑘 candidates to suppress false positives, resulting in more balanced performance. However, it was not fine-tuned for legal texts, suggesting room for improvement via domain adaptation. Citation inlining is simple but lossy: Recursive inlining preserves dependency information without adding edges, but flattens the distinction between citing and cited content. Future work will explore explicit modeling of referential links in the graph. Toward bridging lexical gaps: JLGR partially handles mismatches between user language and statute wording through structure, but surface variation remains a challenge. Hybrid retrieval (e.g., with BM25) and LLM-based query expansion offer promising extensions. 30 / 32 30 / 32
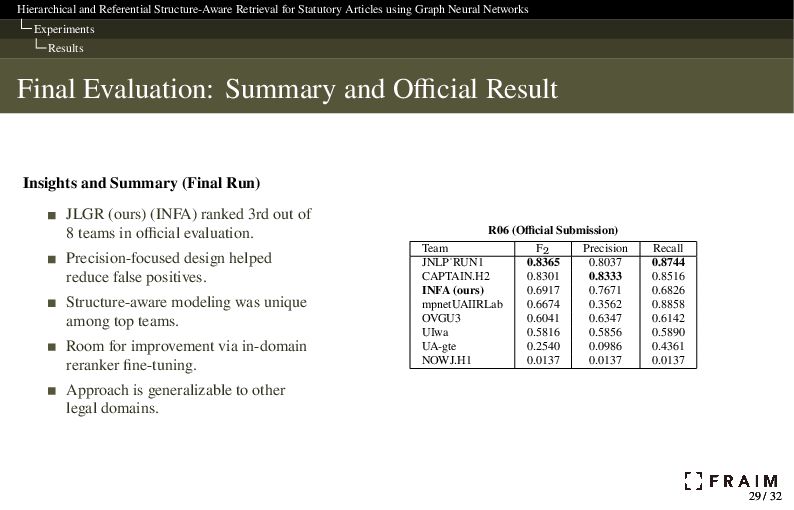
Neural Networks Discussion & Conclusion Conclusion We proposed JLGR, a structure-aware retrieval model for legal documents that combines GNN-based propagation with dense and cross-encoder retrieval. JLGR represents articles and captions as a graph, recursively inlines citations, and integrates contextual signals using GNNs. A two-stage retrieval pipeline (bi-encoder + reranker) balances recall and precision. JLGR achieved an F2 score of 0.5944 on R05 (validation) and 0.6917 on R06 (formal run), ranking 3rd out of 8 teams in COLIEE 2025 Task 3. It provides an interpretable and structure-aware alternative to purely dense models. The results highlight the value of incorporating legal structure and inter-article references in retrieval systems, especially for high-recall applications. Future directions include in-domain reranker fine-tuning, hybrid retrieval with lexical signals, LLM-based query rewriting, and applications to other statutory domains. 31 / 32 31 / 32
Neural Networks Discussion & Conclusion Thank You Thank you for your attention! Questions, comments, or feedback are welcome. Feel free to contact us: Takao Mizuno [email protected] This work was developed as part of the COLIEE 2025 shared task (Task 3). 32 / 32 32 / 32
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}