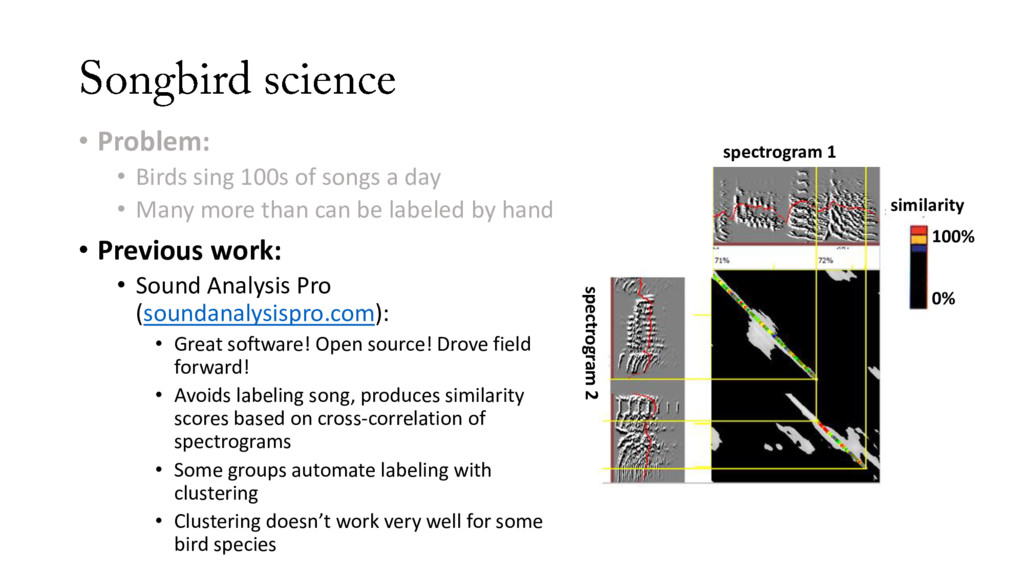
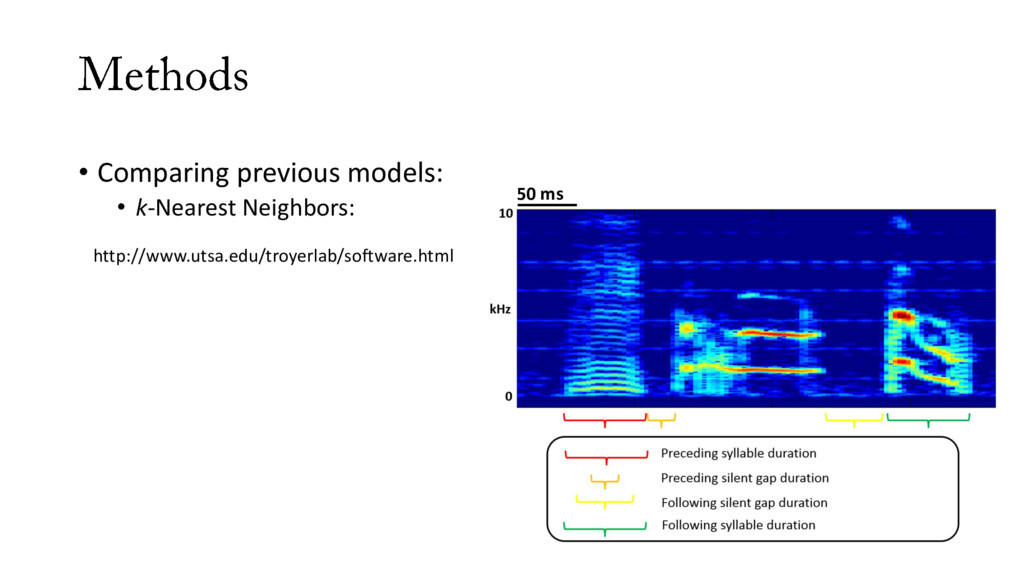
• Many more than can be labeled by hand • Previous work: • Sound Analysis Pro (soundanalysispro.com): • Great software! Open source! Drove field forward! • Avoids labeling song, produces similarity scores based on cross-correlation of spectrograms • Some groups automate labeling with clustering • Clustering doesn’t work very well for some bird species similarity spectrogram 1 spectrogram 2 100% 0%
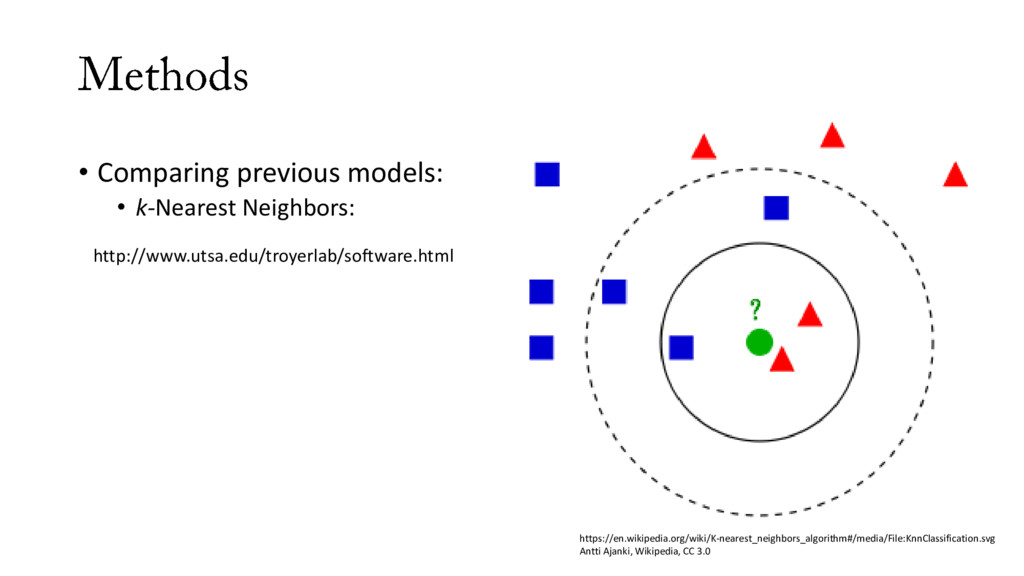
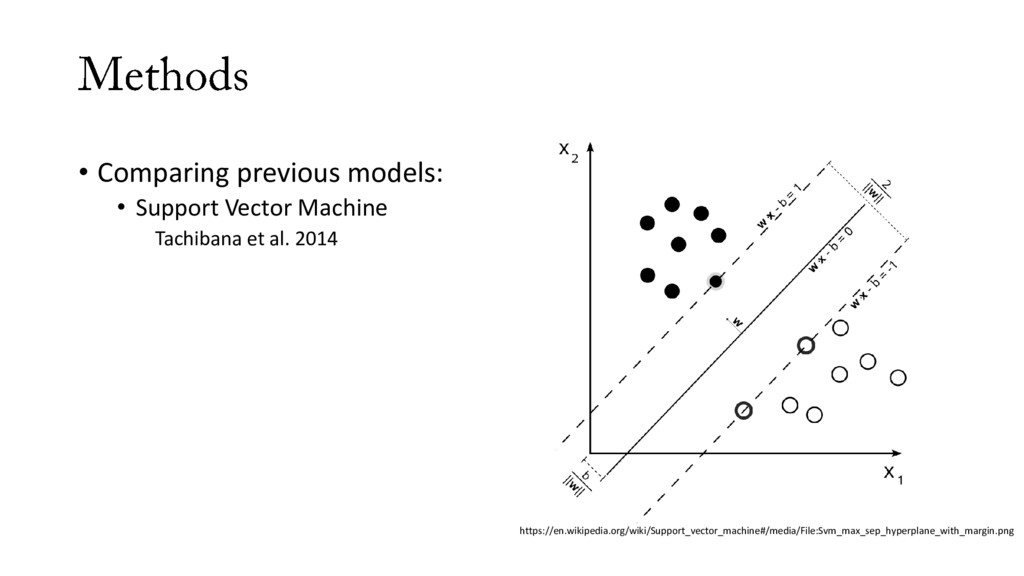
• Many more than can be labeled by hand • Previous work: • Sound Analysis Pro • Other machine learning methods applied to Bengalese finch song • K nearest neighbors (k-NN) • Support Vector Machines (SVM) • Convolutional Neural Network (CNN)
• Many more than can be labeled by hand • Previous work: • Sound Analysis Pro • Other machine learning methods applied to Bengalese finch song • Hard to compare different machine learning methods • not all open-source • not all well-documented software • very little in the way of publicly available repository of song
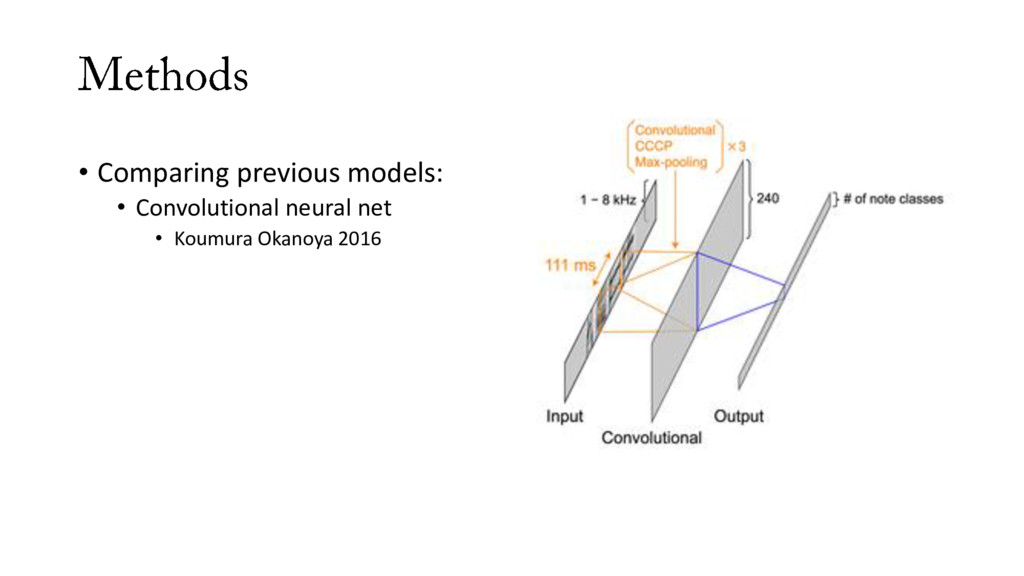
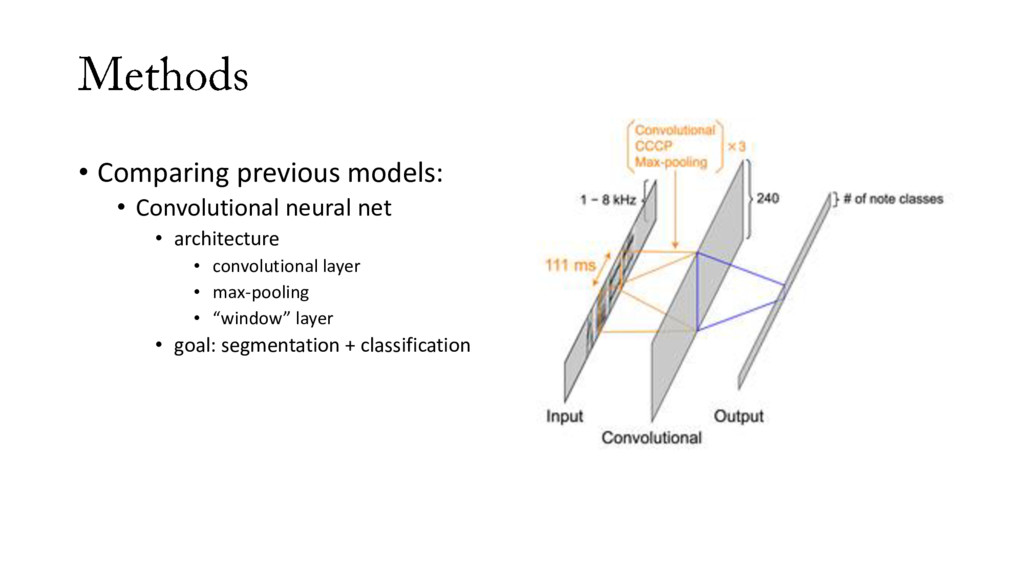
implements previously proposed approaches: • SVM and k-NN via scikit-learn • neural nets using Keras • easy to use, run on YAML config scripts • released with a large data set • hand-labeled data • well-segmented song • days, ~20k data points/day
label song in an automated way 2. make it easy to compare different previously-proposed machine learning methods for automated labeling of song 3. make it easy to test new machine learning methods
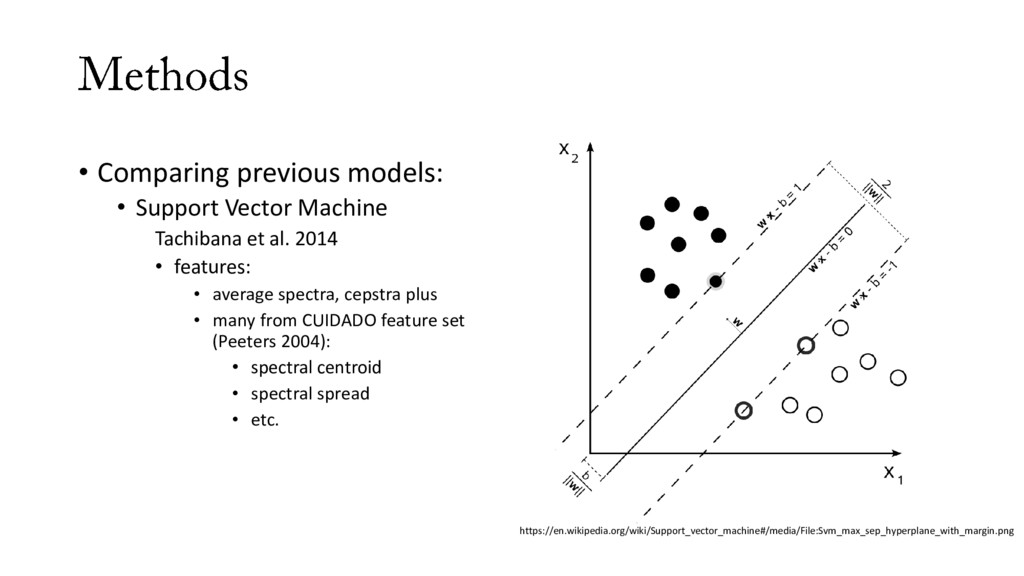
al. 2014 • features: • average spectra, cepstra plus • many from CUIDADO feature set (Peeters 2004): • spectral centroid • spectral spread • etc. https://en.wikipedia.org/wiki/Support_vector_machine#/media/File:Svm_max_sep_hyperplane_with_margin.png
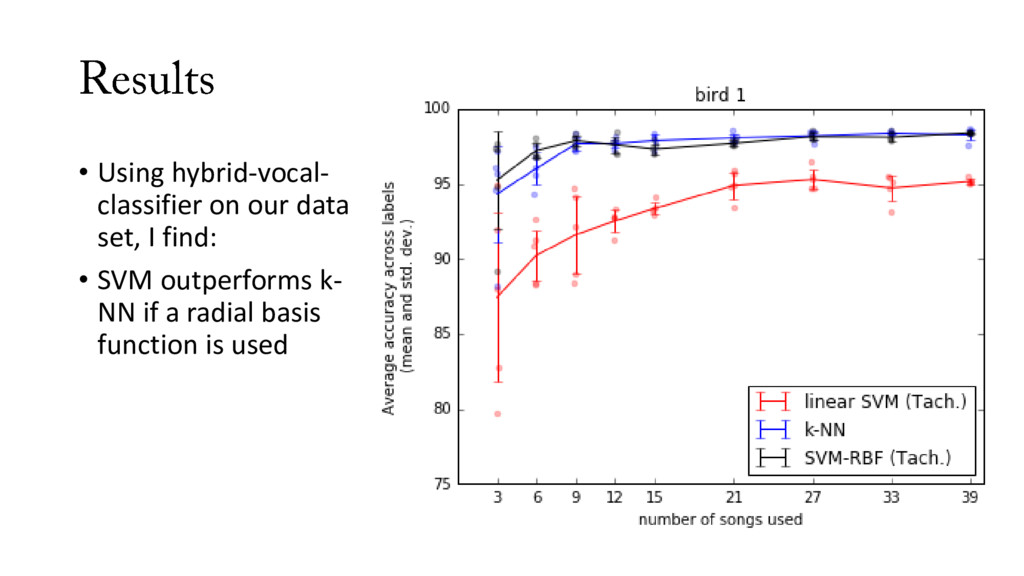
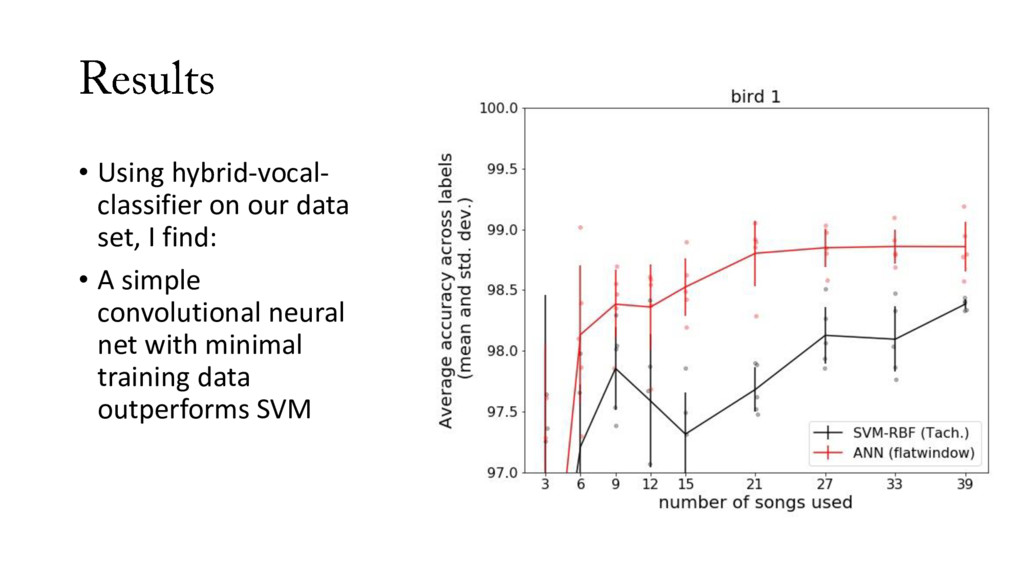
data (# of hand-labeled songs) • I want the best model for the least data • 5-fold cross validation • For each fold: random grab of n songs from training set, measure average accuracy across syllables
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}