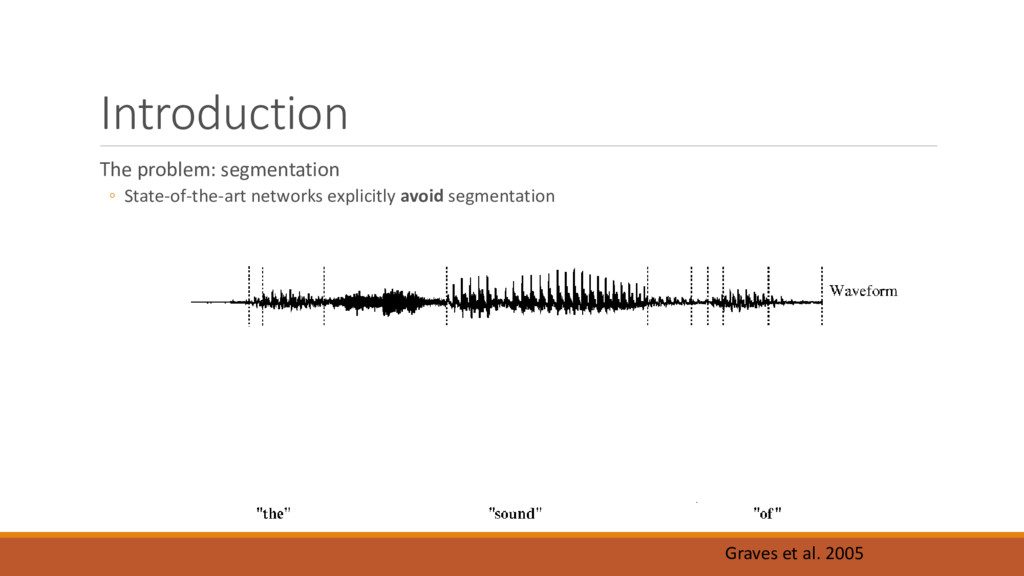
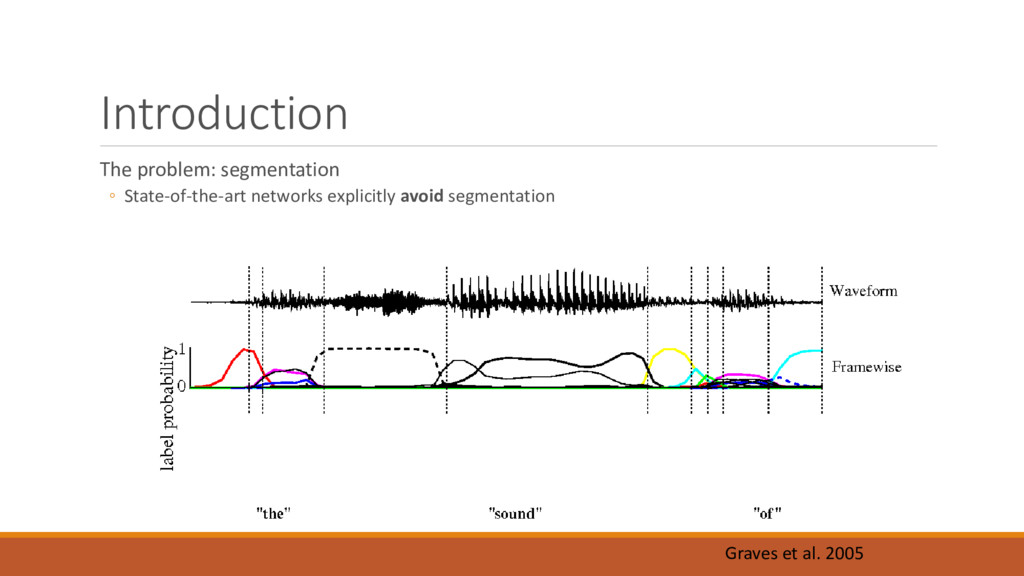
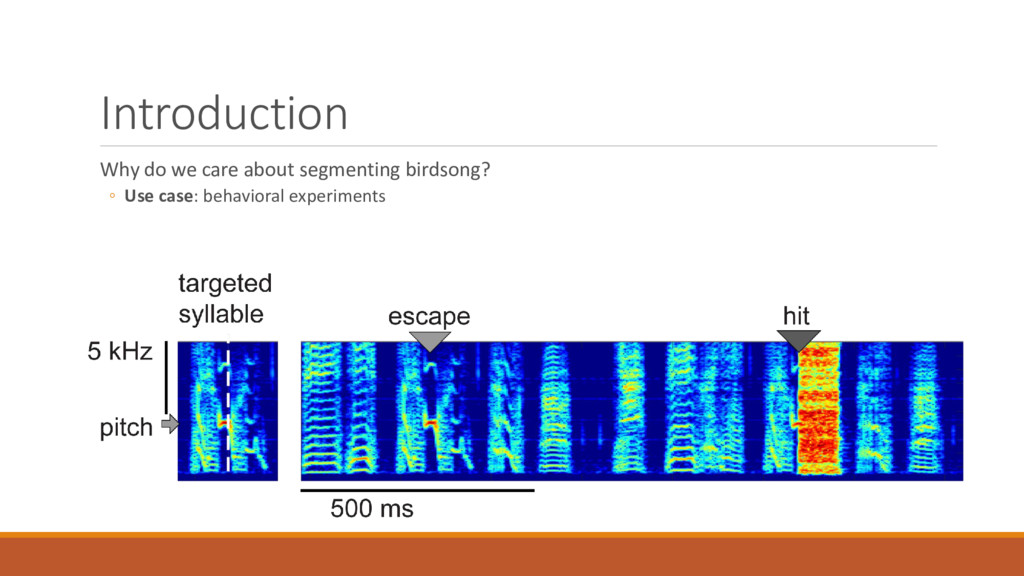
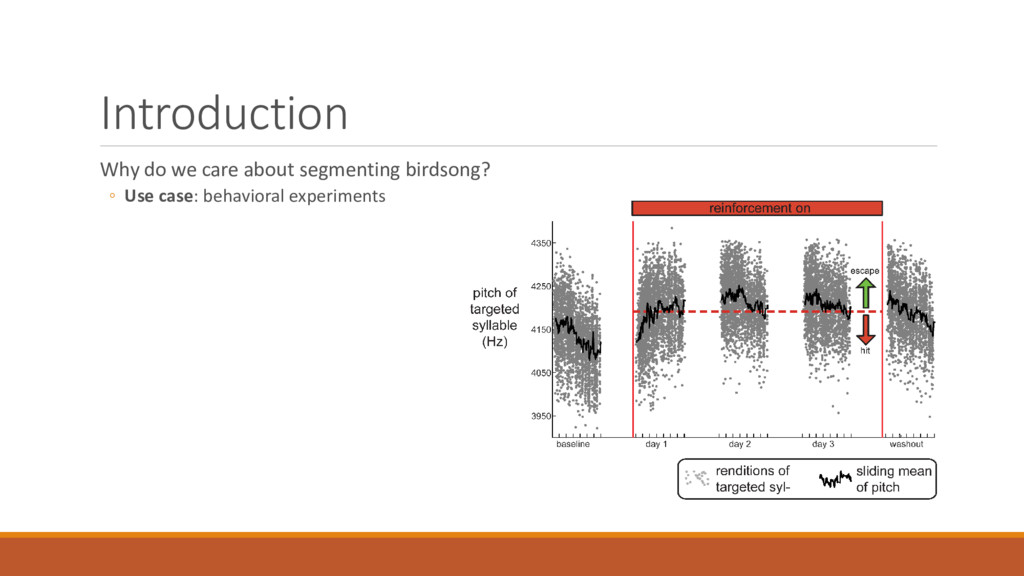
segmentation ◦ Diagnosis of speech disorders, e.g., stuttering ◦ Understand how brain controls speech ◦ At the level of muscles ◦ At the level of phonemes ◦ As a feature that may make ASR more robust ◦ Background noise ◦ Different accents Büchel C, Sommer M (2004) What Causes Stuttering?. PLOS Biology
Object recognition ◦ Image segmentation ◦ Finding piano keys in music (S. Böck and M. Schedl 2012) ◦ Finding events embedded in background noise (Parascandolo, Huttunen, and Virtanen 2016) ◦ Finding elements of birdsong (Koumura, and Okanoya 2016)
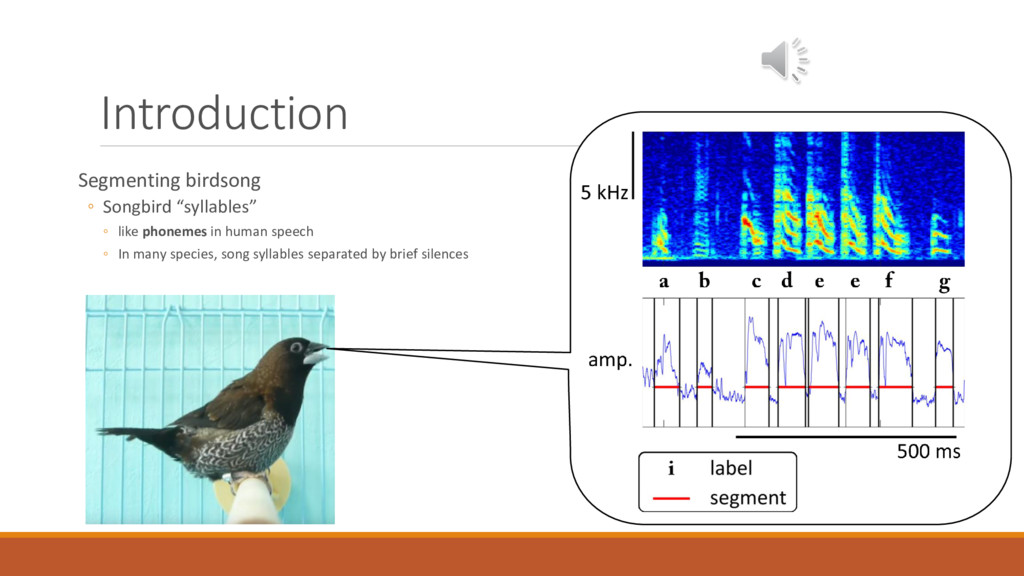
learns speech and similar motor skills ◦ learn their vocalizations by social interaction, from a tutor http://songbirdscience.com/ Photo: Jon Sakata. Spectrogram: Dooling lab
much as phonemes and syntax vary between languages ◦ Allows us to test how well models generalize across different “languages” Zebra finch: 1 Sec Canaries: 1 Sec
classify segments* ◦ But fail when: ◦ Segmenting fails due to ◦ Noise ◦ Change in song because of experiment ◦ Bird has a song that is not easily segmented ◦ Canary song *hybrid-vocal-classifier.readthedocs.io
classify segments* ◦ But fail when: ◦ Segmenting fails due to ◦ Noise ◦ Change in song because of experiment ◦ Bird has a song that is not easily segmented ◦ Canary song The solution? Neural networks, of course *hybrid-vocal-classifier.readthedocs.io
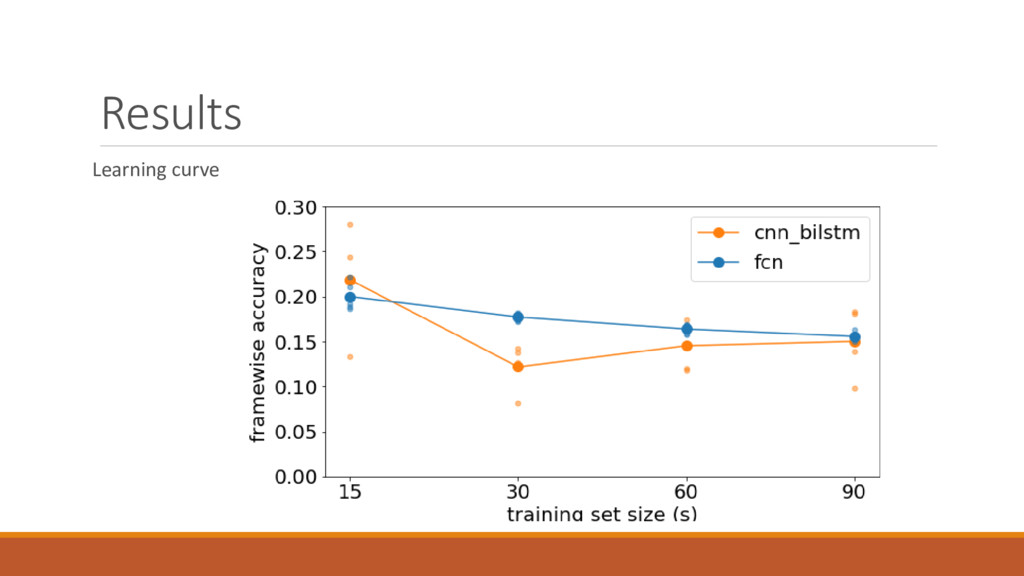
of increasing size ◦ What’s the best we can do with the least amount of data ◦ Replicate for each size with random grab of song files ◦ Measures: accuracy ◦ Framewise accuracy
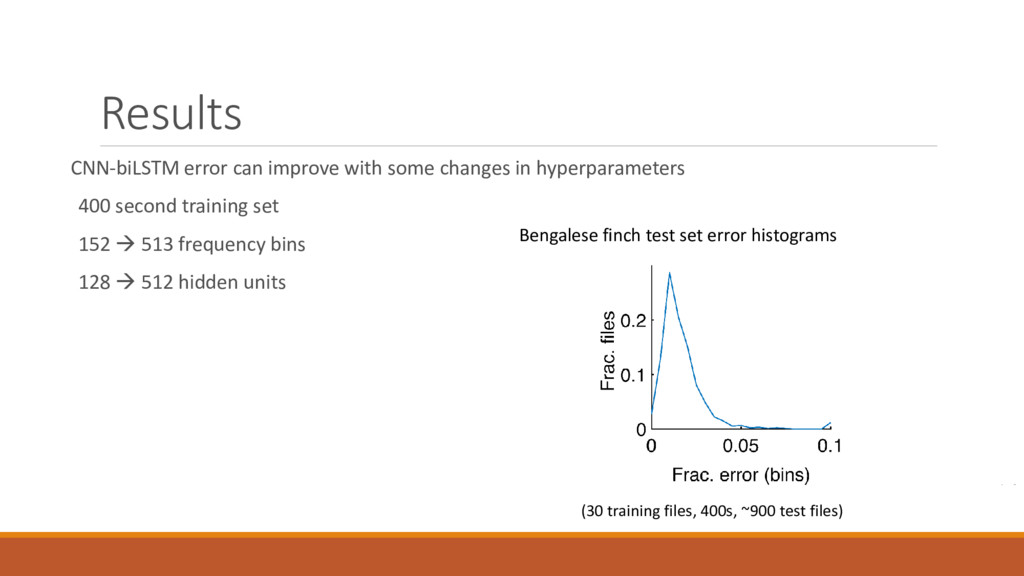
400 second training set 152 513 frequency bins 128 512 hidden units Bengalese finch test set error histograms (30 training files, 400s, ~900 test files)
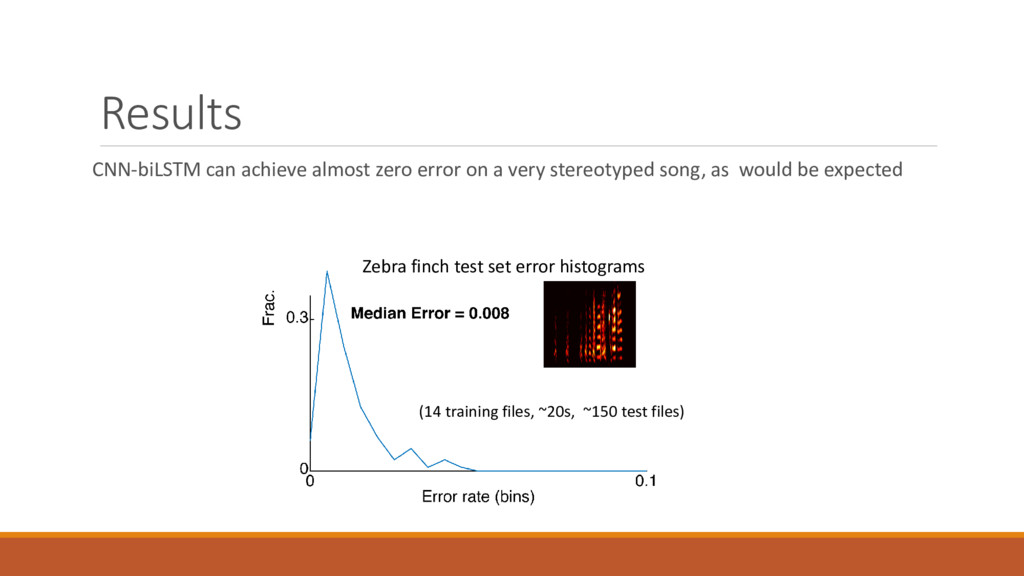
of CNN-biLSTM can improve further by changing hyperparameters CNN-biLSTM performs near perfect when segmenting syllables from a species with a very stereotyped song
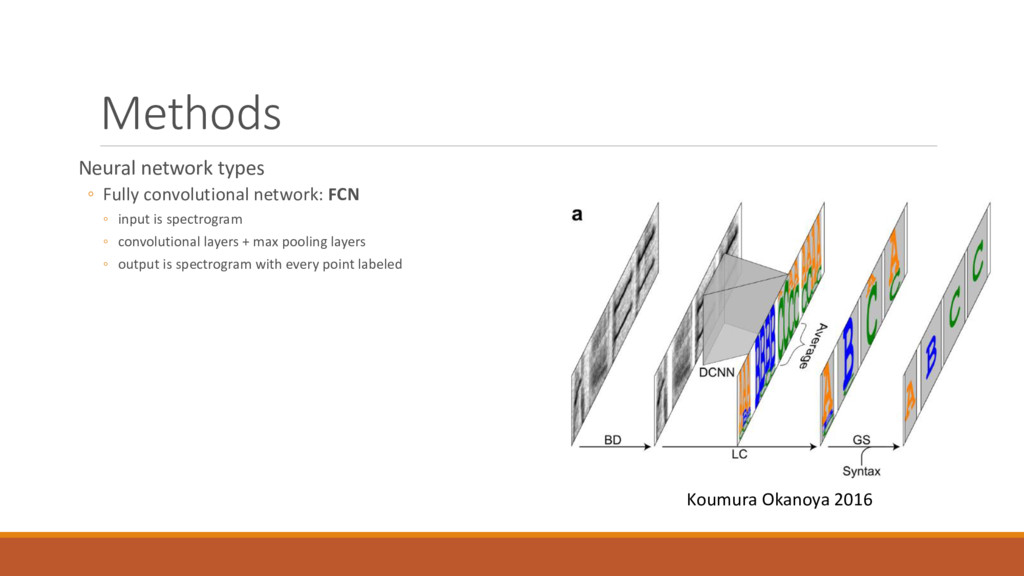
Consider other architectures developed ◦ “sliding window” convolutional network ◦ Koumura Okanoya 2016: https://github.com/cycentum/birdsong-recognition ◦ similar architecture in Keras: https://github.com/kylerbrown/deepchirp ◦ Applications ◦ Automated segmentation of song ◦ Speech disorder diagnosis, improved ASR
sources ◦ NIH ◦ NSF ◦ NVIDIA GPU grant program Fork us on Github https://github.com/yardencsGitHub/tf_syllable_segmentation_annotation https://github.com/NickleDave/tf_syllable_segmentation_annotation https://github.com/NickleDave/fcn-syl-seg
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}