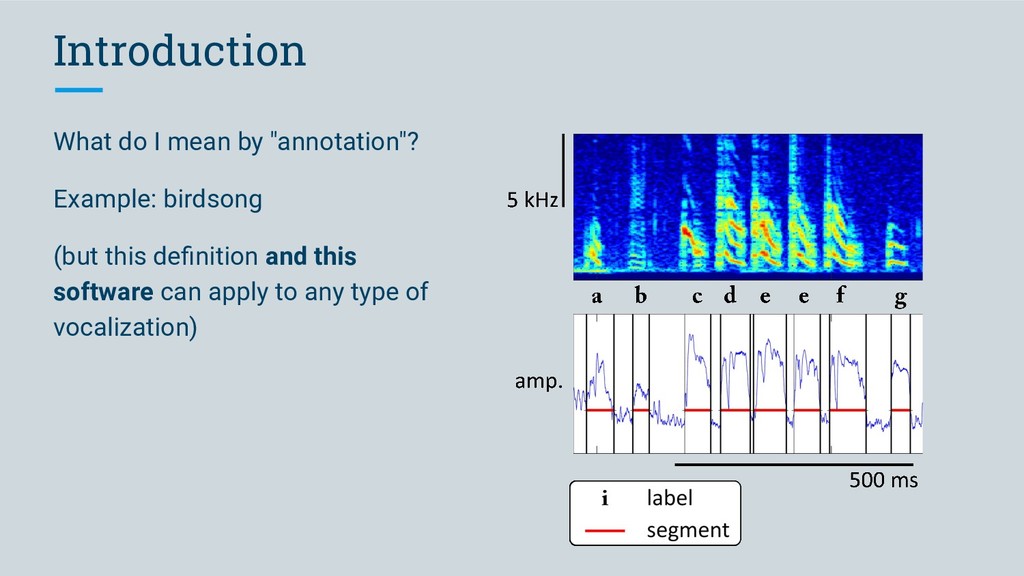
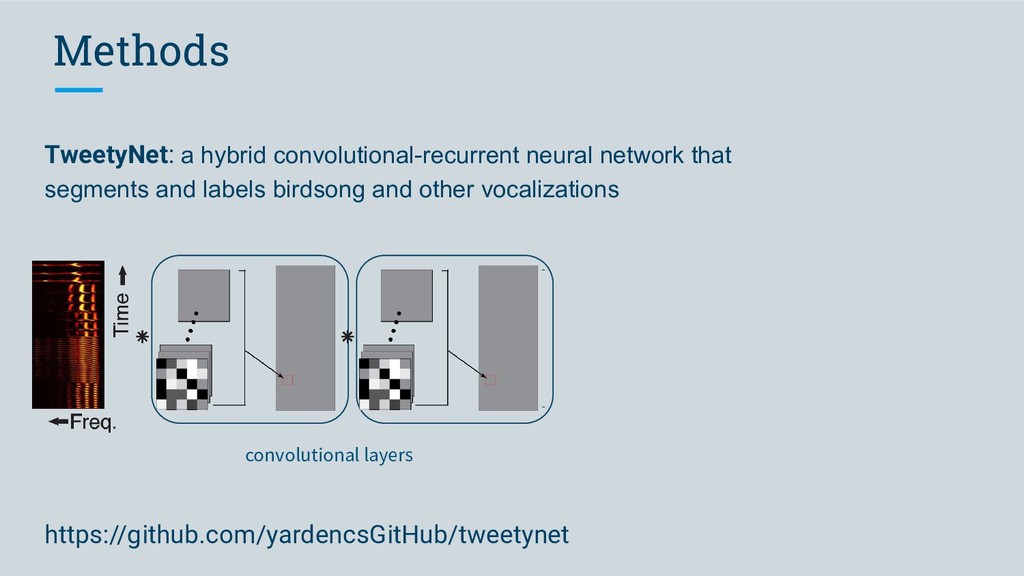
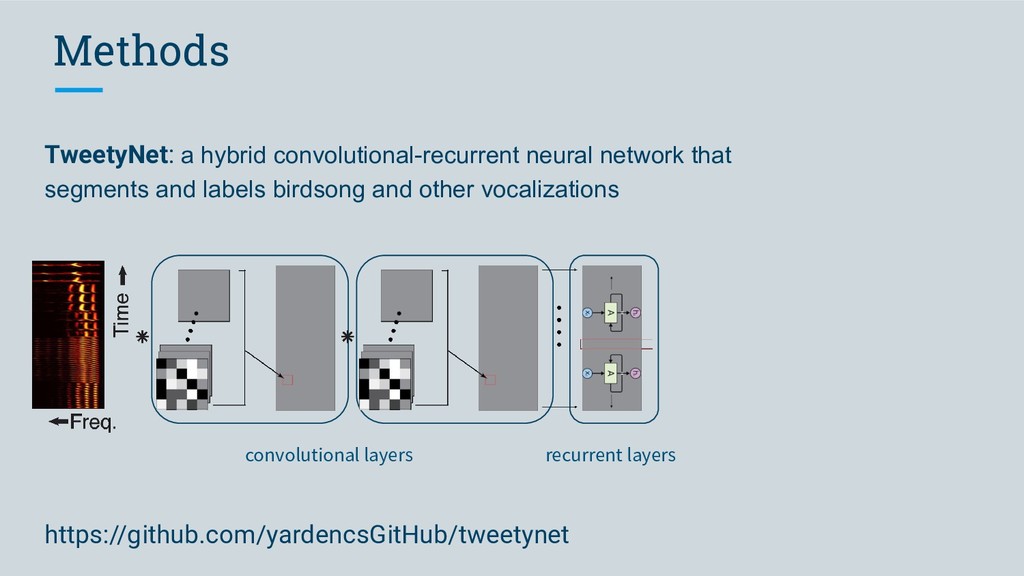
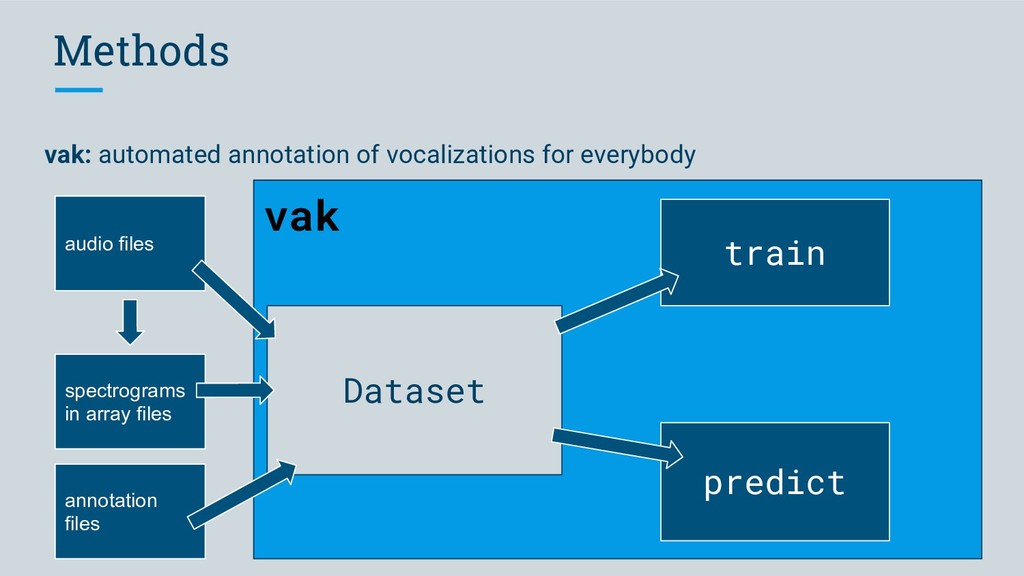
Software we developed to meet this criterion • segment audio into vocalizations • predict labels for segments TweetyNet (neural network) • make it easy for anyone to use vak (library)
Software we developed to meet this criterion • segment audio into vocalizations • predict labels for segments TweetyNet (neural network) • make it easy for anyone to use vak (library) • work with many different data formats vak, crowsetta (libraries)
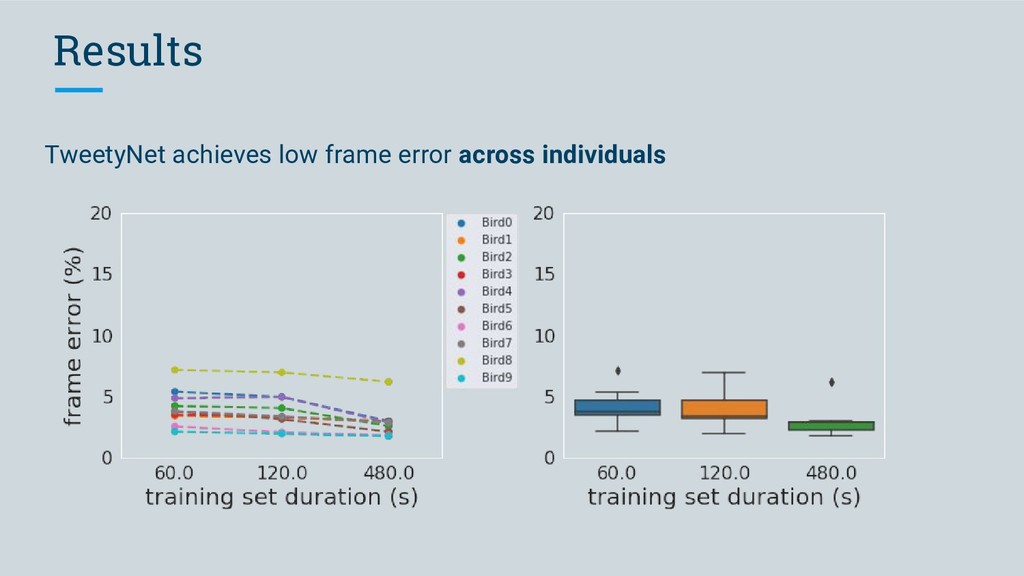
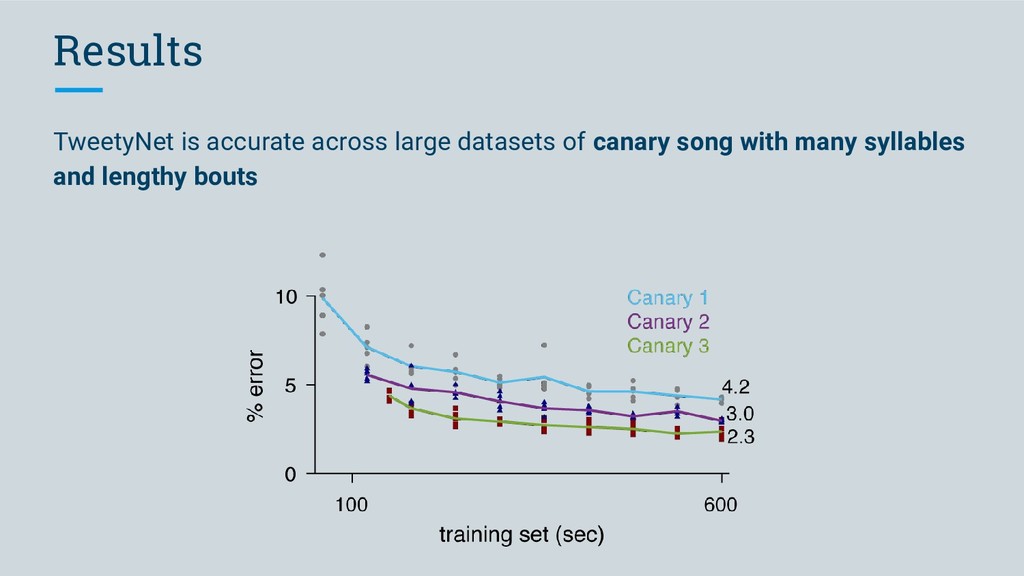
Bengalese Finch song ◦ compare error with previously published hybrid HMM-neural network model 2. apply our software to canary song (lengthy bouts, large vocabulary of song syllables) ◦ currently no automated annotation methods available
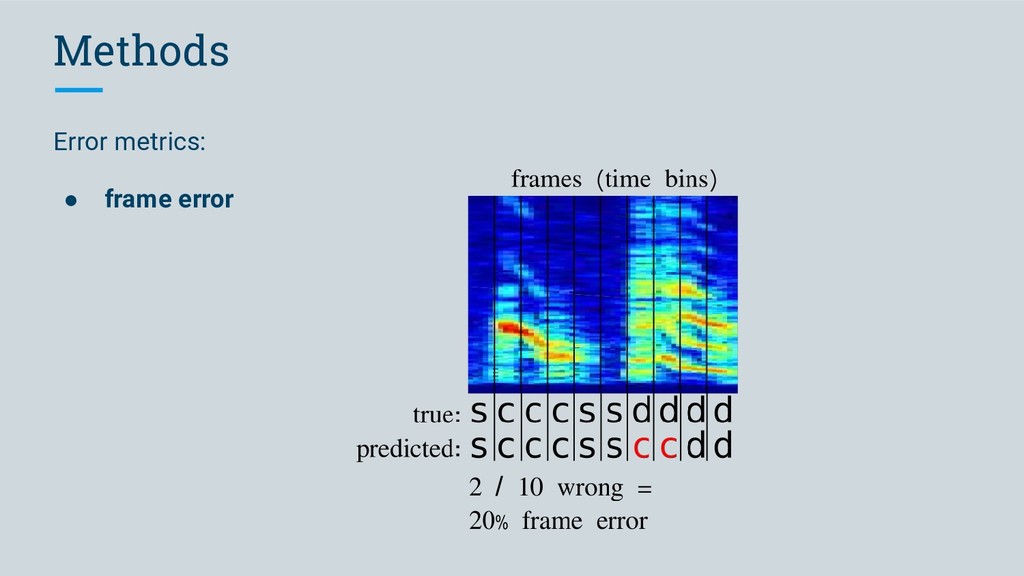
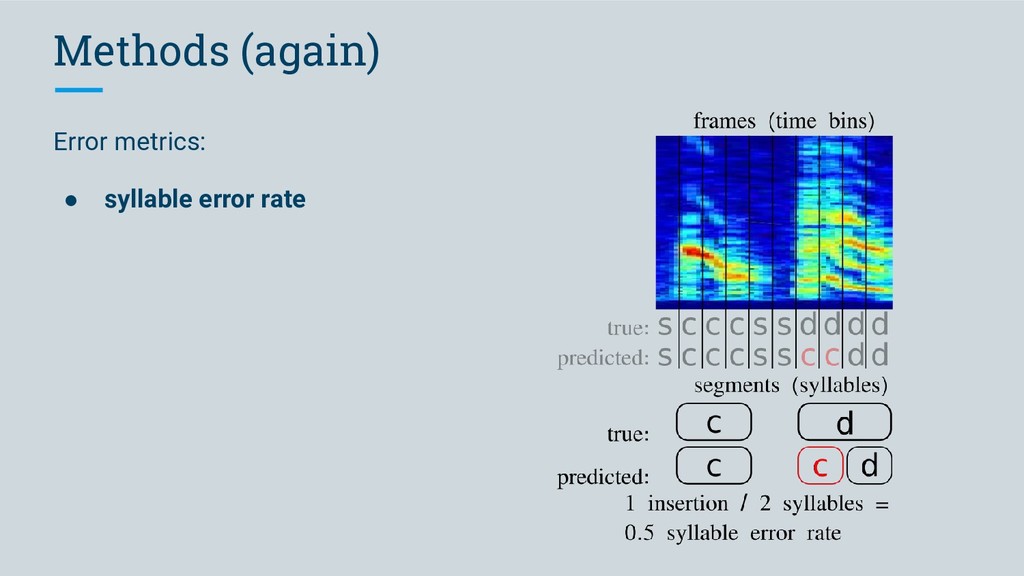
to word error rate used in speech recognition / speech-to-text ◦ an edit distance: how many edits do I have to make to the predicted sequence to recover the true sequence?
to word error rate used in speech recognition / speech-to-text ◦ an edit distance: how many edits do I have to make to the predictioned sequence to recover the true sequence? https://medium.com/descript/challenges-in-measuring-automatic-transcription-accuracy-f322bf5994f
to word error rate used in speech recognition / speech-to-text ◦ an edit distance: how many edits do I have to make to the predictioned sequence to recover the true sequence? https://medium.com/descript/challenges-in-measuring-automatic-transcription-accuracy-f322bf5994f
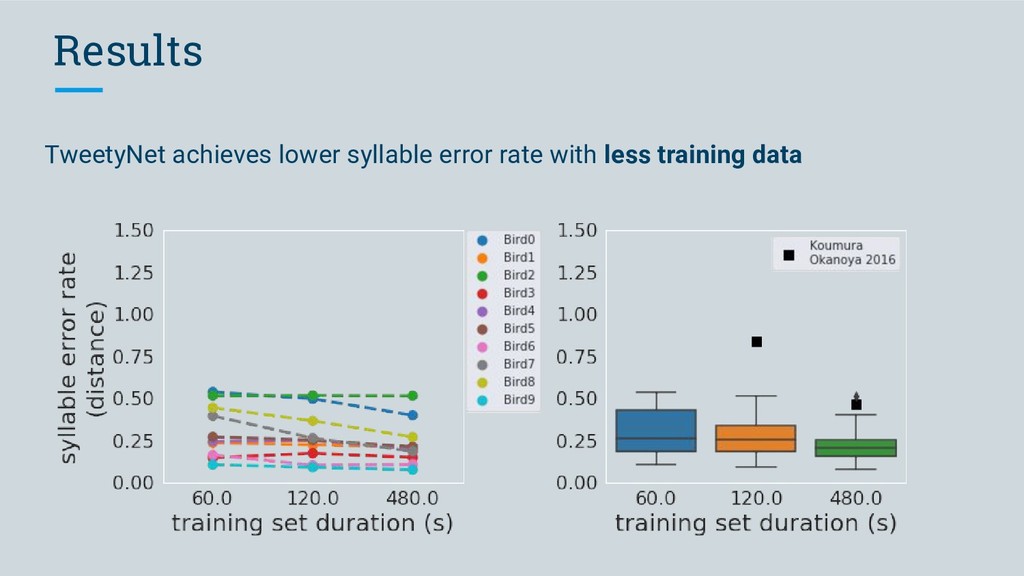
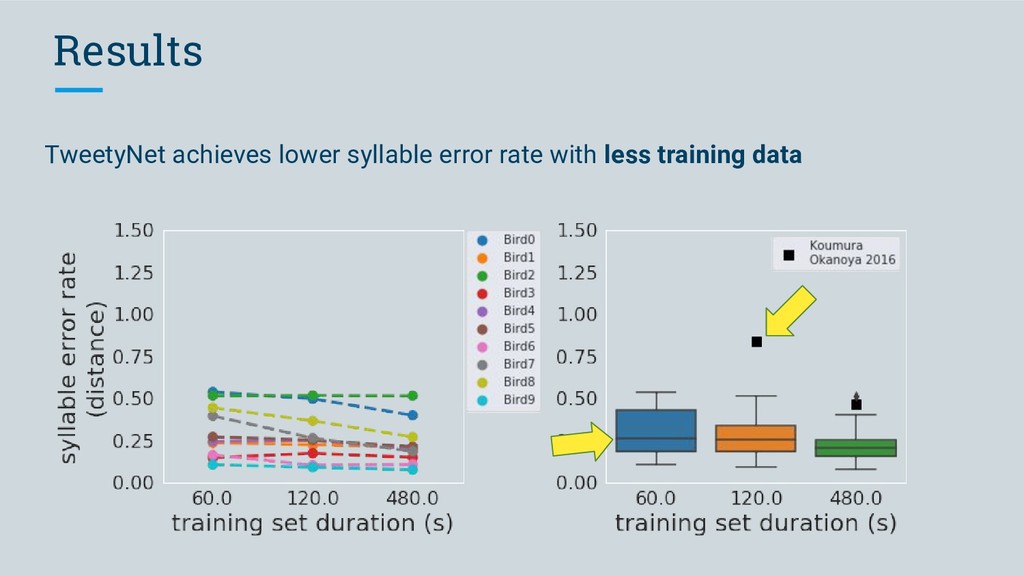
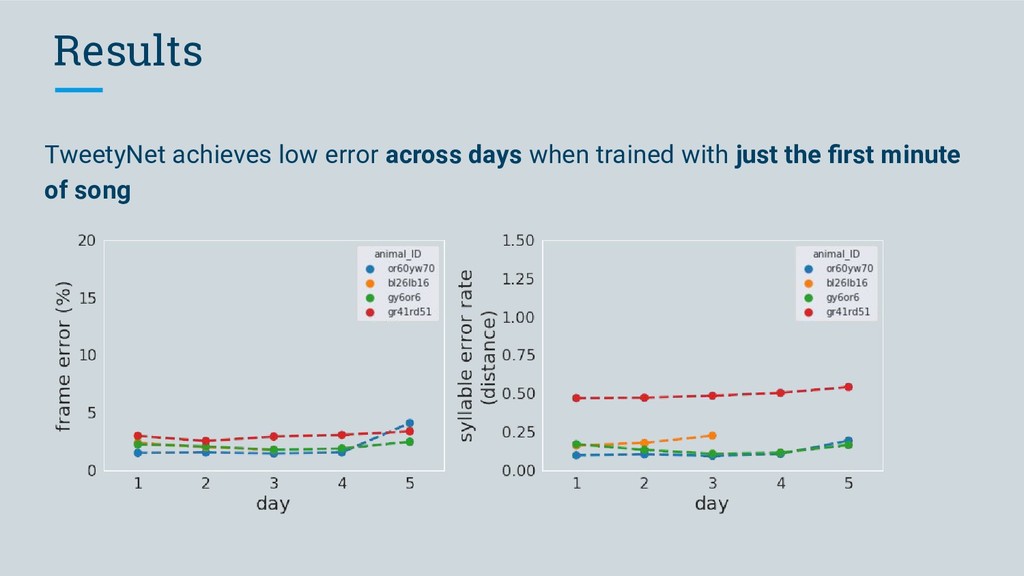
◦ achieves low frame error across individual Bengalese finches ◦ achieves a lower syllable error rate with les data than a previously proposed model ◦ can for the first time automate annotation of Bengalese • Our vision for vak is: ◦ an open-source, community-developed tool ◦ that will enable researchers studying vocalizations to perform high-throughput automated annotation ◦ using neural networks, without needing detailed knowledge of machine learning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}