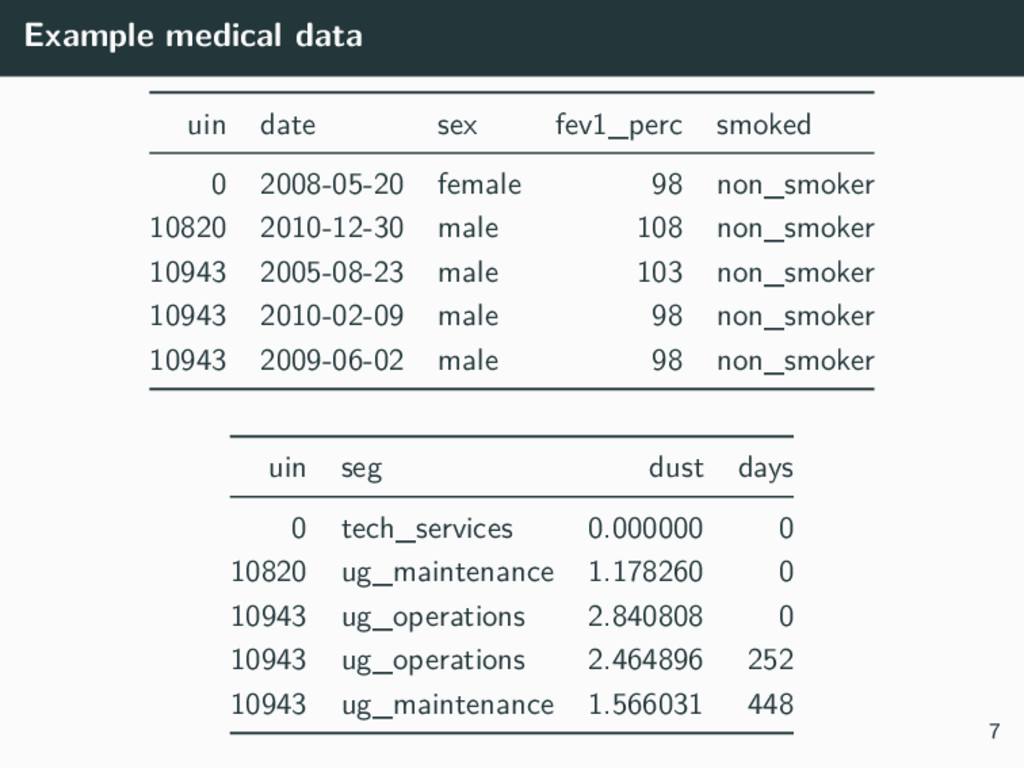
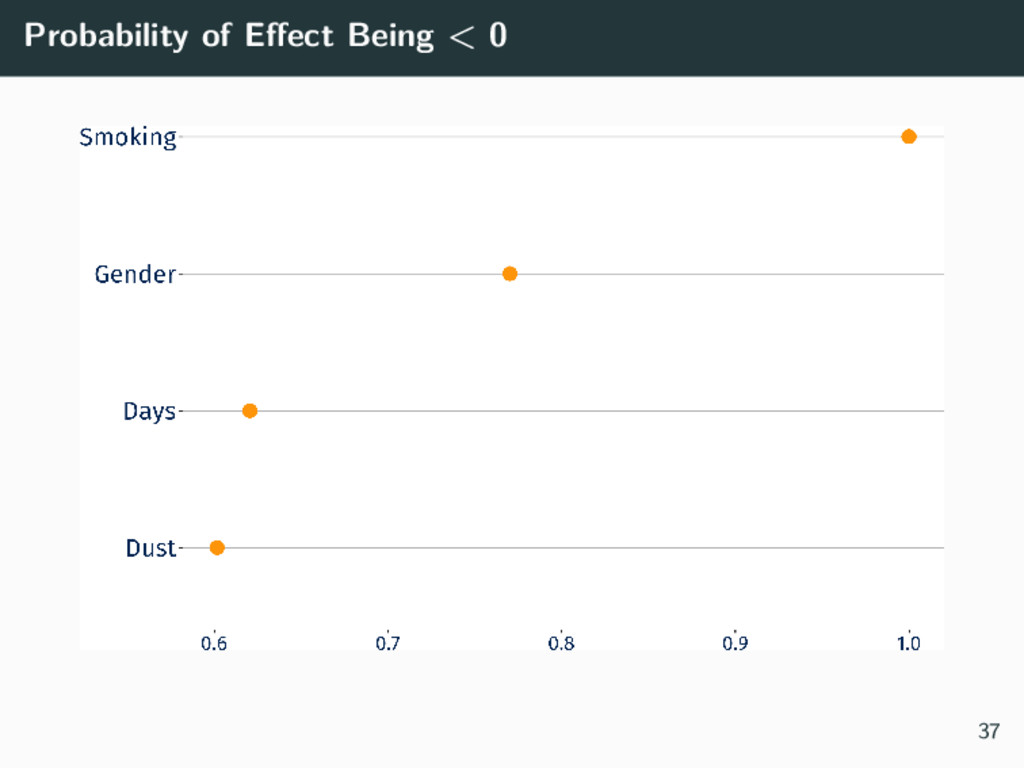
Working with real world data is often difficult and almost always messy. This talk discusses a real world research project under a new PhD scheme, the Industry Doctoral Training Centre (IDTC). The IDTC is a new program in Australia where PhD students work with an industry partner, and the research problem may have its roots in industry, rather than academia and theory. In this research project, Nicholas Tierney works with Hunter Industrial Medicine, a firm of occupational physicians who help monitor the health of employees in various industries such as mining, police, fire and rescue, and construction. This process of monitoring health is known as Occupational Health Surveillance (OHS), the systematic collection, analysis, and dissemination of employee environmental exposure and health data to facilitate early detection of disease and dangerous exposures in the workplace. Presently, analyses in OHS often ignore repeated measurements, missing data, and workplace structures, resulting in limited predictive performance and poor inference. This work aims to improve OHS models by applying Bayesian methods and machine learning techniques to help create occupational health risk profiles.
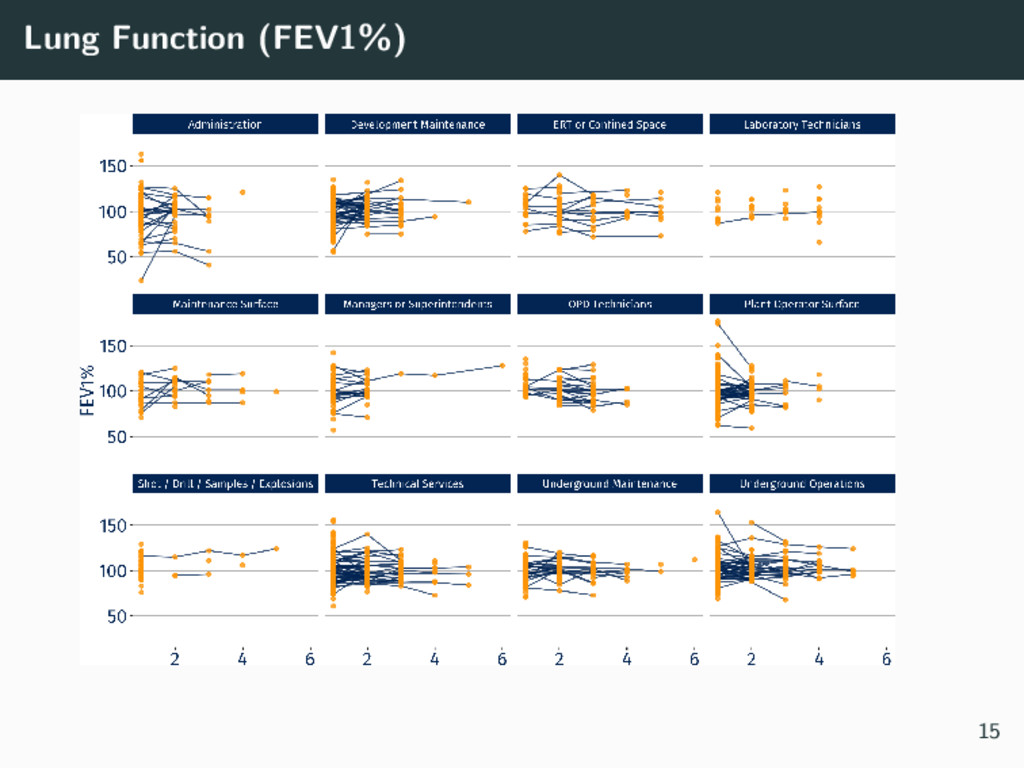
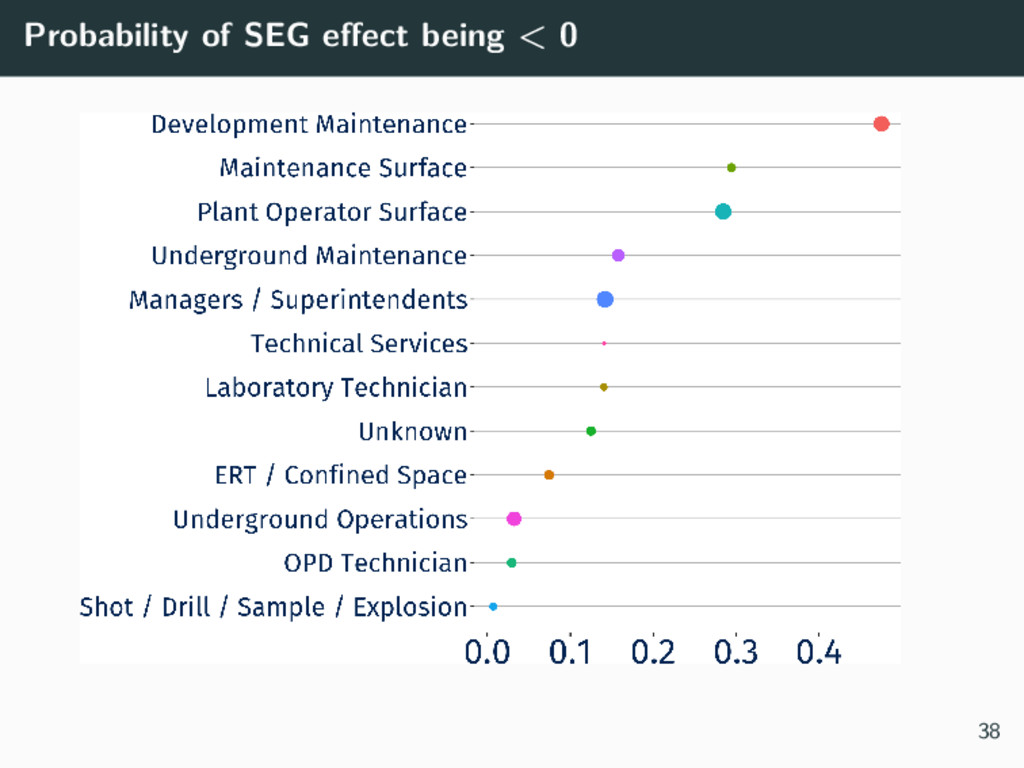
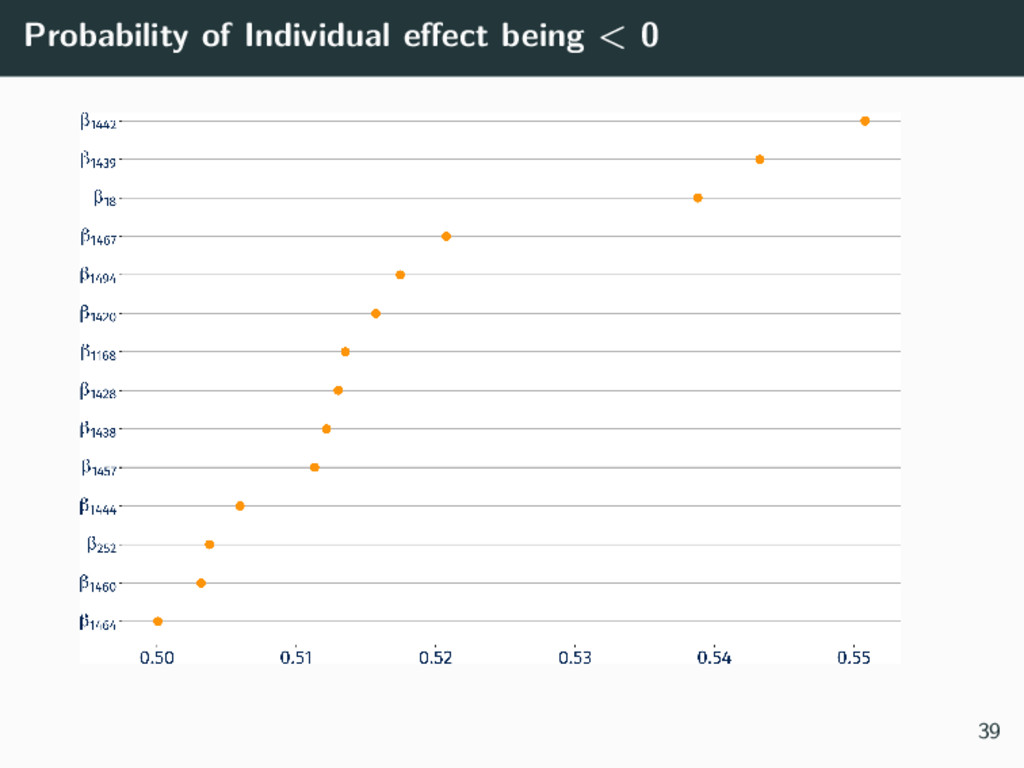
We consider a case study dataset from a mining site in Australia, which contains employee medical history and environmental exposures. Each employee may have multiple visits, and is within a Similar Exposure Group (SEG) based on their occupation (e.g., administration is in a different SEG to underground technician). We discuss the results so far in this work, plans for future analyses, and the lessons we have learnt from working with an industry partner and a real live dataset.
This project has been made available through partnership with Hunter Industrial Medicine, and is sponsored by the Industry Doctoral Training Centre, the Australian Centre of Excellence for Mathematical and Statistical Frontiers, and the Queensland University of Technology.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
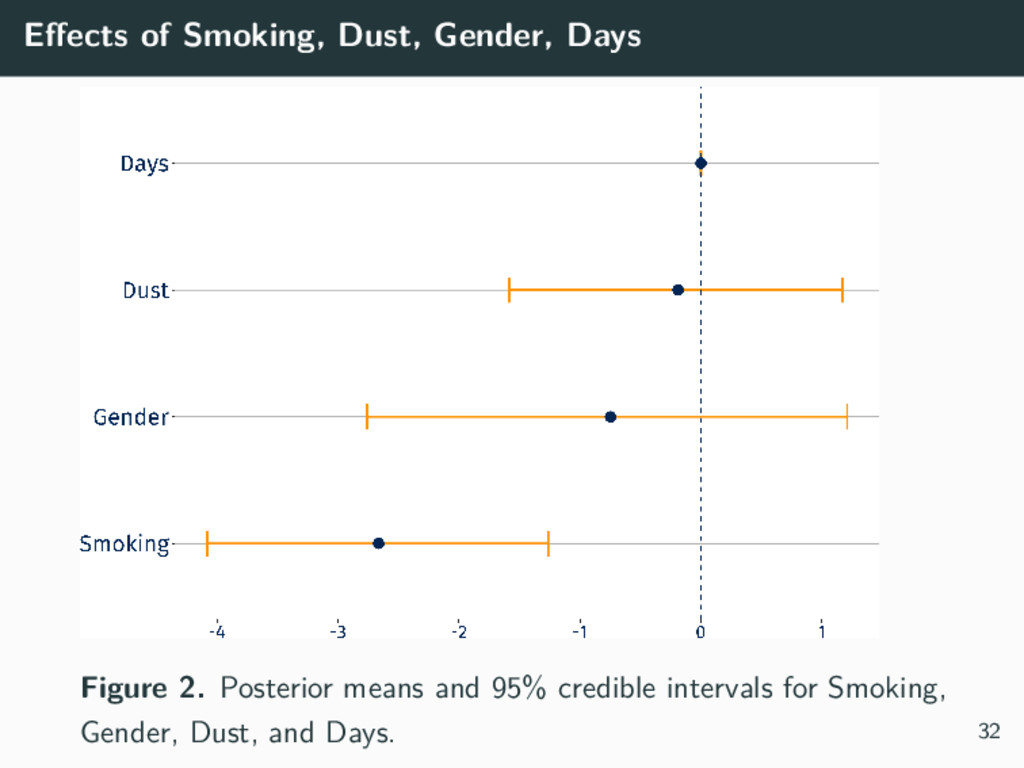{kind=link}
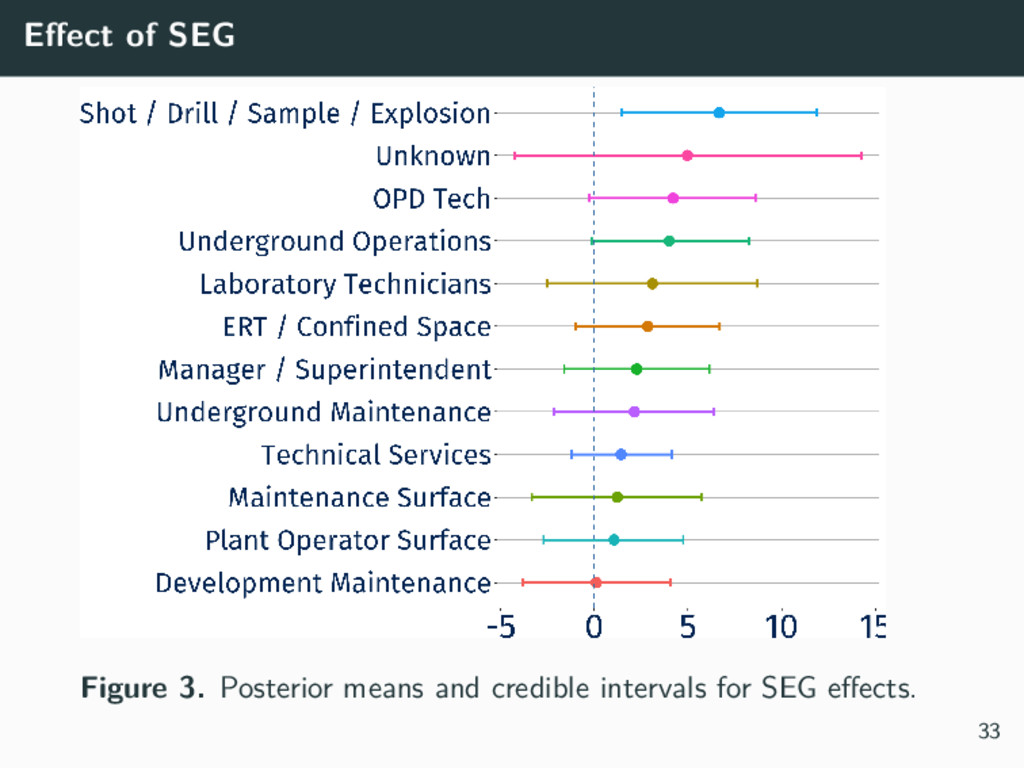{kind=link}
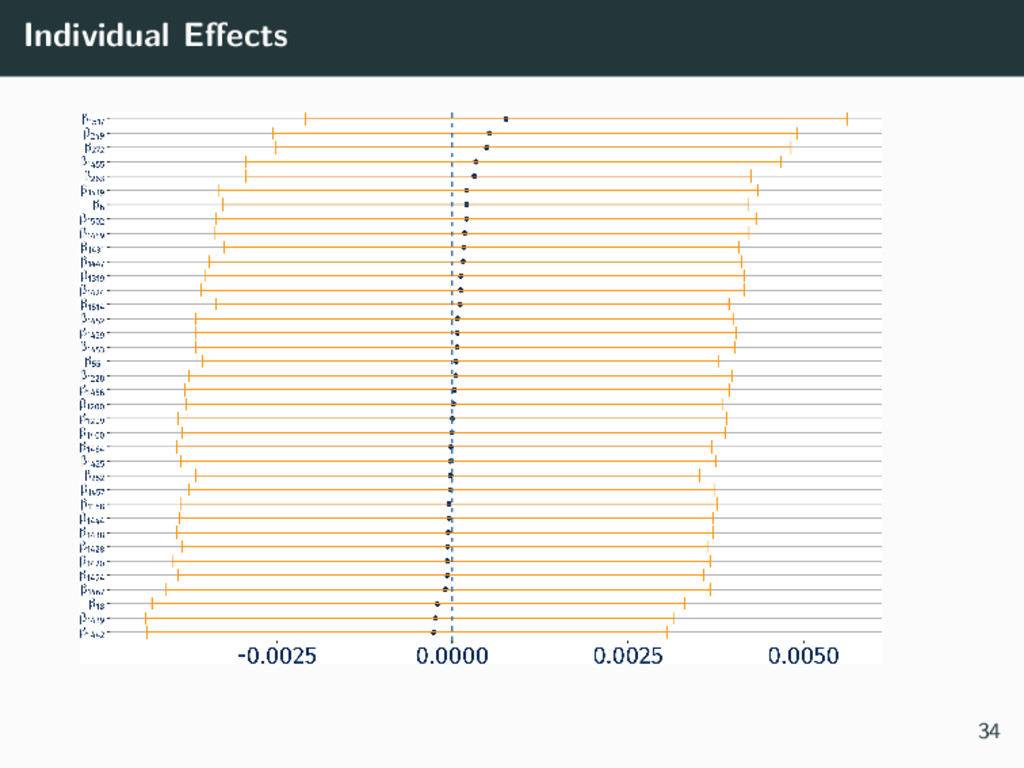{kind=link}
{kind=link}
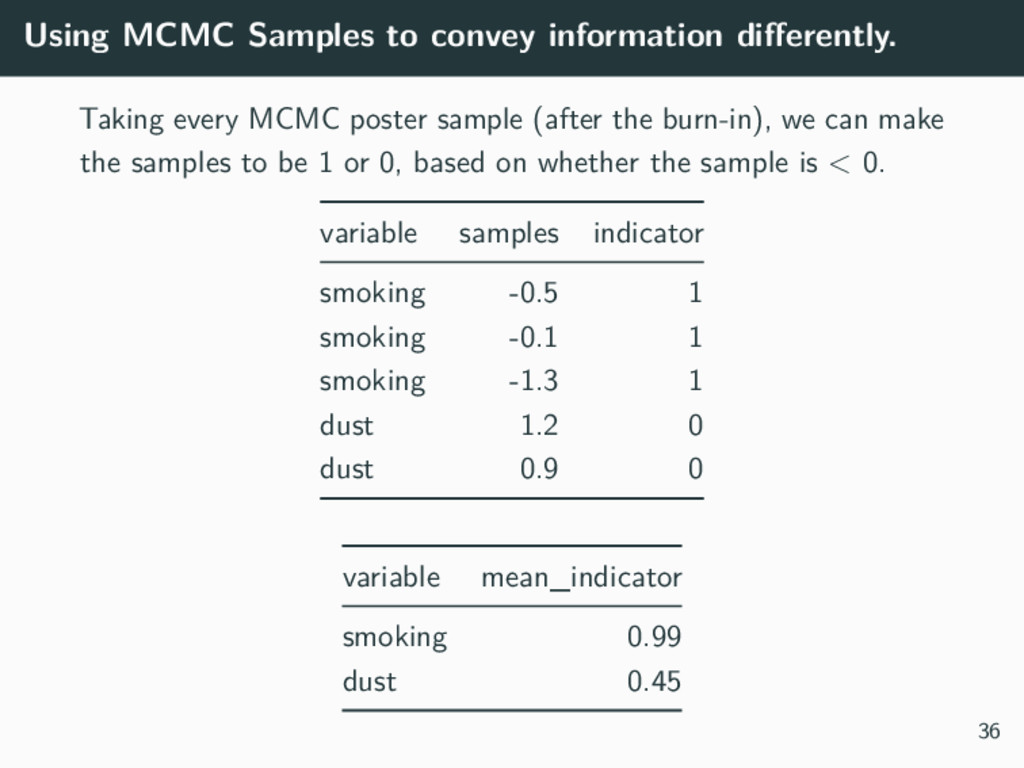{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contact Email: [email protected] Website: www.njtierney.com Twitter: nj_tierney Github: njtierney 49](https://files.speakerdeck.com/presentations/4db7284c2e3f4c8fba8f045db2696b23/slide_48.jpg){kind=link}