With access to data becoming easier, and the emergence of Big Data, situations arise where researchers may not easily understand the context in which the data was measured, collected, and collated. Consequentially, researchers may find themselves confused as to what they should do with an ‘unusable’ dataset containing a high number of missing values. Although multiple imputation (MI) methods can provide accurate prediction of missing values, they are not always the answer to a researcher’s missing data problem, and rely heavily on the researcher having a complete understanding of how data were generated. We demonstrate a method for approaching missing data when using linked health data, and propose a set of steps that could be generalised to applied research.
{kind=link}
{kind=link}
{kind=link}
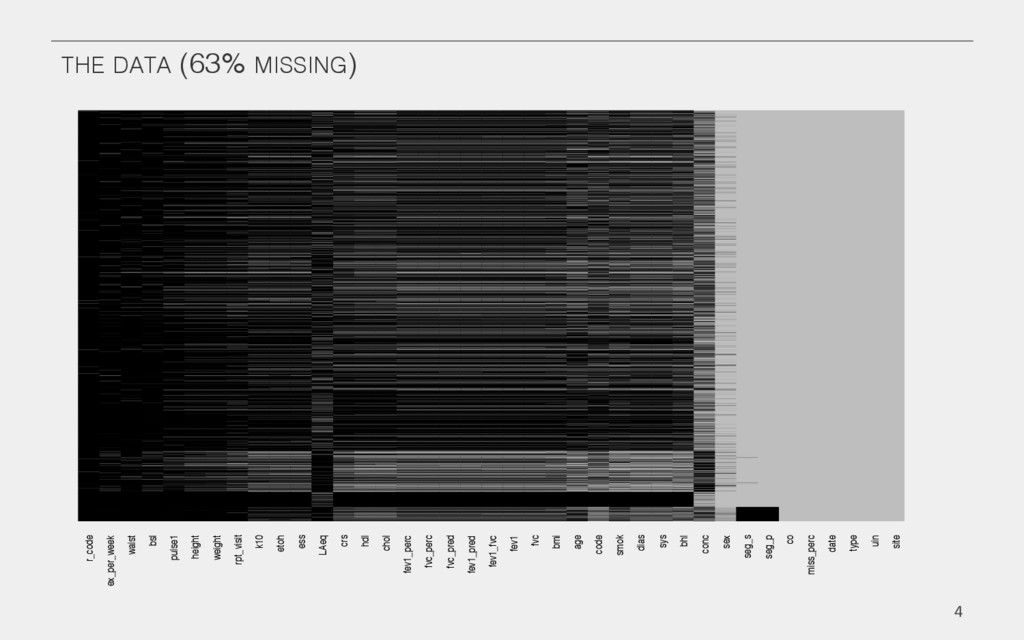{kind=link}
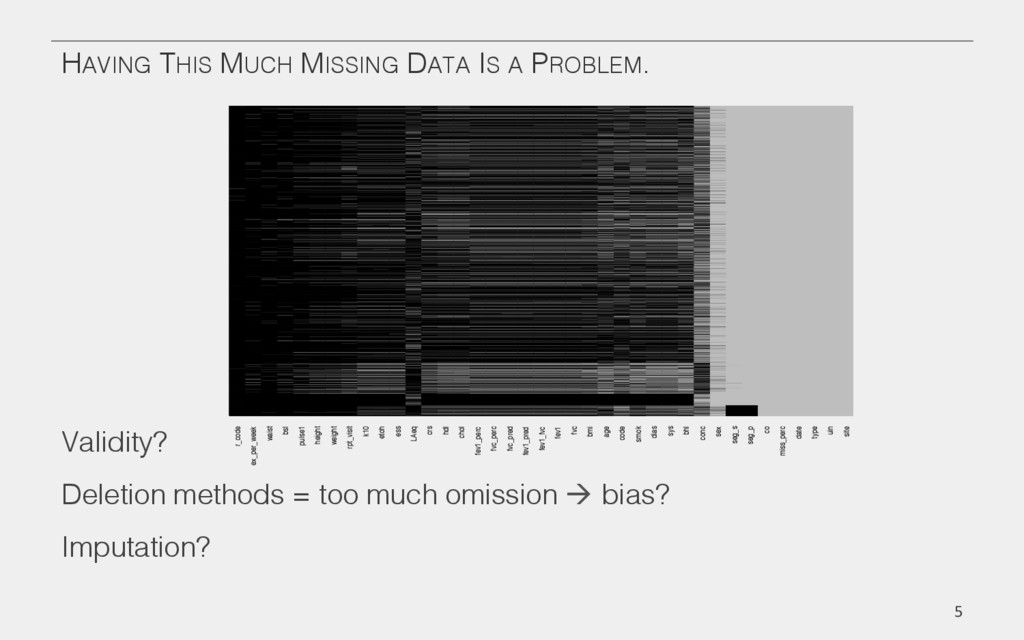{kind=link}
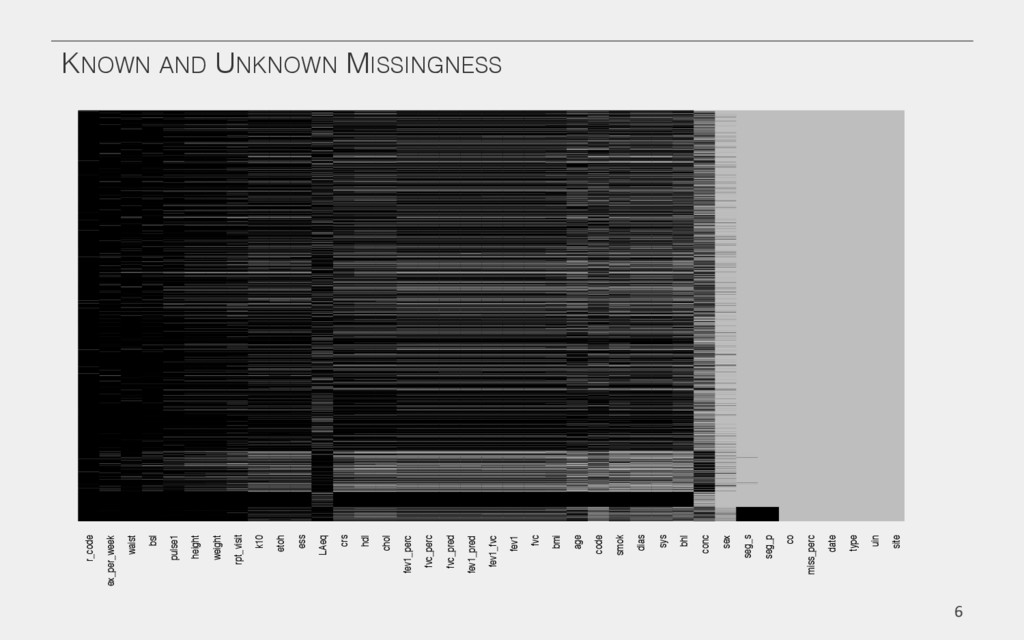{kind=link}
{kind=link}
{kind=link}
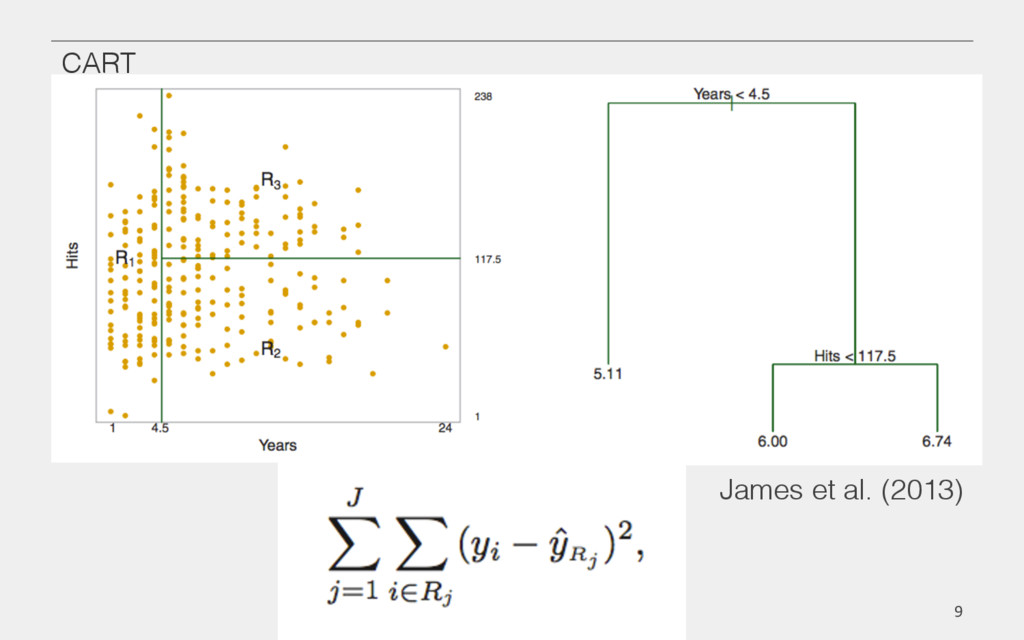{kind=link}
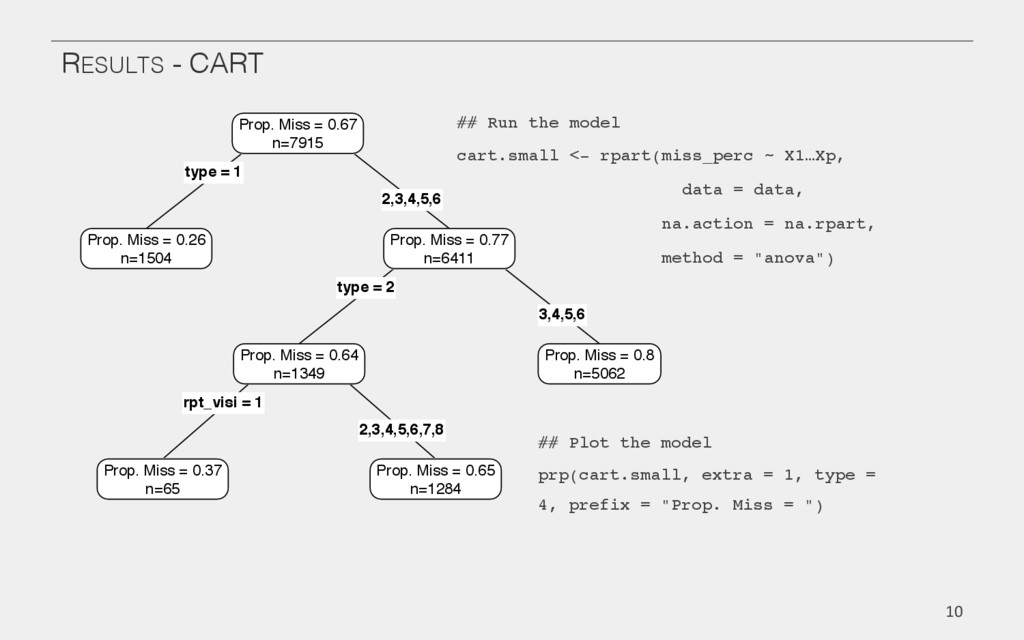{kind=link}
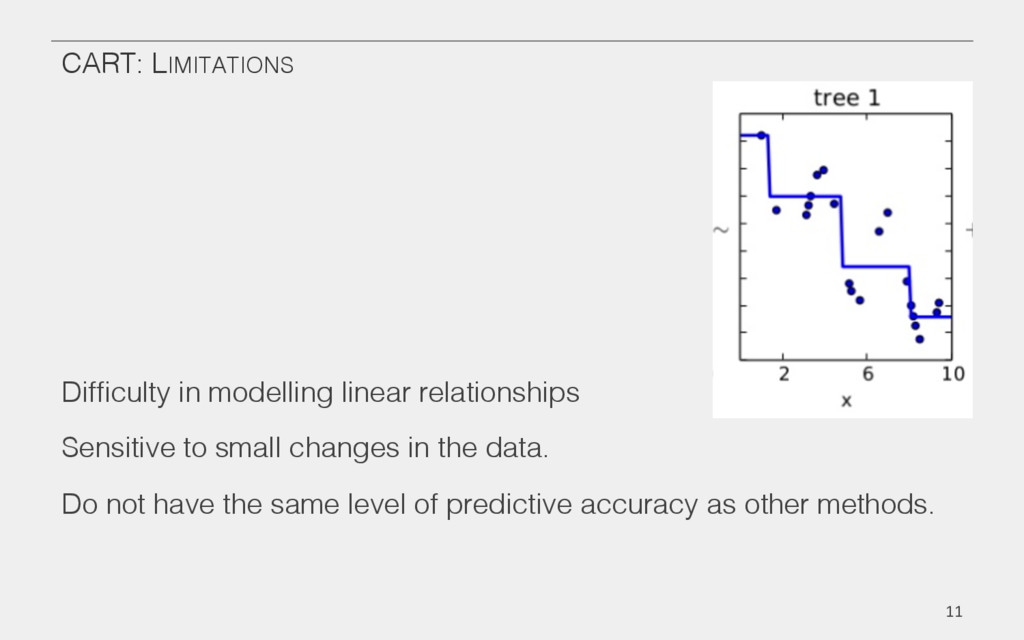{kind=link}
{kind=link}
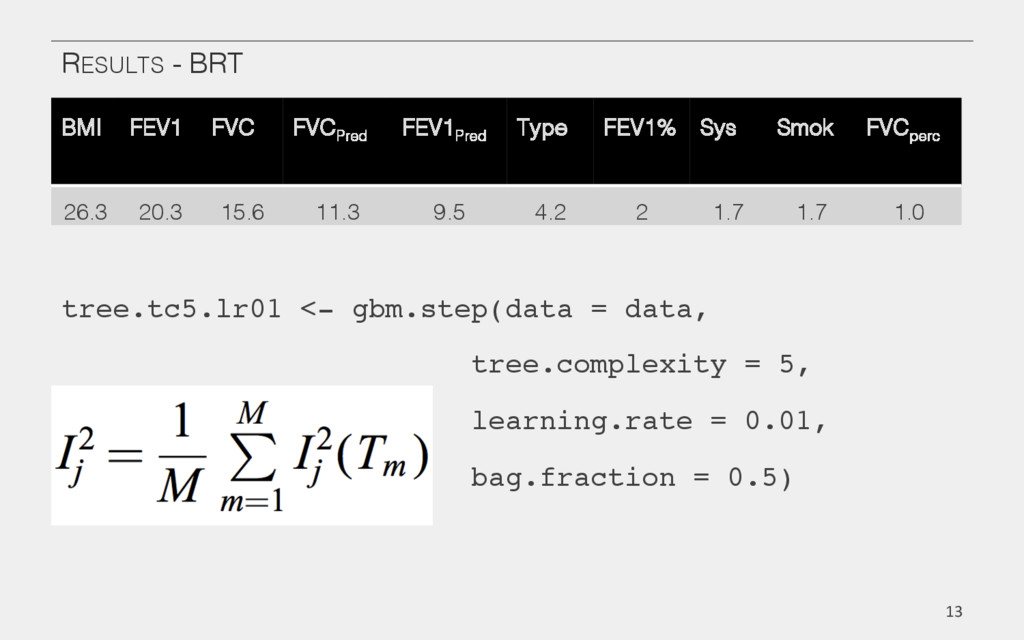{kind=link}
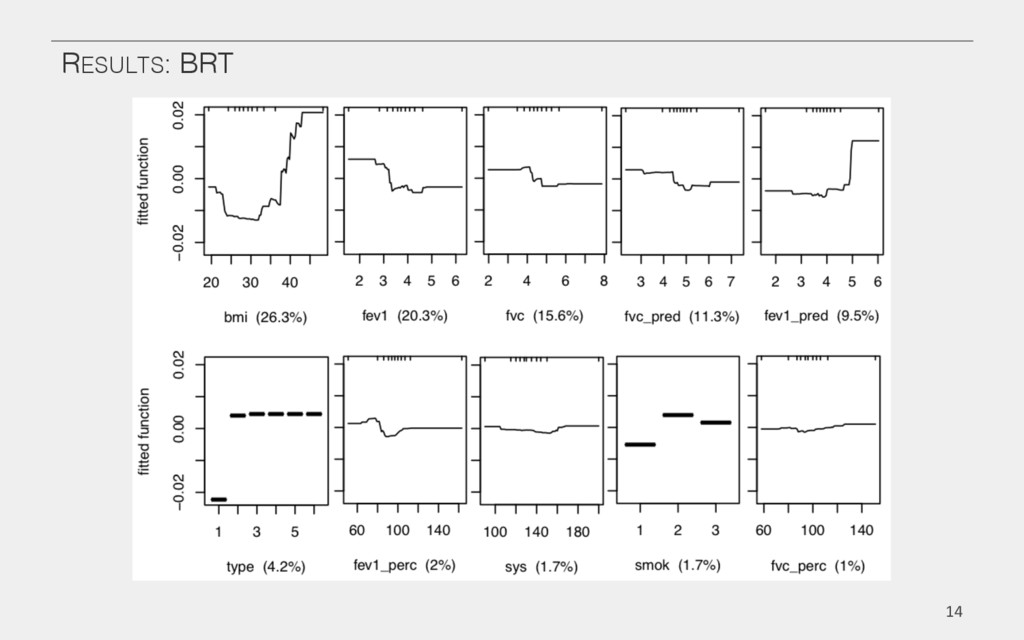{kind=link}
{kind=link}
{kind=link}
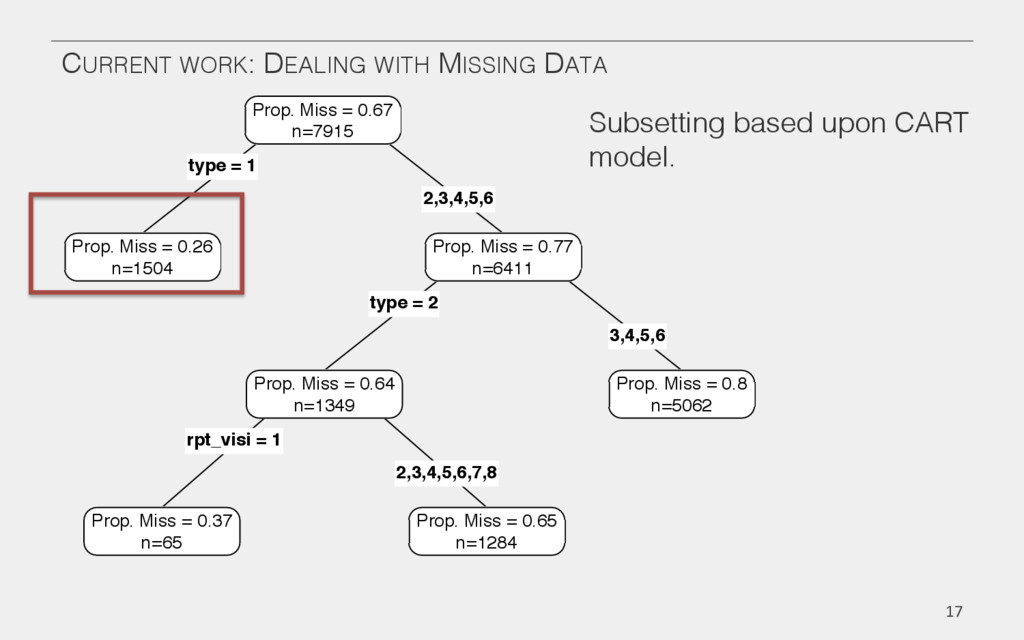{kind=link}
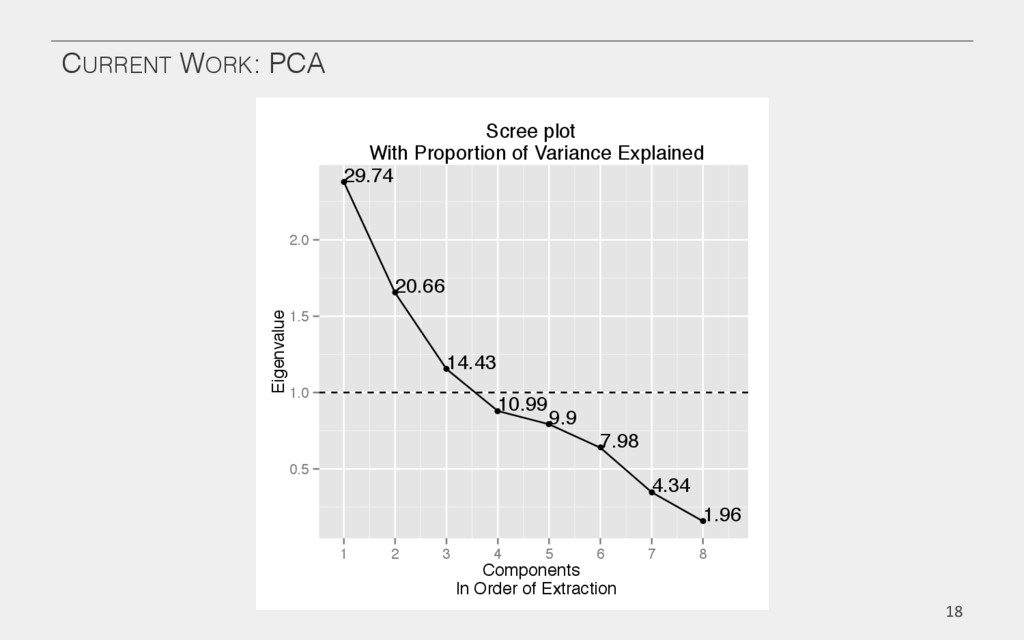{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
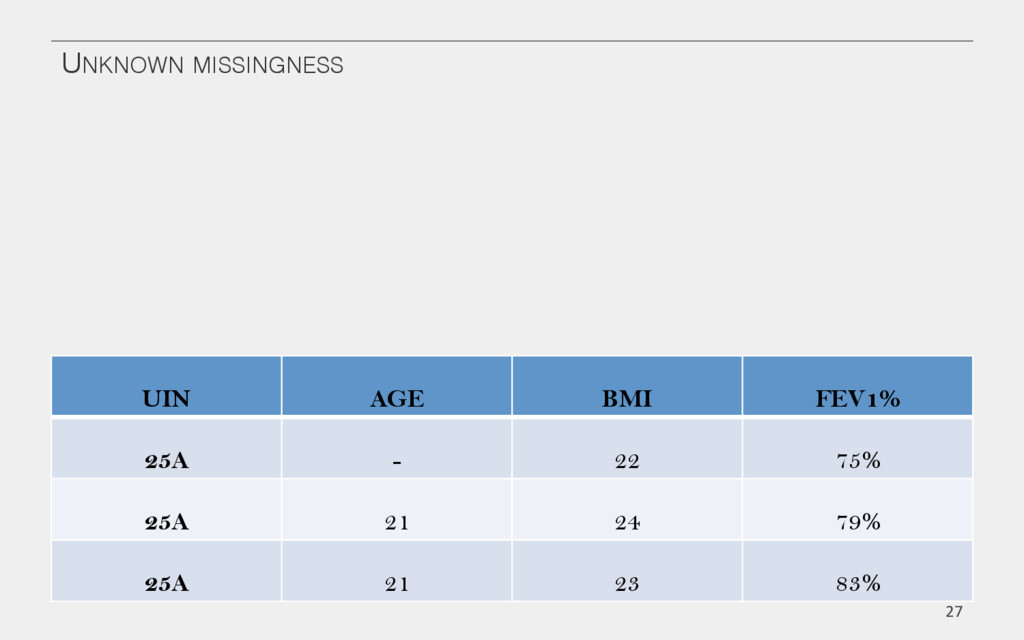{kind=link}
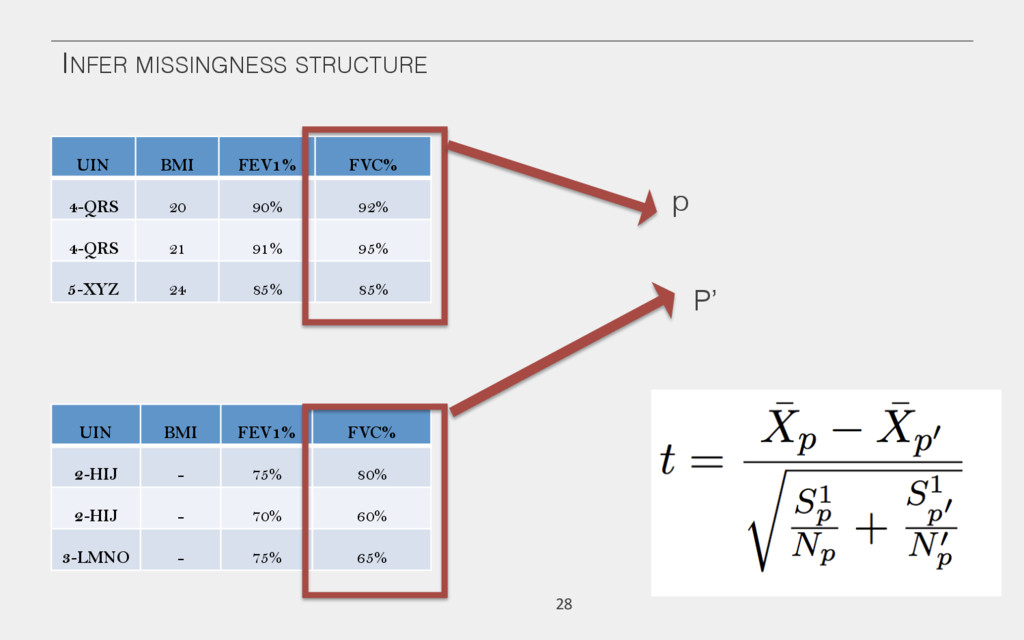{kind=link}
{kind=link}
{kind=link}