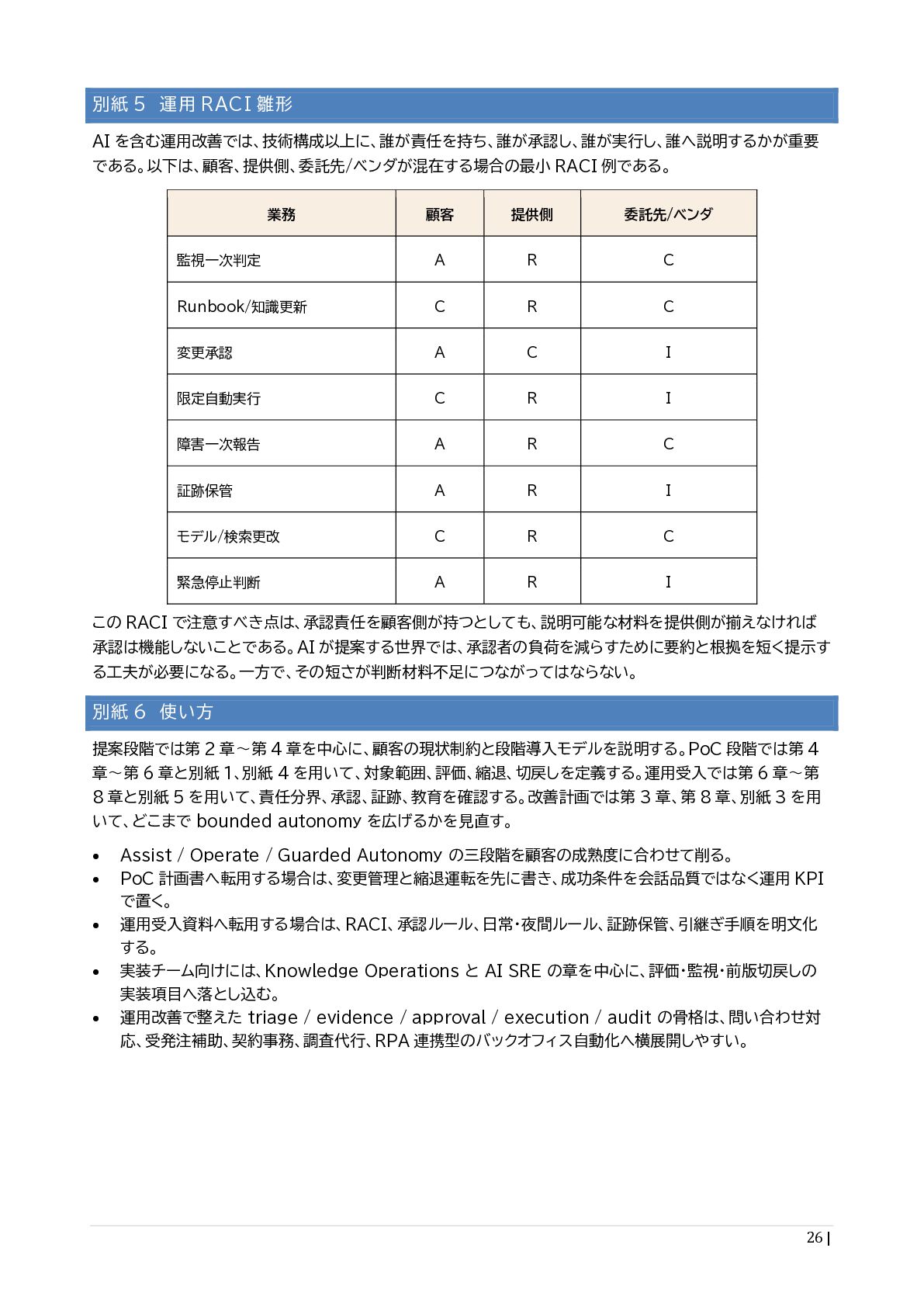
RACI 例である。 業務 顧客 提供側 委託先/ベンダ 監視一次判定 A R C Runbook/知識更新 C R C 変更承認 A C I 限定自動実行 C R I 障害一次報告 A R C 証跡保管 A R I モデル/検索更改 C R C 緊急停止判断 A R I この RACI で注意すべき点は、承認責任を顧客側が持つとしても、説明可能な材料を提供側が揃えなければ 承認は機能しないことである。AI が提案する世界では、承認者の負荷を減らすために要約と根拠を短く提示す る工夫が必要になる。一方で、その短さが判断材料不足につながってはならない。 別紙 6 使い方 提案段階では第 2 章〜第 4 章を中心に、顧客の現状制約と段階導入モデルを説明する。PoC 段階では第 4 章〜第 6 章と別紙 1、別紙 4 を用いて、対象範囲、評価、縮退、切戻しを定義する。運用受入では第 6 章〜第 8 章と別紙 5 を用いて、責任分界、承認、証跡、教育を確認する。改善計画では第 3 章、第 8 章、別紙 3 を用 いて、どこまで bounded autonomy を広げるかを見直す。 • Assist / Operate / Guarded Autonomy の三段階を顧客の成熟度に合わせて削る。 • PoC 計画書へ転用する場合は、変更管理と縮退運転を先に書き、成功条件を会話品質ではなく運用 KPI で置く。 • 運用受入資料へ転用する場合は、RACI、承認ルール、日常・夜間ルール、証跡保管、引継ぎ手順を明文化 する。 • 実装チーム向けには、Knowledge Operations と AI SRE の章を中心に、評価・監視・前版切戻しの 実装項目へ落とし込む。 • 運用改善で整えた triage / evidence / approval / execution / audit の骨格は、問い合わせ対 応、受発注補助、契約事務、調査代行、RPA 連携型のバックオフィス自動化へ横展開しやすい。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
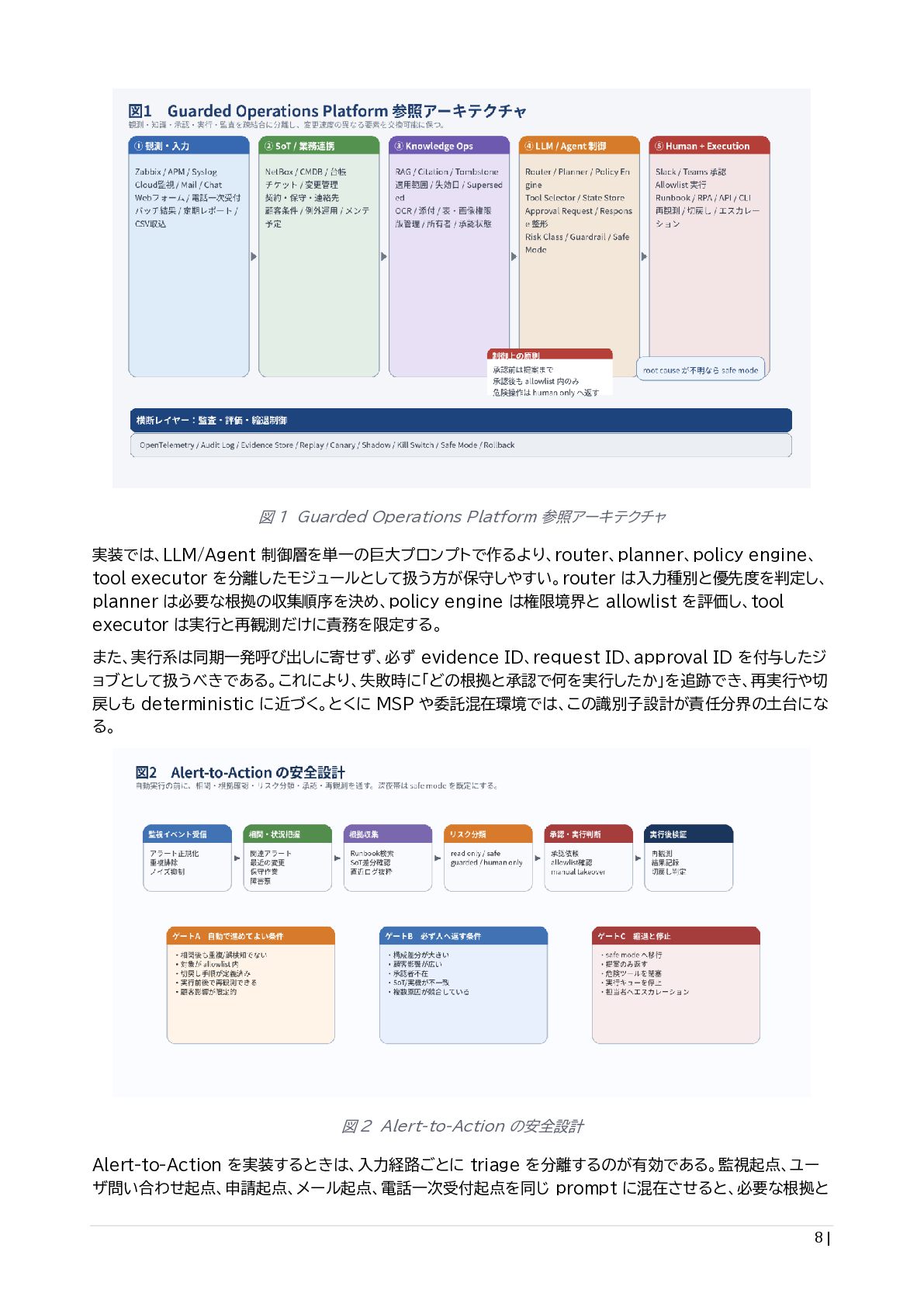{kind=link}
{kind=link}
{kind=link}
{kind=link}
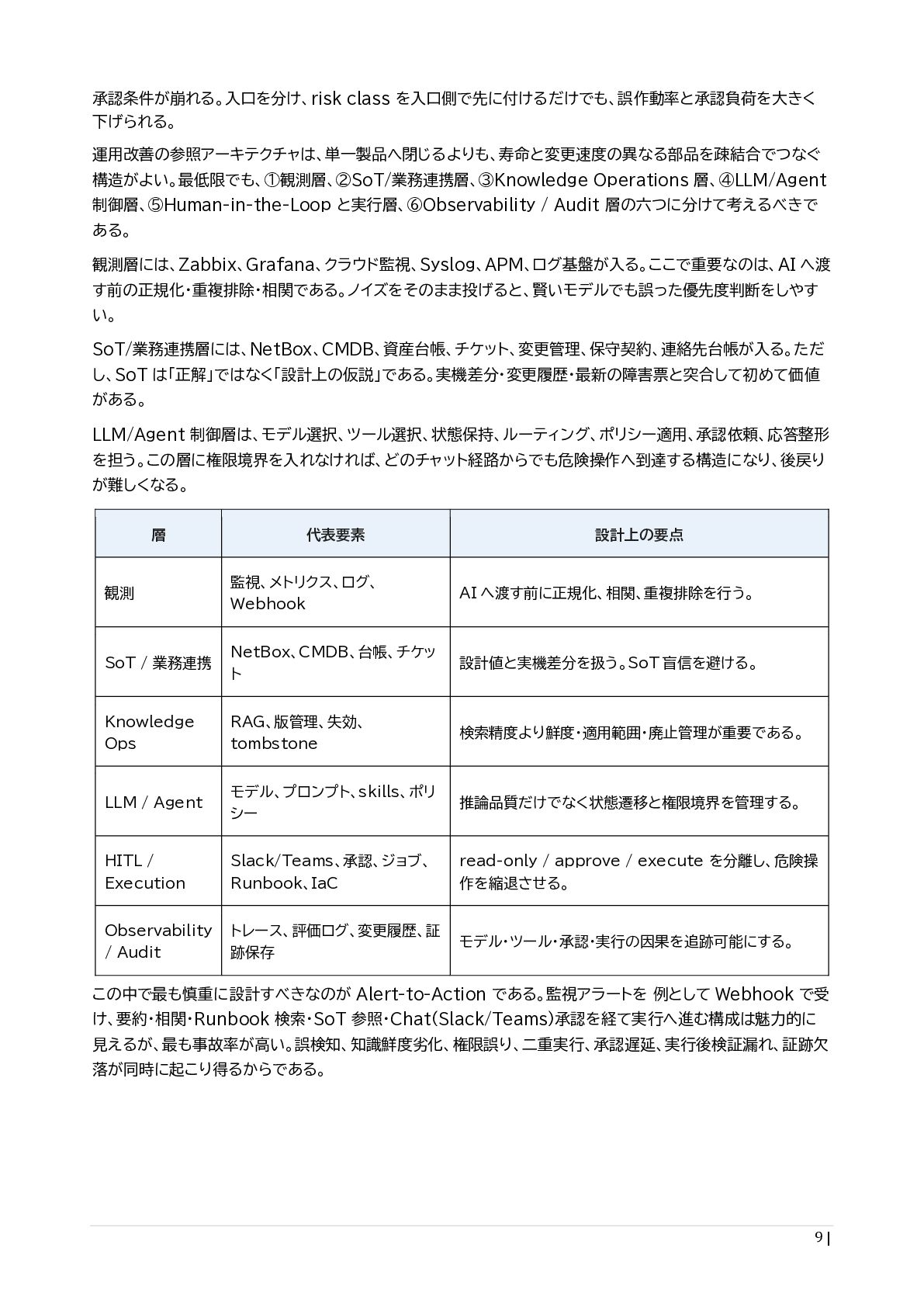
{kind=link}
{kind=link}
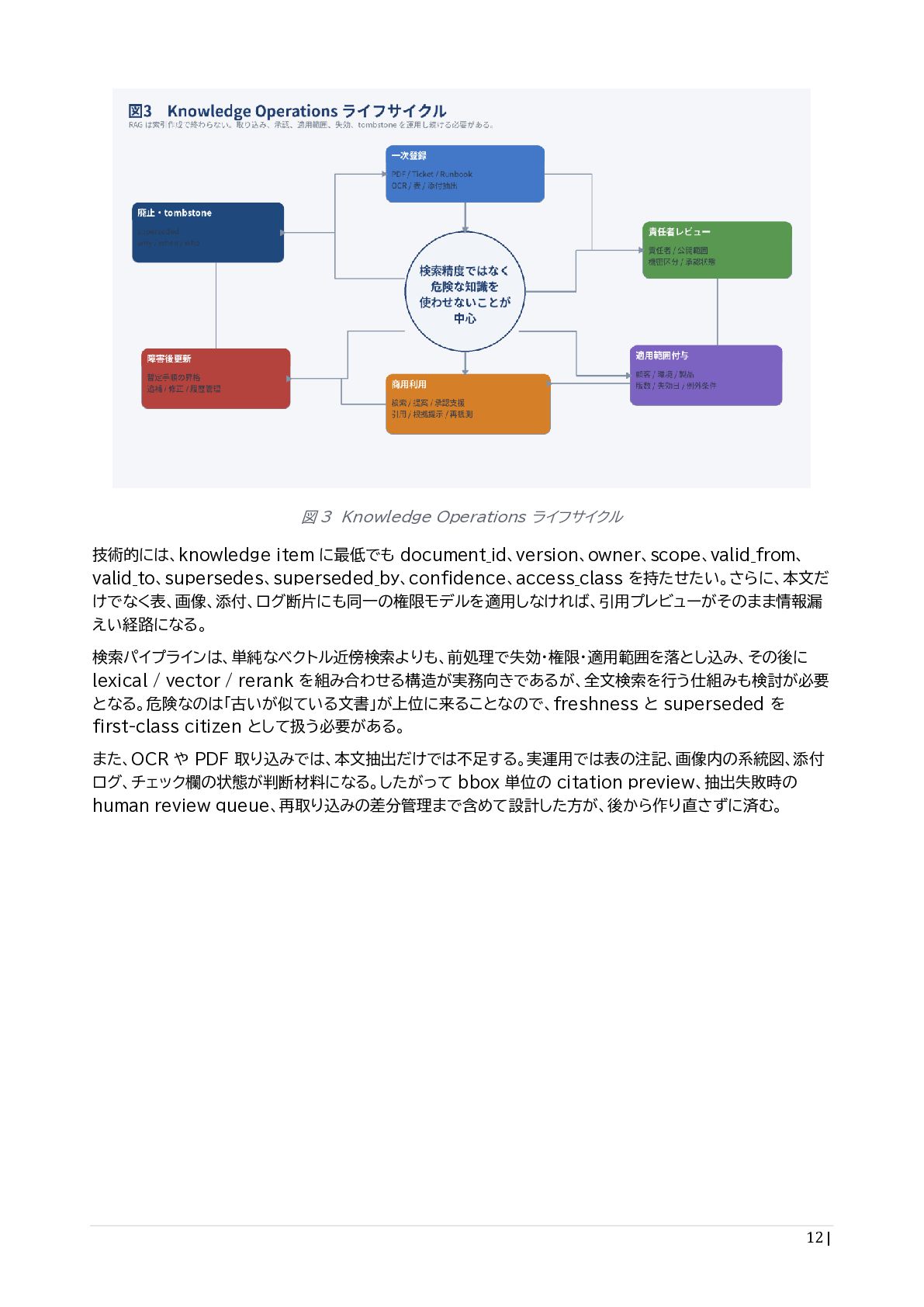
{kind=link}
{kind=link}
{kind=link}
{kind=link}
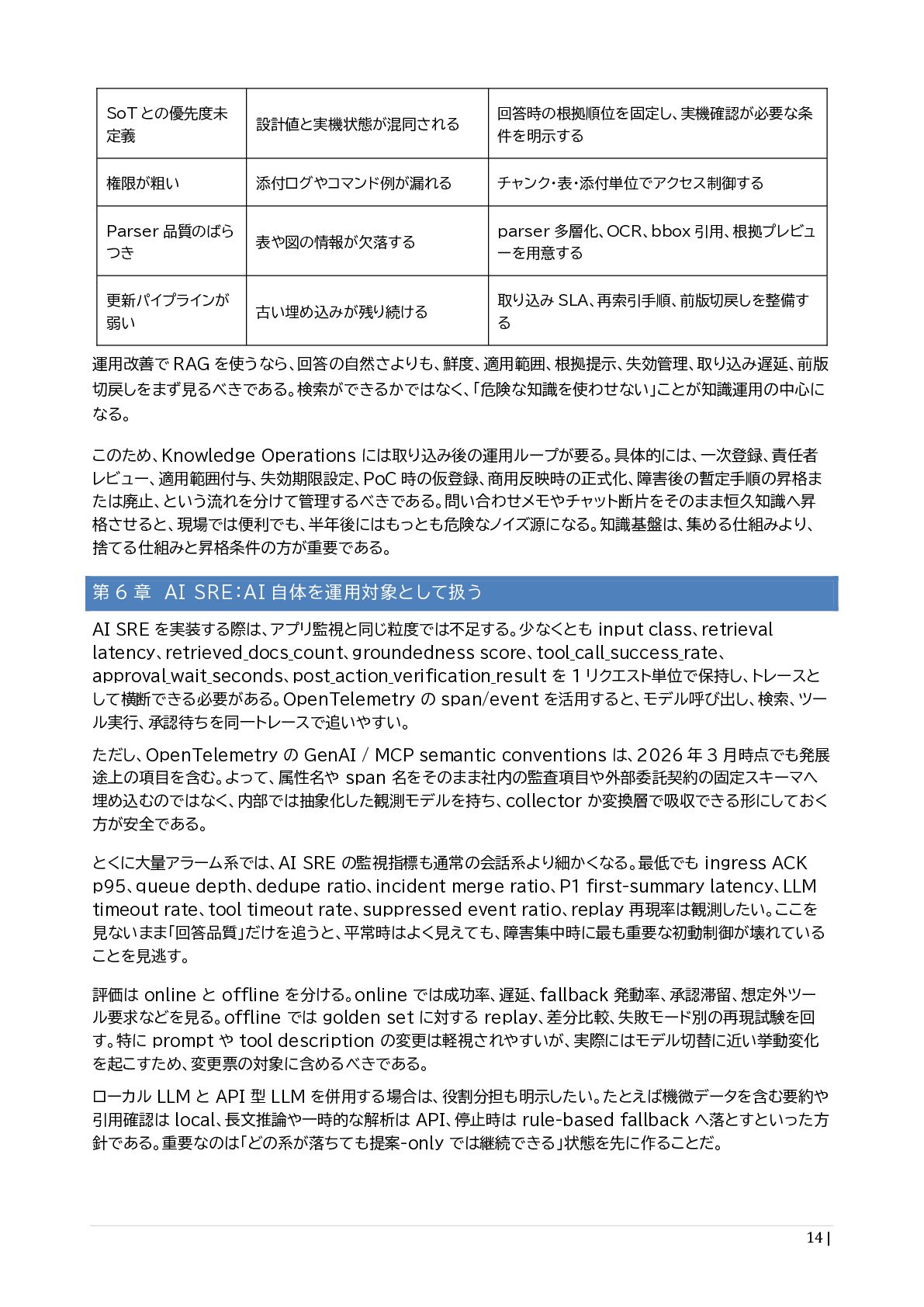
{kind=link}
{kind=link}
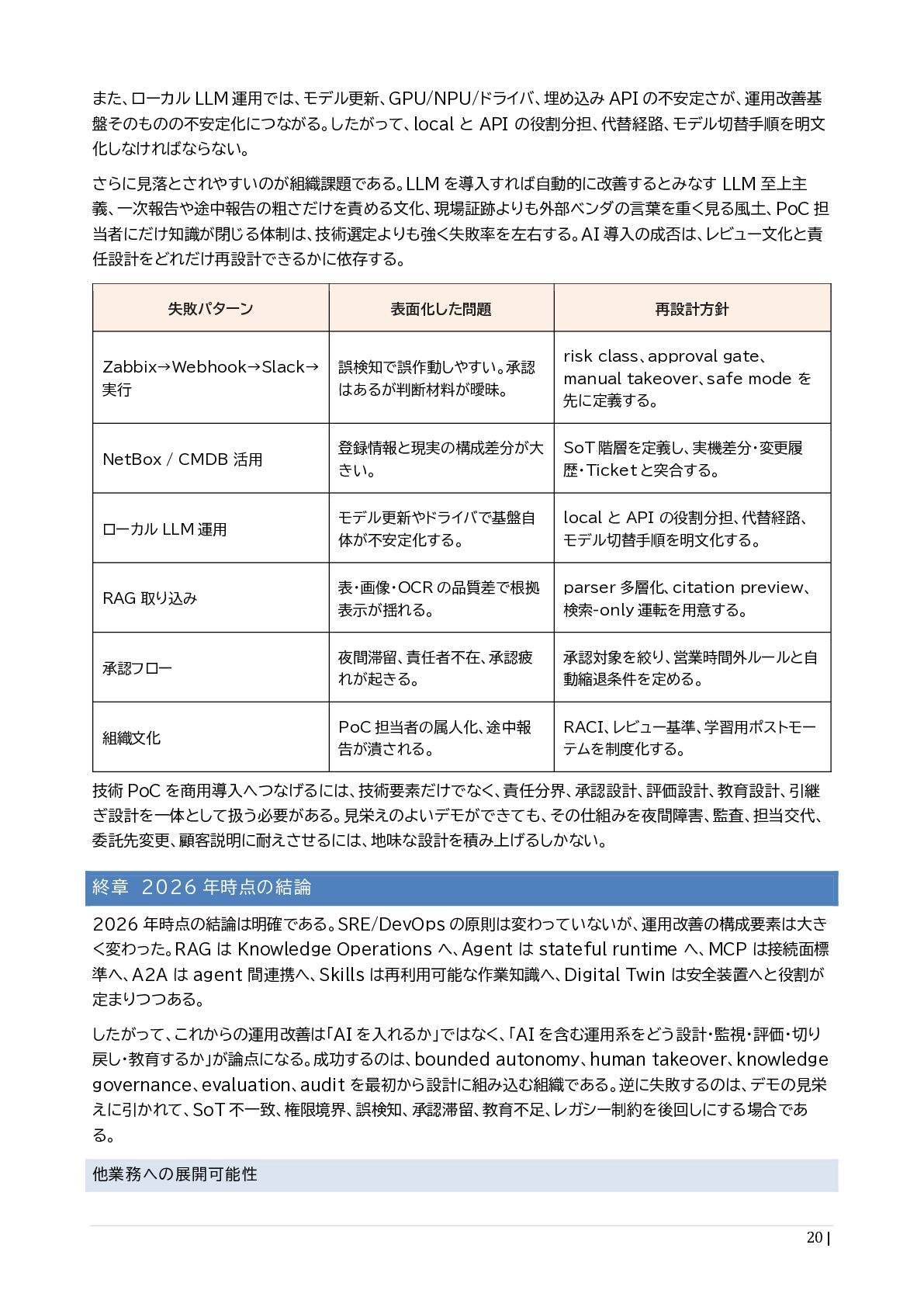{kind=link}
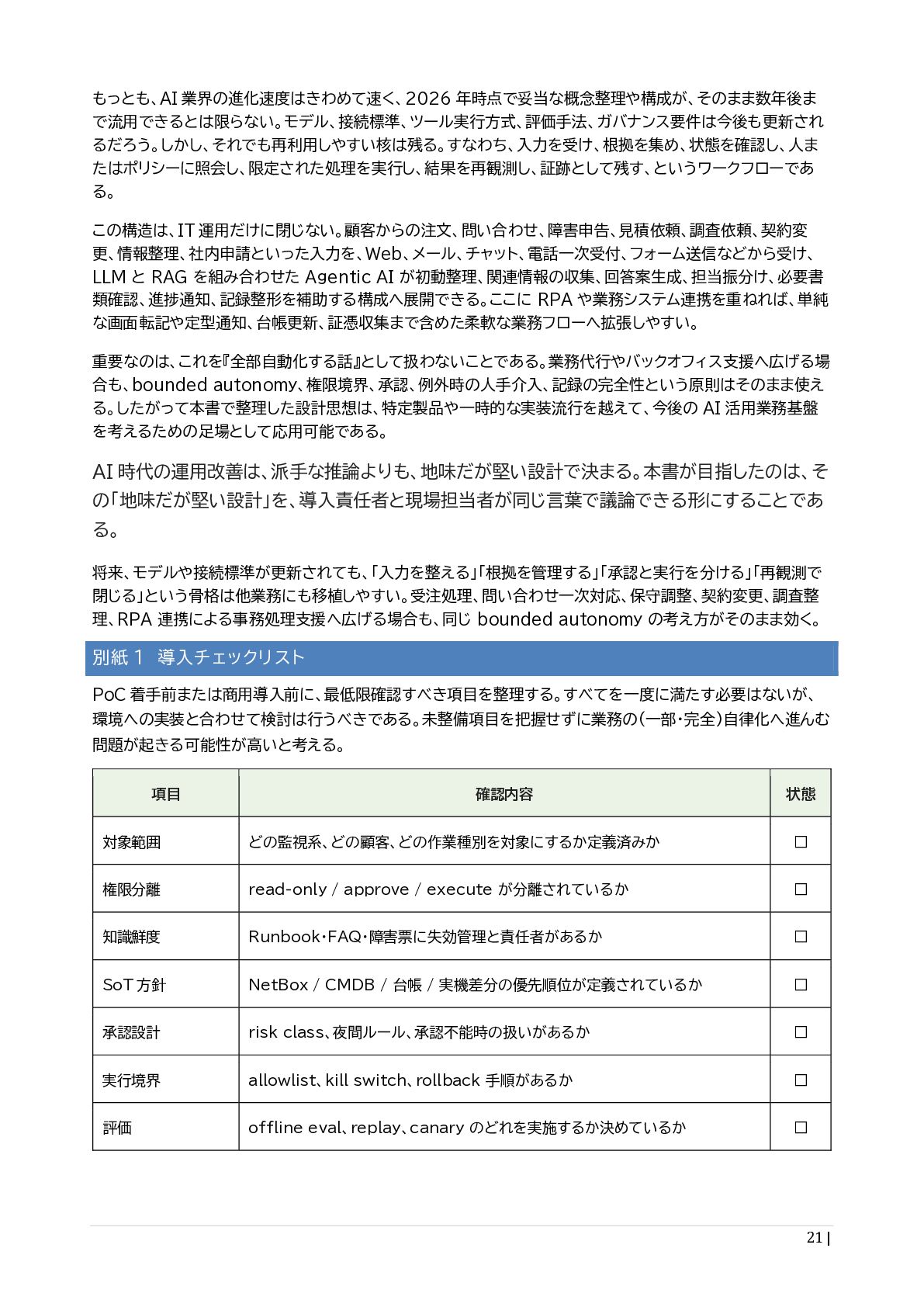{kind=link}
{kind=link}
{kind=link}
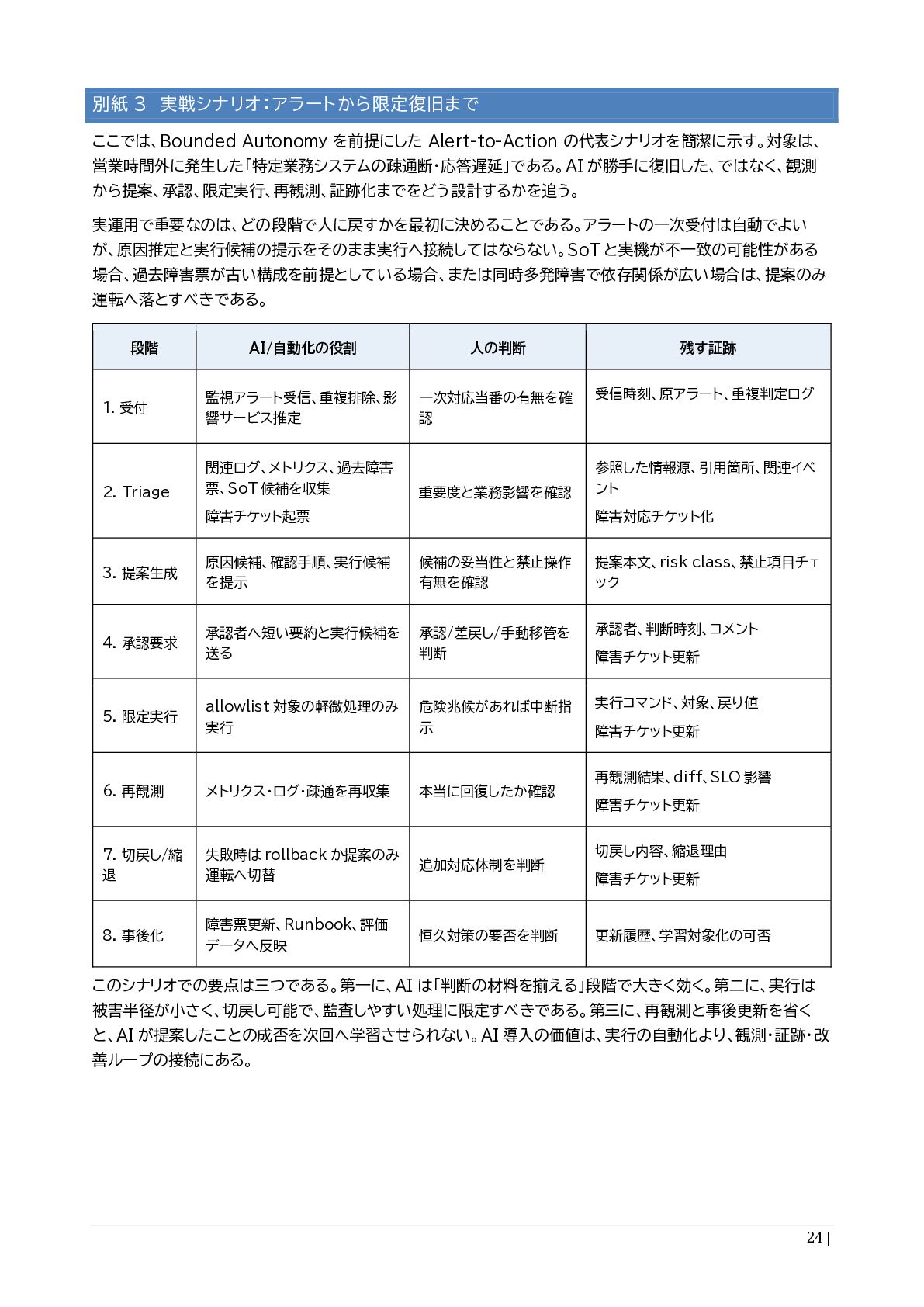{kind=link}
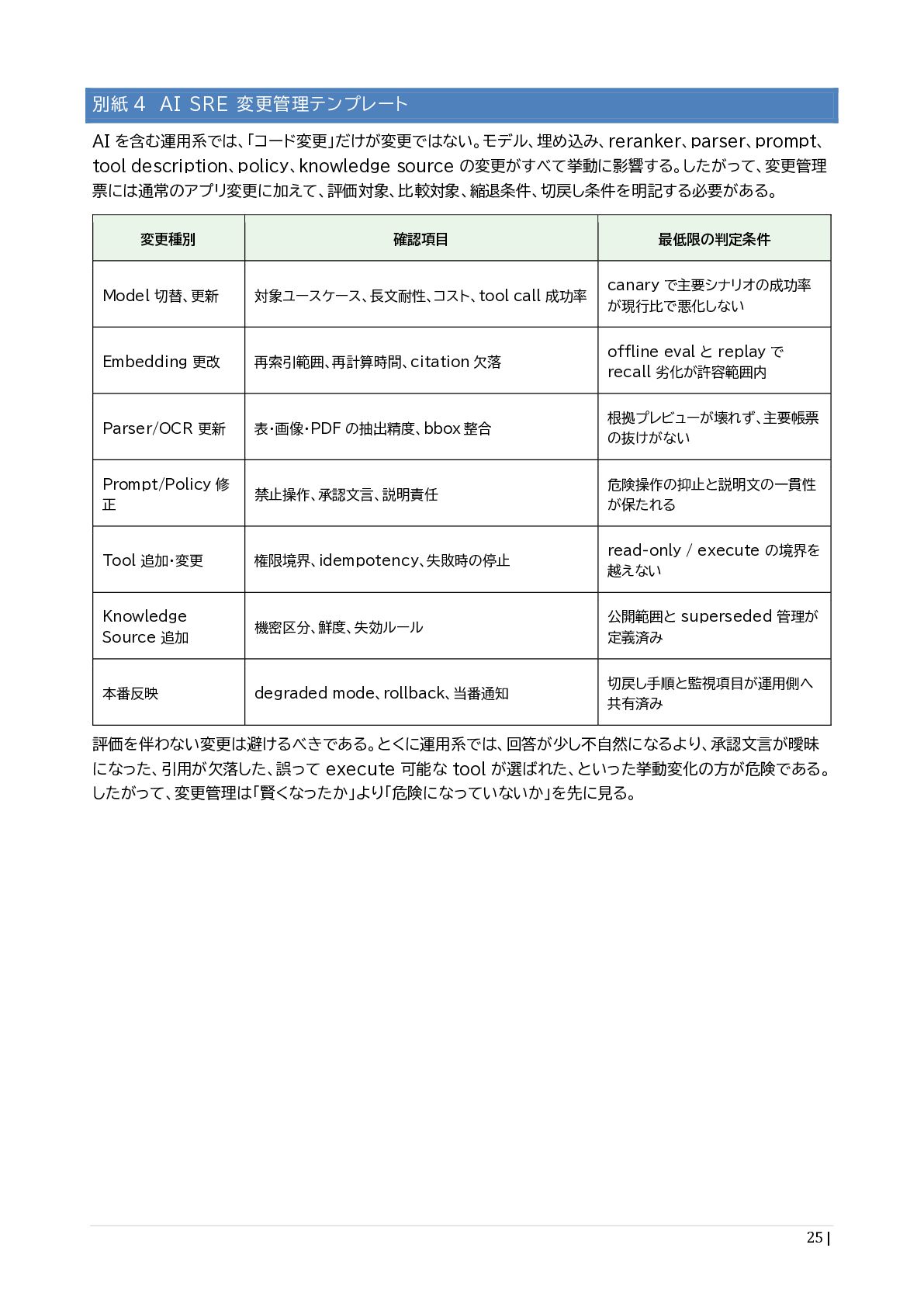{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}