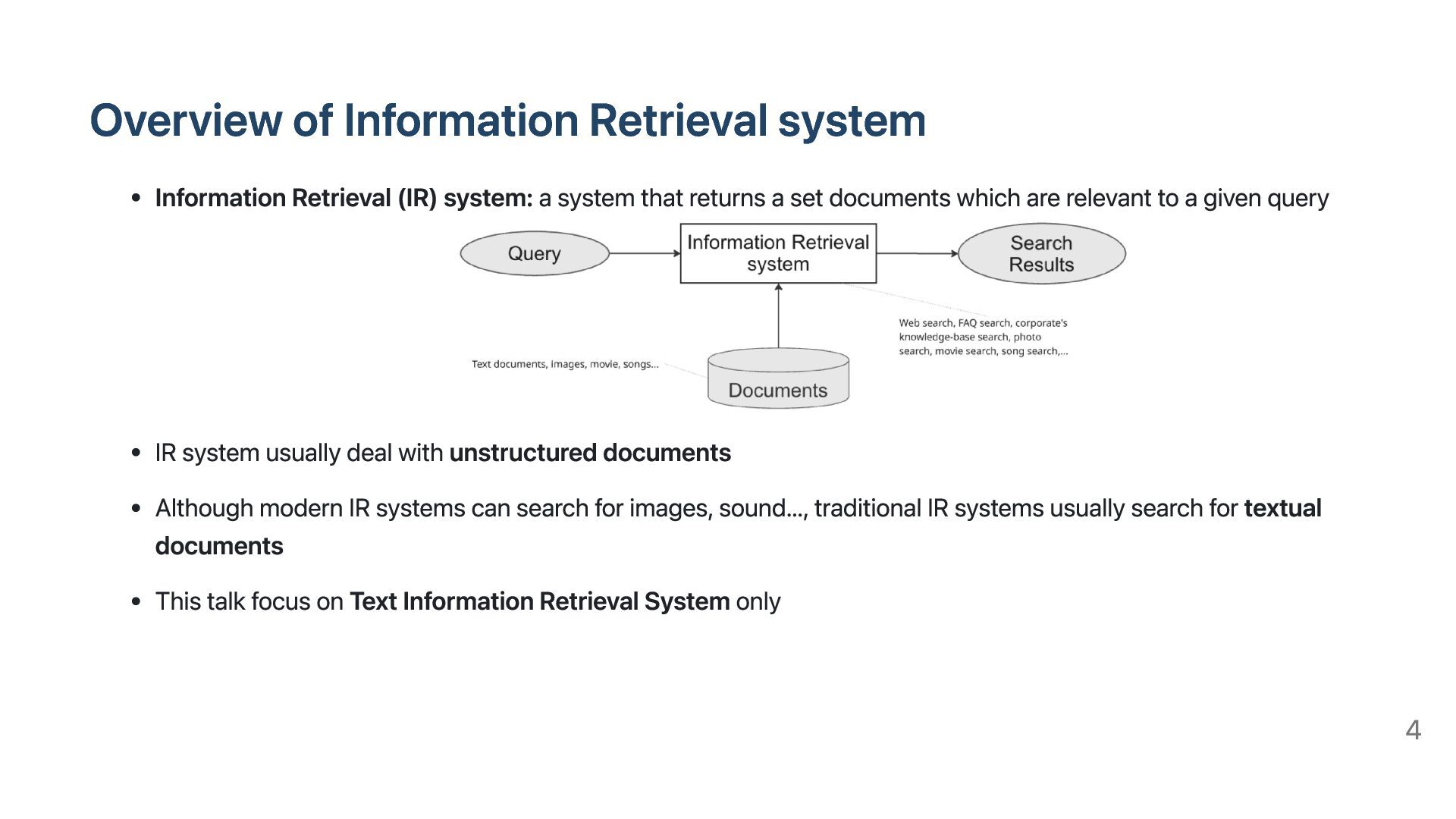
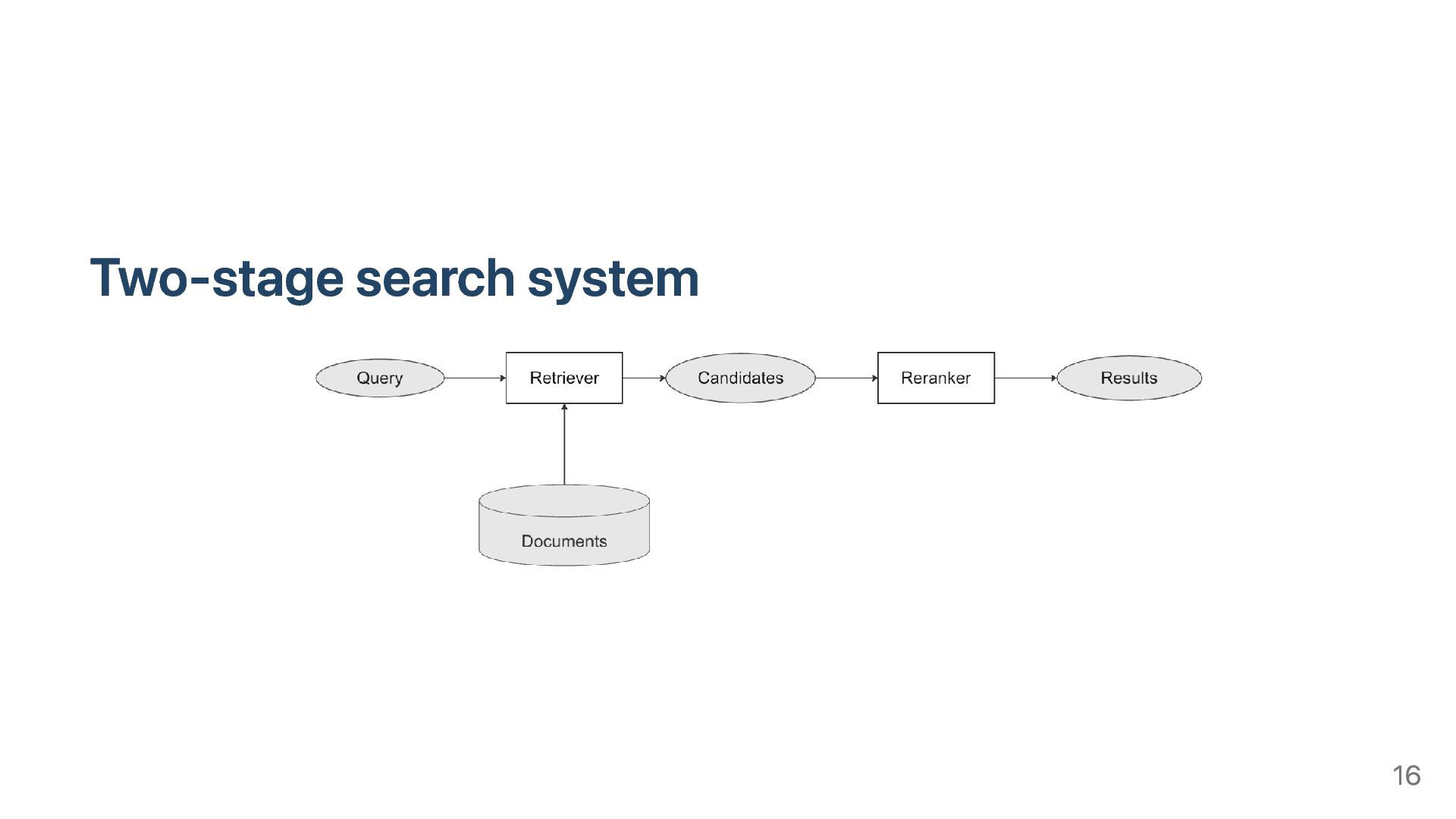
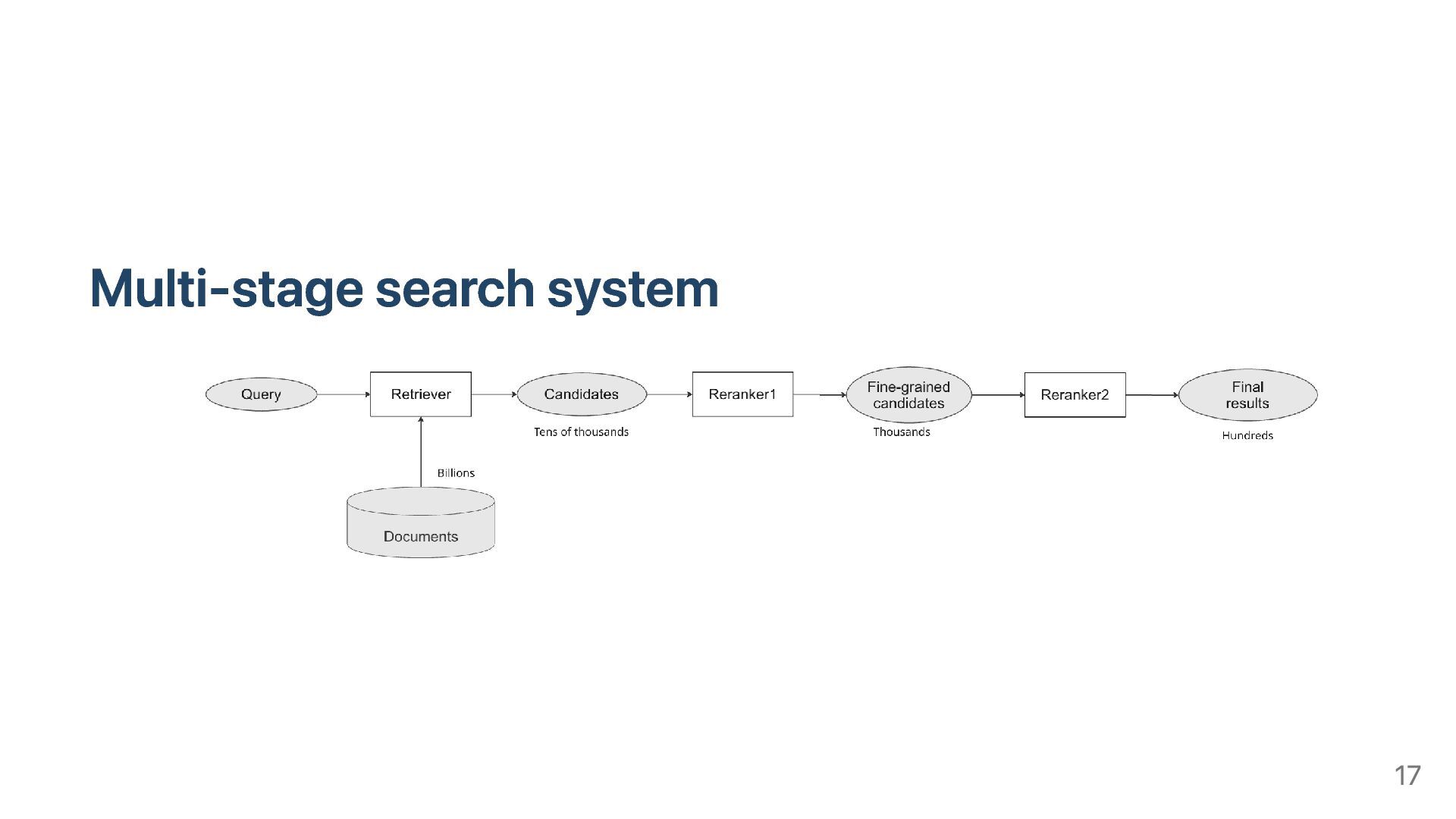
system that returns a set documents which are relevant to a given query IR system usually deal with unstructured documents Although modern IR systems can search for images, sound…, traditional IR systems usually search for textual documents This talk focus on Text Information Retrieval System only 4
relevant to given text query Estimate the relevance score of a each document w.r.t the given query Return the relevant documents using the score E.g., may be similarity score between Documents with higher similarity scores are more relevant to the query Sort documents by similarity score and return TOP-K documents We will examine several traditional methods to estimate the relevance score 5
the corpu D and build a vocabulary With any , a document , compute the Term-Frequency tf and Inverse Document Frequency idf where is the number of documents that contain the term . tf-idf score for the term t with respect to the document d is The simplest way to compute the query score is to sum up tf-idf score of each query term 6
simple, they have the following key problems: Short query Short queries contain few terms, which leads the search system to return few or no results Vocabulary mismatch Queries and documents may use different vocabularies to express the same concept Queries may contain new terms Lack of semantic understanding Use only the count of query terms in the document but ignore their positions and interactions with other terms 8
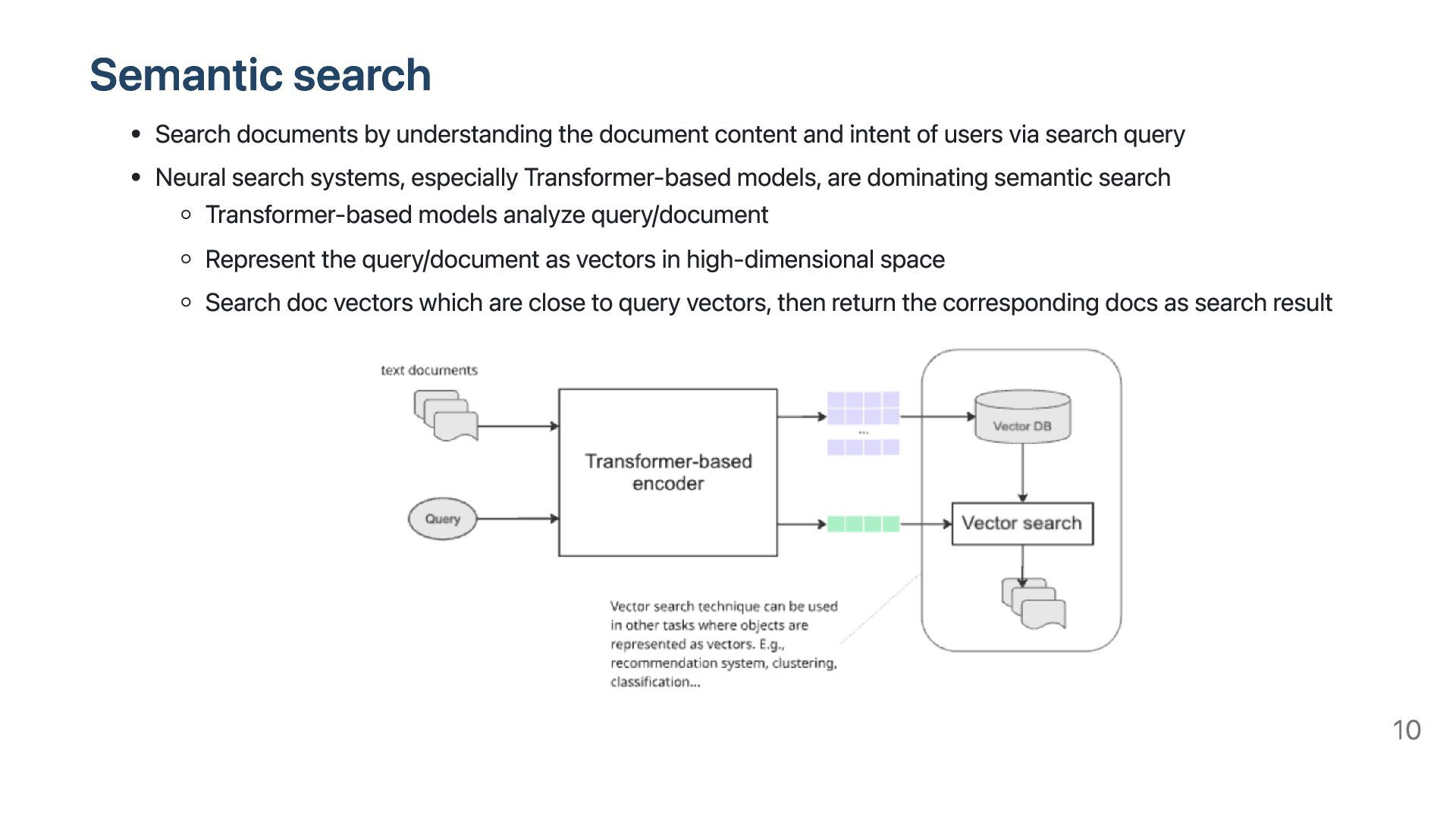
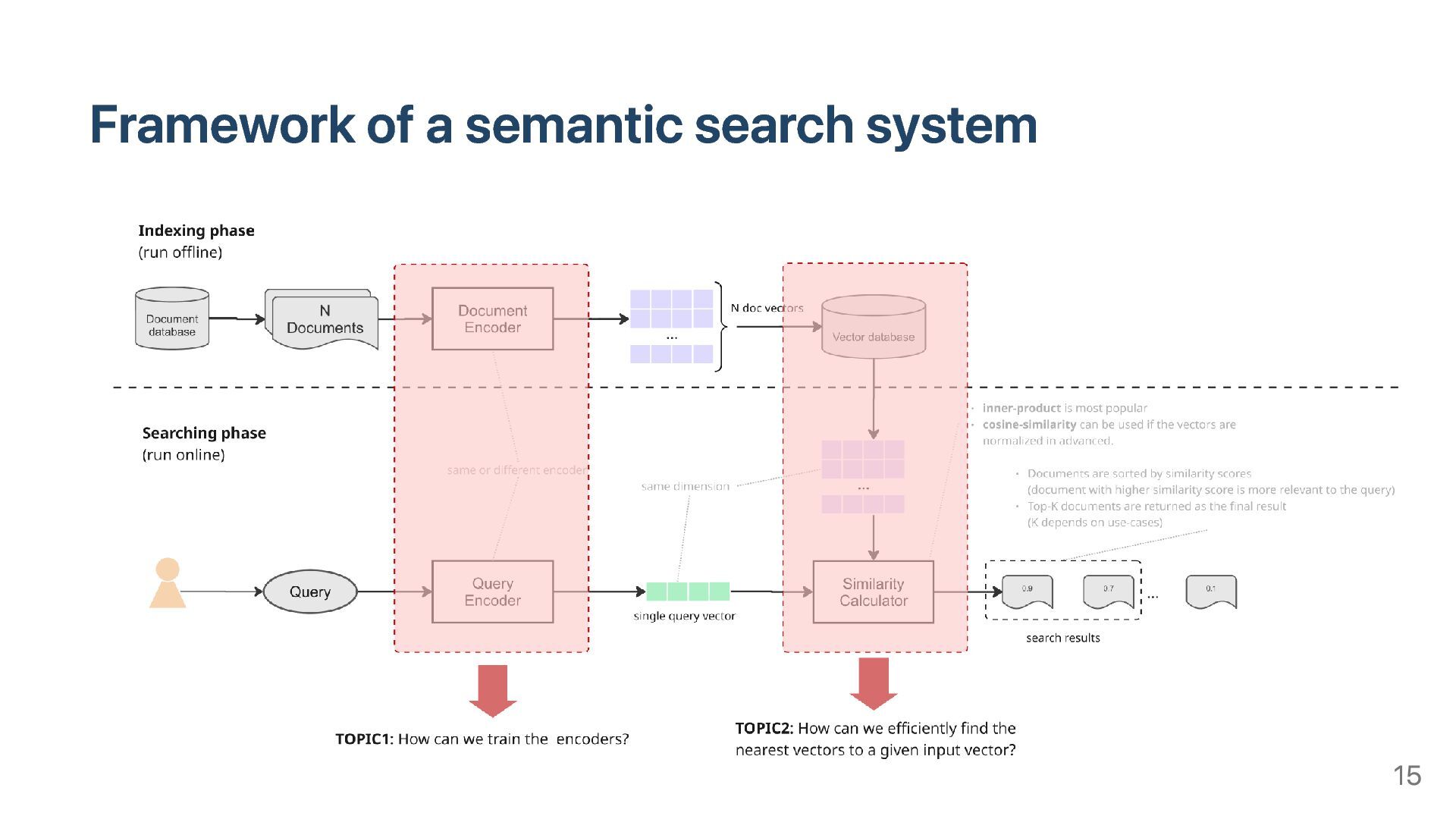
intent of users via search query Neural search systems, especially Transformer-based models, are dominating semantic search Transformer-based models analyze query/document Represent the query/document as vectors in high-dimensional space Search doc vectors which are close to query vectors, then return the corresponding docs as search result 10
model to specify relevant documents for the given question The apply some answering models to extract the answer from the relevant documents RAG (Retrieval-Augmented Generation) RAG becomes more popular after ChatGPT was published. RAG is a special case of Question Answer, in which the answering model is an LLM Embed question along with relevant documents into prompt LLM will automatically generate the answer for the question 12
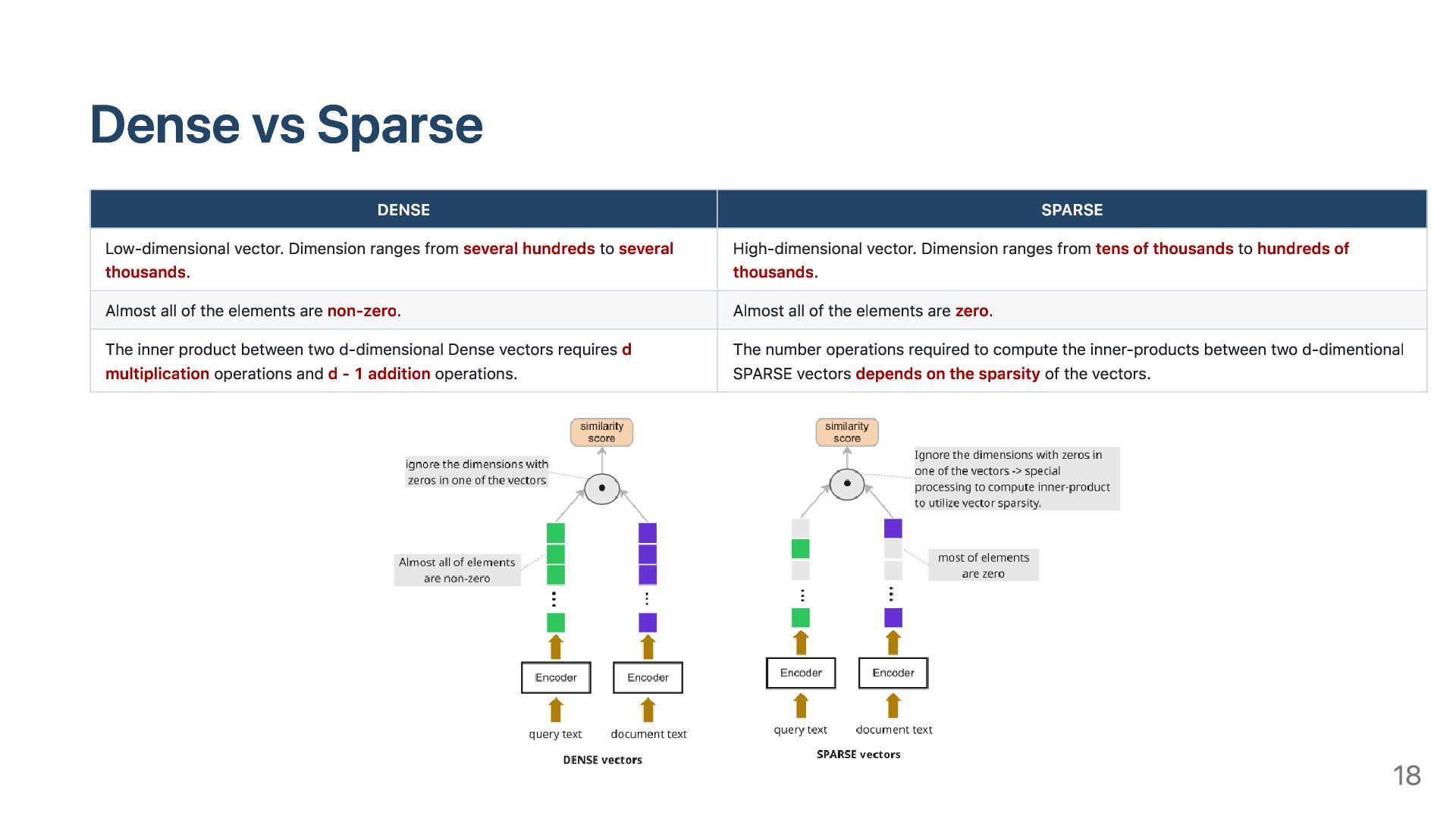
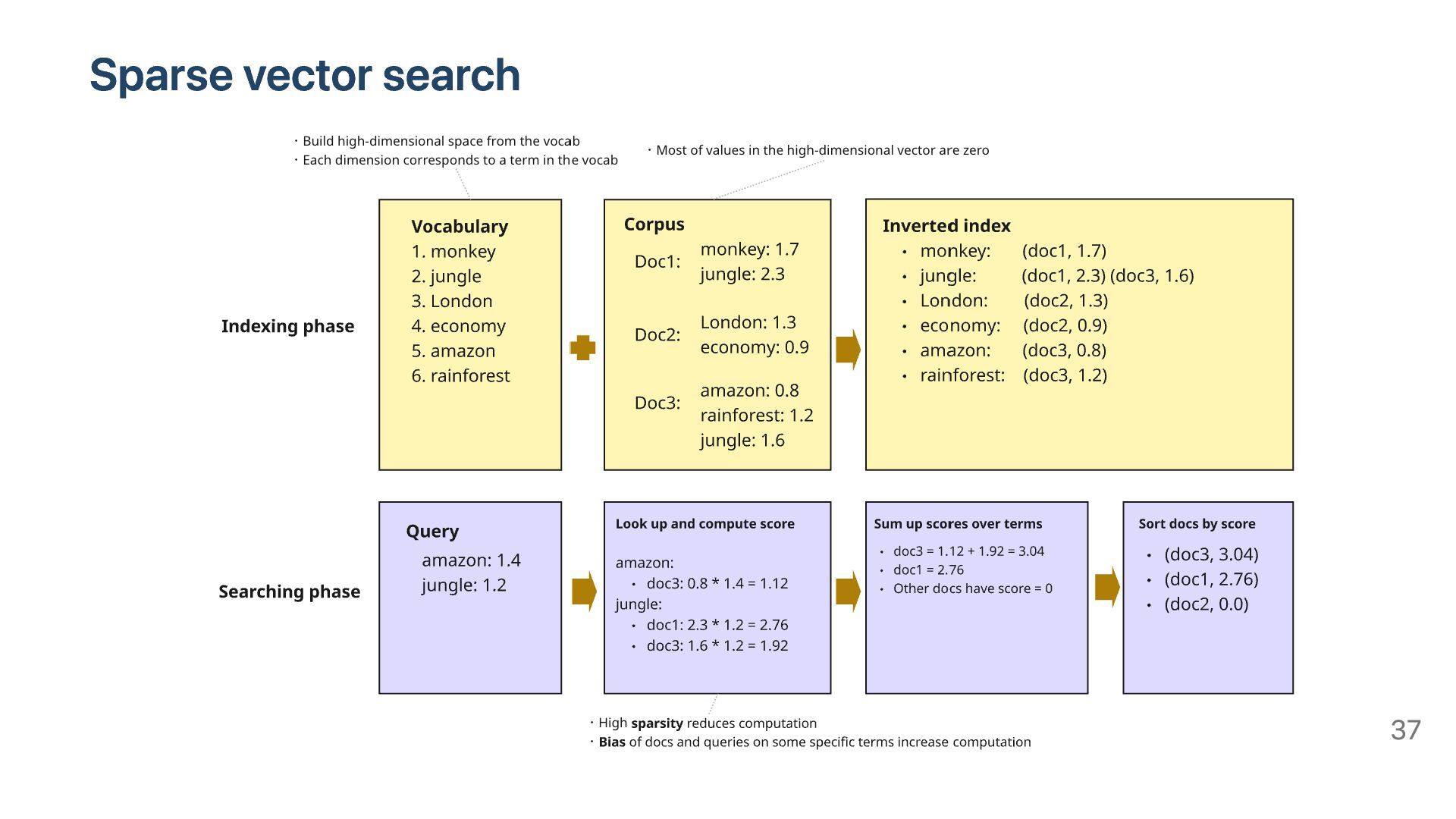
several hundreds to several thousands. High-dimensional vector. Dimension ranges from tens of thousands to hundreds of thousands. Almost all of the elements are non-zero. Almost all of the elements are zero. The inner product between two d-dimensional Dense vectors requires d multiplication operations and d - 1 addition operations. The number operations required to compute the inner-products between two d-dimentional SPARSE vectors depends on the sparsity of the vectors. 18
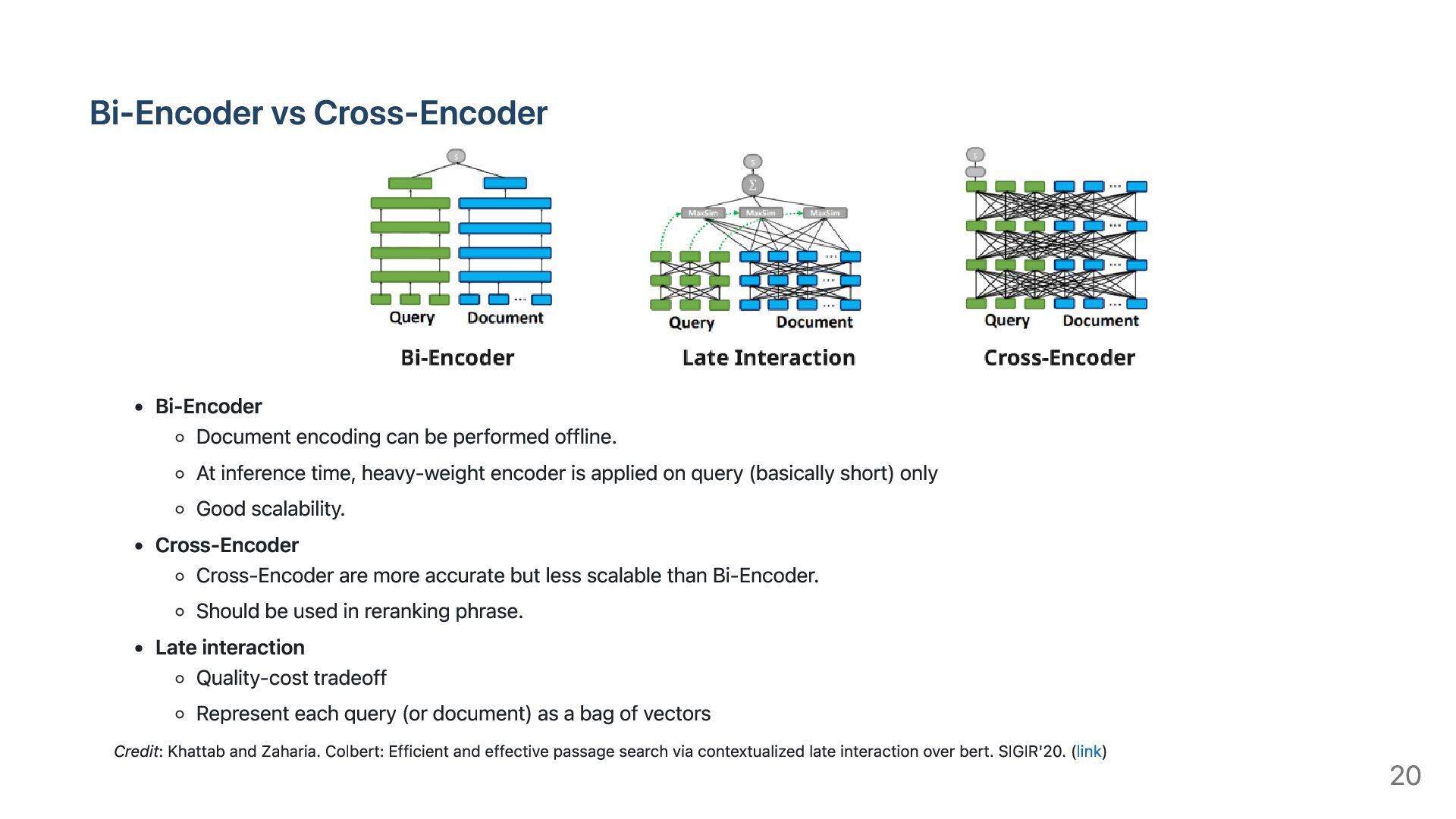
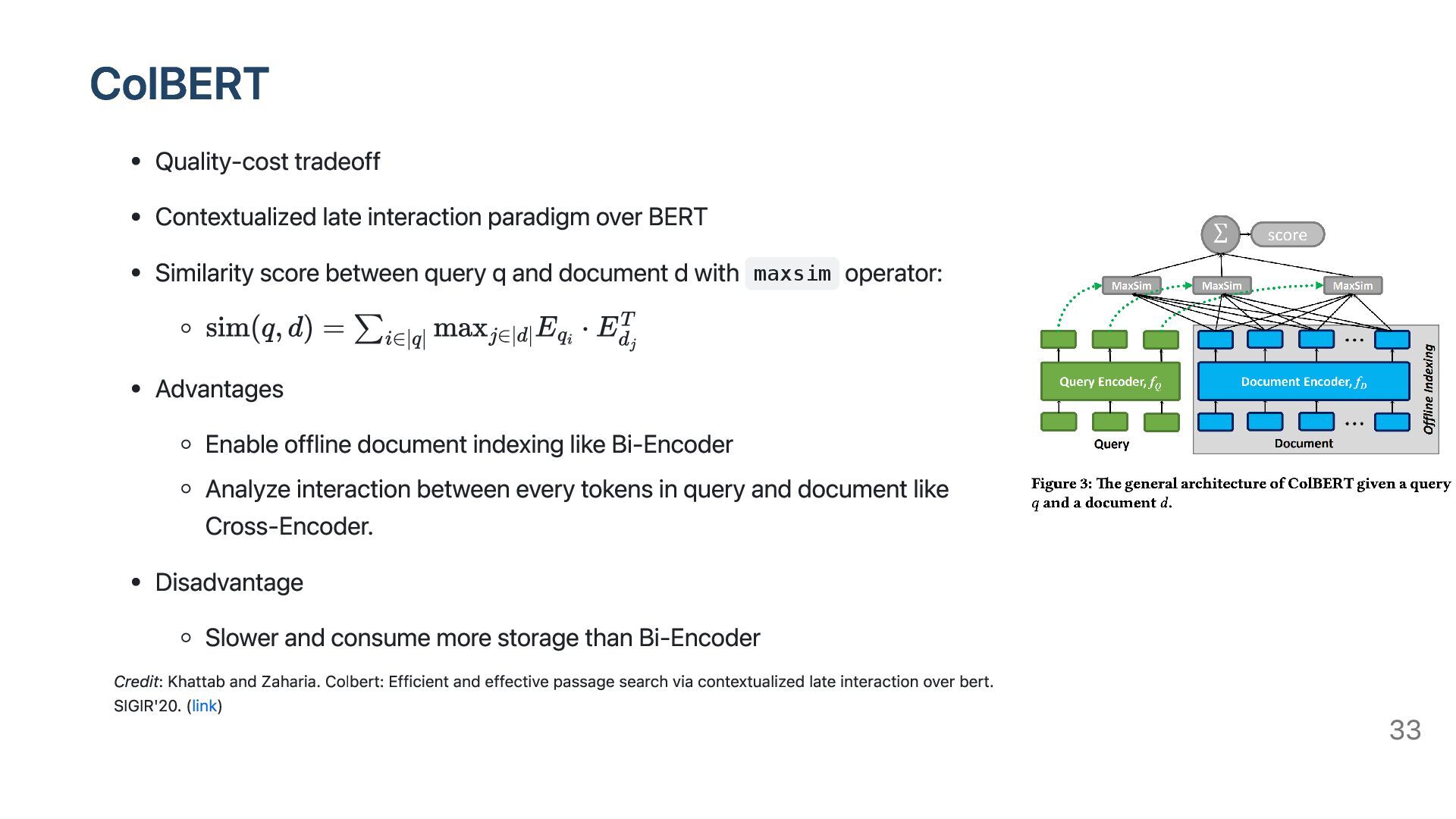
At inference time, heavy-weight encoder is applied on query (basically short) only Good scalability. Cross-Encoder Cross-Encoder are more accurate but less scalable than Bi-Encoder. Should be used in reranking phrase. Late interaction Quality-cost tradeoff Represent each query (or document) as a bag of vectors Credit: Khattab and Zaharia. Colbert: Efficient and effective passage search via contextualized late interaction over bert. SIGIR'20. (link) 20
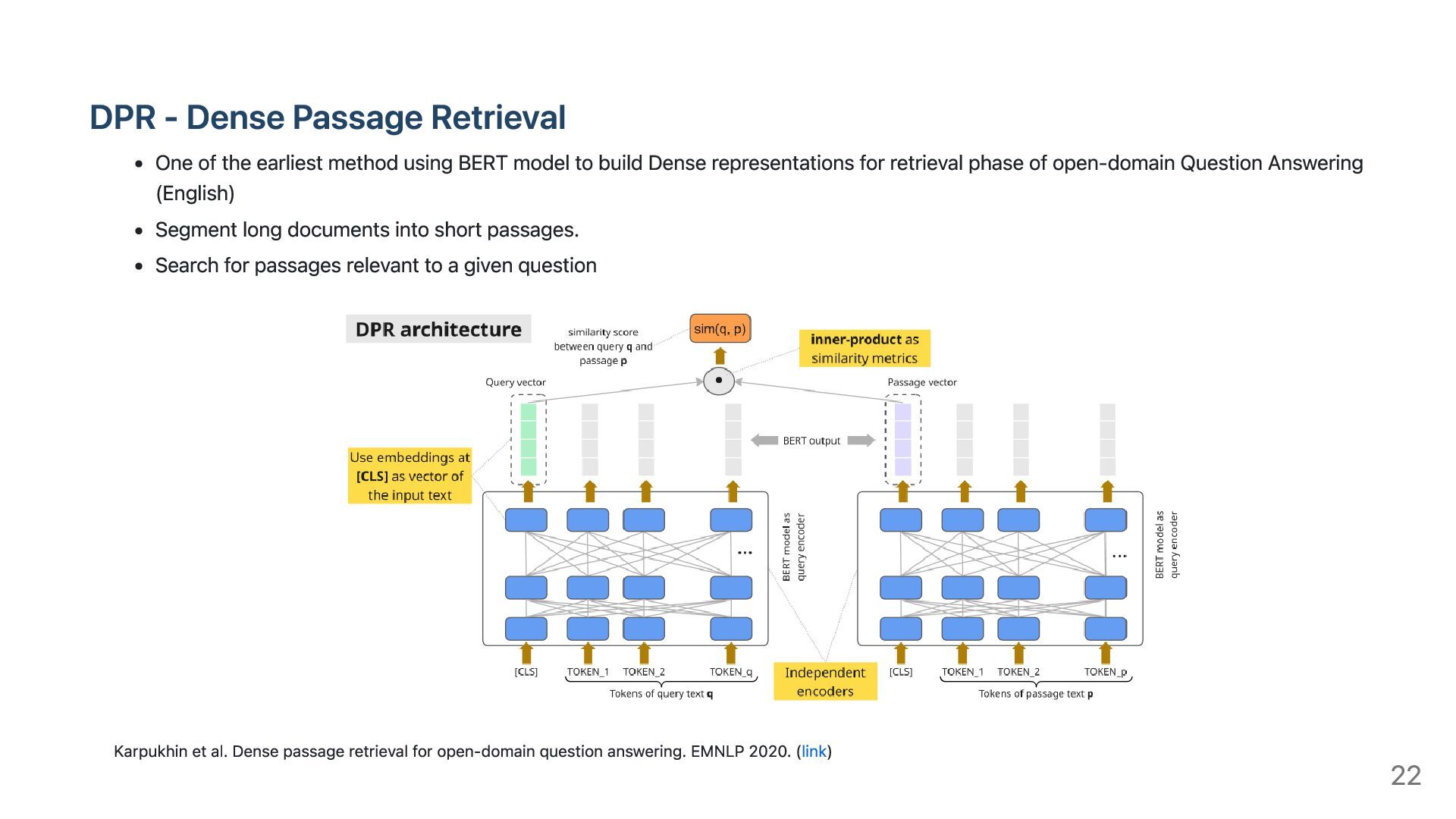
using BERT model to build Dense representations for retrieval phase of open-domain Question Answering (English) Segment long documents into short passages. Search for passages relevant to a given question Karpukhin et al. Dense passage retrieval for open-domain question answering. EMNLP 2020. (link) 22
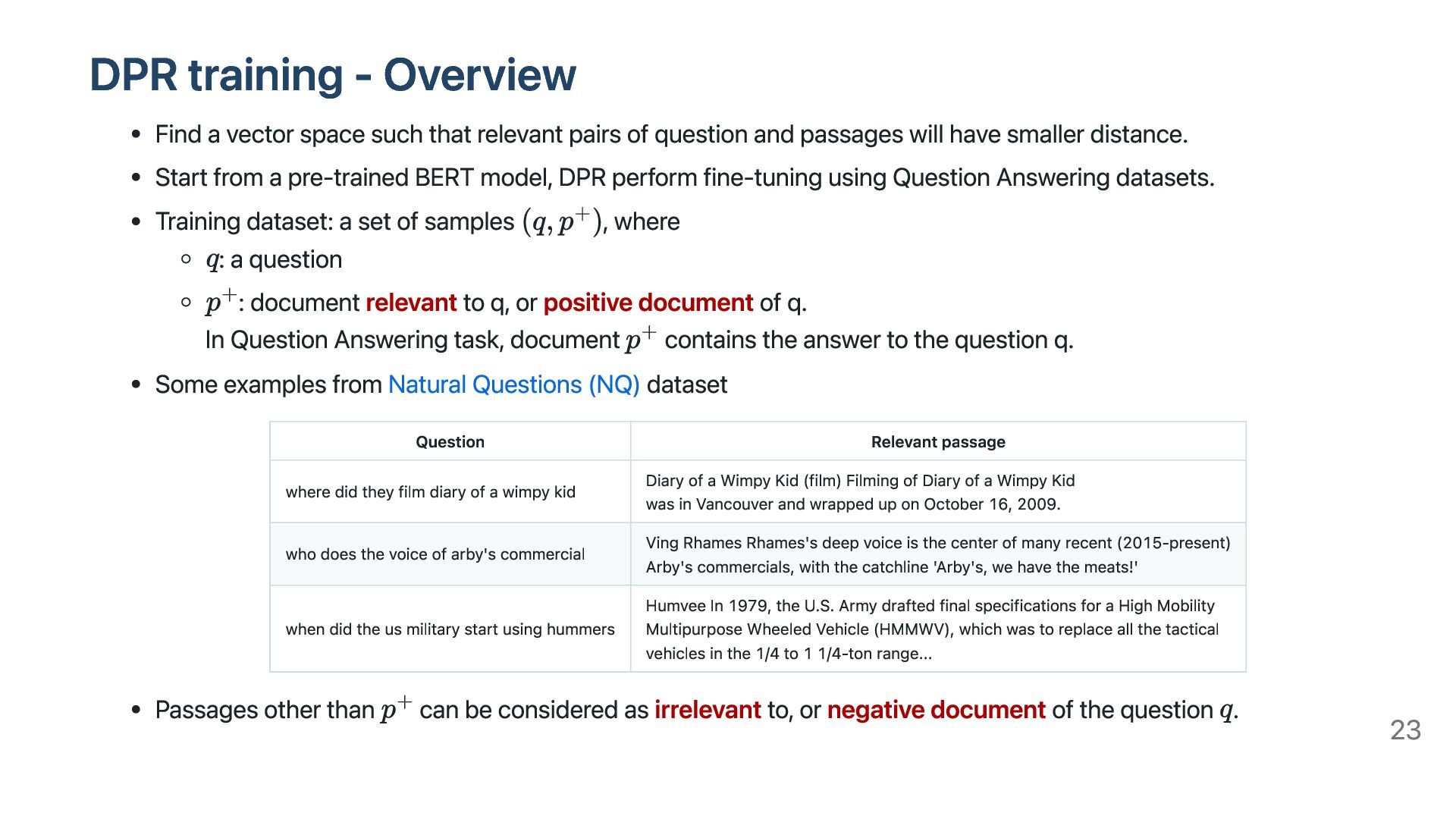
relevant pairs of question and passages will have smaller distance. Start from a pre-trained BERT model, DPR perform fine-tuning using Question Answering datasets. Training dataset: a set of samples , where : a question : document relevant to q, or positive document of q. In Question Answering task, document contains the answer to the question q. Some examples from Natural Questions (NQ) dataset Question Relevant passage where did they film diary of a wimpy kid Diary of a Wimpy Kid (film) Filming of Diary of a Wimpy Kid was in Vancouver and wrapped up on October 16, 2009. who does the voice of arby's commercial Ving Rhames Rhames's deep voice is the center of many recent (2015-present) Arby's commercials, with the catchline 'Arby's, we have the meats!' when did the us military start using hummers Humvee In 1979, the U.S. Army drafted final specifications for a High Mobility Multipurpose Wheeled Vehicle (HMMWV), which was to replace all the tactical vehicles in the 1/4 to 1 1/4-ton range... Passages other than can be considered as irrelevant to, or negative document of the question . 23
of B training samples For a query , consider positive documents of other queries ( ) as its negative documents ,..., So, the sample becomes a (B+1)-tuple: Loss function of the sample in the batch is defined as: 24
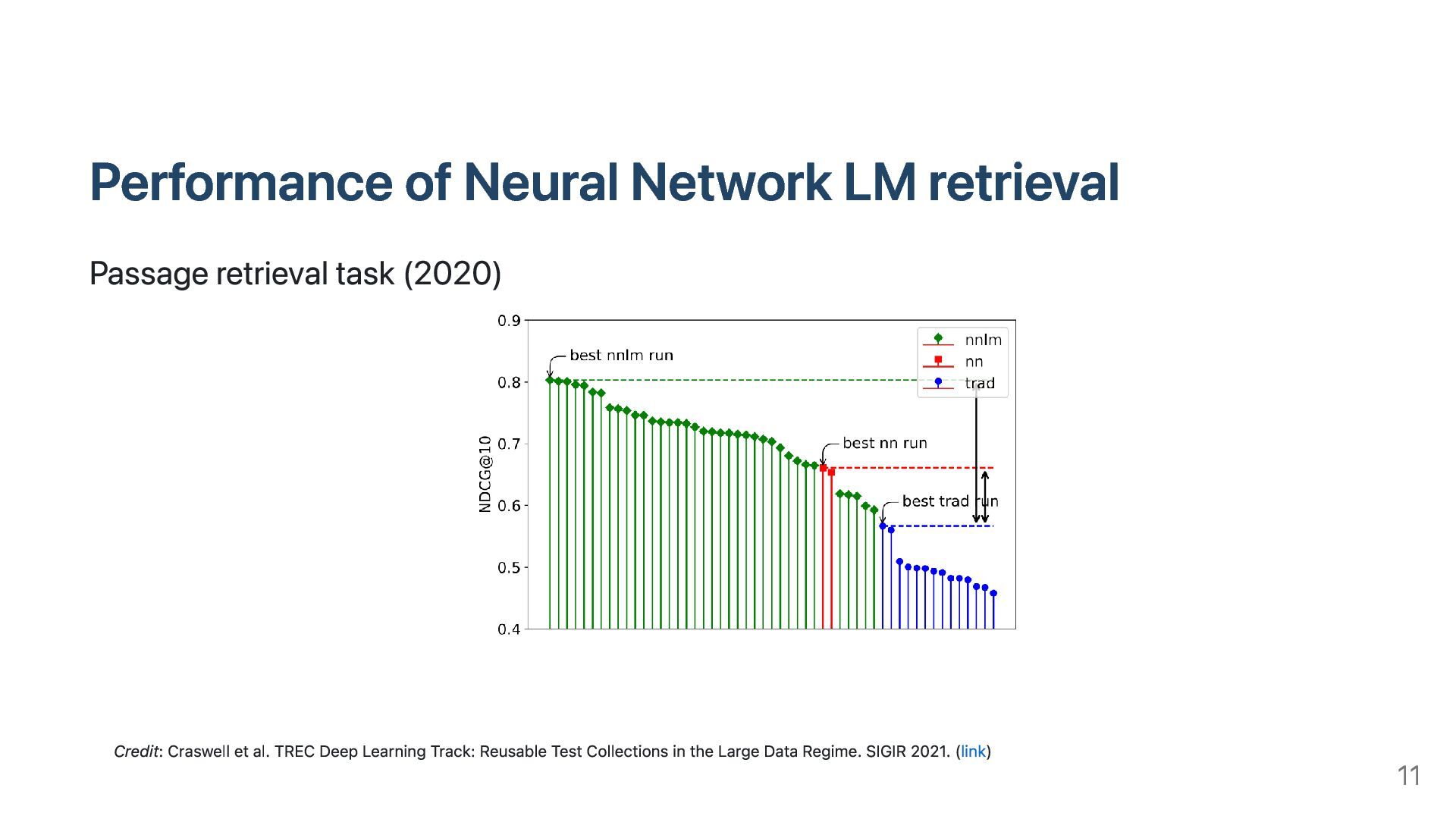
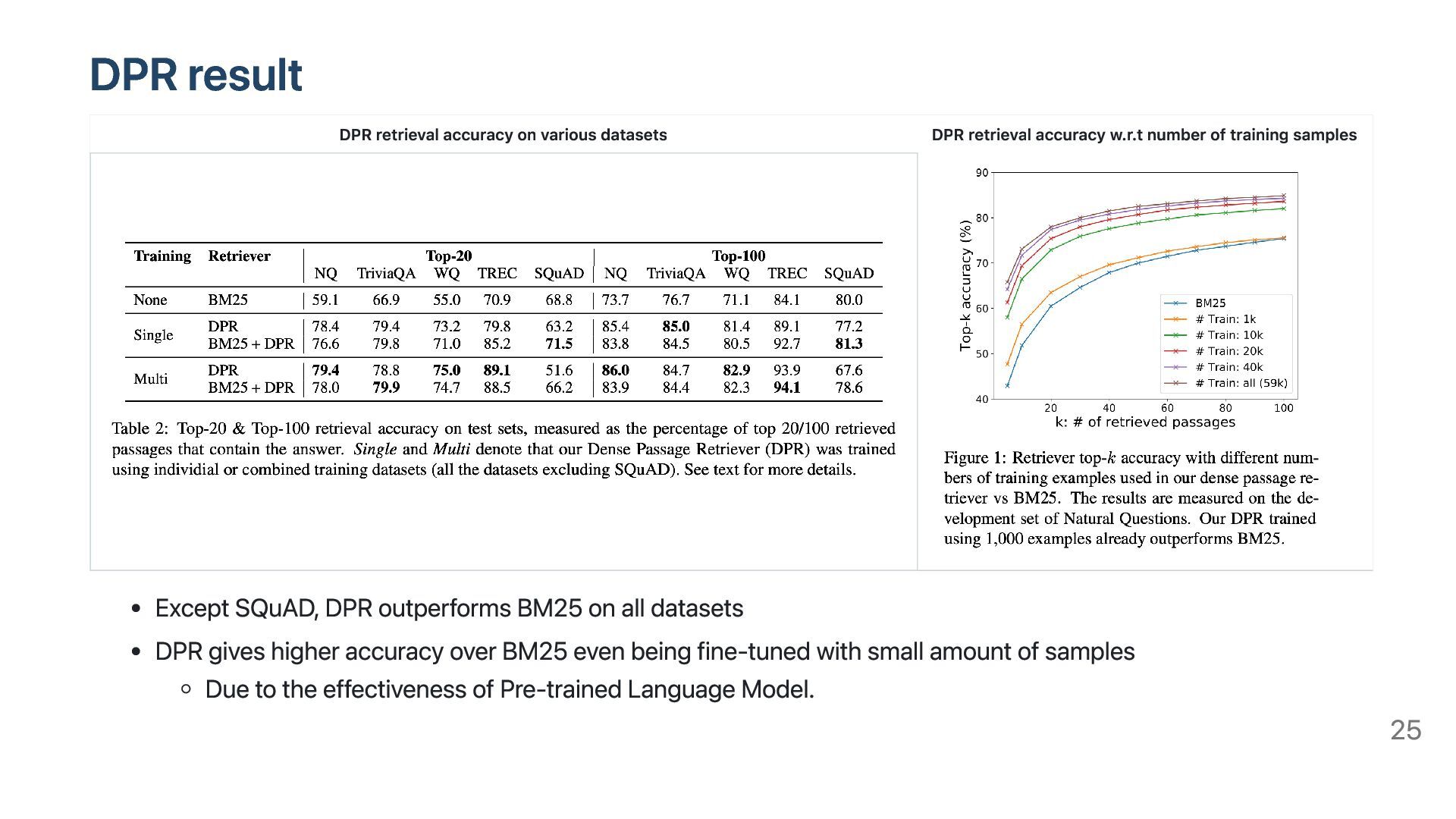
accuracy w.r.t number of training samples Except SQuAD, DPR outperforms BM25 on all datasets DPR gives higher accuracy over BM25 even being fine-tuned with small amount of samples Due to the effectiveness of Pre-trained Language Model. 25
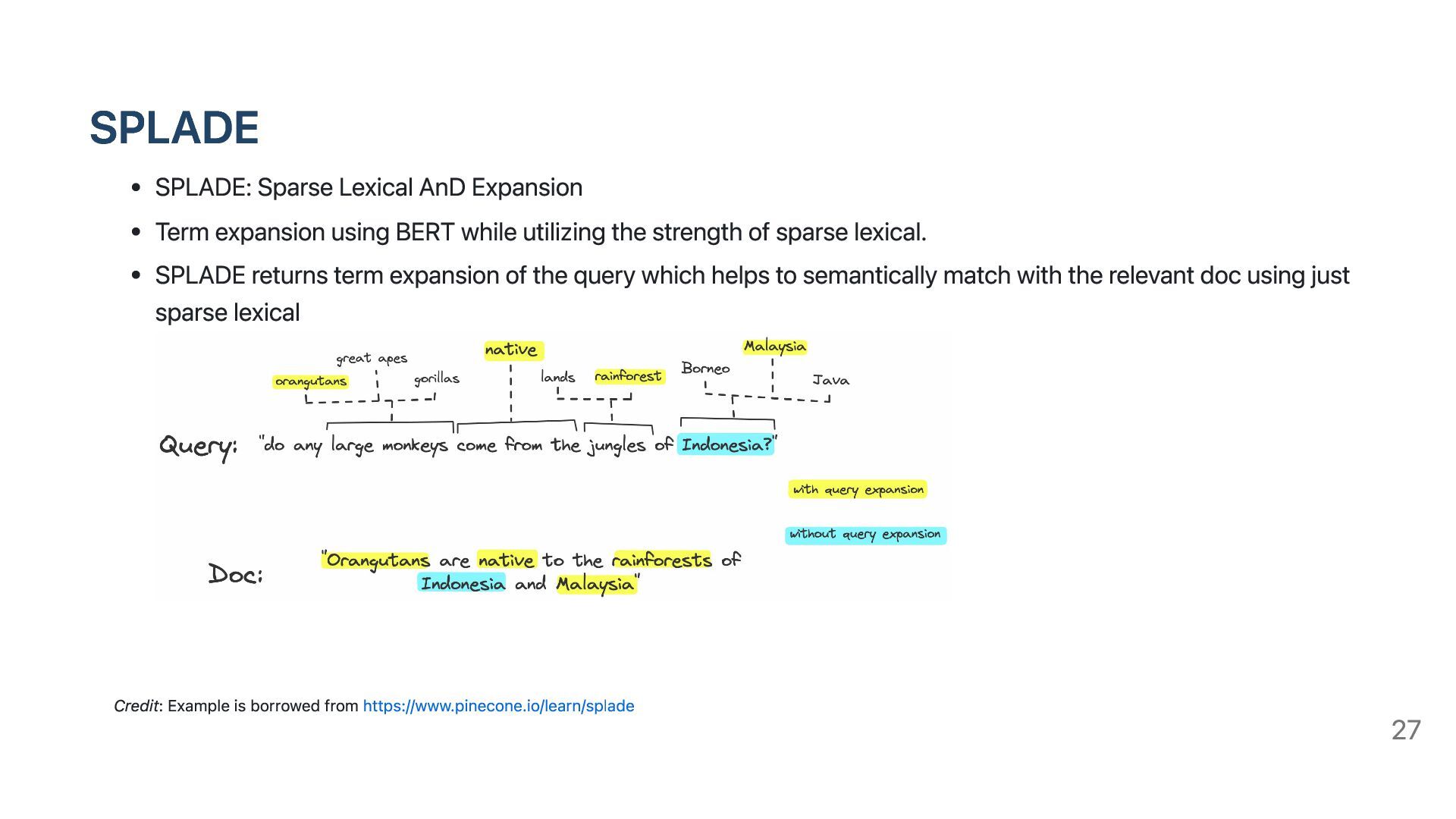
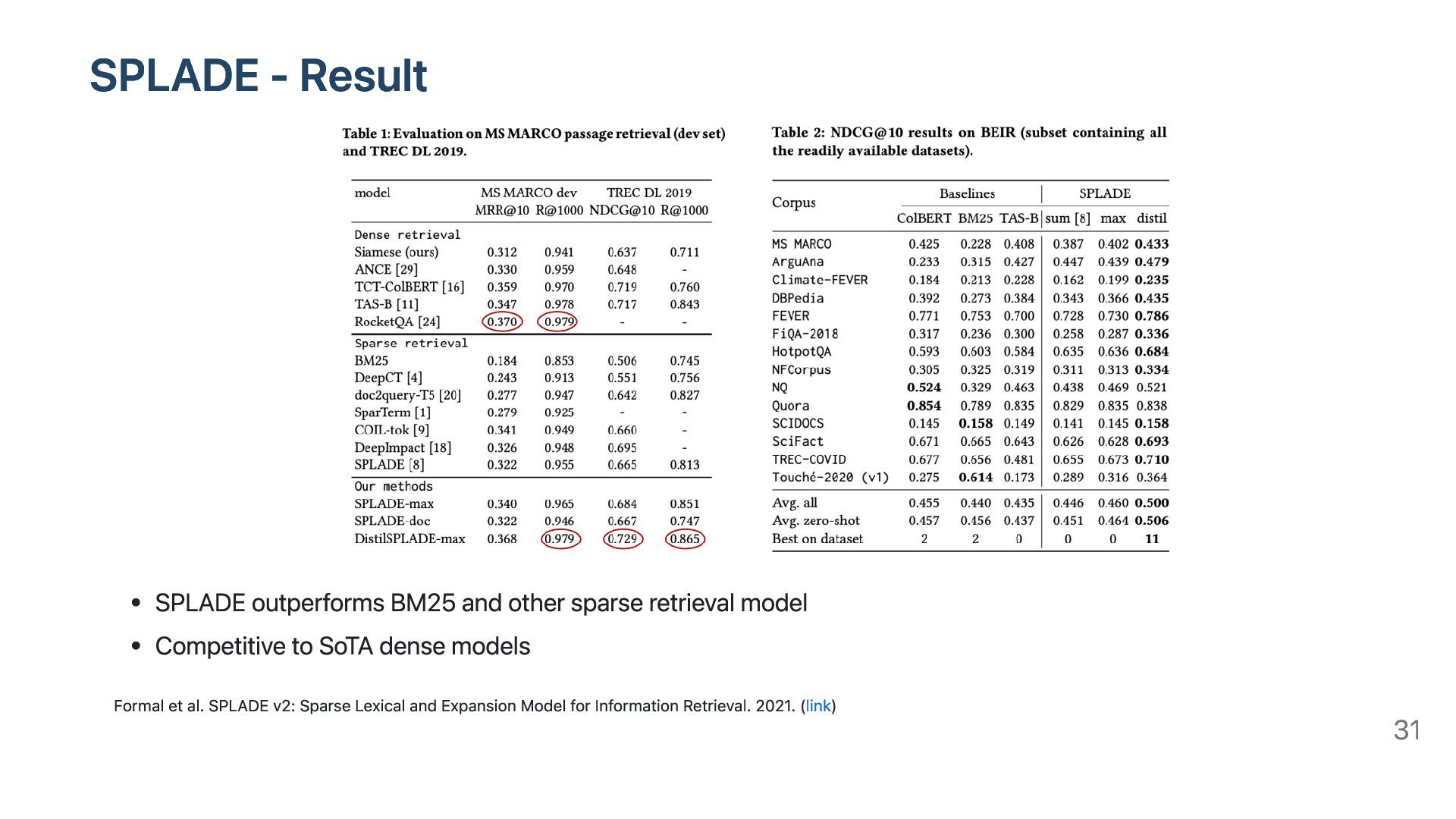
while utilizing the strength of sparse lexical. SPLADE returns term expansion of the query which helps to semantically match with the relevant doc using just sparse lexical Credit: Example is borrowed from https://www.pinecone.io/learn/splade 27
input text with BERT and project in BERT vocabulary Input text tokens Pass the tokens to BERT and obtain hidden vectors Compute importance of the token in the vocab for a token of the input Score of each token in the vocabulary is Formal et al. SPLADE: Sparse lexical and expansion model for first stage ranking. SIGIR'21 short paper. (link) Formal et al. SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval. 2021. (link) 28
dot-product Sparse Regularization [2] , where B is the batch size Total loss: , where is the on query is the on document [1] Formal et al. SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval. 2021. (link) [2] Paria el al. Minimizing FLOPs to Learn Efficient Sparse Representations. ICLR 2020. (link) 29
Generate triplets , along with similarity scores for , predicted by the CE. Fine-tune SPLADE with the triplets using Margin-MSE loss where : similarity score returned by the teacher model : similarity score returned by the student model Formal et al. SPLADE v2: Sparse Lexical and Expansion Model for Information Retrieval. 2021. (link) Hofstätter et al. Improving Efficient Neural Ranking Models with Cross-Architecture Knowledge Distillation. 2020. (link) 30
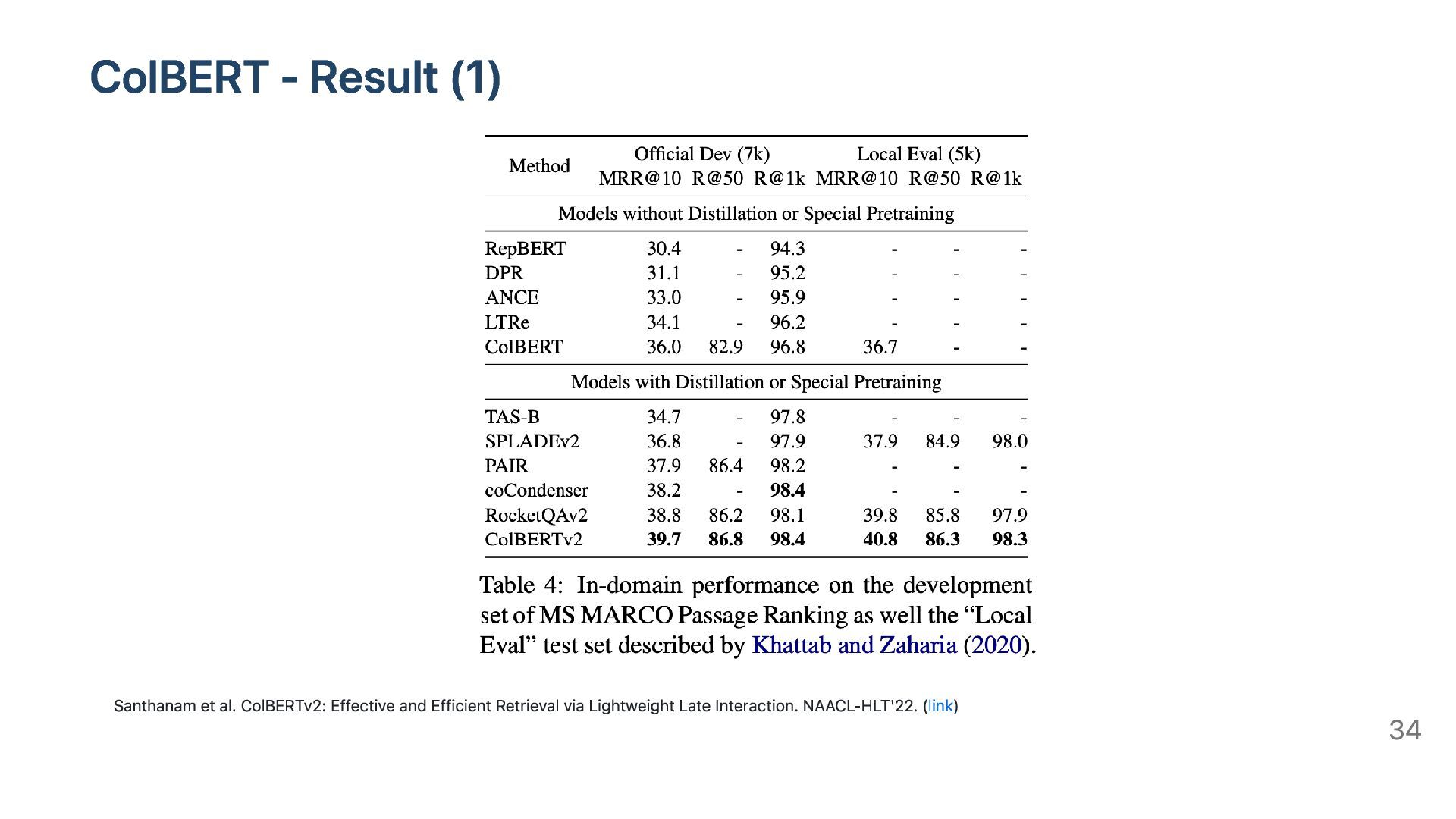
score between query q and document d with maxsim operator: Advantages Enable offline document indexing like Bi-Encoder Analyze interaction between every tokens in query and document like Cross-Encoder. Disadvantage Slower and consume more storage than Bi-Encoder Credit: Khattab and Zaharia. Colbert: Efficient and effective passage search via contextualized late interaction over bert. SIGIR'20. (link) 33
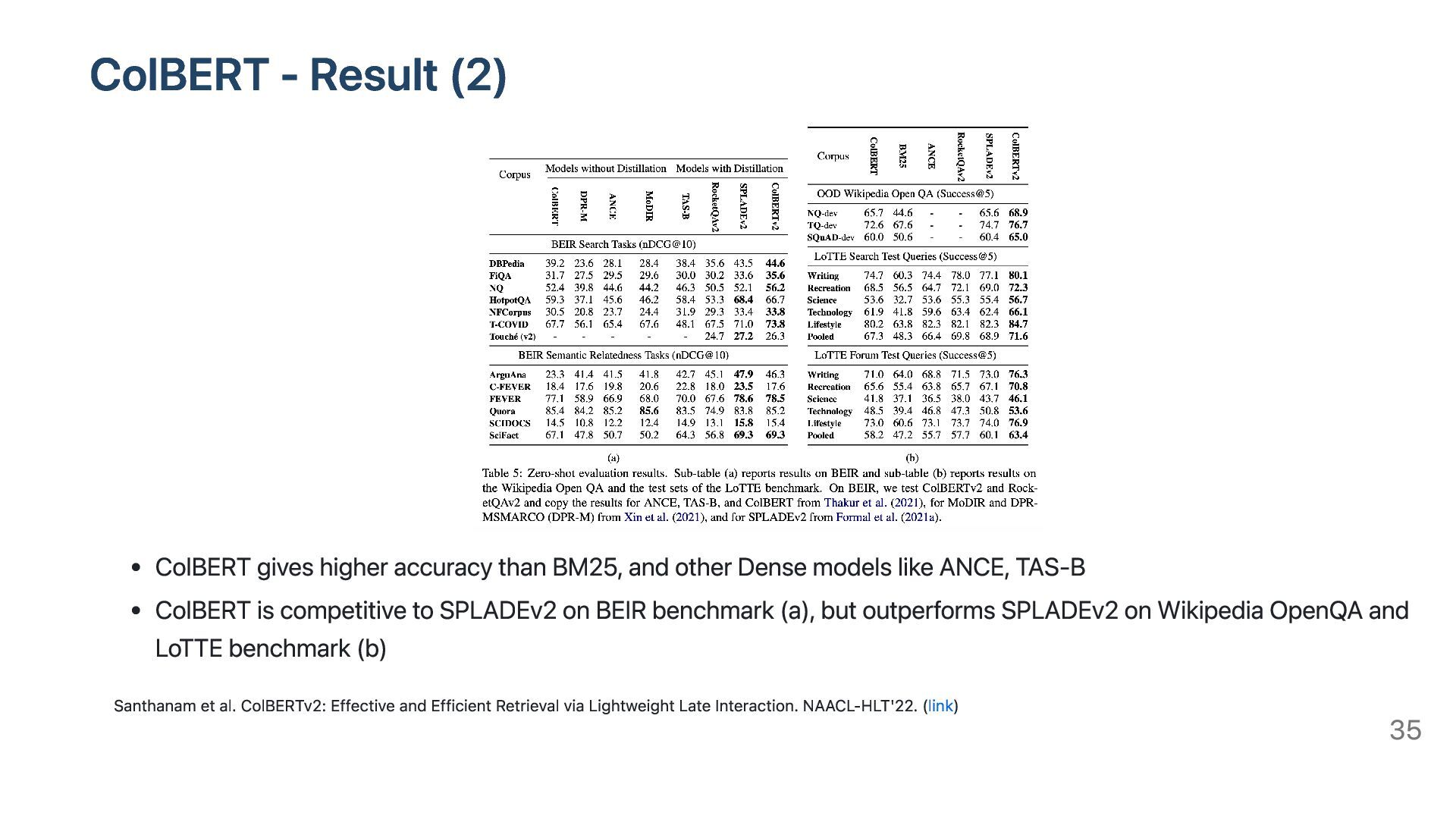
and other Dense models like ANCE, TAS-B ColBERT is competitive to SPLADEv2 on BEIR benchmark (a), but outperforms SPLADEv2 on Wikipedia OpenQA and LoTTE benchmark (b) Santhanam et al. ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction. NAACL-HLT'22. (link) 35
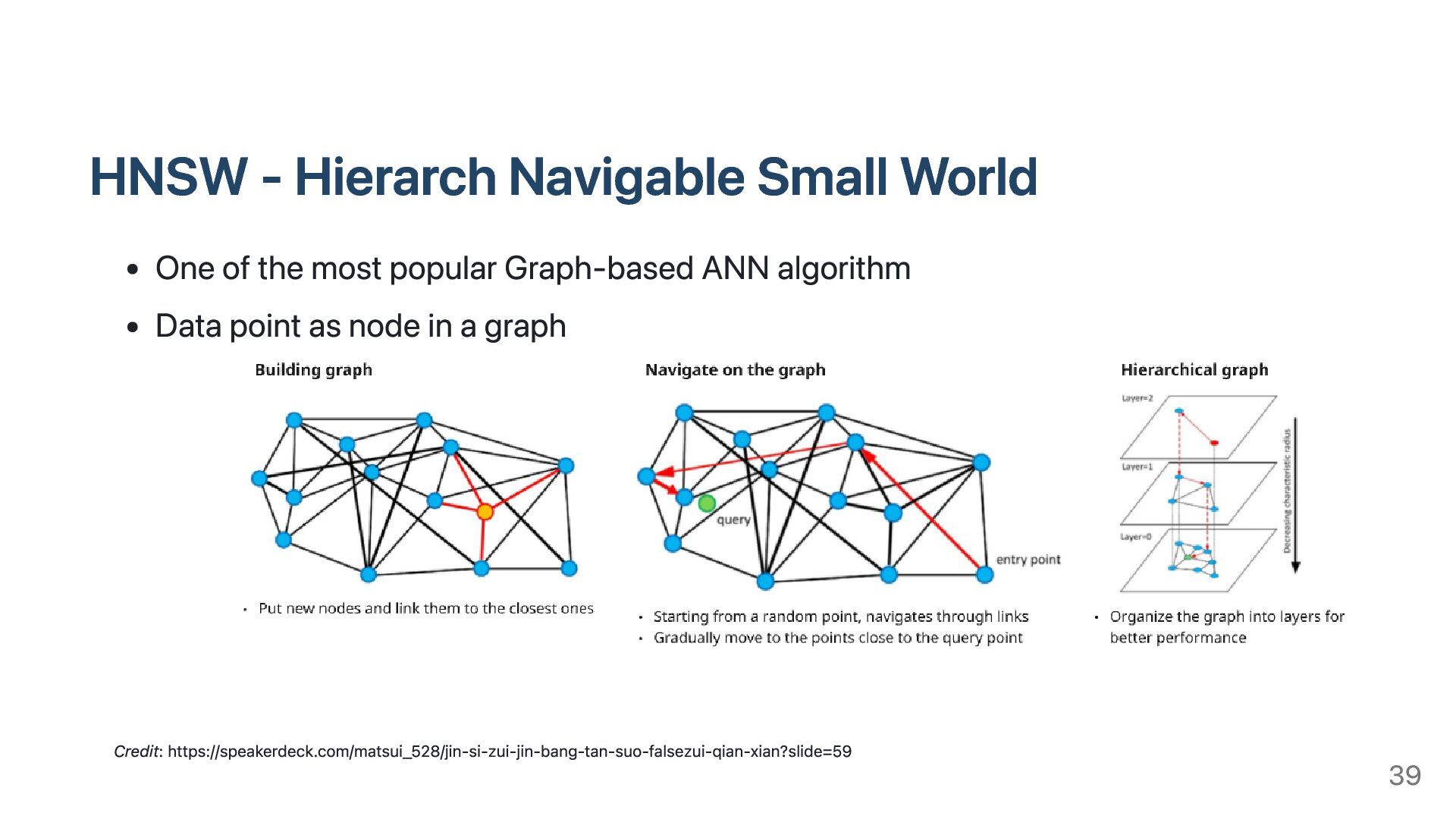
vector search becomes more crucial Necessary on searching for data in multi modality ANN: Approximate Nearest Neighbor Search for data points that are very close to the given query point, but not necessarily the closest. Better scalability than methods with absolute solutions. Common approaches for ANN: Tree, hash, graph 38
popular Graph-based ANN algorithm Data point as node in a graph Credit: https://speakerdeck.com/matsui_528/jin-si-zui-jin-bang-tan-suo-falsezui-qian-xian?slide=59 39
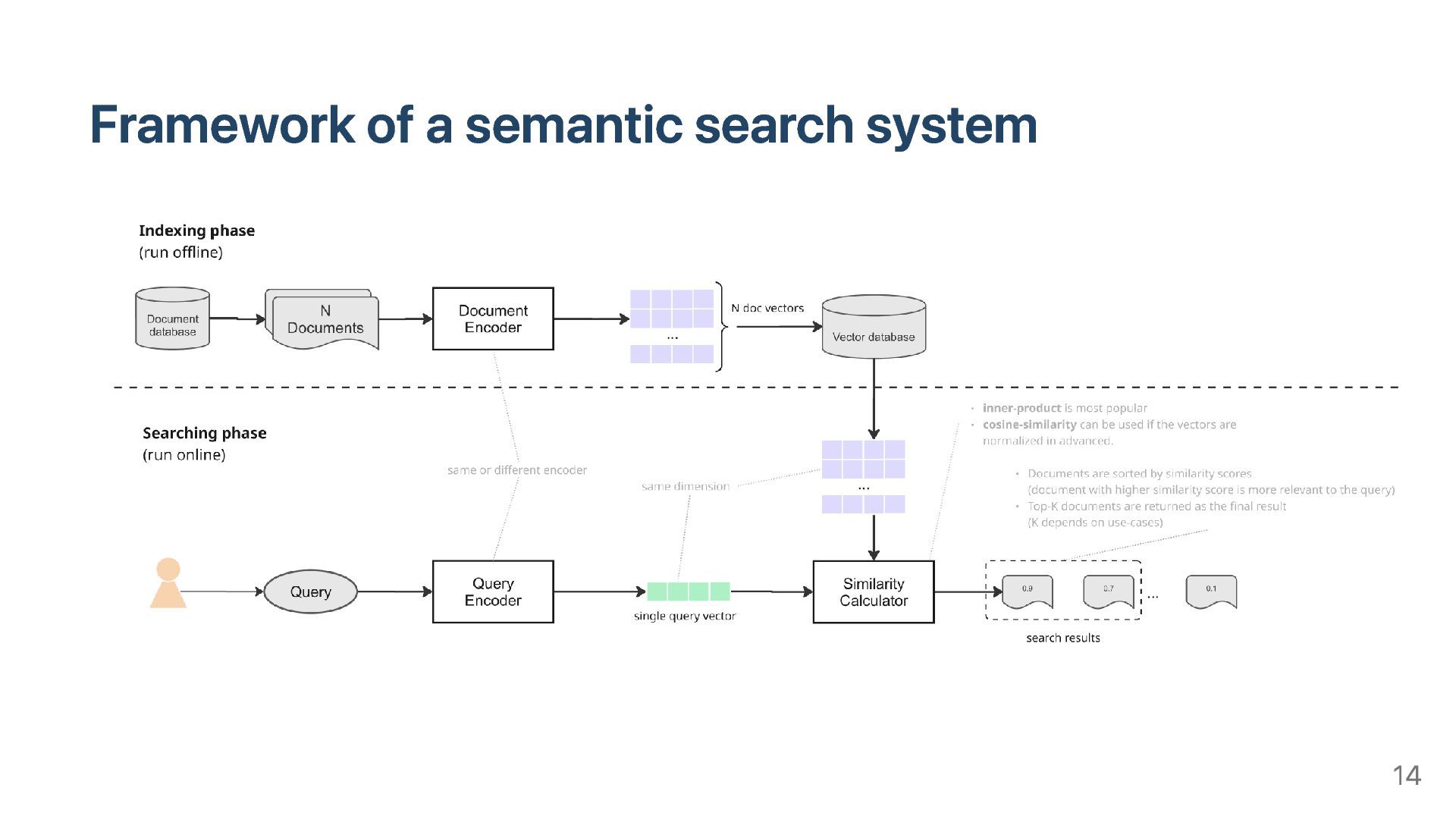
Search models heavily depend on transformer-based Neural network. Semantic search consists of 2 steps Encode query and documents to vectors Search document vectors which are close to given query vector There are 2 types of Semantic Search models: Dense vector-based model: DPR, ColBERT... Sparse vector-based model: SPLADE 40
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![SPLADE - Training Ranking loss-InfoNCE [1] In SPLADE, sim is](https://files.speakerdeck.com/presentations/56c40f41caca4c82abf35f4b9a39e840/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}