Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
NIIにおける大規模言語モデル構築事業の現在地
Search
Yusuke Oda
December 07, 2025
3.4k
7
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
NIIにおける大規模言語モデル構築事業の現在地
人工知能学会合同研究会 招待講演資料
2025-12-01 慶応大学日吉キャンパス
Yusuke Oda
December 07, 2025
More Decks by Yusuke Oda
See All by Yusuke Oda
LLM-jp-3 and beyond: Training Large Language Models
odashi
1
890
Collaborative Development of Foundation Models at Japanese Academia
odashi
2
660
Featured
See All Featured
Everyday Curiosity
cassininazir
0
260
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
Code Reviewing Like a Champion
maltzj
528
40k
Raft: Consensus for Rubyists
vanstee
141
7.6k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
Thoughts on Productivity
jonyablonski
76
5.2k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
180
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Transcript
NIIにおける 大規模言語モデル構築事業の現在地 小田 悠介 (国立情報学研究所) 2025-12-01 人工知能学会合同研究会2025 LLM-jp
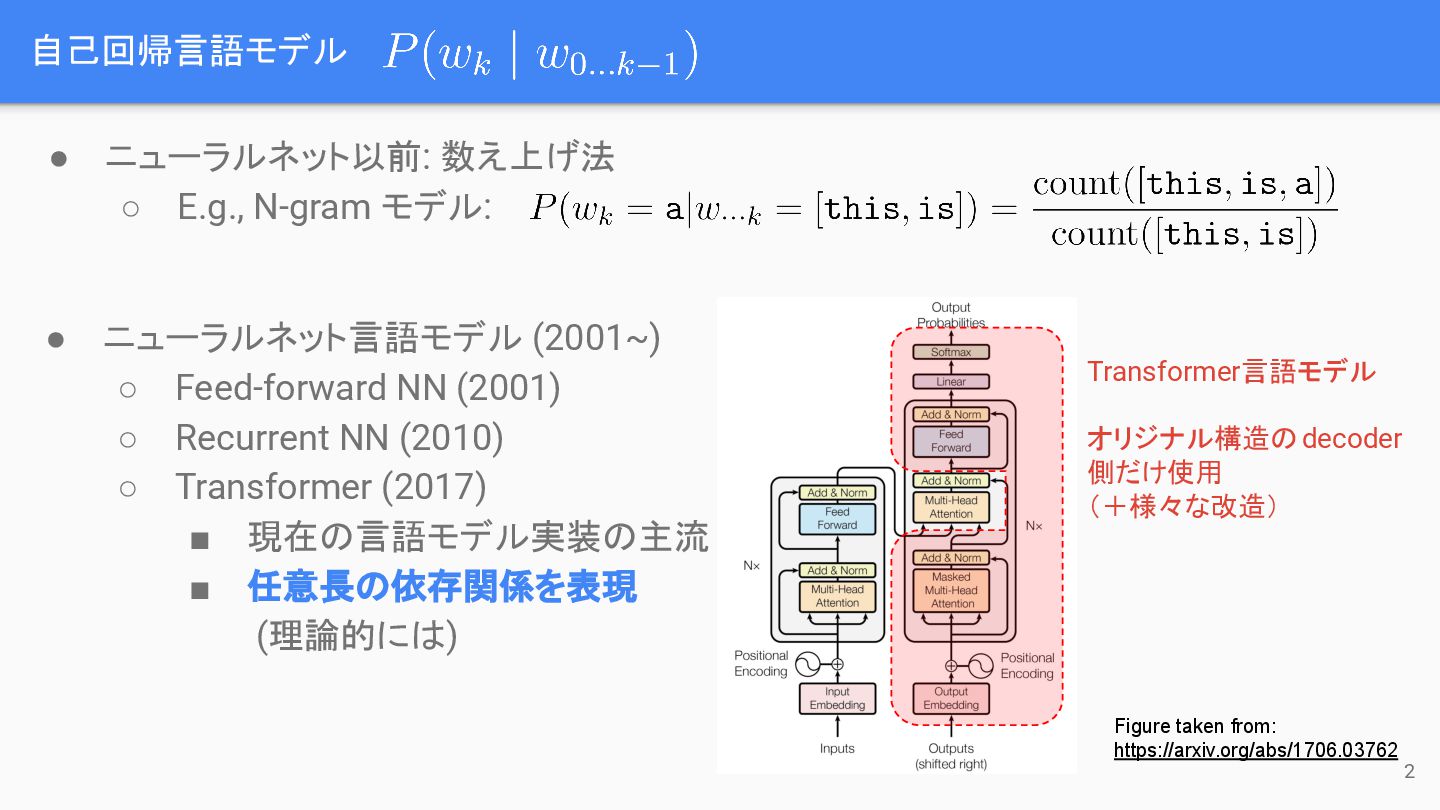
自己回帰言語モデル • ニューラルネット以前: 数え上げ法 ◦ E.g., N-gram モデル: • ニューラルネット言語モデル
(2001~) ◦ Feed-forward NN (2001) ◦ Recurrent NN (2010) ◦ Transformer (2017) ▪ 現在の言語モデル実装の主流 ▪ 任意長の依存関係を表現 (理論的には) Figure taken from: https://arxiv.org/abs/1706.03762 Transformer言語モデル オリジナル構造のdecoder 側だけ使用 (+様々な改造) 2
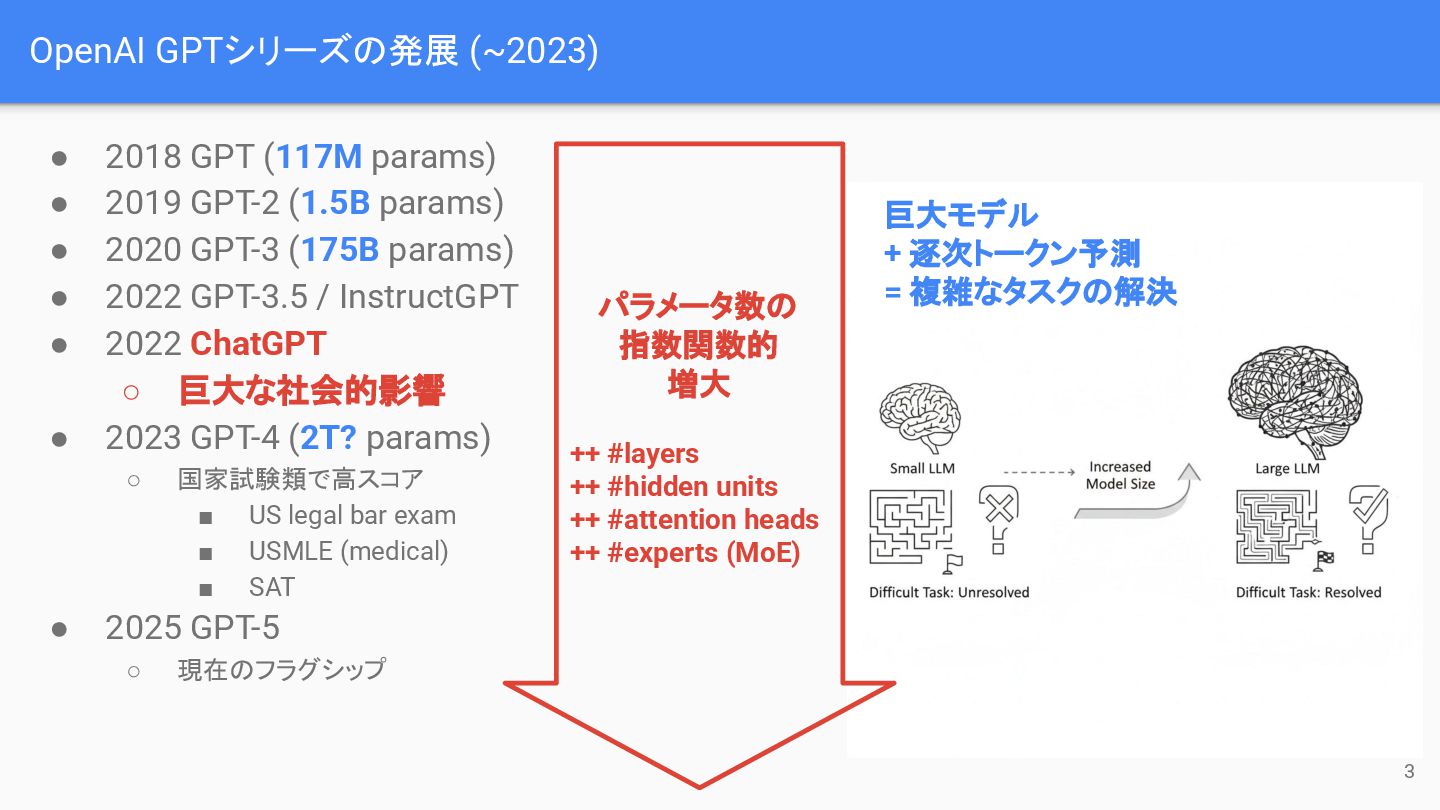
OpenAI GPTシリーズの発展 (~2023) • 2018 GPT (117M params) • 2019
GPT-2 (1.5B params) • 2020 GPT-3 (175B params) • 2022 GPT-3.5 / InstructGPT • 2022 ChatGPT ◦ 巨大な社会的影響 • 2023 GPT-4 (2T? params) ◦ 国家試験類で高スコア ▪ US legal bar exam ▪ USMLE (medical) ▪ SAT • 2025 GPT-5 ◦ 現在のフラグシップ パラメータ数の 指数関数的 増大 ++ #layers ++ #hidden units ++ #attention heads ++ #experts (MoE) 巨大モデル + 逐次トークン予測 = 複雑なタスクの解決 3
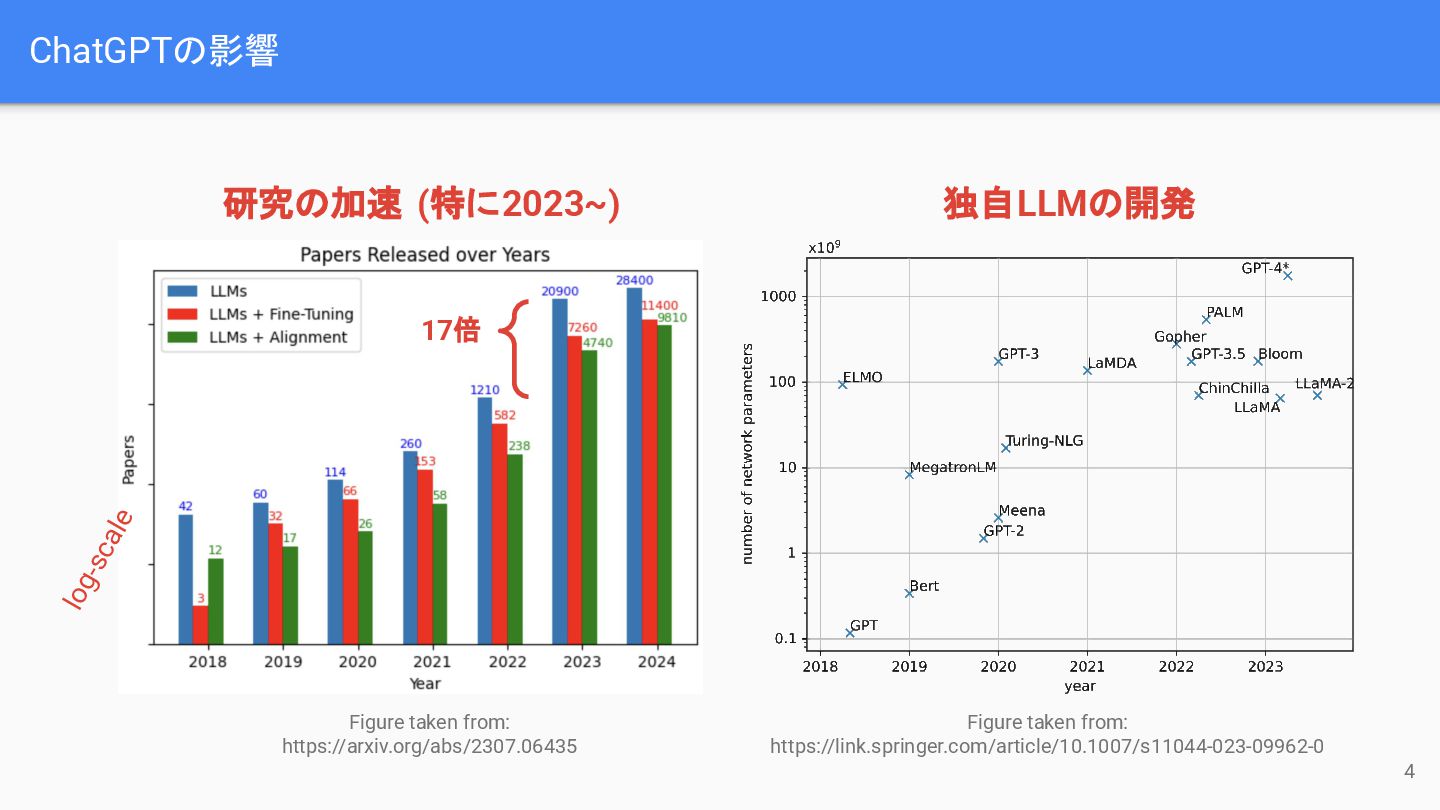
ChatGPTの影響 Figure taken from: https://arxiv.org/abs/2307.06435 Figure taken from: https://link.springer.com/article/10.1007/s11044-023-09962-0 研究の加速
(特に2023~) 独自LLMの開発 log-scale 4 17倍
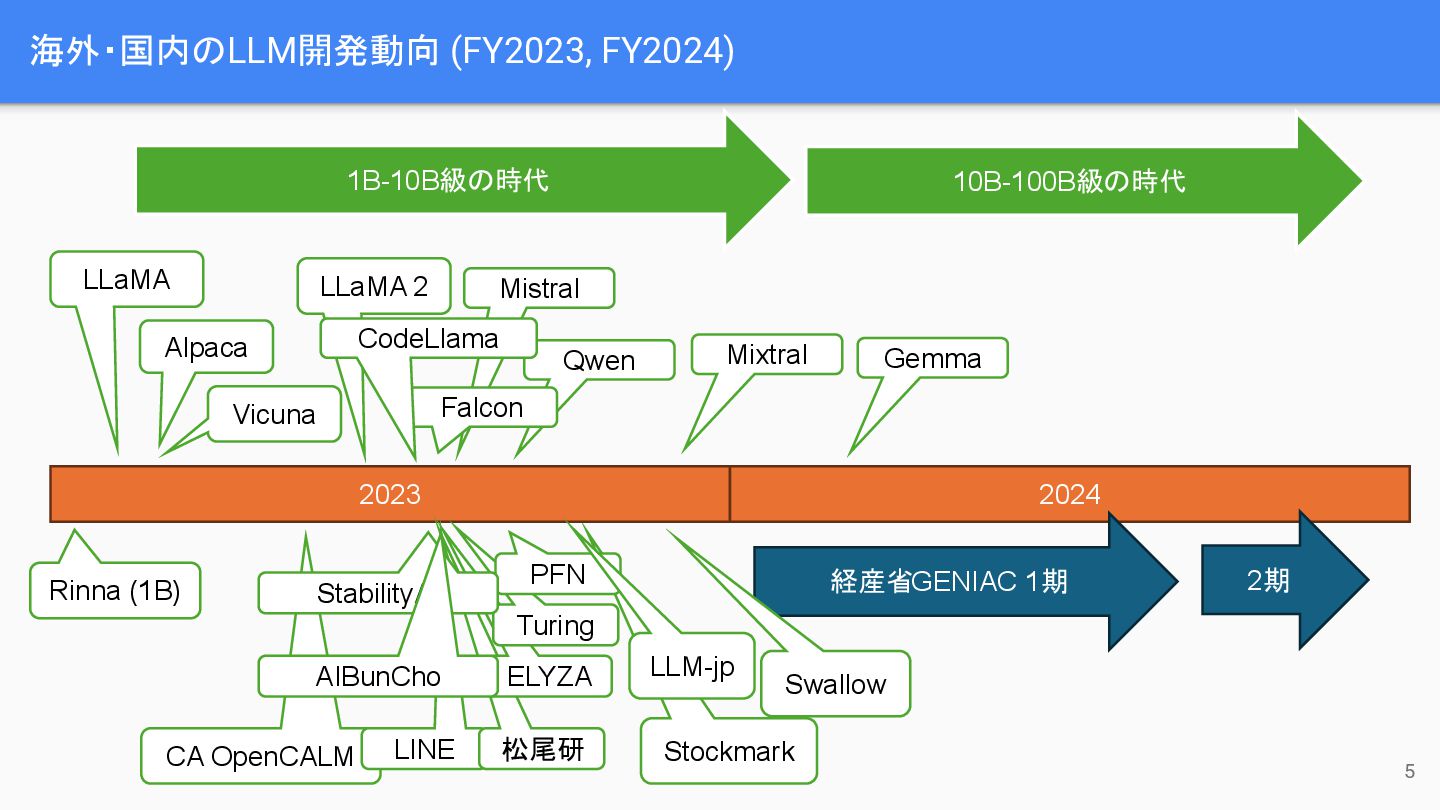
海外・国内のLLM開発動向 (FY2023, FY2024) 5 Stockmark Qwen CA OpenCALM 2023 LLaMA
Alpaca Vicuna Rinna (1B) LLaMA 2 LINE 松尾研 ELYZA Mistral Turing PFN StabilityAI AIBunCho Falcon CodeLlama LLM-jp 2024 経産省GENIAC 1期 Mixtral Swallow Gemma 1B-10B級の時代 10B-100B級の時代 2期
LLM-jp LLM-jp (LLM勉強会) • 日本語LLMを構築するためのオープンサイエンス組織(NII主宰) ◦ LLMの動作原理を究明 ◦ モデル・データ・ツールなど成果物の公開 ▪
成功事例だけでなく失敗事例も共有 • ポリシーに賛同する人は誰でも参加可能 2023-05: First meetup 2023-10: First 13B model 2024-09: LLM-jp-3 ~13B (7 models) 2024-12: LLM-jp-3 172B 2025-05: LLM-jp-3.1 (3 models) 2025-03: LLM-jp-3 MoE 8x1.8B, 8x13B Now: Training v4 models 2000~ 参加者 30名のNLP研究者で 開始 2024-04: NII LLM研究開発センター (LLMC) 6
なぜ日本でLLM開発? (1) • 地域固有の知識の担保 ◦ 英語・中国語モデルにおける日本関係知識の欠落 ▪ 最先端モデルは賢いが、データ入手困難な地域固有の常識・知識は欠落 ▪ 地域(=日本)の情報はその地域で主体的に研究開発する必要性
Japanese languages Japanese culture Geolocational information in/around Japan 7
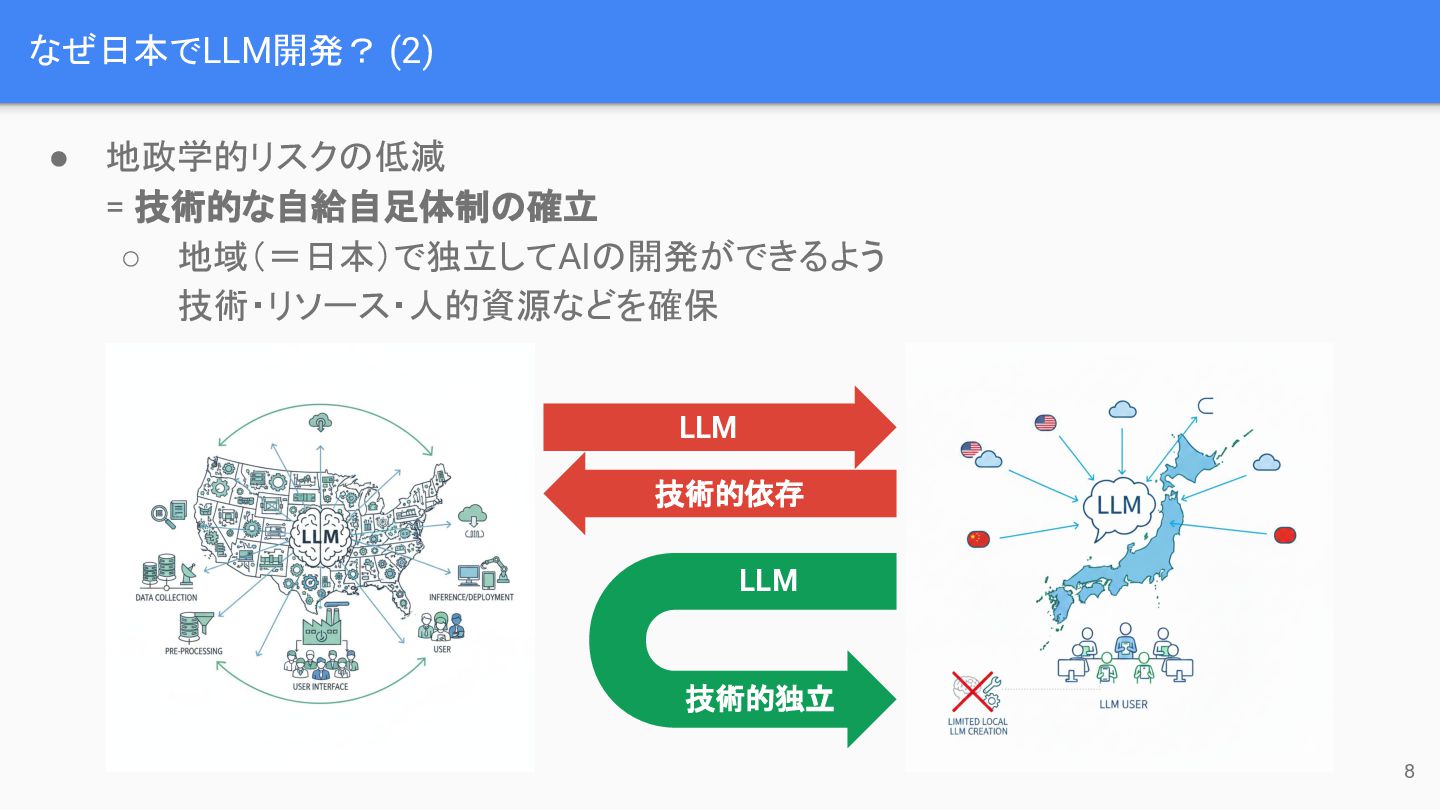
なぜ日本でLLM開発? (2) • 地政学的リスクの低減 = 技術的な自給自足体制の確立 ◦ 地域(=日本)で独立してAIの開発ができるよう 技術・リソース・人的資源などを確保 LLM
技術的依存 LLM 8 技術的独立
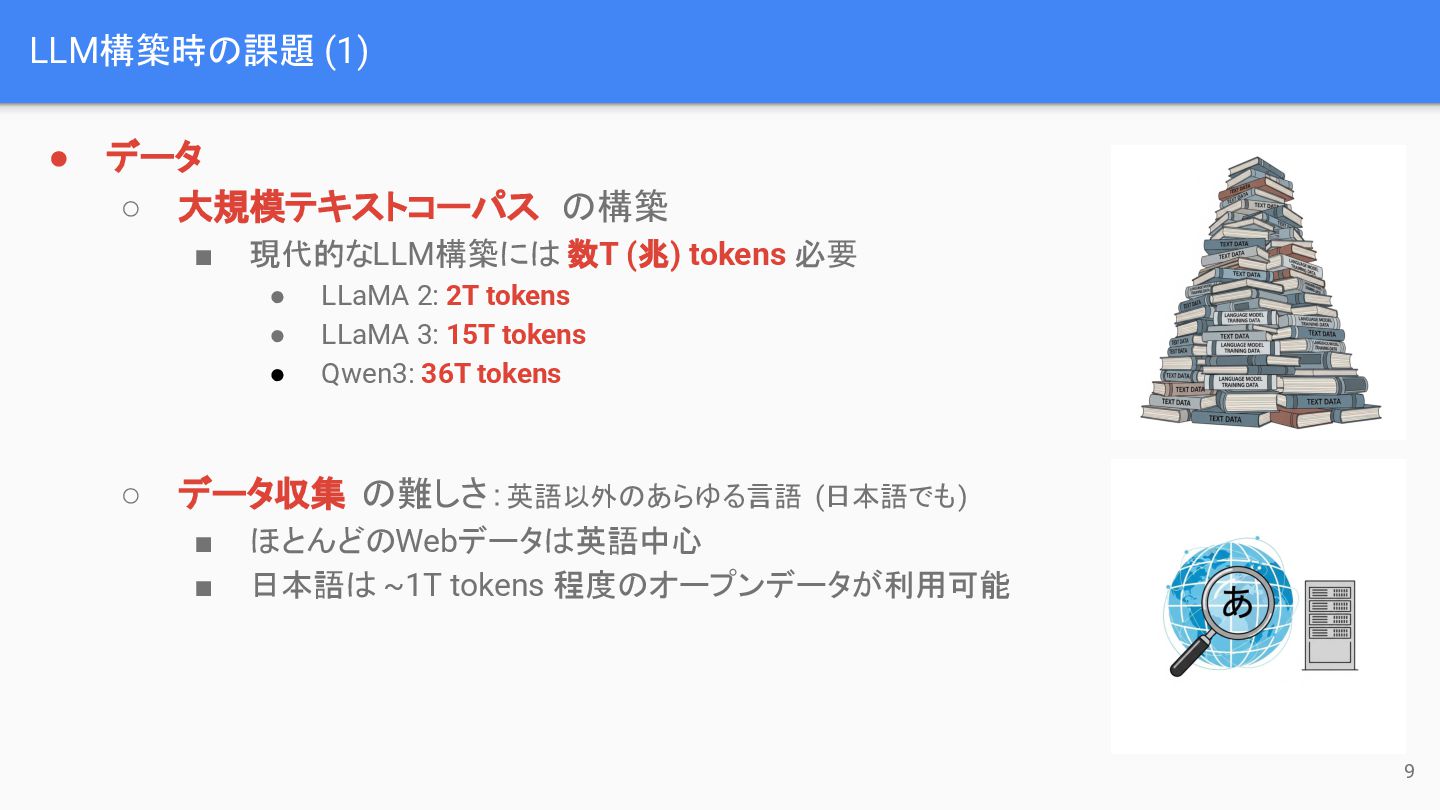
LLM構築時の課題 (1) • データ ◦ 大規模テキストコーパス の構築 ▪ 現代的なLLM構築には 数T
(兆) tokens 必要 • LLaMA 2: 2T tokens • LLaMA 3: 15T tokens • Qwen3: 36T tokens ◦ データ収集 の難しさ:英語以外のあらゆる言語 (日本語でも) ▪ ほとんどのWebデータは英語中心 ▪ 日本語は ~1T tokens 程度のオープンデータが利用可能 9
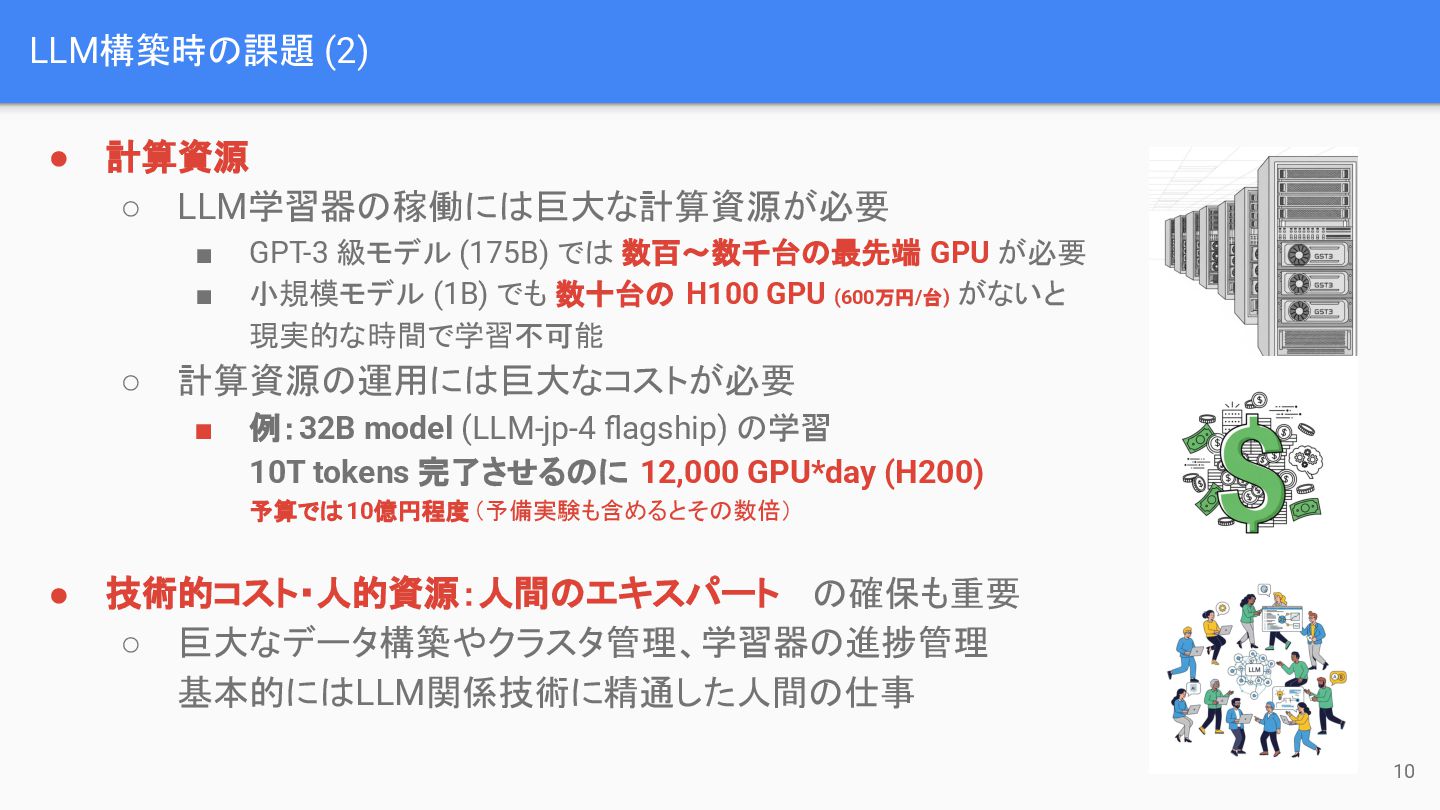
LLM構築時の課題 (2) • 計算資源 ◦ LLM学習器の稼働には巨大な計算資源が必要 ▪ GPT-3 級モデル (175B)
では 数百~数千台の最先端 GPU が必要 ▪ 小規模モデル (1B) でも 数十台の H100 GPU (600万円/台) がないと 現実的な時間で学習不可能 ◦ 計算資源の運用には巨大なコストが必要 ▪ 例:32B model (LLM-jp-4 flagship) の学習 10T tokens 完了させるのに 12,000 GPU*day (H200) 予算では10億円程度(予備実験も含めるとその数倍) • 技術的コスト・人的資源:人間のエキスパート の確保も重要 ◦ 巨大なデータ構築やクラスタ管理、学習器の進捗管理 基本的にはLLM関係技術に精通した人間の仕事 10
政府の支援 (FY2024) 11 経済産業省 ▪ AI橋渡しクラウド (ABCI) ▪ 基盤モデル向け計算能力の提供
▪ インフラ事業者向けの計算資源構築支援 Swallow Project (w/科学大) ▪ 継続学習による日本語強化LLM開発 ▪ GENIAC (NEDO) ▪ 基盤モデル開発事業者への 資金・計算資源援助 ▪ 1期: 大規模基盤モデル開発 ▪ 2期: 応用特化 内閣府 ▪ 戦略的イノベーション創造プログラム (SIP) ▪ 医療向け応用のための基盤モデル開発 総務省 ▪ 情報通信研究機構 (NICT) ▪ 独自コーパス・独自基盤モデル開発 文部科学省 ▪ mdx (東京大学) ▪ 基盤モデル向け計算能力の提供 ▪ 理化学研究所 ▪ Fugaku-LLM ▪ 国立情報学研究所 (NII) ▪ 基盤モデル研究開発拠点の設置 (大規模言語モデル研究開発センター) ▪ LLM勉強会 などなど・・・
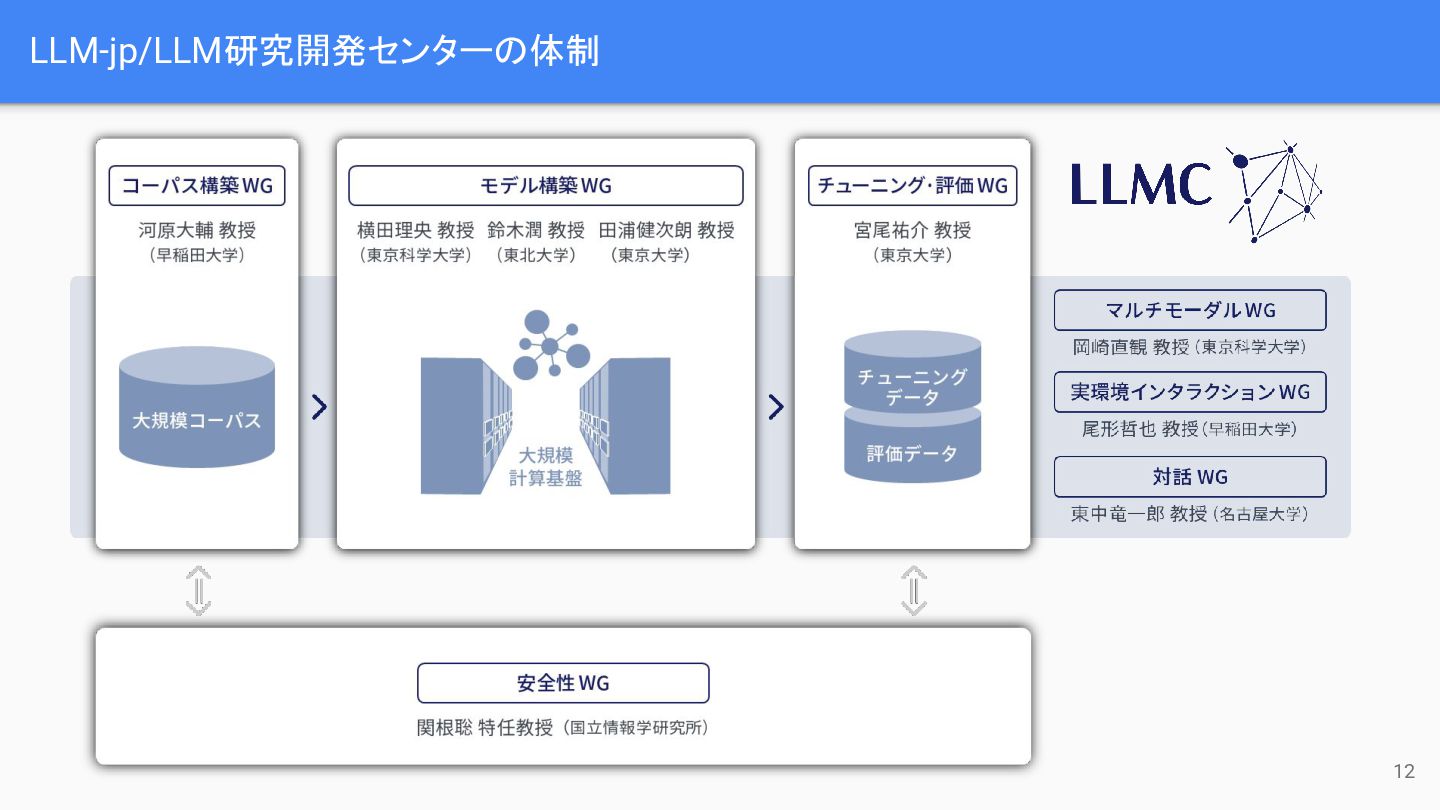
LLM-jp/LLM研究開発センターの体制 12
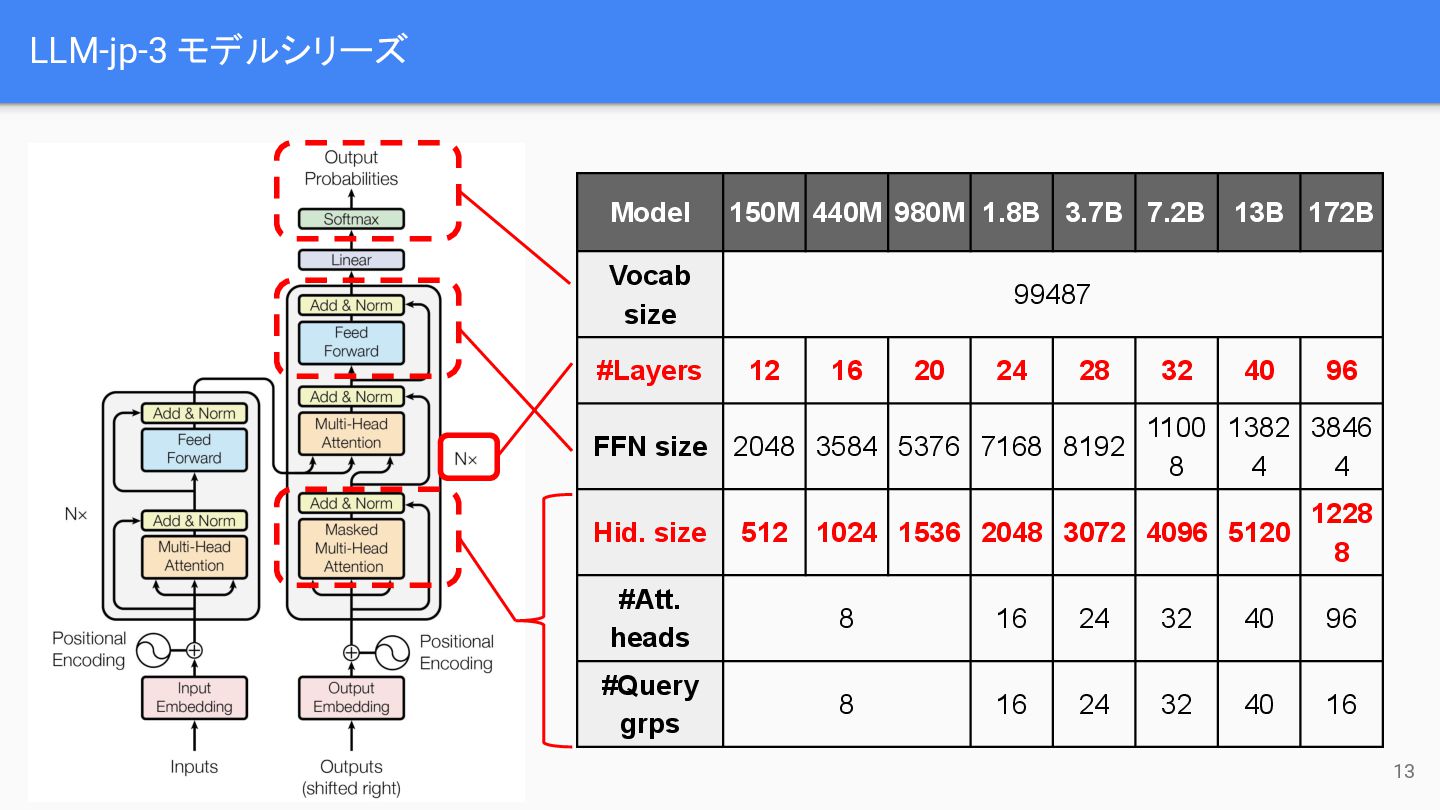
LLM-jp-3 モデルシリーズ Model 150M 440M 980M 1.8B 3.7B 7.2B 13B
172B Vocab size 99487 #Layers 12 16 20 24 28 32 40 96 FFN size 2048 3584 5376 7168 8192 1100 8 1382 4 3846 4 Hid. size 512 1024 1536 2048 3072 4096 5120 1228 8 #Att. heads 8 16 24 32 40 96 #Query grps 8 16 24 32 40 16 13
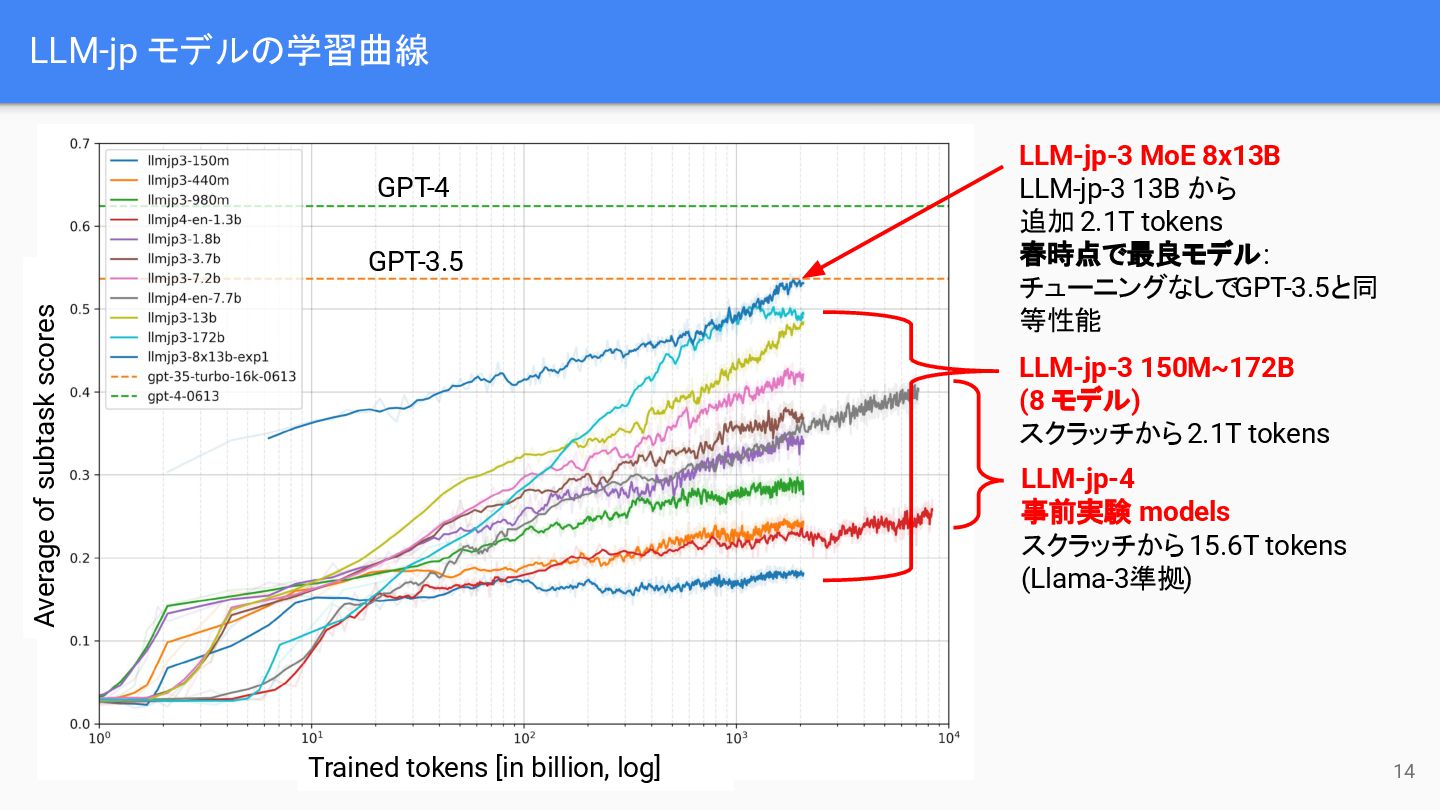
LLM-jp モデルの学習曲線 LLM-jp-3 MoE 8x13B LLM-jp-3 13B から 追加 2.1T
tokens 春時点で最良モデル: チューニングなしでGPT-3.5と同 等性能 LLM-jp-3 150M~172B (8 モデル) スクラッチから 2.1T tokens LLM-jp-4 事前実験 models スクラッチから 15.6T tokens (Llama-3準拠) GPT-3.5 GPT-4 Trained tokens [in billion, log] Average of subtask scores 14
(再掲) NIIにおける 大規模言語モデル構築事業の現在地 とは題しましたが…
今日触れる範囲 16 • NII/LLM-jpの活動は非常に広範 自分も全体を把握していないので 本日は特に深く関与している ◦ コーパス構築 ◦ モデル学習(事前学習)
◦ ポリシーメイキング を中心に紹介します。 • 他の話題で気になる方は是非 LLM-jp にご参加ください! https://llm-jp.nii.ac.jp/ この部分
コーパス構築 17
「兆」スケールコーパスの収集 18 • コーパスの構築 = LLMの開発で最も重要な要素(学習よりも) ◦ 巨大・高品質 コーパスがモデルの性能担保に必要 •
LLM-jpではどう集めているか? ◦ オープンデータ ▪ Common Crawl (CC): 第三者の収集した巨大Webコーパス ◦ 独自のクローリング ◦ 他の研究所との連携 ▪ 国立国会図書館 (NDL) ▪ 国立国語研究所 (NINJAL) ▪ 国文学研究資料館 (NIJL)
NIIと国会図書館の連携 (2024, 2025) 19 2024: 官公庁の Web URLリストの提供 (LLM-jp-3の学習に使用) 2025:
官公庁出版物の OCRデータの提供 (公開モデルには現状不使用)
コーパス比率 (1) 20 • 学習中に各サブセットを 繰り返す回数 の決定 ◦ 多すぎ: 過学習
(コーパス丸覚え等が発生) ◦ 少なすぎ: 学習不足(小規模・高品質コーパスで顕著) ◦ 小規模実験を回し、実際のパフォーマンスを確認しながら調整 • 実際の切り分け実験の例: サブ セット 候補パターン (濃い色=繰り返し回数大)
コーパス比率 (2) 21 LLM-jp-3 Total: 2.1T tokens LLM-jp-4 Total: 22T
tokens • 実際に採用したコーパス比率 (LLM-jp-3/LLM-jp-4) ◦ LLM-jp-3: 日本語と英語をほぼ同量に設定 ◦ LLM-jp-4: 英語の比率を大幅に増加 ▪ 日本語性能が落ちない範囲で調整 ▪ 英語コーパスの方が全体の知識量は多いため、基礎能力確保に有用 10倍
コーパスの有効性の検証 (1) 22 • コーパスの追加設定の検証 (LLM-jp-4) ◦ 5つの候補 ▪ Candidate
1: Stack (coding) を v1 から v2 に変更 ▪ Candidate 2: FineWeb (Web) を少なくして相対的に STEM系データを増強 ▪ Candidate 3: MegaMath (math) の追加 ▪ Candidate 4: Laboro corpus (日英対訳) の追加 ▪ Candidate 5: FinePDFs (OCR済みPDF、テーブルデータ等) の追加 ◦ どの設定が独立して効果があるのかを見積もらなければならない ◦ あらゆる設定で実験するのは不可能 ▪ 32 (=2^5) 回の実験が必要、それぞれ数百万円程度のコスト ▪ 実験回数を減らす必要あり
コーパスの有効性の検証 (2) 23 • 一部実施要因計画法 による効果の測定 ◦ 適用したい設定をon/offの因子として定義 ◦ アルゴリズムで実験設定を決定、その設定で学習
◦ 結果を統合して各因子の有効性を検証 • 実際の受入試験: ◦ 5因子、Resolution IIIの計画 ▪ 実験回数は8回のみ ▪ 主効果のみの測定 効果量 (Cohen's f) F検定のp-value 平均の差分 (on - off) Setting C (Add MegaMath) のみ明確な正の効果あり
モデル学習(事前学習) 24
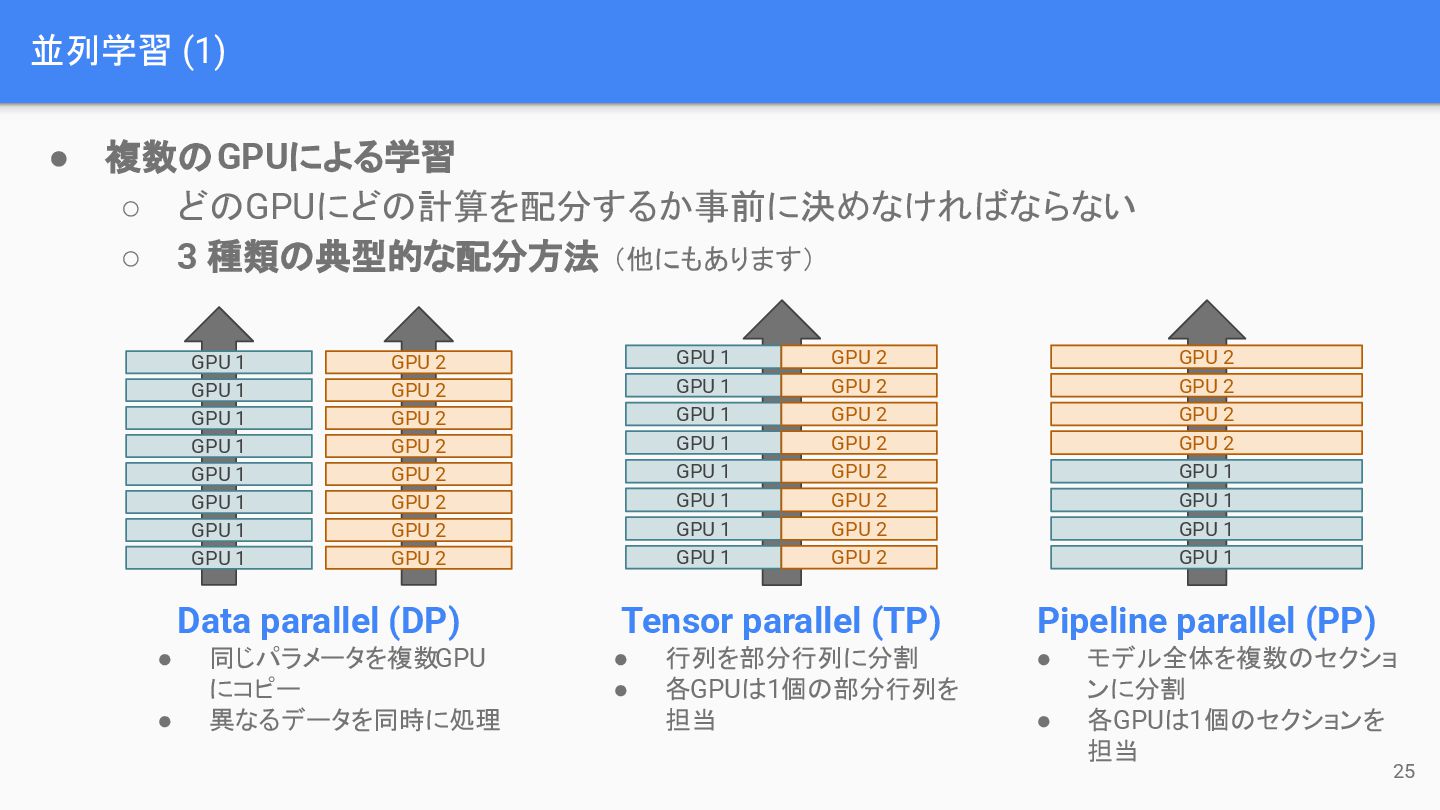
並列学習 (1) 25 • 複数のGPUによる学習 ◦ どのGPUにどの計算を配分するか事前に決めなければならない ◦ 3 種類の典型的な配分方法
(他にもあります) GPU 1 GPU 1 GPU 1 GPU 1 GPU 1 GPU 1 GPU 1 GPU 1 GPU 2 GPU 2 GPU 2 GPU 2 GPU 2 GPU 2 GPU 2 GPU 2 GPU 1 GPU 1 GPU 1 GPU 1 GPU 1 GPU 1 GPU 1 GPU 1 GPU 2 GPU 2 GPU 2 GPU 2 GPU 2 GPU 2 GPU 2 GPU 2 GPU 2 GPU 2 GPU 2 GPU 2 GPU 1 GPU 1 GPU 1 GPU 1 Data parallel (DP) • 同じパラメータを複数GPU にコピー • 異なるデータを同時に処理 Tensor parallel (TP) • 行列を部分行列に分割 • 各GPUは1個の部分行列を 担当 Pipeline parallel (PP) • モデル全体を複数のセクショ ンに分割 • 各GPUは1個のセクションを 担当
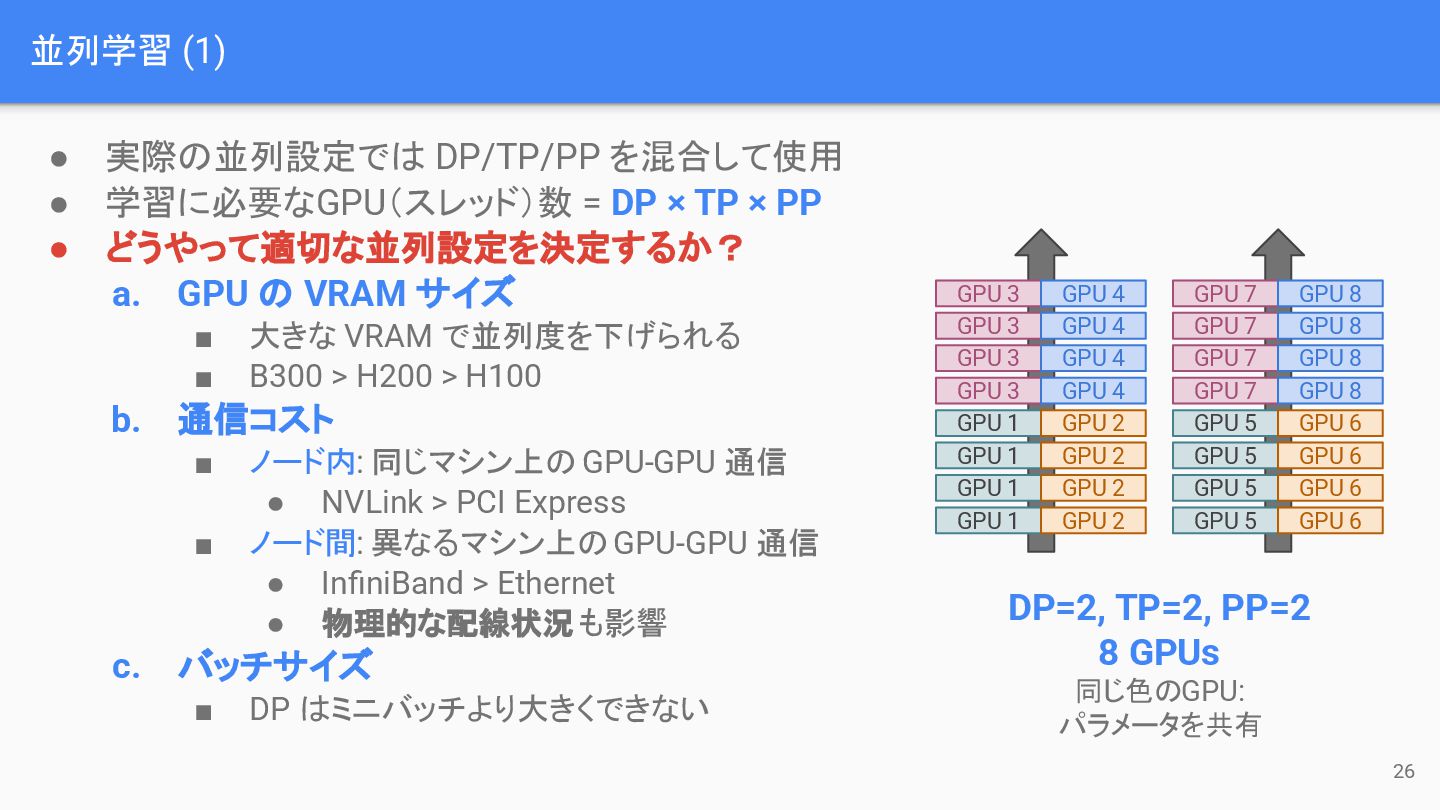
並列学習 (1) 26 • 実際の並列設定では DP/TP/PP を混合して使用 • 学習に必要なGPU(スレッド)数 =
DP × TP × PP • どうやって適切な並列設定を決定するか? a. GPU の VRAM サイズ ▪ 大きな VRAM で並列度を下げられる ▪ B300 > H200 > H100 b. 通信コスト ▪ ノード内: 同じマシン上の GPU-GPU 通信 • NVLink > PCI Express ▪ ノード間: 異なるマシン上の GPU-GPU 通信 • InfiniBand > Ethernet • 物理的な配線状況も影響 c. バッチサイズ ▪ DP はミニバッチより大きくできない GPU 3 GPU 3 GPU 3 GPU 3 GPU 1 GPU 1 GPU 1 GPU 1 GPU 4 GPU 4 GPU 4 GPU 4 GPU 2 GPU 2 GPU 2 GPU 2 GPU 7 GPU 7 GPU 7 GPU 7 GPU 5 GPU 5 GPU 5 GPU 5 GPU 8 GPU 8 GPU 8 GPU 8 GPU 6 GPU 6 GPU 6 GPU 6 DP=2, TP=2, PP=2 8 GPUs 同じ色のGPU: パラメータを共有
並列学習 (3) 27 • LLM-jpモデルでの実際 : LLM-jp-4 32B ◦ パフォーマンス
だけでなく 学習時の安定性 も考慮して 並列設定を決定 採用した設定 最速ではないが確実に動作 最速の設定 しばしばOOM/ハードウェアエラー発生 学習に使用するGPU数とバッチサイズの関係で 採用できない設定も存在
低精度計算 (1) 28 • LLMの学習では 16-bits(半精度)浮動小数点数を利用 ◦ 典型的なビットパターン: BFloat16 (BF16)
▪ 機械学習用に設計 ▪ 8-bits 指数部 • 単精度 (IEEE754 binary32) と同じダイナミックレンジ ▪ 7-bits 仮数部 • 数値の解像度は高くない … 細かい値の違いは気にしない BF16 Single Exponent Fraction Sign
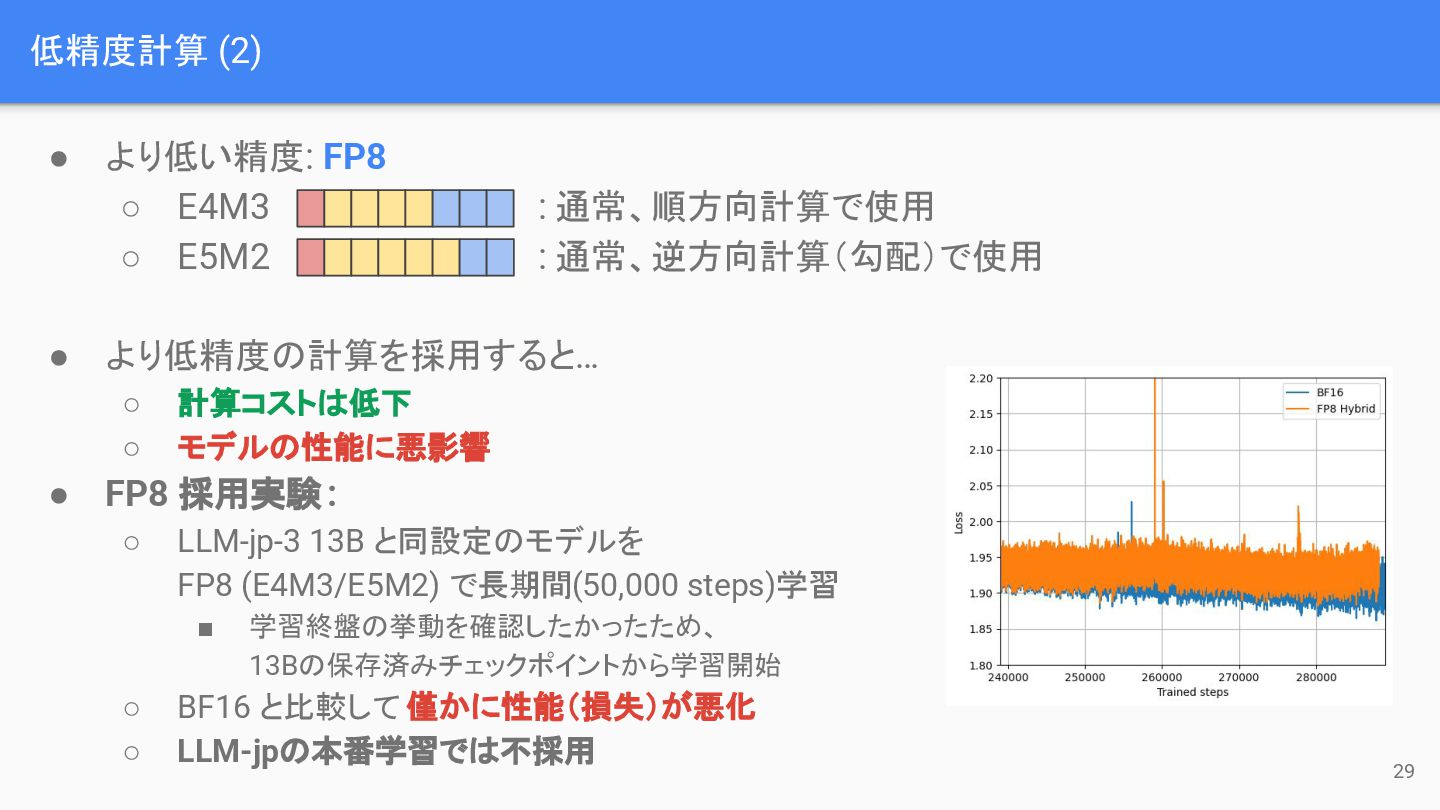
低精度計算 (2) 29 • より低い精度: FP8 ◦ E4M3 : 通常、順方向計算で使用
◦ E5M2 : 通常、逆方向計算(勾配)で使用 • より低精度の計算を採用すると… ◦ 計算コストは低下 ◦ モデルの性能に悪影響 • FP8 採用実験: ◦ LLM-jp-3 13B と同設定のモデルを FP8 (E4M3/E5M2) で長期間(50,000 steps)学習 ▪ 学習終盤の挙動を確認したかったため、 13Bの保存済みチェックポイントから学習開始 ◦ BF16 と比較して 僅かに性能(損失)が悪化 ◦ LLM-jpの本番学習では不採用
学習器の設定 30 • Transformerの学習: 確率的勾配降下法 (SGD) • 実際に用いられるのは AdamW optimizer
◦ SGD + 慣性項 + 勾配の適応的減衰 + 重み減衰 • ハイパーパラメータがいっぱい ◦ 学習率 (η) … モデル依存 (1e-3 ~ 1e-6) ◦ 慣性項の強さ (β1) … 通常 0.9 ◦ 勾配減衰の強さ (β2) … LLMでは通常 0.95 ◦ ゼロ除算回避 (ε) … 通常 1e-8 ◦ 重み減衰 … 通常 0.1 • ひとつでも設定がおかしいと学習がうまくいかない ◦ 多くは経験的に知られている値、強い根拠なし
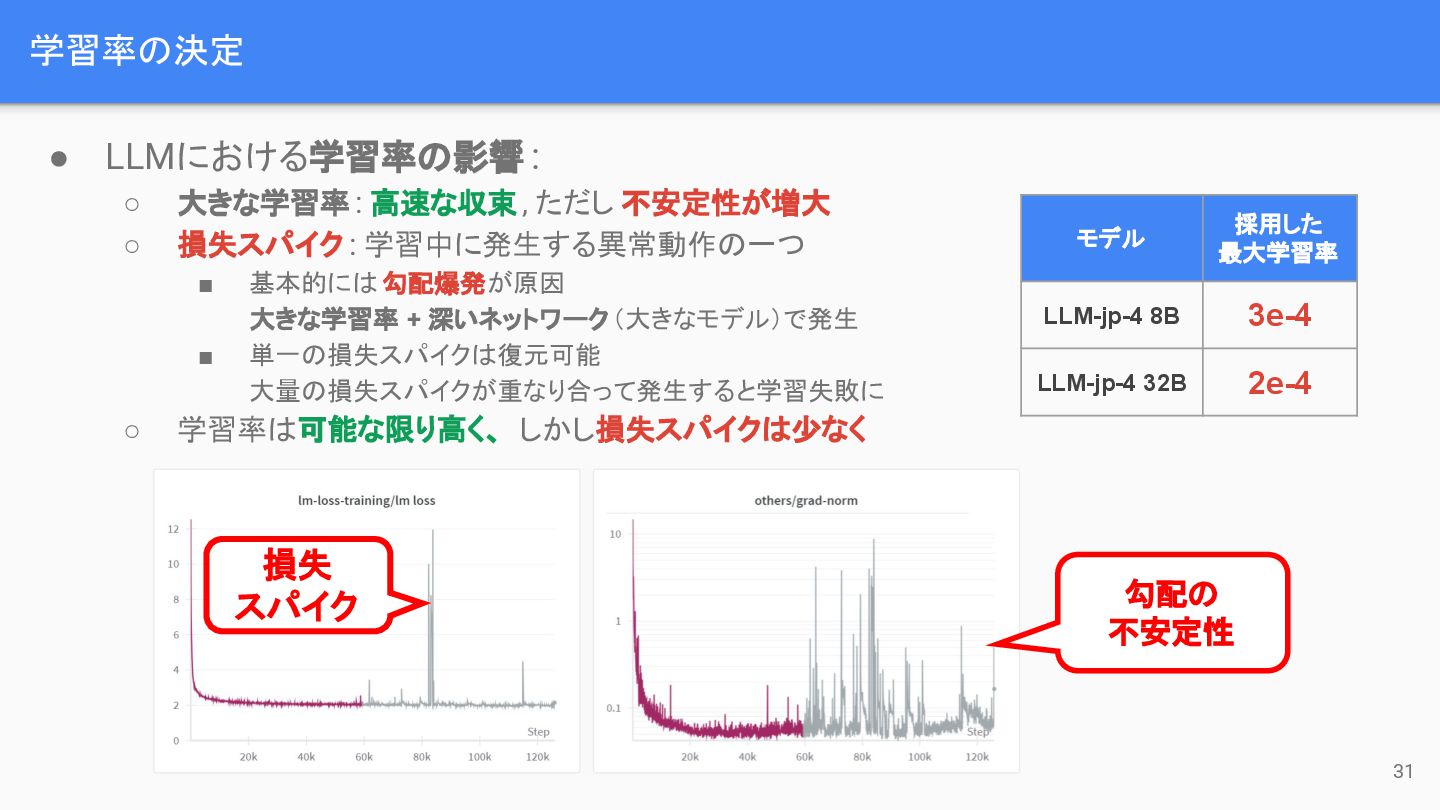
学習率の決定 31 損失 スパイク 勾配の 不安定性 • LLMにおける学習率の影響 : ◦
大きな学習率 : 高速な収束 , ただし 不安定性が増大 ◦ 損失スパイク : 学習中に発生する異常動作の一つ ▪ 基本的には 勾配爆発が原因 大きな学習率 + 深いネットワーク(大きなモデル)で発生 ▪ 単一の損失スパイクは復元可能 大量の損失スパイクが重なり合って発生すると学習失敗に ◦ 学習率は可能な限り高く、 しかし損失スパイクは少なく モデル 採用した 最大学習率 LLM-jp-4 8B 3e-4 LLM-jp-4 32B 2e-4
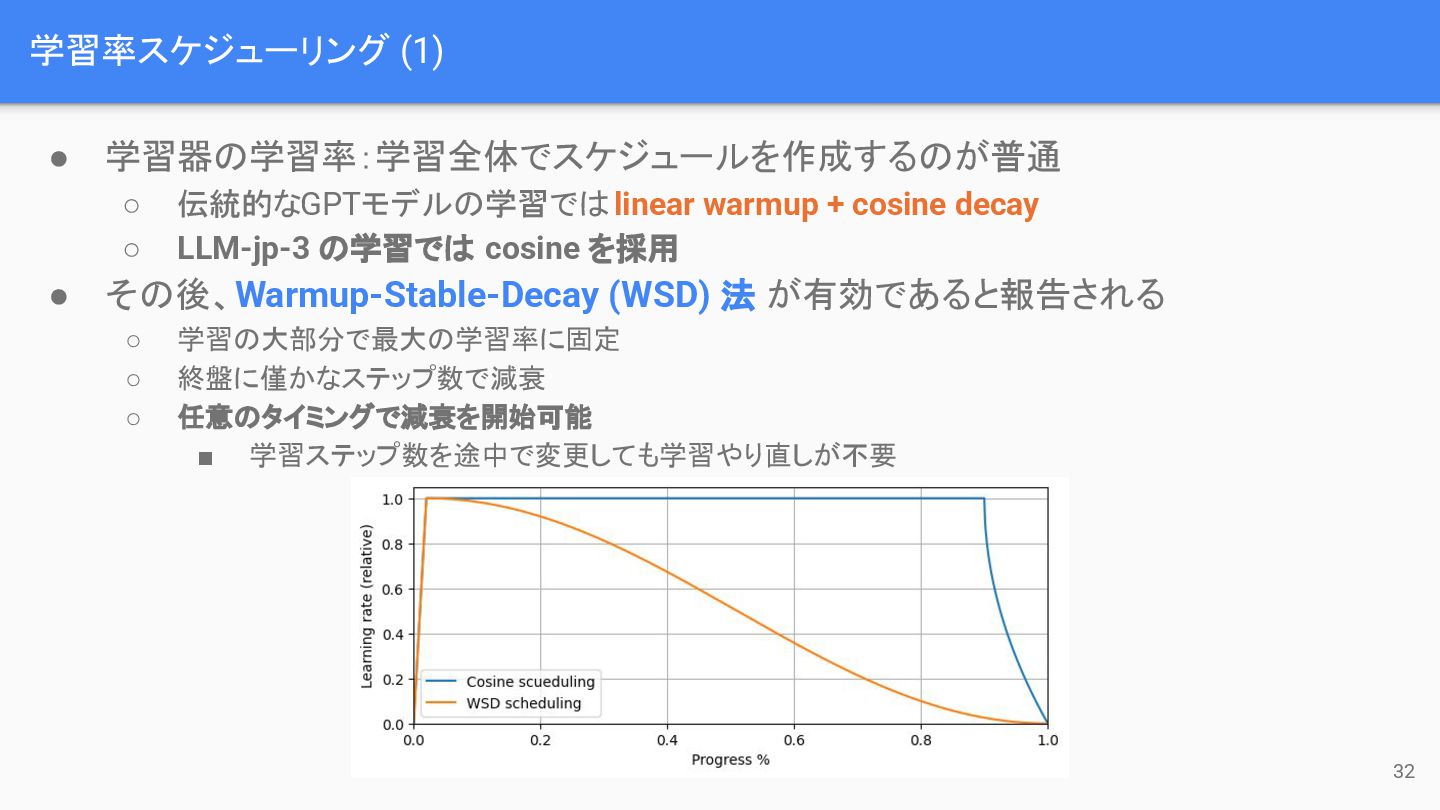
学習率スケジューリング (1) 32 • 学習器の学習率:学習全体でスケジュールを作成するのが普通 ◦ 伝統的なGPTモデルの学習では linear warmup +
cosine decay ◦ LLM-jp-3 の学習では cosine を採用 • その後、Warmup-Stable-Decay (WSD) 法 が有効であると報告される ◦ 学習の大部分で最大の学習率に固定 ◦ 終盤に僅かなステップ数で減衰 ◦ 任意のタイミングで減衰を開始可能 ▪ 学習ステップ数を途中で変更しても学習やり直しが不要
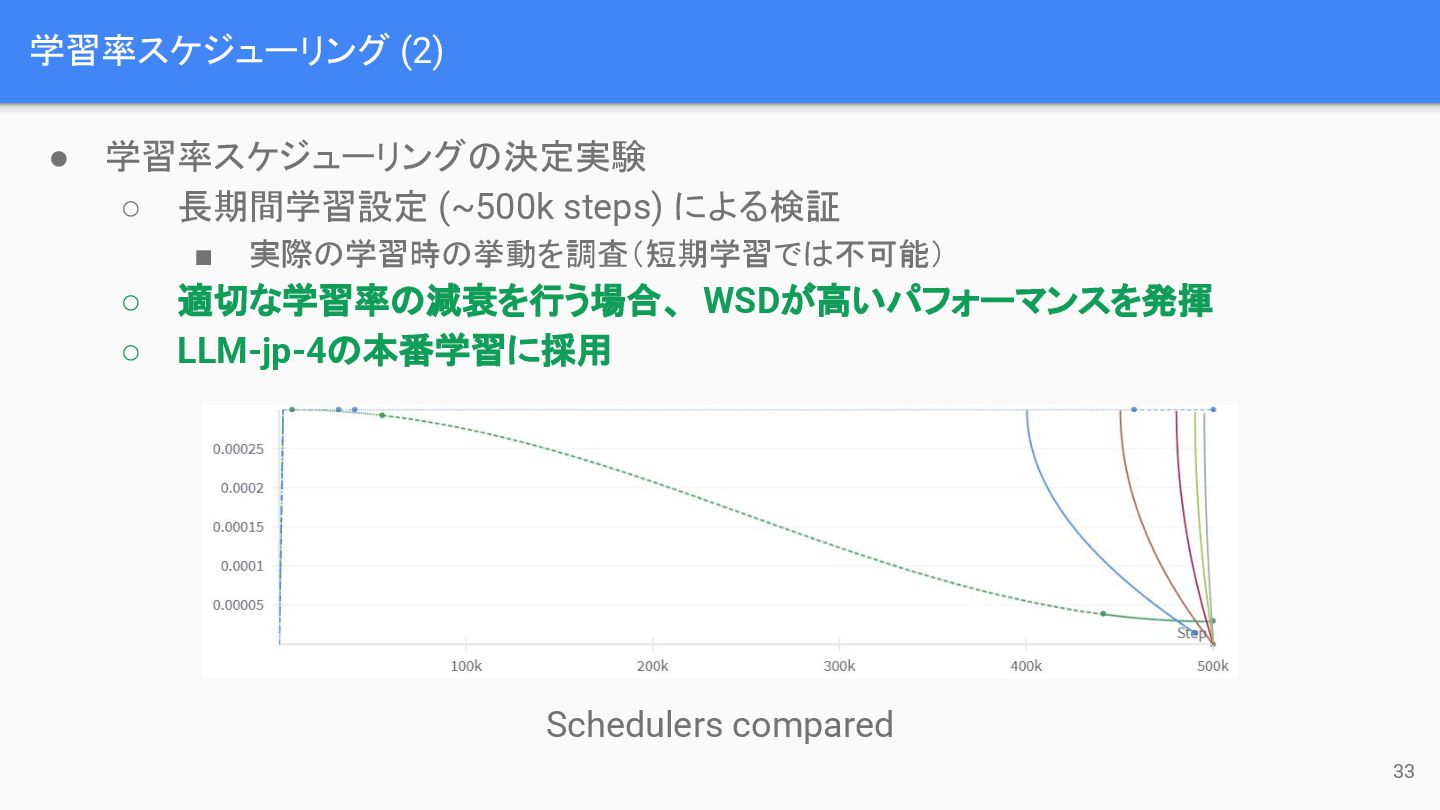
学習率スケジューリング (2) 33 • 学習率スケジューリングの決定実験 ◦ 長期間学習設定 (~500k steps) による検証
▪ 実際の学習時の挙動を調査(短期学習では不可能) ◦ 適切な学習率の減衰を行う場合、 WSDが高いパフォーマンスを発揮 ◦ LLM-jp-4の本番学習に採用 Schedulers compared
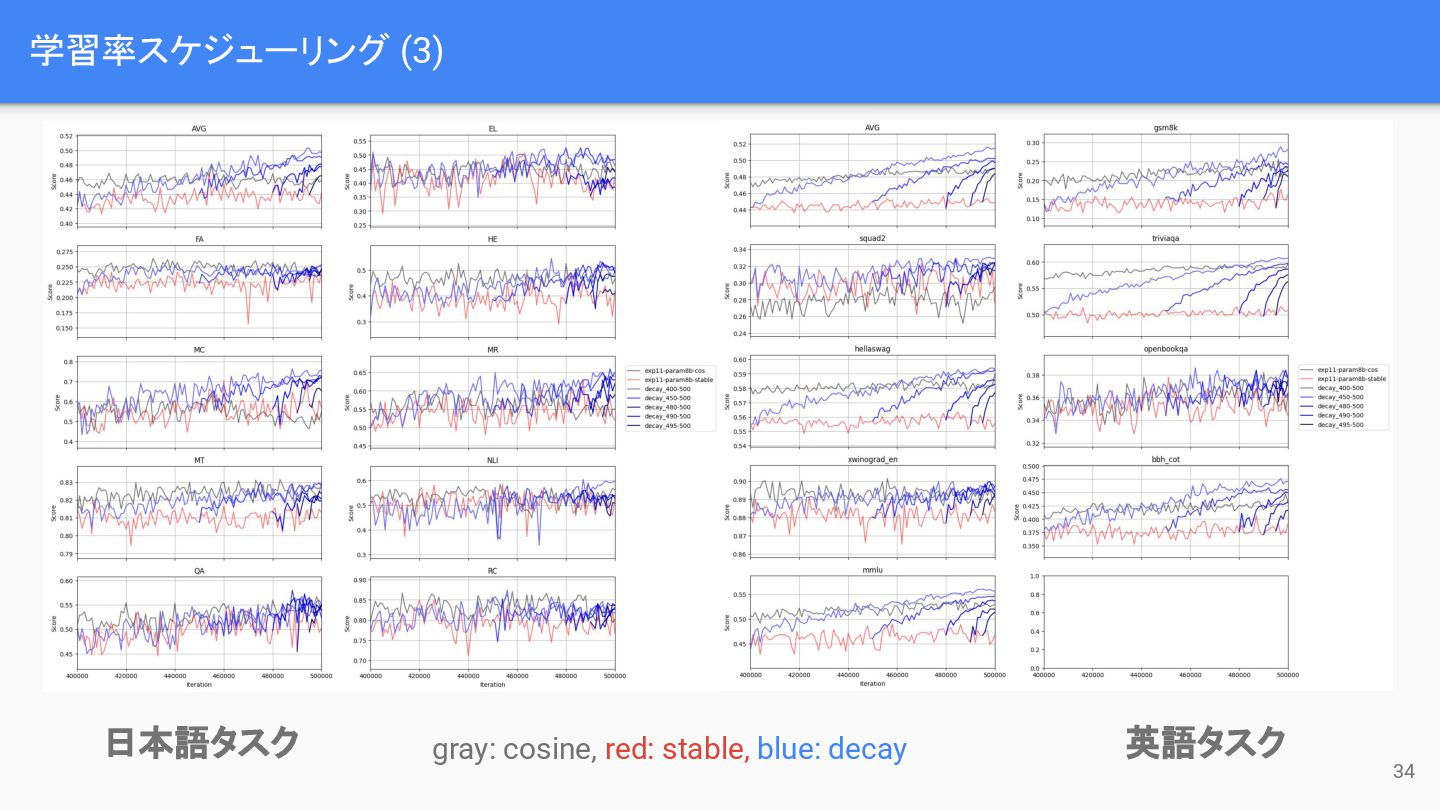
学習率スケジューリング (3) 34 日本語タスク 英語タスク gray: cosine, red: stable, blue:
decay
Adam Epsilon問題 35 • Adam optimizer の Epsilon (ε) ハイパーパラメータ
◦ (実は)モデルの収束に大きな影響 ▪ 可能な限り小さい値にする必要 (< 1e-8) ▪ 当初、Llama2のレポートに従い 1e-5 に設定 • 収束速度が悪化 • この設定でどう学習してもうまくいかない ◦ 恐らく論文の誤記 ◦ 問題発覚時にそれらしい報告なし ◦ 問題観測後、切り分け実験等で上記問題を特定 ▪ 他組織でも同様の問題が発生していることを確認 • →GENIAC等で報告 1e-8: ~3倍高速 1e-5: 非常に遅い収束
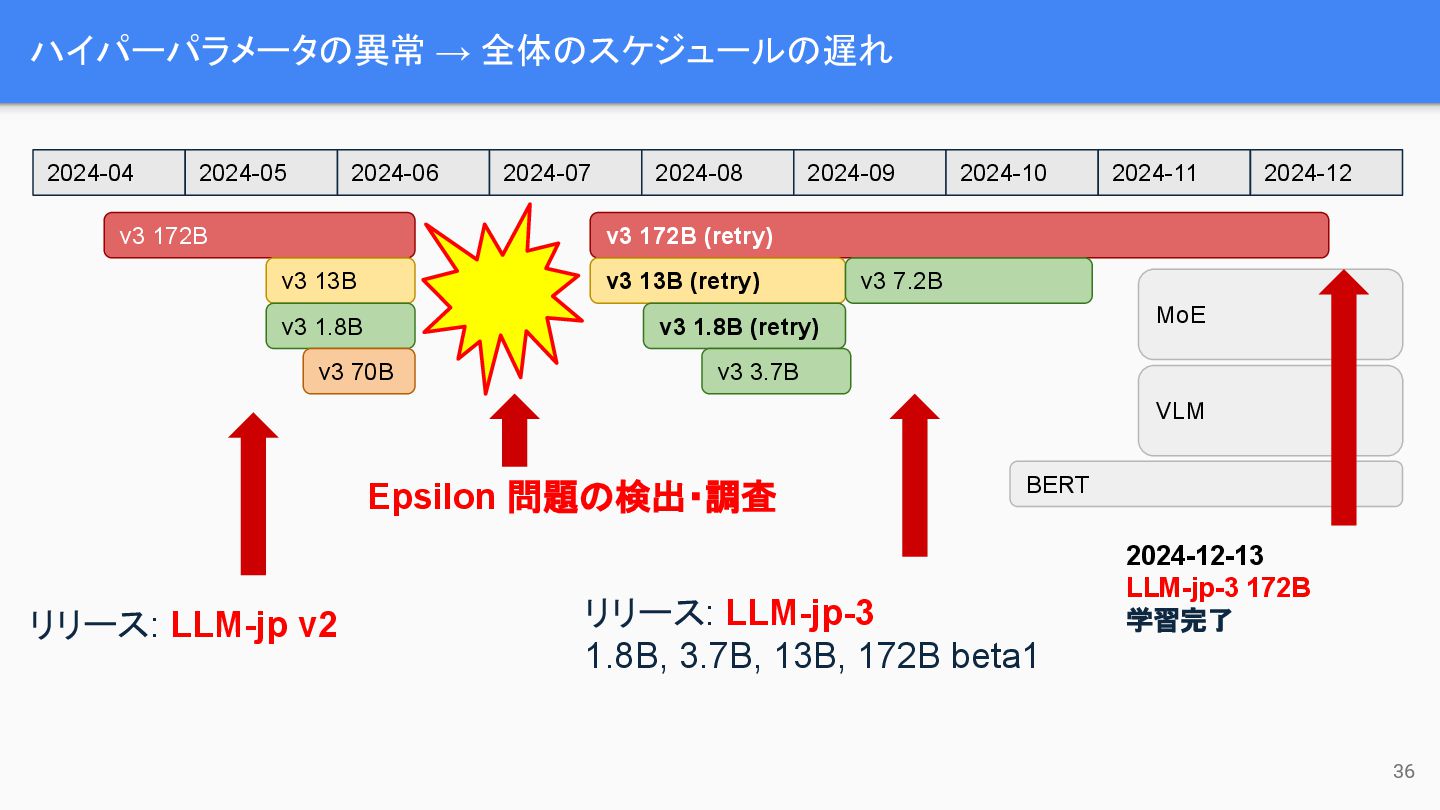
ハイパーパラメータの異常 → 全体のスケジュールの遅れ 36 リリース: LLM-jp v2 v3 172B v3
13B v3 1.8B v3 70B 2024-04 2024-05 2024-06 2024-07 2024-08 2024-09 2024-10 2024-11 2024-12 v3 172B (retry) v3 13B (retry) v3 1.8B (retry) v3 3.7B v3 7.2B リリース: LLM-jp-3 1.8B, 3.7B, 13B, 172B beta1 BERT MoE VLM 2024-12-13 LLM-jp-3 172B 学習完了 Epsilon 問題の検出・調査
ポリシーメイキング 37
LLM-jpとオープンサイエンス 38 • オープンサイエンスの奨励 ◦ LLM-jpは研究成果を広範な人に届けるために活 動している ▪ アカデミアの研究者 ▪
企業の開発者 ▪ ユーザ • LLM-jpの公開する成果物は可能な限りオープンに参 照でき、制約の少ない条件で利用できるようにしたい ◦ モデル開発の透明性 • これを担保するためのいくつかのポリシーを策定
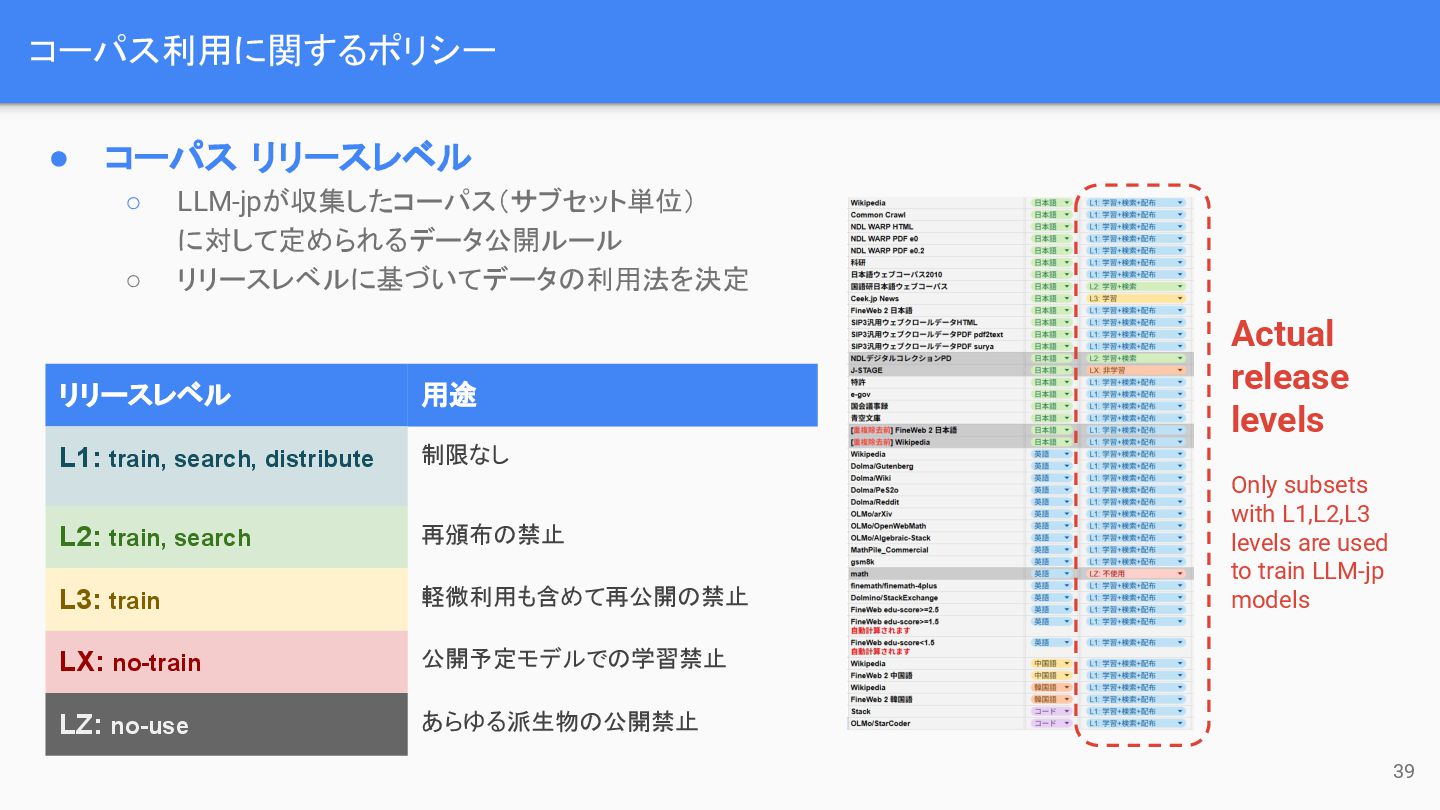
コーパス利用に関するポリシー 39 • コーパス リリースレベル ◦ LLM-jpが収集したコーパス(サブセット単位) に対して定められるデータ公開ルール ◦ リリースレベルに基づいてデータの利用法を決定
リリースレベル 用途 L1: train, search, distribute 制限なし L2: train, search 再頒布の禁止 L3: train 軽微利用も含めて再公開の禁止 LX: no-train 公開予定モデルでの学習禁止 LZ: no-use あらゆる派生物の公開禁止 Actual release levels Only subsets with L1,L2,L3 levels are used to train LLM-jp models
モデル公開に関するポリシー (1) 40 • FY2024 ◦ 昨年度の時点で明示的なポリシーは存在せず ◦ 各リリースで個別にモデルライセンスを策定 ◦
LLM-jp-3 172B ▪ 規約上は 制限ライセンス, しかし手違いで "オープン" と言及 • 他の LLM-jp-3 (~13B) モデルは Apache License 2.0なので 文字通りオープンウェイト • 172B モデルのみ内部的な事情でライセンスが異なる ▪ 公開時に公衆から様々な問題提起が
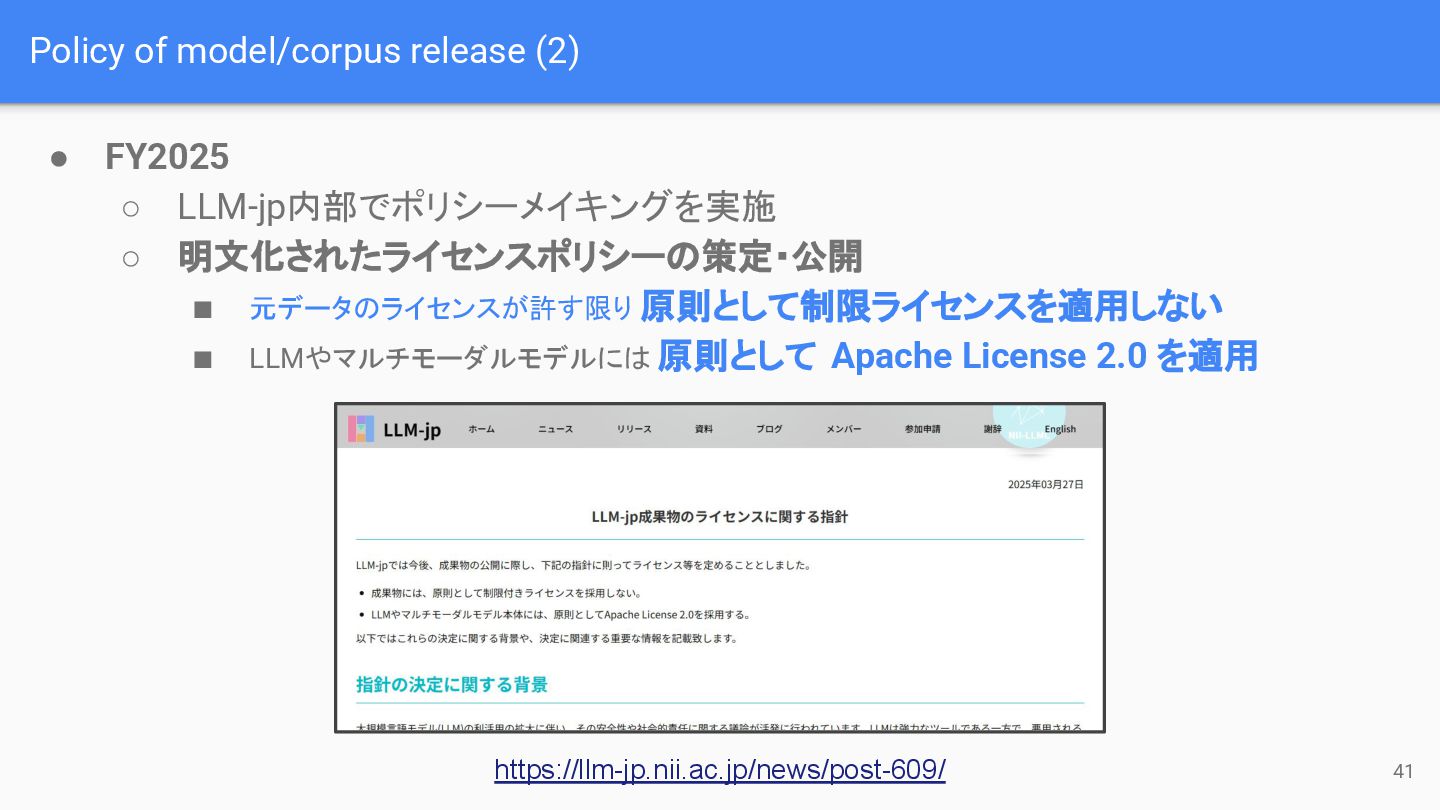
Policy of model/corpus release (2) 41 • FY2025 ◦ LLM-jp内部でポリシーメイキングを実施
◦ 明文化されたライセンスポリシーの策定・公開 ▪ 元データのライセンスが許す限り 原則として制限ライセンスを適用しない ▪ LLMやマルチモーダルモデルには 原則として Apache License 2.0 を適用 https://llm-jp.nii.ac.jp/news/post-609/
End of slides 42 Thanks! https://llm-jp.nii.ac.jp/ LLM-jp
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}