of texts • Desirable text (e.g., human readable text) gets high value • Undesirable text (e.g., random) gets low value • Texts = array of tokens • What is the relationship between LM and generative AI? Last token </s> 1st token <s> 2nd token Hello 3rd token world a text 4
Decomposing LM distribution using the "chain rule" of conditional distribution: Predict 1st word Predict 2nd word given the 1st word Predict 3rd word given the 1st/2nd words Next token prediction model (autoregressive model) Token to append History of past tokens 5
derives a basic generation algorithm: history = [“<s>”] while history[-1] != “</s>”: history.append(sample w from P) return history <s> <s> <s> Hello Hello world <s> Hello world </s> Sample Sample Sample • Very simple, but recent line of research revealed that if the LLM is intelligent enough, next token prediction can solve tasks described in natural language. • Anyway, how do we construct ? 6
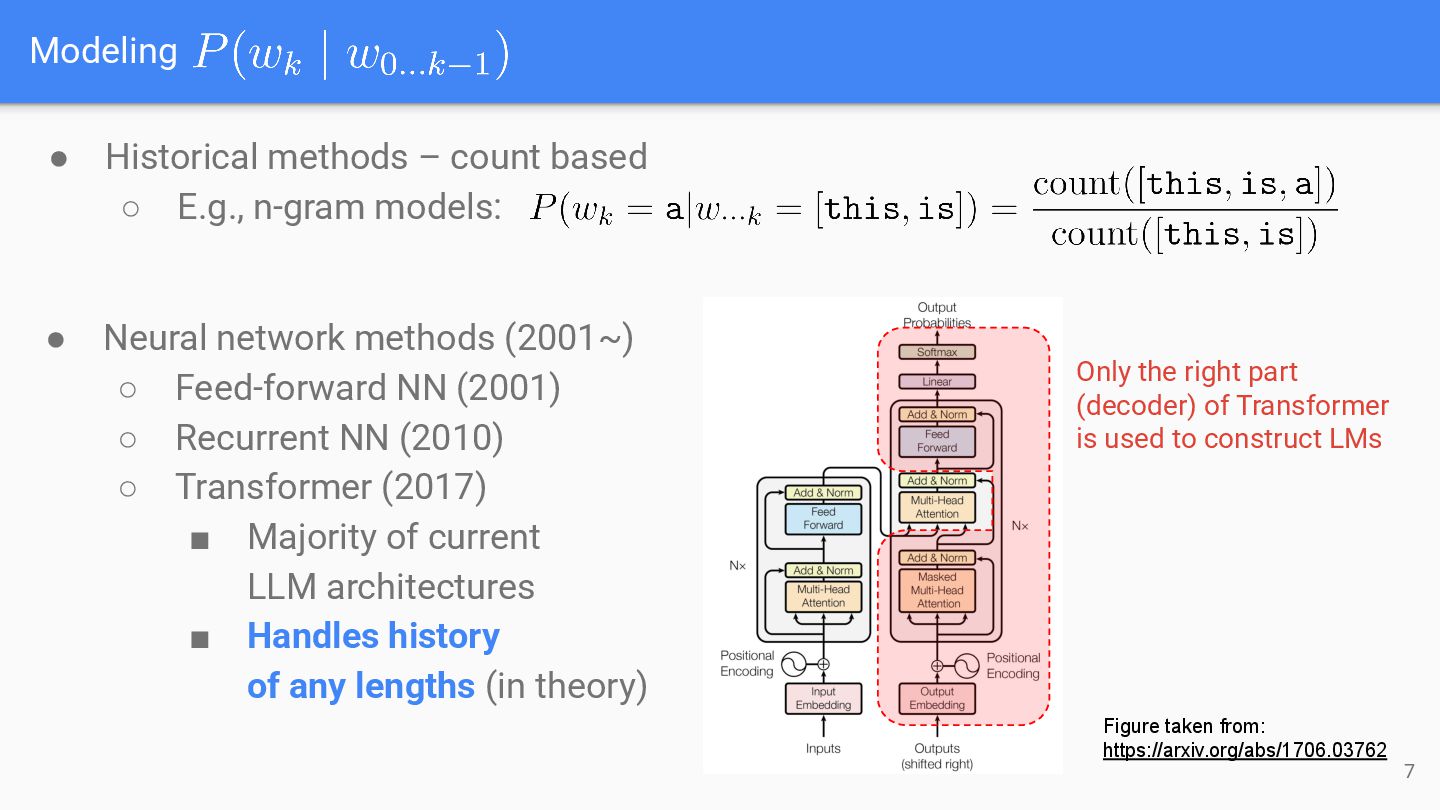
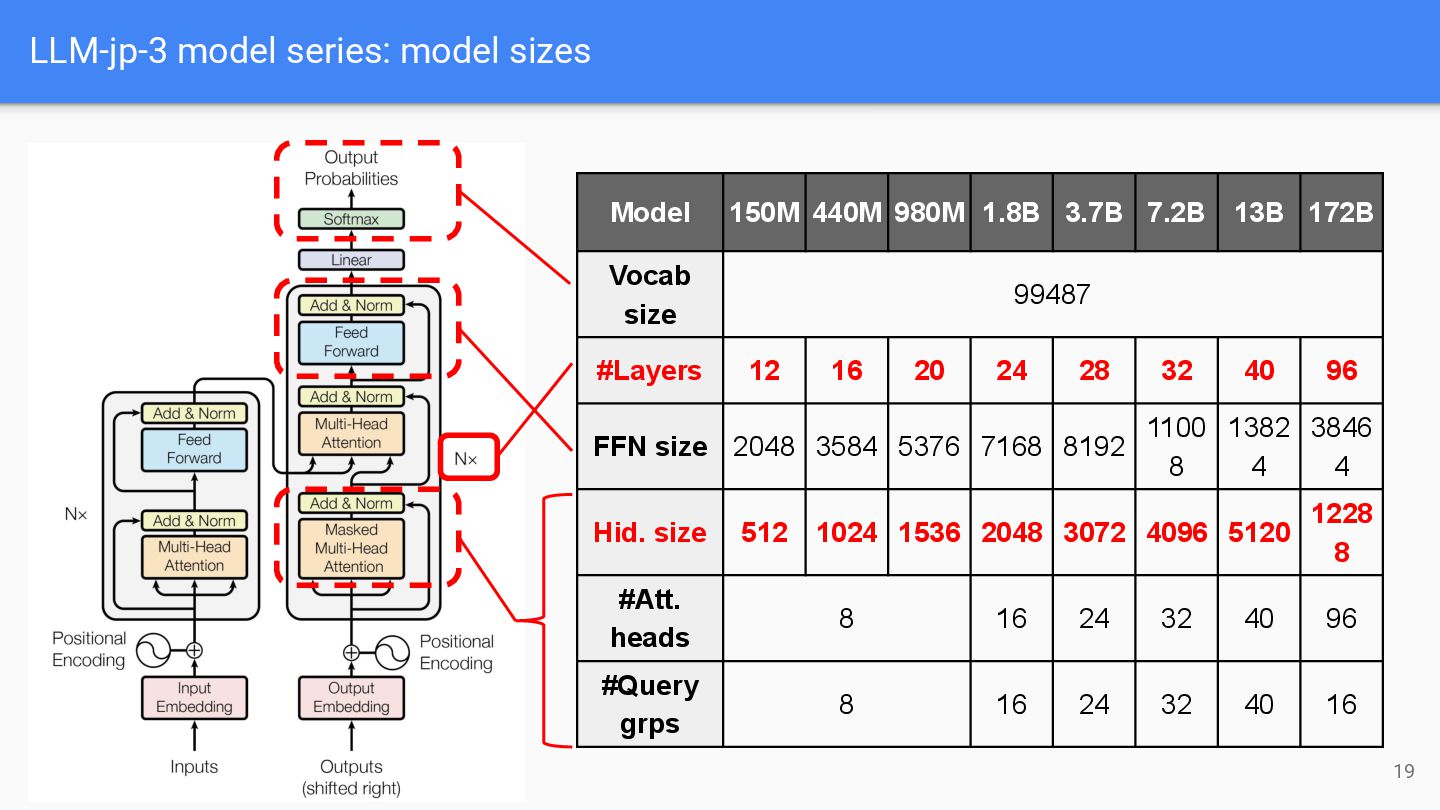
models: • Neural network methods (2001~) ◦ Feed-forward NN (2001) ◦ Recurrent NN (2010) ◦ Transformer (2017) ▪ Majority of current LLM architectures ▪ Handles history of any lengths (in theory) Figure taken from: https://arxiv.org/abs/1706.03762 Only the right part (decoder) of Transformer is used to construct LMs 7
• Revealing the operating principle of LLMs • Release models, data, tools, and related techniques and materials, not only successful work but also progress and/or failures. • Anyone who agree the above policy can participate in us. 2023-05: First meetup 2023-10: First 13B model 2024-09: LLM-jp-3 ~13B (7 models) 2024-12: LLM-jp-3 172B 2025-05: LLM-jp-3.1 (3 models) 2025-03: LLM-jp-3 MoE 8x1.8B, 8x13B Now: Training v4 models 2000~ members Started with 30 NLP researchers 2024-04: NII R&D Center for LLMs (LLMC, dedicated lab) 11
local knowledge ◦ Flagship LLMs are not trained well for local knowledge/commonsense ▪ They works anyway, with limited inner knowledge and RAG ◦ Necessity to train LLMs (pretraining and/or tuning) with local knowledge Japanese languages Japanese culture Geolocational information in/around Japan 12
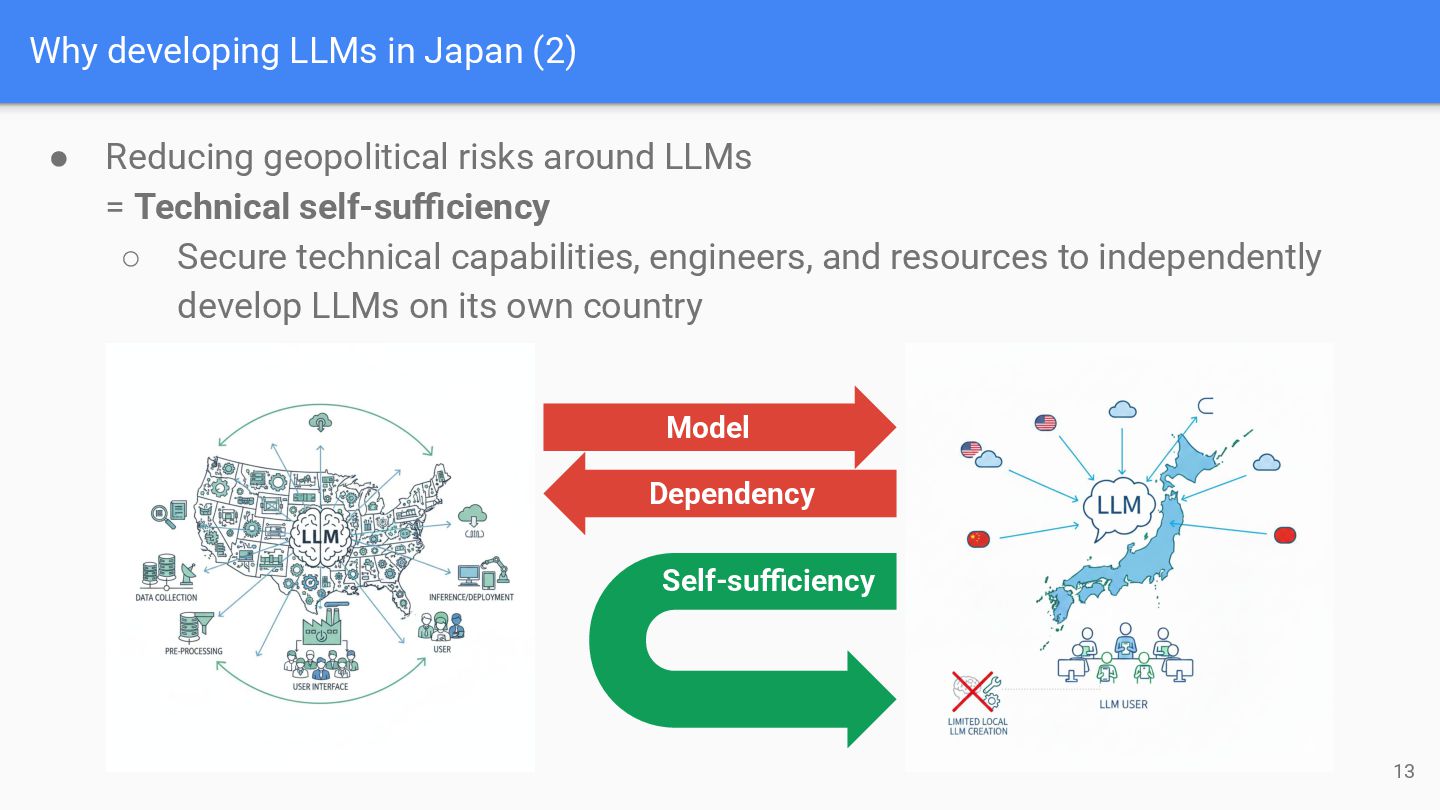
around LLMs = Technical self-sufficiency ◦ Secure technical capabilities, engineers, and resources to independently develop LLMs on its own country Model Dependency Self-sufficiency 13
of text data is required to train LLMs ▪ Trillions of tokens should be prepared • LLaMA 2: 2T tokens • LLaMA 3: 15T tokens • Qwen3: 36T tokens ◦ Collecting data is challenging especially in non-English languages (even Japanese) ▪ Most open web data (Common Crawl) is written in English ▪ Only ~1T open data is available in Japanese 14
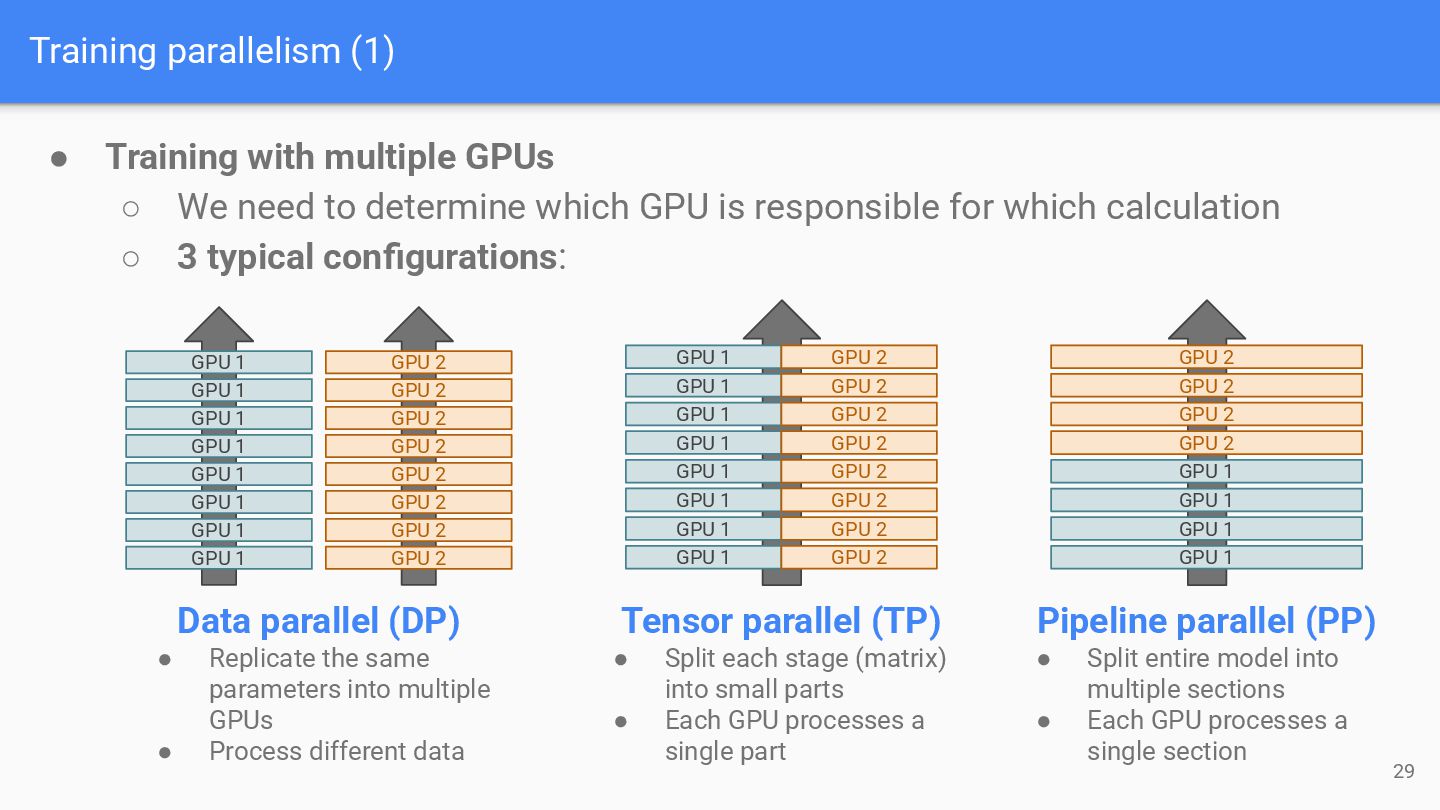
cluster is required to handle training jobs ▪ GPT-3 scale models (175B) require hundreds ~ thousands of Flagship GPUs to train ▪ Even small models (1B) require tens of H100 GPUs to train within a handy time ◦ Operating computing cluster requires large cost ▪ Training a 32B model (LLM-jp-4 flagship) with 10T tokens require 12k GPU (H200) days, $~10M • Engineering cost/workforce ◦ Human experts are also required to handle large scale data collection, developing/managing training pipelines, and computing resources 15
• Providing financial support for setting up 3rd-party compute resources • ABCI supercomputer • Providing compute support for LLM development • GENIAC (NEDO) • Providing financial/compute support for LLM development Cabinet Office(内閣府) • Providing support LLM development for medical domain (SIP) MIC(総務省) • NICT • Develop owned LLM model with their own corpus/resources MEXT(文部科学省) • University of Tokyo • Preparing computing resources for LLM/other foundation model • RIKEN • Experiment to employ Fugaku supercomputer for LLM training • National Institute of Informatics • Organize LLM-jp • R&D center for LLM 16
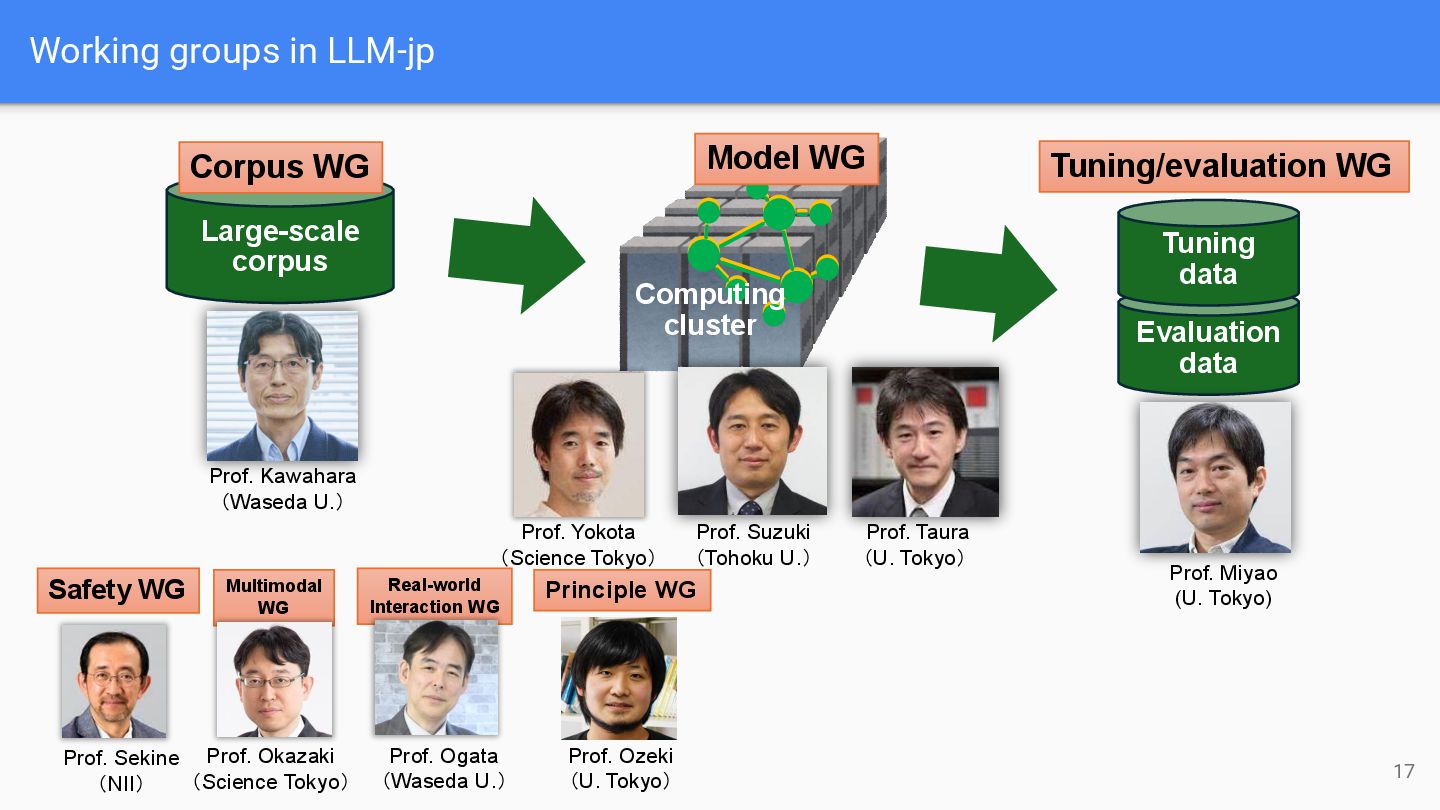
Tuning data Prof. Ogata (Waseda U.) Prof. Suzuki (Tohoku U.) Prof. Miyao (U. Tokyo) Prof. Taura (U. Tokyo) Prof. Yokota (Science Tokyo) Safety WG Prof. Sekine (NII) Multimodal WG Prof. Okazaki (Science Tokyo) Real-world Interaction WG Prof. Kawahara (Waseda U.) Principle WG Prof. Ozeki (U. Tokyo) Model WG Computing cluster Corpus WG 17
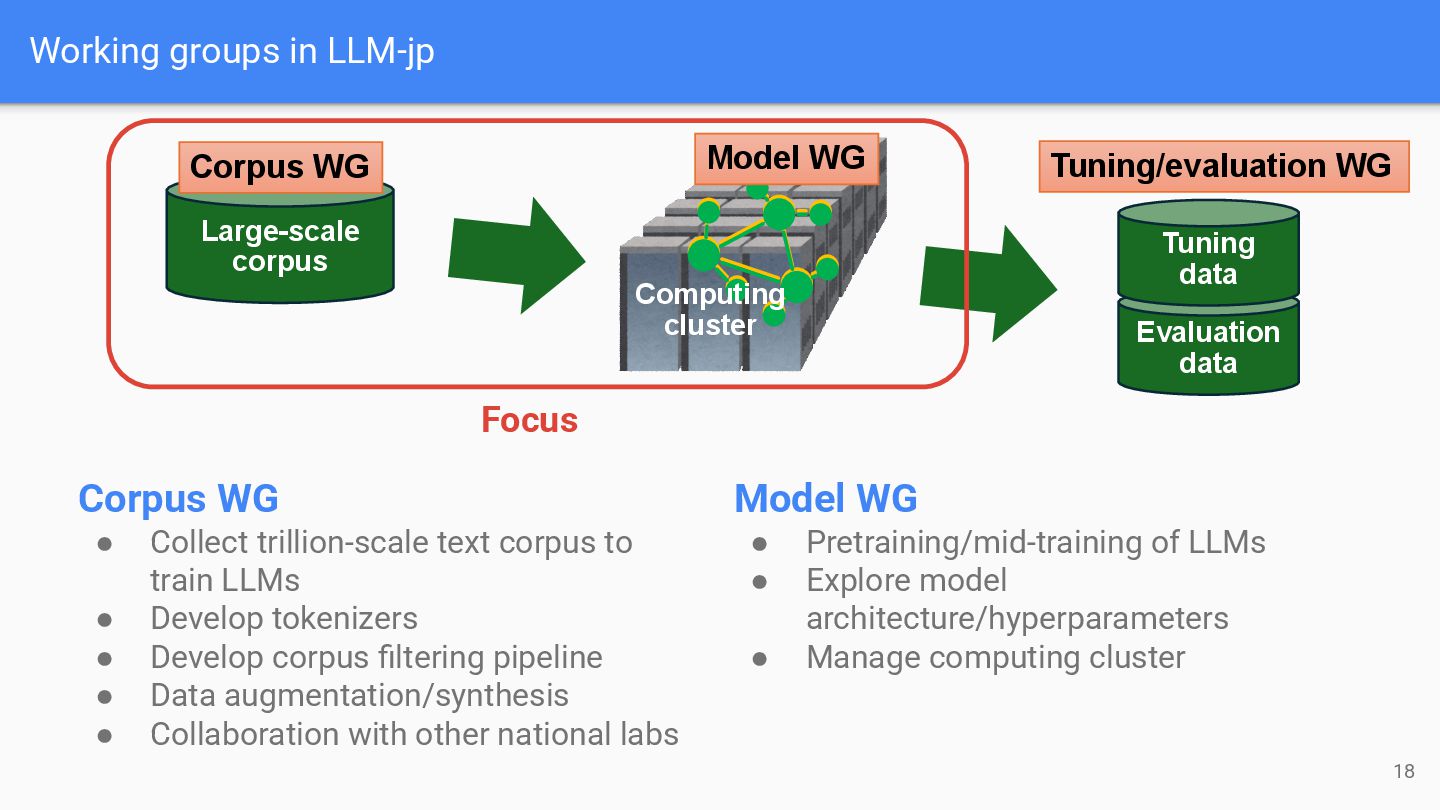
corpus to train LLMs • Develop tokenizers • Develop corpus filtering pipeline • Data augmentation/synthesis • Collaboration with other national labs Model WG • Pretraining/mid-training of LLMs • Explore model architecture/hyperparameters • Manage computing cluster Tuning/evaluation WG Large-scale corpus Evaluation data Tuning data Model WG Computing cluster Corpus WG Focus 18
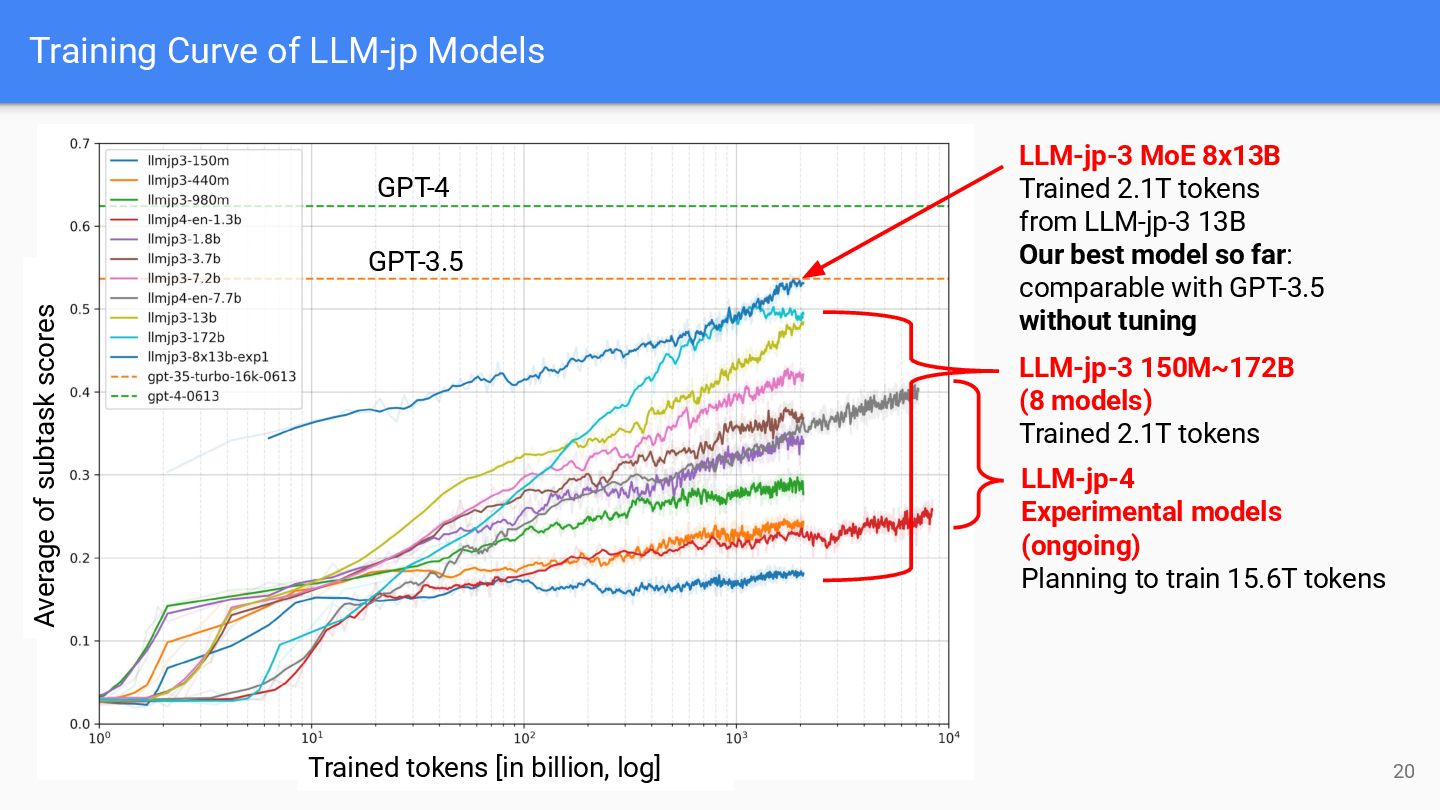
tokens from LLM-jp-3 13B Our best model so far: comparable with GPT-3.5 without tuning LLM-jp-3 150M~172B (8 models) Trained 2.1T tokens LLM-jp-4 Experimental models (ongoing) Planning to train 15.6T tokens GPT-3.5 GPT-4 Trained tokens [in billion, log] Average of subtask scores 20
crucial part of LLM development ◦ Large-scale corpus improves model quality ◦ High-quality corpus also improves model quality • How to collect huge corpus (in LLM-jp) ◦ Leveraging public corpus ▪ Common Crawl (CC): huge collection of Web pages ◦ Our own crawling ◦ Collaborative work with other laboratories ▪ National Diet Library (NDL: 国立国会図書館) ▪ National Institute of Japanese Literature (NIJL: 国文学研究資料館)
subset tokens during training ◦ Many repeats: Increase subset ratio, but may cause overfitting ◦ Few repeats: may cause underfitting ◦ Corpus ratio also affects against balance of task performance • Ablation study conducted with various patterns of repeats Subset Candidate patterns (color represents number of repeats)
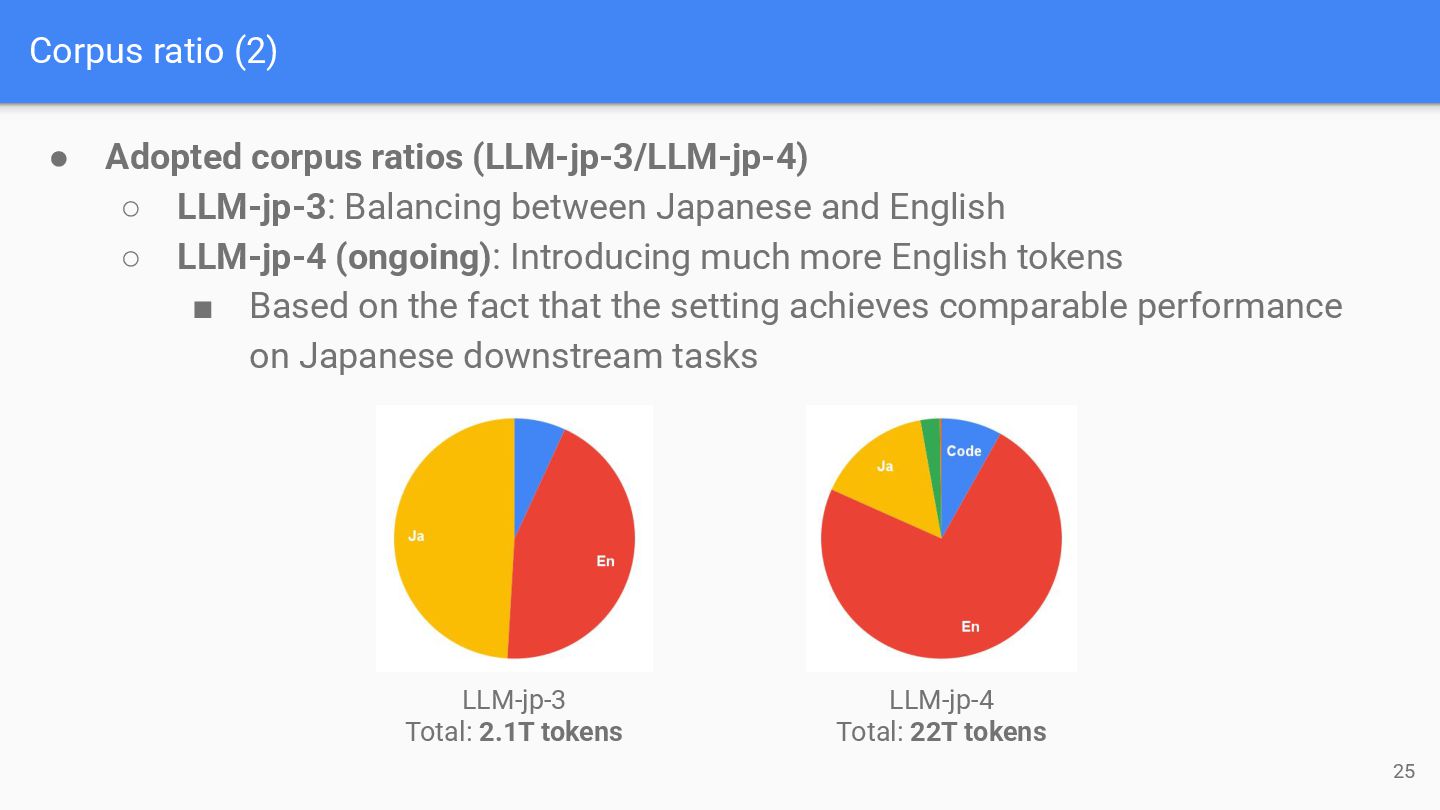
22T tokens • Adopted corpus ratios (LLM-jp-3/LLM-jp-4) ◦ LLM-jp-3: Balancing between Japanese and English ◦ LLM-jp-4 (ongoing): Introducing much more English tokens ▪ Based on the fact that the setting achieves comparable performance on Japanese downstream tasks
of new corpus configuration (LLM-jp-4) ◦ 5 configurations are investigated ▪ Candidate 1: Replace Stack (coding corpus) from v1 to v2 ▪ Candidate 2: Reduce FineWeb (Web corpus) to enhance STEM data ▪ Candidate 3: Add MegaMath (Math corpus) ▪ Candidate 4: Add Laboro corpus (parallel corpus) ▪ Candidate 5: Add FinePDFs corpus (table corpus) ◦ We need to determine which configuration is actually effective independently from other settings (= avoid interaction effect) ◦ Directly measuring every on/off setting is intractable ▪ Training 32 (=2^5) models, each require certain cost (millions of JPY) ▪ Need to reduce number of experiments
factorial design ◦ Design each experiment with a mixture of on/off ◦ Keep every experiment orthogonal • Perform only 8 model training ◦ Then aggregate results to measure each effect Effect size (Cohen's f) p-value of F statistical test Difference of mean (on-results - off-results) Result: Only the setting C (Add MegaMath) has a clear positive effect
(ongoing) ◦ Determining the actual configuration according to not only performance but also actual stability of training Adopted configuration Not fast, but stable Best configuration Faster, but flaky Ablation study performed well, but actual training tends to OOM/hardware errors Some configurations can't be selected due to GBS restriction (256, 512)
◦ Typical bit pattern: BFloat16 (BF16) ▪ Designed for machine learning ▪ 8-bits exponents • Same dynamic range with single precision (IEEE754 binary32) ▪ 7-bits fraction • Diminished resolution BF16 Single Exponent Fraction Sign
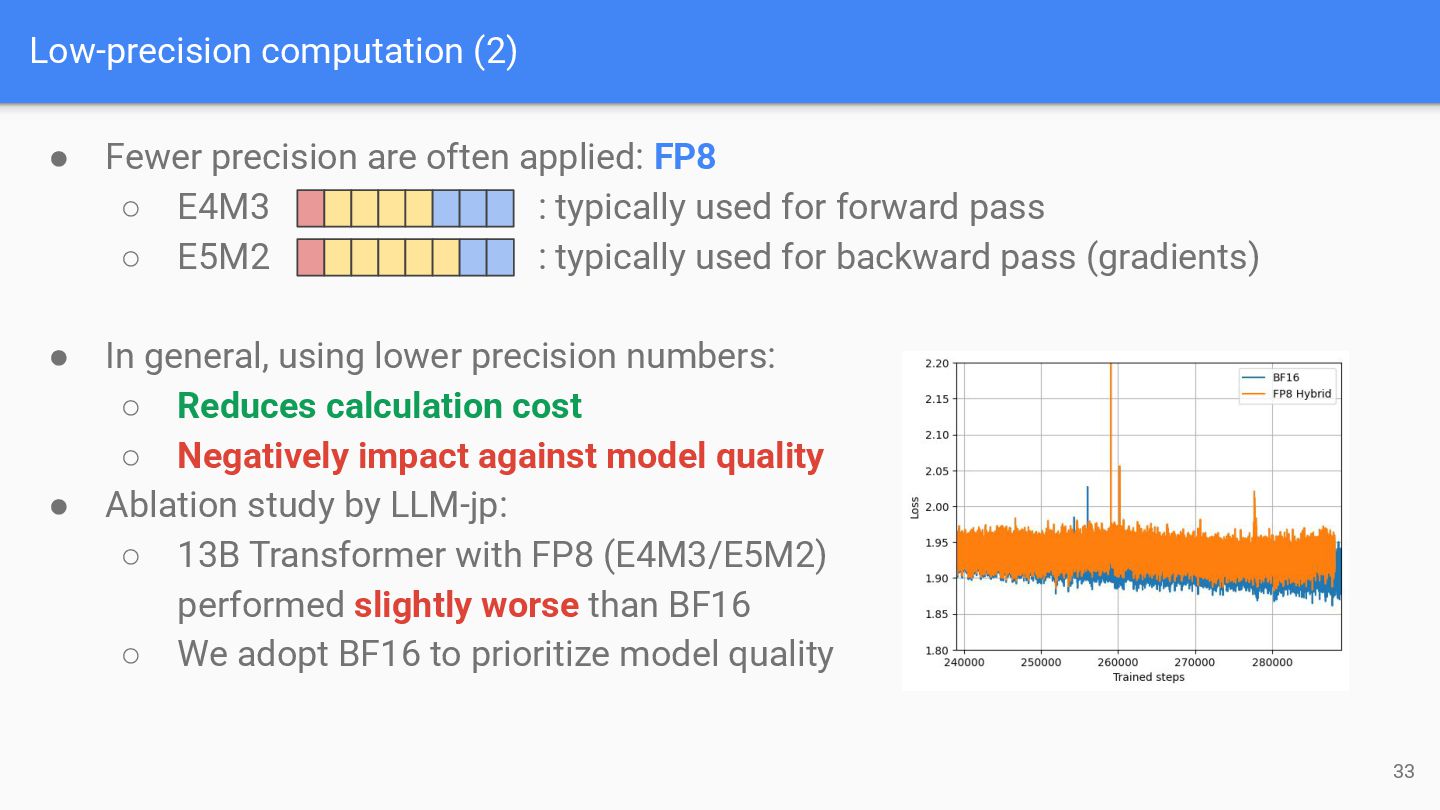
FP8 ◦ E4M3 : typically used for forward pass ◦ E5M2 : typically used for backward pass (gradients) • In general, using lower precision numbers: ◦ Reduces calculation cost ◦ Negatively impact against model quality • Ablation study by LLM-jp: ◦ 13B Transformer with FP8 (E4M3/E5M2) performed slightly worse than BF16 ◦ We adopt BF16 to prioritize model quality
gradient descent (SGD) • Actual training usually adopts a variant of SGD: AdamW ◦ SGD + momentum + adaptive gradient decay + weight decay • Many hyperparameters required: ◦ Learning rate (η) … depends on model (1e-3 ~ 1e-6) ◦ momentum strength (β1) … usually set to 0.9 for any models ◦ gradient decay strength (β2) … usually set to 0.95 for LLMs ◦ A factor to avoid zero-division (ε) … usually set to 1e-8 ◦ weight decay strength … usually set to 0.1 • Inappropriate hyperparameter causes inaccurate training and every one is crucial
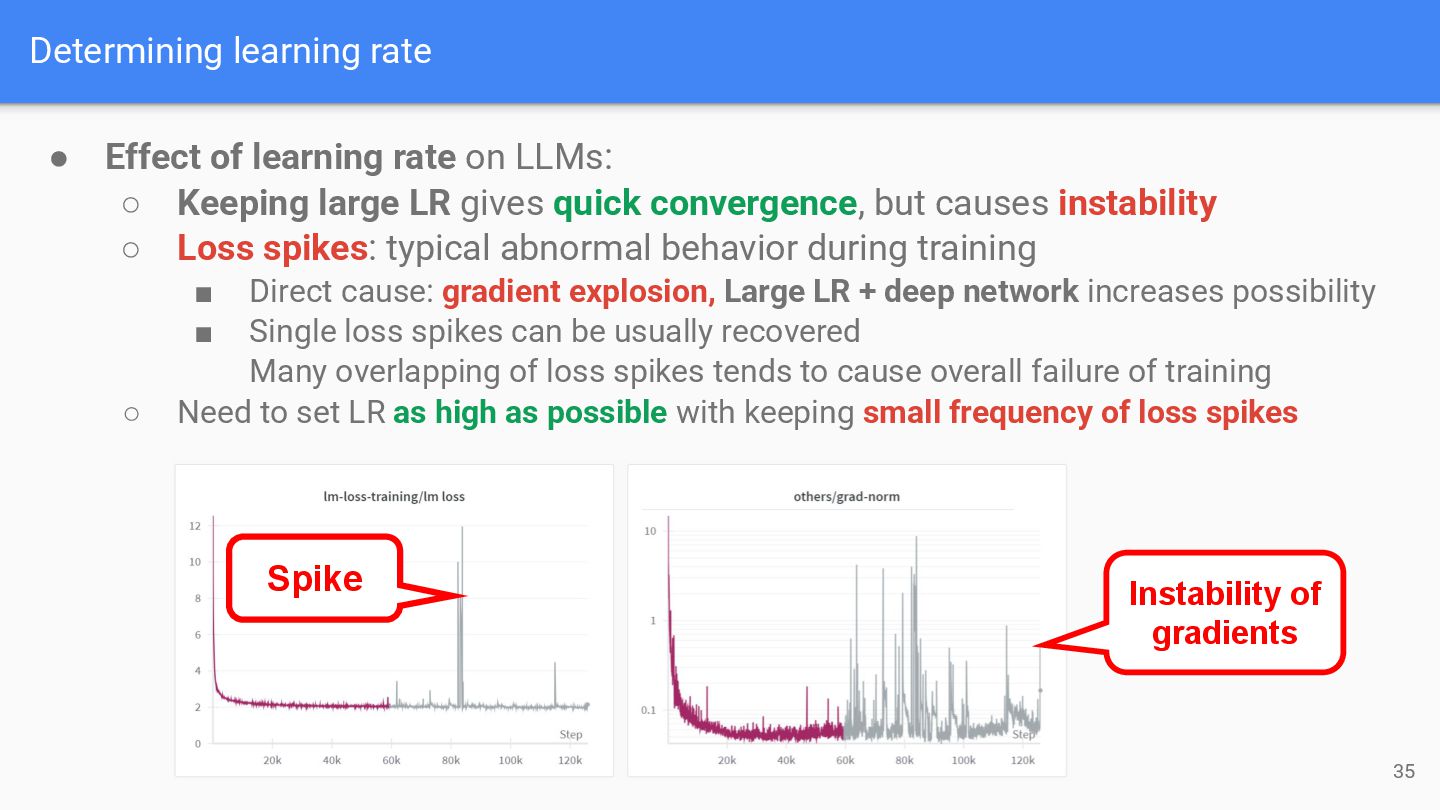
of learning rate on LLMs: ◦ Keeping large LR gives quick convergence, but causes instability ◦ Loss spikes: typical abnormal behavior during training ▪ Direct cause: gradient explosion, Large LR + deep network increases possibility ▪ Single loss spikes can be usually recovered Many overlapping of loss spikes tends to cause overall failure of training ◦ Need to set LR as high as possible with keeping small frequency of loss spikes
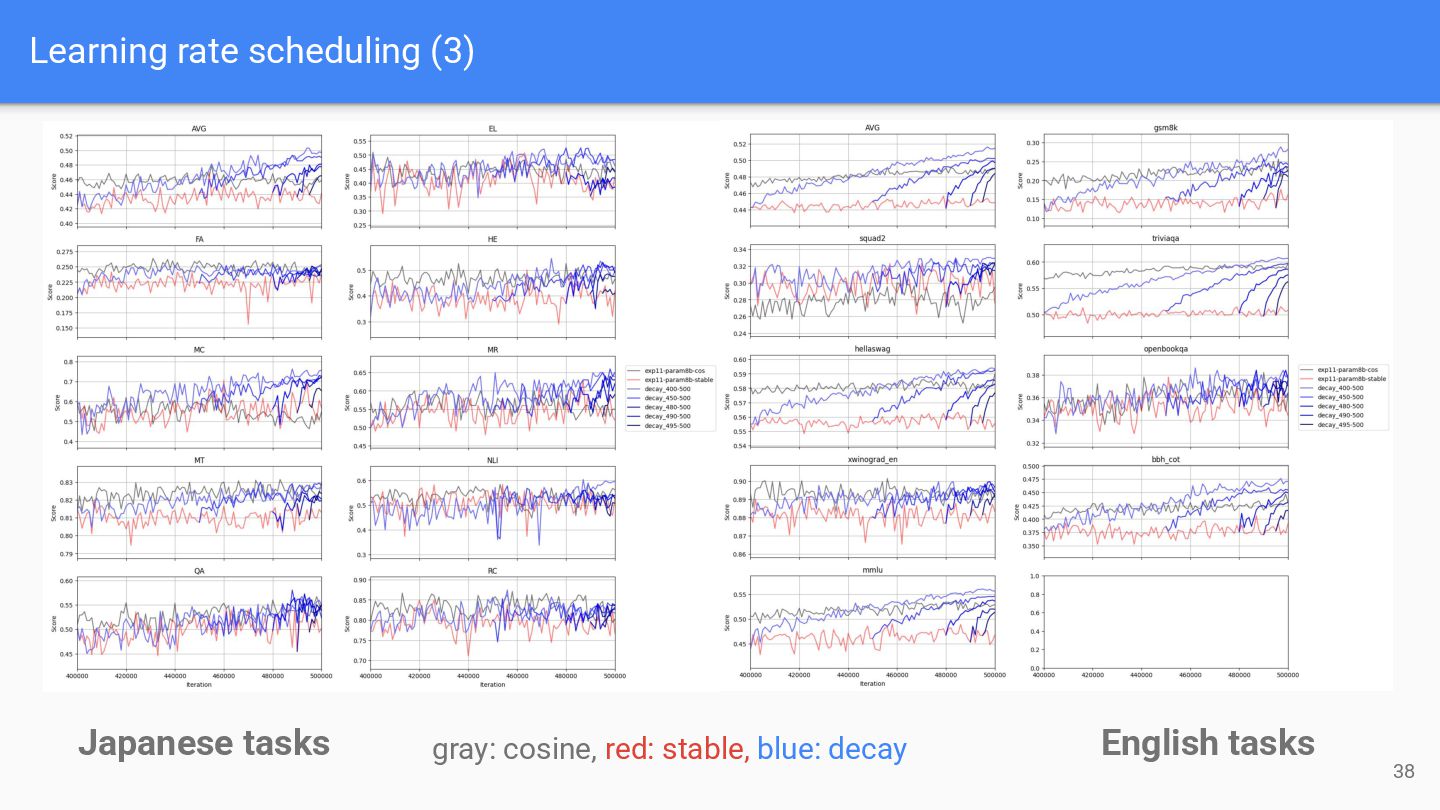
the entire training process ◦ Traditional configuration: linear warmup + cosine decay ◦ LLM-jp-3 adopted cosine scheduling • Some studies argued the advantage of warmup-stable-decay (WSD) scheduling ◦ Keep the maximum LR during end of the training, with small amount of decay steps
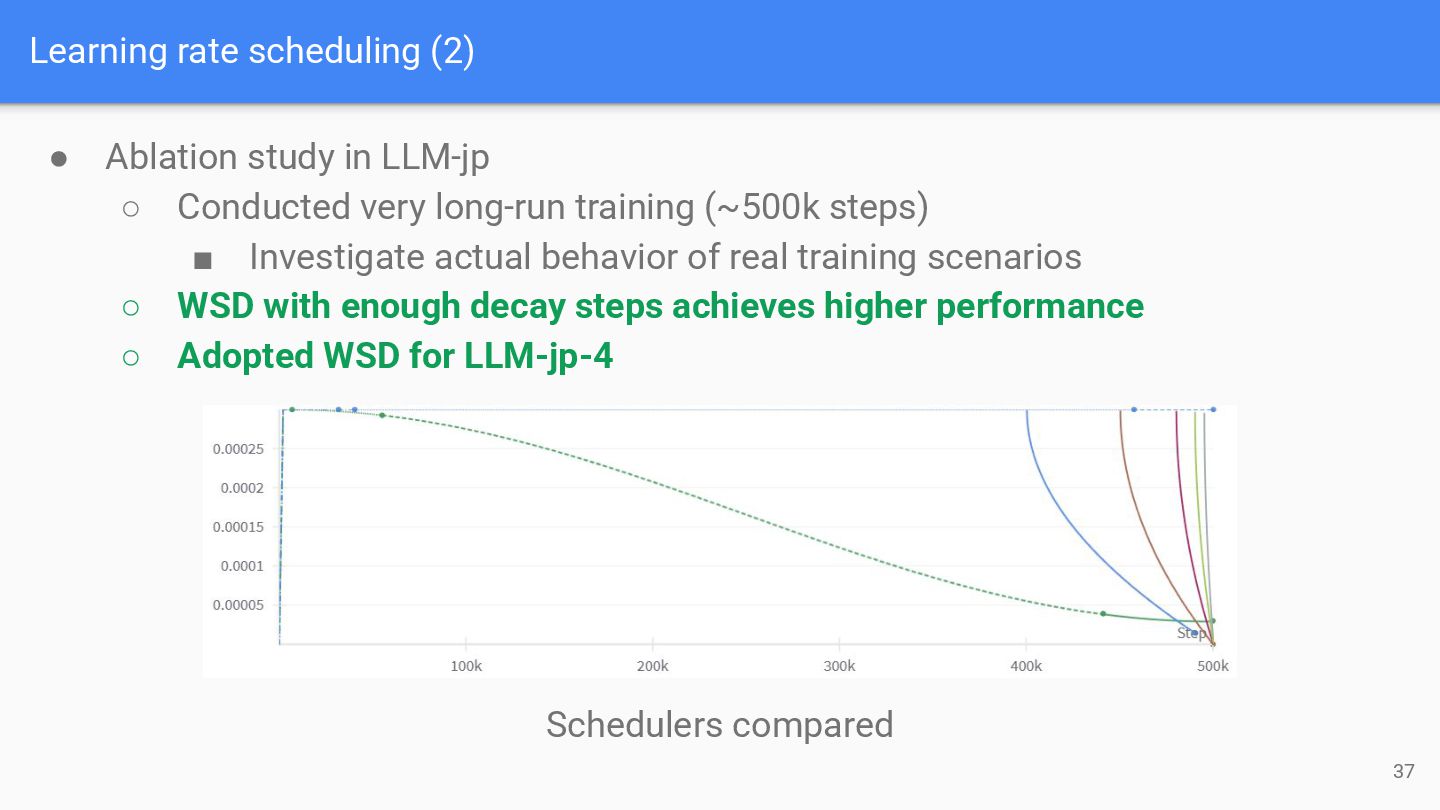
◦ Conducted very long-run training (~500k steps) ▪ Investigate actual behavior of real training scenarios ◦ WSD with enough decay steps achieves higher performance ◦ Adopted WSD for LLM-jp-4 Schedulers compared
of Adam Optimizer ◦ Important role for model convergence ▪ Should set to 1e-8 ▪ It was 1e-5 in the LLaMA2 technical report, but this setting lead to fail training of large models ◦ LLM-jp conducted some ablation study and reported results to Japanese community ▪ Confirmed that some other organization faced the same problem ▪ Huge amount of loss of compute 1e-8: 3x faster 1e-5: very slow convergence
LLM-jp is working to share our knowledge to wide range of people ▪ Academic researchers ▪ Industry developers ▪ Users • Materials developed by LLM-jp should also be released publicly, with as few restrictions as possible ◦ Transparency of model development • Several policy is formulated to keep our transparency
Quantifies how the collected corpus is used in LLM-jp (train/test) Release Level Purpose L1: train, search, distribute Use for any purposes (if license allowed) L2: train, search Prohibit to re-distribute L3: train Prohibit to expose outside LLM-jp LX: no-train Prohibit to train, use test-time only LZ: no-use Prohibit to use for any purposes (including illegal data) Actual release levels Only subsets with L1,L2,L3 levels are used to train LLM-jp models
don't have any written policy of our released materials ◦ License is determined according to each discussion ◦ Release of LLM-jp-3 172B ▪ Under restricted license, but announced as "open model" • Other variants of LLM-jp-3 (~13B) were released under Apache License 2.0 • Only 172B model was released under a special license ▪ Received negative attention from public audience
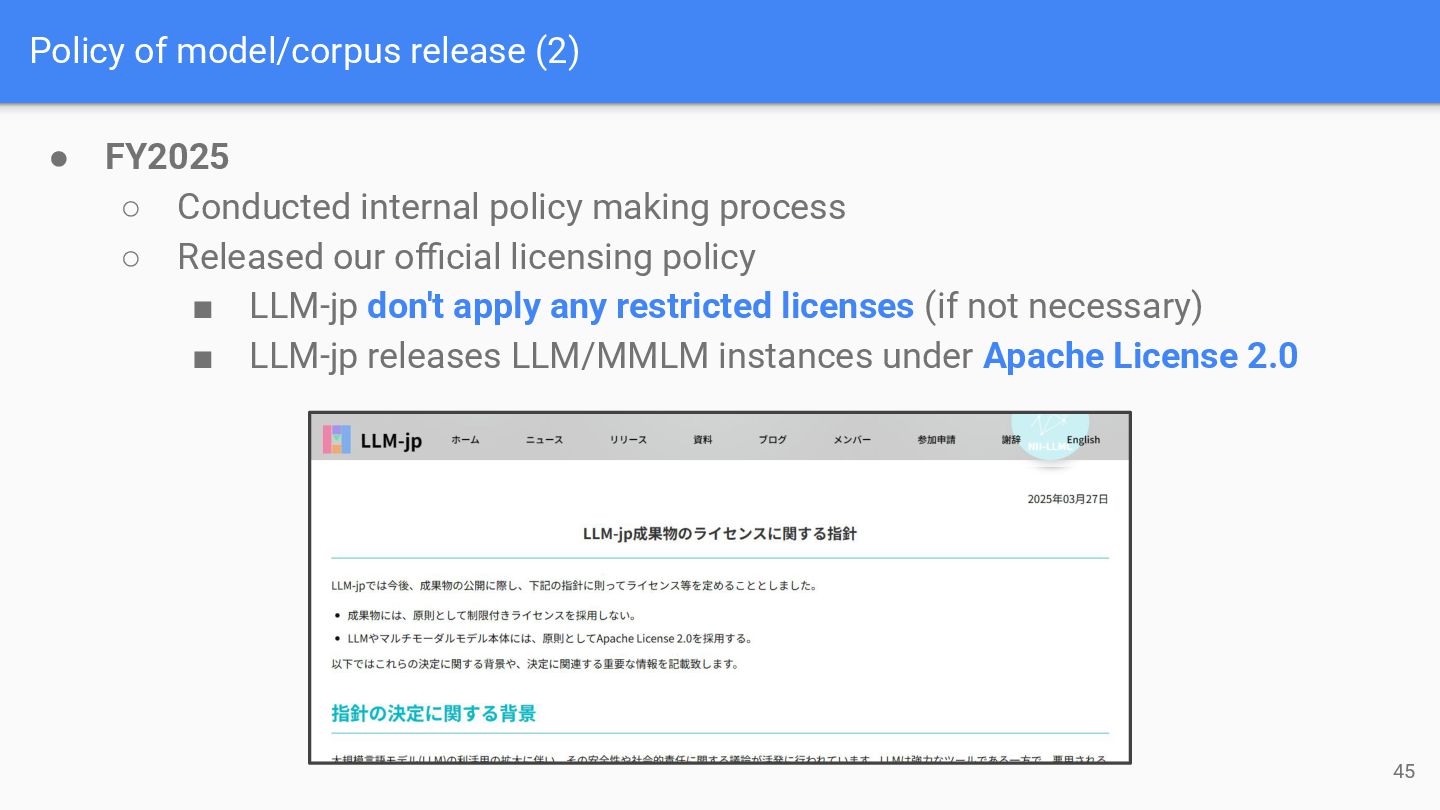
internal policy making process ◦ Released our official licensing policy ▪ LLM-jp don't apply any restricted licenses (if not necessary) ▪ LLM-jp releases LLM/MMLM instances under Apache License 2.0
LLM ◦ Focus on only publicly-available models ◦ Both proprietary/open models allowed • Investigate what are the important technical breakthroughs applied to construct the selected LLM ◦ Bonus: do such breakthroughs affect your own research topic? ◦ Bonus: what are NOT achieved yet by such breakthroughs? • Write 1-pager summary of the above survey ◦ LLM-assisted writing allowed But the soundness of the whole content must be guaranteed by yourself
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}