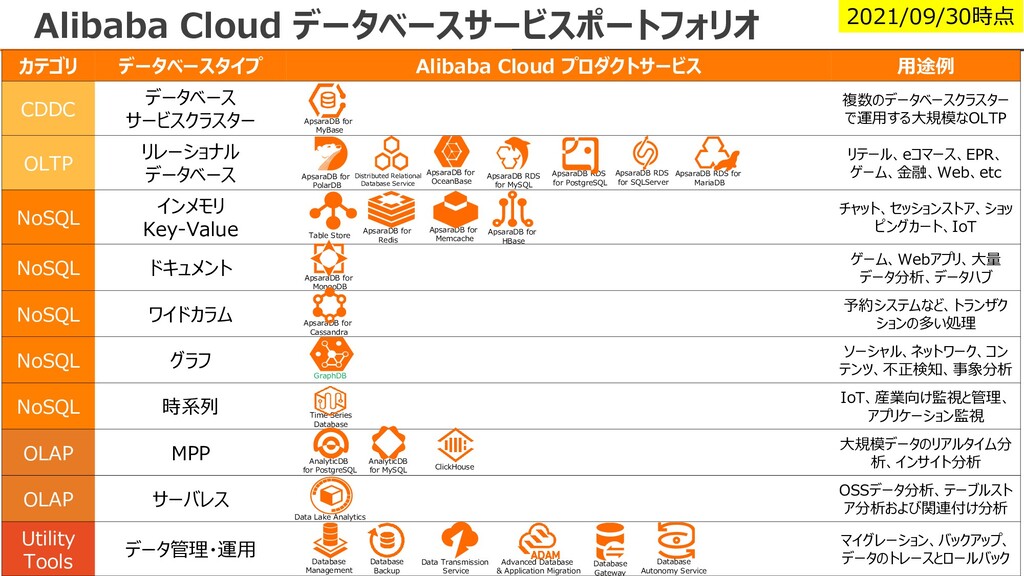
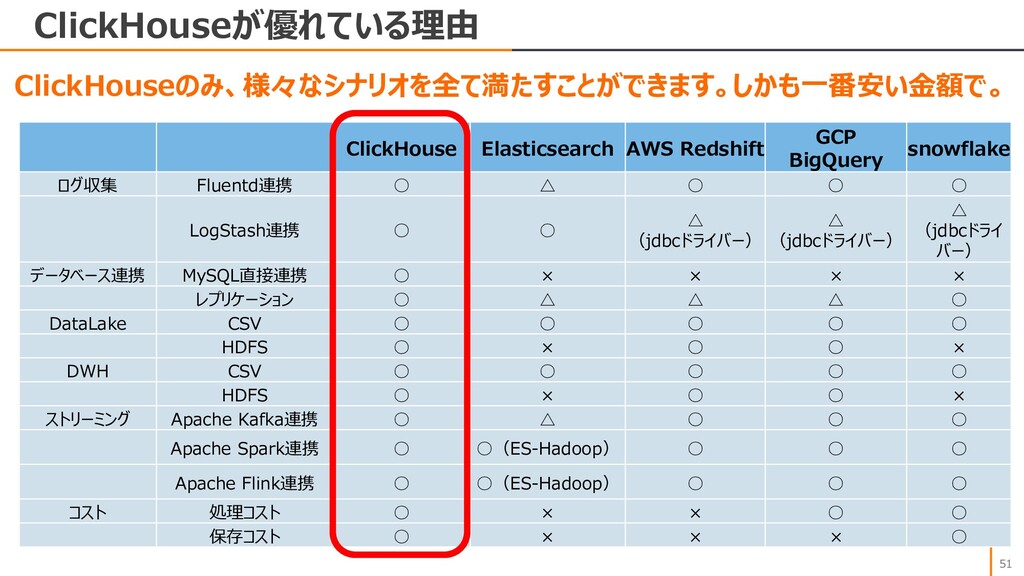
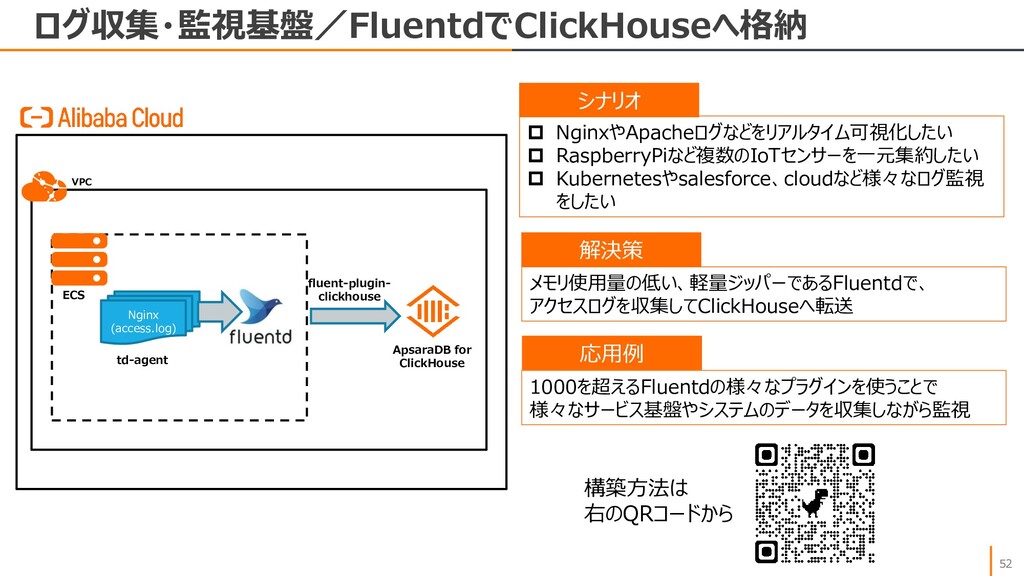
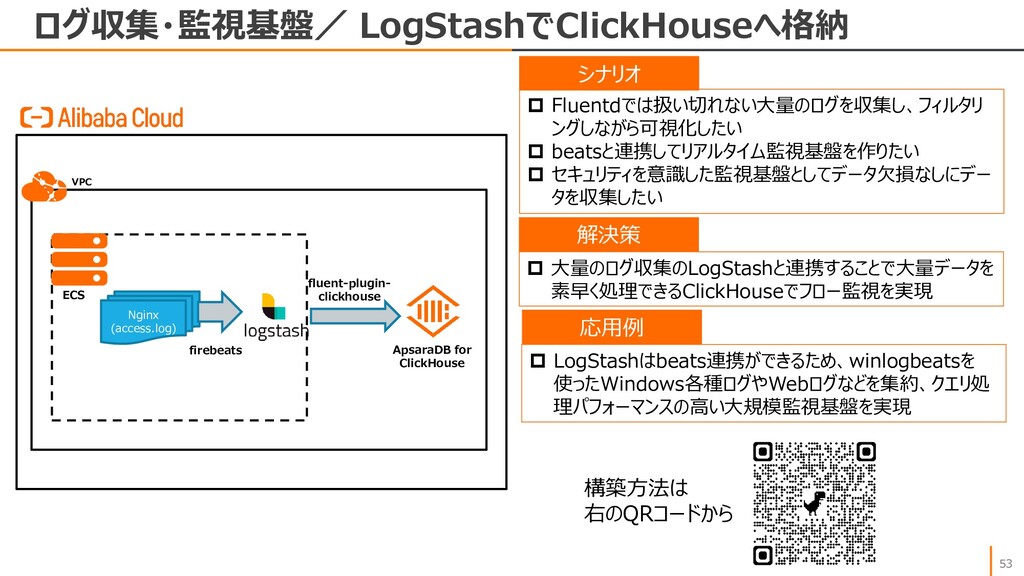
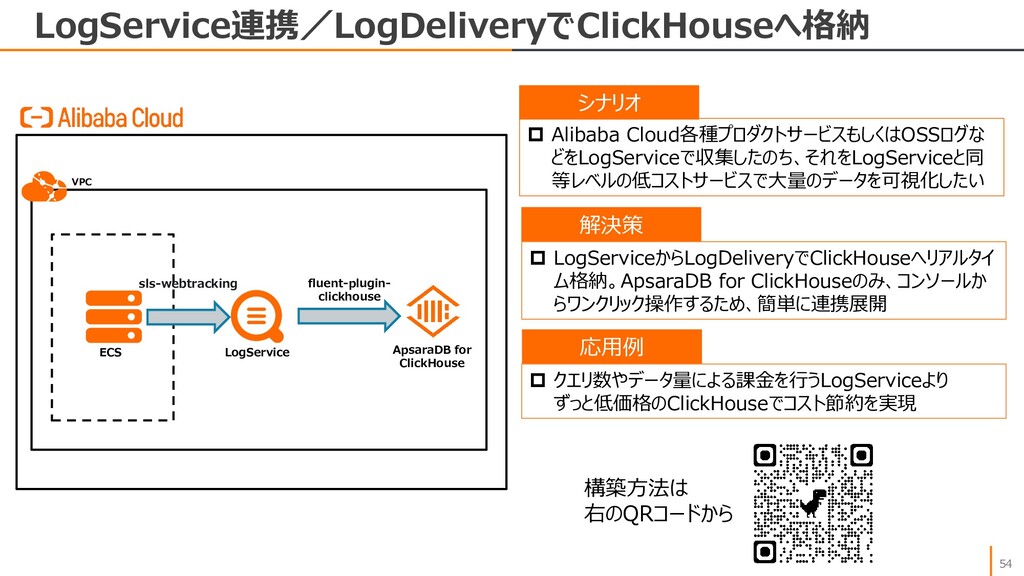
CDDC データベース サービスクラスター 複数のデータベースクラスター で運用する大規模なOLTP OLTP リレーショナル データベース リテール、eコマース、EPR、 ゲーム、金融、Web、etc NoSQL インメモリ Key-Value チャット、セッションストア、ショッ ピングカート、IoT NoSQL ドキュメント ゲーム、Webアプリ、大量 データ分析、データハブ NoSQL ワイドカラム 予約システムなど、トランザク ションの多い処理 NoSQL グラフ ソーシャル、ネットワーク、コン テンツ、不正検知、事象分析 NoSQL 時系列 IoT、産業向け監視と管理、 アプリケーション監視 OLAP MPP 大規模データのリアルタイム分 析、インサイト分析 OLAP サーバレス OSSデータ分析、テーブルスト ア分析および関連付け分析 Utility Tools データ管理・運用 マイグレーション、バックアップ、 データのトレースとロールバック ApsaraDB RDS for MySQL ApsaraDB RDS for PostgreSQL ApsaraDB RDS for SQLServer ApsaraDB for PolarDB Distributed Relational Database Service ApsaraDB RDS for MariaDB ApsaraDB for OceanBase ApsaraDB for Redis ApsaraDB for Memcache Table Store ApsaraDB for HBase ApsaraDB for MongoDB ApsaraDB for Cassandra GraphDB Time Series Database AnalyticDB for MySQL AnalyticDB for PostgreSQL ClickHouse Data Lake Analytics Database Management Advanced Database & Application Migration Database Backup Data Transmission Service Database Gateway Database Autonomy Service 2021/09/30時点 ApsaraDB for MyBase
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
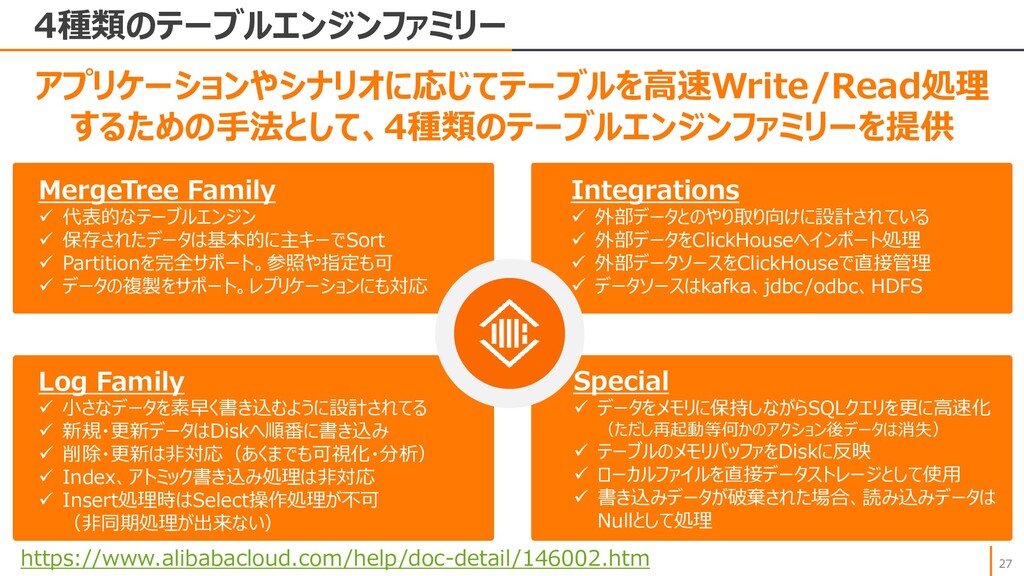{kind=link}
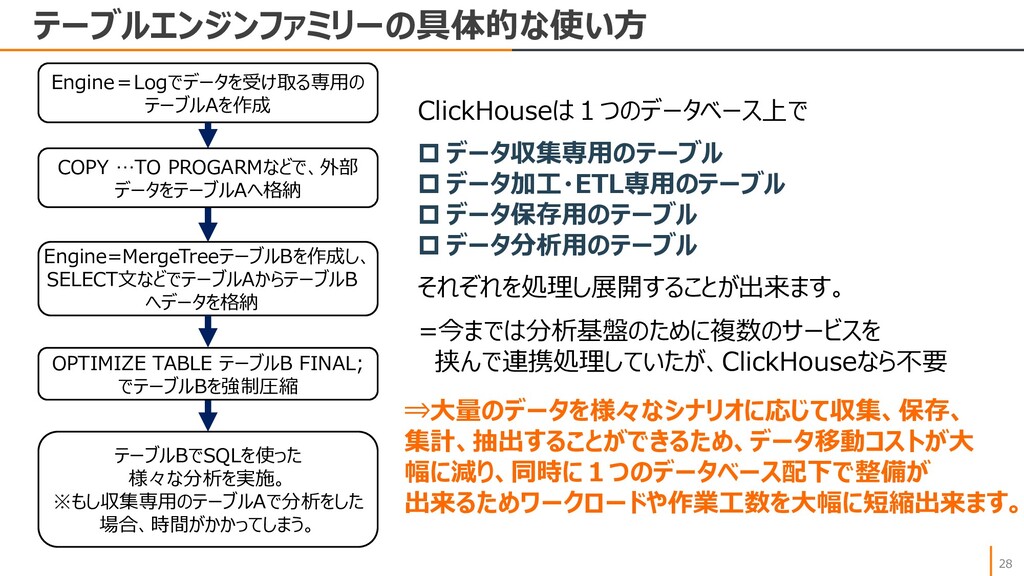{kind=link}
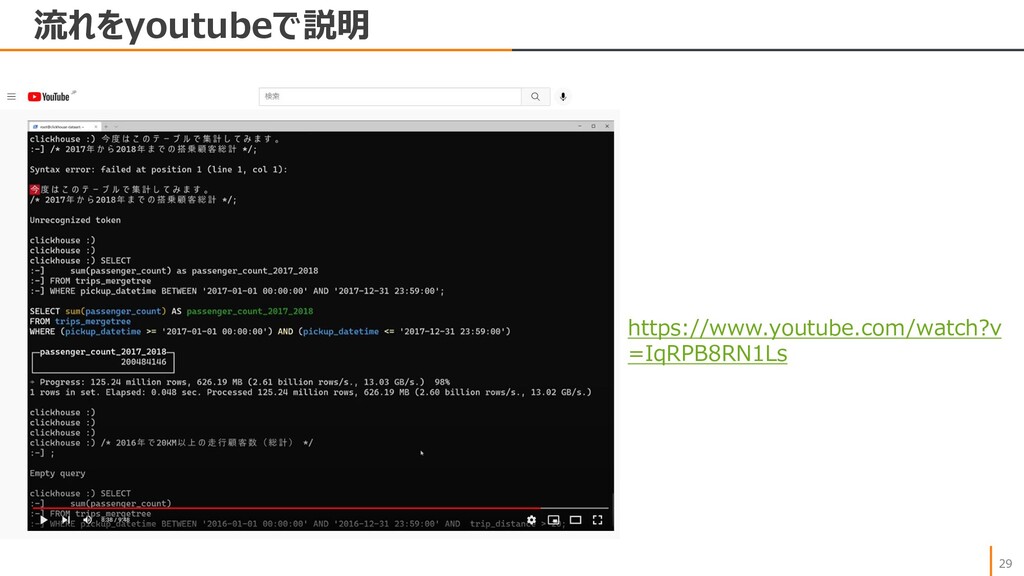{kind=link}
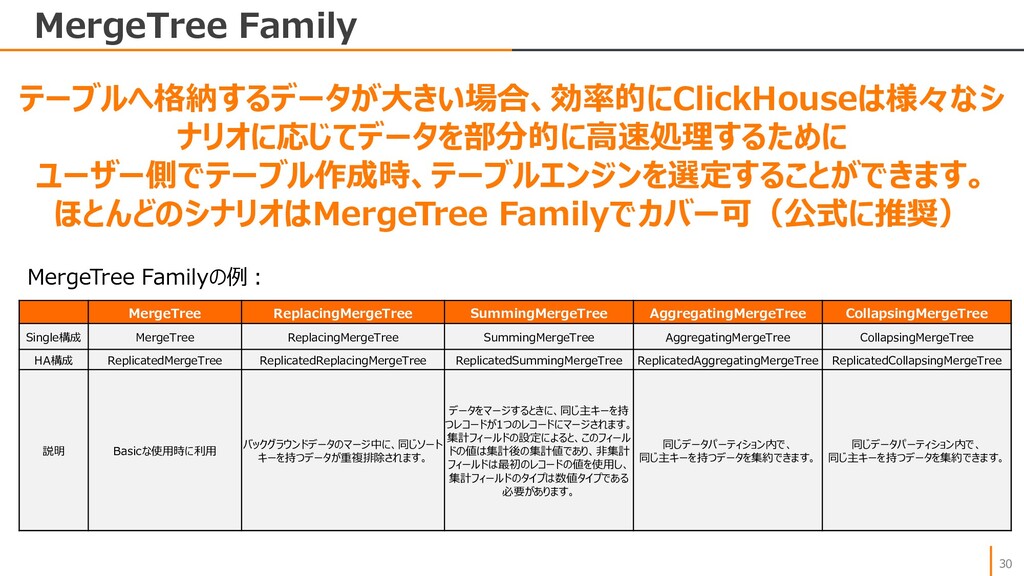{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
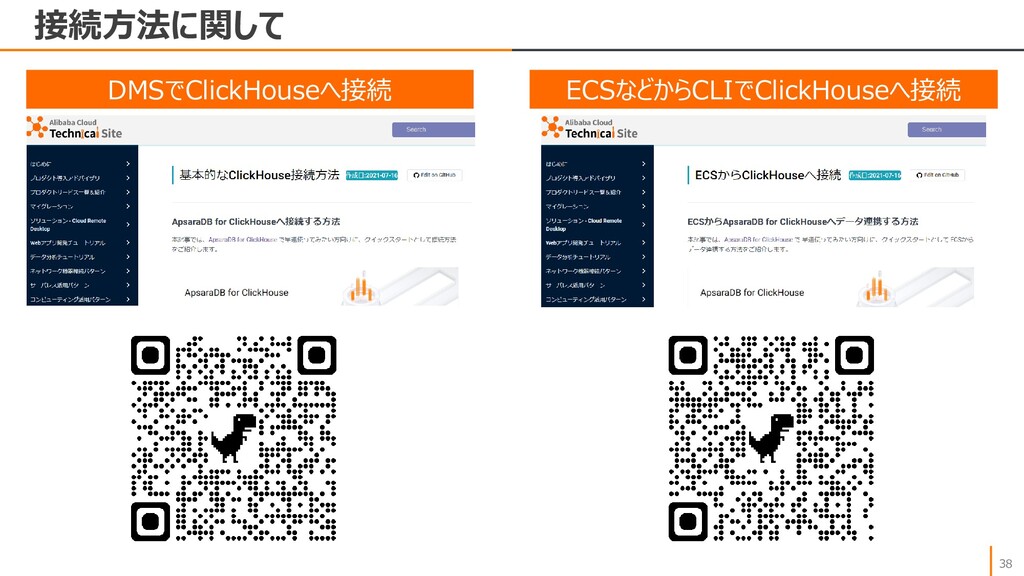{kind=link}
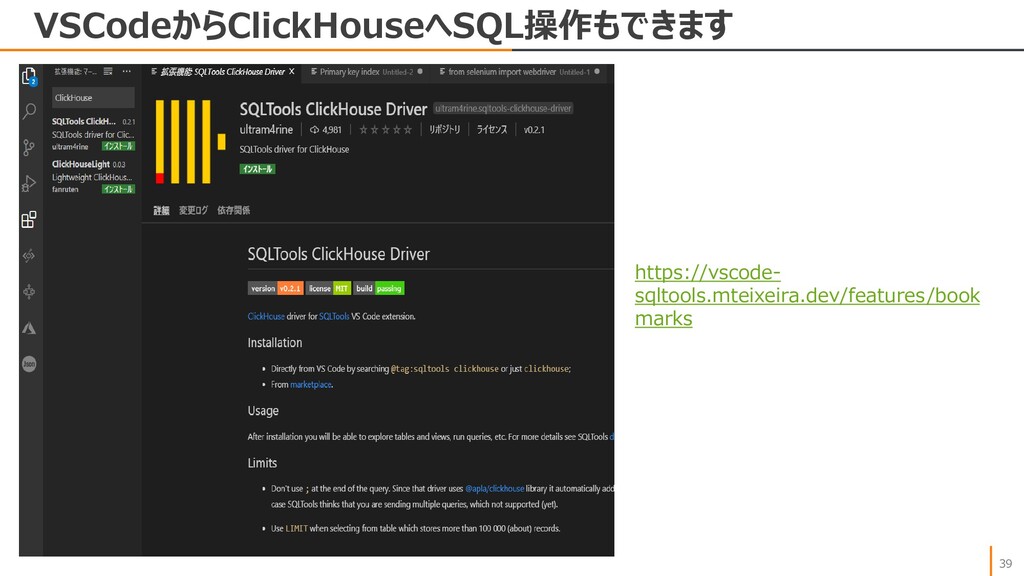{kind=link}
{kind=link}
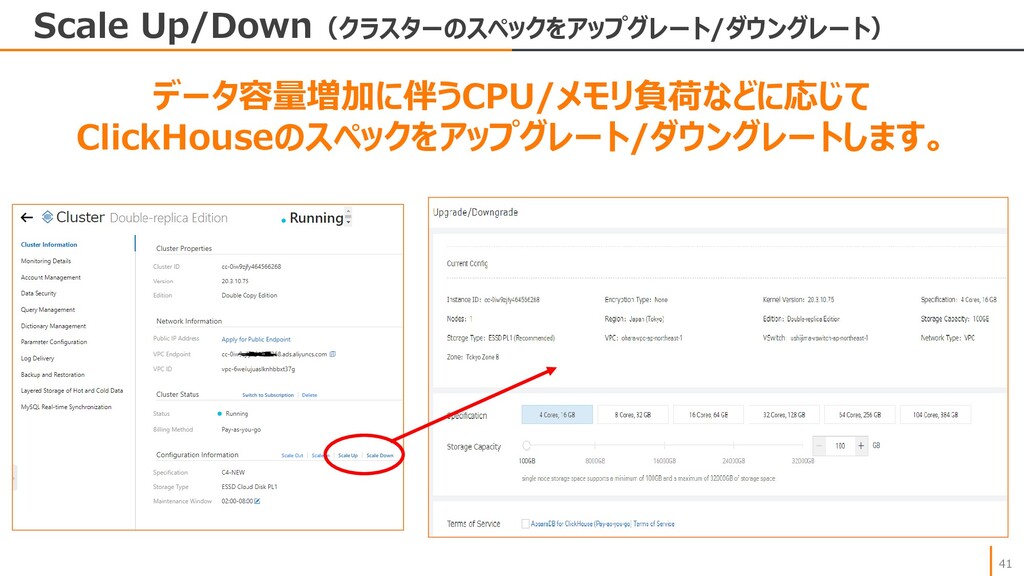{kind=link}
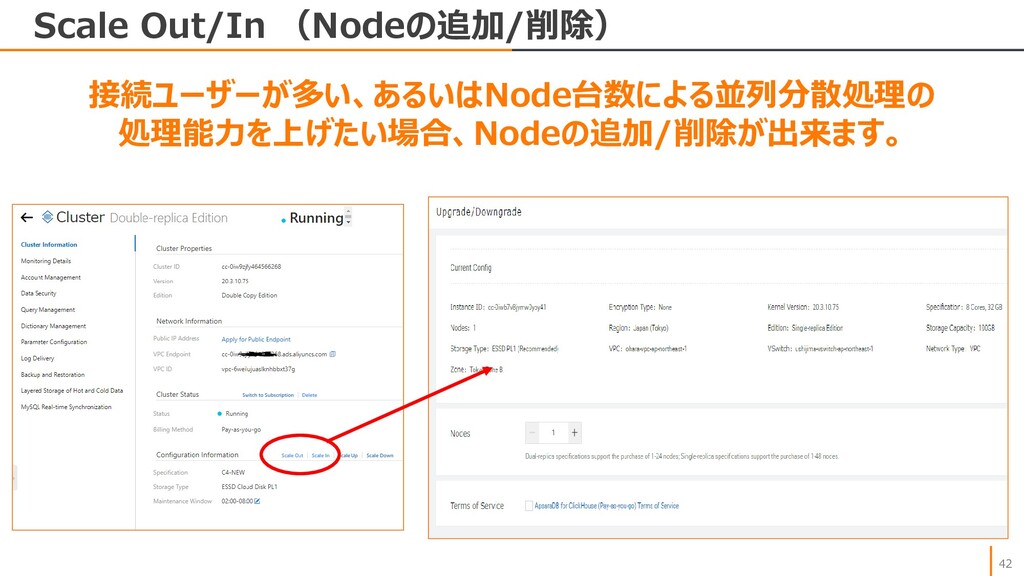{kind=link}
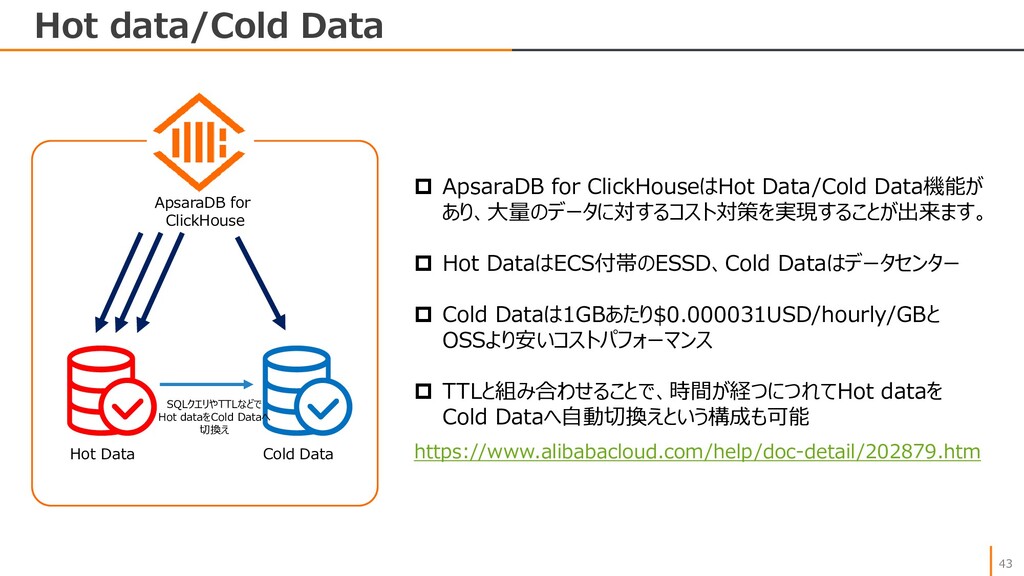{kind=link}
{kind=link}
{kind=link}
{kind=link}
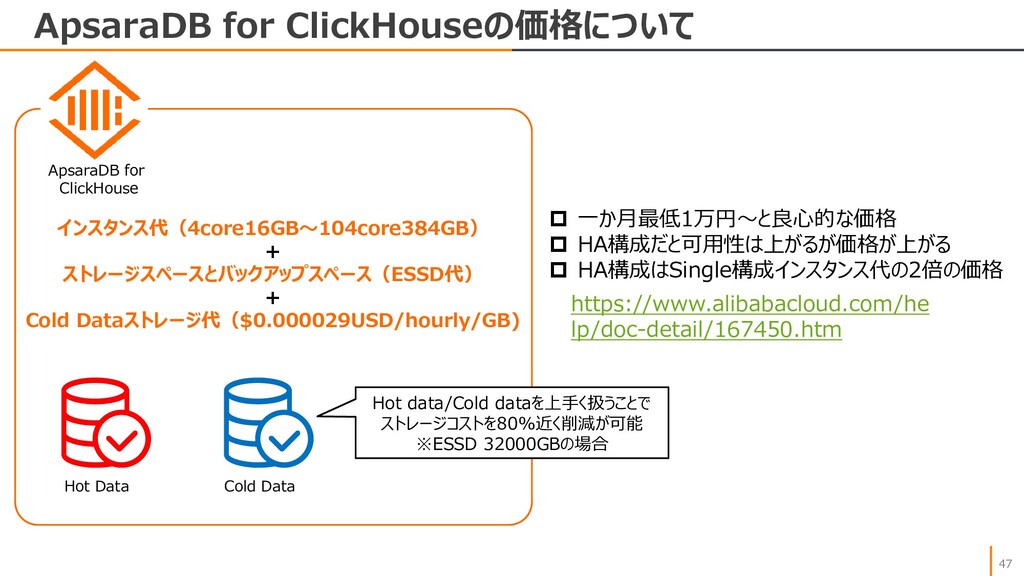{kind=link}
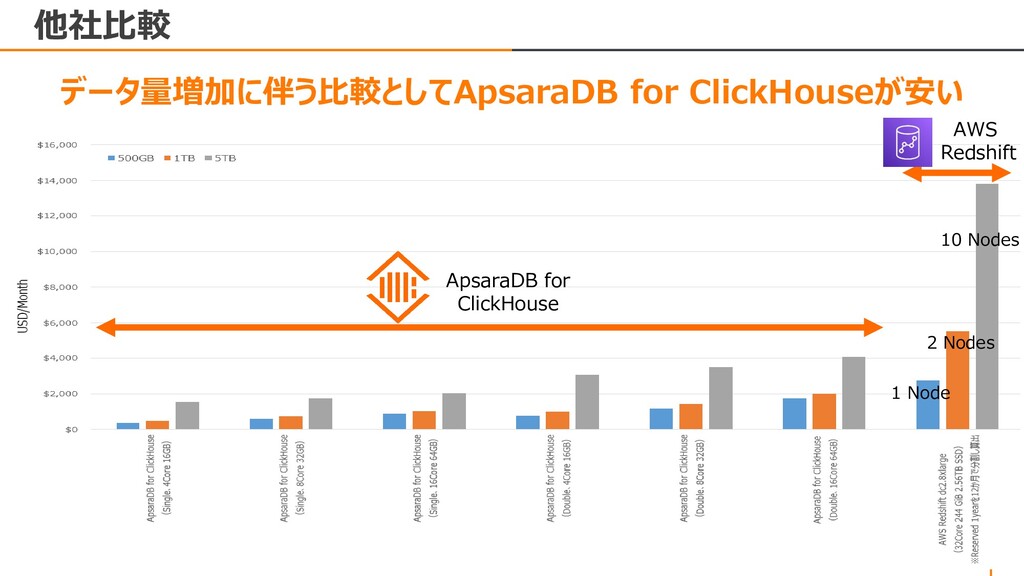{kind=link}
{kind=link}
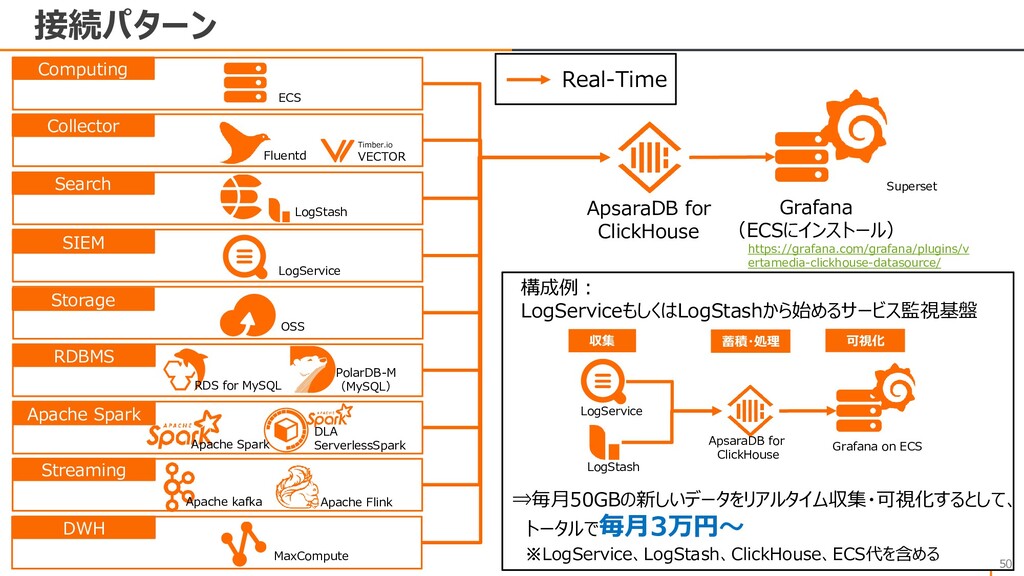{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
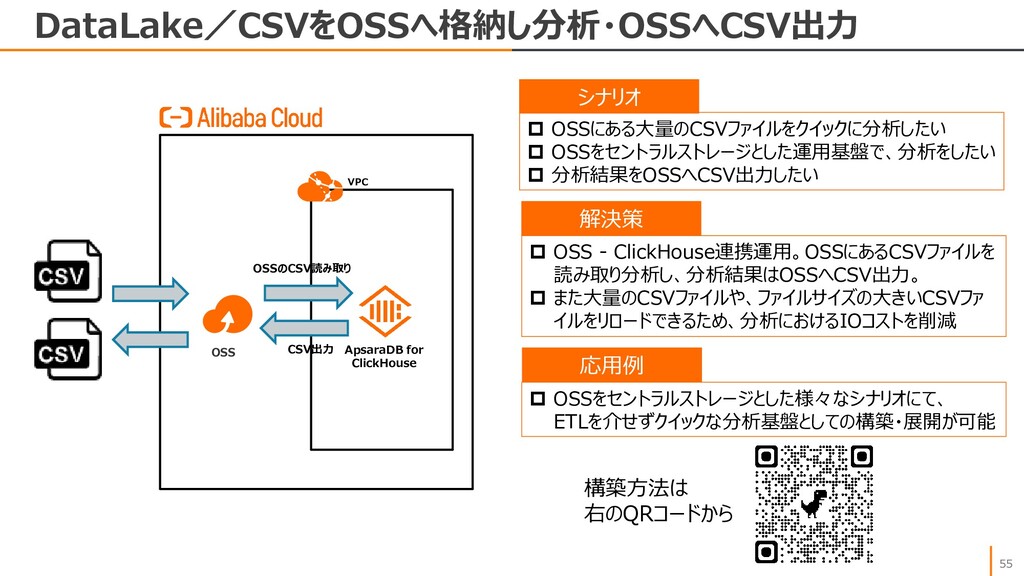{kind=link}
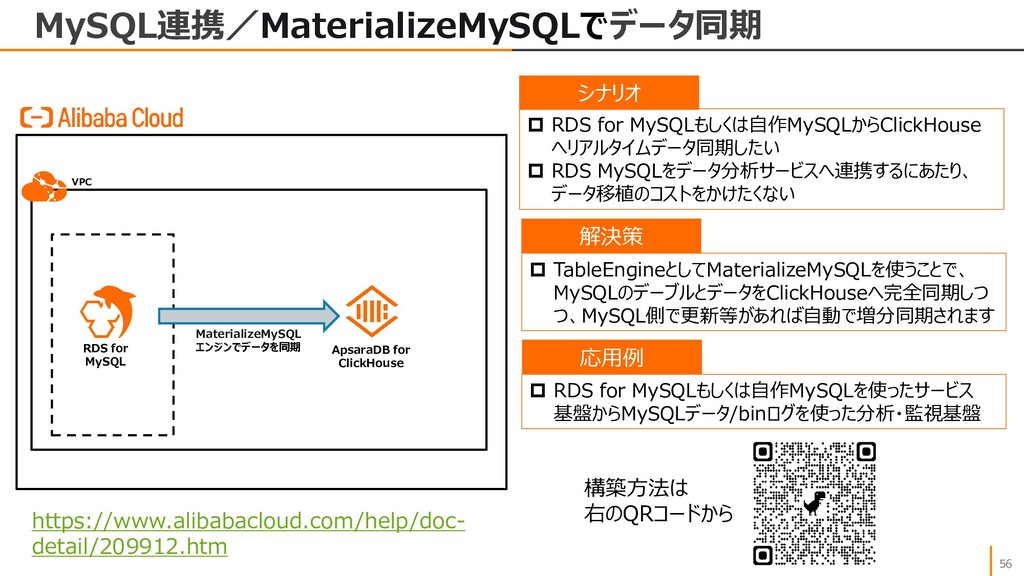{kind=link}
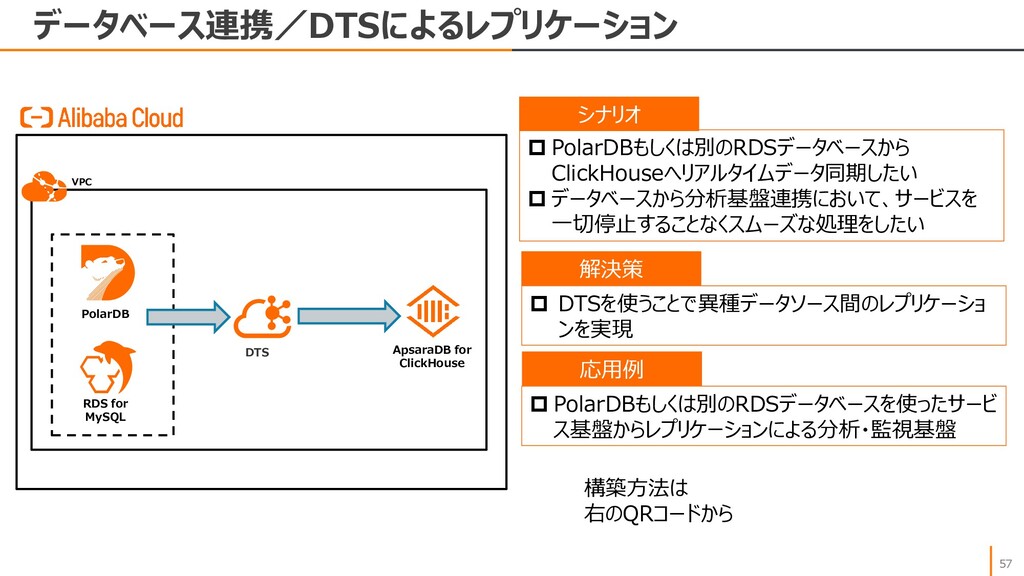{kind=link}
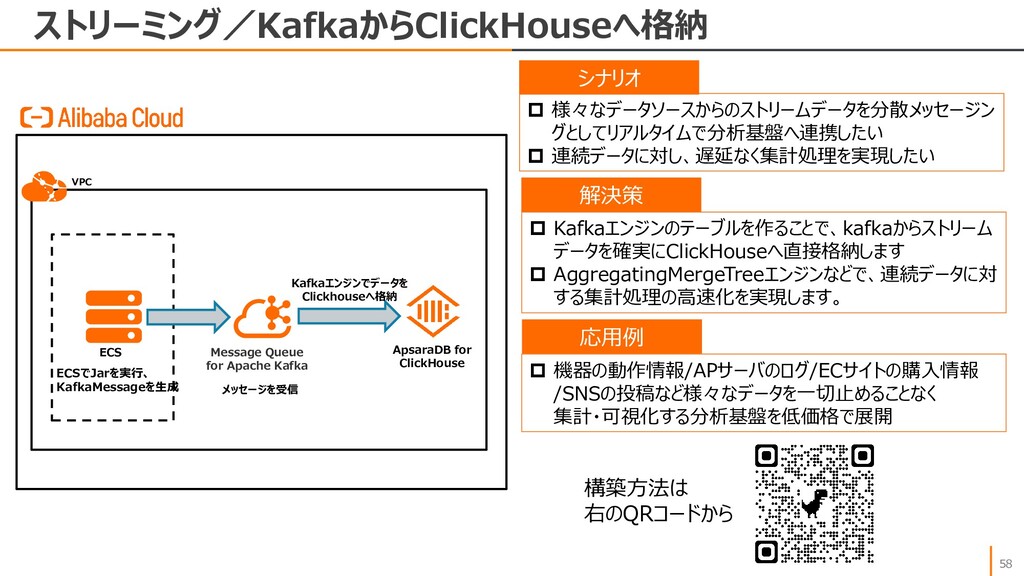{kind=link}
{kind=link}
{kind=link}
{kind=link}