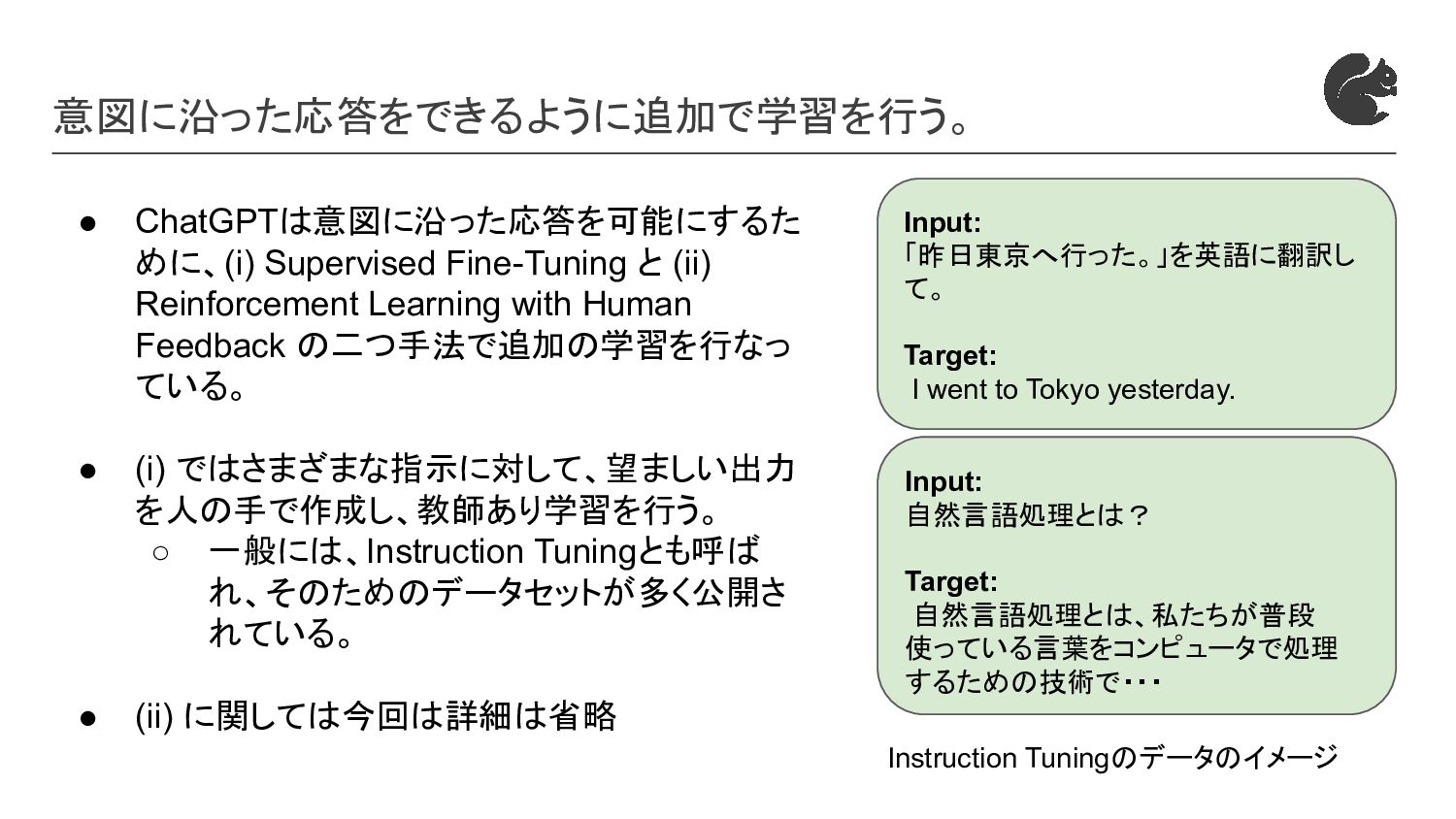
with Human Feedback の二つ手法で追加の学習を行なっ ている。 • (i) ではさまざまな指示に対して、望ましい出力 を人の手で作成し、教師あり学習を行う。 ◦ 一般には、Instruction Tuningとも呼ば れ、そのためのデータセットが多く公開さ れている。 • (ii) に関しては今回は詳細は省略 Input: 「昨日東京へ行った。」を英語に翻訳し て。 Target: I went to Tokyo yesterday. Input: 自然言語処理とは? Target: 自然言語処理とは、私たちが普段 使っている言葉をコンピュータで処理 するための技術で・・・ Instruction Tuningのデータのイメージ
{kind=link}
{kind=link}
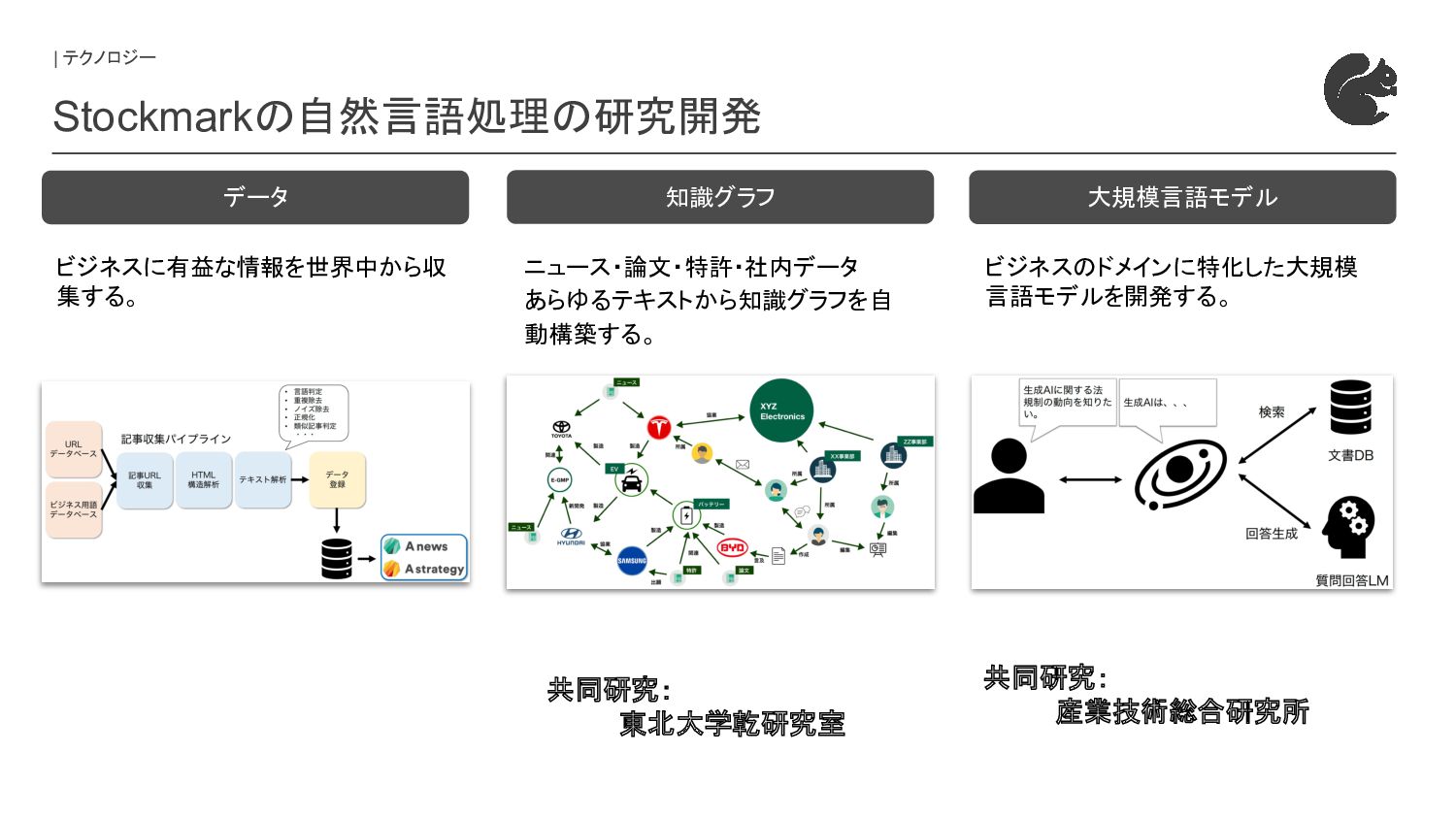{kind=link}
{kind=link}
{kind=link}
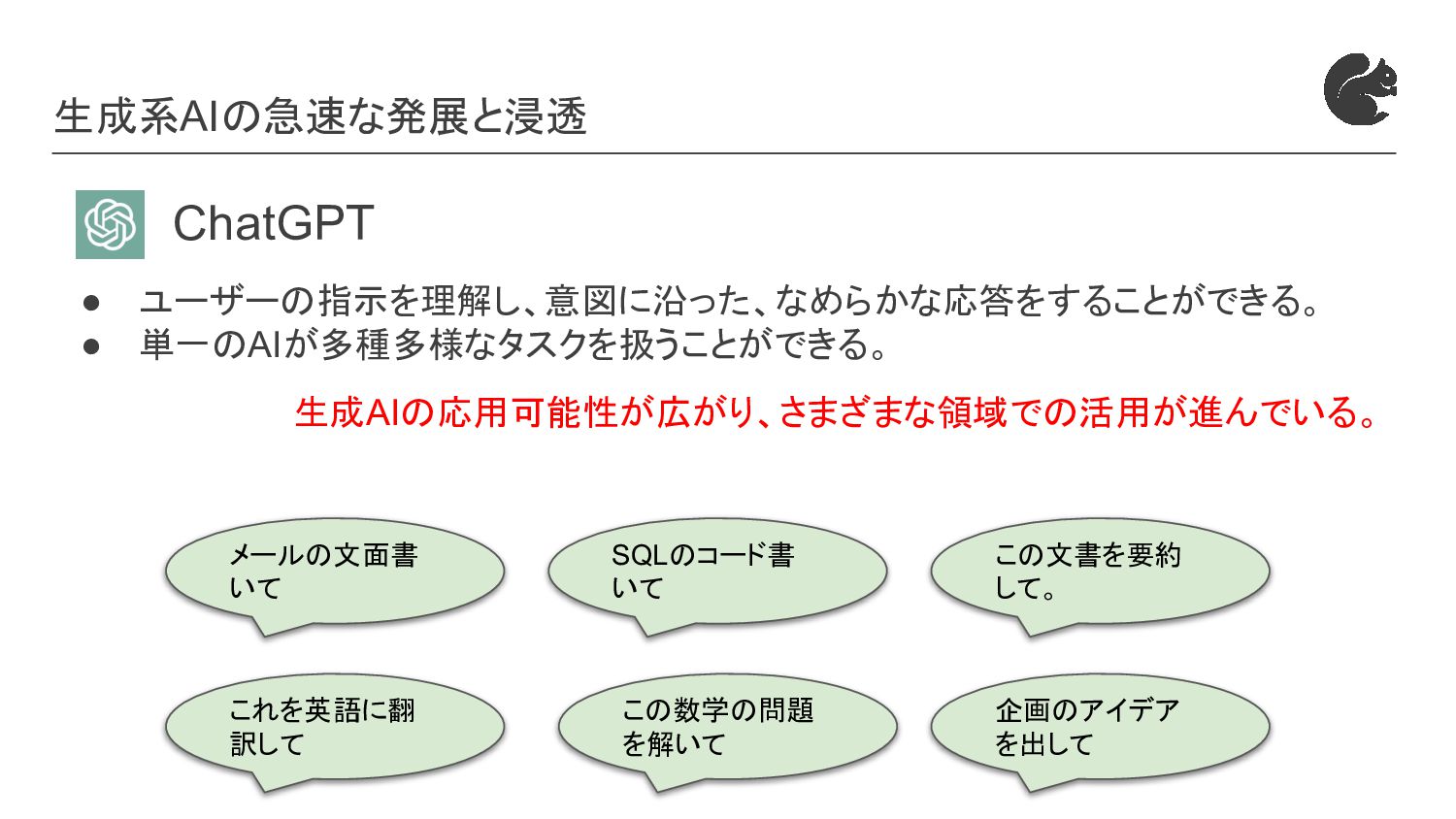{kind=link}
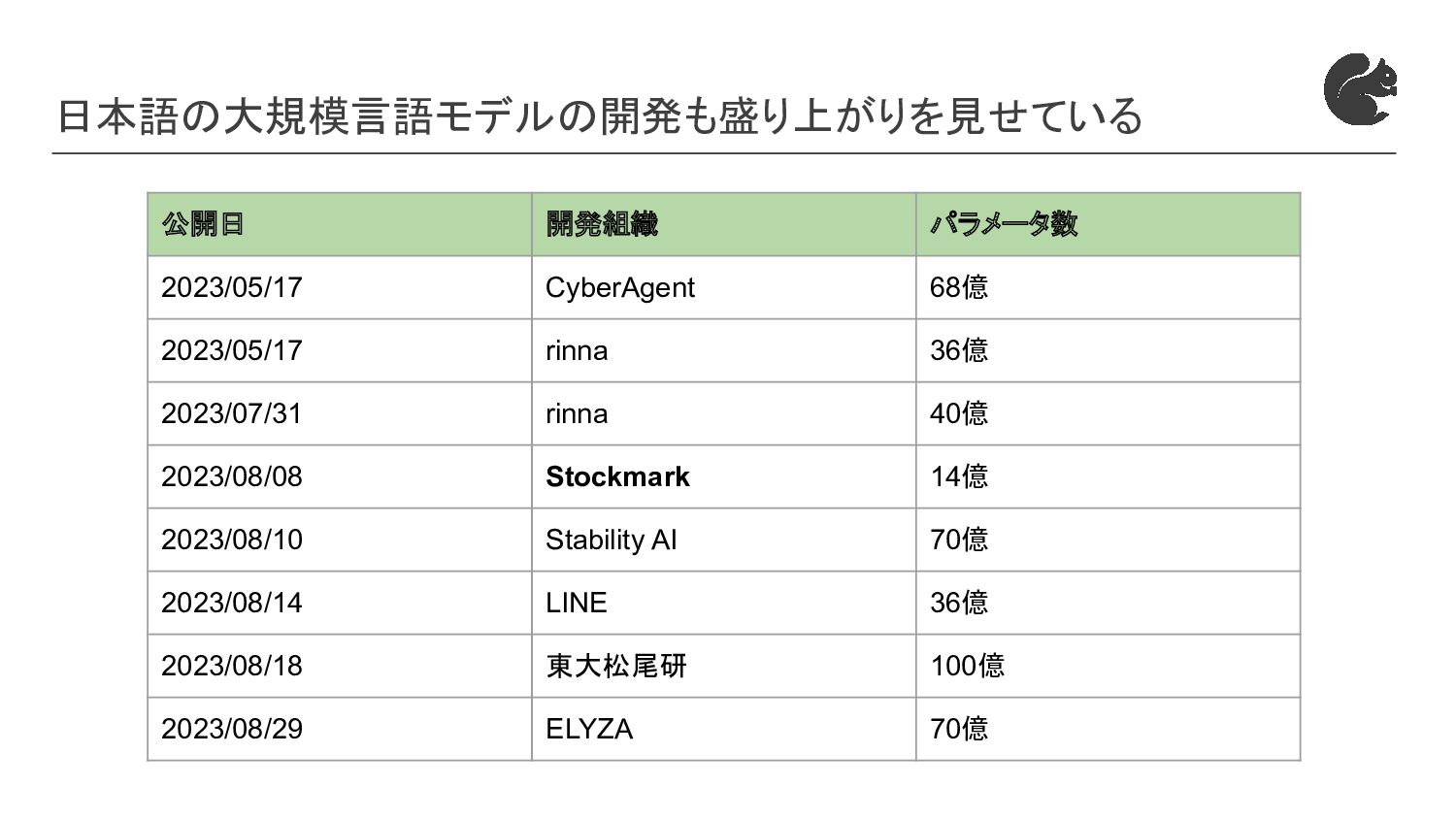{kind=link}
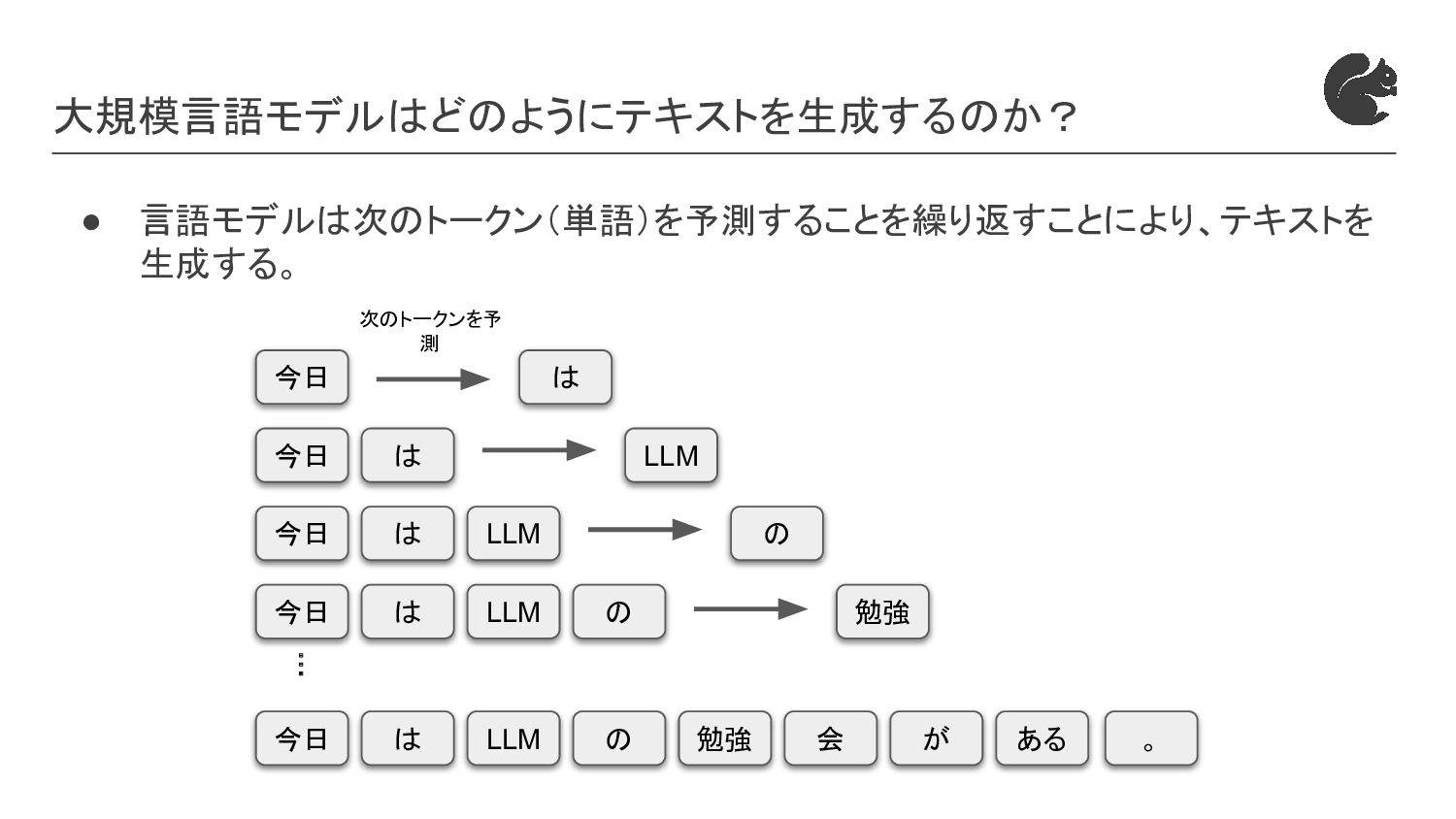{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}