Designing Functional Data Pipelines for Reproducibility and Maintainability
Event: EuroPython 2021
Date: 29 July 2021
Location: Online
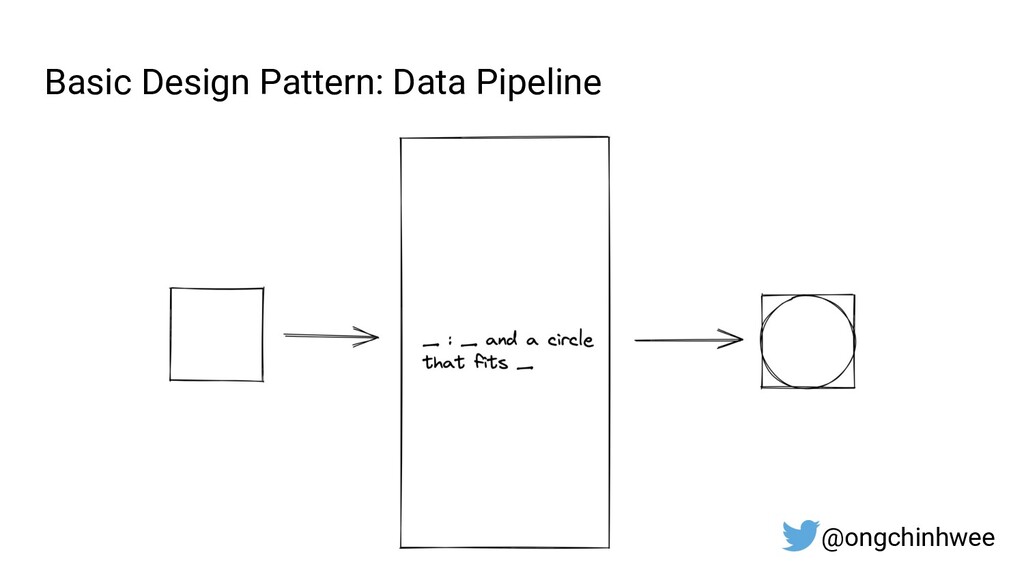
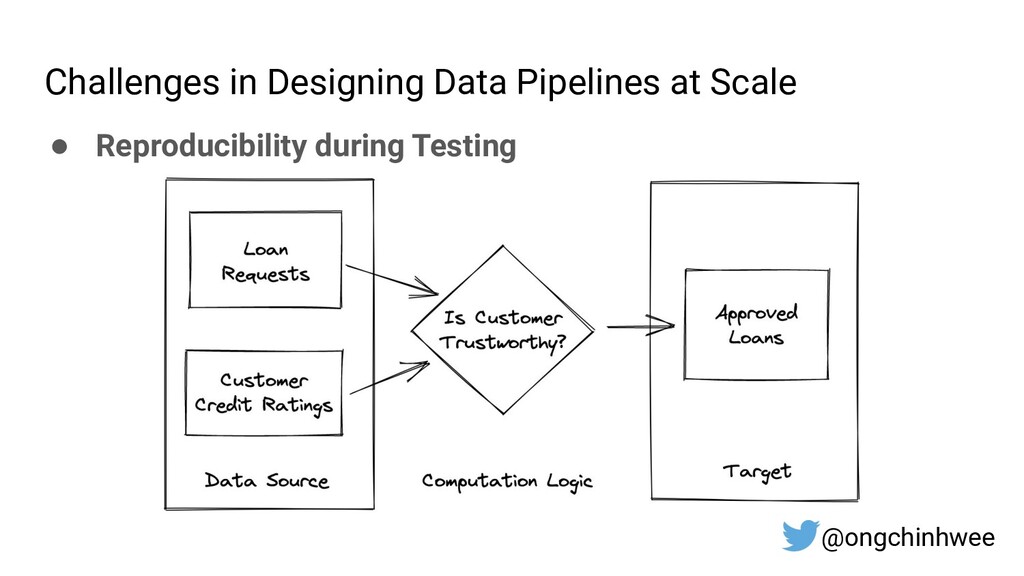
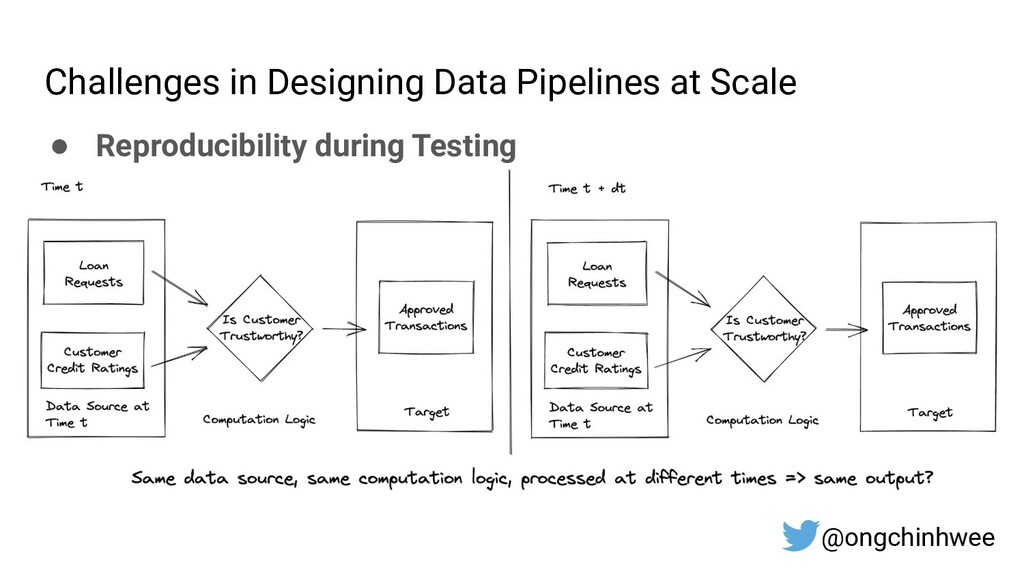
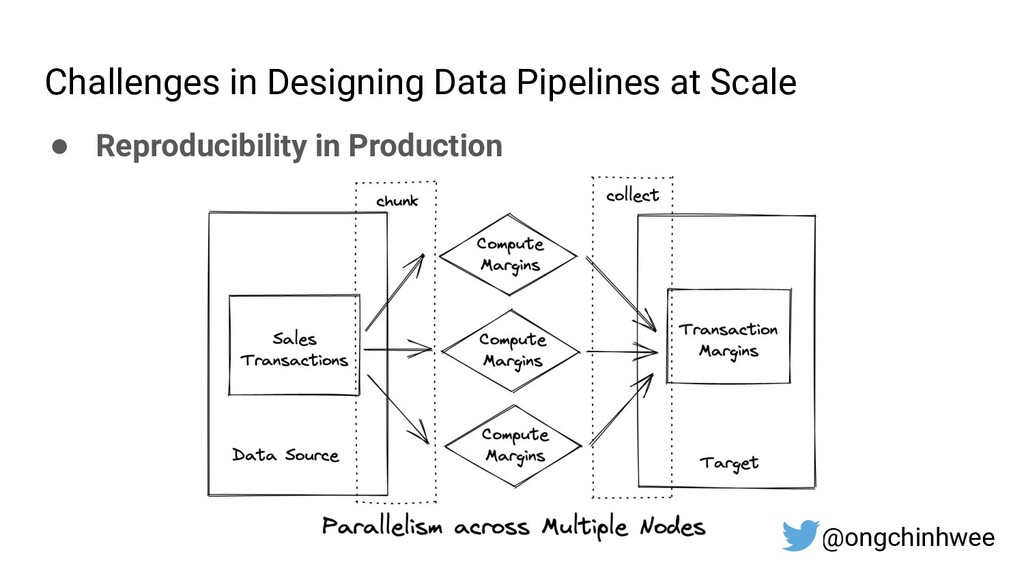
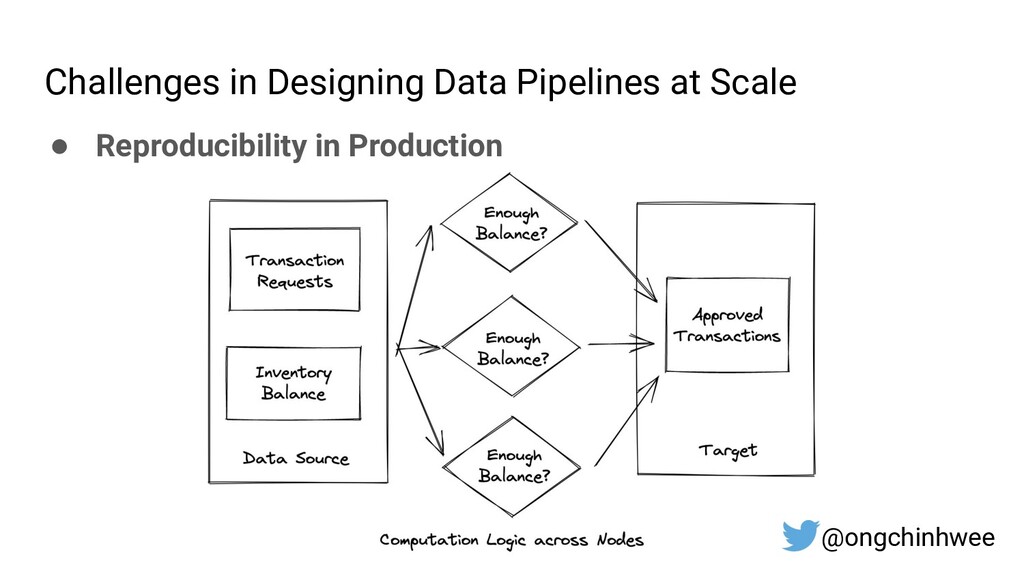
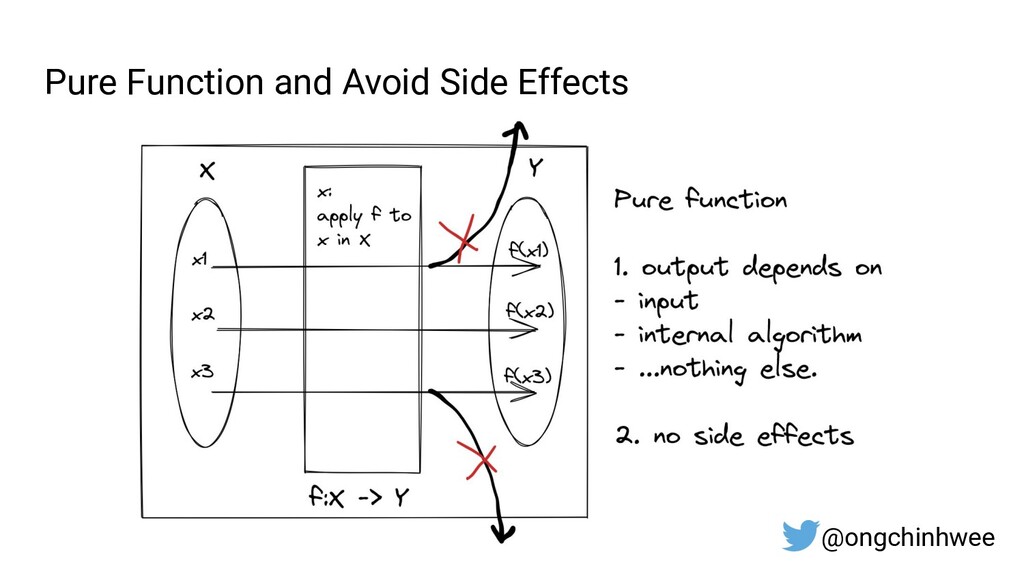
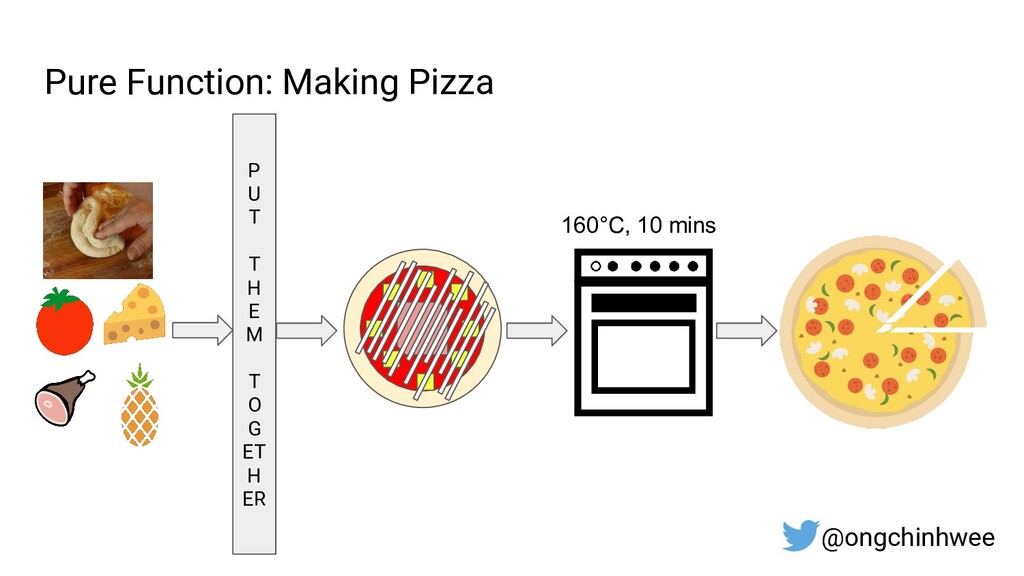
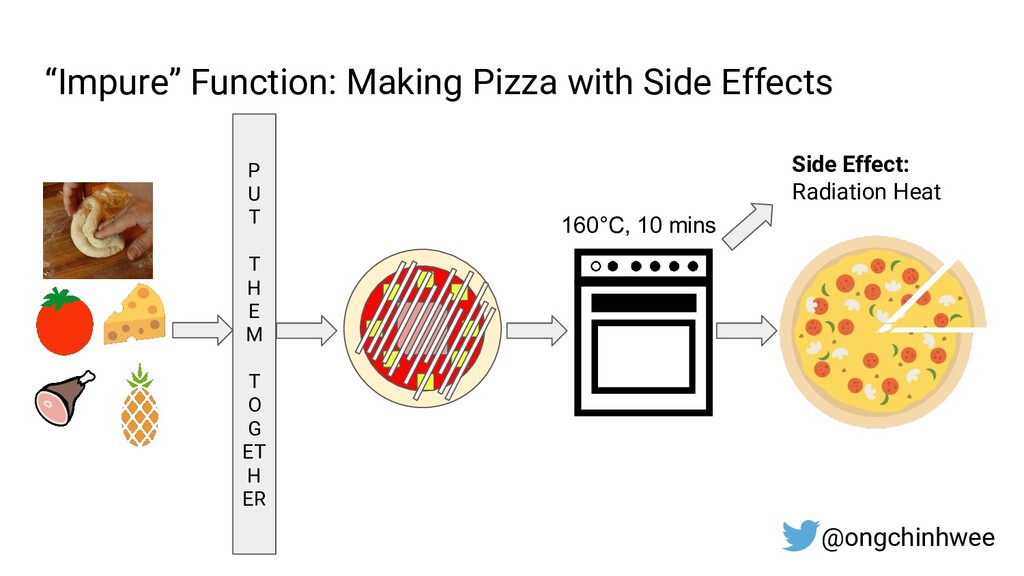
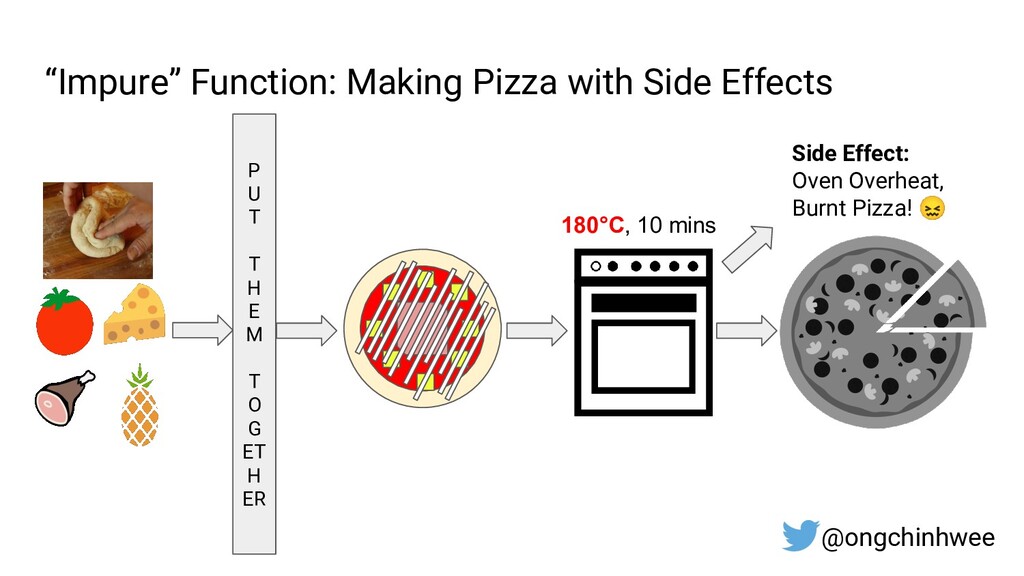
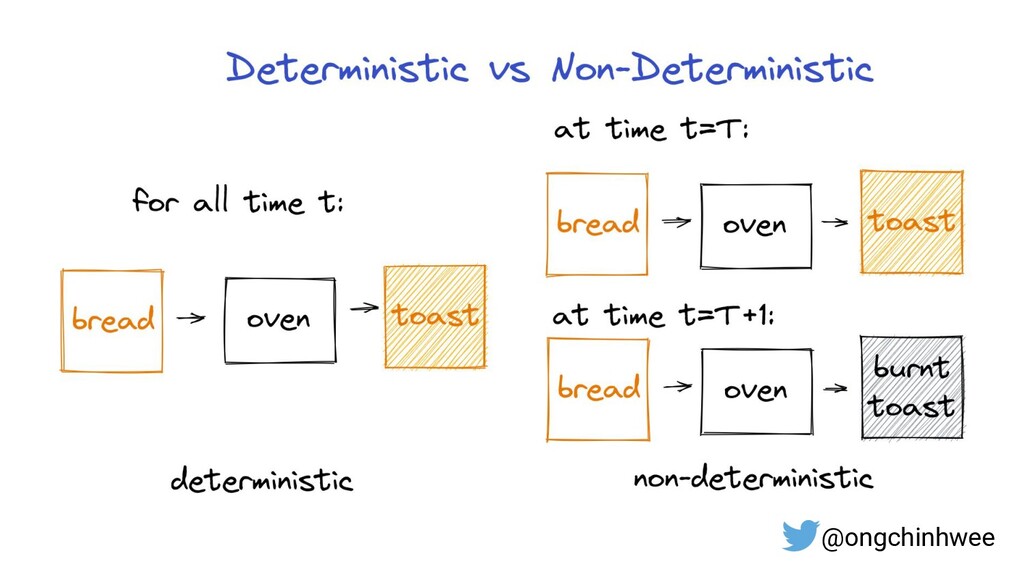
When building data pipelines at scale, it is crucial to design data pipelines that are reliable, scalable and extensible according to evolving business needs. Designing data pipelines for reproducibility and maintainability is a challenge, as testing and debugging across compute units (threads/cores/computes) are often complex and time-consuming due to dependencies and shared states at runtime. In this talk, I will be sharing about common challenges in designing reproducible and maintainable data pipelines at scale, and exploring the use of functional programming in Python to build scalable production-ready data pipelines that are designed for reproducibility and maintainability. Through analogies and realistic examples inspired by data pipeline designs in production environments, you will learn about:
1. What is Functional Programming, and how it differs from other programming paradigms
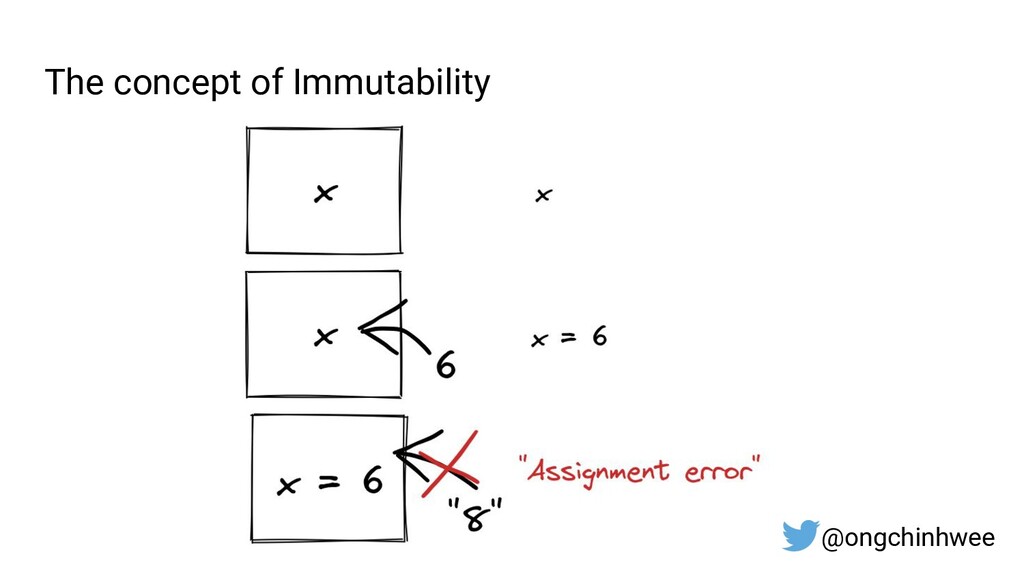
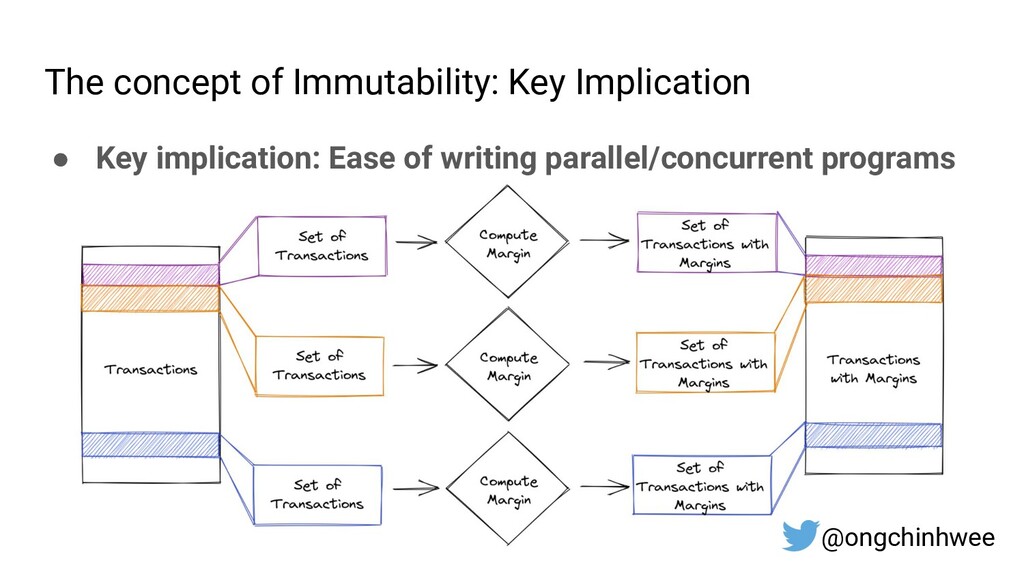
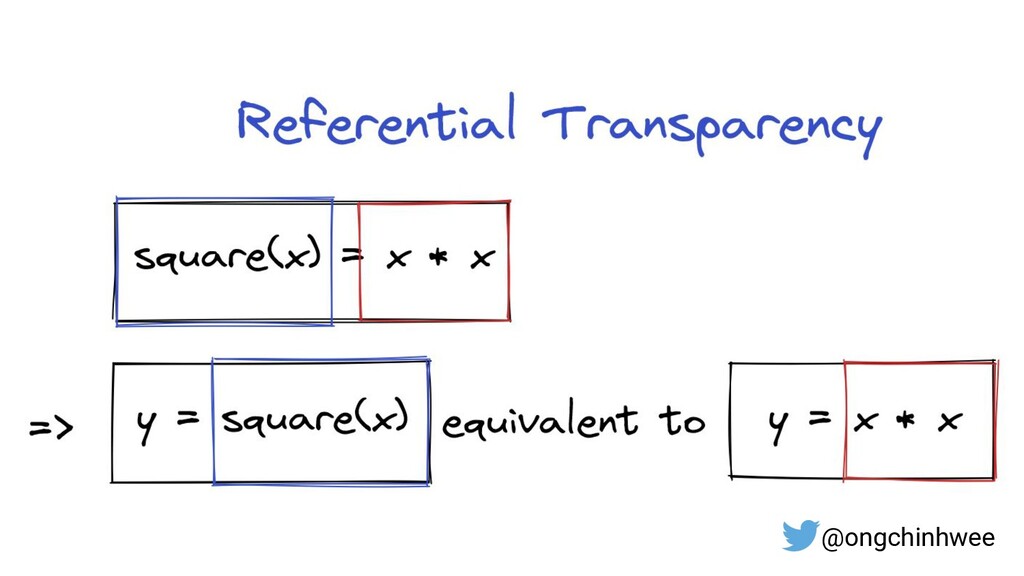
2. Key Principles of Functional Programming
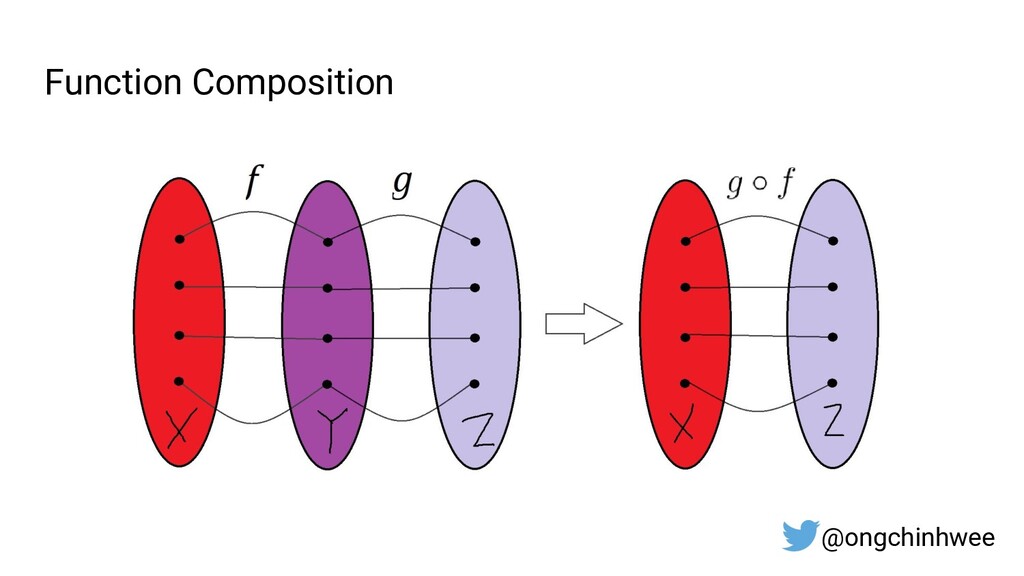
3. How "control flow" is implemented in Functional Programming
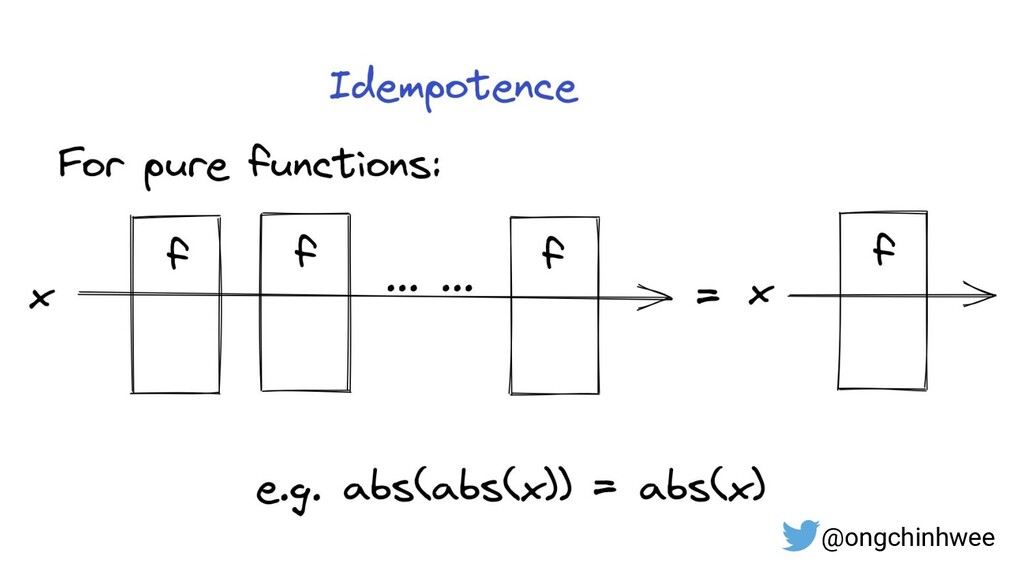
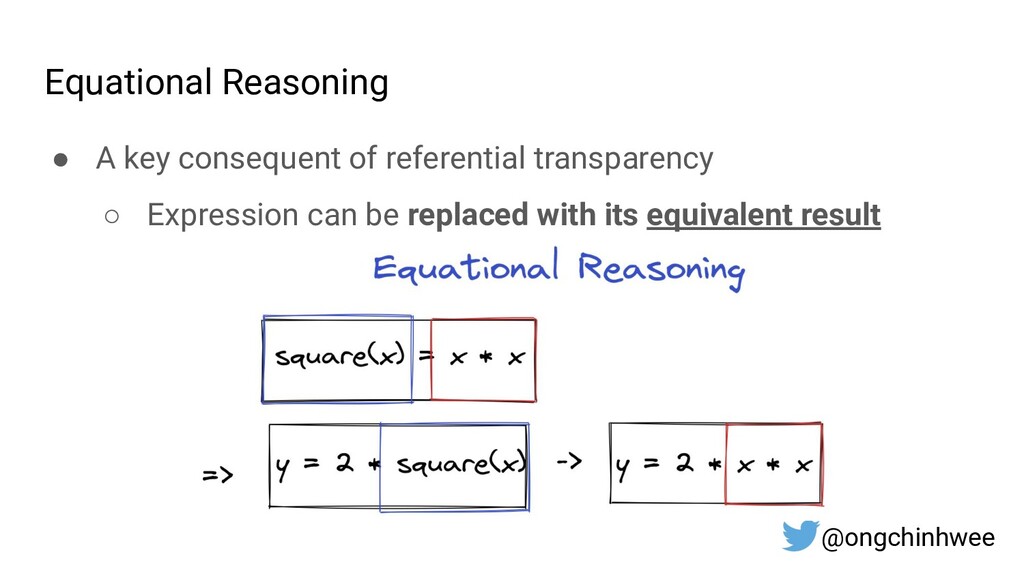
4. Functional design patterns for data pipeline design in Python, and how they improve reproducibility and maintainability
5. Whether it is possible to write a purely functional program in Python
This talk assumes basic understanding of building data pipelines with functions and classes/objects. While the main target audience are data scientists/engineers and developers building data-intensive applications, anyone with hands-on experience in imperative programming (including Python) would be able to understand the key concepts and use-cases in functional programming.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}