tools, etc) • Experimental nature of academic SW tends to be difficult to install, configure and deploy • Heterogeneous executing platforms and system architecture (laptop→supercomputer)
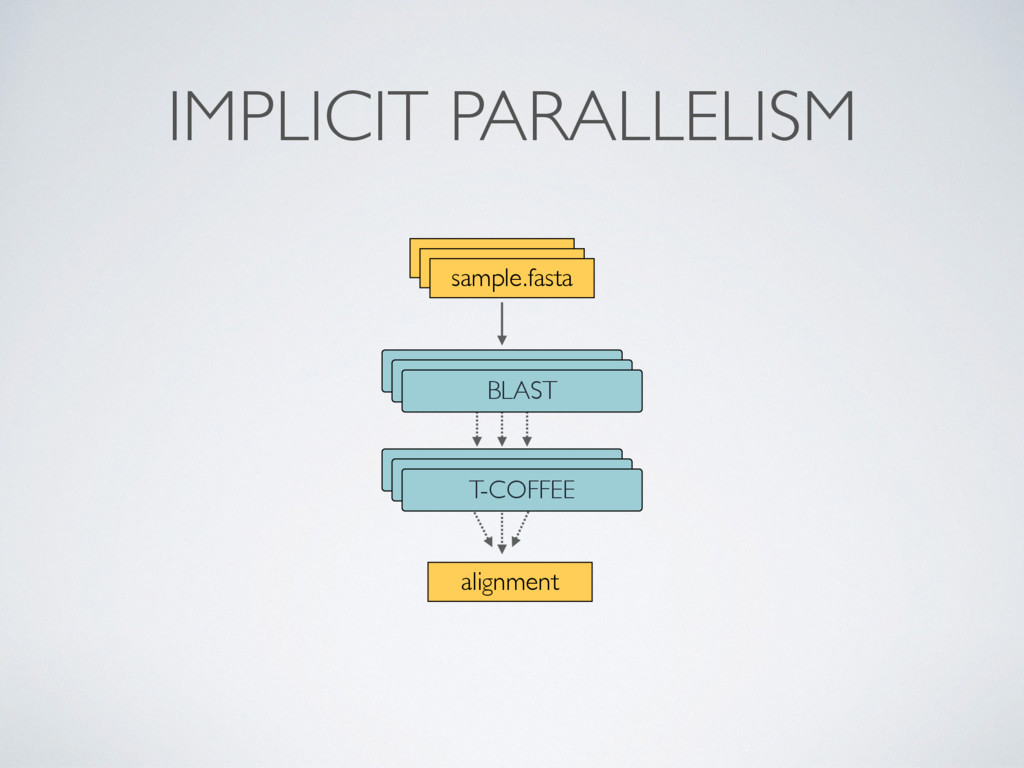
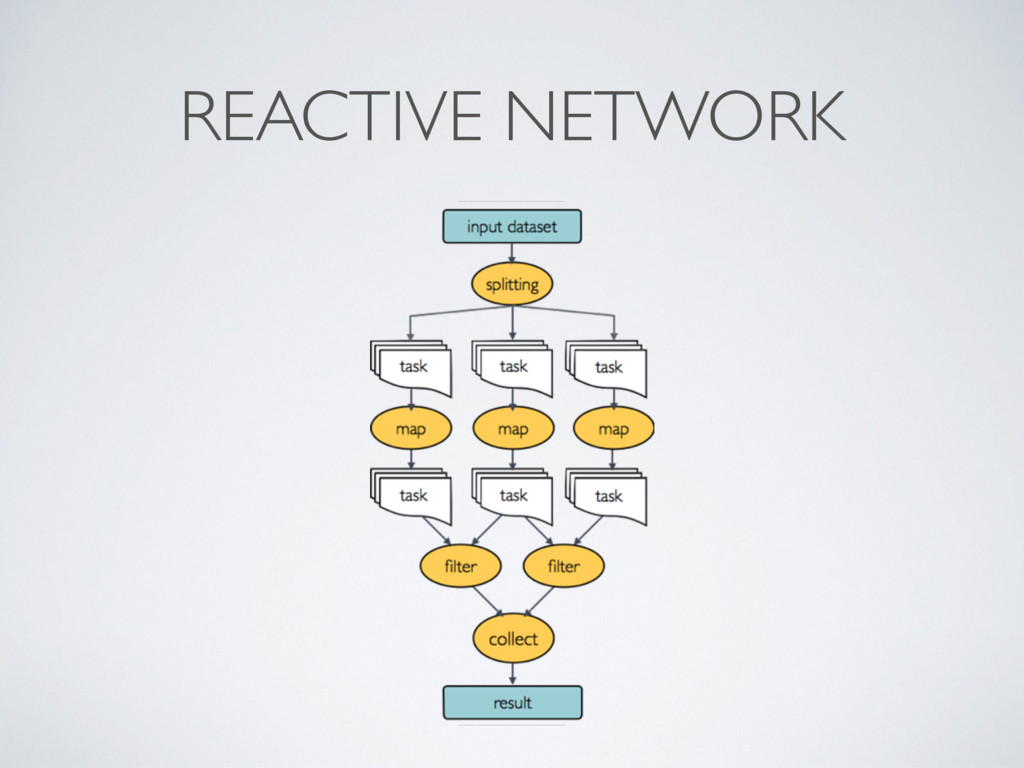
wait for data, when an input set is ready the process is executed • They communicate by using dataflow variables i.e. async stream of data called channels • Parallelisation and tasks dependencies are implicitly defined by process in/out declarations
of Cornell University • Center for Biotechnology, Bielefeld University • Genetic Cancer group, International Agency for Cancer Research • Guigo Lab, Center for Genomic Regulation • Medical genetics diagnostic, Oslo University Hospital • National Marrow Donor Program • Joint Genomic Institute • Parasite Genomics, Sanger Institute
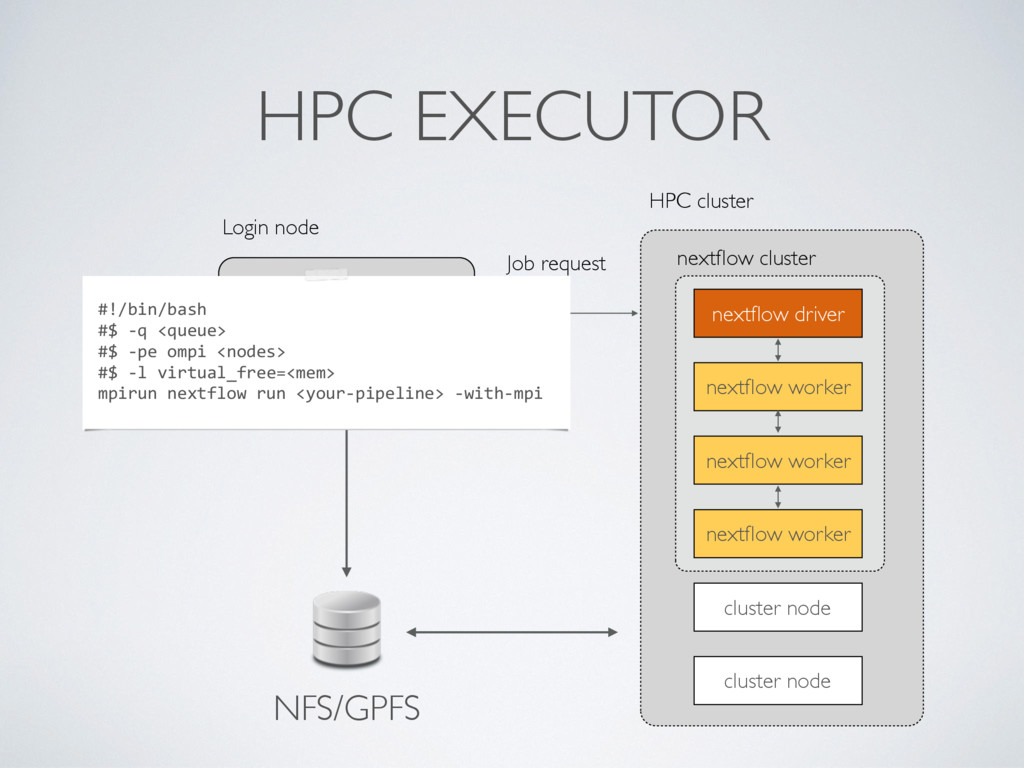
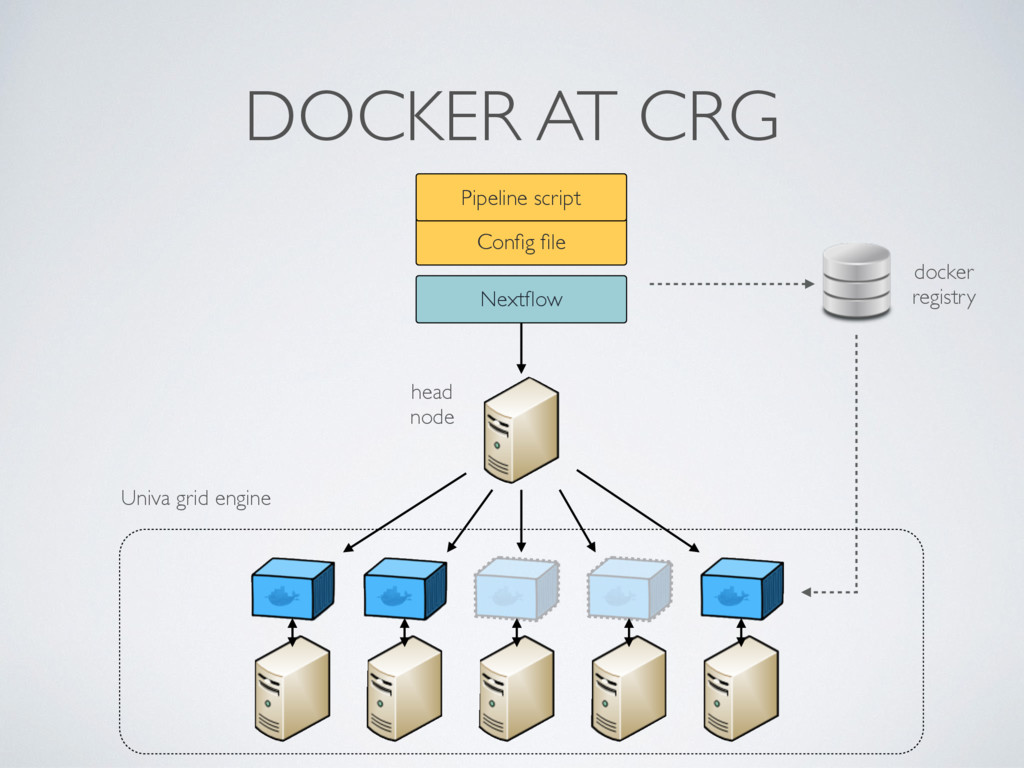
Enhance scheduling capability of HPC execution mode • Version 1.0 (second half 2016) Long term • Web user interface • Enhance support for cloud (Google Compute Engine)
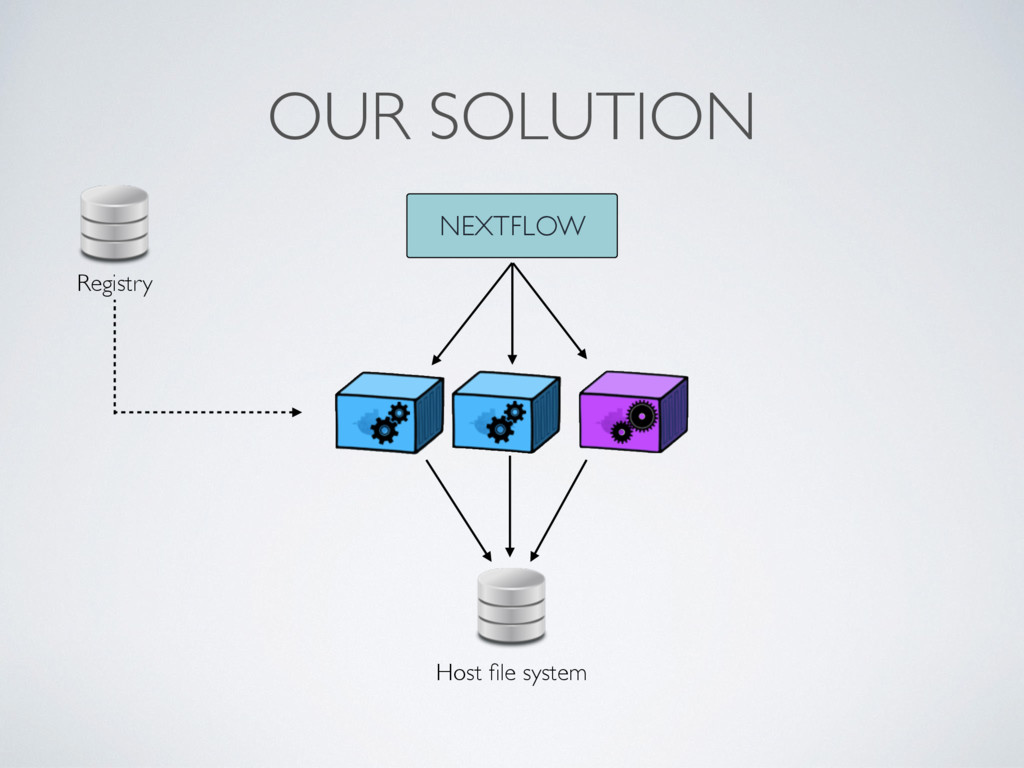
workflows. • It is not supposed to replace your favourite tools • It provides a parallel and scalable environment for your scripts • It enables reproducible pipelines deployment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}