CARRY OUT BIOINFORMATICS ANALYSIS?* • Ability to compile/run the average software suite. • Diversity and complexity of software deployments. • Poor and/or incomplete documentation. • Installation of different software, packages,... and getting them to work on different platforms. • Lack of truly standard file formats. • Time installing software. • Lack of computing resources (cpus, memory, storage, etc). * available at https://goo.gl/TF9TMj
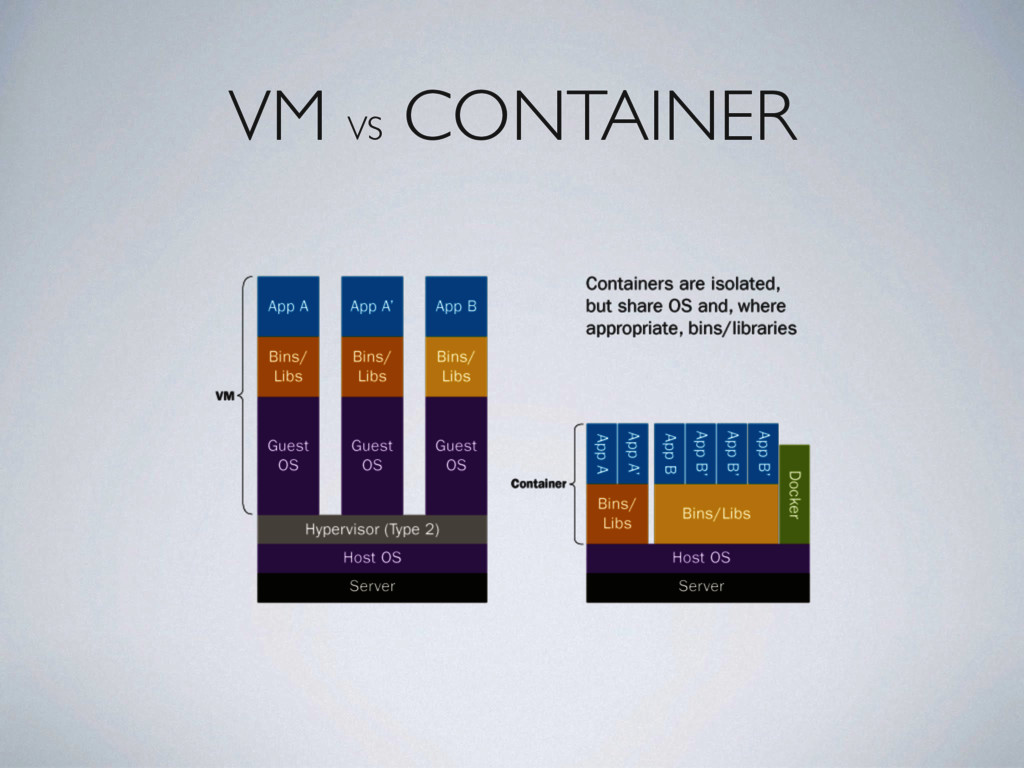
tools, etc) • Experimental nature of academic SW tends to be difficult to install, configure and deploy • Heterogeneous executing platforms and system architecture (laptop→supercomputer)
P, Heuer ML, Notredame C. (2015) The impact of Docker containers on the performance of genomic pipelines. PeerJ 3:e1273 https://dx.doi.org/10.7717/peerj.1273
of Cornell University • Center for Biotechnology, Bielefeld University • Genetic Cancer group, International Agency Cancer Research • Guigo Lab, Center for Genomic Regulation • Medical genetics diagnostic, Oslo University Hospital • National Marrow Donor Program • Parasite Genomics, Sanger Institute • Sabeti Lab, Broad Institute • Veracyte Inc
Support for Git LFS (large file storage) • Version 1.0 (first half 2016) Long term • Enhance processing capabilities with distributed caching and data affinity. • Interoperability with YARN / Spark clusters / Common WL
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}