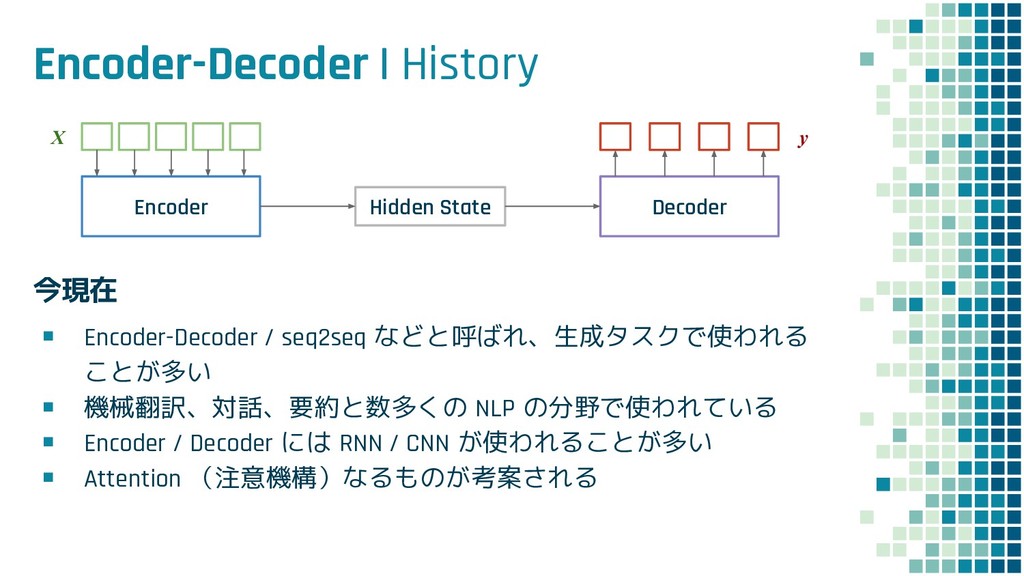
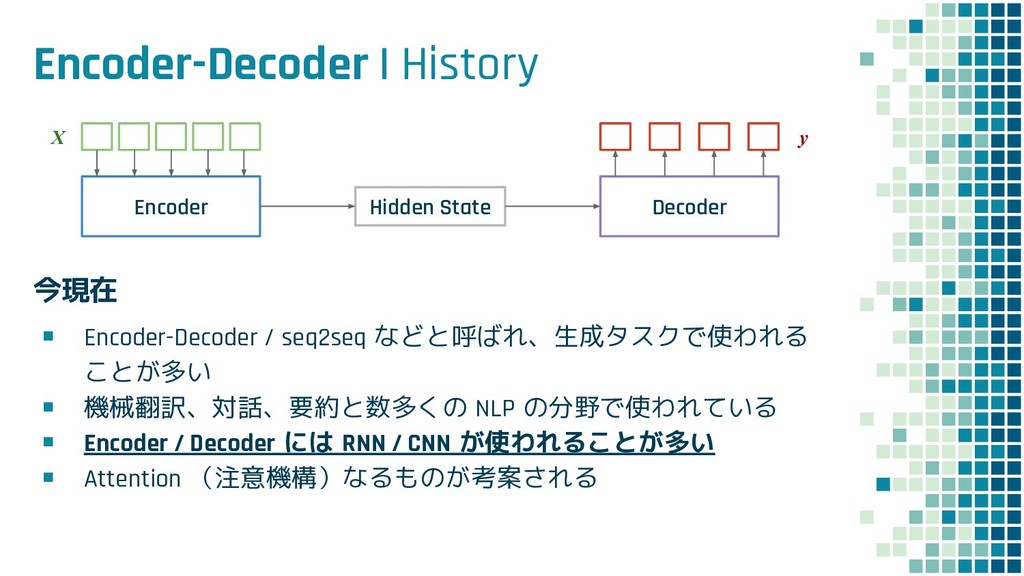
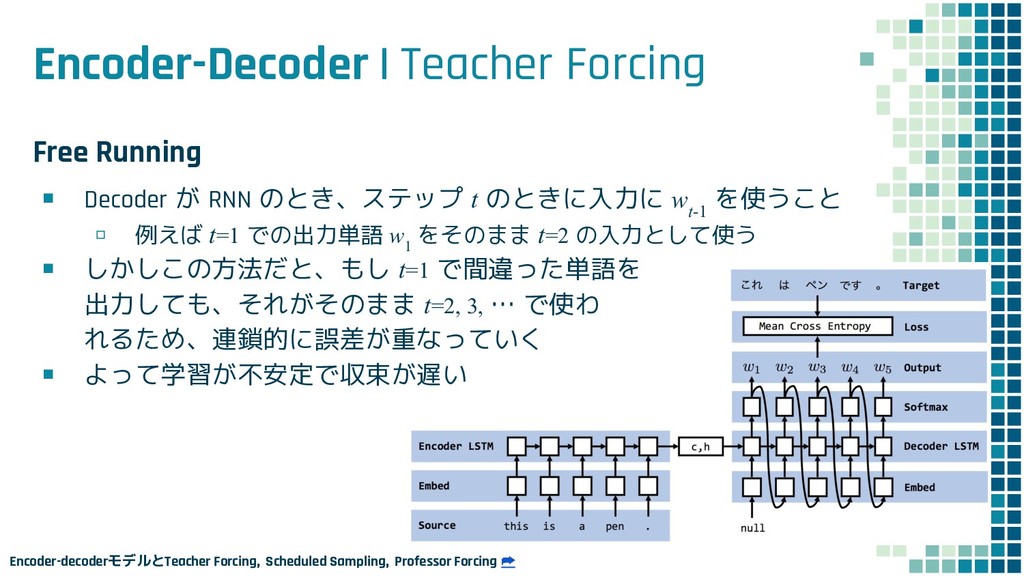
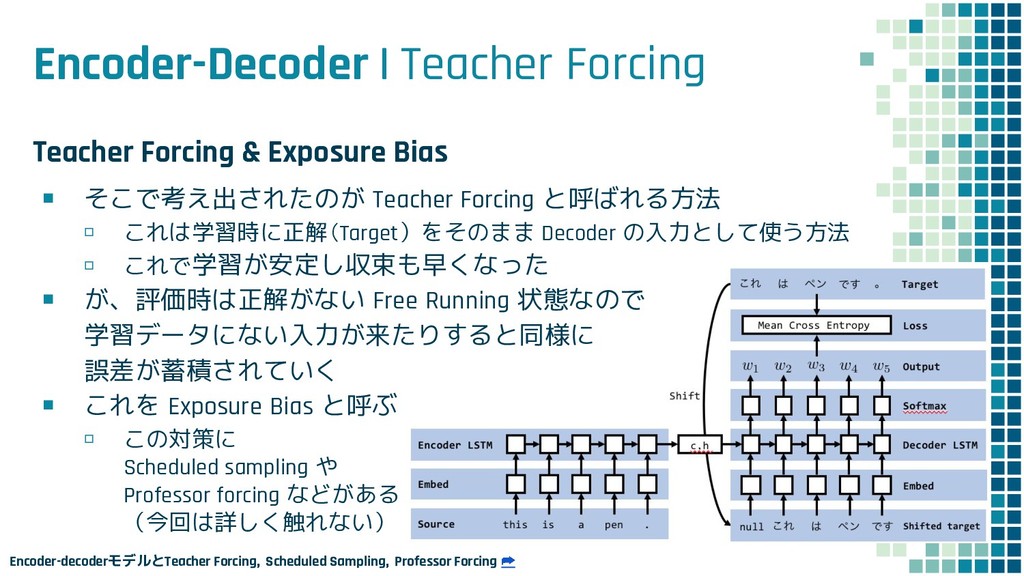
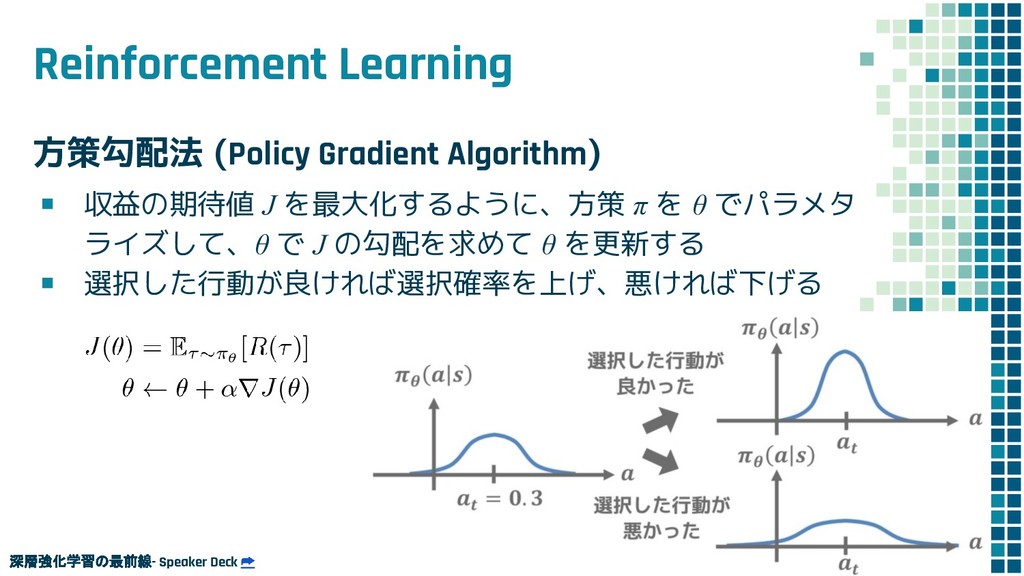
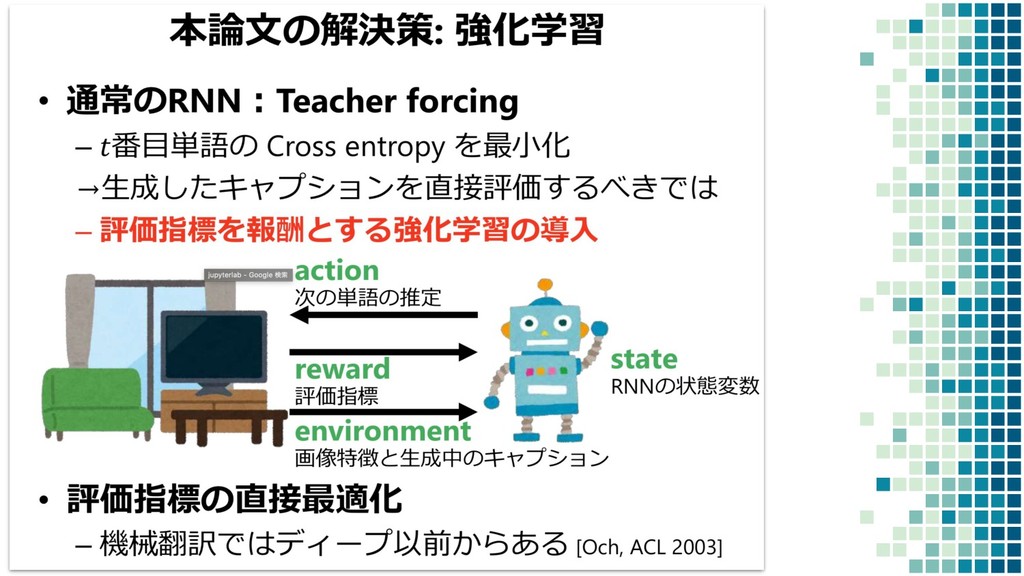
+ Policy Learning ▪ Teacher Forcing loss L ml ▪ Policy Learning loss L rl ▪ Mixed loss L mixed 出力 y と正解 y* との maximum-likelihood policy learning の loss 学習時に 25% の確率で正解ではなく t-1 で生成された token を使用するこ とで、exposure bias を軽減する試み
+ Policy Learning ▪ Teacher Forcing loss L ml ▪ Policy Learning loss L rl ▪ Mixed loss L mixed 出力 y と正解 y* との maximum-likelihood policy learning の loss self-critical sequence training という手法を使用
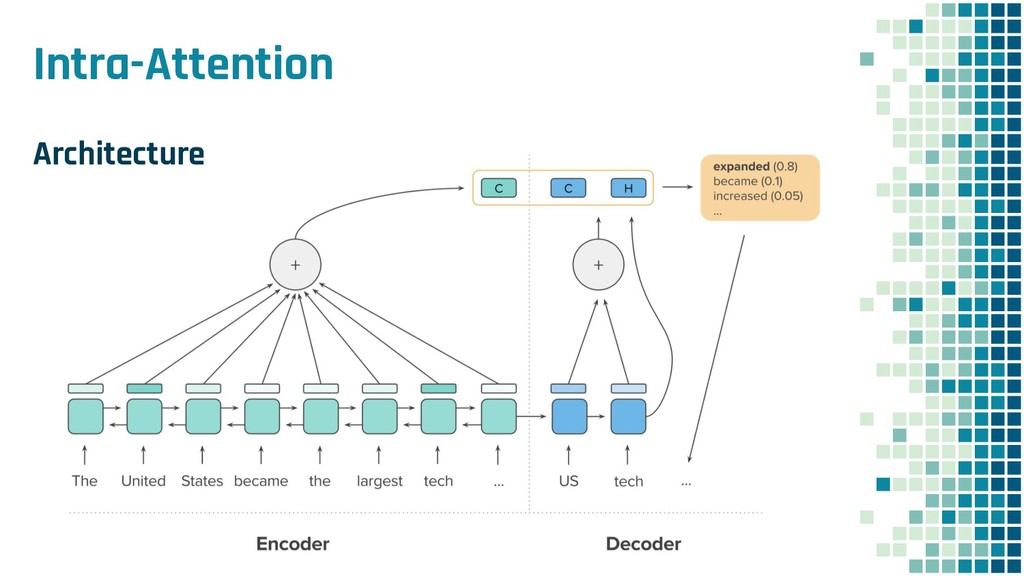
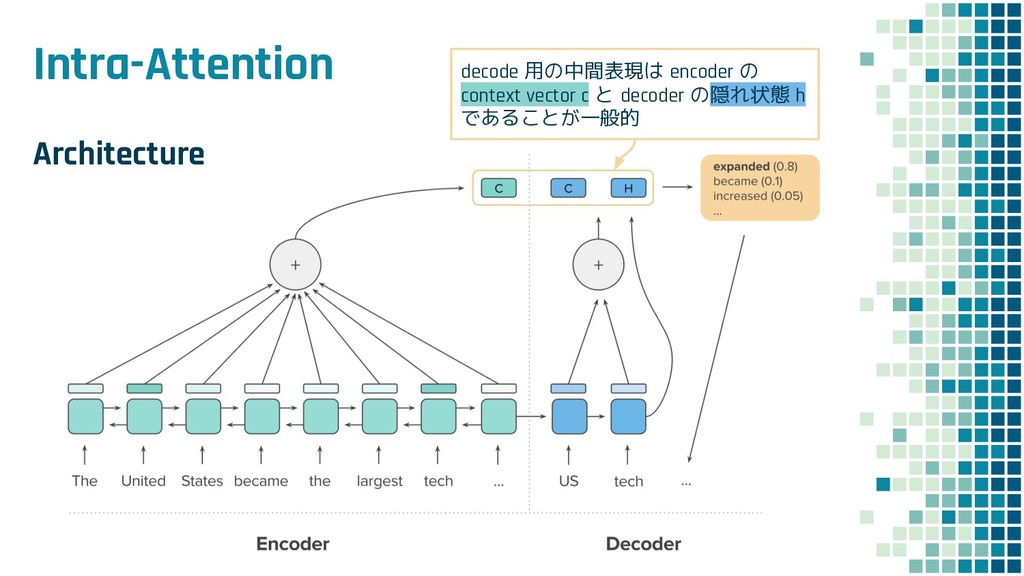
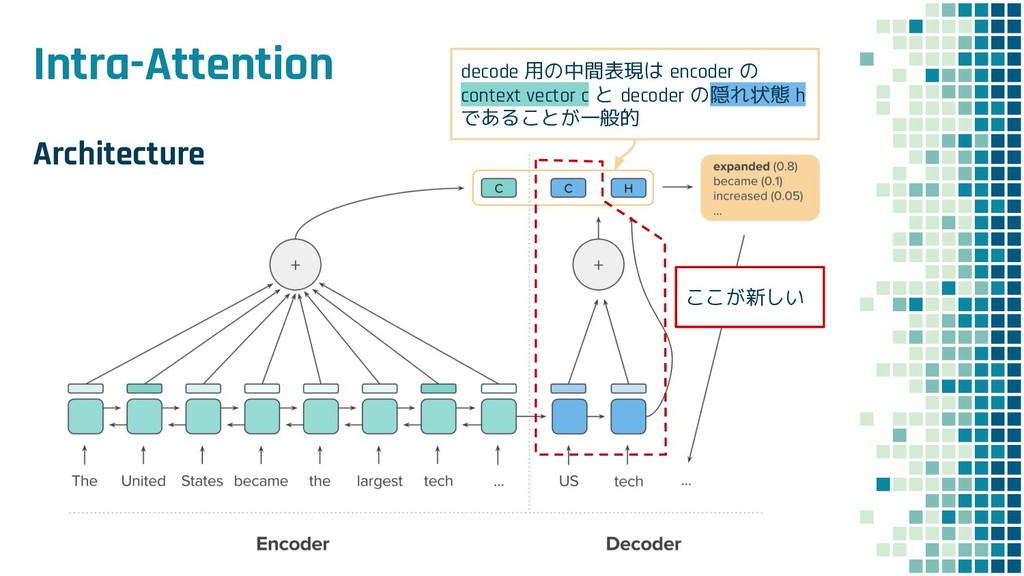
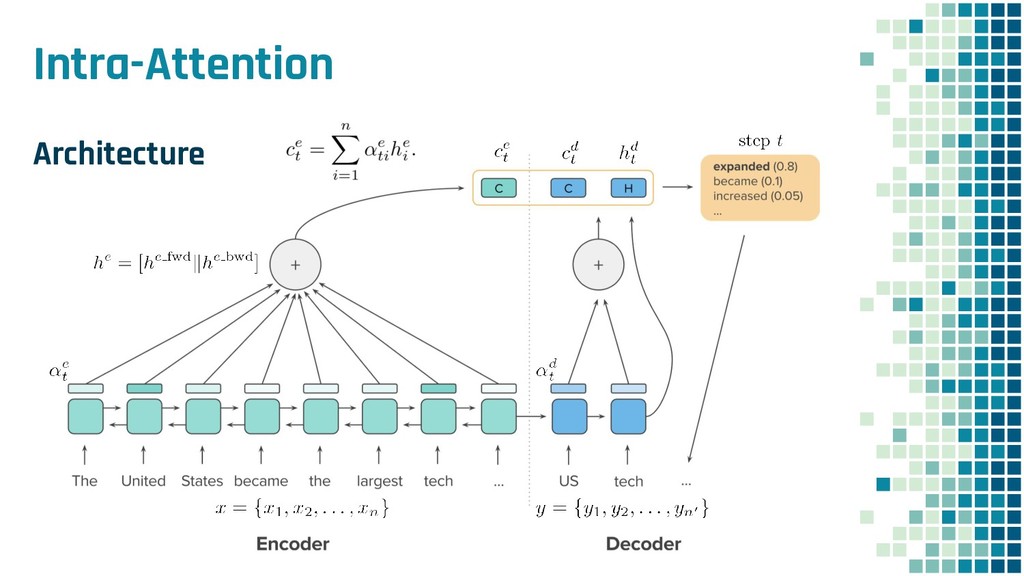
+ Policy Learning ▪ Teacher Forcing loss L ml ▪ Policy Learning loss L rl ▪ Mixed loss L mixed 出力 y と正解 y* との maximum-likelihood policy learning の loss
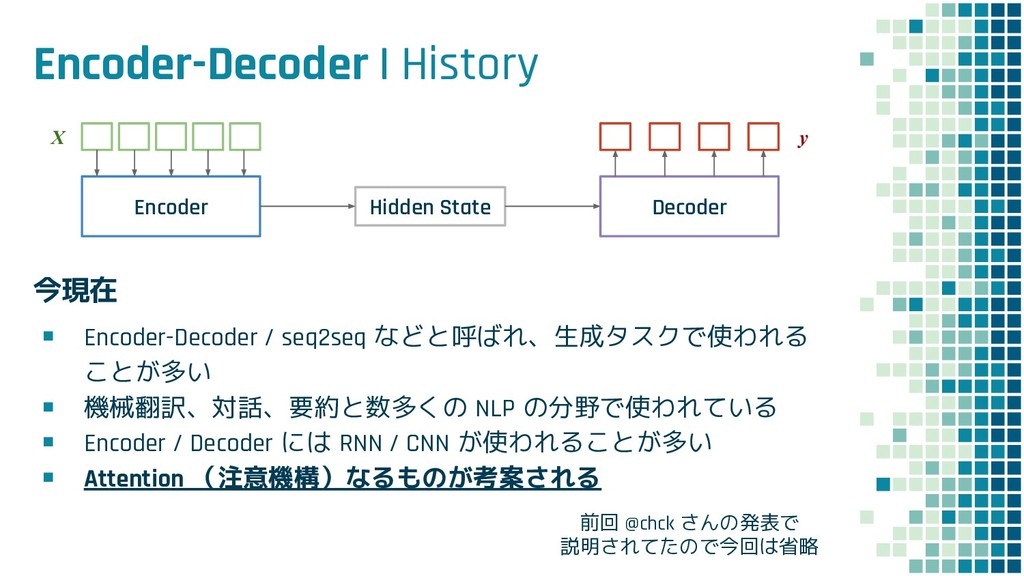
Abstractive Summarization, ICLR 2018 ➦ ▪ Richard Socher - Home Page ➦ ▪ Your TL;DR by an AI: A Deep Reinforced Model for Abstractive Summarization - Salesforce.com ➦ ▪ Erkan et al., Lexrank: Graph-based lexical centrality as salience in text summarization, JAIR 2004 ➦ ▪ Mihalcea et al., TextRank: Bringing Order into Texts, EMNLP 2004 ➦ ▪ ROUGEを訪ねて三千里:より良い要約の評価を求めて - Qiita ➦ ▪ Encoder-decoderモデルとTeacher Forcing,Scheduled Sampling,Professor Forcing ➦ ▪ Vinyals et al., Pointer Networks, NIPS 2015 ➦ ▪ Gu et al., Incorporating Copying Mechanism in Sequence-to-Sequence Learning, ACL 2016 ➦ ▪ See et al., Get To The Point: Summarization with Pointer-Generator Networks, ACL 2017 ➦ ▪ 言葉のもつ広がりを、モデルの学習に活かそう -one-hot to distribution in language modeling- - SlideShare ➦ ▪ 深層強化学習の最前線 - Speaker Deck ➦ ▪ Rennie et al., Self-Critical Sequence Training for Image Captioning, CVPR 2017 ➦ ▪ Self-Critical Sequence Training for Image Captioning - SlideShare ➦ ▪ 論文解説 Attention Is All You Need (Transformer) ➦
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Self-critical Sequence Training for Image Captioning [Rennie et al., 2017]](https://files.speakerdeck.com/presentations/af483f1586f34f73949eb9d833b526bb/slide_34.jpg){kind=link}
![Self-critical Sequence Training for Image Captioning [Rennie et al., 2017]](https://files.speakerdeck.com/presentations/af483f1586f34f73949eb9d833b526bb/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
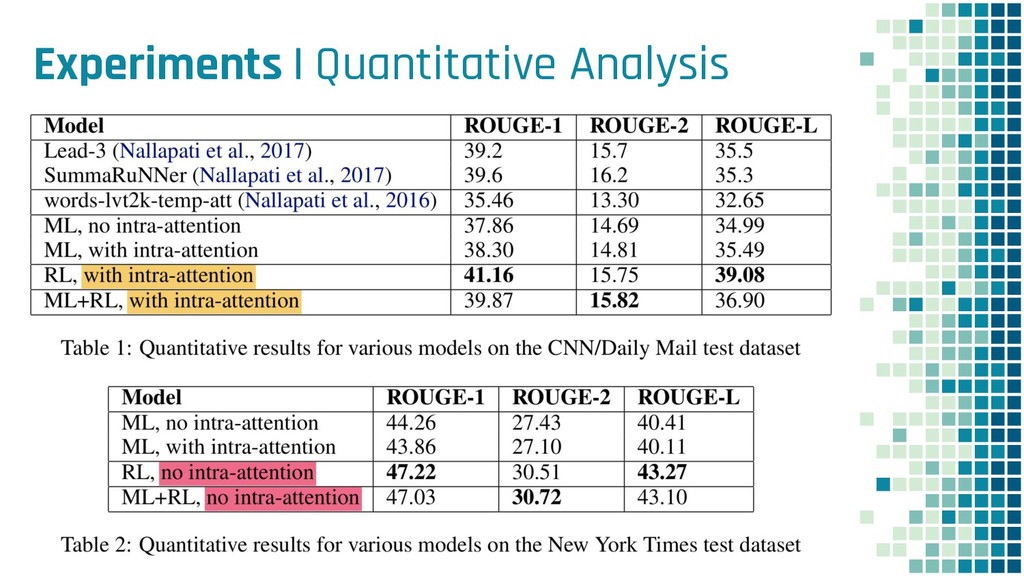{kind=link}
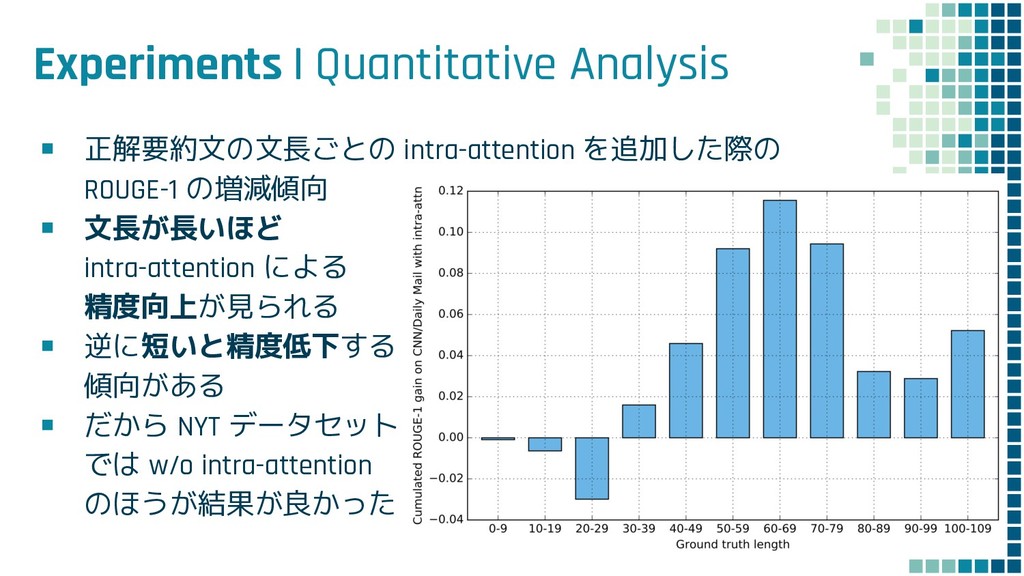{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
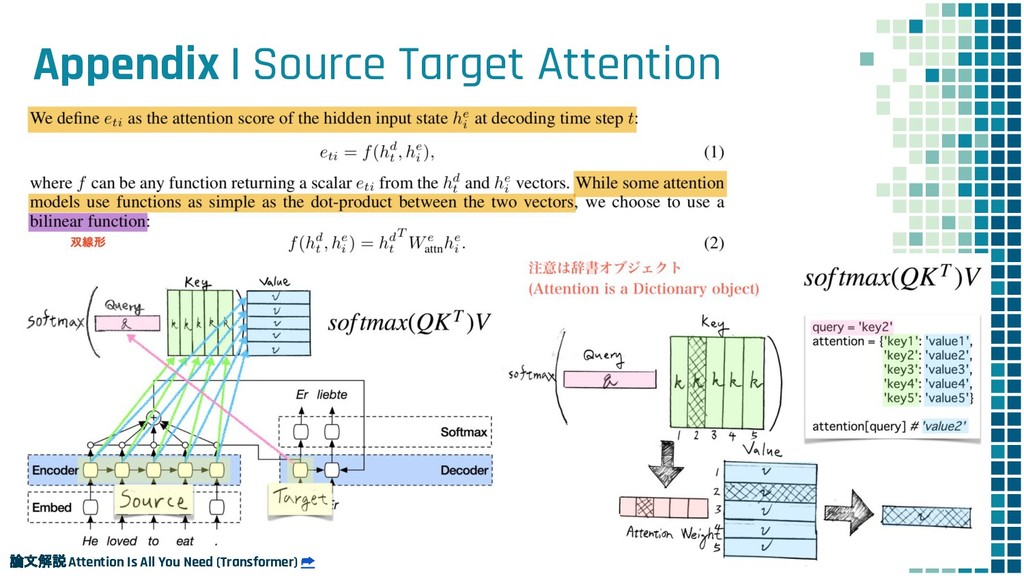{kind=link}
{kind=link}
{kind=link}