Presentation materials for the vLLM Roundup Community Meetup Tokyo. Demonstrates how PLaMo™ 2 has been officially supported by vLLM and showcases various acceleration features.
vLLM roundup Community Meetup Tokyoでの発表資料です。モデルベンダーとしてvLLMで正式にPLaMo 2をサポートし、様々な高速化機能を利用する方法を紹介します。
{kind=link}
{kind=link}
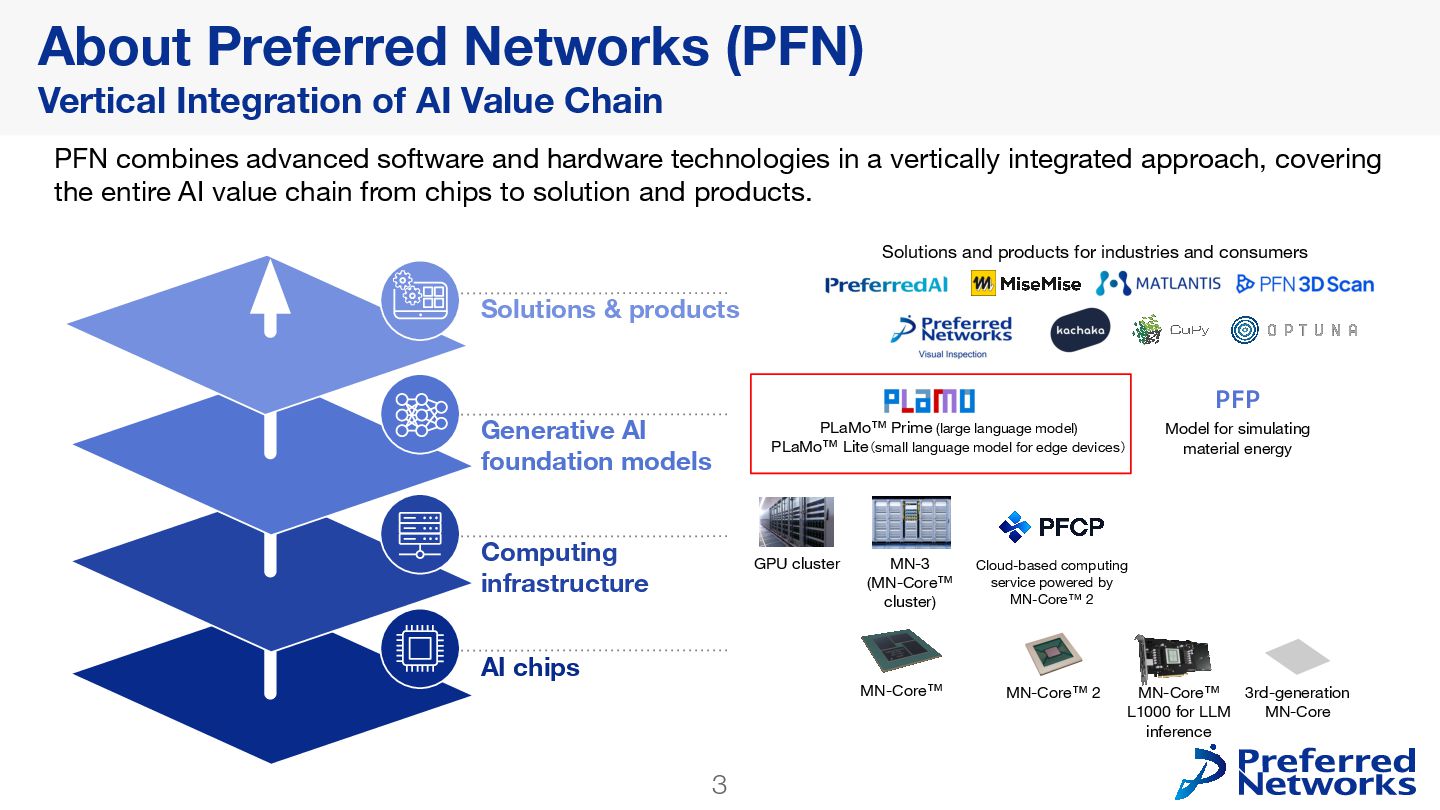{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
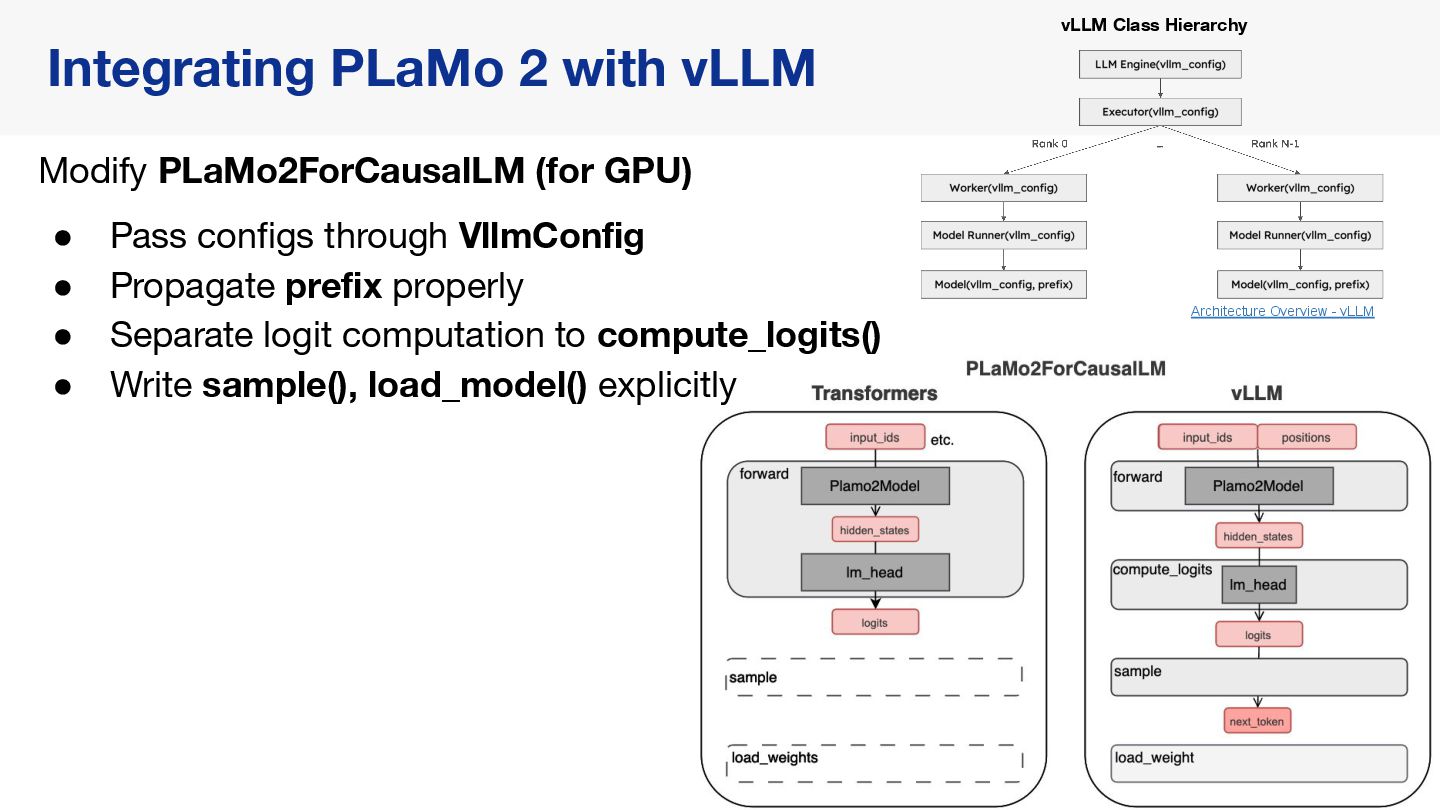{kind=link}
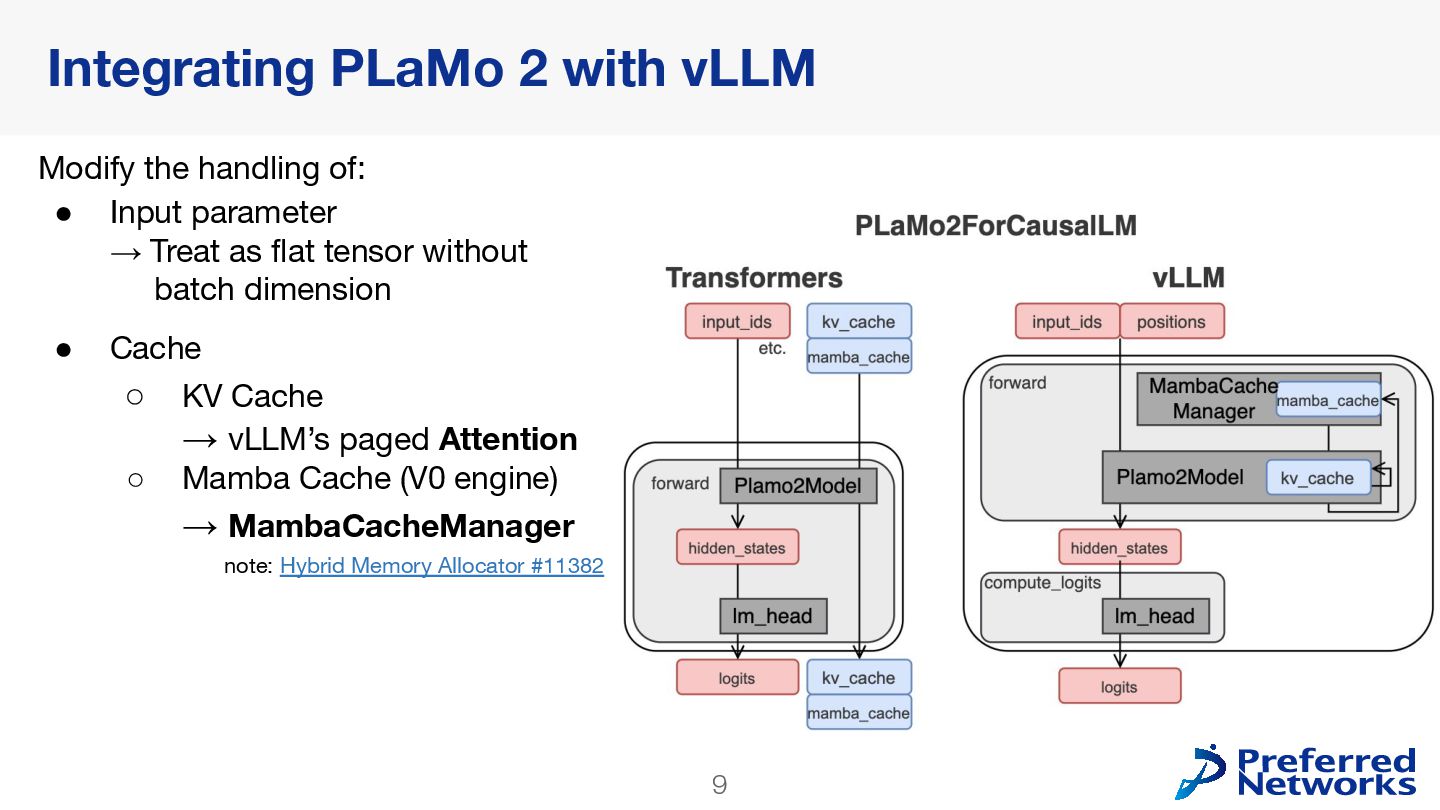{kind=link}
{kind=link}
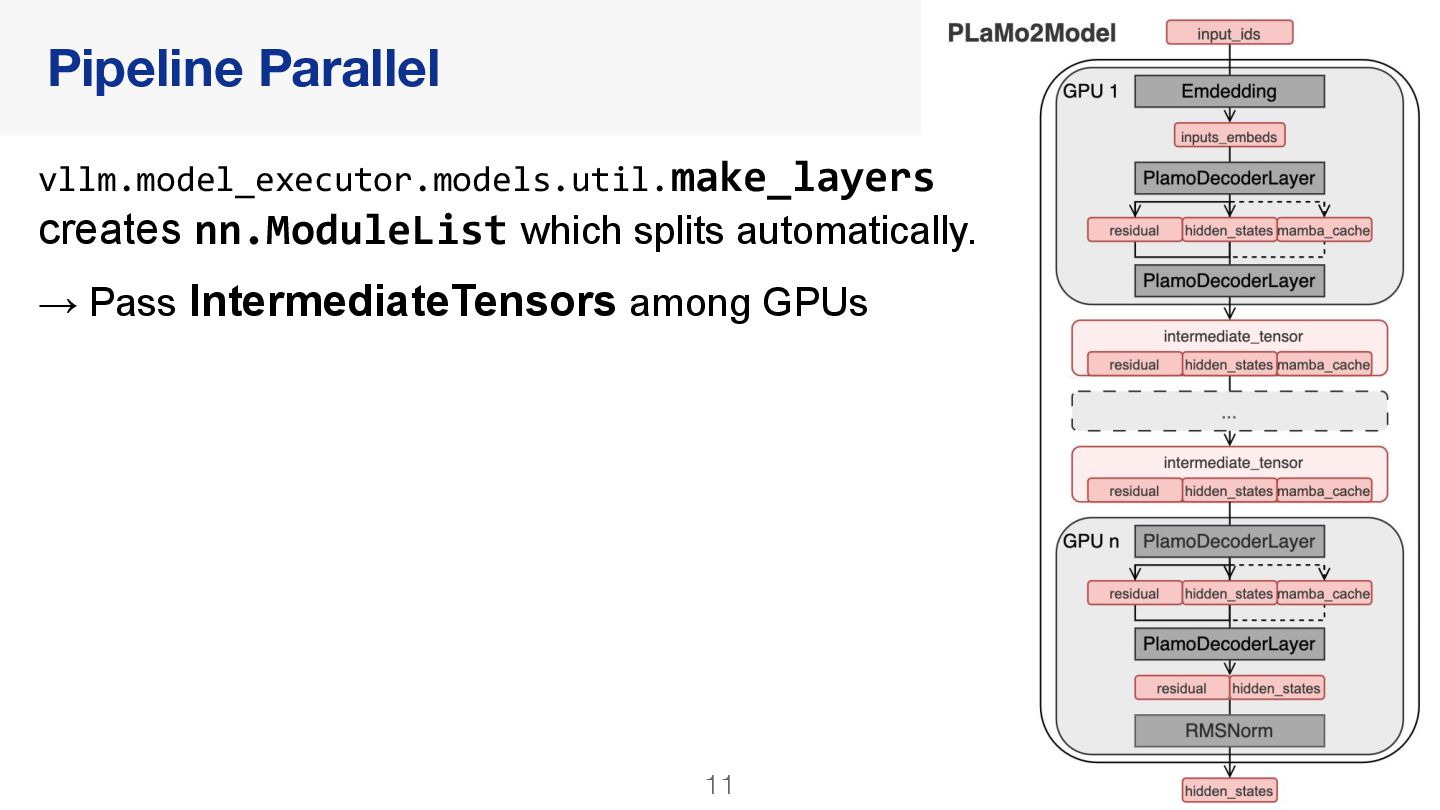{kind=link}
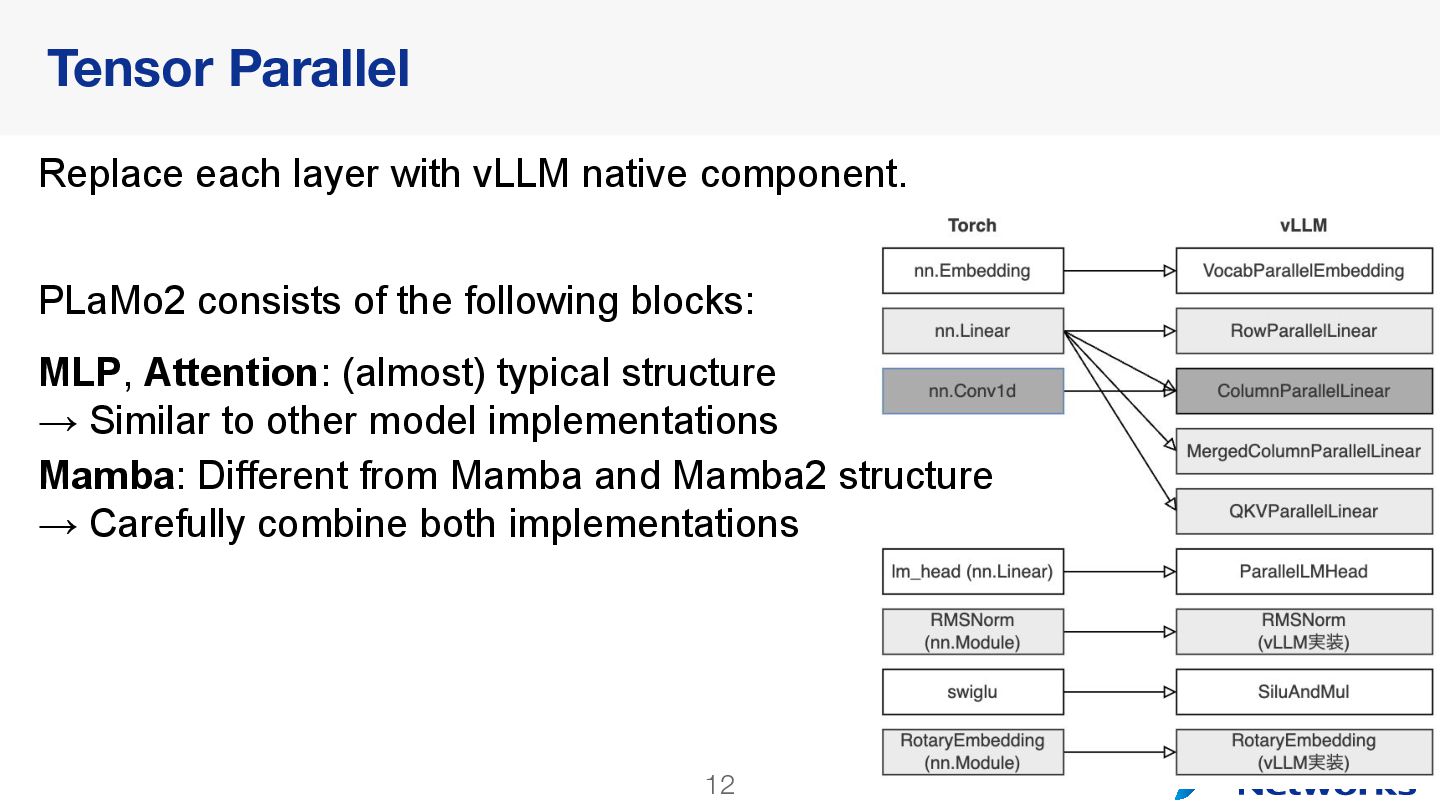{kind=link}
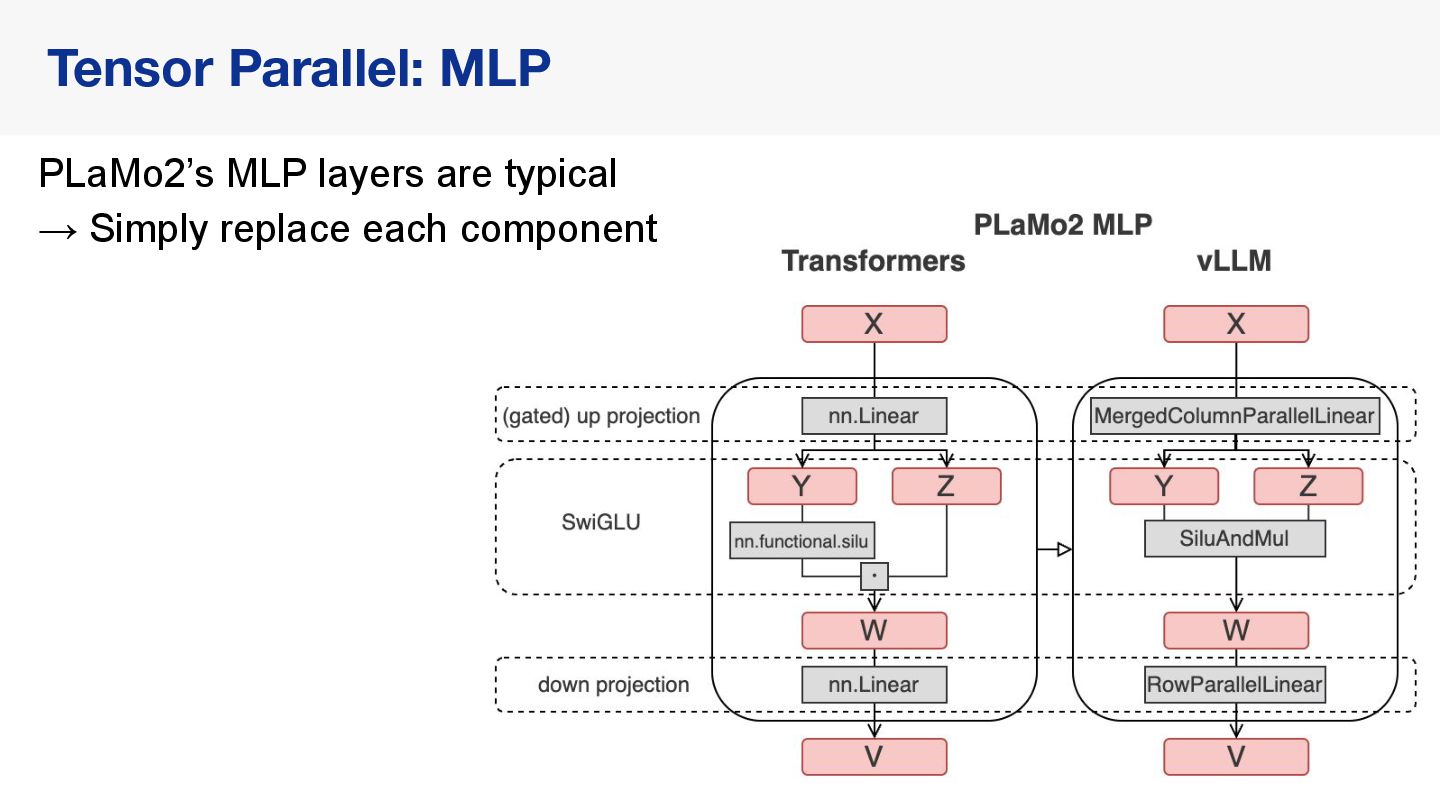{kind=link}
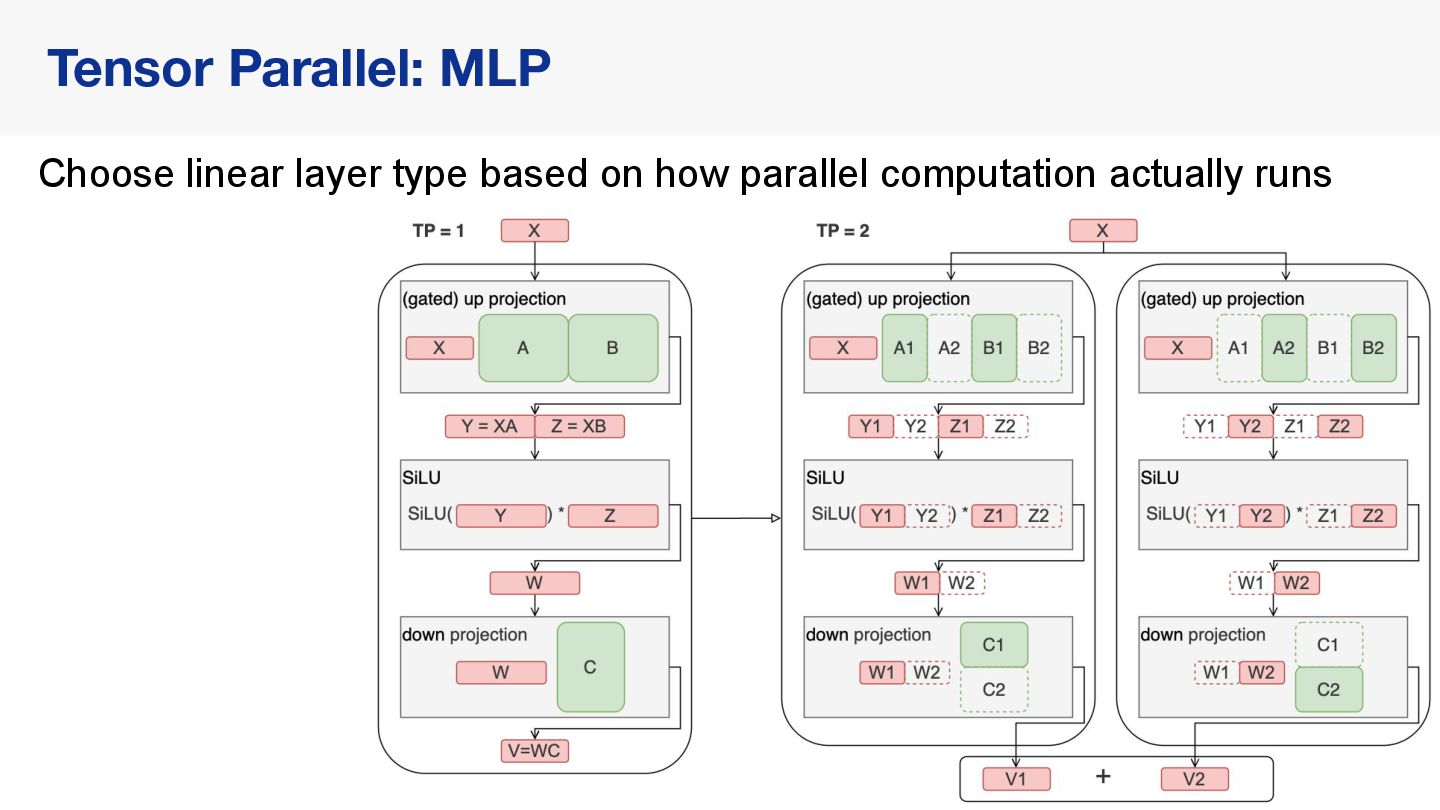{kind=link}
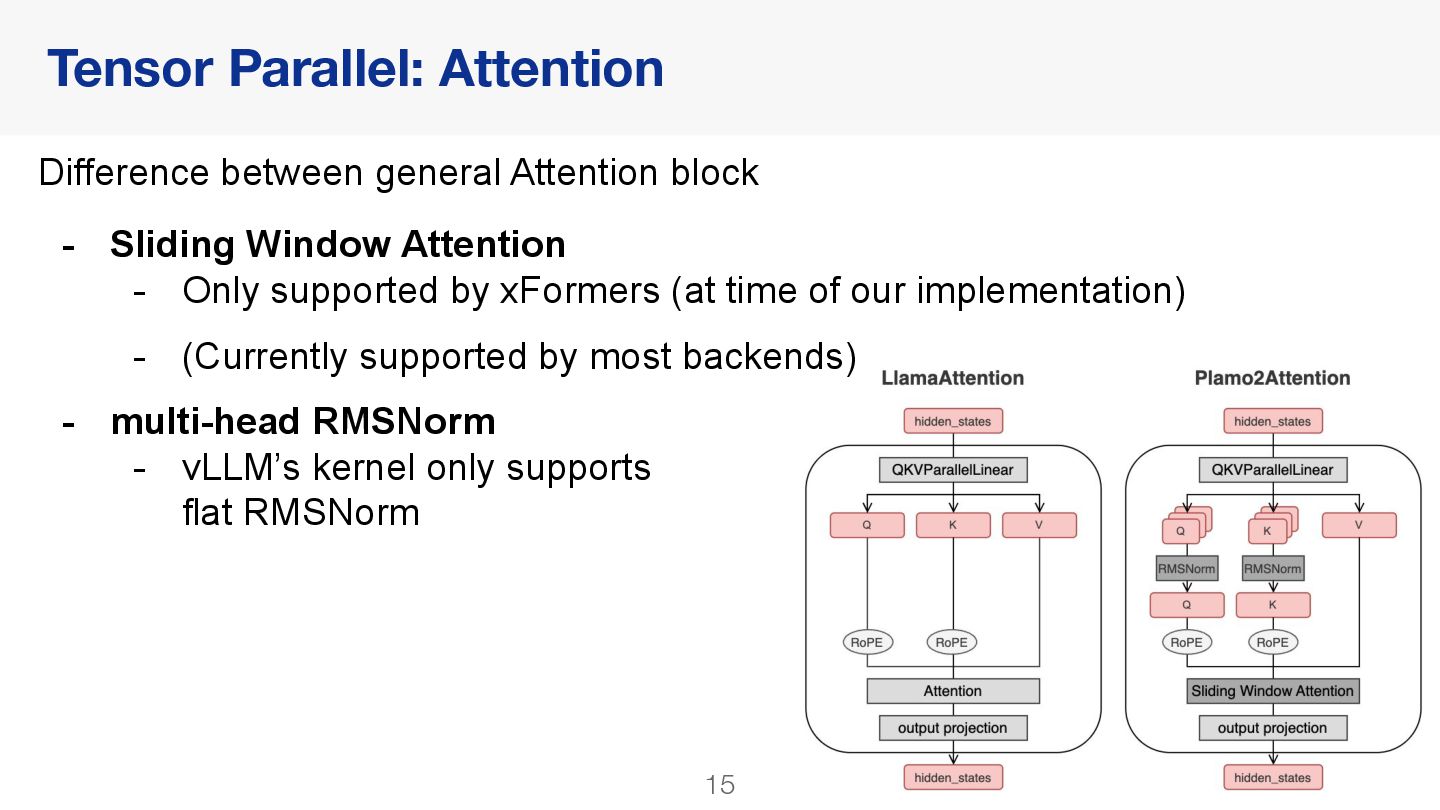{kind=link}
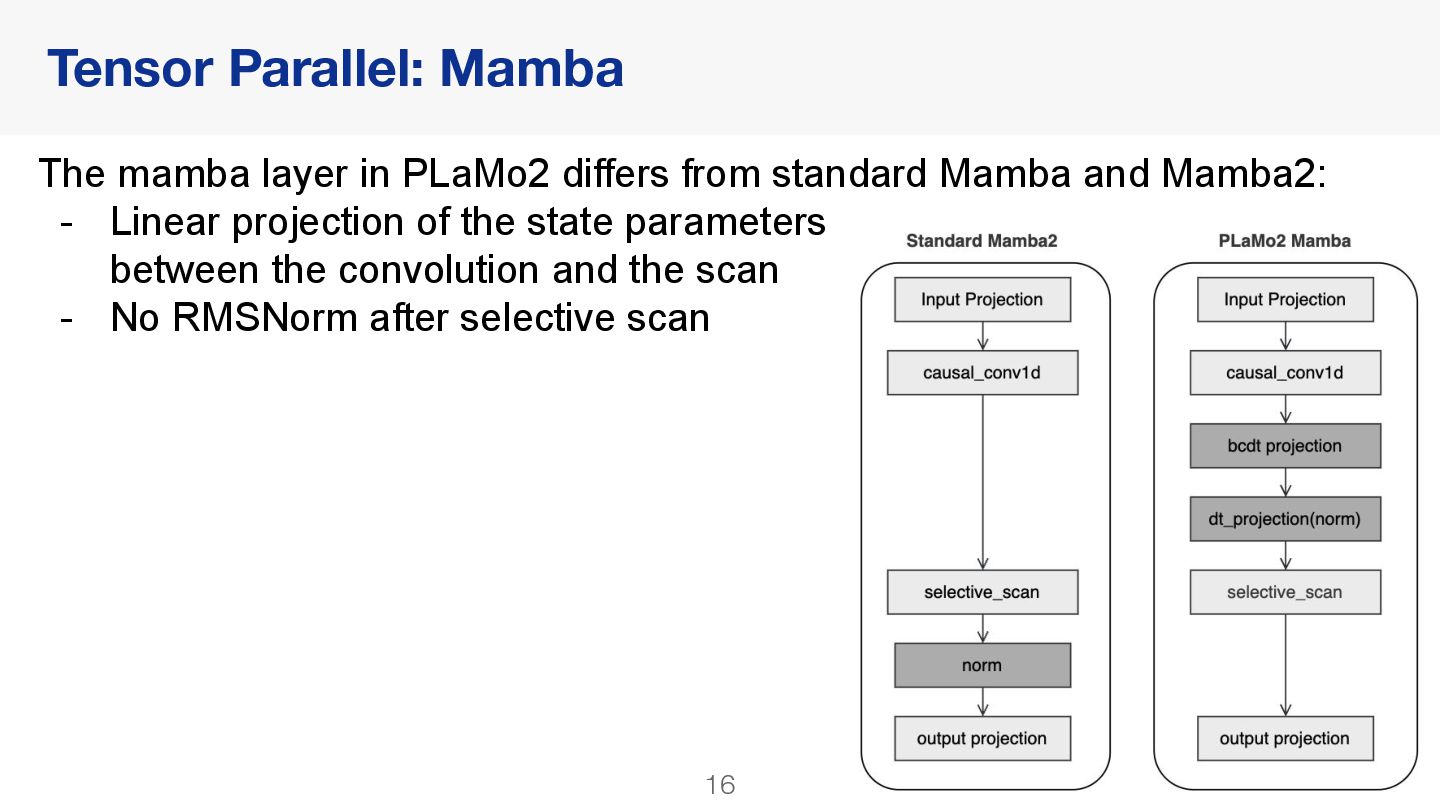{kind=link}
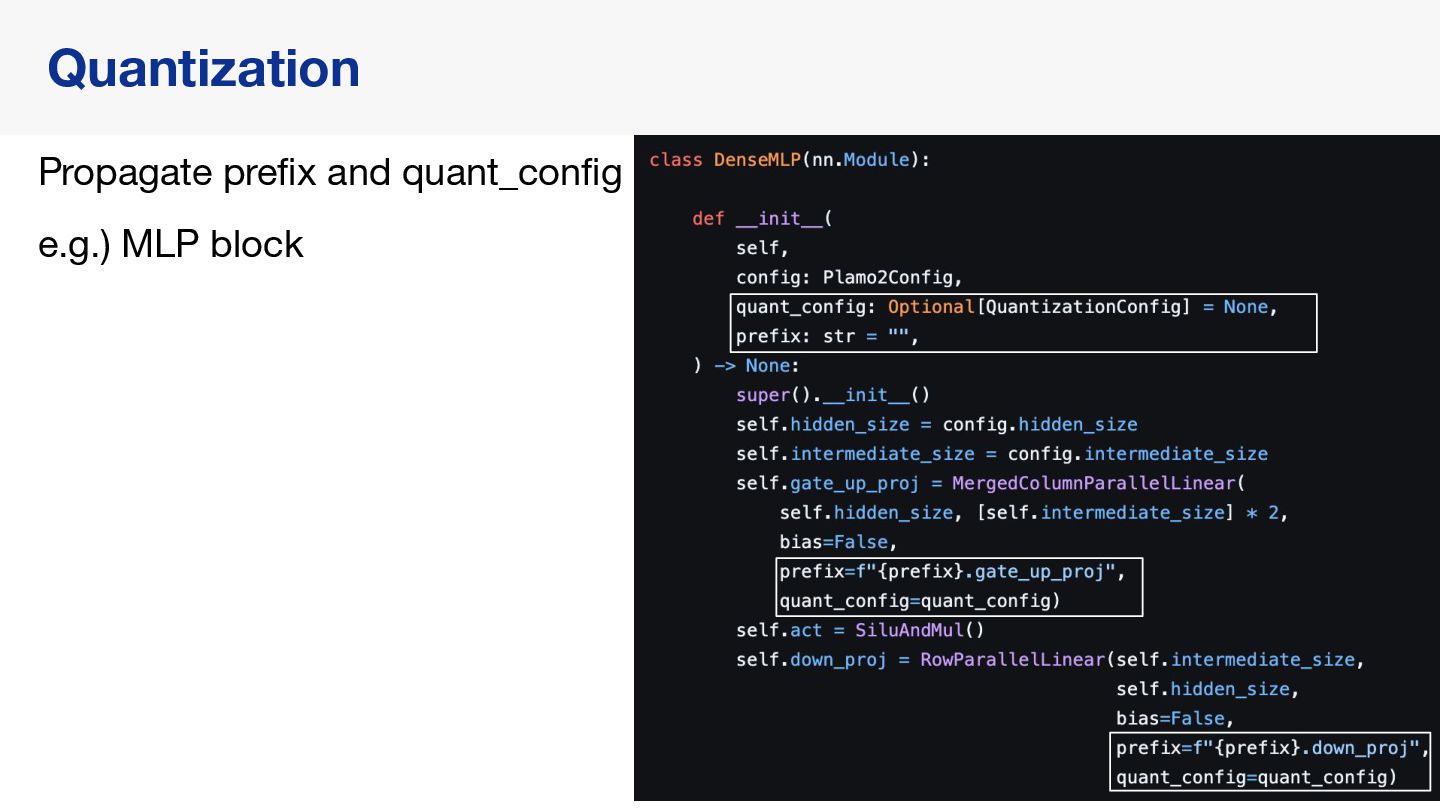{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
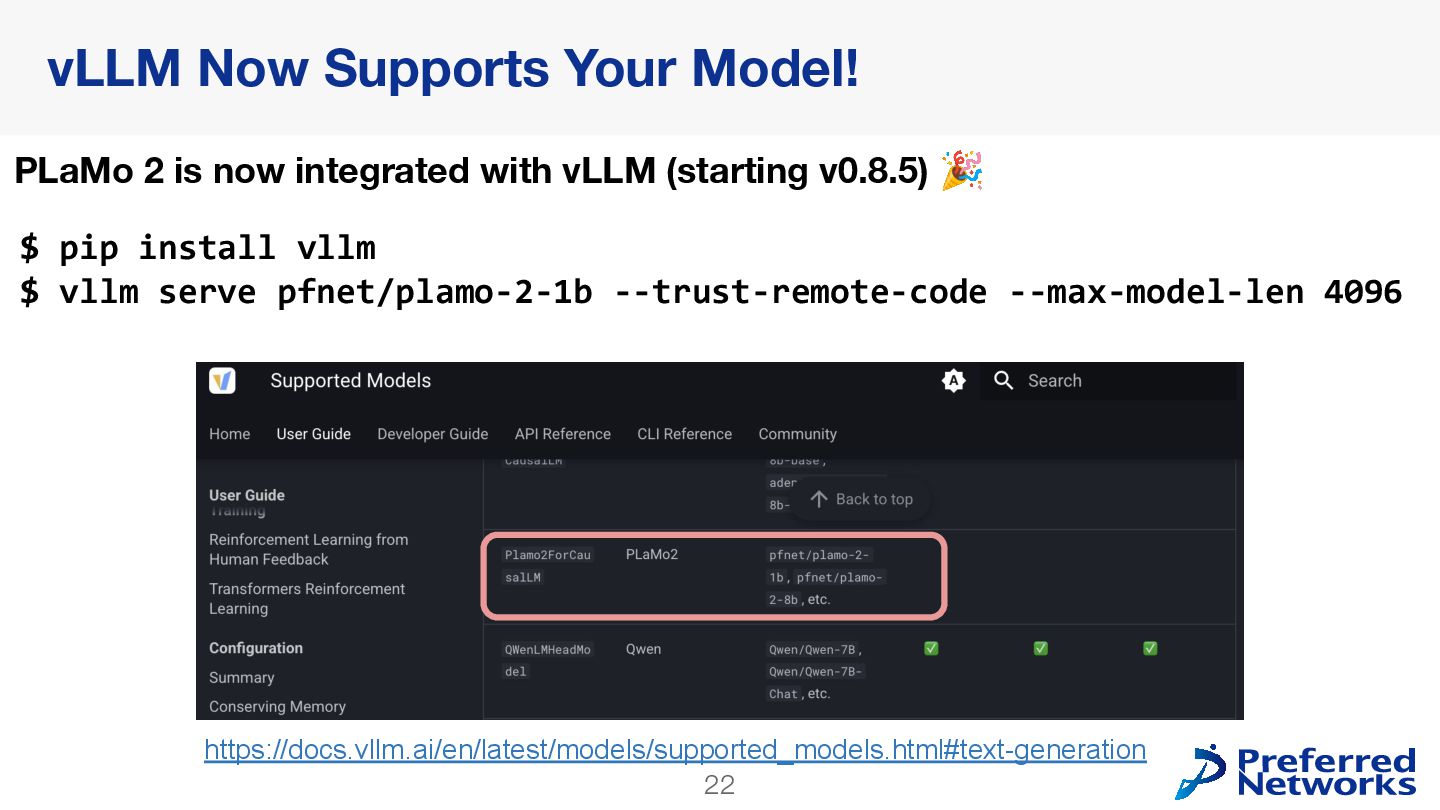{kind=link}
{kind=link}
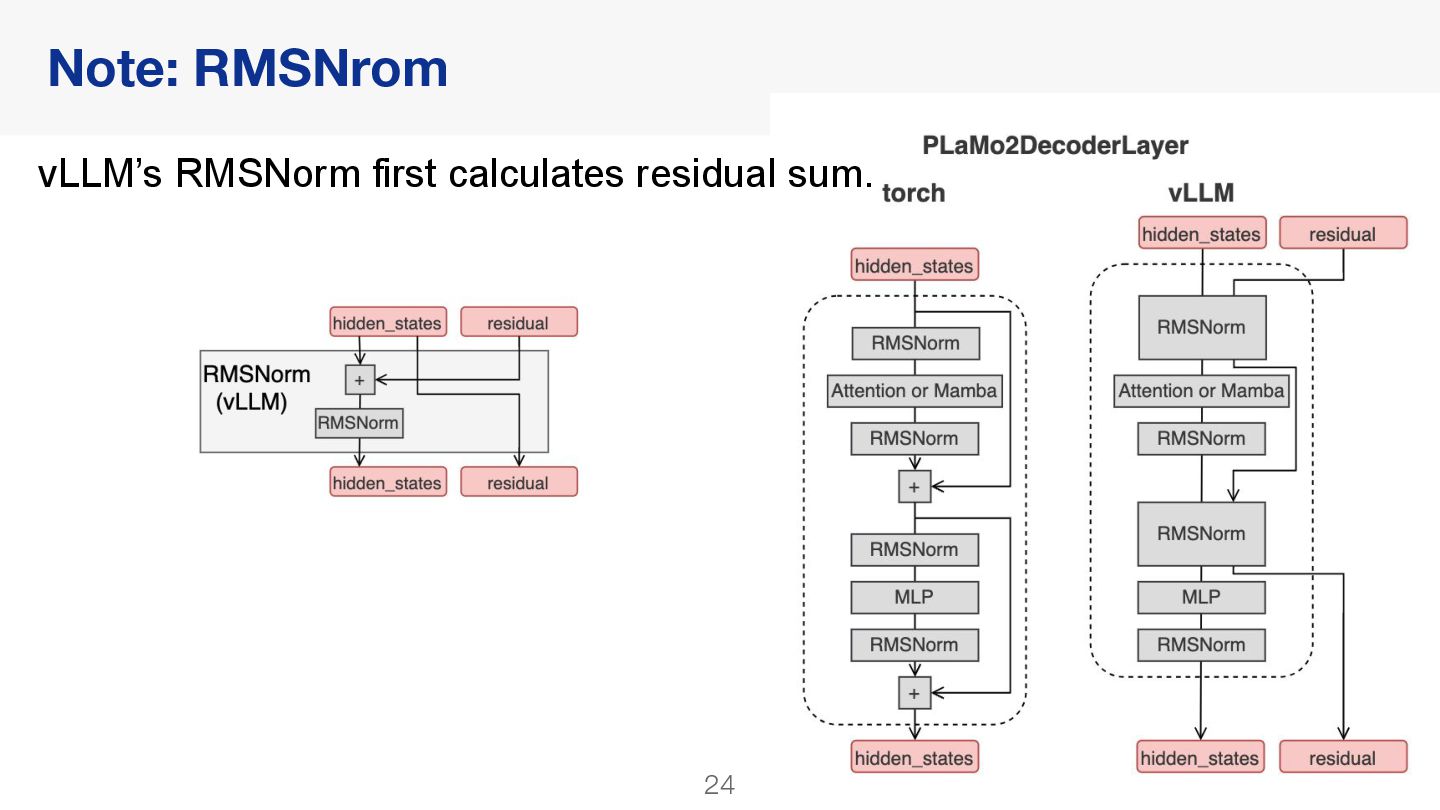{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}