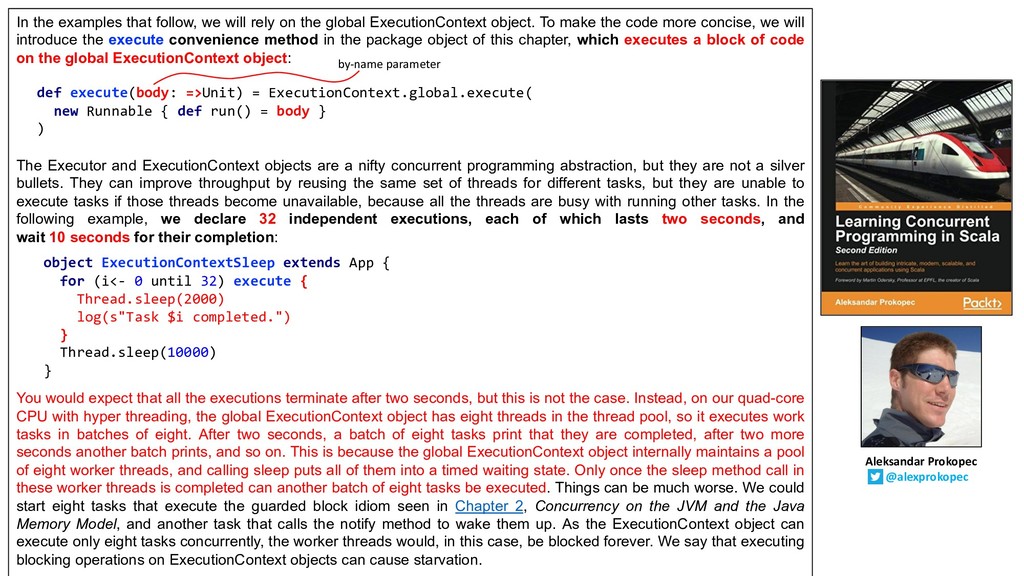
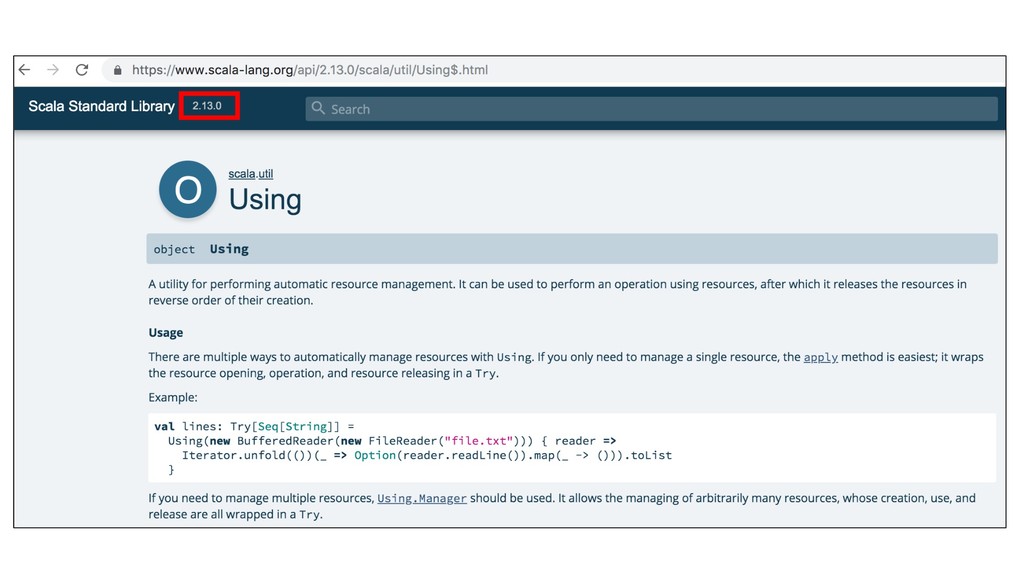
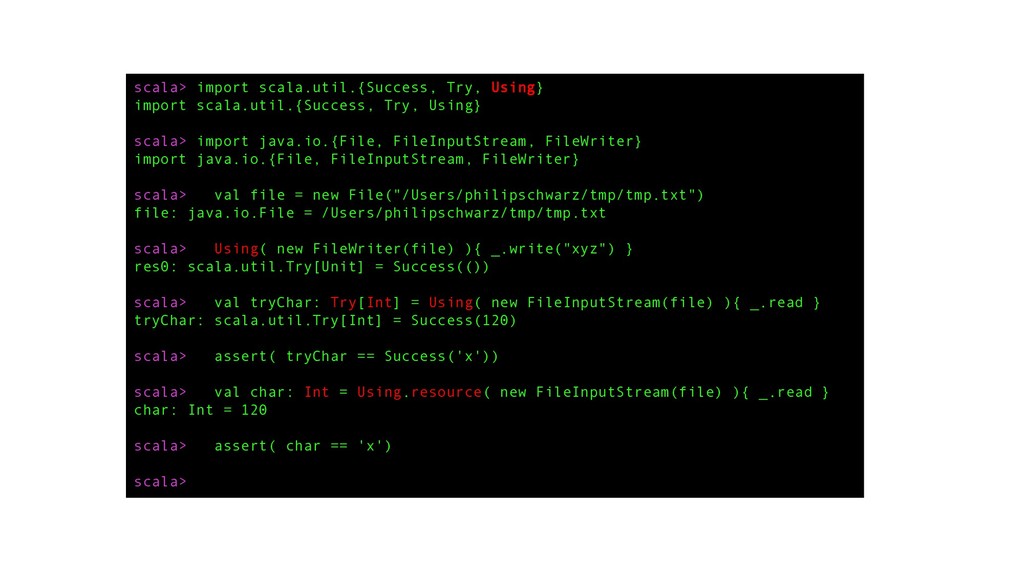
Download for perfect quality.
Non strict functions, bottom and scala by-name parameters - ‘a close look’, through the work of Runar Bjarnason, Paul Chiusano, Martin Odersky, Bill Venners, Lex Spoon, Alvin Alexander, Mark Lewis and Aleksandar Prokopec.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
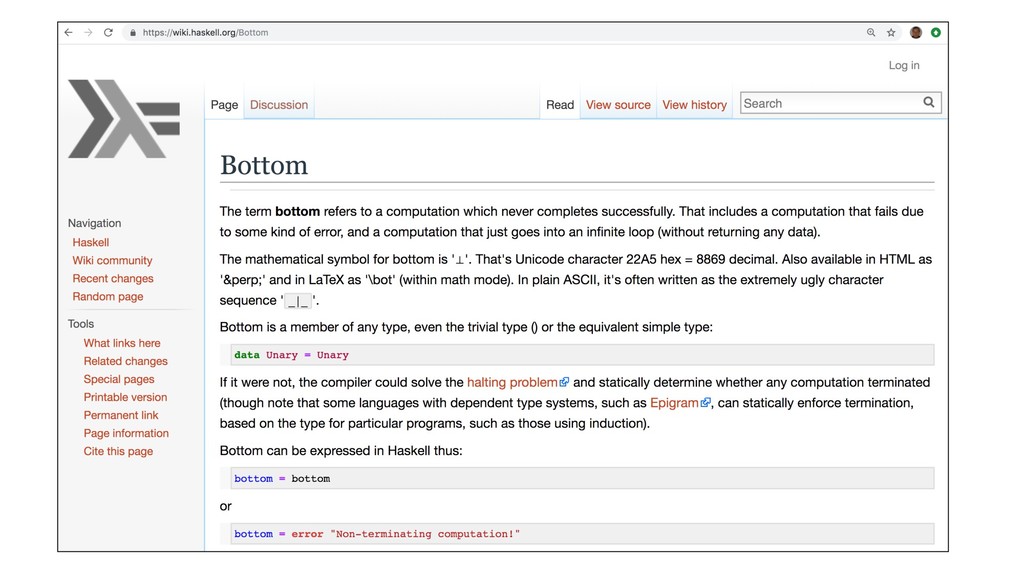{kind=link}
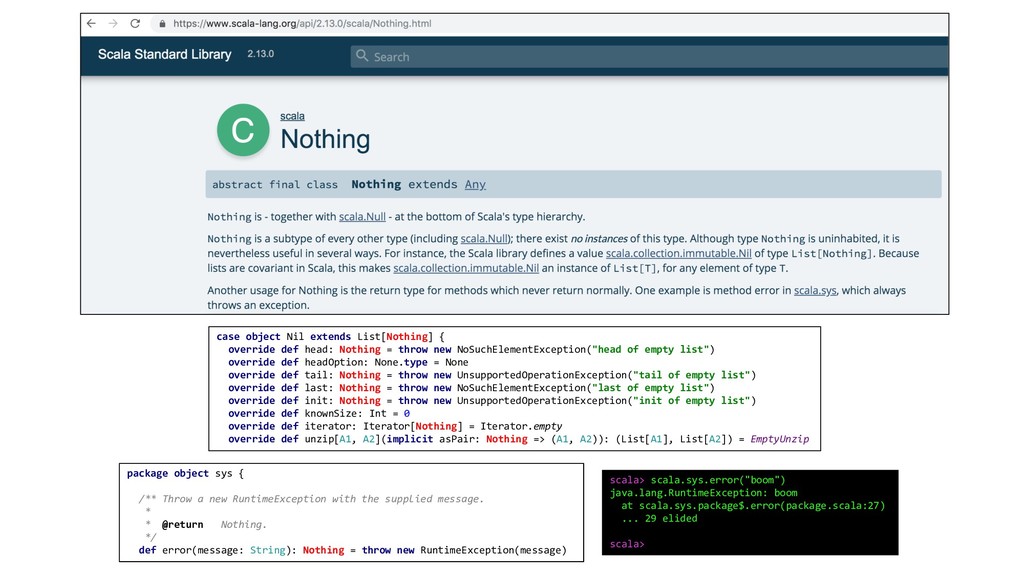{kind=link}
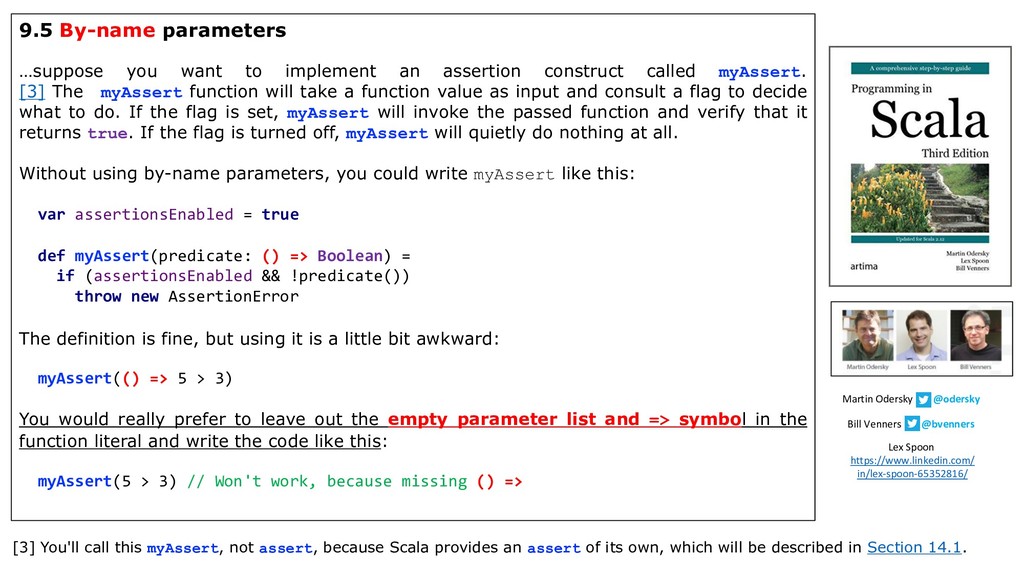{kind=link}
{kind=link}
{kind=link}
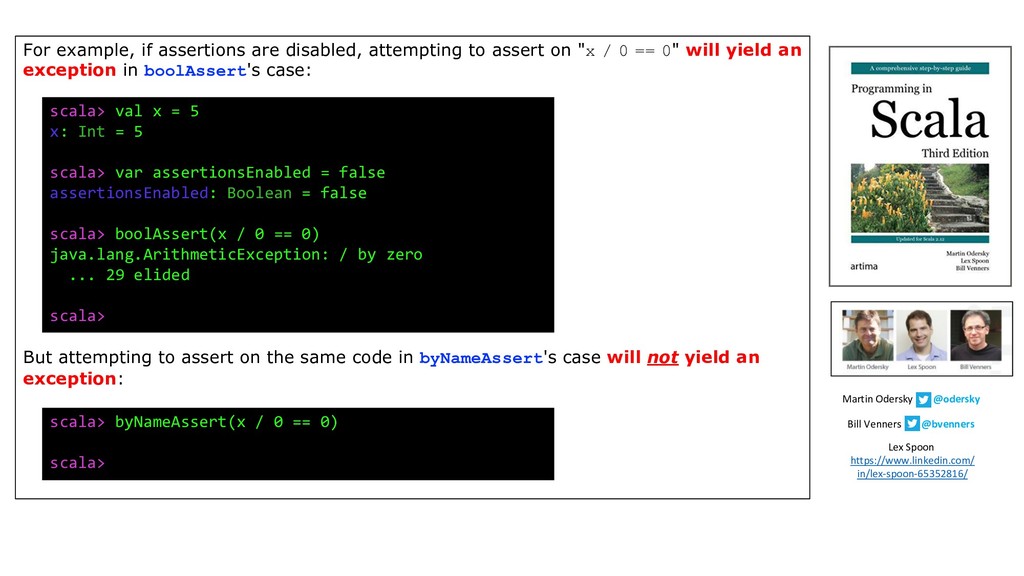{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}