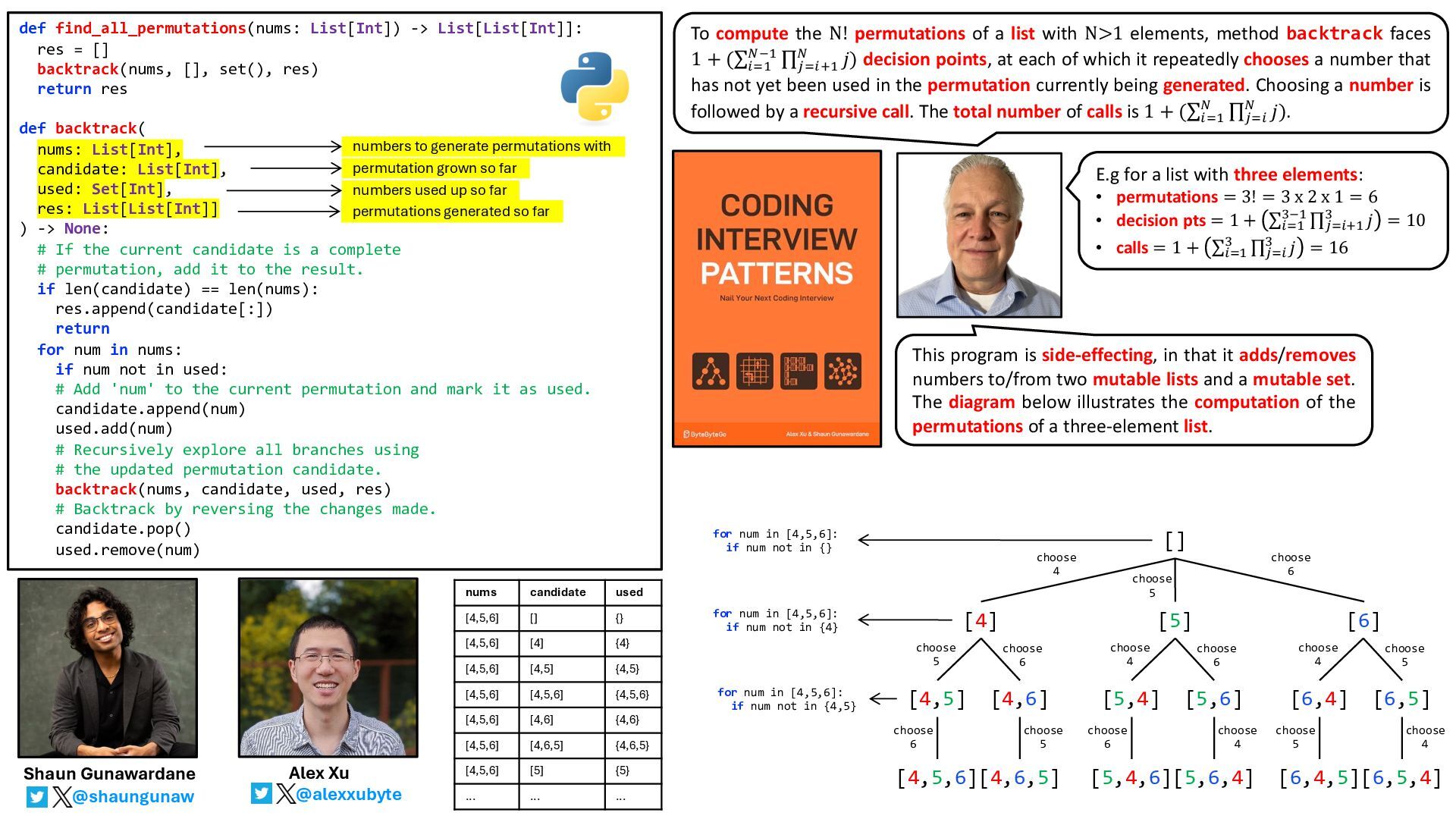
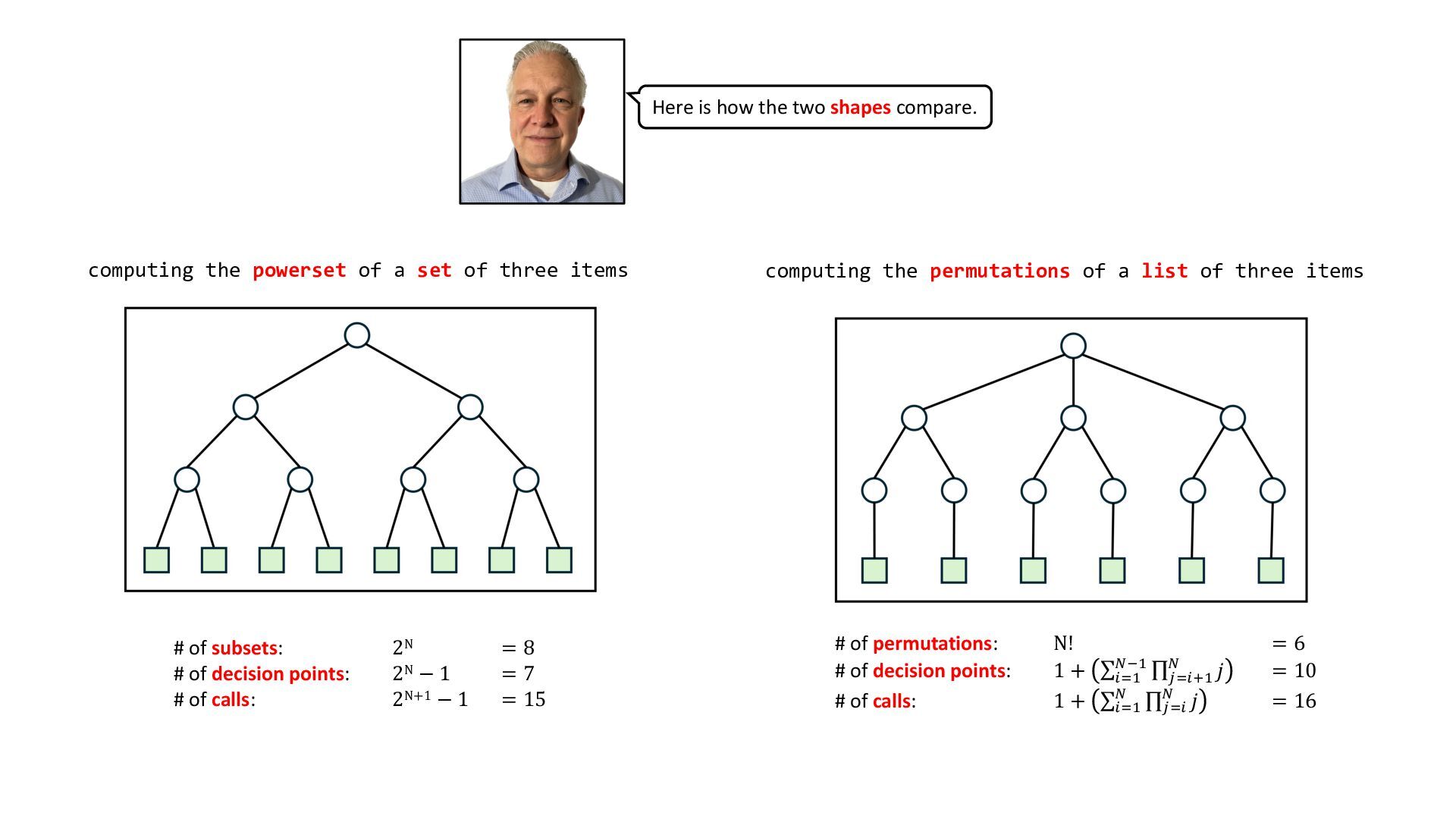
elements, method backtrack faces 1 + (∑ !"# $%# ∏ &"!'# $ 𝑗) decision points, at each of which it repeatedly chooses a number that has not yet been used in the permutation currently being generated. Choosing a number is followed by a recursive call. The total number of calls is 1 + (∑!"# $ ∏&"! $ 𝑗). def find_all_permutations(nums: List[Int]) -> List[List[Int]]: res = [] backtrack(nums, [], set(), res) return res def backtrack( nums: List[Int], candidate: List[Int], used: Set[Int], res: List[List[Int]] ) -> None: # If the current candidate is a complete # permutation, add it to the result. if len(candidate) == len(nums): res.append(candidate[:]) return for num in nums: if num not in used: # Add 'num' to the current permutation and mark it as used. candidate.append(num) used.add(num) # Recursively explore all branches using # the updated permutation candidate. backtrack(nums, candidate, used, res) # Backtrack by reversing the changes made. candidate.pop() used.remove(num) @alexxubyte Alex Xu @shaungunaw Shaun Gunawardane numbers to generate permutations with permutation grown so far numbers used up so far permutations generated so far This program is side-effecting, in that it adds/removes numbers to/from two mutable lists and a mutable set. The diagram below illustrates the computation of the permutations of a three-element list. E.g for a list with three elements: • permutations = 3! = 3 x 2 x 1 = 6 • decision pts = 1 + ∑!"# (%# ∏&"!'# ( 𝑗 = 10 • calls = 1 + ∑!"# ( ∏&"! ( 𝑗 = 16 [] [4] [6] [4,5] [4,6] [4,5,6][4,6,5] choose 4 choose 6 choose 5 choose 6 choose 6 choose 5 [5] [5,4] [5,6] [5,4,6][5,6,4] choose 4 choose 6 choose 6 choose 4 [6,4] [6,5] [6,4,5][6,5,4] choose 4 choose 5 choose 5 choose 4 choose 5 nums candidate used [4,5,6] [] {} [4,5,6] [4] {4} [4,5,6] [4,5] {4,5} [4,5,6] [4,5,6] {4,5,6} [4,5,6] [4,6] {4,6} [4,5,6] [4,6,5] {4,6,5} [4,5,6] [5] {5} … … … for num in [4,5,6]: if num not in {} for num in [4,5,6]: if num not in {4} for num in [4,5,6]: if num not in {4,5}
{kind=link}
{kind=link}
![def find_all_subsets(nums: List[Int]) -> List[List[Int]]: res = [] backtrack(0, [],](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_2.jpg){kind=link}
![def find_all_subsets(nums: List[Int]): List[List[Int]] = val res = List.empty[List[Int]] backtrack(0,](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_3.jpg){kind=link}
: List[List[A]] = as match case Nil =>](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_4.jpg){kind=link}
: List[List[A]] = as match case Nil =>](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_5.jpg){kind=link}
{kind=link}
![def find_all_subsets(nums: List[Int]) -> List[List[Int]]: res = [] backtrack(0, [],](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
![def find_all_permutations(nums: List[Int]) -> List[List[Int]]: res = [] backtrack(nums, [],](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
![def find_all_permutations(nums: List[Int]): List[List[Int]] = val res = List.empty[List[Int]] backtrack(nums,](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![perms :: [a] -> [[a]] perms [] = [[]] perms](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_23.jpg){kind=link}
{kind=link}
![perms :: [a] -> [[a]] perms [] = [[]] perms](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_25.jpg){kind=link}
: List[List[A]] = as match case Nil =>](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_26.jpg){kind=link}
![def find_all_permutations(nums: List[Int]): List[List[Int]] = val res = List.empty[List[Int]] backtrack(nums,](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_27.jpg){kind=link}
![perms :: Eq a => [a] -> [[a]] perms []](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_28.jpg){kind=link}
{kind=link}
: List[List[A]] = if as.isEmpty then List(Nil) else](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![-- powerset of [x1,x2,…,xm ] powersetm = do let [x1,x2,…,xm](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_34.jpg){kind=link}
{kind=link}
![-- powerset of [x1,x2,…,xm ] powersetm = do let [x1,x2,…,xm]=[1,2,…,m]](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_36.jpg){kind=link}
![-- powerset of [x1,x2,…,xm ] powersetm = do let [x1,x2,…,xm](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_37.jpg){kind=link}
![-- powerset of [x1,x2,…,xm ] powersetm = do let [x1,x2,…,xm](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_38.jpg){kind=link}
![-- powerset of [x1,x2,…,xm ] powersetm = do let [x1,x2,…,xm](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_39.jpg){kind=link}
![-- powerset of [x1,x2,…,xm ] powersetm = do let [x1,x2,…,xm](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_40.jpg){kind=link}
![-- powerset of [x1,x2,…,xm ] powersetm = do let [x1,x2,…,xm](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_41.jpg){kind=link}
{kind=link}
: List[List[A]] = items.foldM((candidate = Nil, unused =](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_43.jpg){kind=link}
{kind=link}
![def find_all_permutations(nums: List[Int]) -> List[List[Int]]: res = [] backtrack(nums, [],](https://files.speakerdeck.com/presentations/74b3928d88b14bac8850d0feaa8fc3c1/slide_45.jpg){kind=link}
{kind=link}