Les réseaux de neurones: les comprendre et en créer avec TensorFlow et Keras
Après une présentation générale du monde du deep learning (concept, vocabulaire, fonctionnement), nous verrons les différentes étapes de la création d'un réseau de neurones avec Keras et TensorFlow. Cette conférence s'adresse à tous !
du système neuronal biologique. • Là où il y a quelques années, les meilleurs modèles peinaient à atteindre les 60-70 % de précision, ils atteignent aujourd’hui les 97 % de précision. • Branche de l’IA et plus particulièrement du deep learning. • Ensemble d’algorithme complexe organisé sous forme de couches et de neurones.
de layers eux-mêmes composés de tensors (neurones). • Il existe différents types de layer : – Covolutional Layer : c’est ces layers qui vont faire la plupart des calculs. – Fully-connected : seul layer qui a accès à tous les autres, c’est celui qu’on interroge. – Etc (plus de détails) • Les tensors sont représentés par des numpy arrays (tableau multidimentionnel).
texte… • Peut répondre aux problématiques de : – Reconnaissance – Classification – Suggestion – Calcul complexe – Analyse Predictions of a deep convolutional networks using a Region Proposal Network (RPN) and an Object Detection Network
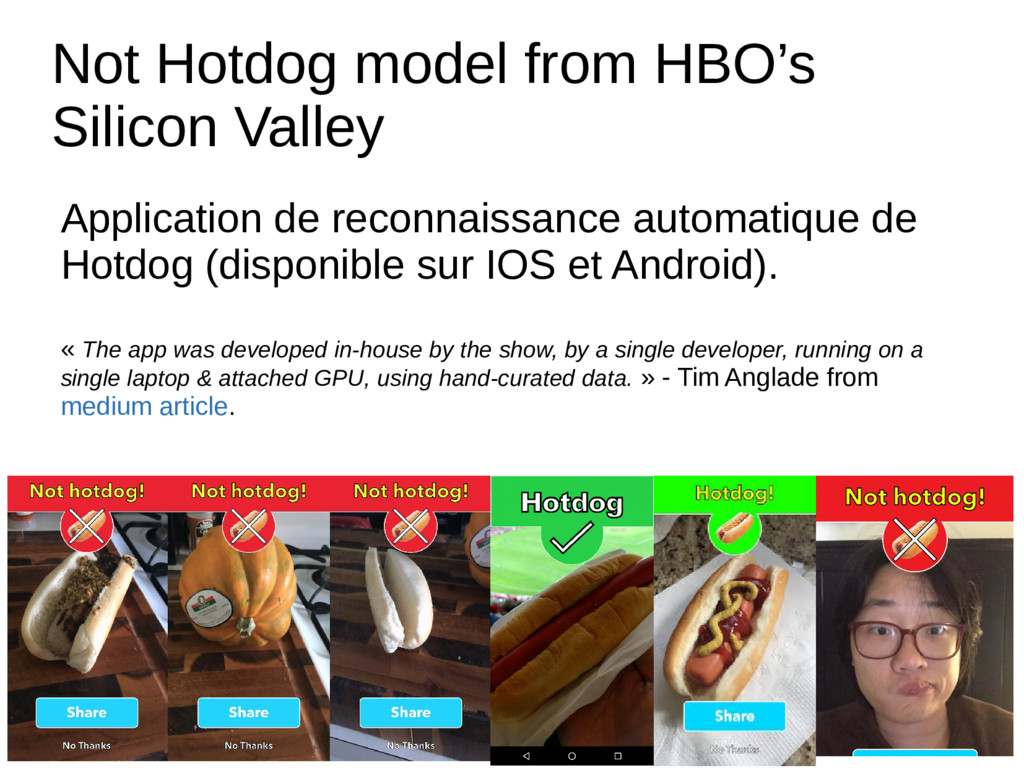
automatique de Hotdog (disponible sur IOS et Android). « The app was developed in-house by the show, by a single developer, running on a single laptop & attached GPU, using hand-curated data. » - Tim Anglade from medium article.
library for numerical computation using data flow graphs. » • Performant, complet et en évolution constante. • En python ou en C++. • Compatible tout OS. • Calcul GPU et/ou CPU. • Documentation claire et communauté importante. • Version de production avec TensorFlow Serve. • Simplicité d’utilisation.
Communauté et documentation. • De nombreux modèles directement disponibles. • Simplifie encore plus le processus de création du réseau. • Compatible avec les concurrents de TensorFlow. « Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It was developed with a focus on enabling fast experimentation. »
jeu de données (dataset) • Définition/rechargement du modèle • Paramétrage : – Taille du batch – Nombre d’epoch – Pourcentage de données de validation • L’apprentissage et la validation • Le test et la prédiction • La mise en production Tips : image-net et kaggle
modèle existant (Inception, VGG, ResNet...) • Privilégier le fine-tuning quand un modèle correspond déjà à votre besoin : – Gain de temps énorme par rapport au résultat. – Le modèle final donnera généralement de meilleur résultat. – Complexité moins élevé puisque l’architecture a déjà été pensée. • Privilégier la création pour un besoin nouveau, pour apprendre ou encore pour essayer de mettre en place une architecture nouvelle.
« accuracy » et « loss » • Le test sur des données étrangères au modèle • Problèmes fréquents : – Overfitting : le modèle connaît trop bien le jeu de données d’entraînement ce qui impacte sa capacité à généraliser – Underfitting : le modèle n’arrive pas à généraliser – Dataset de mauvaise qualité ou non représentatif • Balance entre précision et performance : – Performance : on essaie de diminuer le taux de faux négatif : plus de données seront retenues, mais le taux de faux positifs sera plus élevé. – Précision : on essaie de diminuer le taux de faux positifs : les données retenues seront plus fiables, mais moins nombreuses.
du dataset et de faire varier les données de validation/apprentissage. • Data augmentation : aide avec l’overfitting en générant des variantes modifiées de vos samples. • Early stopping : permet d’arrêter l’entraînement quand celui-ci ne s’améliore pas voire régresse. • Data segmentation : permet d’utiliser d’énormes dataset sans avoir besoin de tonnes de ram.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}