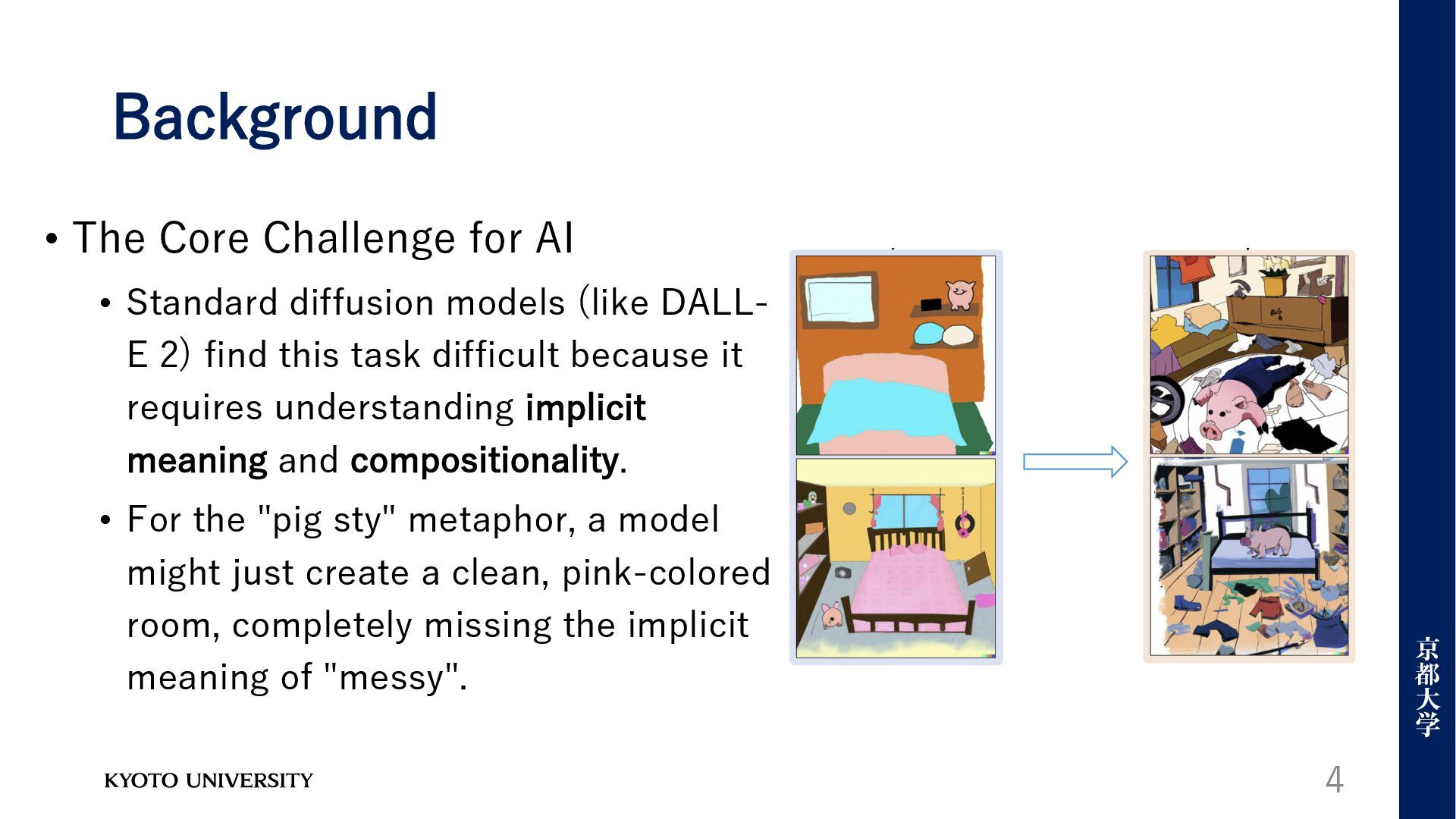
uses images to communicate creative or persuasive ideas. • The Research Task • To generate visual metaphors from linguistic metaphors. For example, turning the text "My bedroom is a pig sty" into a representative image 3
models (like DALL- E 2) find this task difficult because it requires understanding implicit meaning and compositionality. • For the "pig sty" metaphor, a model might just create a clean, pink-colored room, completely missing the implicit meaning of "messy". 4
perform poorly when processing figurative language, especially metaphors. • Failure to Grasp Implicit Meaning • Failure in Compositionality • Under-specification of Prompts 5
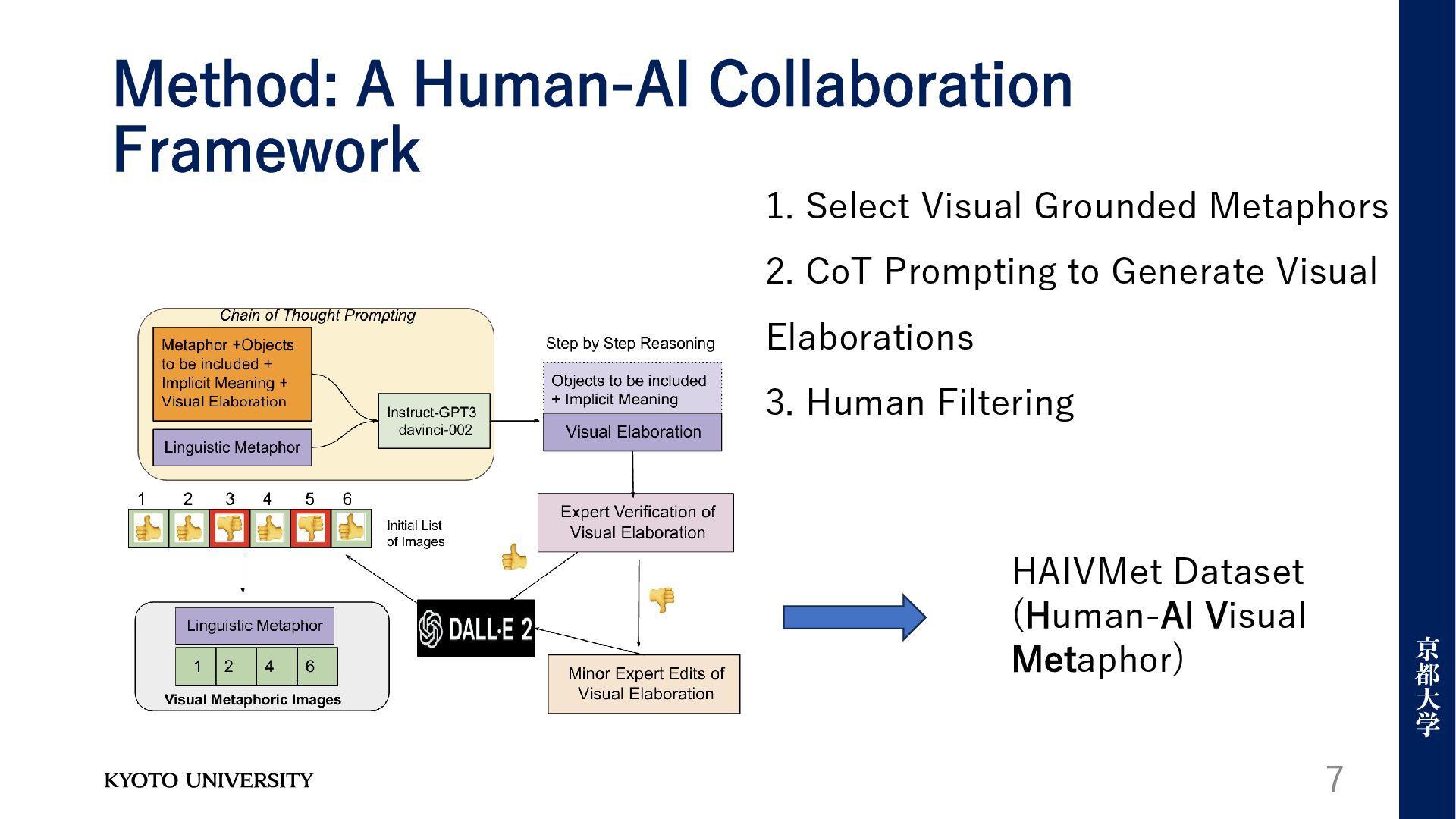
method where a Large Language Model (LLM) collaborates with a text-to-image diffusion model • High-Quality Dataset: HAIVMet • The creation of HAIVMet (Human-AI Visual Metaphor), a new, large- scale dataset. • Thorough Evaluation Framework • The paper presents a comprehensive evaluation of this new approach. 6
Grounded Metaphors • Visually Grounded Metaphors: Such as metaphors of concrete subjects or some abstract subjects like ‘confusion’ as a question mark or ‘idea’ as a lightbulb over someone’s head 8 ‘idea’ as a lightbulb
Few-Shot • Human experts then validate and, if necessary, perform minor edits on these elaborations (this occurred in 29% of cases). • Step 3: Image Generation and Human Filtering • The detailed "visual elaboration" from Step 2 is used as a prompt for a diffusion model (DALL-E 2) to generate images. 9 Method: A Human-AI Collaboration Framework
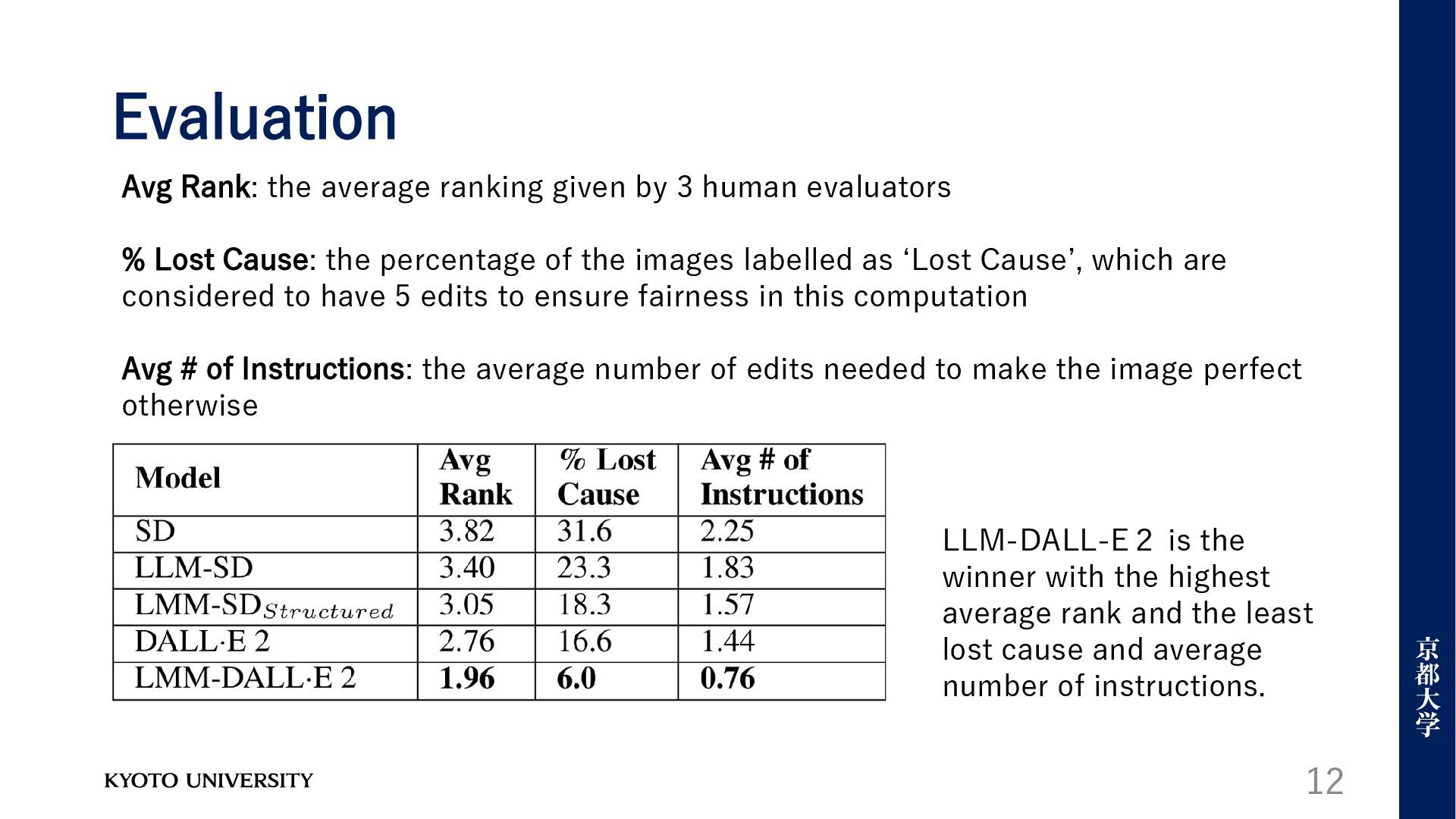
Model collaboration • Evaluation Setup: • Conducted by three professional illustrators and designers recruited via the Upwork platform. • The illustrators ranked the outputs from five different system setups (Among 100 random metaphors, ) • Rankings were based on the image representation of the metaphor. Raters also provided natural language instructions to improve imperfect images. 11
rank and the least lost cause and average number of instructions. Avg Rank: the average ranking given by 3 human evaluators % Lost Cause: the percentage of the images labelled as ‘Lost Cause’, which are considered to have 5 edits to ensure fairness in this computation Avg # of Instructions: the average number of edits needed to make the image perfect otherwise
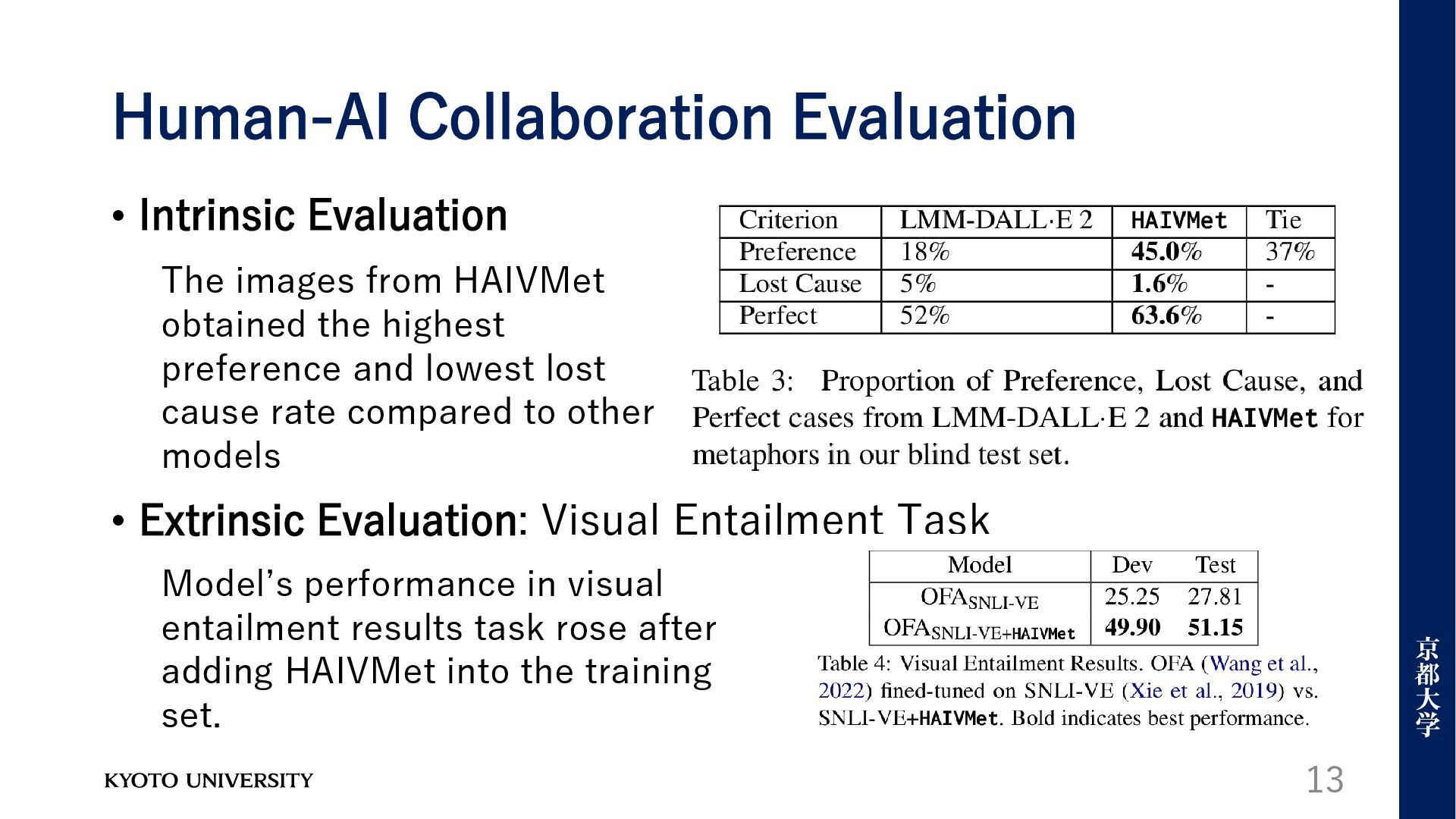
Entailment Task 13 The images from HAIVMet obtained the highest preference and lowest lost cause rate compared to other models Model’s performance in visual entailment results task rose after adding HAIVMet into the training set.
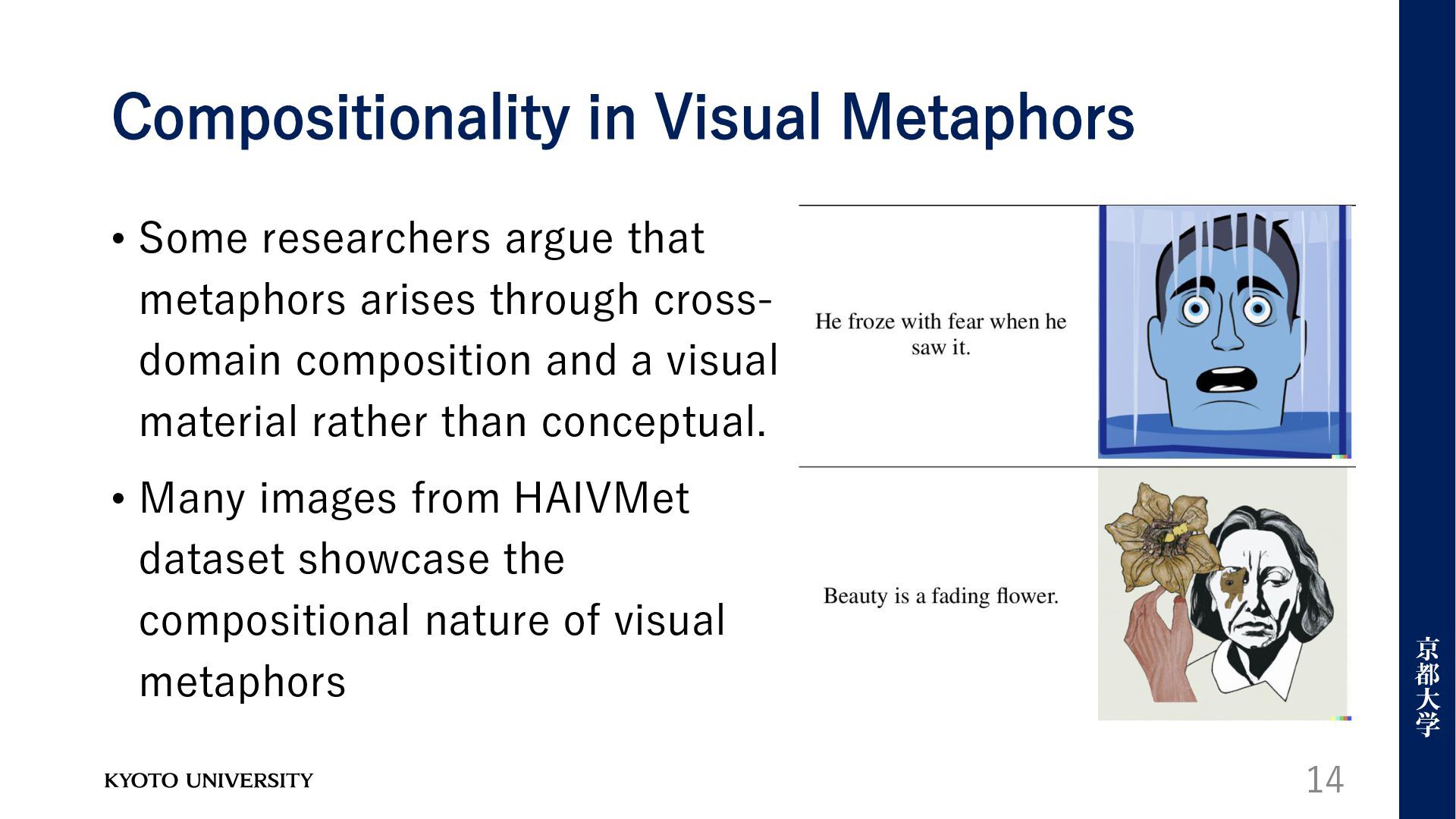
arises through cross- domain composition and a visual material rather than conceptual. • Many images from HAIVMet dataset showcase the compositional nature of visual metaphors 14
‘translator’, interpreting abstract metaphors into concrete instructions. • Diffusion Model(Depicting): An ‘artist’, generating high-quality images from the specific instructions • Human(Evaluating): Managing context and quality that AI alone cannot. 15
a LLM with CoT prompting to generate detailed "visual elaborations" significantly improves the quality of visual metaphors produced by diffusion models • The resulting HAIVMet dataset • Limitations: • The Human-AI collaboration process can be time-consuming. • The best-performing models used in the study are not open-source and are accessed via paid APIs. • The current work is limited to English-only metaphors. 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}