Shen Nie, Fengqi Zhu, Zebin You, Xiaohu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, Chongxuan Li. • Institution: Gaoling School of Artificial Intelligence, Renmin University of China ; Ant Group • Pub. Date: 2025.02 • Link: https://arxiv.org/abs/2502.09992 2
of large language models • It is generative principles instead of autoregressive formulation that fundamentally underpin the essential properties of Large Language Models. 3 𝑝𝑑𝑎𝑡𝑎 · : True language distribution 𝑝𝜃 · ∶ 𝑀𝑜𝑑𝑒𝑙 𝑑𝑖𝑠𝑡𝑟𝑖𝑏𝑢𝑡𝑖𝑜𝑛 𝑥 is a sequence of length 𝐿 𝑥𝑖 is the 𝑖-th token
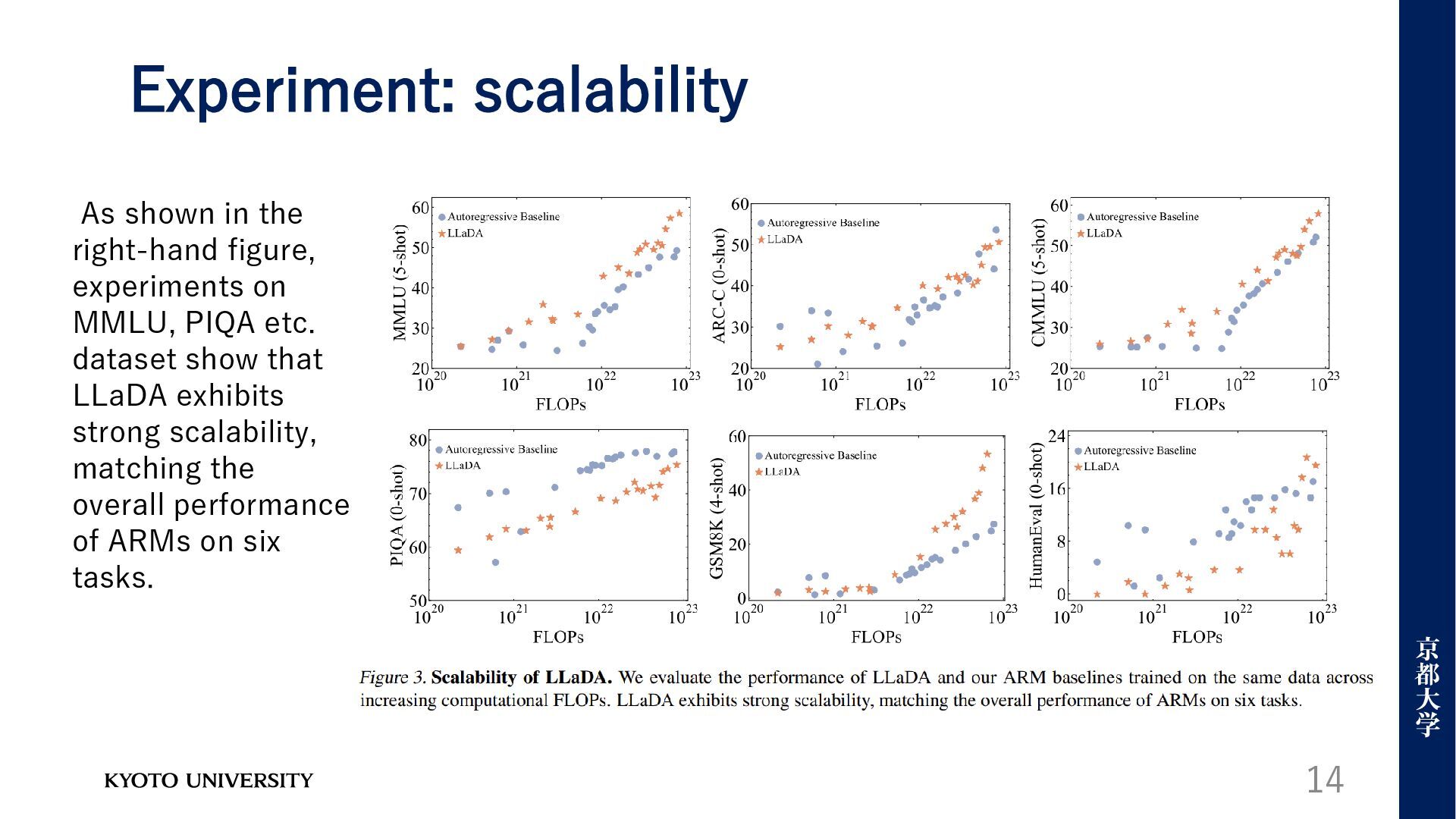
High computational costs • The left-to-right modeling limits effectiveness in reversal reasoning tasks 4 To investigate whether the capabilities exhibited by LLMs can emerge from generative modeling principles beyond ARMs, LLaDA, a Large Language Diffusion with mAsking, was introduced.
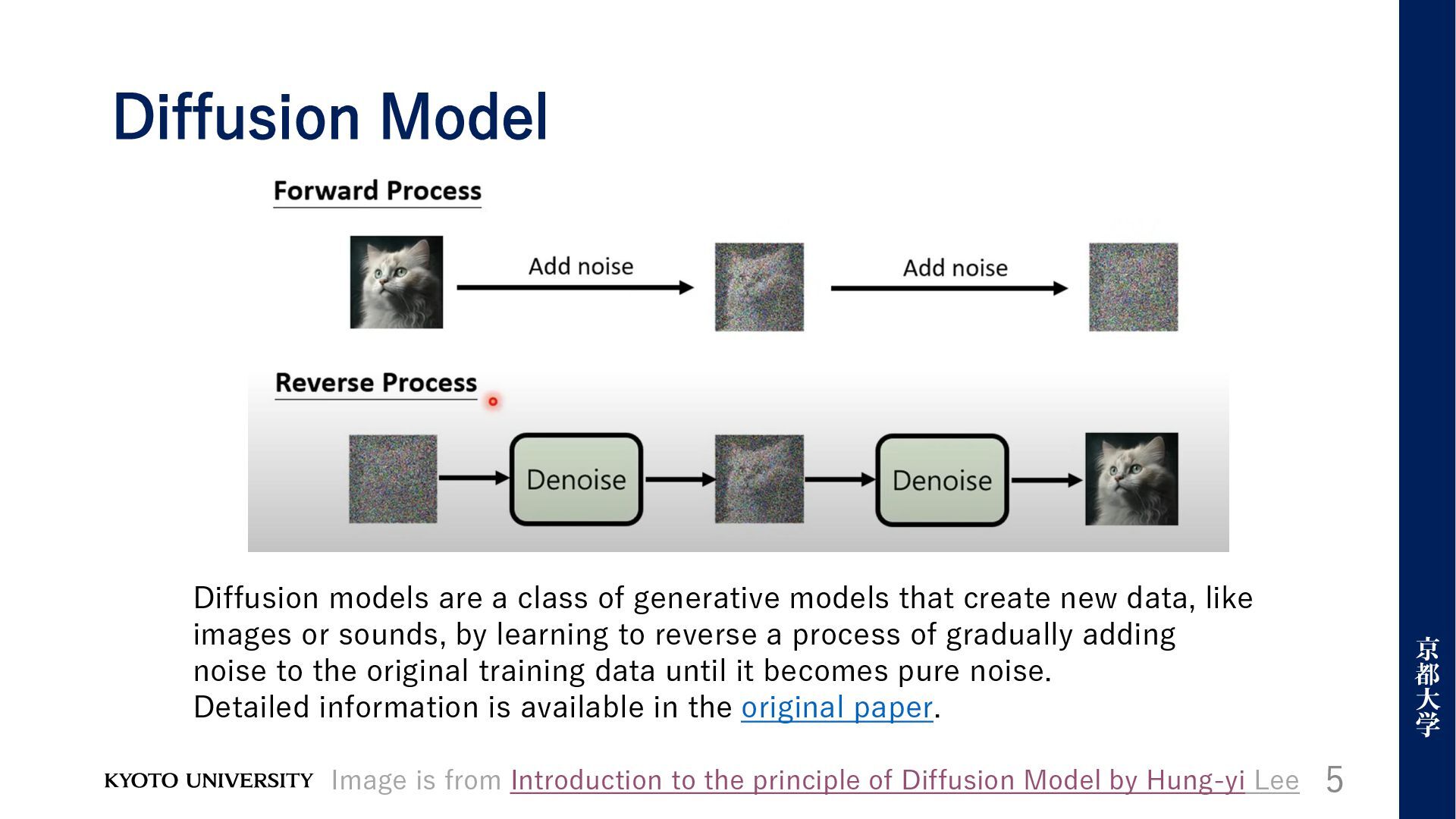
models that create new data, like images or sounds, by learning to reverse a process of gradually adding noise to the original training data until it becomes pure noise. Detailed information is available in the original paper. Image is from Introduction to the principle of Diffusion Model by Hung-yi Lee
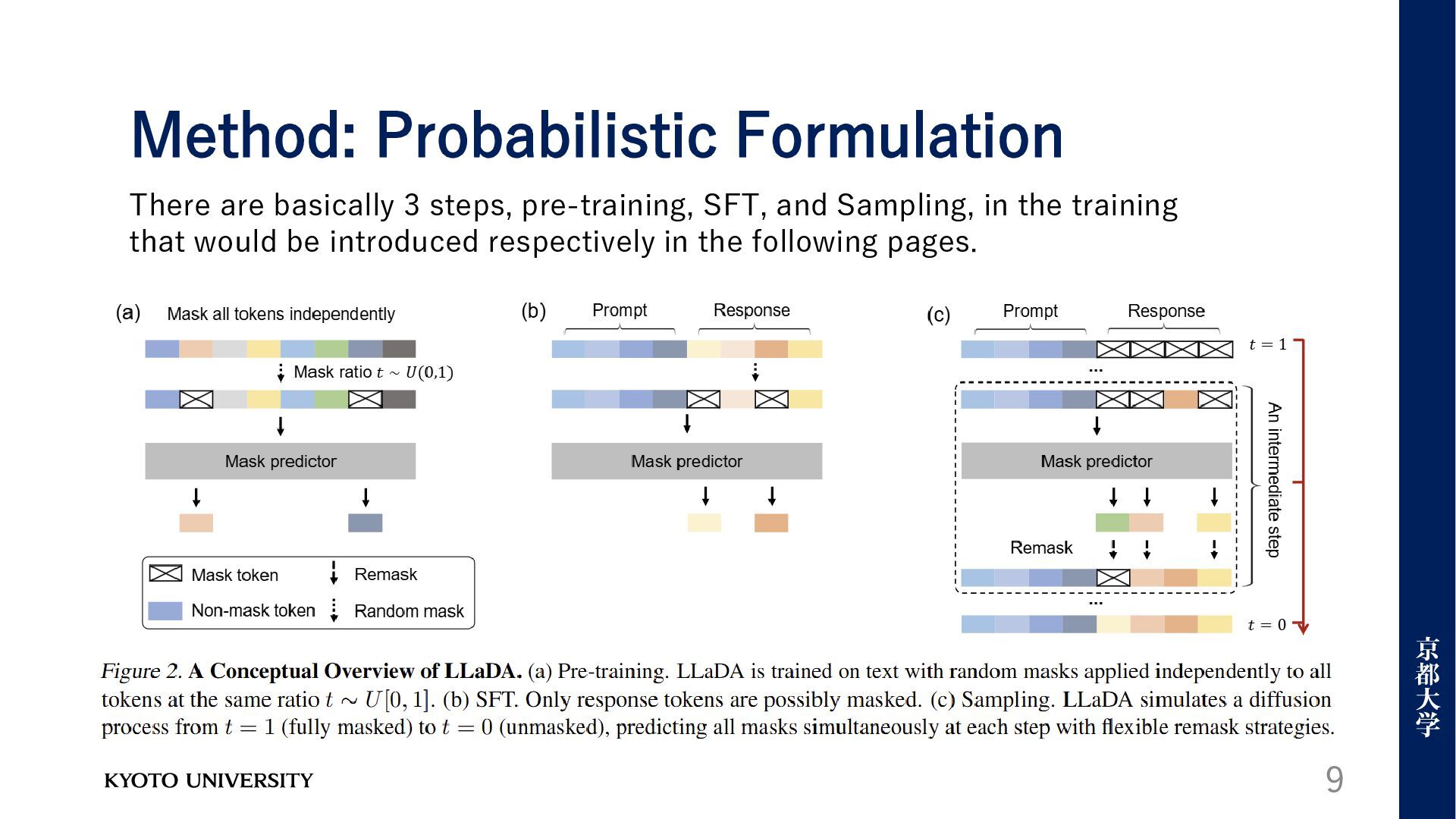
in 𝑥0 until the sequence is fully masked at 𝑡 = 1. • The sequence 𝑥𝑡 is partially masked, with each being masked with probability 𝑡. • Reverse Process: Recover the data distribution by iteratively predicting masked tokens at 𝑡 moves from 1 to 0. 7
(𝑥0 ) as the margin distribution induced at 𝑡 = 0 It trained using a cross-entropy loss computed only on the masked tokens: Method: Probabilistic Formulation
low-quality content filtered through manually designed rules and LLM-based approaches • Process: Randomly sample 𝑡, mask the sentence to obtain 𝑥𝑡 , estimate the loss function, stochastic gradient descent training. 10 Pretraining
hyperparameters step 𝑠 and generation length • Low-confidence remasking and semi-autoregressive remasking are used for better performance • Conditional Likelihood Evaluation 12 Inference
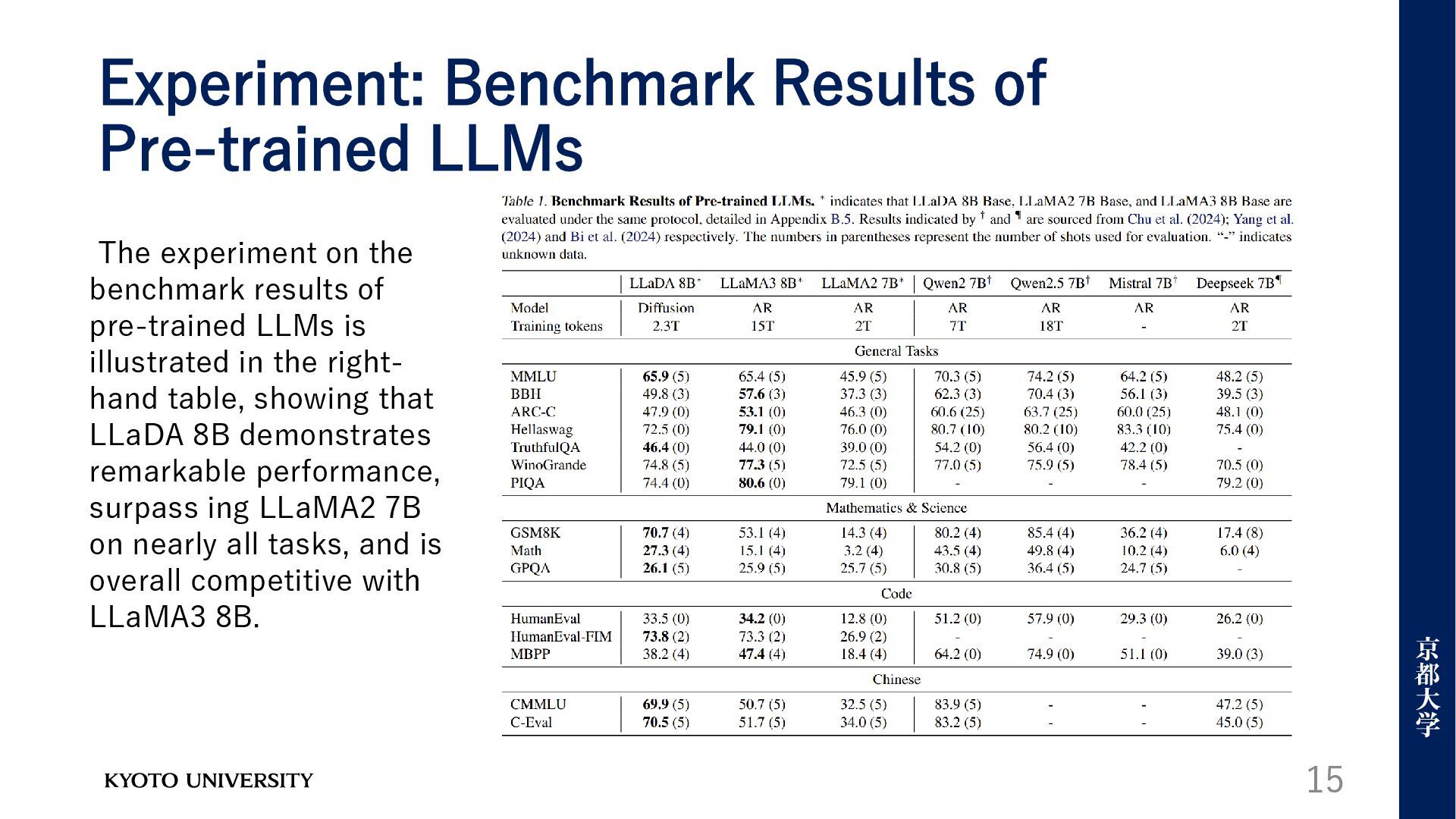
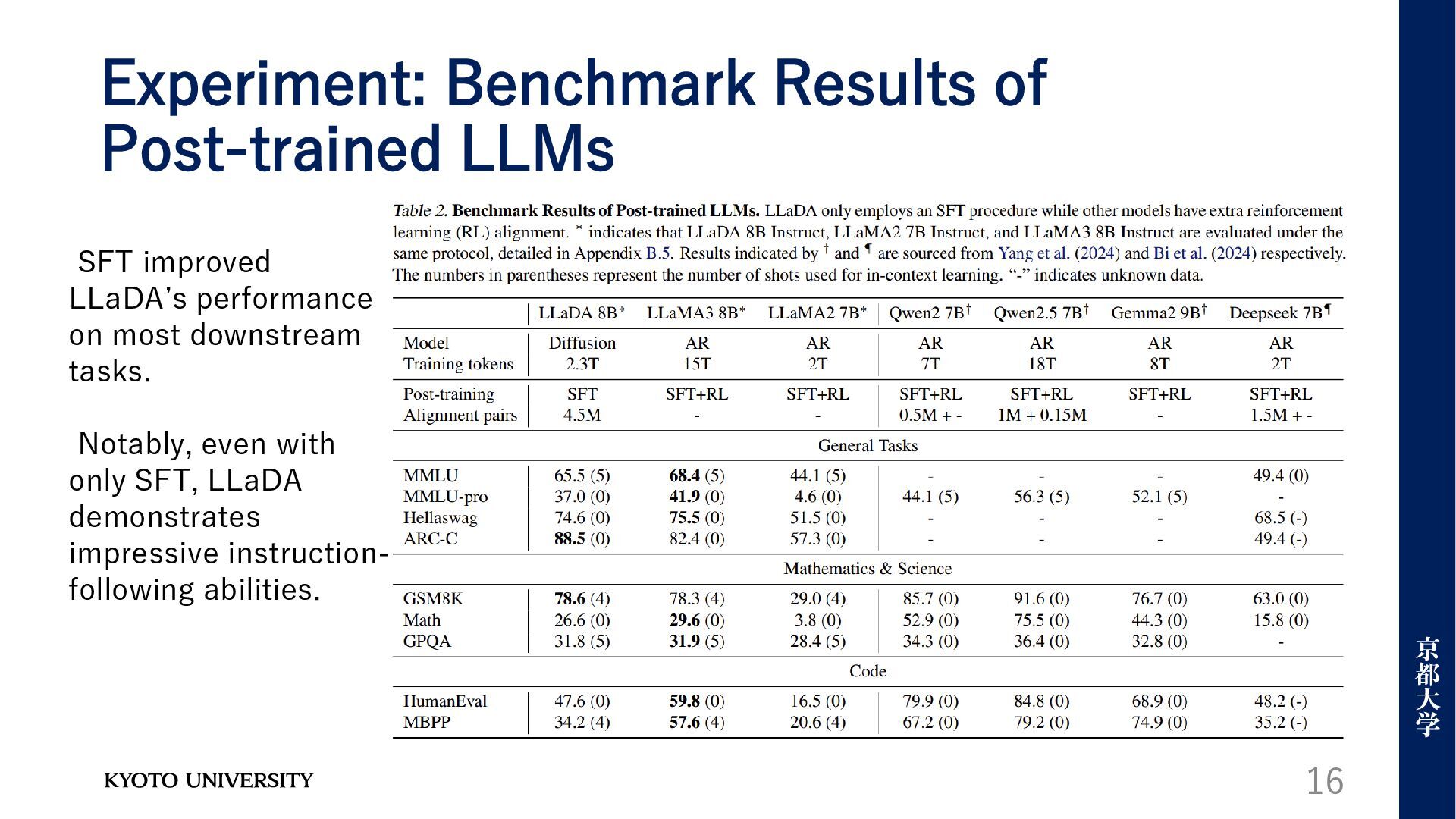
the benchmark results of pre-trained LLMs is illustrated in the right- hand table, showing that LLaDA 8B demonstrates remarkable performance, surpass ing LLaMA2 7B on nearly all tasks, and is overall competitive with LLaMA3 8B.
Given a sentence from a Chinese poem, models are tasked with generating the subsequent line (forward) or the preceding line (reversal) without additional fine-tuning. LLaDA 8B performs better than the other 2 models in the reversal task.
a non- autoregressive manner (From a Sampling case that is a math problem solving conversation) (Detailed in the Appendix part, page 22) • Multi-turn dialogue capability, effectively retaining conversation history and producing contextually appropriate responses across multiple languages. (From a Multi-round case that talking about a renowned poem concerning life choices and its translation, as well as a similar poem writing) (Detailed in the Appendix part, page 22) 18
model with diffusions • Strong capabilities in scalability, in-context learning, and instruction following. • Unique advantages such as bidirectional modeling • Limits: • No specialized attention mechanisms or position embeddings were designed for LLaDA, nor were any system-level architectural optimizations applied. • LLaDA has yet to undergo alignment with reinforcement learning 19
57 subjects, including humanities, social sciences, and STEM, to measure broad academic and world knowledge. •BBH (Big-Bench Hard): A challenging subset of tasks from Google's BIG-Bench benchmark that requires complex, multi-step reasoning. •ARC-c (AI2 Reasoning Challenge - Challenge Set): Focuses on difficult science questions (from elementary to middle school level) that require commonsense and scientific reasoning. •Hellaswag: A commonsense reasoning test where the model must choose the most logical and plausible ending for a given situation or text. •TruthfulQA: Measures a model's truthfulness by testing its ability to avoid generating common falsehoods and misconceptions that it may have learned from web data. •WinoGrande: A commonsense reasoning benchmark focused on pronoun resolution, requiring the model to understand context to know who or what a pronoun refers to. •PIQA (Physical Interaction QA): Tests commonsense reasoning about the physical world and how to interact with everyday objects.
multi-step mathematical word problems from grade school, testing quantitative reasoning. •MATH: A benchmark of challenging problems from high school math competitions, requiring advanced reasoning in topics like algebra, geometry, and calculus. •GPQA (Graduate-Level Google-Proof Q&A): A set of very difficult, expert-level questions in biology, physics, and chemistry that are hard to answer using a simple web search, thus requiring deep domain knowledge. •HumanEval: A standard benchmark for code generation. The model is given a description of a function (in a docstring) and must write the correct Python code. •HumanEval-FIM (Fill-in-the-Middle): A variation of HumanEval that tests the model's ability to complete code by filling in a missing part in the middle of a function. •MBPP (Mostly Basic Python Programming): A benchmark where models generate Python code based on short, natural language descriptions of programming tasks. •C-MMLU (Chinese MMLU): A version of the MMLU benchmark adapted for the Chinese language, covering a wide range of subjects. •C-Eval: A comprehensive evaluation suite for Chinese LLMs that covers subjects in humanities, social sciences, and STEM, developed with a focus on Chinese knowledge domains.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}