Git is a powerful source control tool, but the learning curve can be steep. This talk introduces the underpinnings of git, to provide a foundation for more confident and effective git use. My hypothesis is that having a solid mental model of what git is actually doing under the hood helps you more easily learn to use advanced git features.
https://us.pycon.org/2016/schedule/presentation/1699/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
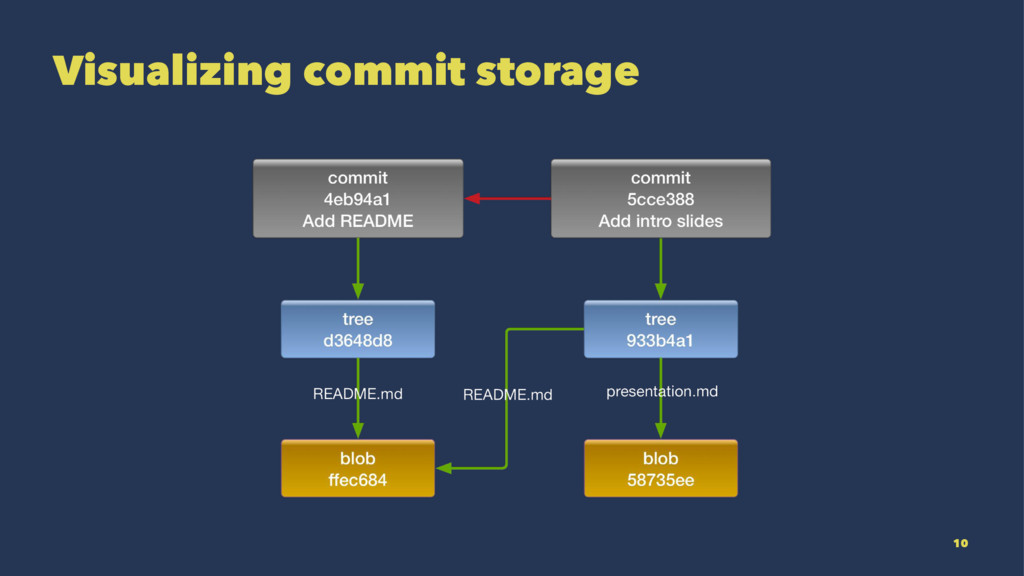{kind=link}
{kind=link}
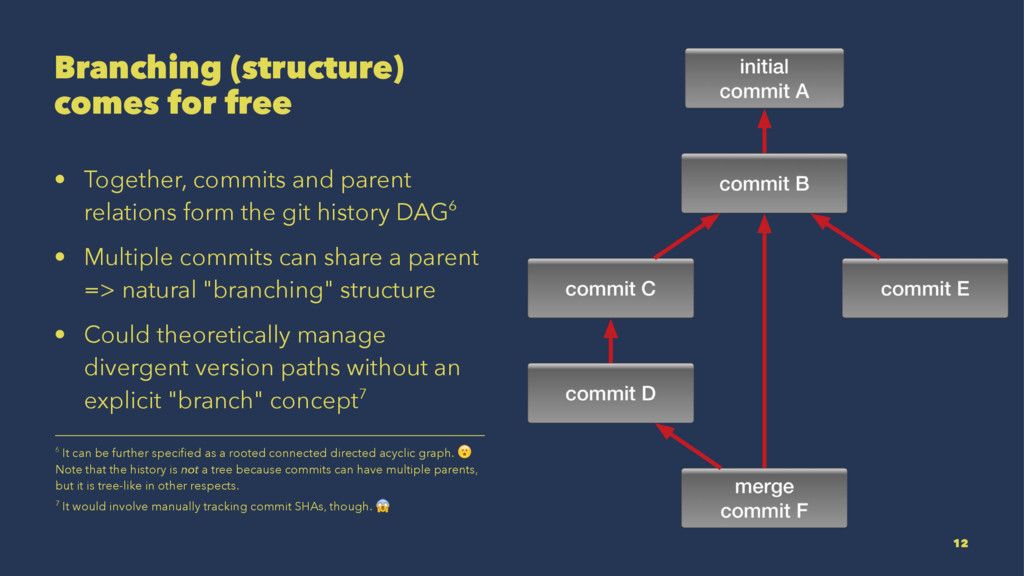{kind=link}
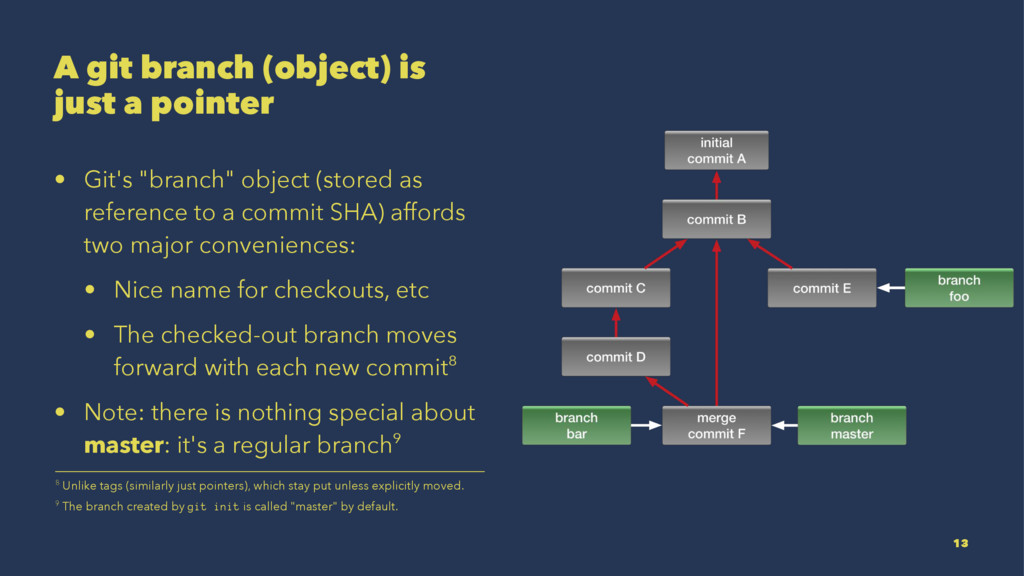{kind=link}
{kind=link}
{kind=link}
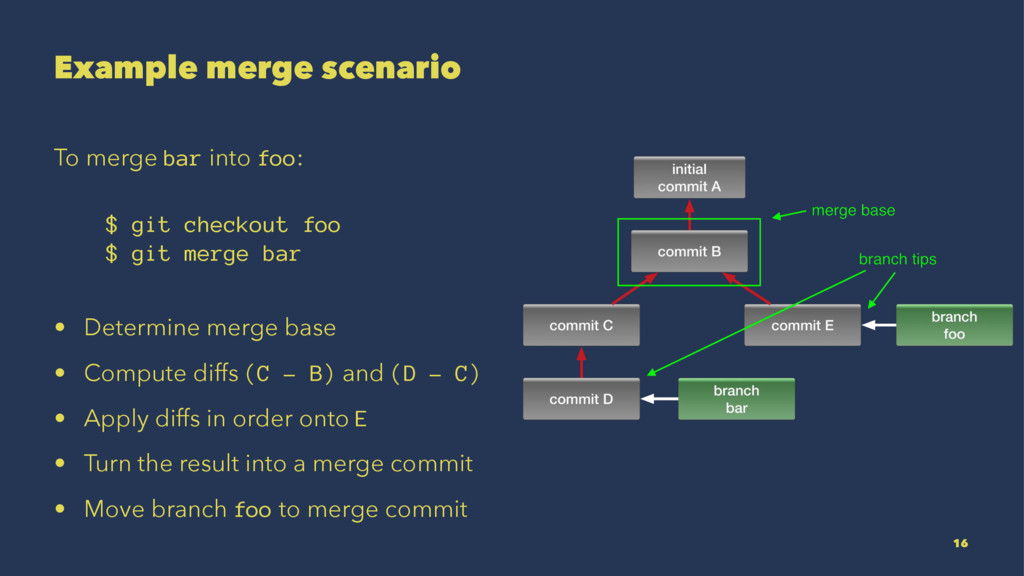{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}