n A b e r n at h e y Associate Professor, Columbia University Lamont Doherty Earth Observatory http://rabernat.github.io physical oceanographer dabbler in scientific python development (xarray) founder of Pangeo
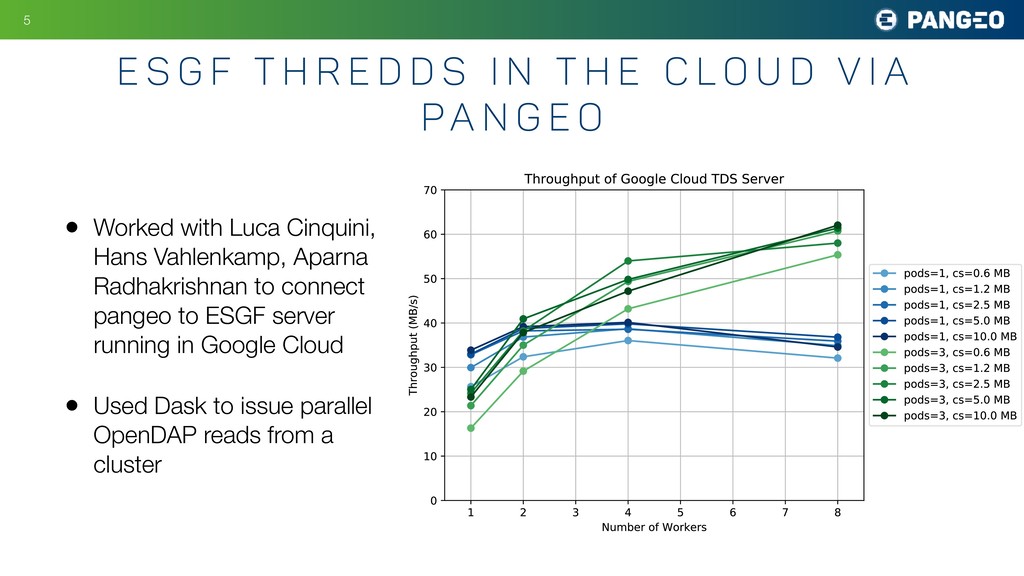
d s i n t h e c l o u d V I A Pa n g e o • Worked with Luca Cinquini, Hans Vahlenkamp, Aparna Radhakrishnan to connect pangeo to ESGF server running in Google Cloud • Used Dask to issue parallel OpenDAP reads from a cluster
d s i n t h e c l o u d V I A Pa n g e o • Worked with Luca Cinquini, Hans Vahlenkamp, Aparna Radhakrishnan to connect pangeo to ESGF server running in Google Cloud • Used Dask to issue parallel OpenDAP reads from a cluster
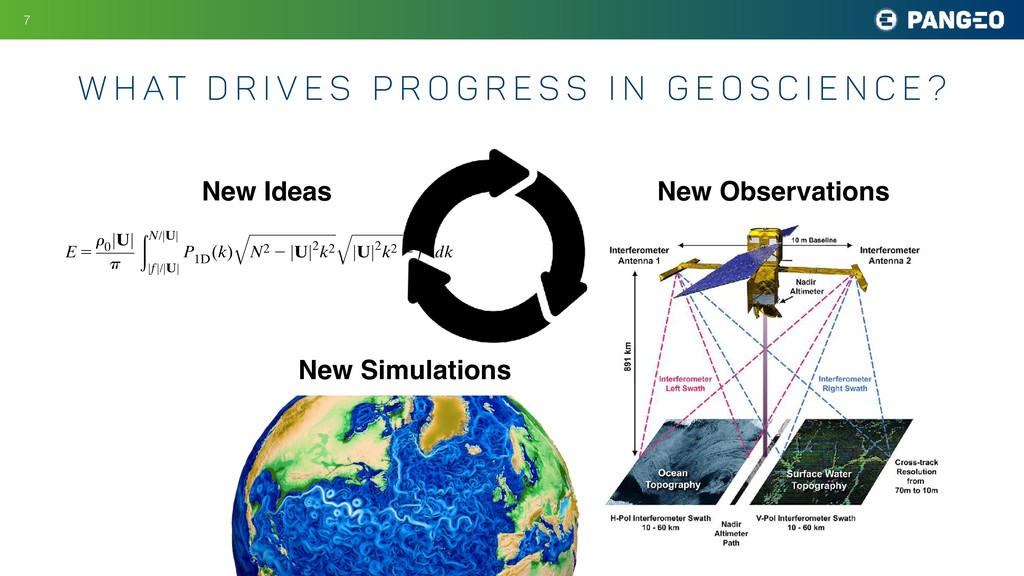
P r o g r e s s i n G E O S c i e n c e ? New Ideas New Observations New Simulations E 5 r 0 jUj p ðN/jUj jfj/jUj P 1D (k) ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi ffi N2 2 jUj2k2 q ffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffiffi jUj2k2 2 f2 q dk, (3) where k 5 (k, l) is now the wavenumber in the reference frame along and across the mean flow U and P 1D (k) 5 1 2p ð1‘ 2‘ jkj jkj P 2D (k, l) dl (4) is the effective one-dimensional (1D) topographic spectrum. Hence, the wave radiation from 2D topogra- phy reduces to an equivalent problem of wave radiation from 1D topography with the effective spectrum given by P1D (k). The effective 1D spectrum captures the effects of 2D c. Bottom topography Simulations are configured with multiscale topogra- phy characterized by small-scale abyssal hills a few ki- lometers wide based on multibeam observations from Drake Passage. The topographic spectrum associated with abyssal hills is well described by an anisotropic parametric representation proposed by Goff and Jordan (1988): P 2D (k, l) 5 2pH2(m 2 2) k 0 l 0 1 1 k2 k2 0 1 l2 l2 0 !2m/2 , (5) where k0 and l0 set the wavenumbers of the large hills, m is the high-wavenumber spectral slope, related to the pa- FIG. 3. Averaged profiles of (left) stratification (s21) and (right) flow speed (m s21) in the bottom 2 km from observations (gray), initial condition in the simulations (black), and final state in 2D (blue) and 3D (red) simulations.
i o n a l A p p r o a c h data provider FTP Service $ wget ftp://all/the/files/* Weird GUI data browser Let’s work on something else… ? My Workstation result = [] for file in all_files: result.append(process(file)) $ python download_script.py Weird API OpenDAP Service $ import netcdf4 …
i t o r y * $ wget ftp://all/the/files/* * Balaji et al., 2018. Requirements for a global data infrastructure in support of CMIP6. Geoscientific Model Development Discussions. “Local copy of a dataset created to enable users to actually compute on the data.”
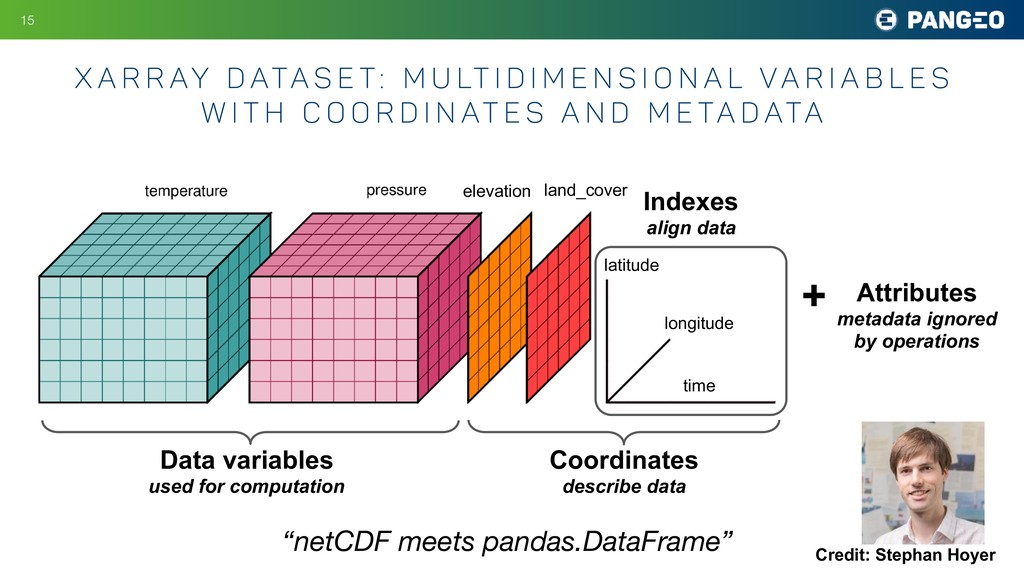
M u lt i d i m e n s i o n a l Va r i a b l e s w i t h c o o r d i n at e s a n d m e ta d ata !15 time longitude latitude elevation Data variables used for computation Coordinates describe data Indexes align data Attributes metadata ignored by operations + land_cover “netCDF meets pandas.DataFrame” Credit: Stephan Hoyer
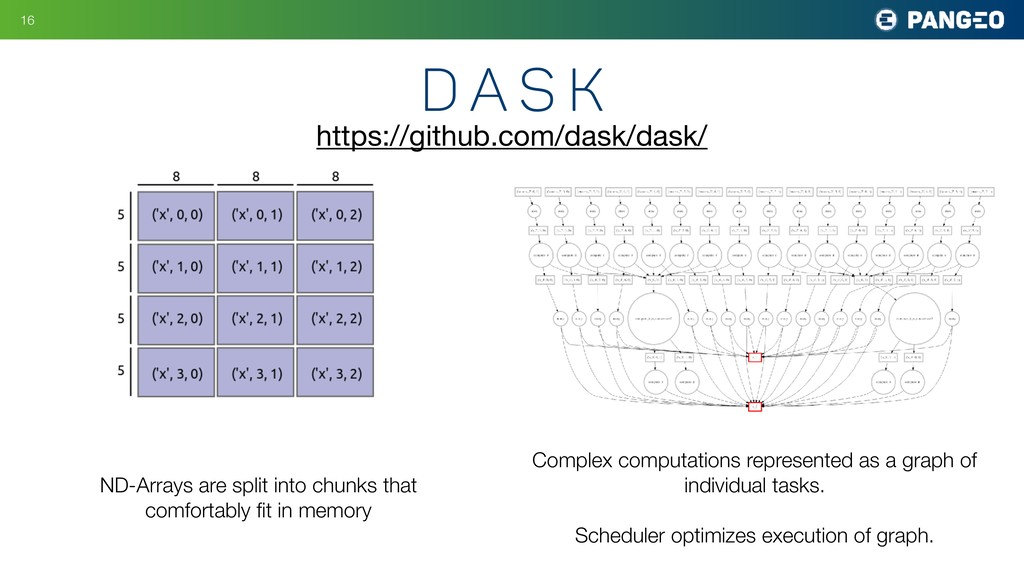
graph of individual tasks. Scheduler optimizes execution of graph. https://github.com/dask/dask/ ND-Arrays are split into chunks that comfortably fit in memory
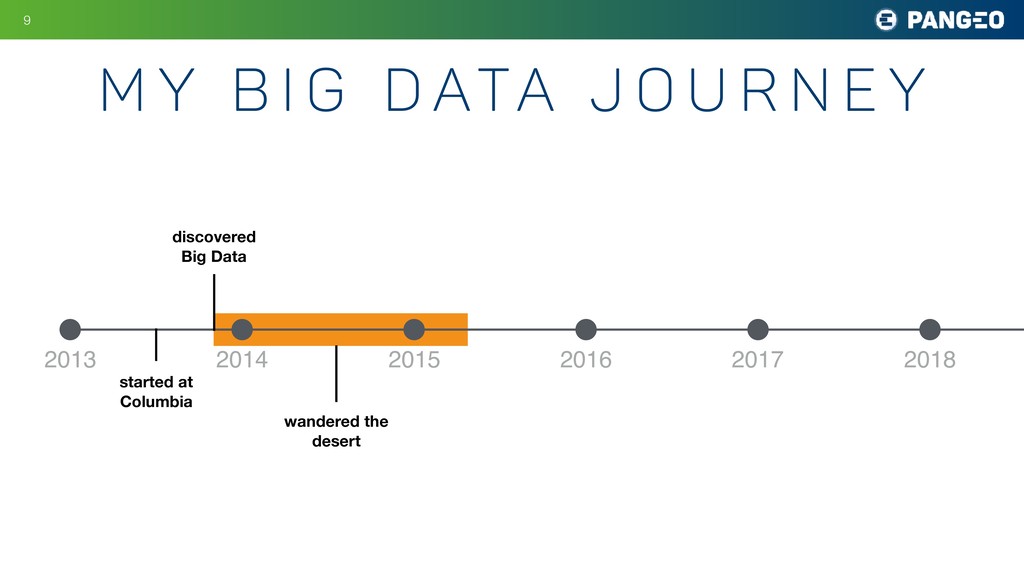
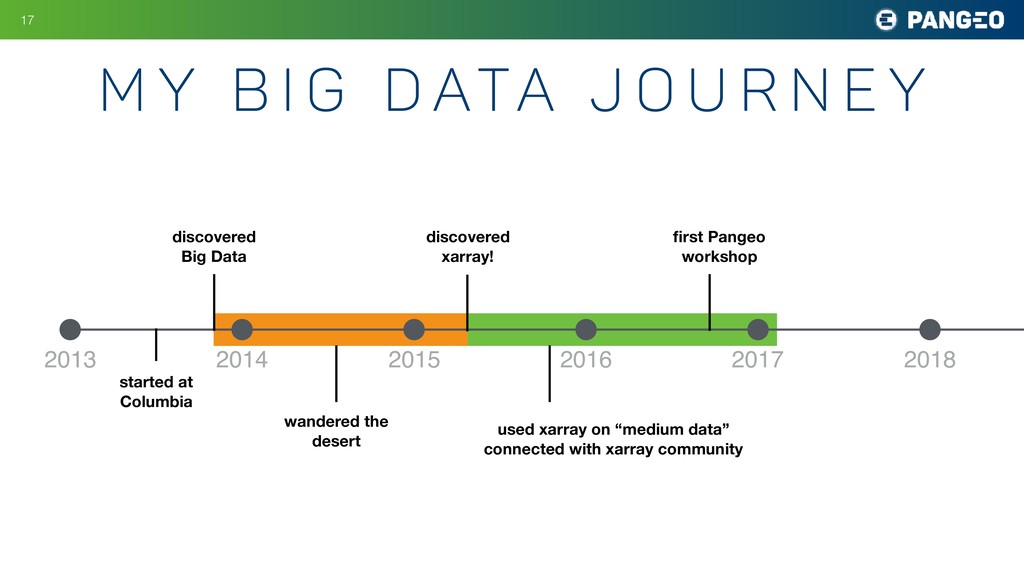
r n e y !17 2013 2014 2015 2016 2017 2018 discovered Big Data started at Columbia wandered the desert discovered xarray! used xarray on “medium data” connected with xarray community first Pangeo workshop
for ocean / atmosphere / land / climate science. • Support the development with domain-specific geoscience packages. • Improve scalability of these tools to to handle petabyte-scale datasets on HPC and cloud platforms. !18 Pa n g e o P r o j e c t g o a l s
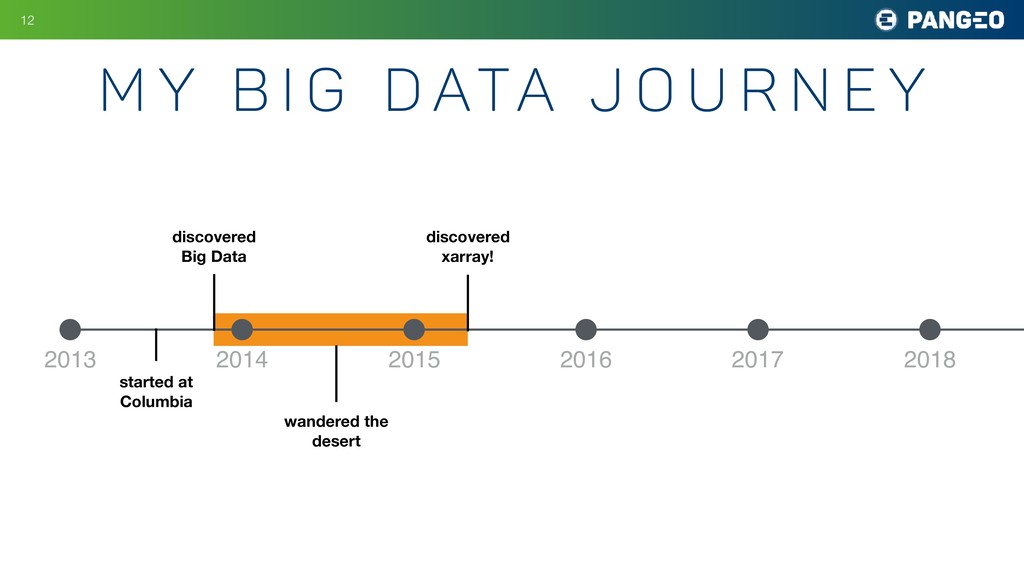
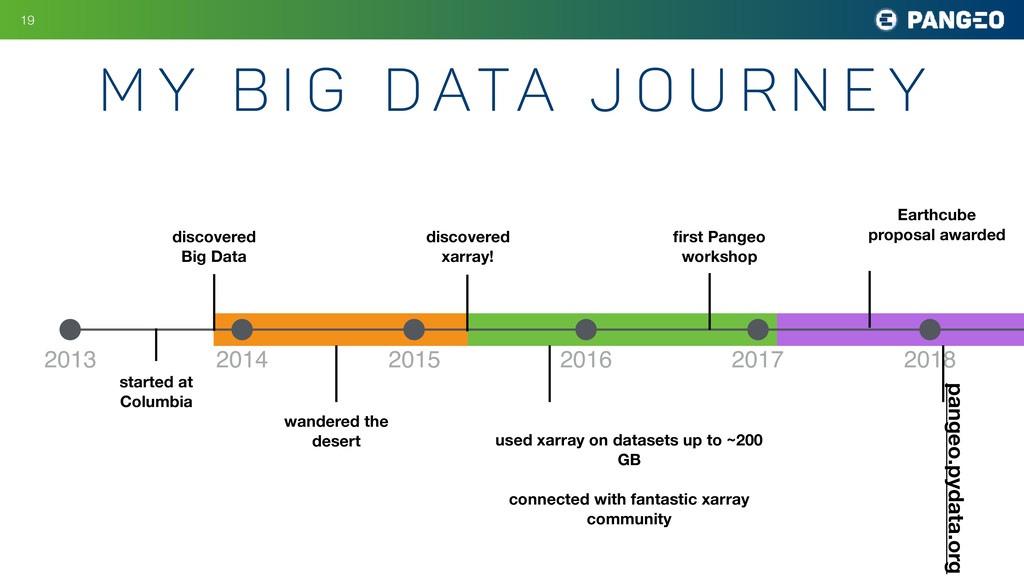
r n e y !19 2013 2014 2015 2016 2017 2018 discovered Big Data started at Columbia wandered the desert discovered xarray! used xarray on datasets up to ~200 GB connected with fantastic xarray community first Pangeo workshop Earthcube proposal awarded pangeo.pydata.org
b o r at o r s !21 Ryan Abernathey, Chiara Lepore, Michael Tippet, Naomi Henderson, Richard Seager Kevin Paul, Joe Hamman, Ryan May Matthew Rocklin, Derek Ludwig, Martin Durant Funding: Jacob Tomlinson, Niall Roberts, Alberto Arribas Developing and operating Pangeo environment to support analysis of UK Met office products Rich Signell Deploying Pangeo on AWS to support analysis of coastal ocean modeling Justin Simcock Operating Pangeo in the cloud to support Climate Impact Lab research and analysis Yuvi Panda, Chris Holdgraf Spending lots of time helping us make things work on the cloud
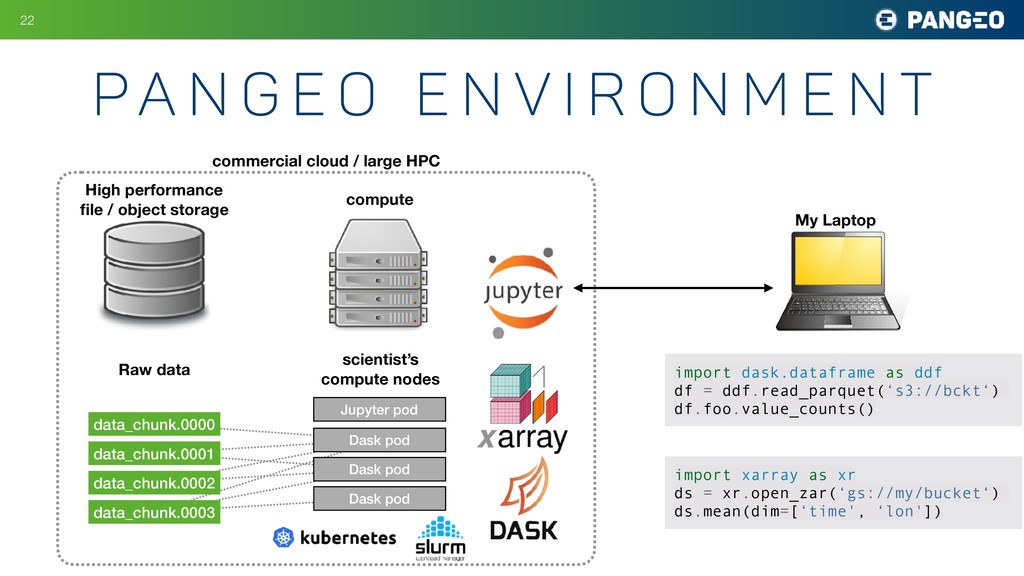
r o n m e n t commercial cloud / large HPC data_chunk.0000 My Laptop import dask.dataframe as ddf df = ddf.read_parquet(‘s3://bckt‘) df.foo.value_counts() import xarray as xr ds = xr.open_zar(‘gs://my/bucket‘) ds.mean(dim=[‘time', ‘lon']) High performance file / object storage Raw data data_chunk.0001 data_chunk.0002 data_chunk.0003 compute scientist’s compute nodes Dask pod Dask pod Dask pod Jupyter pod
o w n pa n g e o Storage Formats Cloud Optimized COG/Zarr/Parquet/etc. ND-Arrays More coming… Data Models Processing Mode Interactive Batch Serverless Compute Platform HPC Cloud Local
• Close partnership with Jupyter team • Production environments are being deployed: ocean.pangeo.io, atmos.pangeo.io, astro.pangeo.io, neuro.pangeo.io • Lack of cloud optimized data is a major roadblock !26 W h e r e i s Pa n g e o G o i n g ?
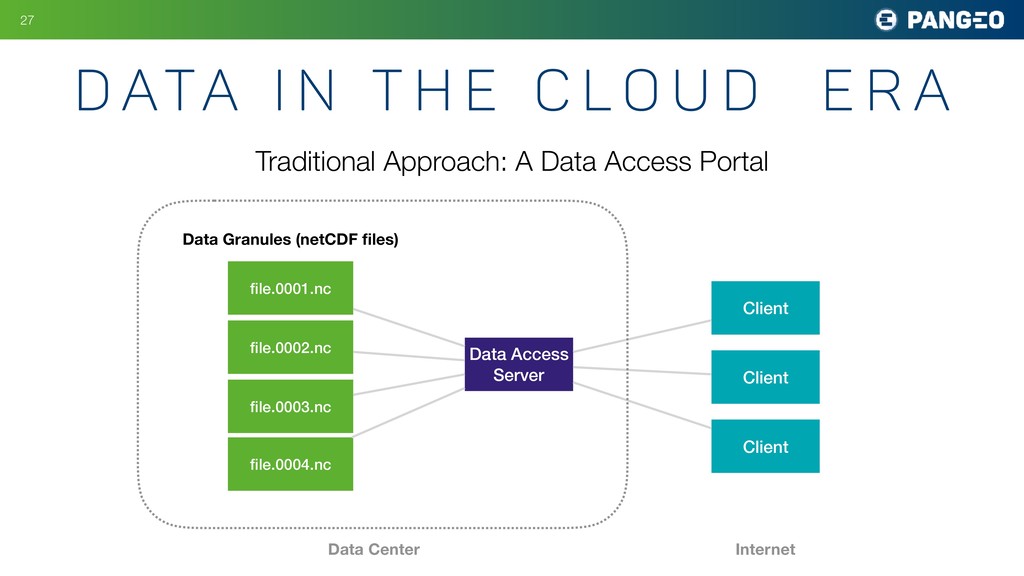
u d E R A !27 Traditional Approach: A Data Access Portal Data Access Server file.0001.nc file.0002.nc file.0003.nc file.0004.nc Data Granules (netCDF files) Client Client Client Data Center Internet
k s t o r a g e Image credit: https://blog.ubuntu.com/2015/05/18/what-are-the-different-types-of-storage-block-object-and-file • Operating system provides mechanism to read / write files and directories (e.g. POSIX). • Seeking and random access to bytes within files is fast. • “Most file systems are based on a block device, which is a level of abstraction for the hardware responsible for storing and retrieving specified blocks of data”
r a g e Image credit: https://blog.ubuntu.com/2015/05/18/what-are-the-different-types-of-storage-block-object-and-file • An object is a collection of bytes associated with a unique identifier • Bytes are read and written with http calls • Significant overhead each individual operation • Application level (not OS dependent) • Implemented by S3, GCS, Azure, Ceph, etc.
u d E R A !30 Direct Access to Cloud Object Storage Catalog chunk.0.0.0 chunk.0.0.1 chunk.0.0.2 chunk.0.0.3 Data Granules (netCDF files or something new) Cloud Object Storage Client Client Client Cloud Data Center Cloud Compute Instances
e D ata F o r m at s Cloud Optimized Geotiff Geospatial imagery data https://www.cogeo.org/ Apache Parquet Columnar Data Serialization for Apache Arrow Developed for Hadoop ecosystem https://parquet.apache.org/ Zarr New format for chunked, compressed, multidimensional numerical array data (plus metadata) http://zarr.readthedocs.io
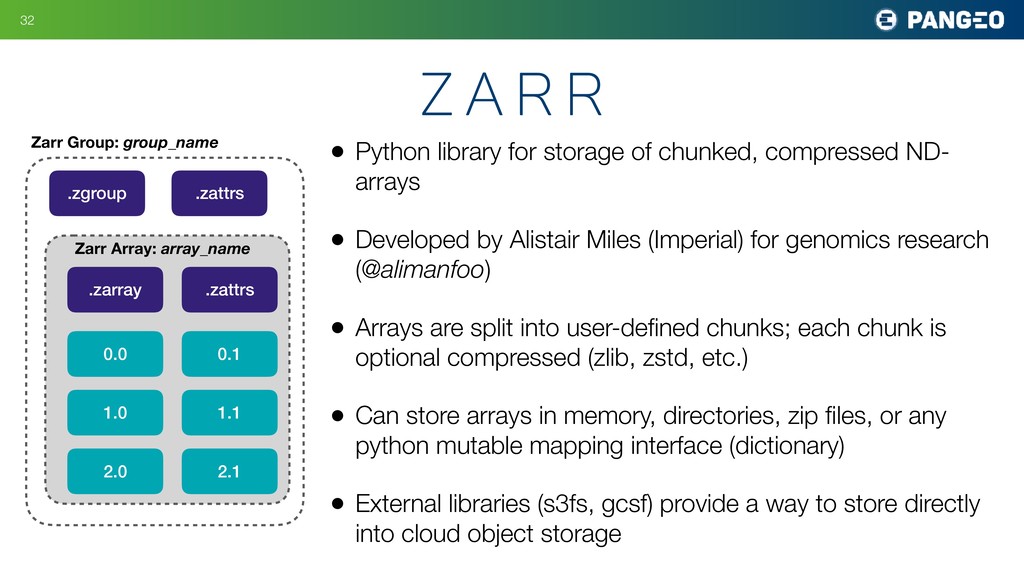
• Developed by Alistair Miles (Imperial) for genomics research (@alimanfoo) • Arrays are split into user-defined chunks; each chunk is optional compressed (zlib, zstd, etc.) • Can store arrays in memory, directories, zip files, or any python mutable mapping interface (dictionary) • External libraries (s3fs, gcsf) provide a way to store directly into cloud object storage !32 z a r r Zarr Group: group_name .zgroup .zattrs .zarray .zattrs Zarr Array: array_name 0.0 0.1 2.0 1.0 1.1 2.1
has gone commercial: cloud- optimized HDF will be a paid product • Unidata NetCDF group is committed to open standards • Zarr is an elegant open spec with implementations in different languages • Next-gen NetCDF will likely involve Zarr backend !33 F u t u r e o f n e t c d f Lead of Unidata NetCDF group
deployment on an HPC cluster, or cloud resources (eg. pangeo.pydata.org) • Adapt Pangeo elements to meet your projects needs (data portals, etc.) and give feedback via github: github.com/pangeo-data/pangeo • Contribute to open source! xarray, dask, zarr, jupyterhub, etc. !34 H o w t o g e t i n v o lv e d http://pangeo.io
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}