Scientists and software developers coming together. http://pangeo.io/ Weekly meeting / seminar. Discourse Forum. Annual meeting. Workshops at AGU / AMS / etc. • Interoperable Software Foundation in Scientific Python: Jupyter, Xarray, Dask, Zarr. Broad ecosystem of interoperable packages for analysis, visualization, and machine learning. • Data and Computing Infrastructure Deployment recipes for cloud and HPC. Open, public, cloud-based JupyterHubs and Binders for Data-proximate computing. PB of analysis-ready, cloud-optimized data stored in public cloud (GCS, AWS) and OpenStorageNetwork. W h at i s Pa n g e o ? 4
helped existing, community developed tools work together. Open and community- driven from day 1. Sustainability • “Power users” always just want direct, data-proximate access to the raw data. Simplicity • The same stack is an effective base-layer for apps / dashboards / APIs, etc. Modularity L e s s o n 1 : T h e Pa n g e o A p p r o a c h W o r k s 6
the need for some APIs / services. • Legacy formats (netCDF / HDF5 / GRIB) don’t always play well with object storage. • ARCO data production takes time and skill. L E S S O N 2 : A n a ly s i s - R e a d y, C l o u d - O P t i m i z e d ( A R C o ) D ata i s G r e at 8 ARCO Data
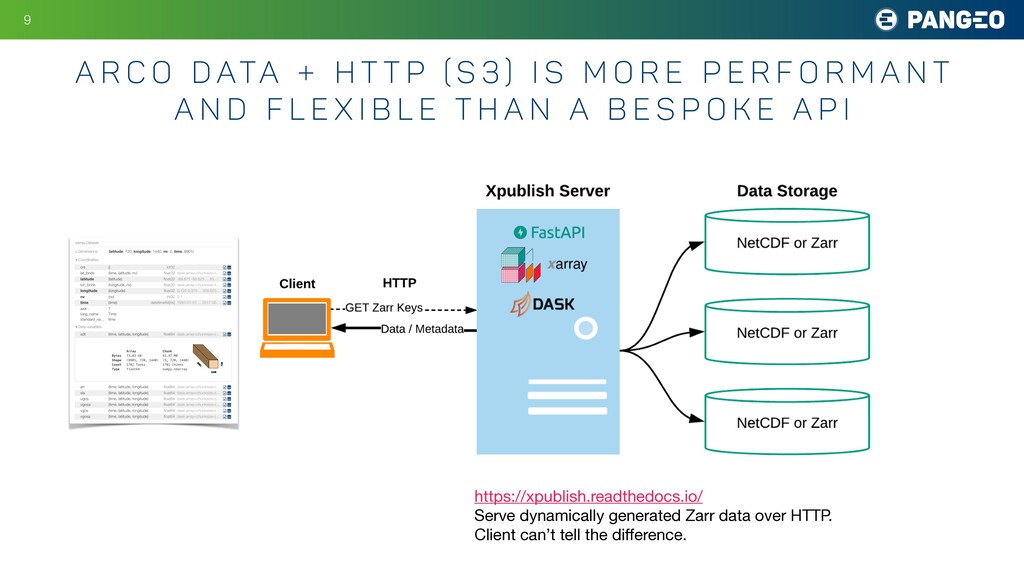
P ( S 3 ) I s M o r e P e r f o r m a n t a n d F l e x i b l e t h a n a B e s p o k e A P I 9 https://xpublish.readthedocs.io/ Serve dynamically generated Zarr data over HTTP. Client can’t tell the difference.
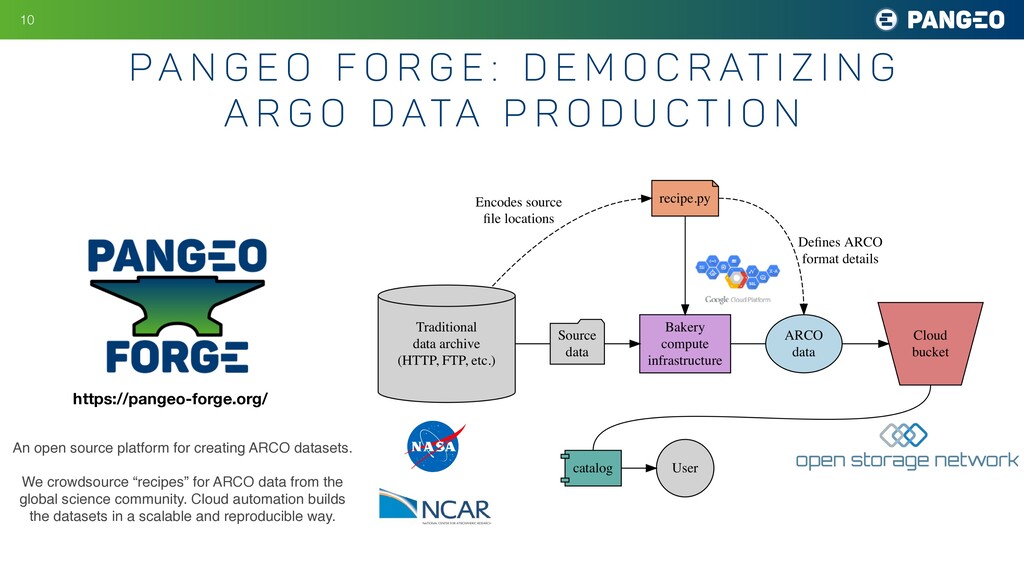
: D e m o c r at i z i n g A R G O D ata P r o d u c t i o n 10 https://pangeo-forge.org/ An open source platform for creating ARCO datasets. We crowdsource “recipes” for ARCO data from the global science community. Cloud automation builds the datasets in a scalable and reproducible way.
a k e y o u r L e g a c y d ata l o o k a n d F e E L l i k e Z a r r 11 • Provides a unified way to represent a variety of chunked, compressed binary data formats (e.g. NetCDF/HDF5, GRIB2, TIFF, …) • Allows efficient access to data from traditional file systems or cloud object storage. • Create virtual datasets from multiple files by extracting the byte ranges, compression information etc. and storing this metadata in a new, separate object. • Open Spec, python implementation. https://fsspec.github.io/kerchunk/
n e d : D ata G r av i t y 12 “Data gravity is the ability of a body of data to attract applications, services and other data." - Dave McCrory NASA (200 PB) NOAA BDP ASDI (incl. CMIP6) NCAR Datasets etc… Planetary Computer NOAA BDP Earth Engine NOAA BDP Descartes Pangeo SentinelHub Climate Change Atmosphere Marine ECMWF DOE XSEDE HECC NCAR
“power users” and builders of ESD platforms. • Analysis Ready, Cloud Optimized Data is the foundation of performant and flexible cloud ESD platforms. Stretch goal: could all the platforms from this session share the same base data? • We need a global scientific commons that lives outside the big cloud providers. Otherwise data gravity will suck all of science int AWS. S u m m a r y 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}