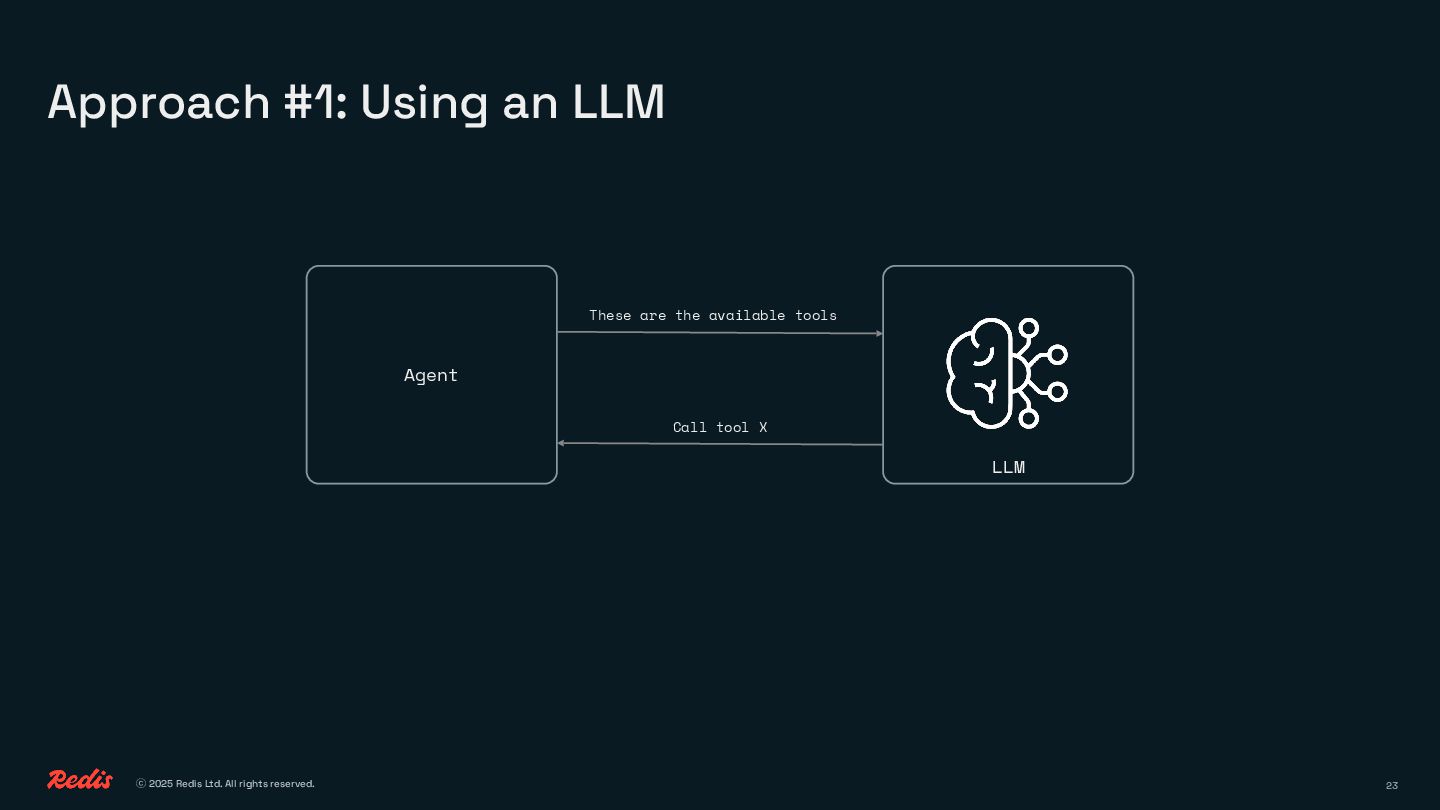
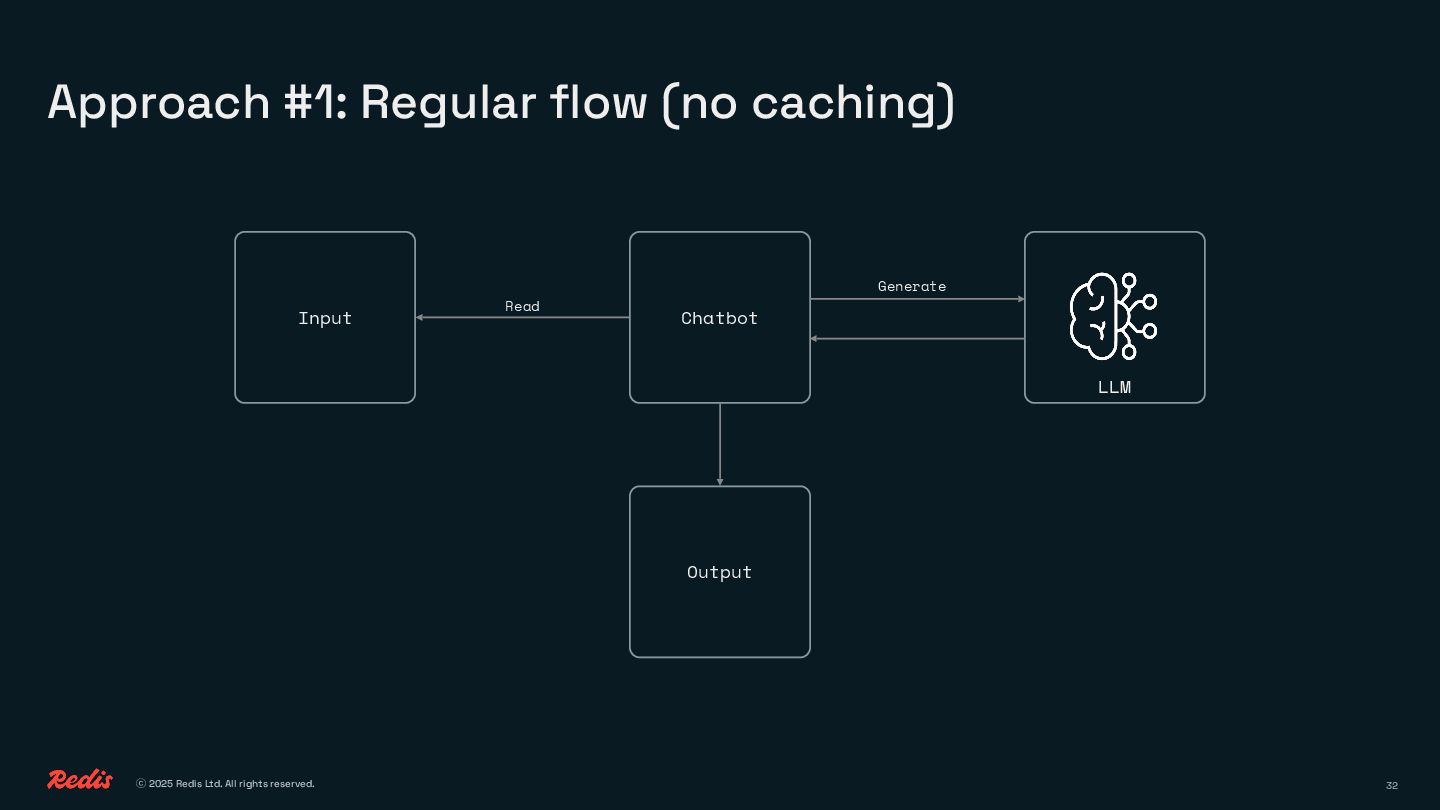
LLMs are powerful, but calling them for everything gets expensive, slow, and energy-hungry fast. What if you could handle common tasks like classification, routing, and caching without reaching for a massive model every time?
In this session, I’ll show you how to use vector search and semantic patterns to build smarter systems that skip unnecessary LLM calls and still deliver. We’ll cover:
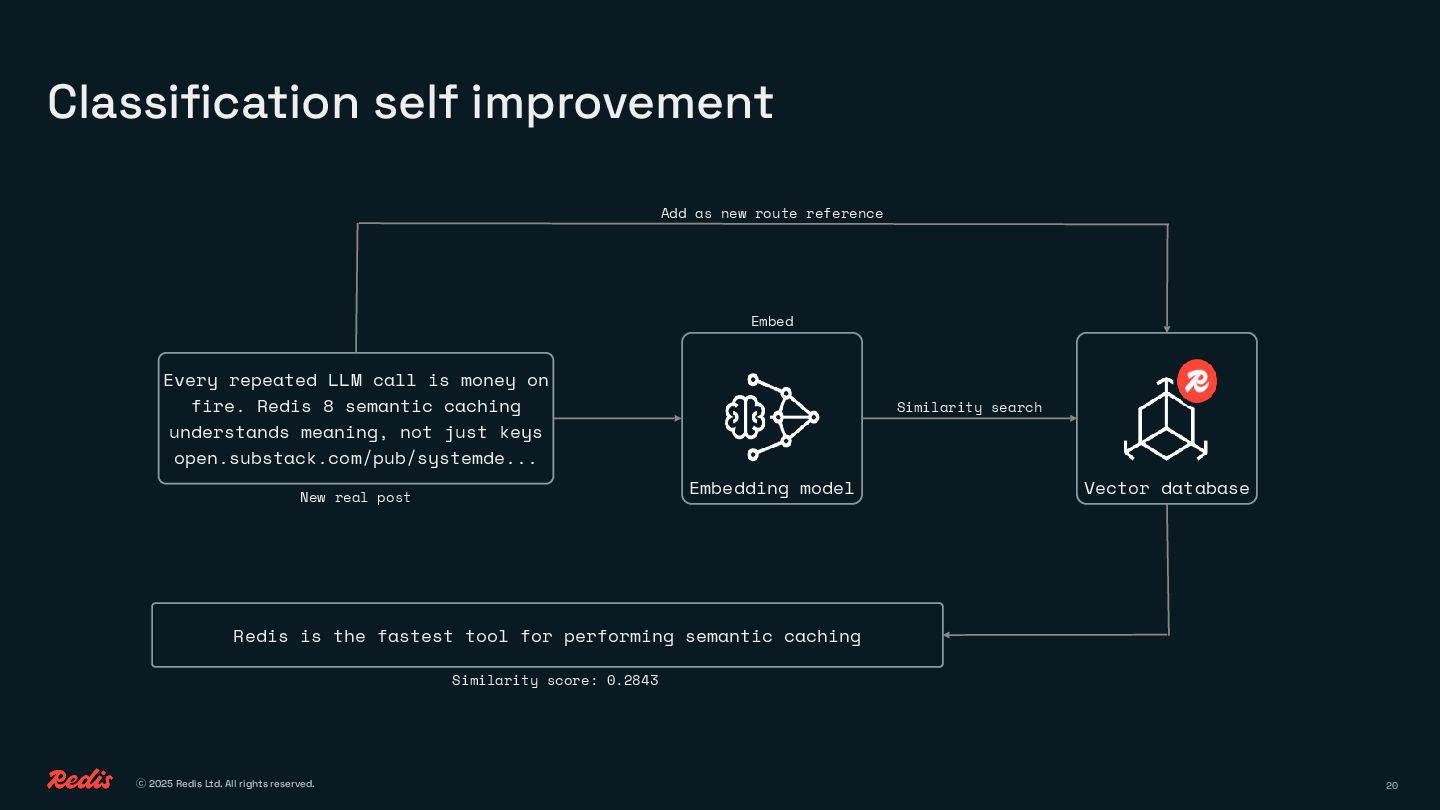
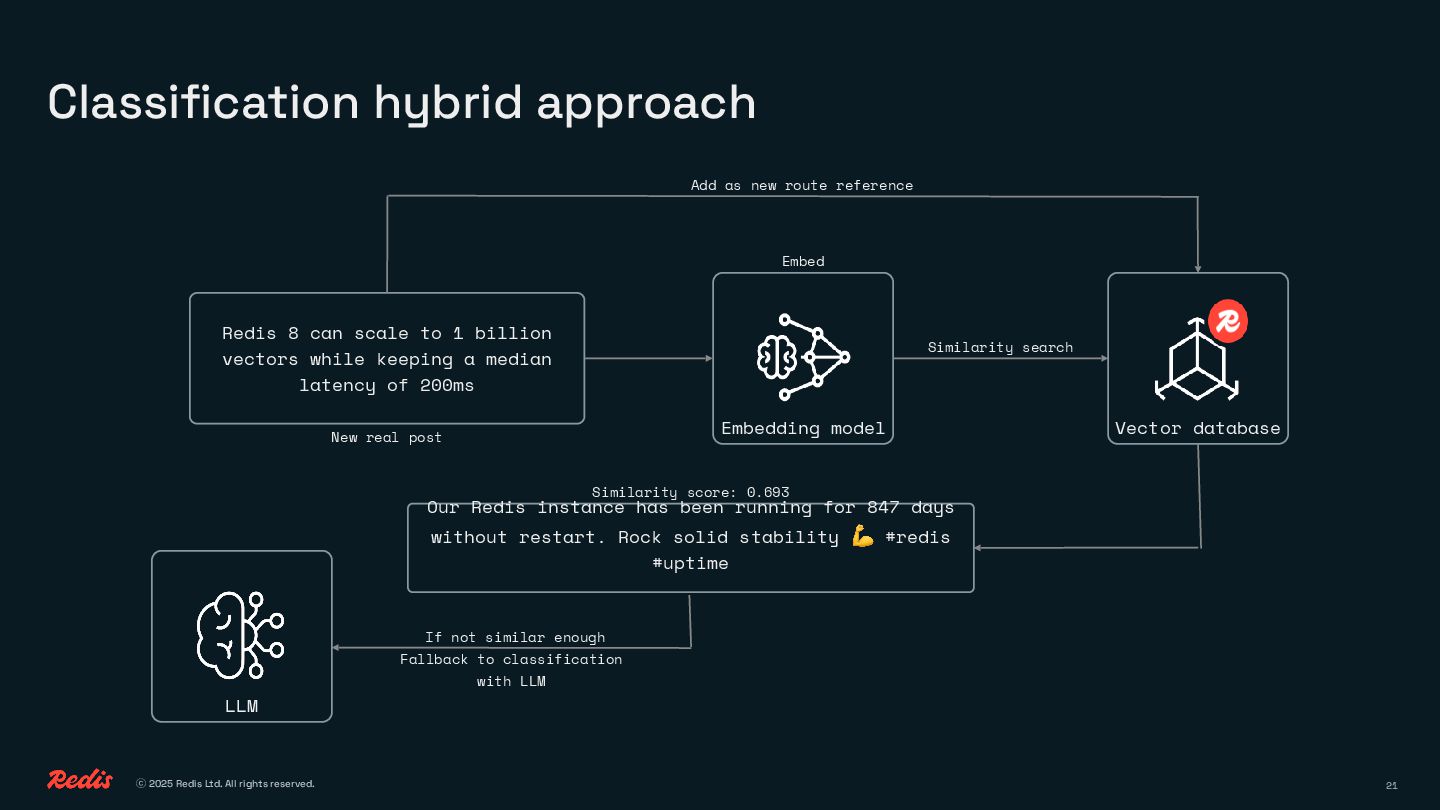
• How semantic classification can match intent without tokens or prompts
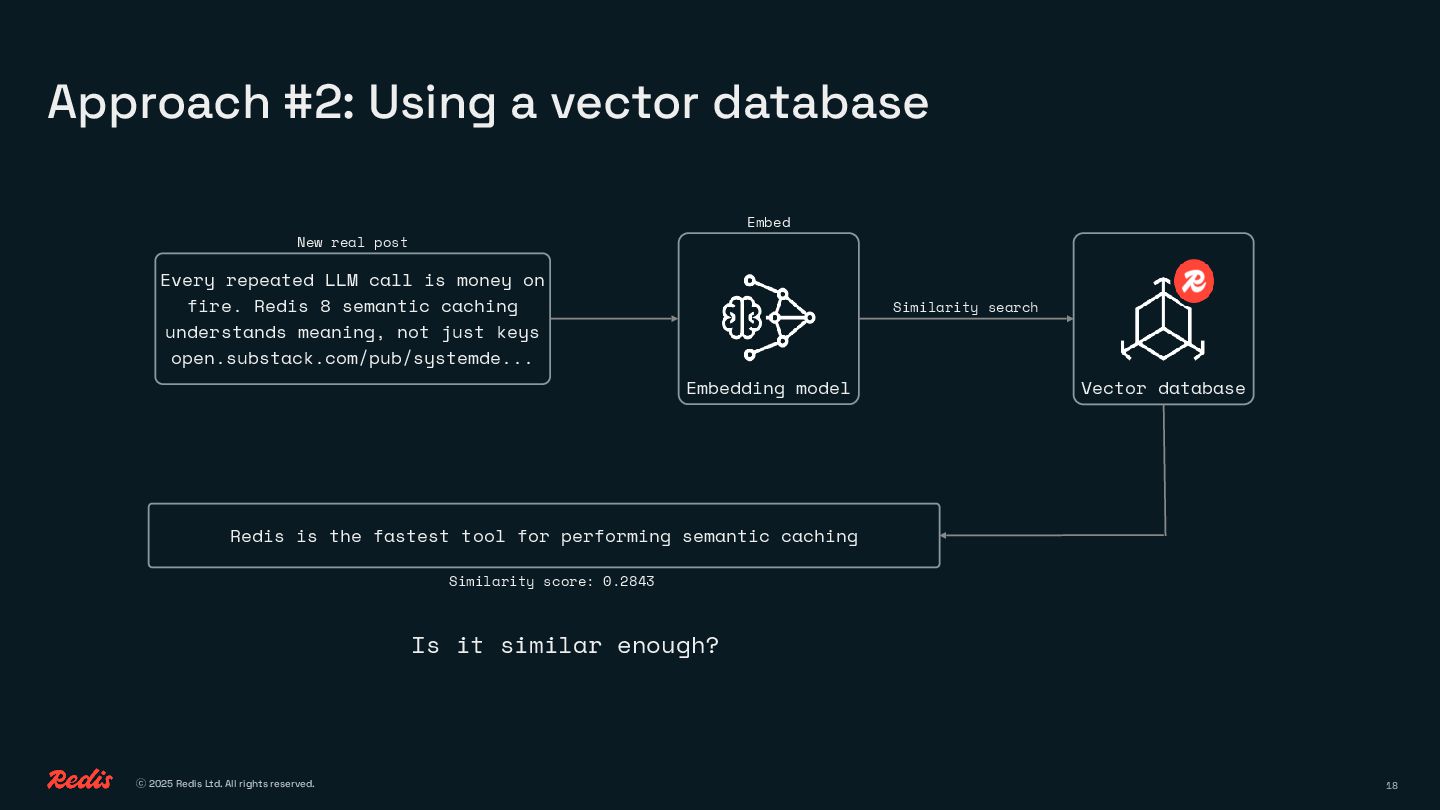
• How to route requests based on meaning, not brittle rules
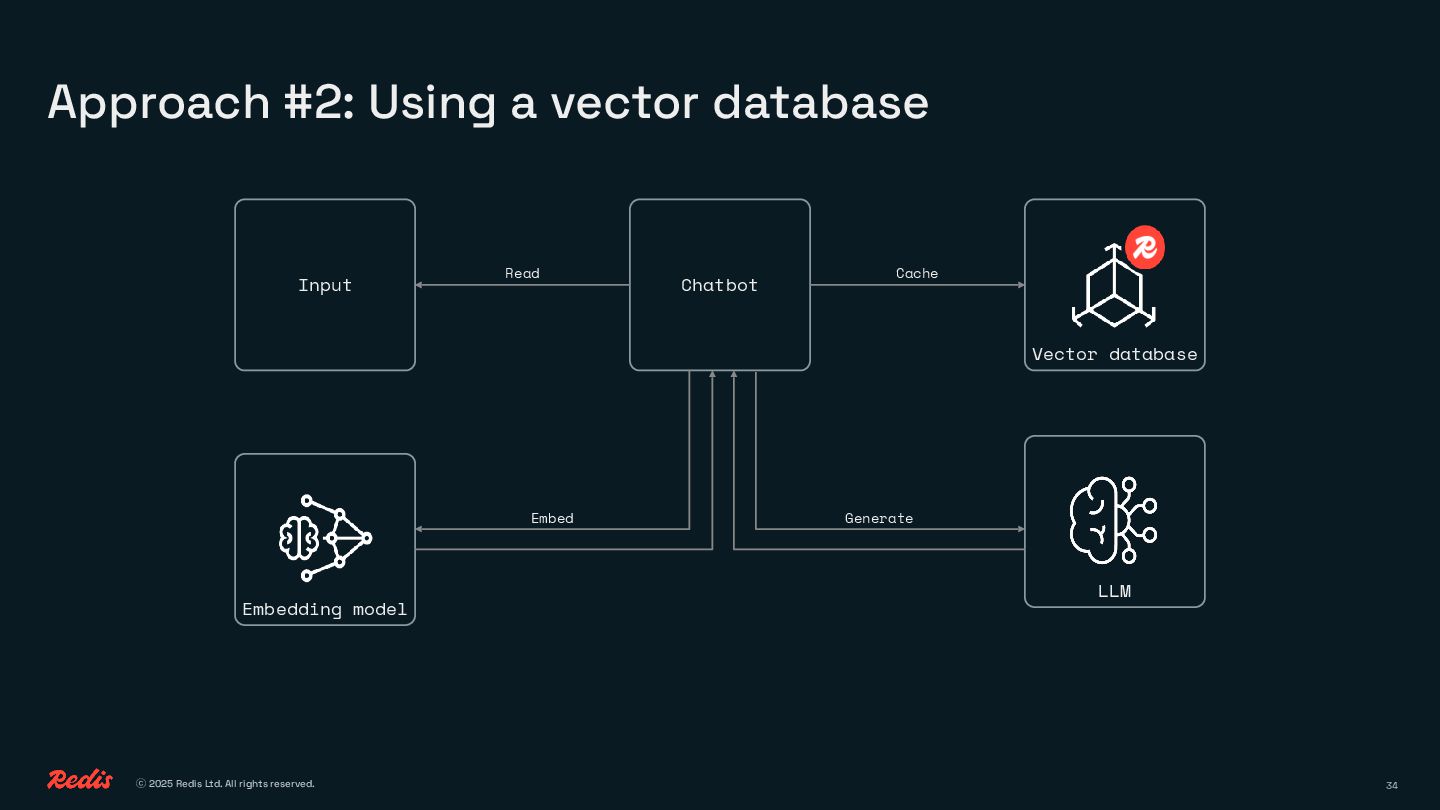
• How semantic caching helps you reuse answers and cut costs
You’ll see how to replace brute-force prompting with clean, efficient logic using embeddings, similarity, and lightweight decision-making. No complex ML pipelines, no GPU bills, just smart patterns that save time, money, and energy.
This session will help you do it better with fewer calls, less waste, and a lot more control.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
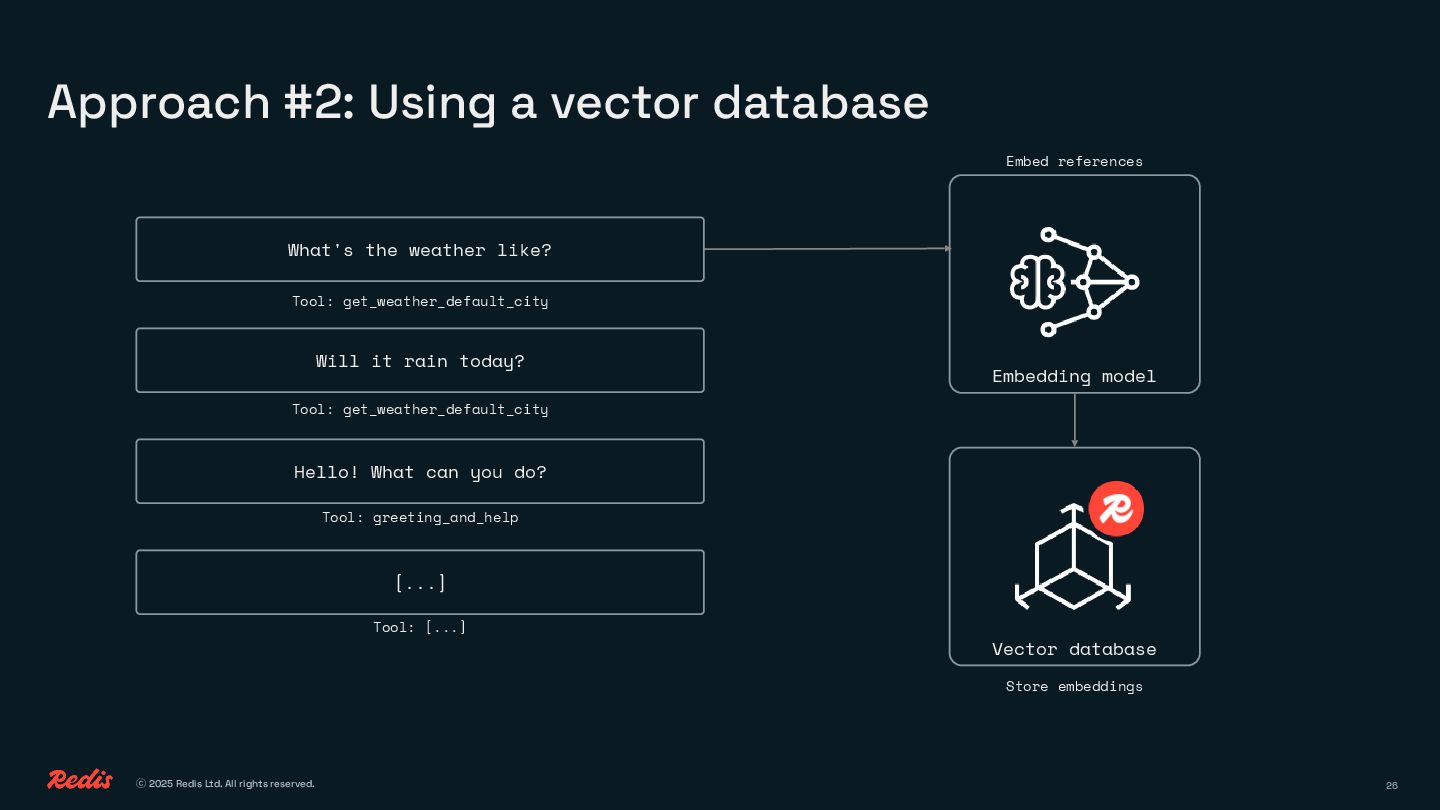{kind=link}
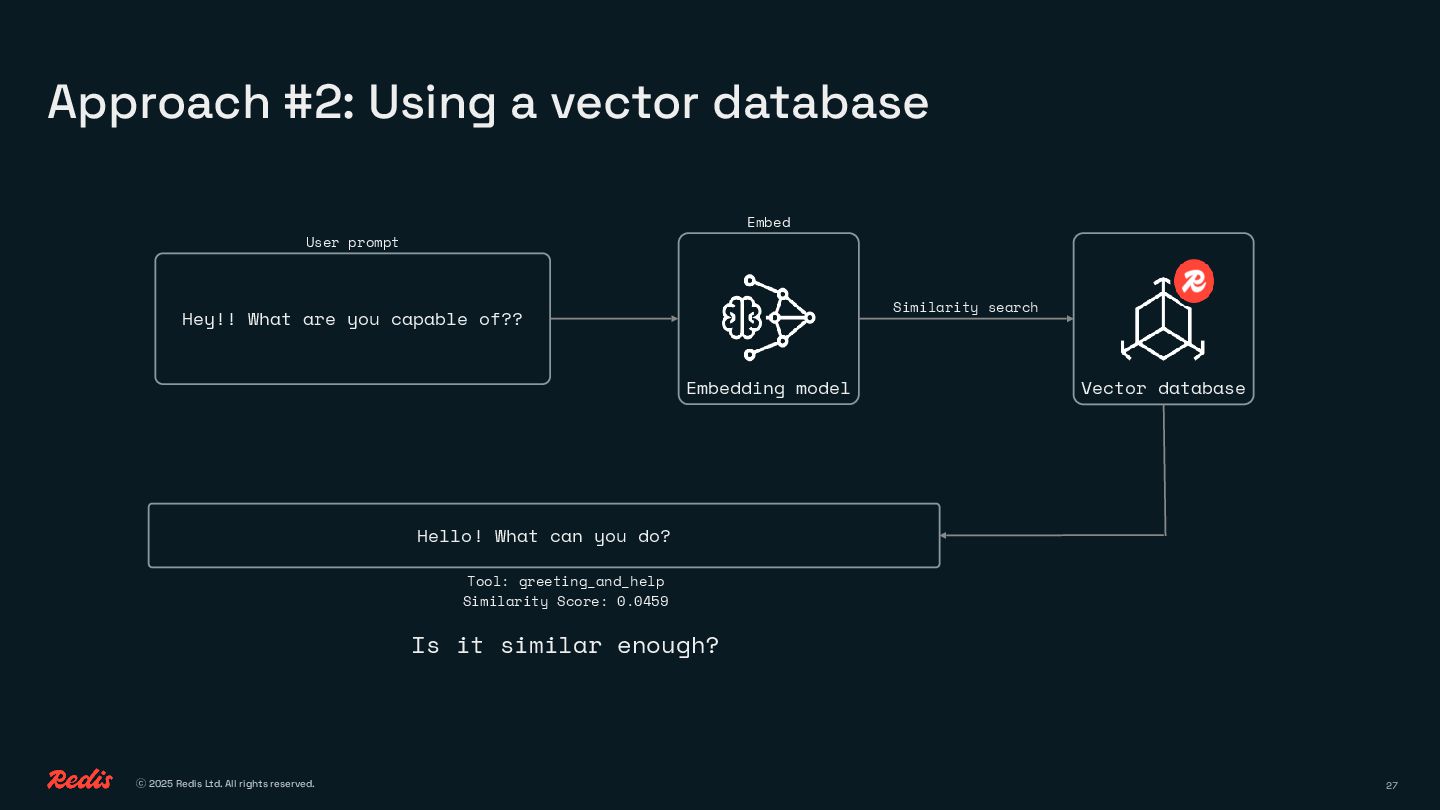{kind=link}
{kind=link}
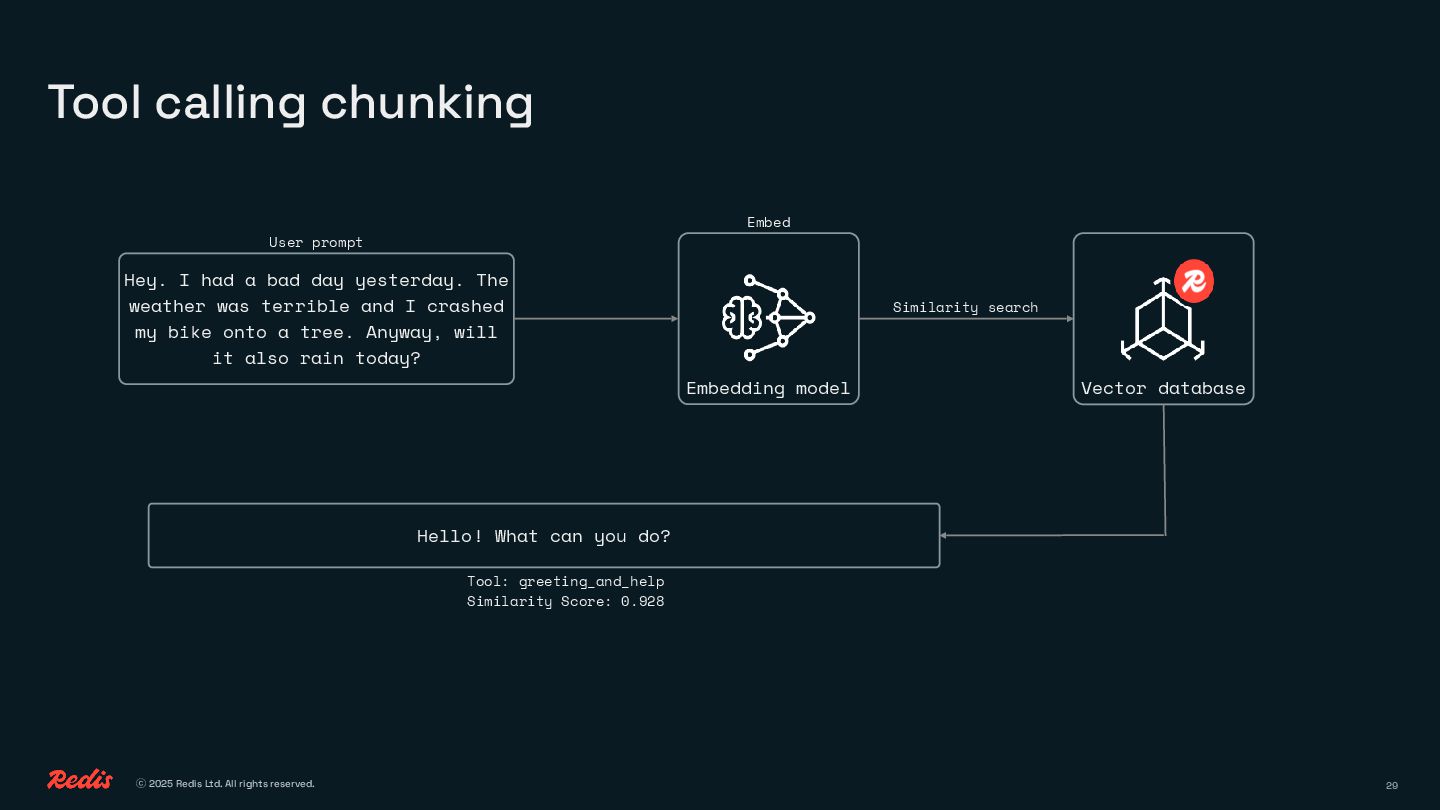{kind=link}
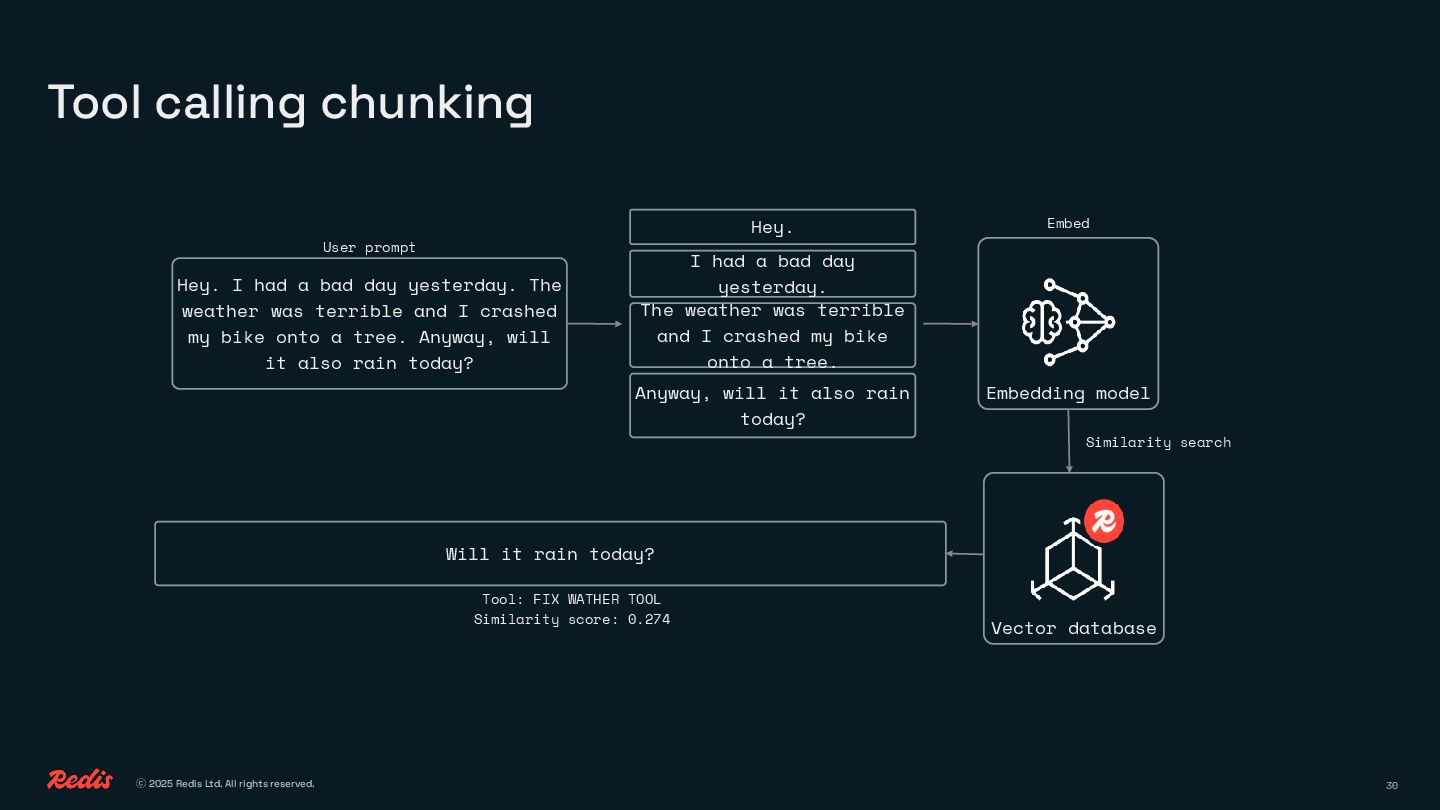{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
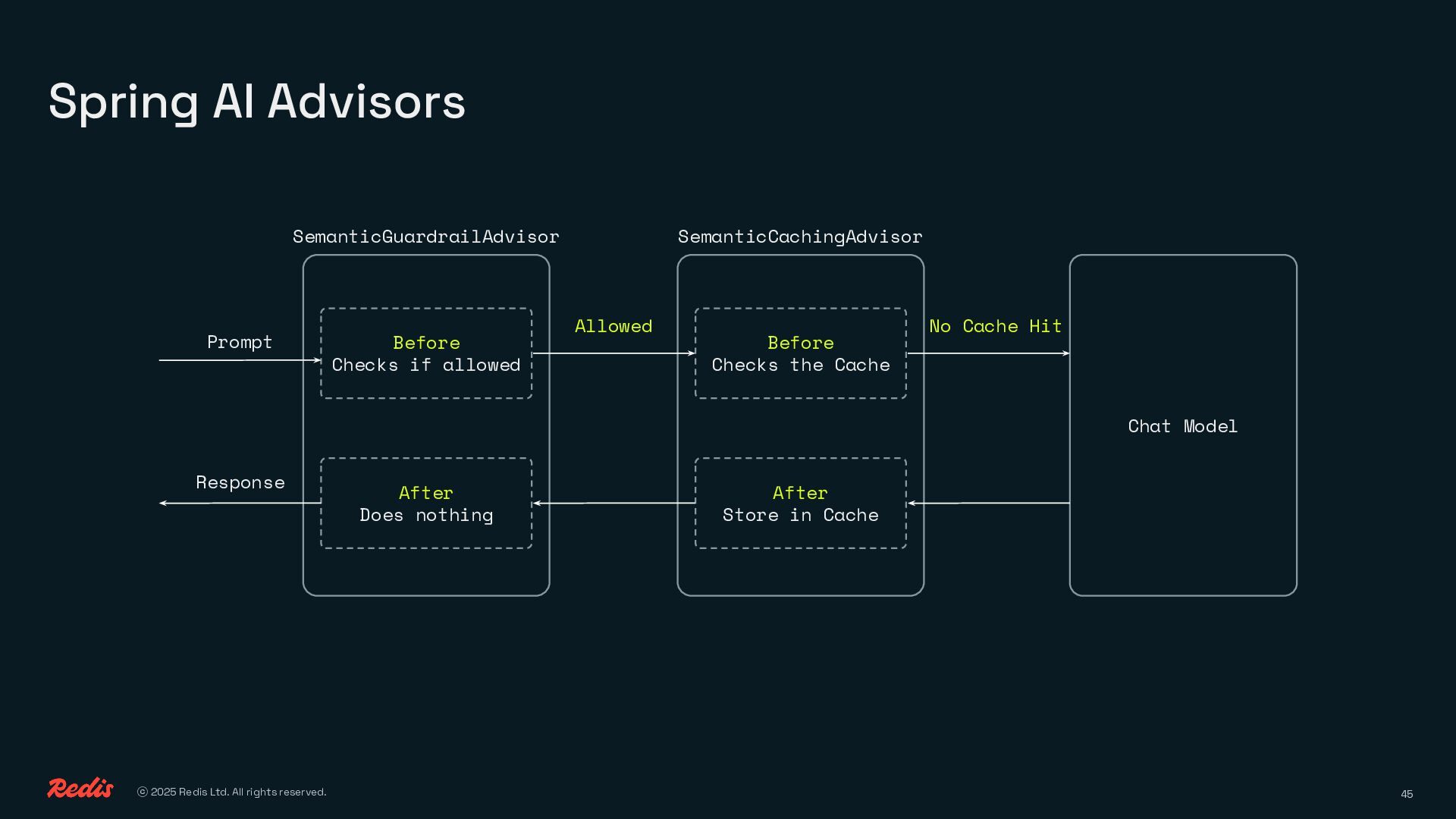{kind=link}
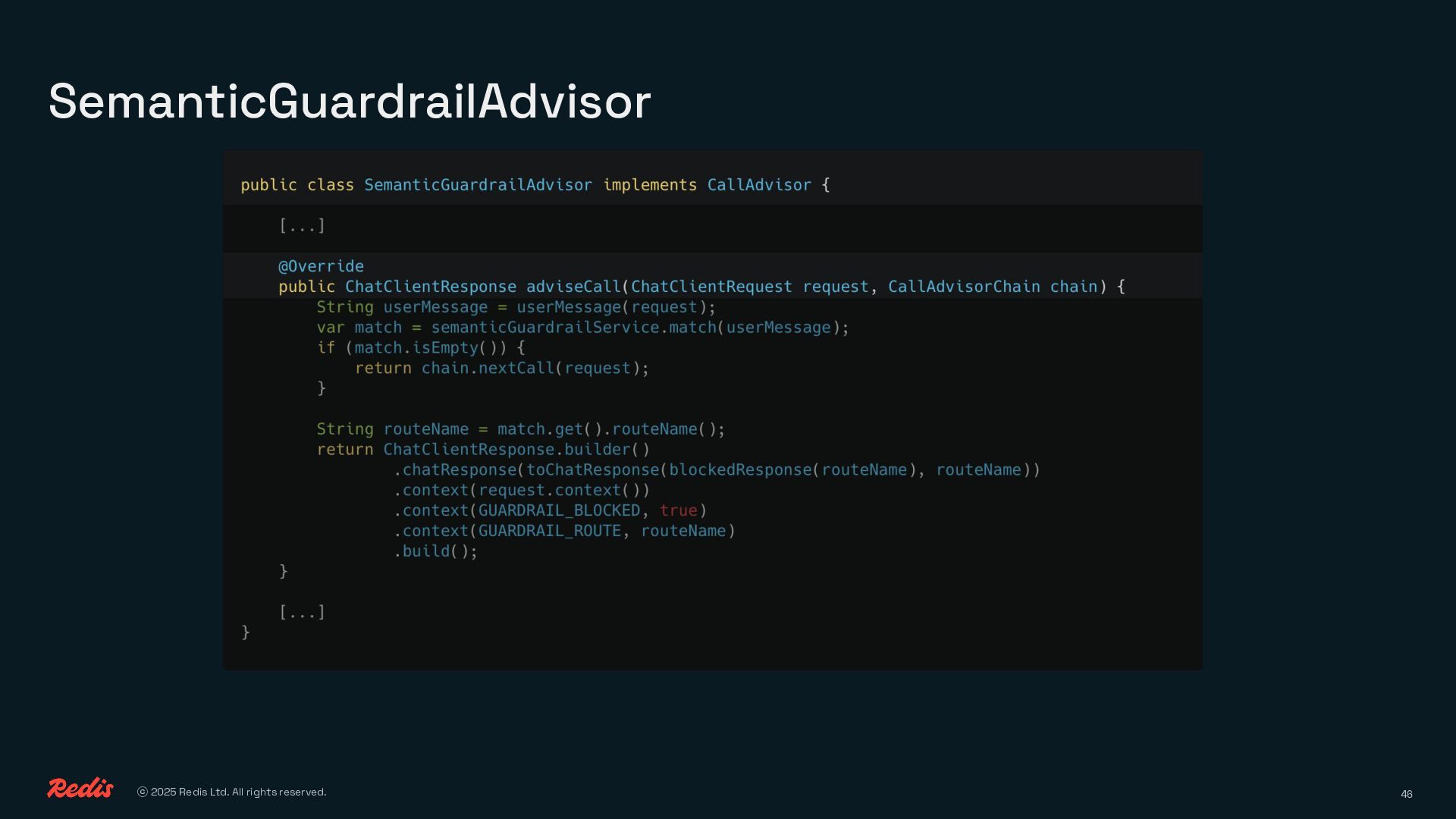{kind=link}
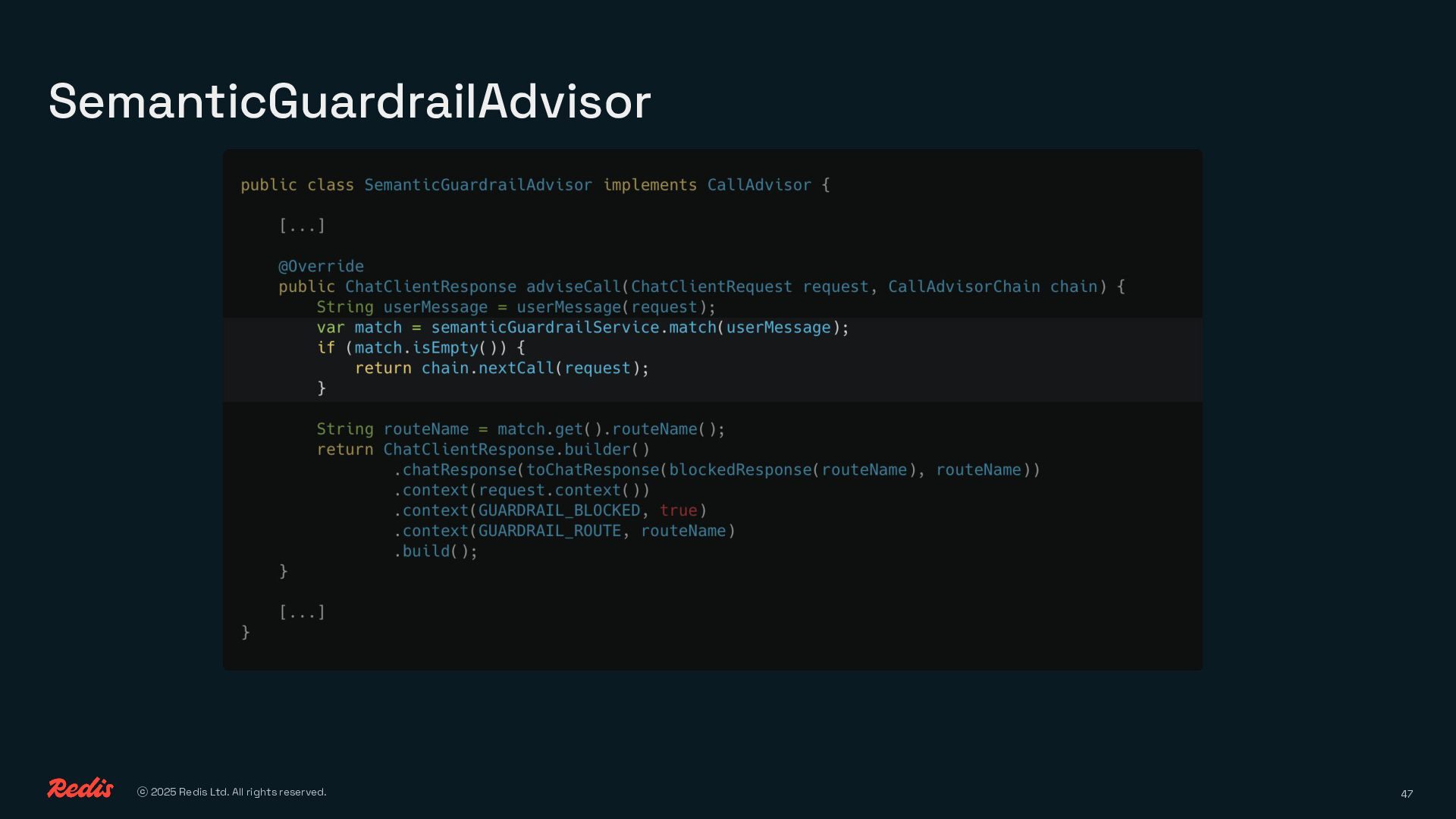{kind=link}
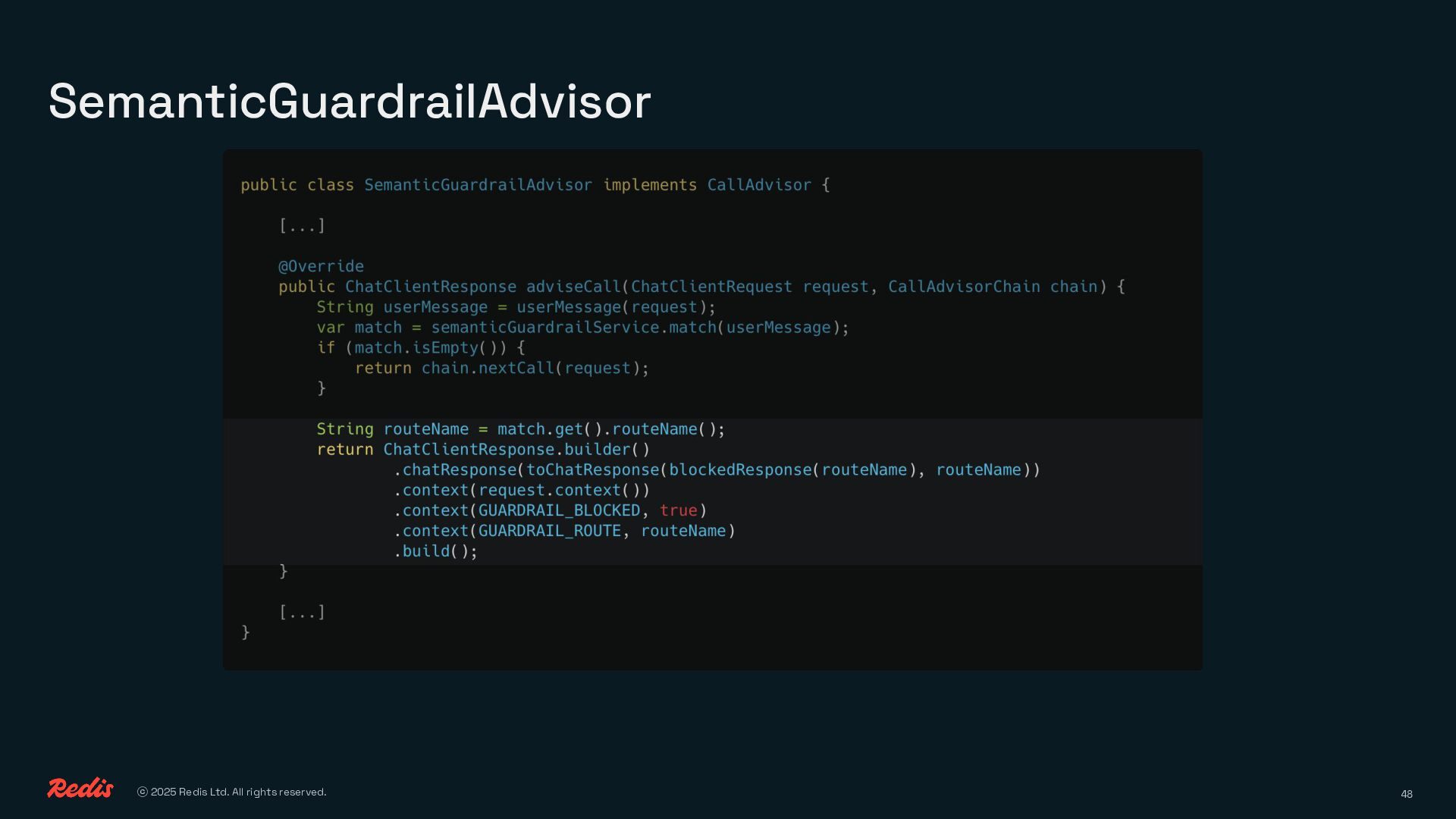{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}