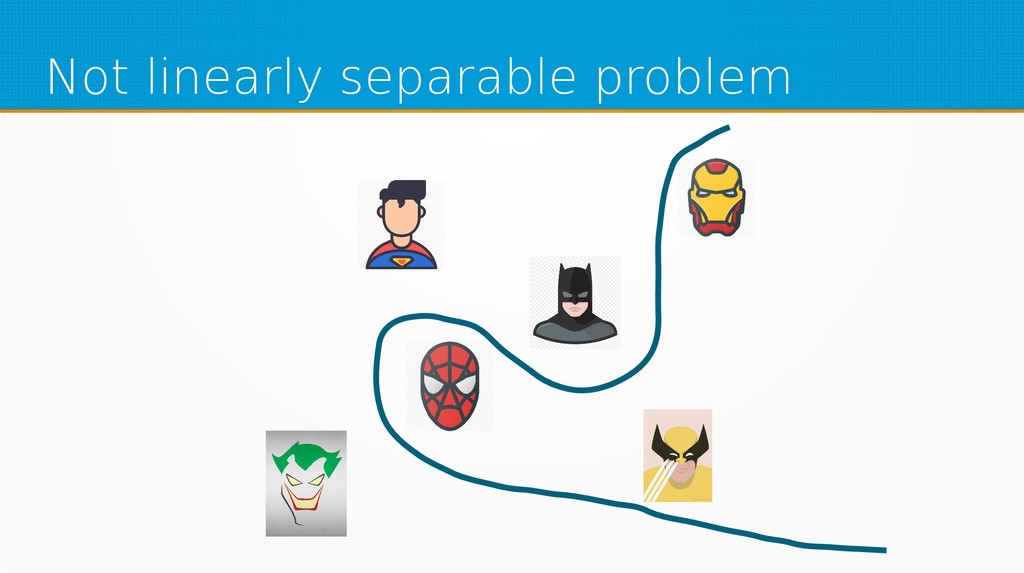
During this presentation, we will answer how much you’ll need to invest in a superhero costume to be as popular as Superman. We will generate a unique logo which will stand against the ever popular Batman and create new superhero teams. We shall achieve it using linear regression and neural networks.
Machine learning is one of the hottest buzzwords in technology today as well as one of the most innovative fields in computer science – yet people use libraries as black boxes without basic knowledge of the field. In this session, we will strip them to bare math, so next time you use a machine learning library, you’ll have a deeper understanding of what lies underneath.
During this session, we will first provide a short history of machine learning and an overview of two basic teaching techniques: supervised and unsupervised learning.
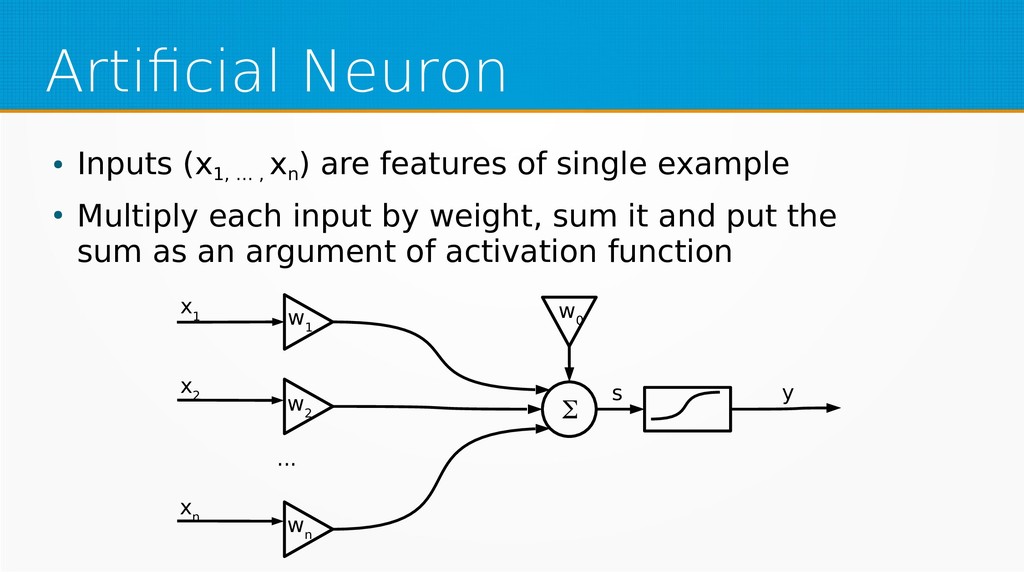
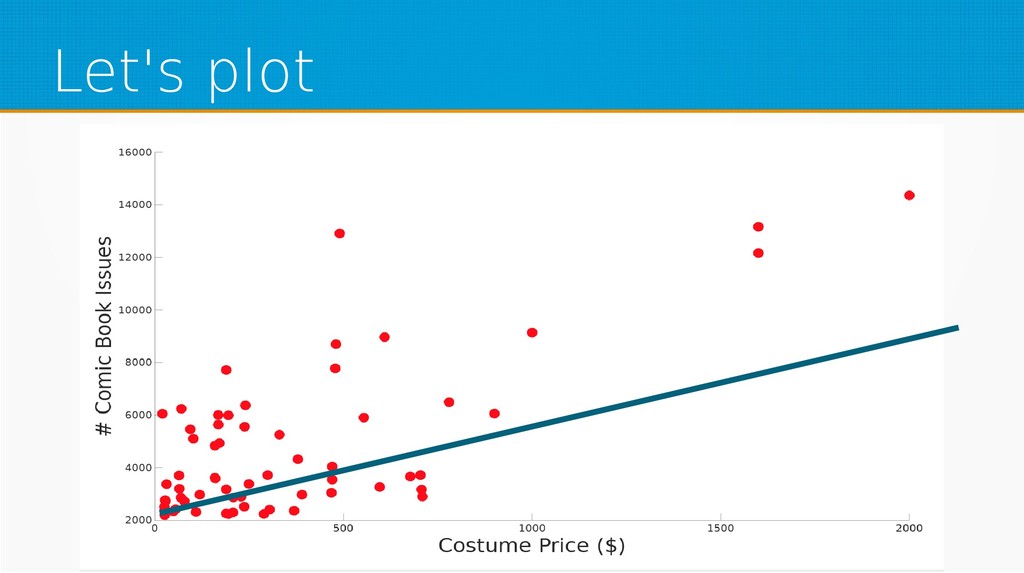
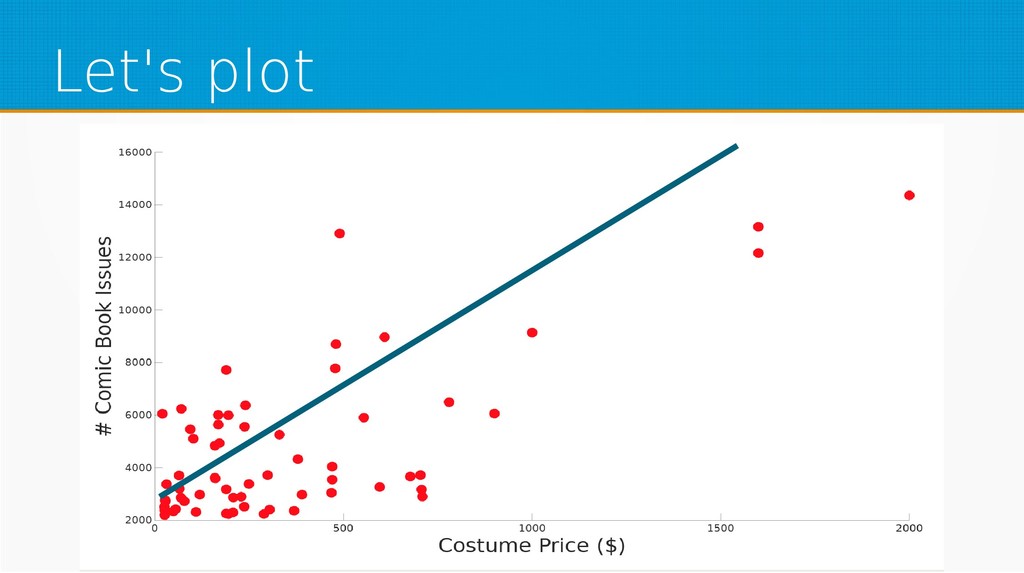
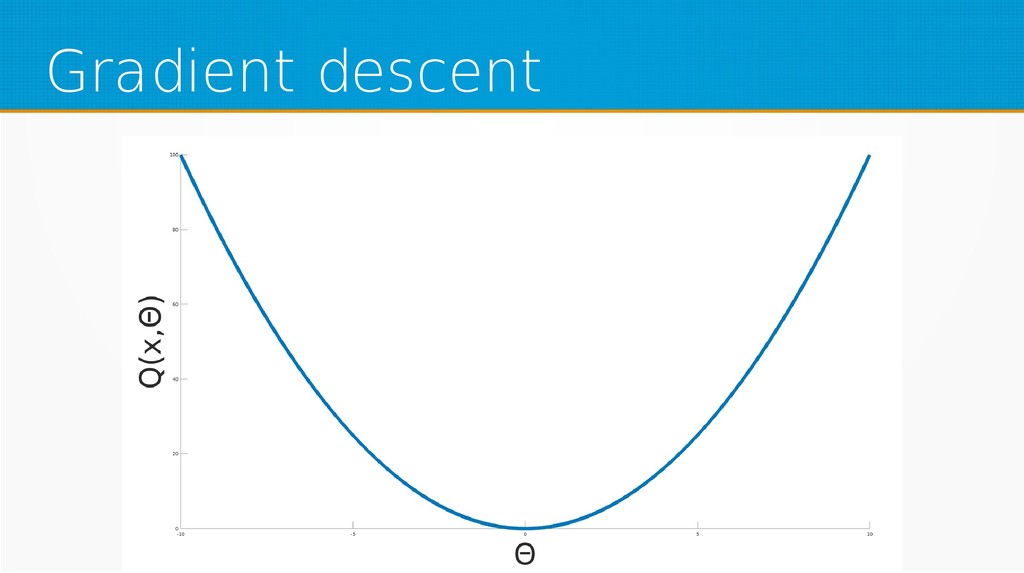
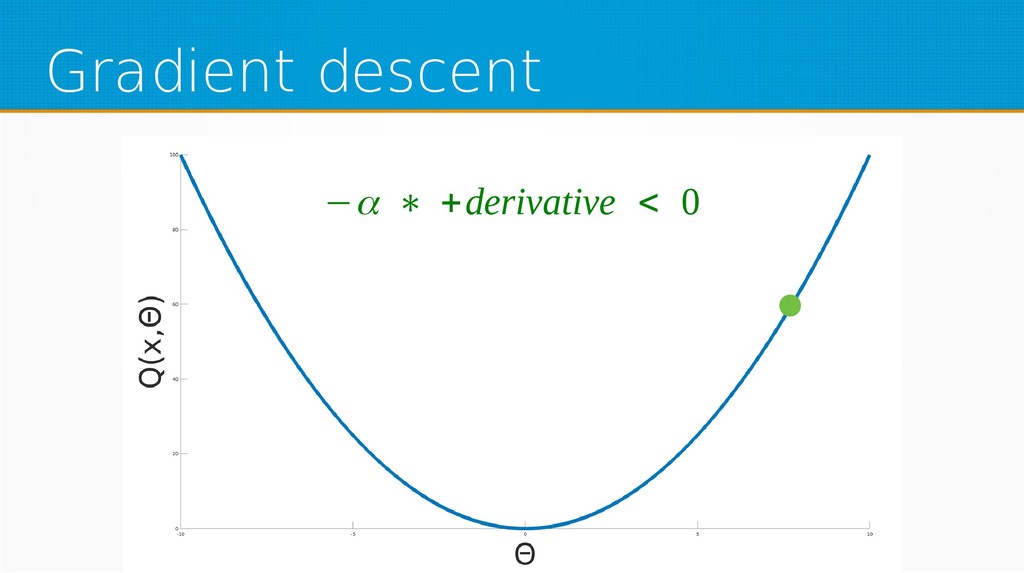
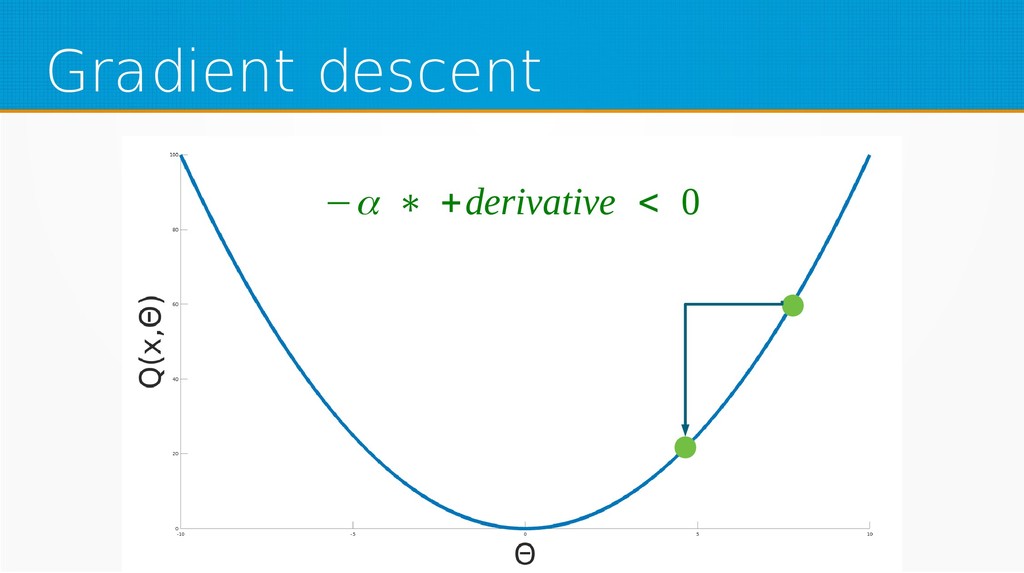
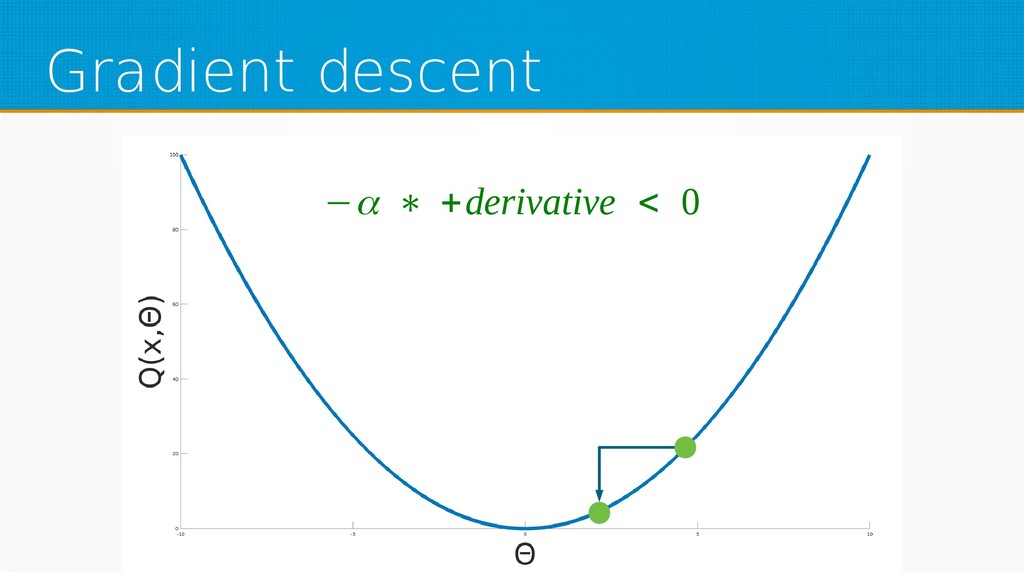
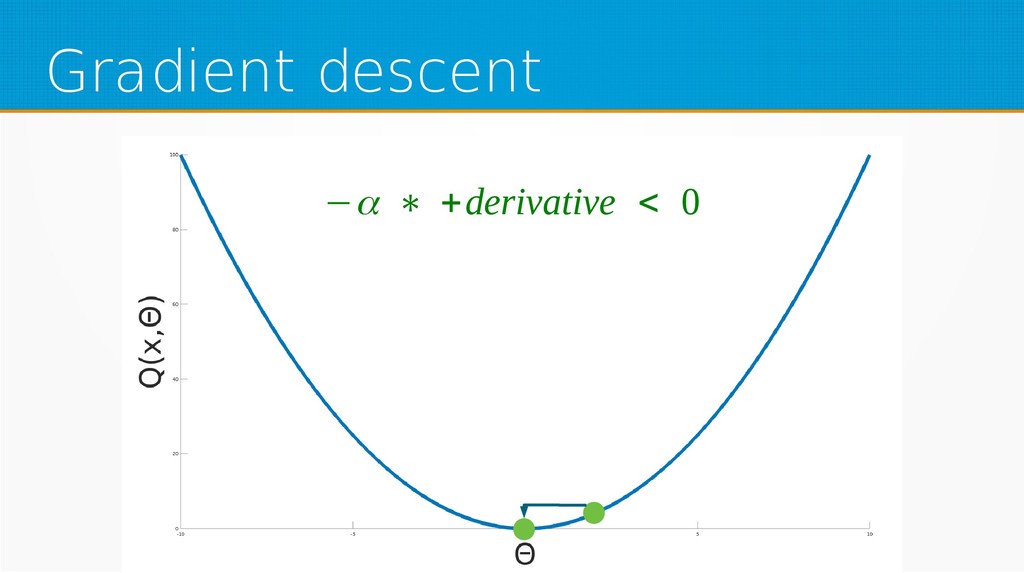
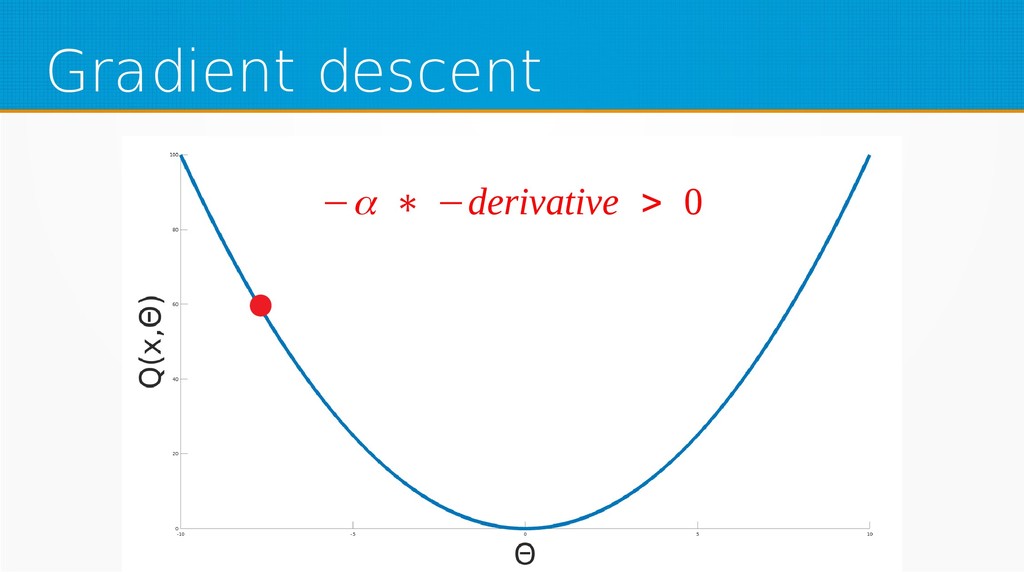
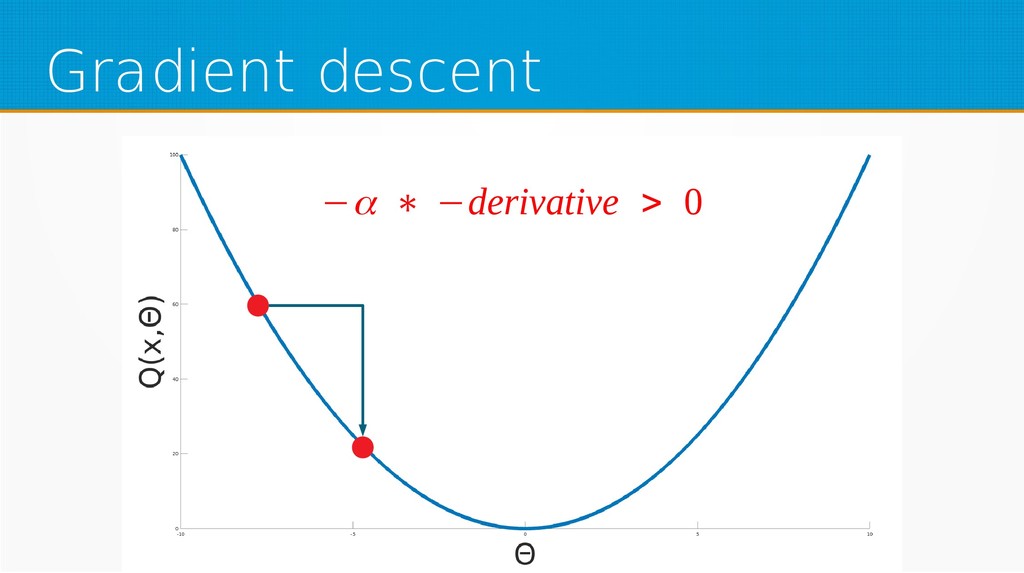
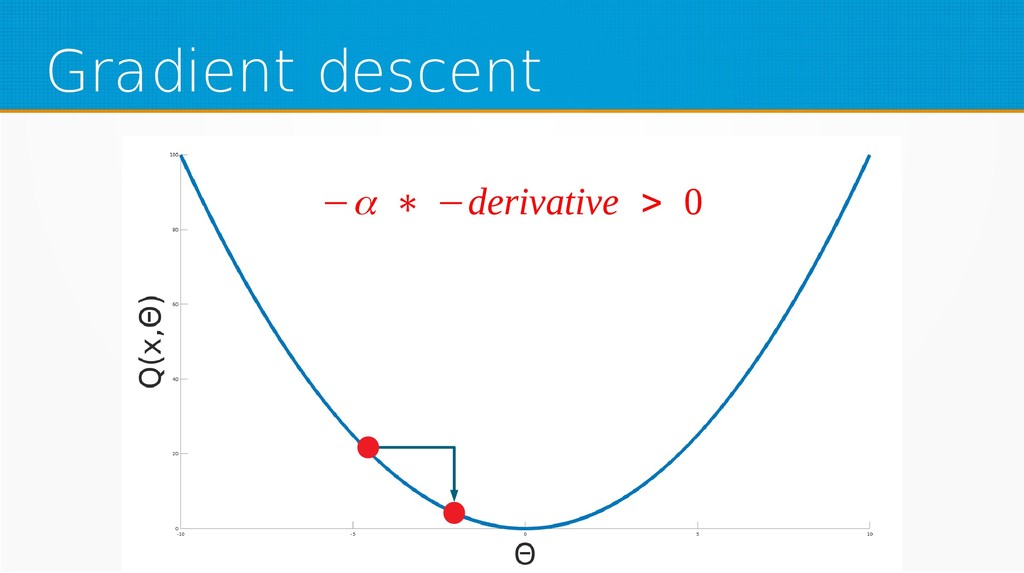
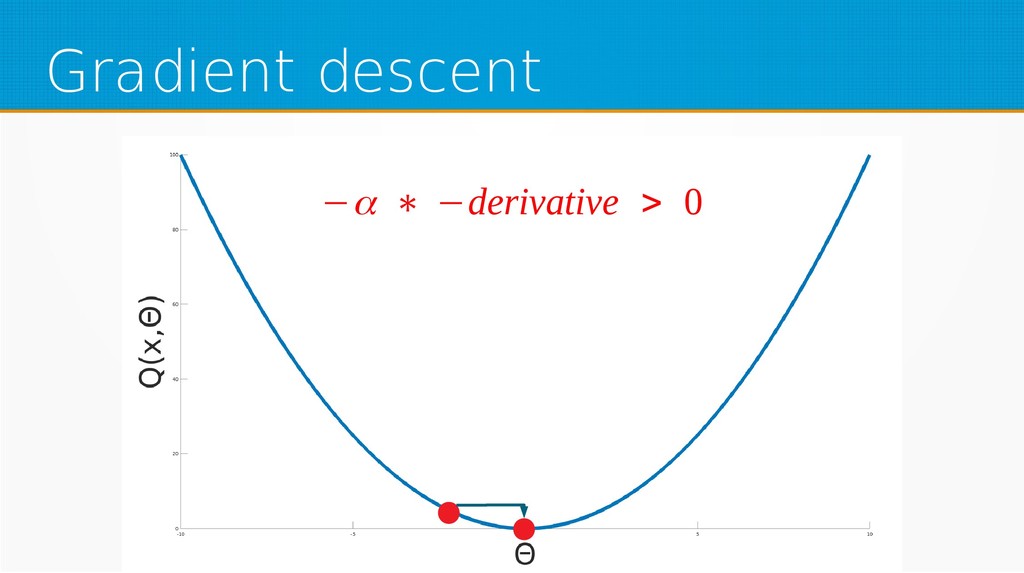
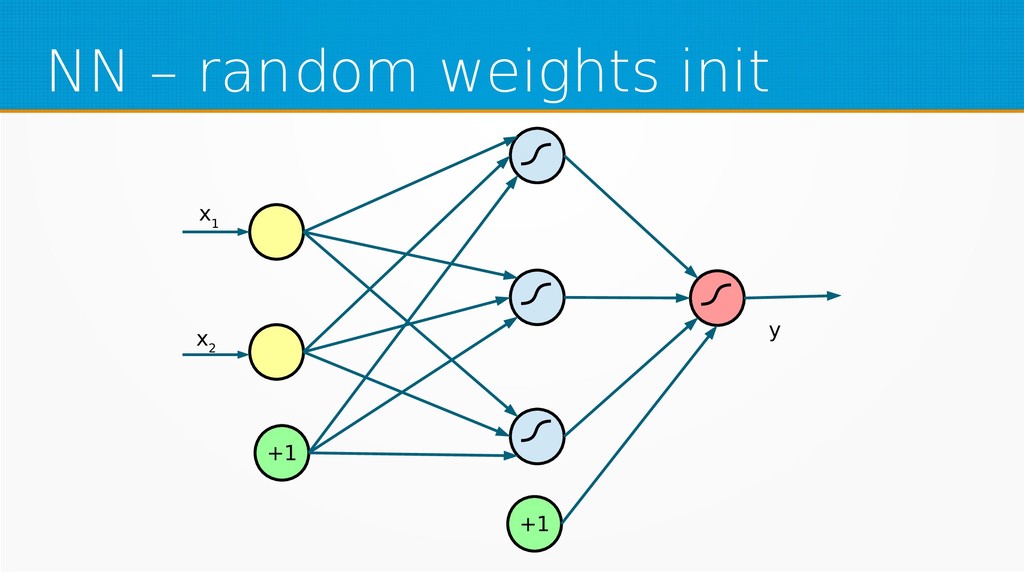
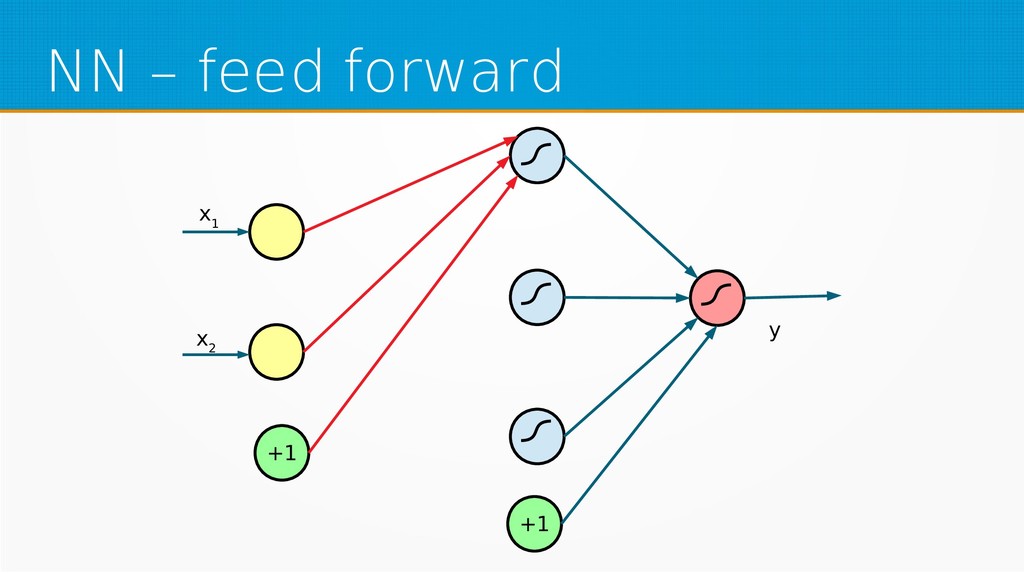
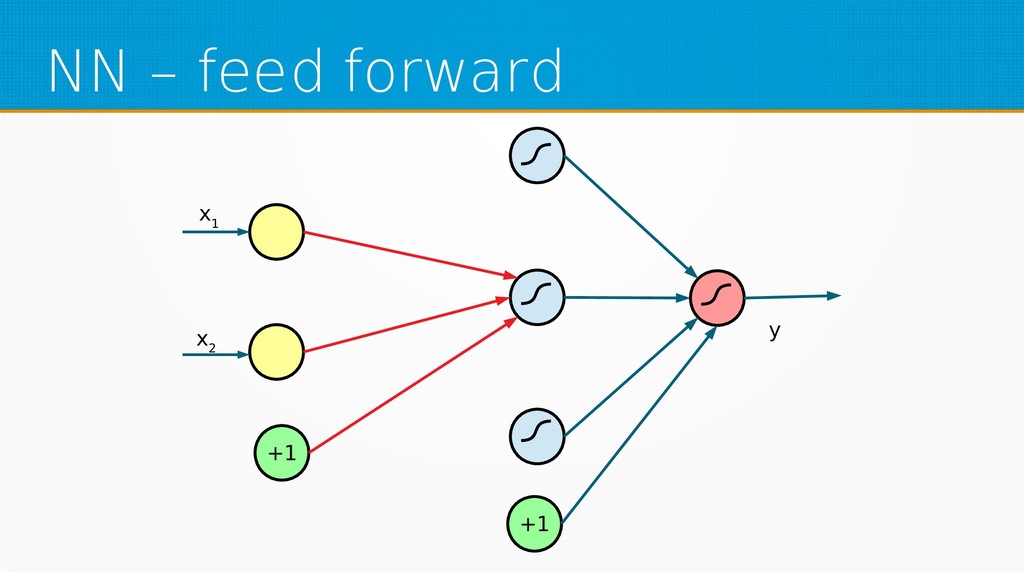
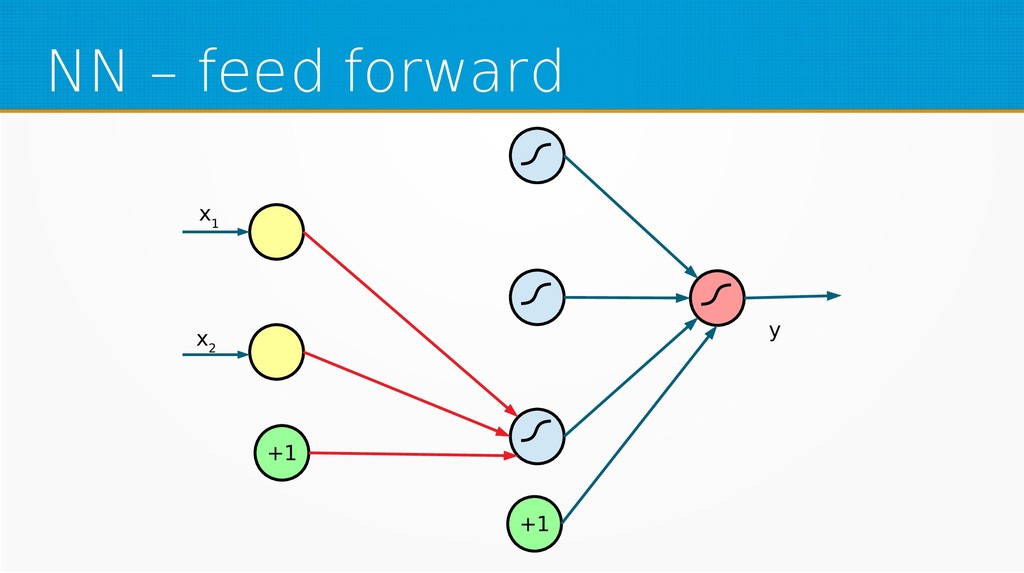
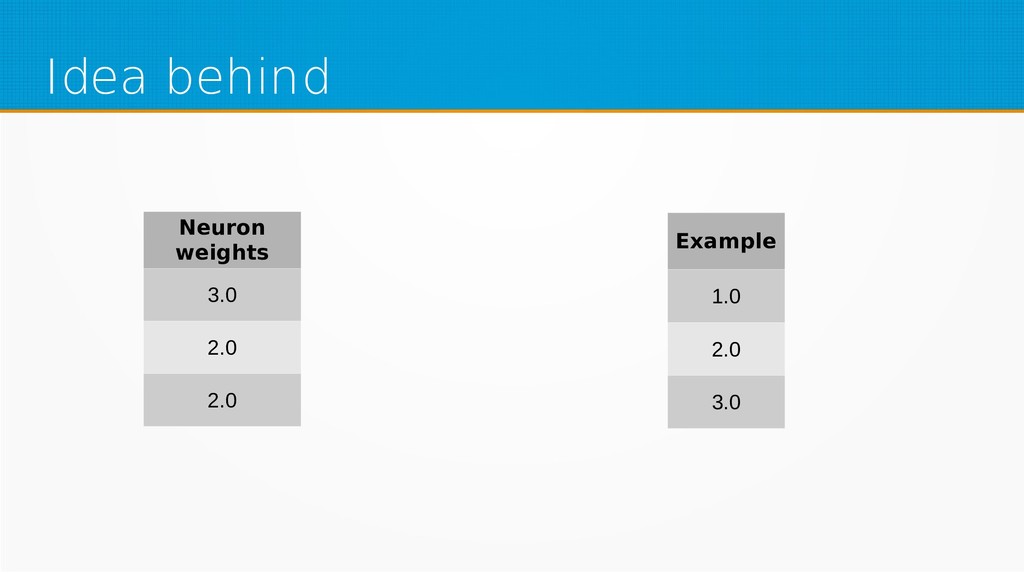
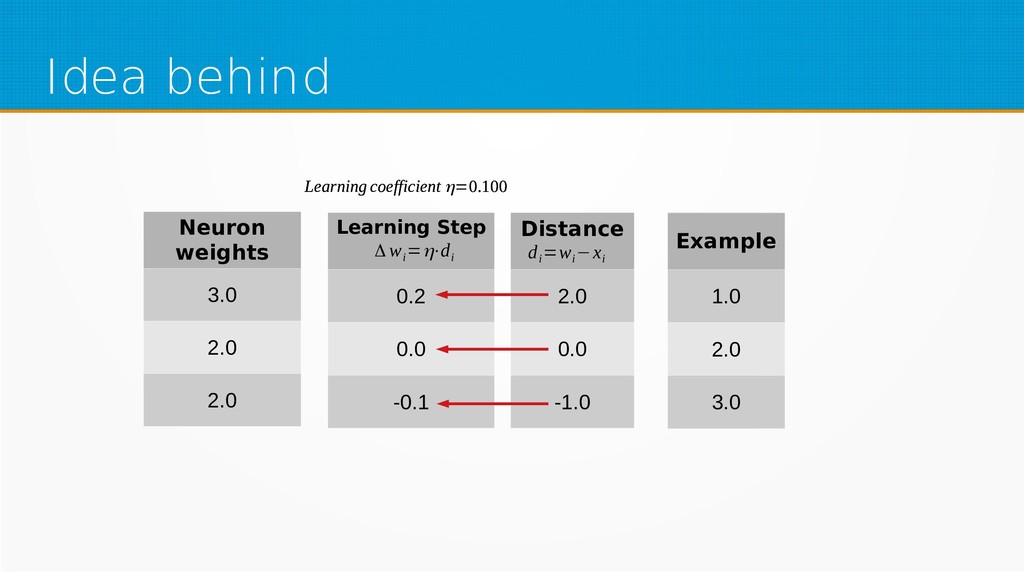
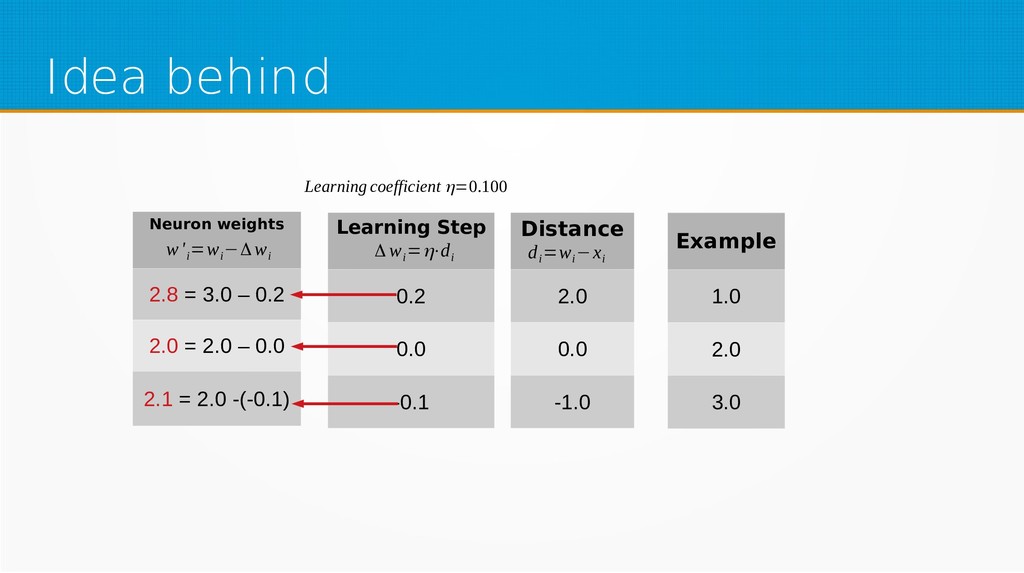
We will start by defining what machine learning is and equip you with an intuition of how it works. We will then explain the gradient descent algorithm with the use of simple linear regression to give you an even deeper understanding of this learning method. Then we will project it to supervised neural networks training.
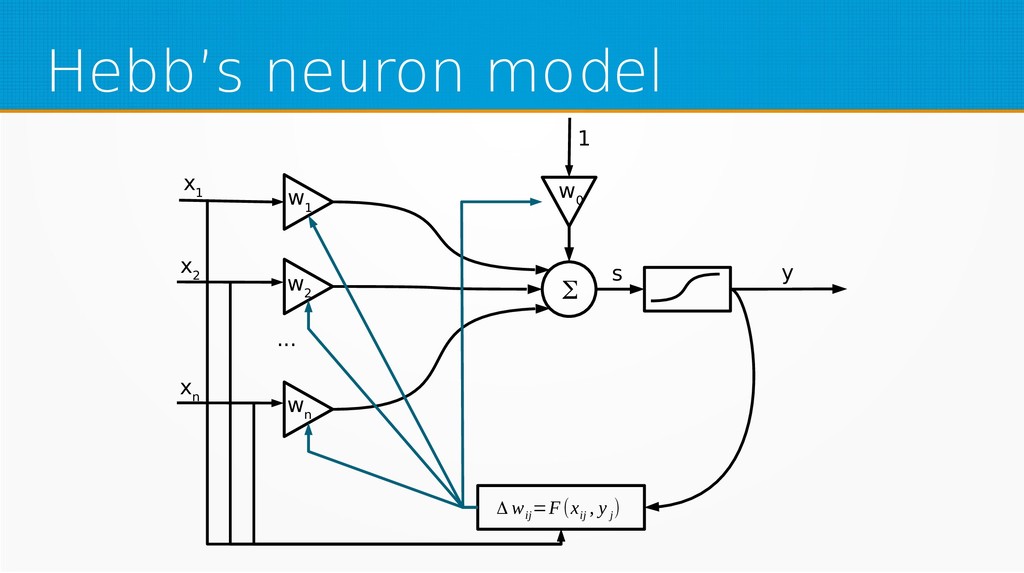
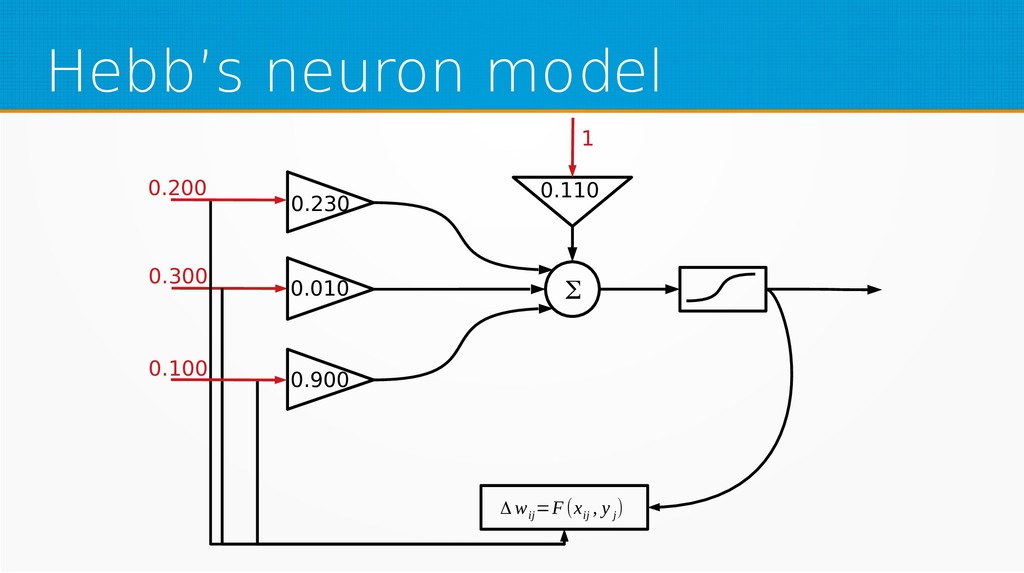
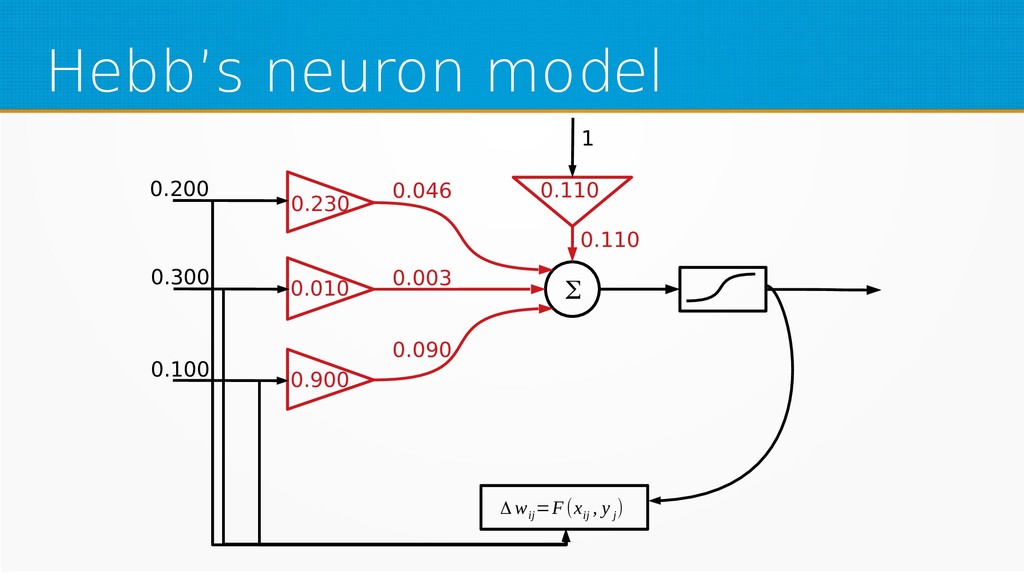
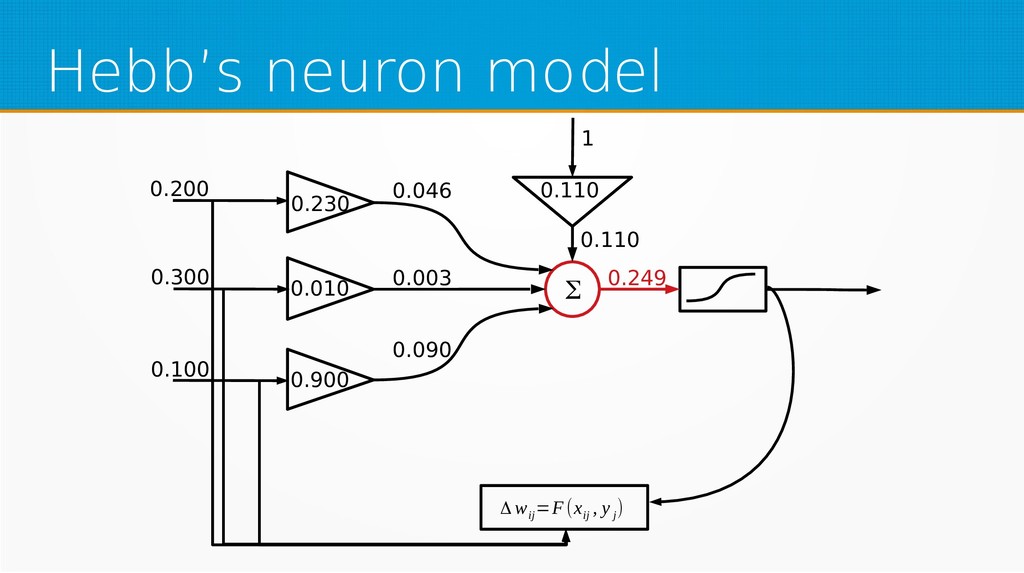
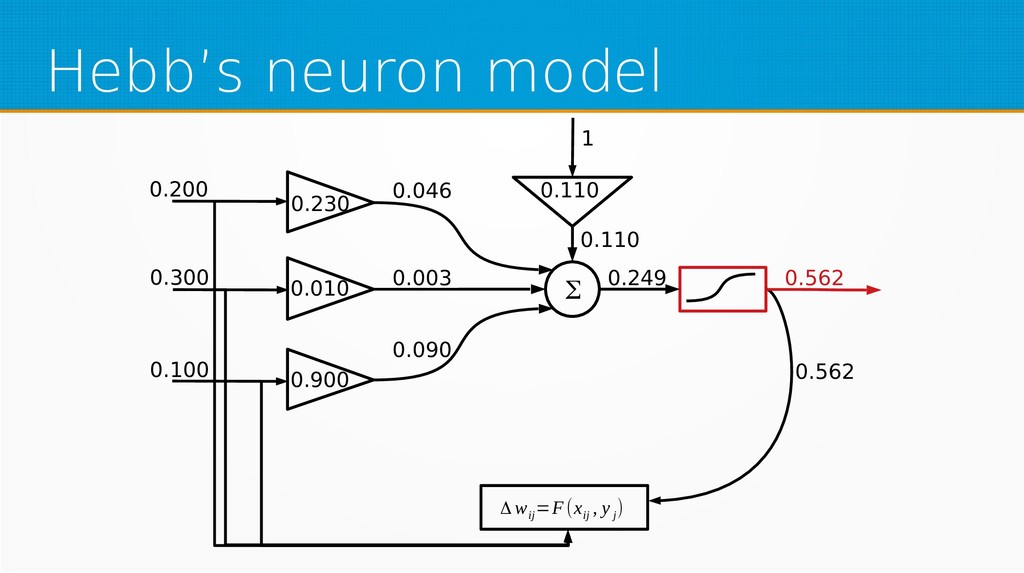
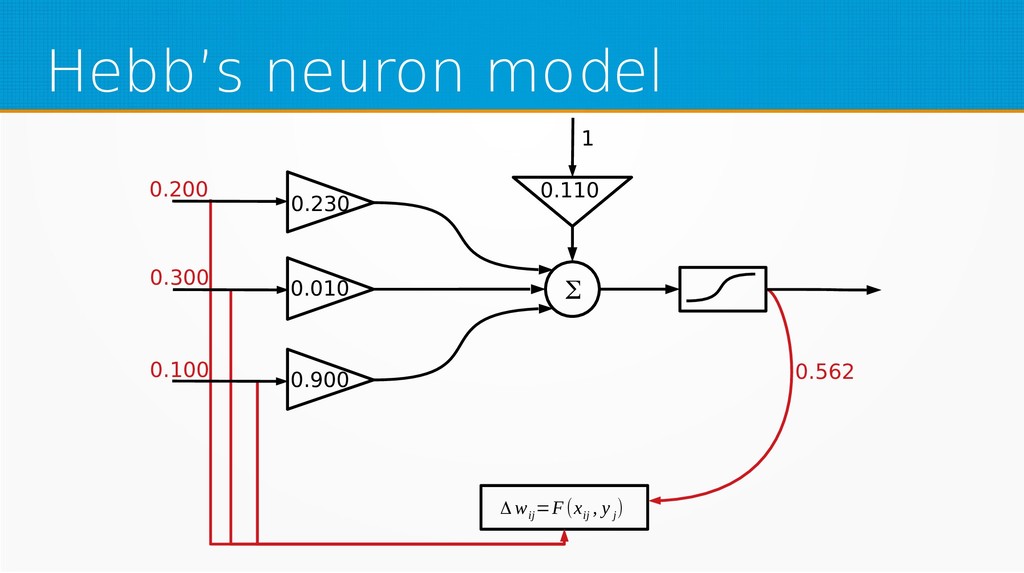
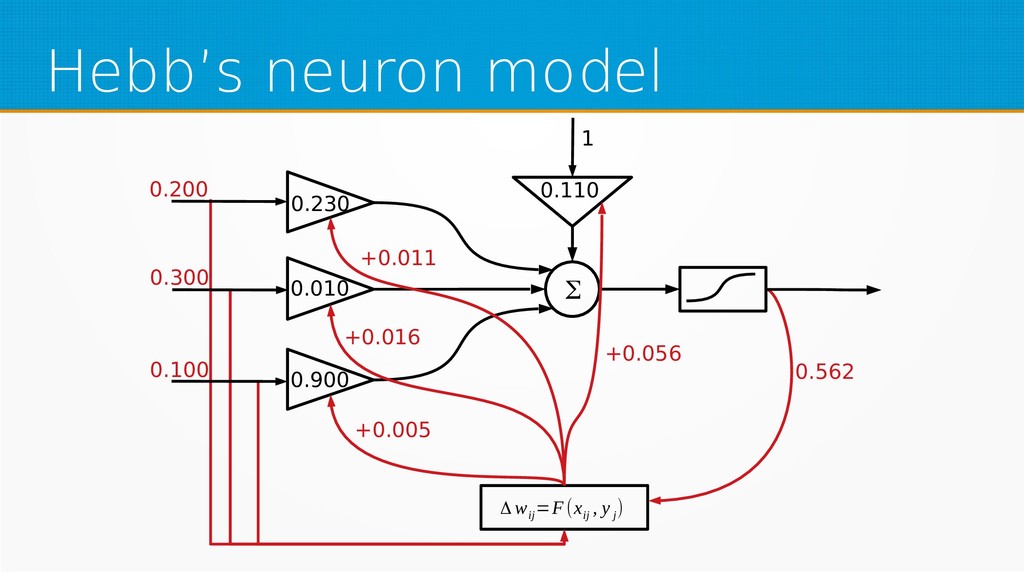
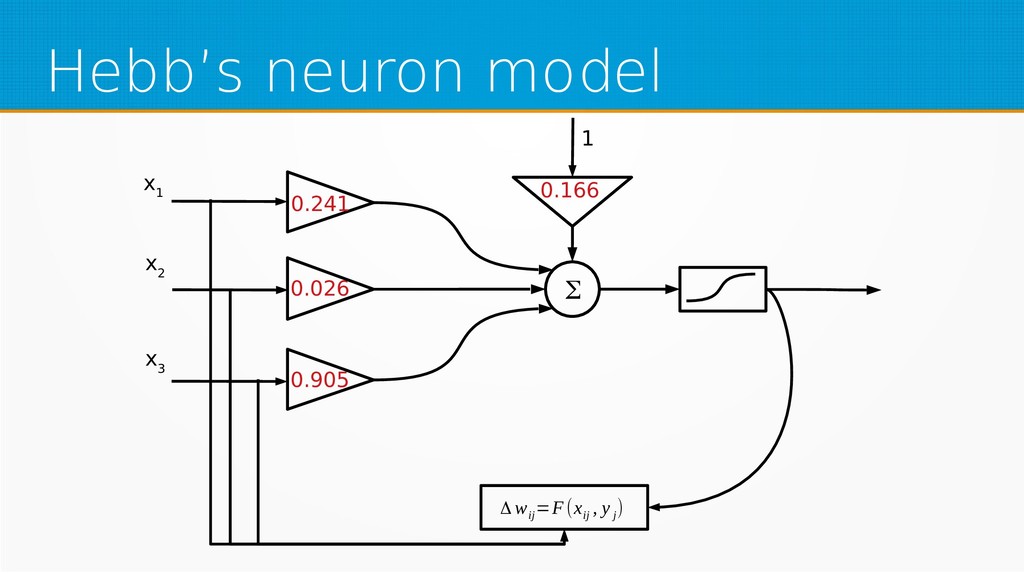
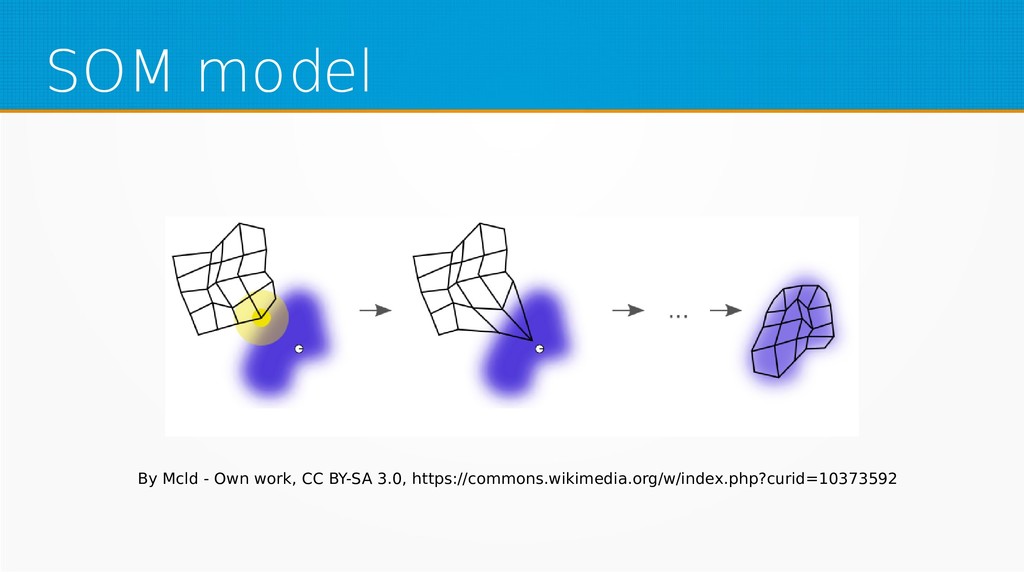
Within unsupervised learning, you will become familiar with Hebb’s learning and learning with concurrency (winner takes all and winner takes most algorithms). We will use Octave for examples in this session; however, you can use your favourite technology to implement presented ideas.
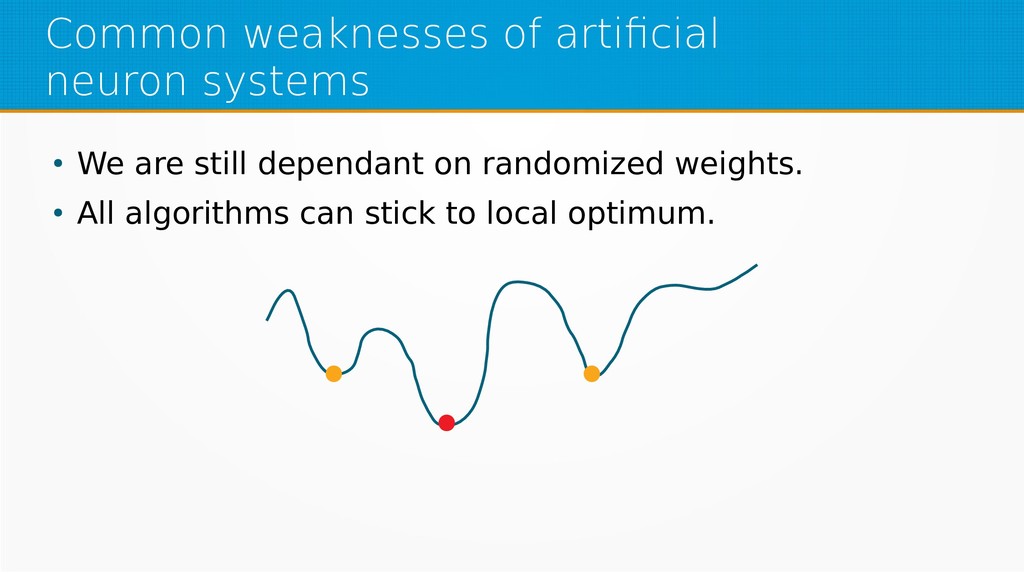
Our aim is to show the mathematical basics of neural networks for those who want to start using machine learning in their day-to-day work or use it already but find it difficult to understand the underlying processes. After viewing our presentation, you should find it easier to select parameters for your networks and feel more confident in your selection of network type, as well as be encouraged to dive into more complex and powerful deep learning methods.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}