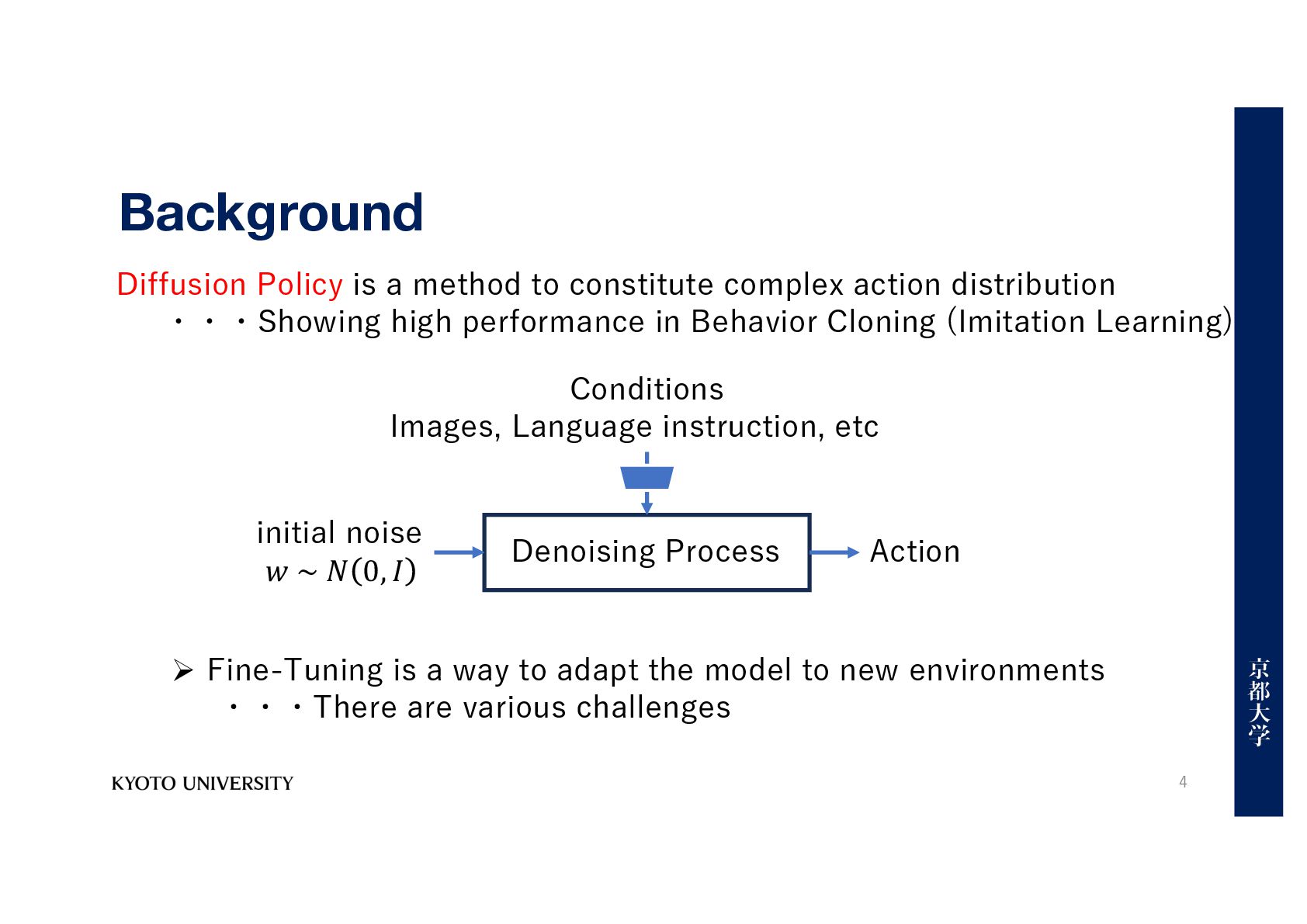
action distribution ・・・Showing high performance in Behavior Cloning (Imitation Learning) initial noise 𝑤 ~ 𝑁 0, 𝐼 Denoising Process Action Conditions Images, Language instruction, etc Ø Fine-Tuning is a way to adapt the model to new environments ・・・There are various challenges
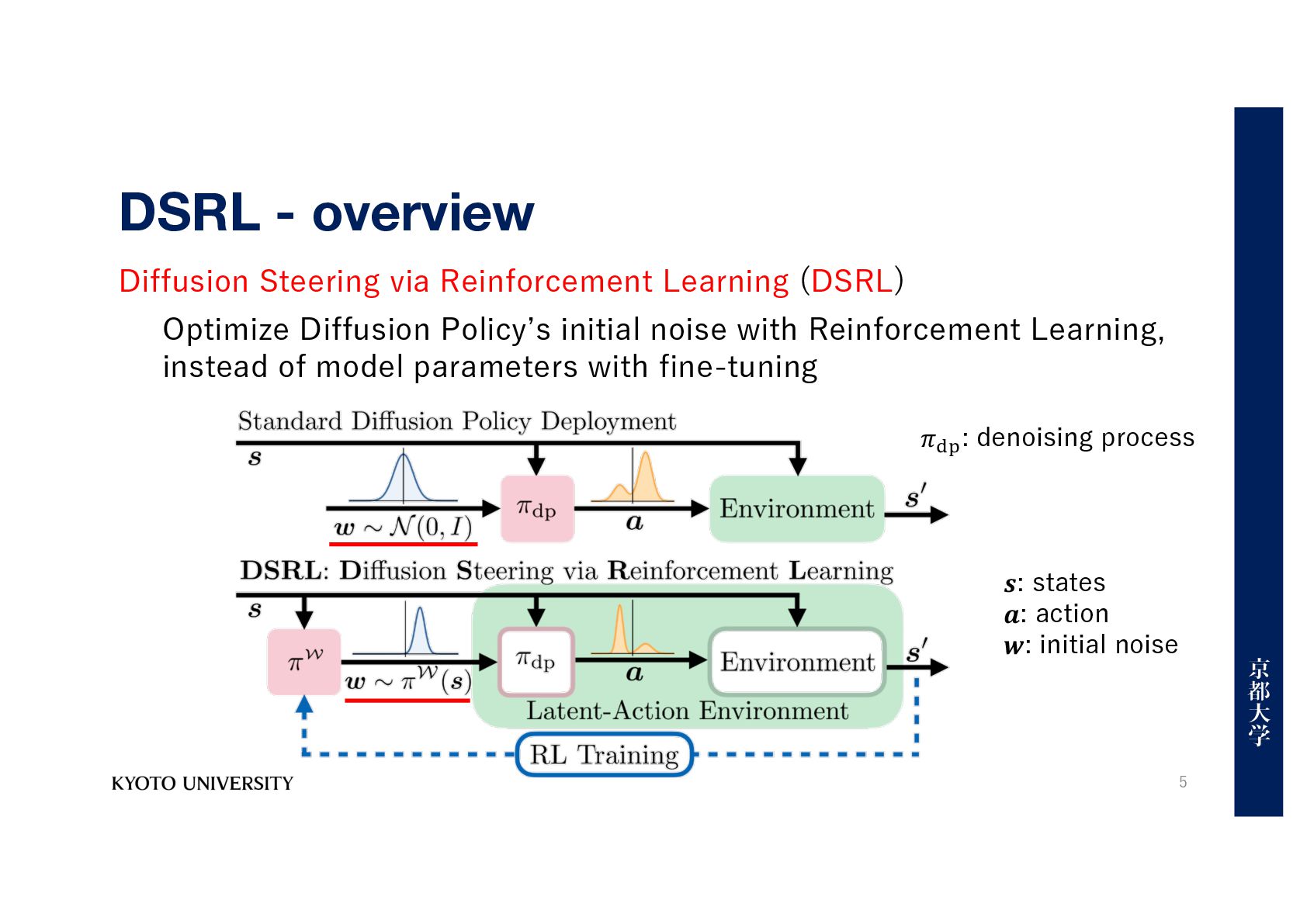
Diffusion Policyʼs initial noise with Reinforcement Learning, instead of model parameters with fine-tuning 𝒔: states 𝒂: action 𝒘: initial noise 𝜋!" : denoising process 5
is considered as Action → We can consider the policy of 𝑤 → Optimizing this policy may be effective for generating Ø Optimize the policy with DDPG method actor: critic: 𝑤 ~ 𝜋$ 𝑠 𝑄$ 𝑠, 𝑤 But, datasets are consisted with 𝑠, 𝑎, 𝑟, 𝑠# in Offline Training = Data in latent-action MDP is not usable adopt Additional Critic to bridge real-env and laten-action env 𝐴-critic: 𝑄% 𝑠, 𝑎 7
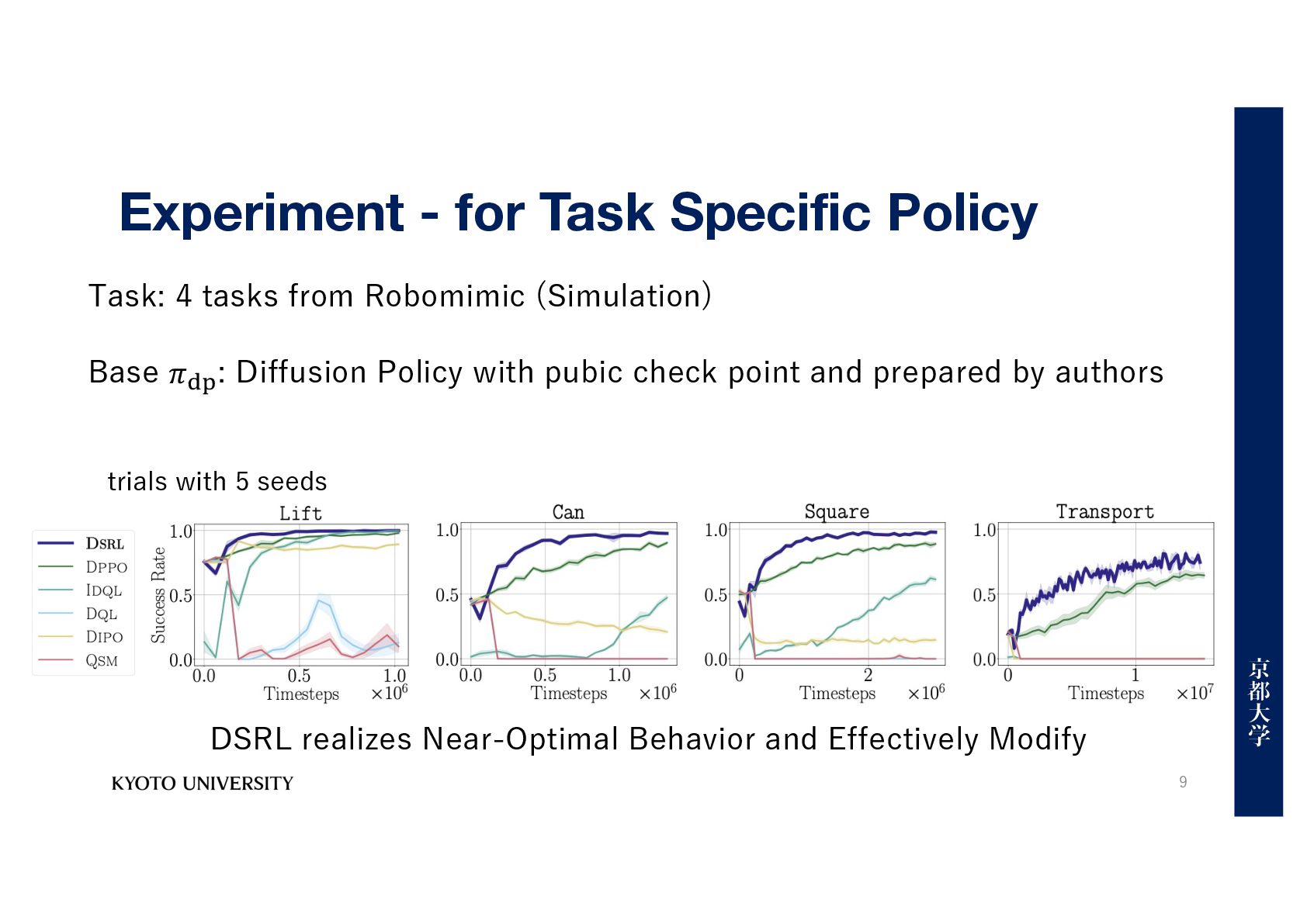
seeds DSRL realizes Near-Optimal Behavior and Effectively Modify Task: 4 tasks from Robomimic (Simulation) Base 𝜋!" : Diffusion Policy with pubic check point and prepared by authors
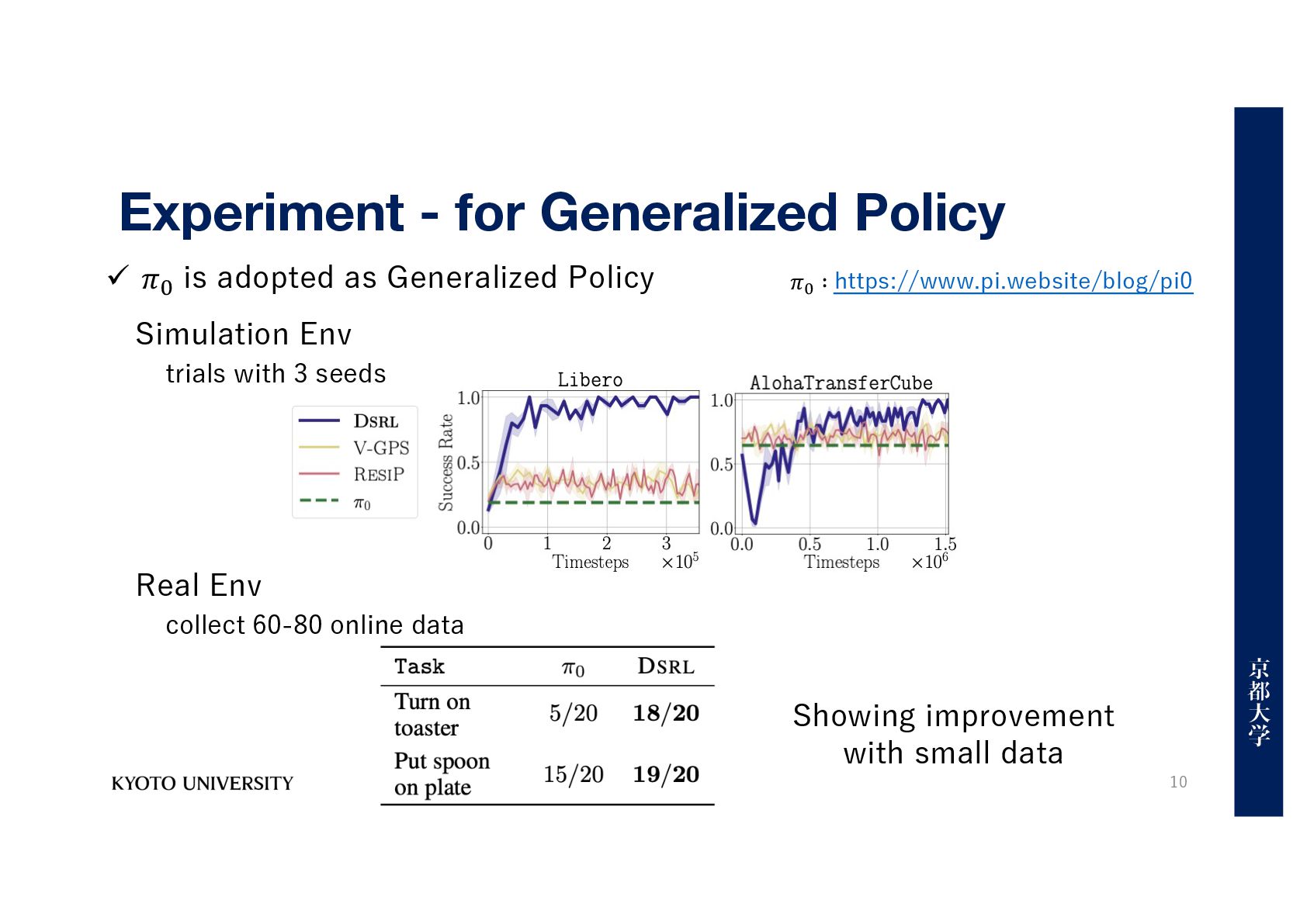
Simulation Env Real Env trials with 3 seeds ü 𝜋& is adopted as Generalized Policy 𝜋! ∶ https://www.pi.website/blog/pi0 Showing improvement with small data
performance is achieved in various experiments by optimizing initial noise of Diffusion Policy ü Comparing with Fine-Tuning, much smaller dataset is enough to improve Limitations • Exploration capabilities are determined by 𝜋!" • You have to make reward signal in Online Training
value with NN 𝑄 𝑠, 𝑎 ≈ 𝑄) 𝑠, 𝑎 object function 𝔼 #,%,&,#! ~ℬ 𝑟 + 𝛾 max %! 𝑄) 𝑠*, 𝑎* − 𝑄) 𝑠, 𝑎 + DDPG Approximate value in case of the continuous action If 𝑎 is continuous, this is difficult Actor: 𝜇* 𝑠 Critic: 𝑄) 𝑠, 𝑎 object function 𝔼 #,%,&,#! ~ℬ 𝑟 + 𝛾𝑄) 𝑠*, 𝜇, 𝑠′ − 𝑄) 𝑠, 𝑎 + 𝔼#~ℬ −𝑄) 𝑠, 𝜇, 𝑠 for 𝜙 for 𝜃
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}