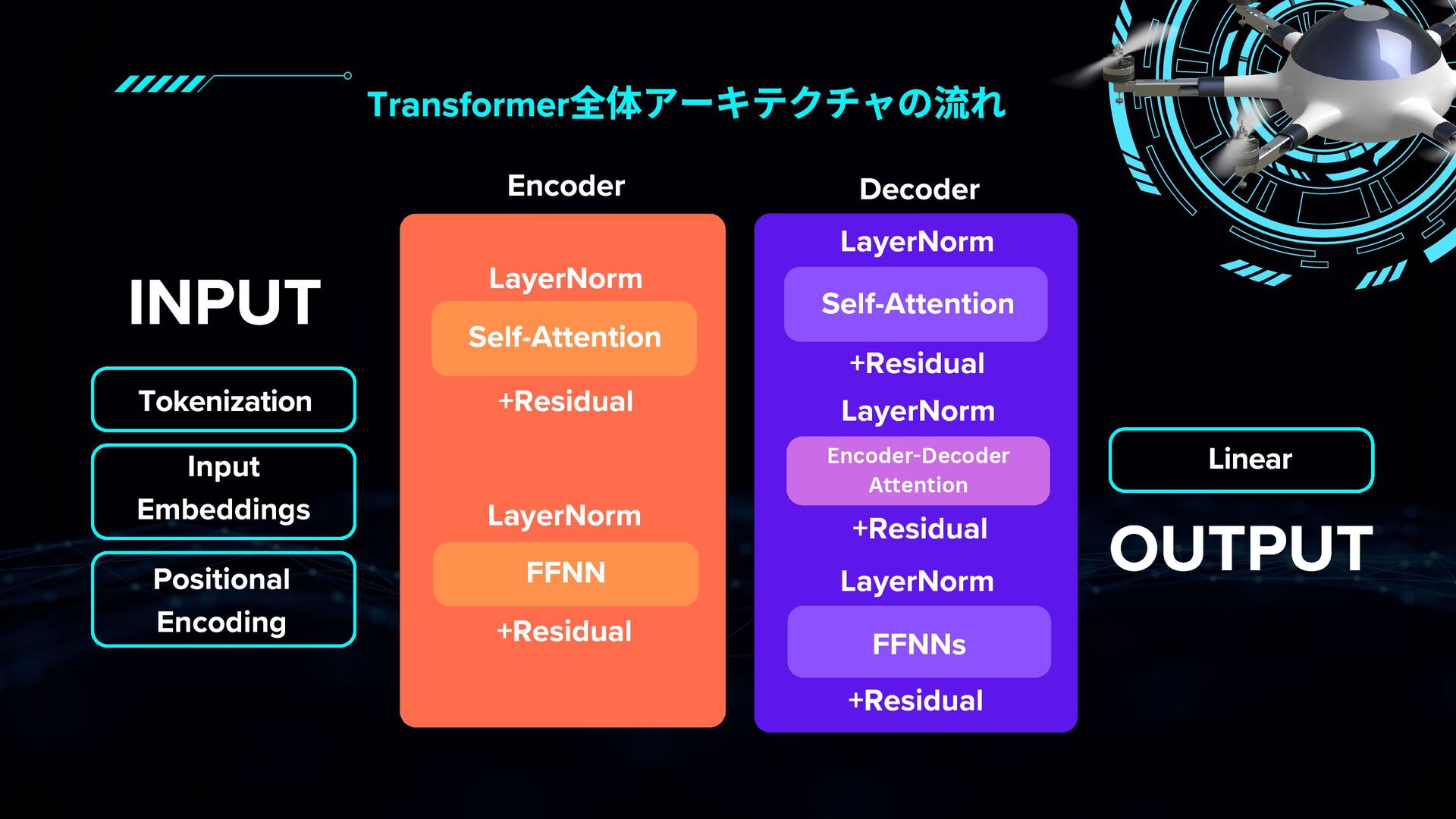
このスライドでは、ChatGPTなどの大規模言語モデルの中核技術である「Transformer」について、初心者にもわかりやすく30分で理解できるように解説しています。
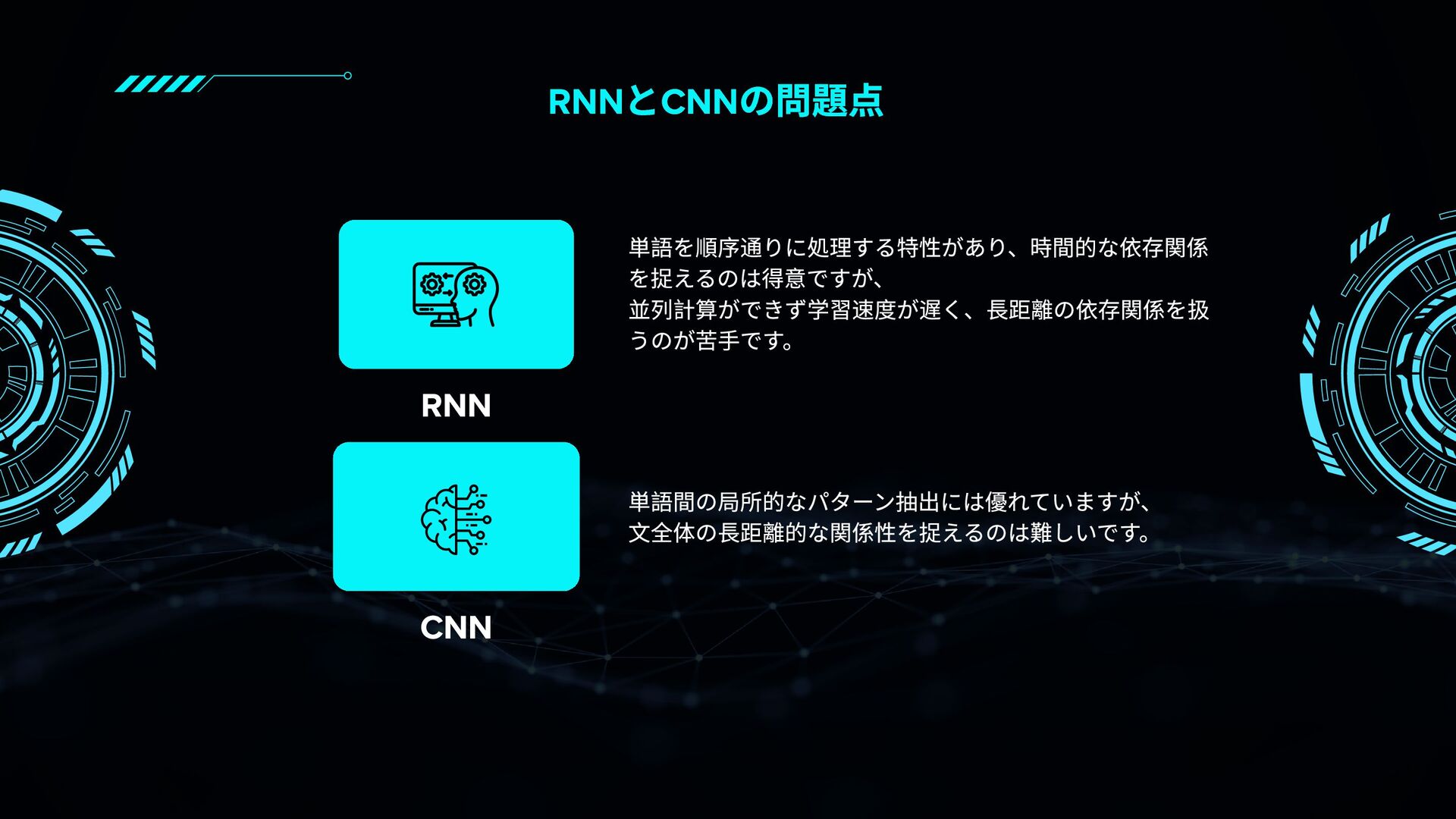
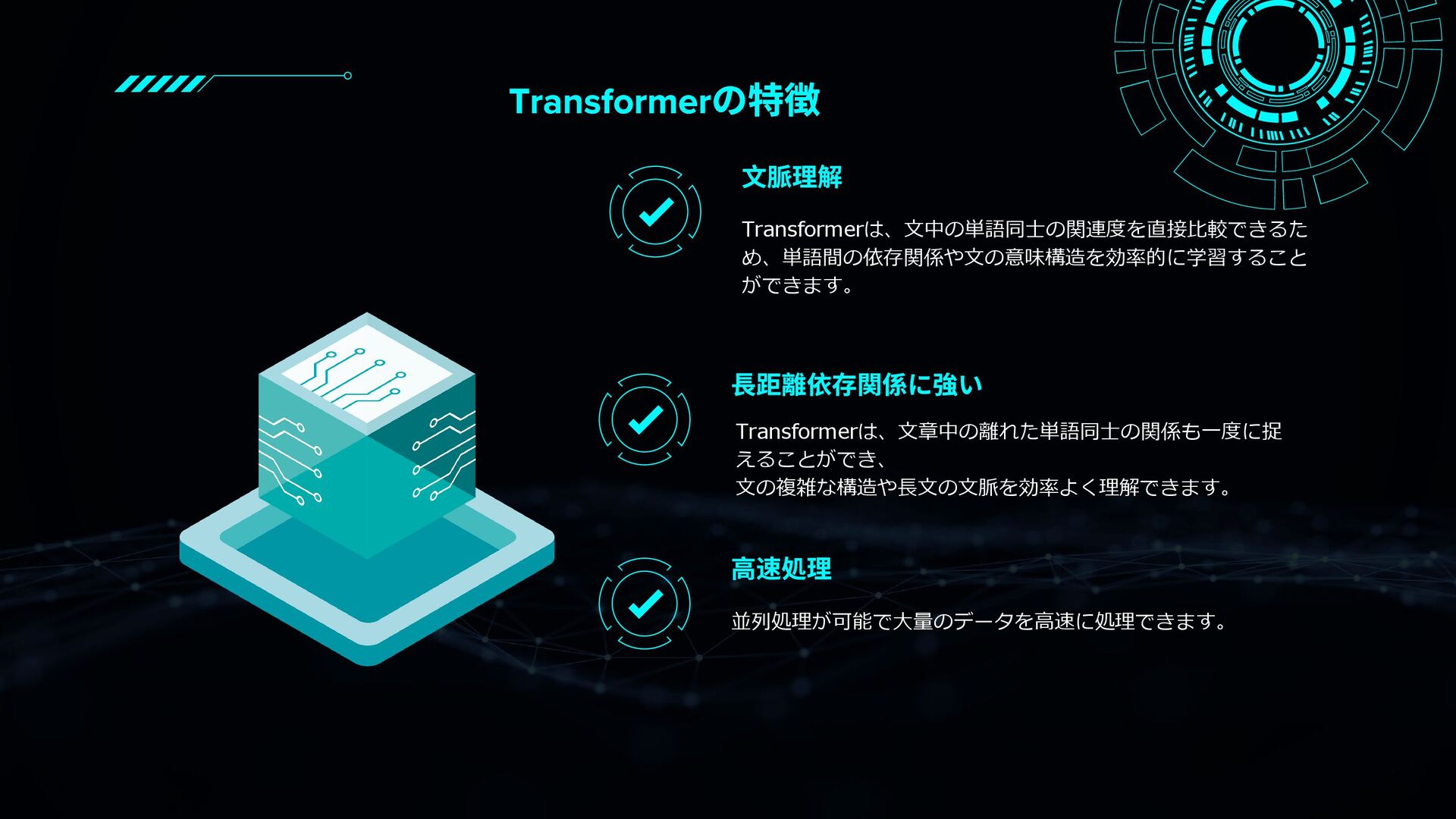
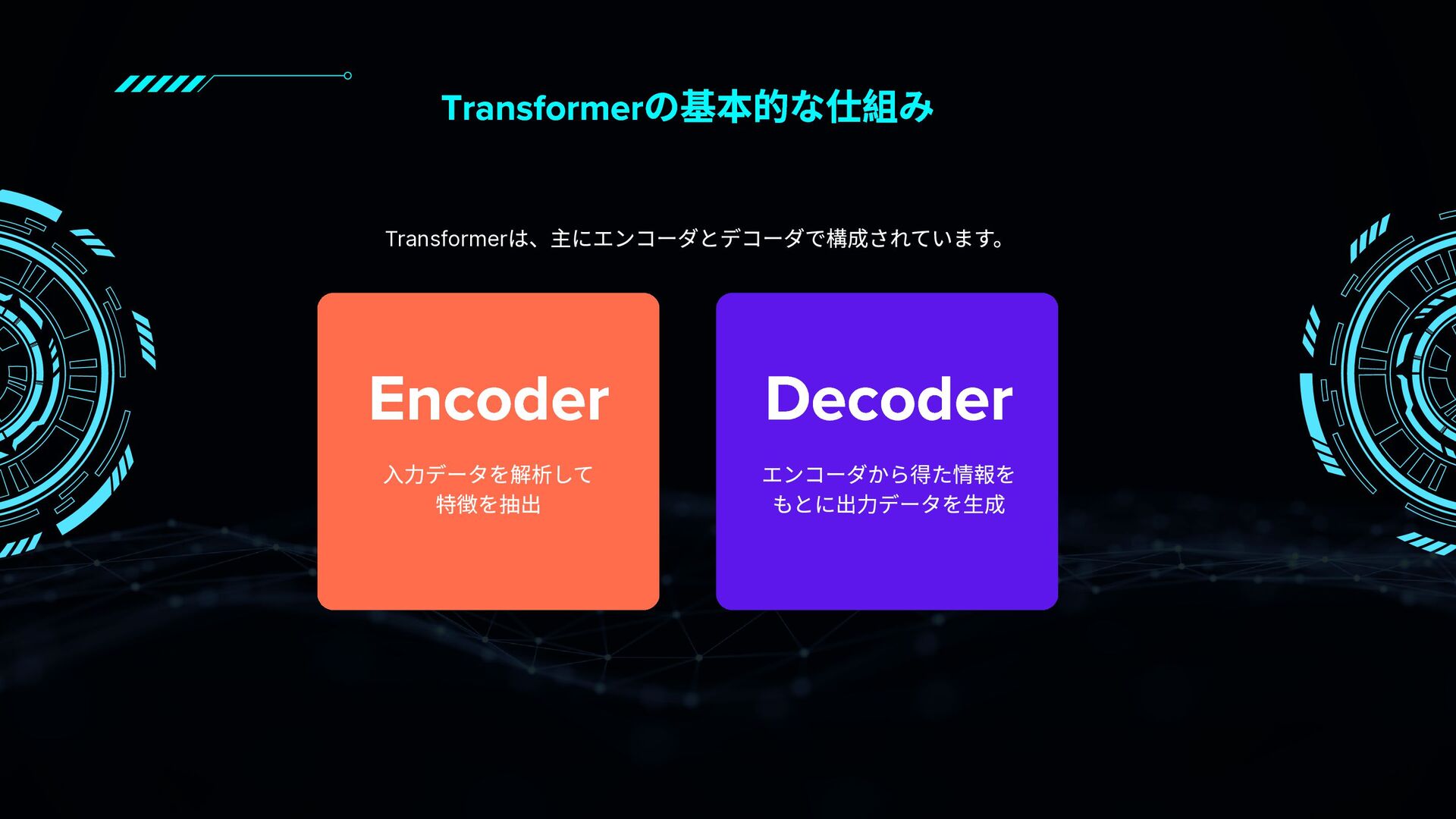
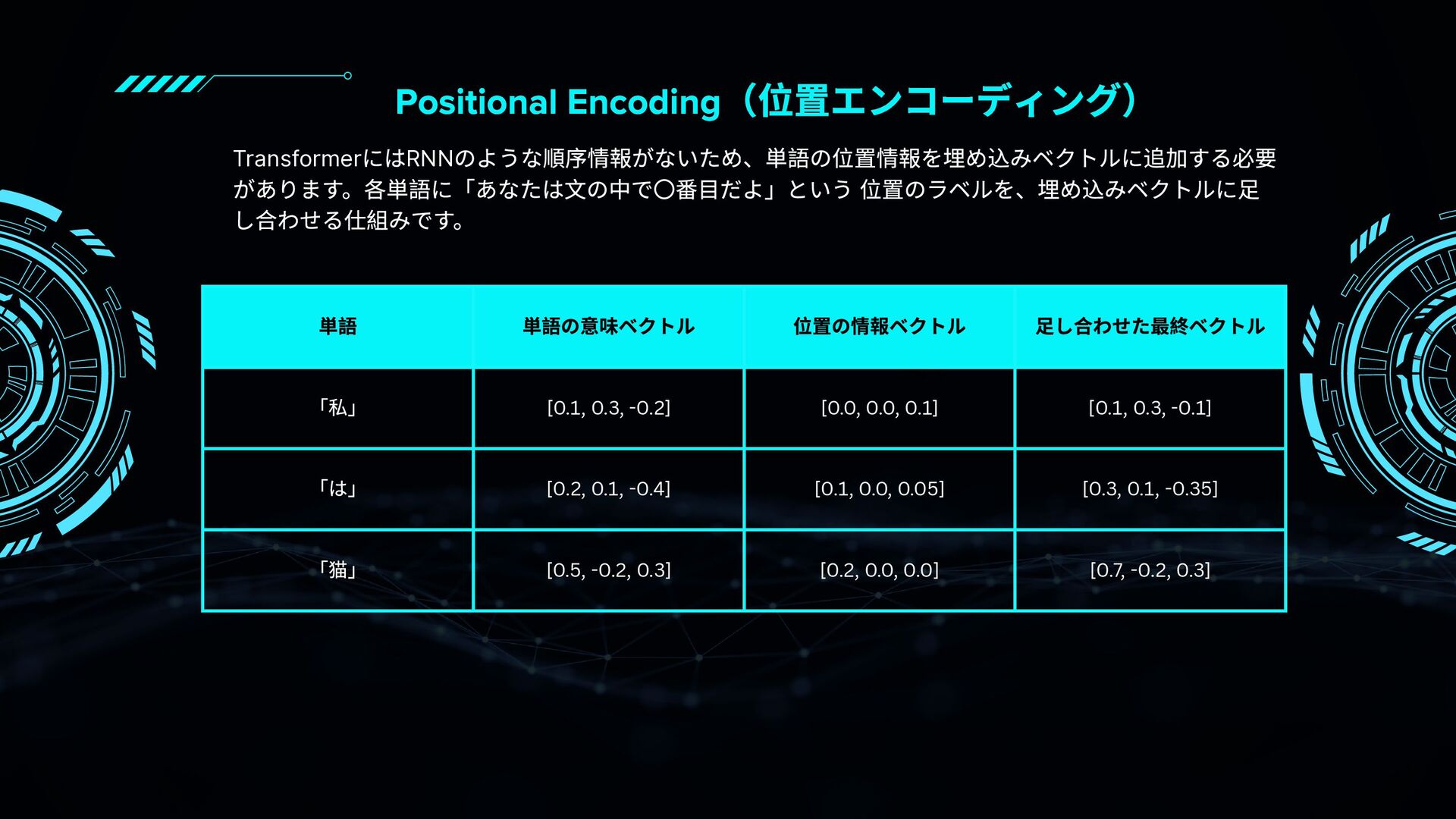
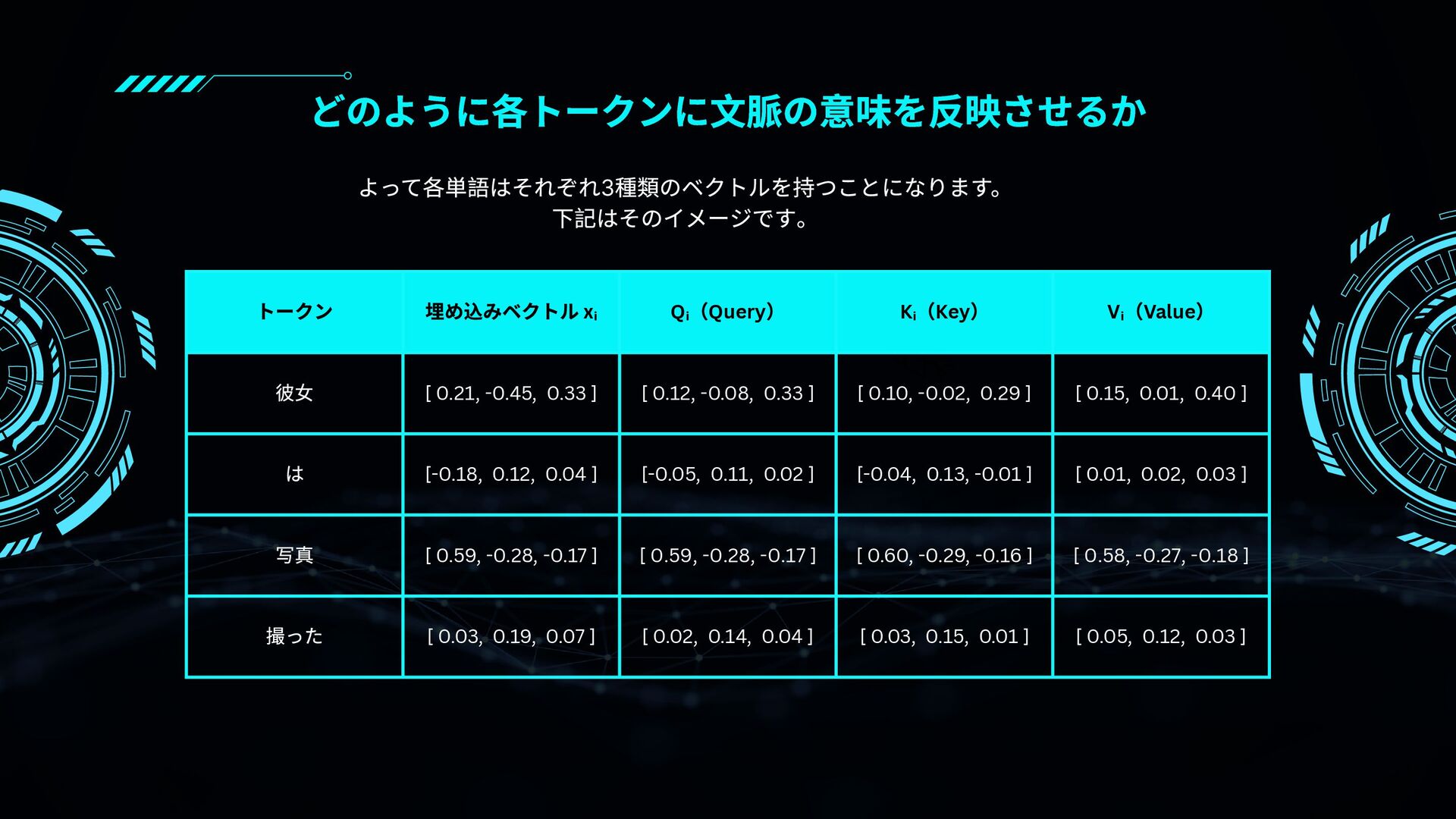
RNNやCNNとの違いから、Self-Attention・Multi-Head Attention・Encoder/Decoder構造・Positional Encodingなどの要素を図解と具体例で丁寧に紹介。
文脈をどう捉え、翻訳や生成をどのように行っているのかが視覚的に学べる内容です。
AIや自然言語処理に興味がある方、これからTransformerを学びたい方におすすめです。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
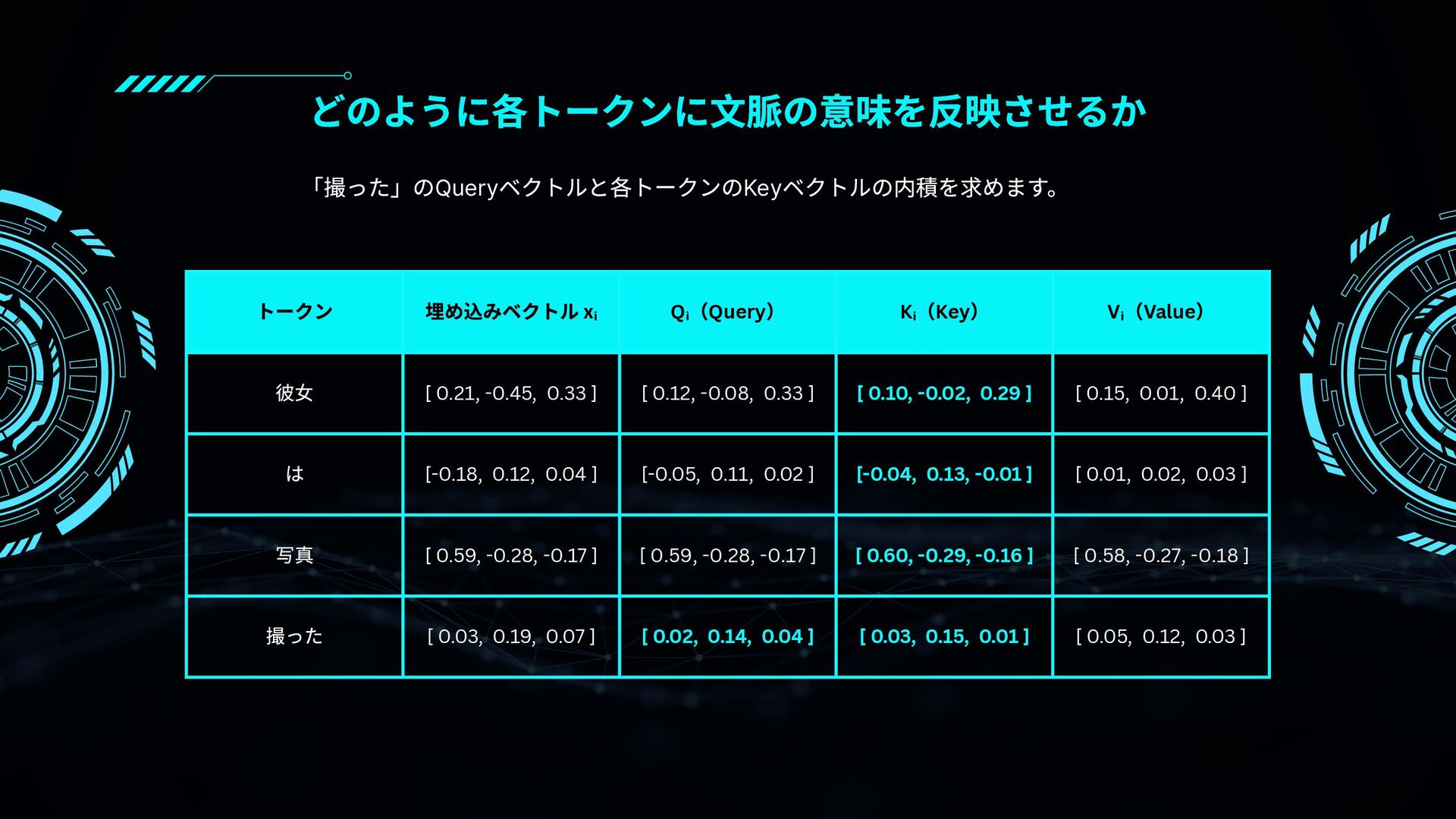{kind=link}
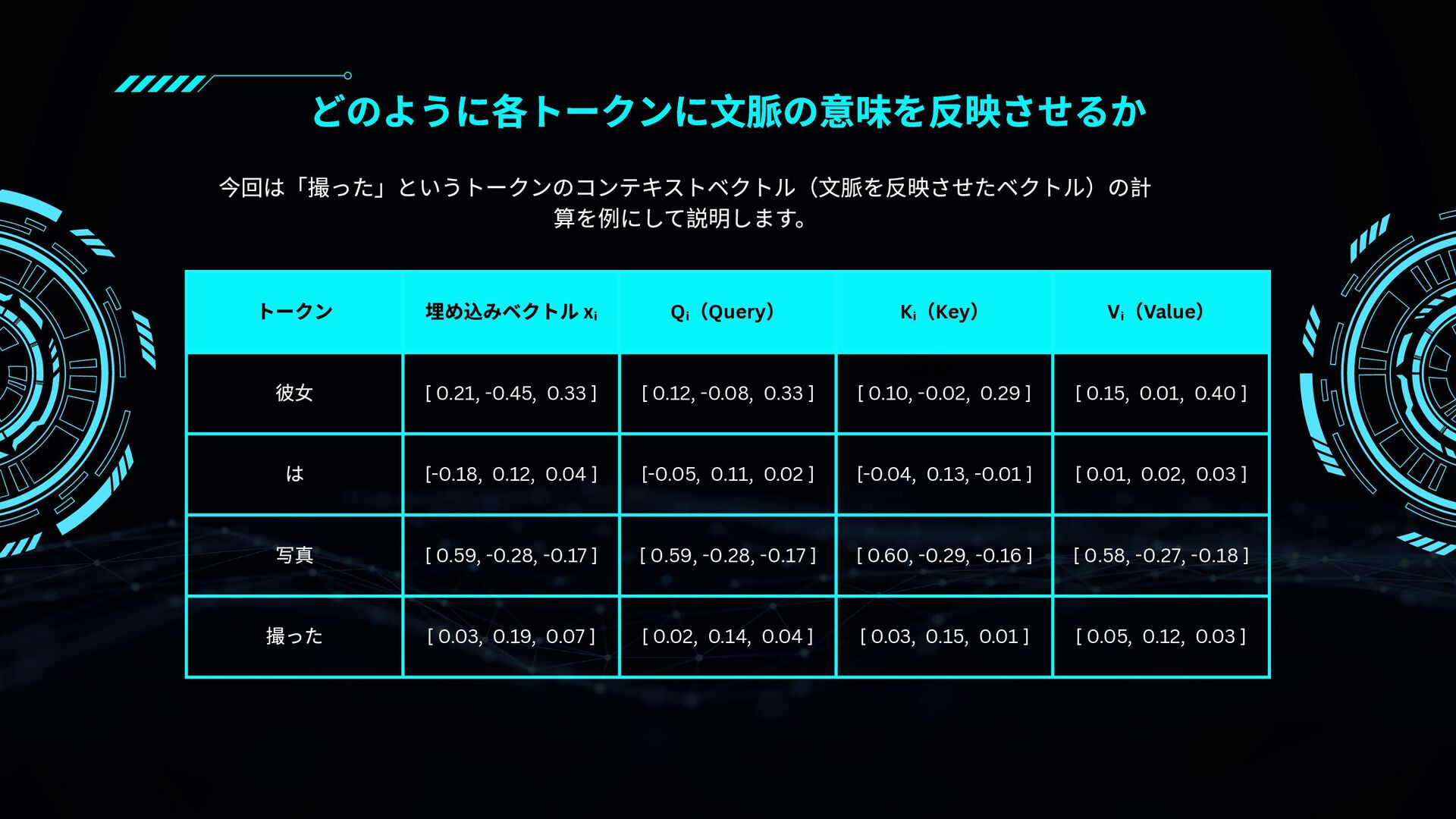
![「撮った」のQuery ベクトル:[0.02, 0.14, 0.04] 「彼女」の Key ベクトル:[0.10, -0.02, 0.29] =](https://files.speakerdeck.com/presentations/1e4d41c6fdd74641b8c930aea931aae8/slide_25.jpg){kind=link}
{kind=link}
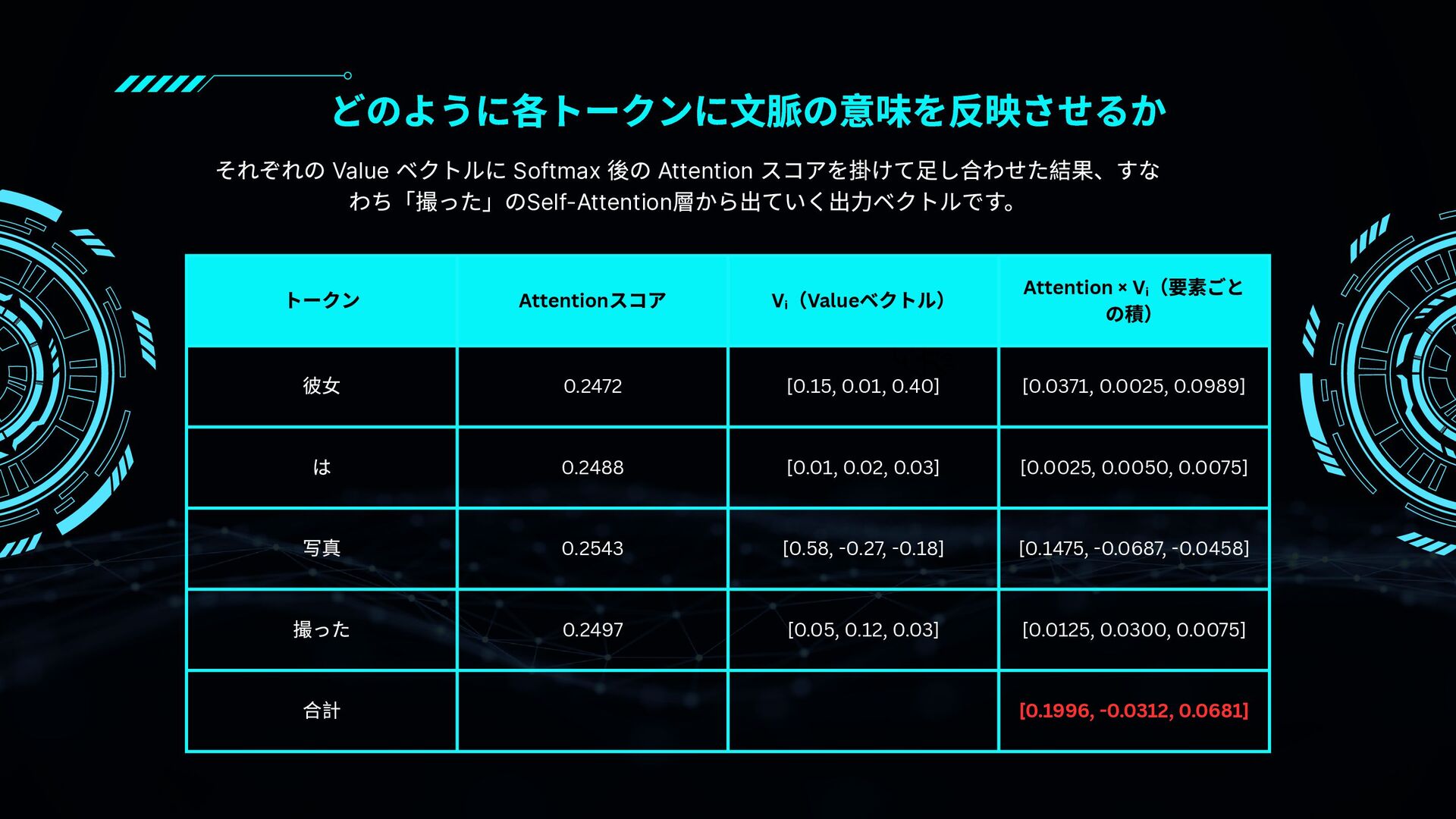{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}