In this talk we will build together a toolbox to tame complicated (known unknowns) and complex (unknown unknowns) systems in production: monitoring and traceability, reproducibility and access, team dynamics and incident management, and more.
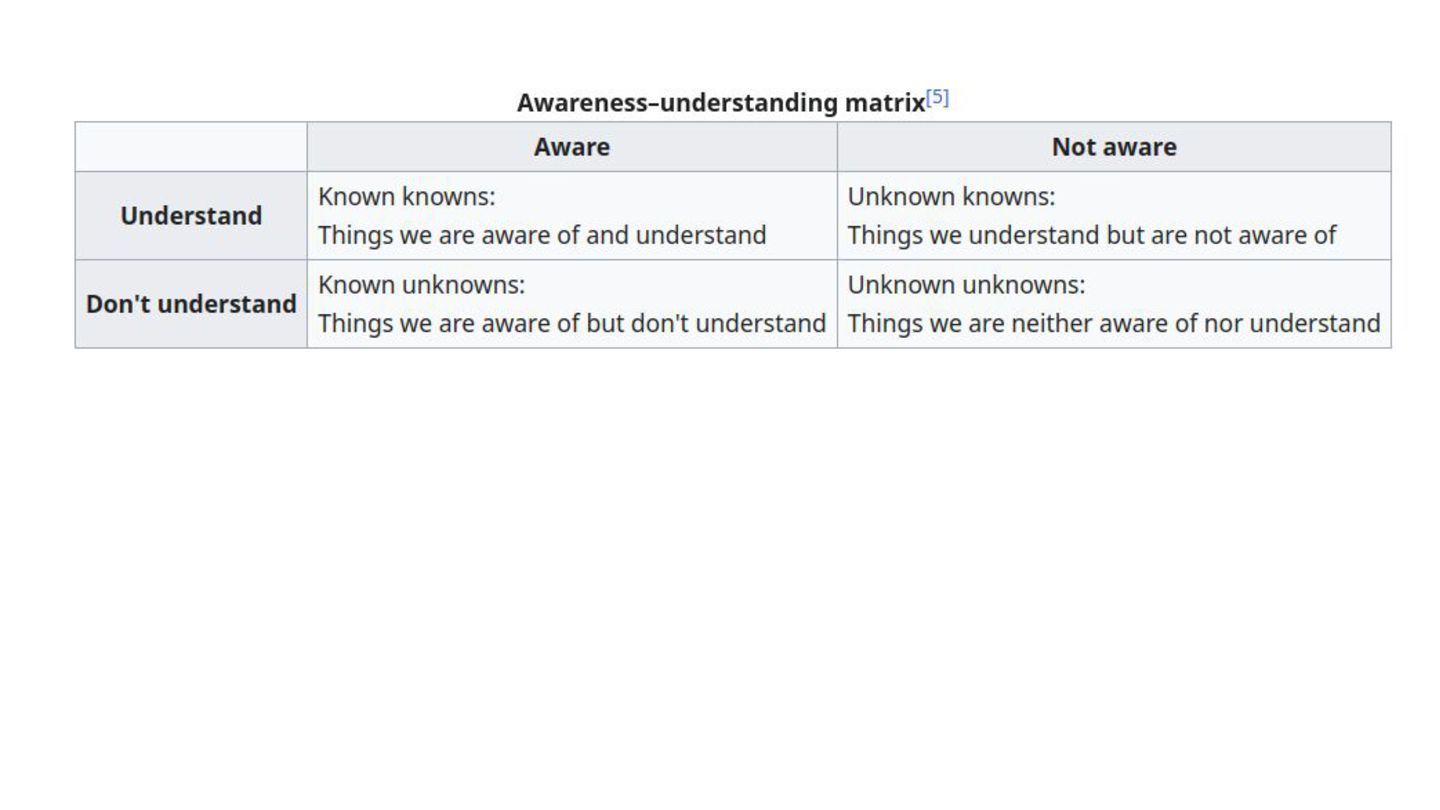
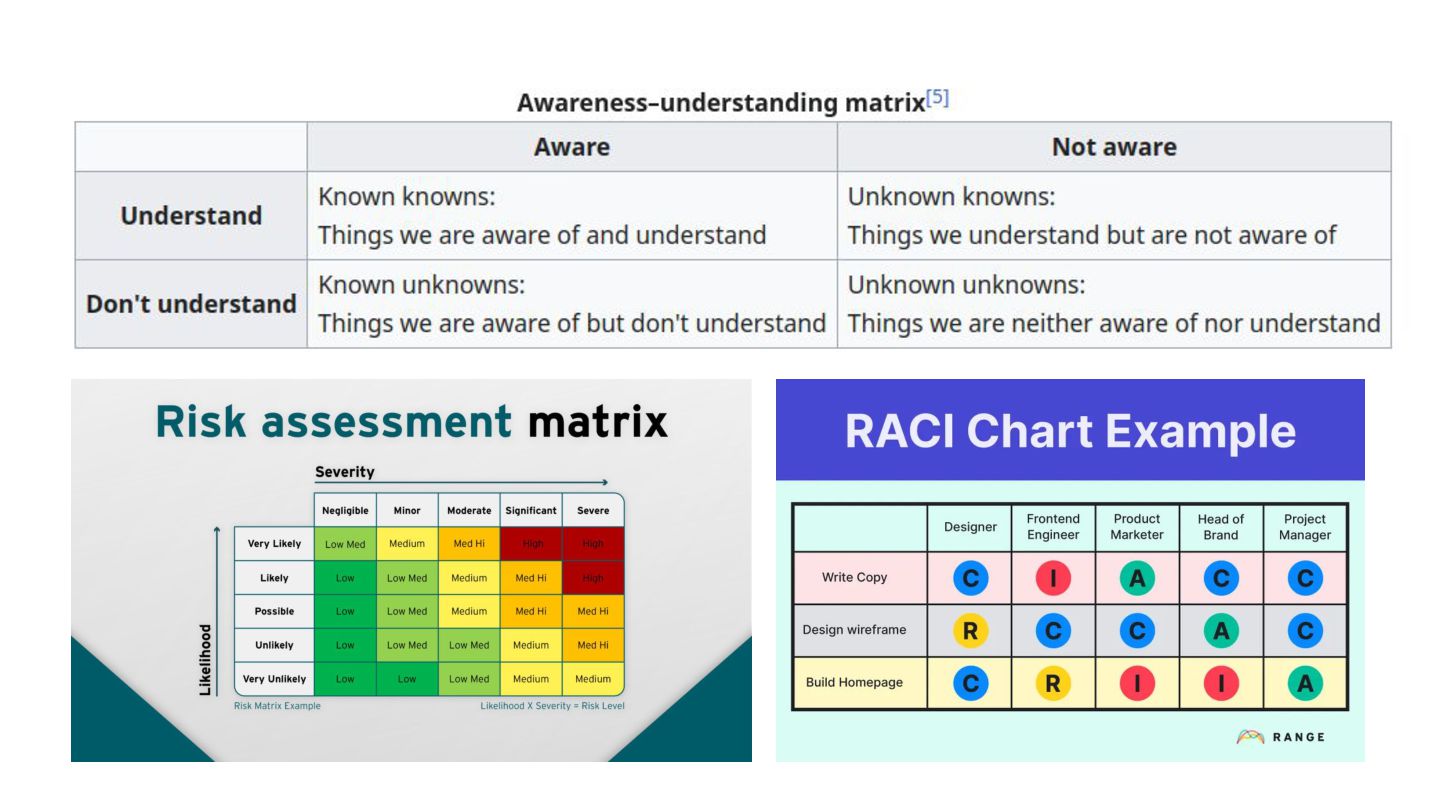
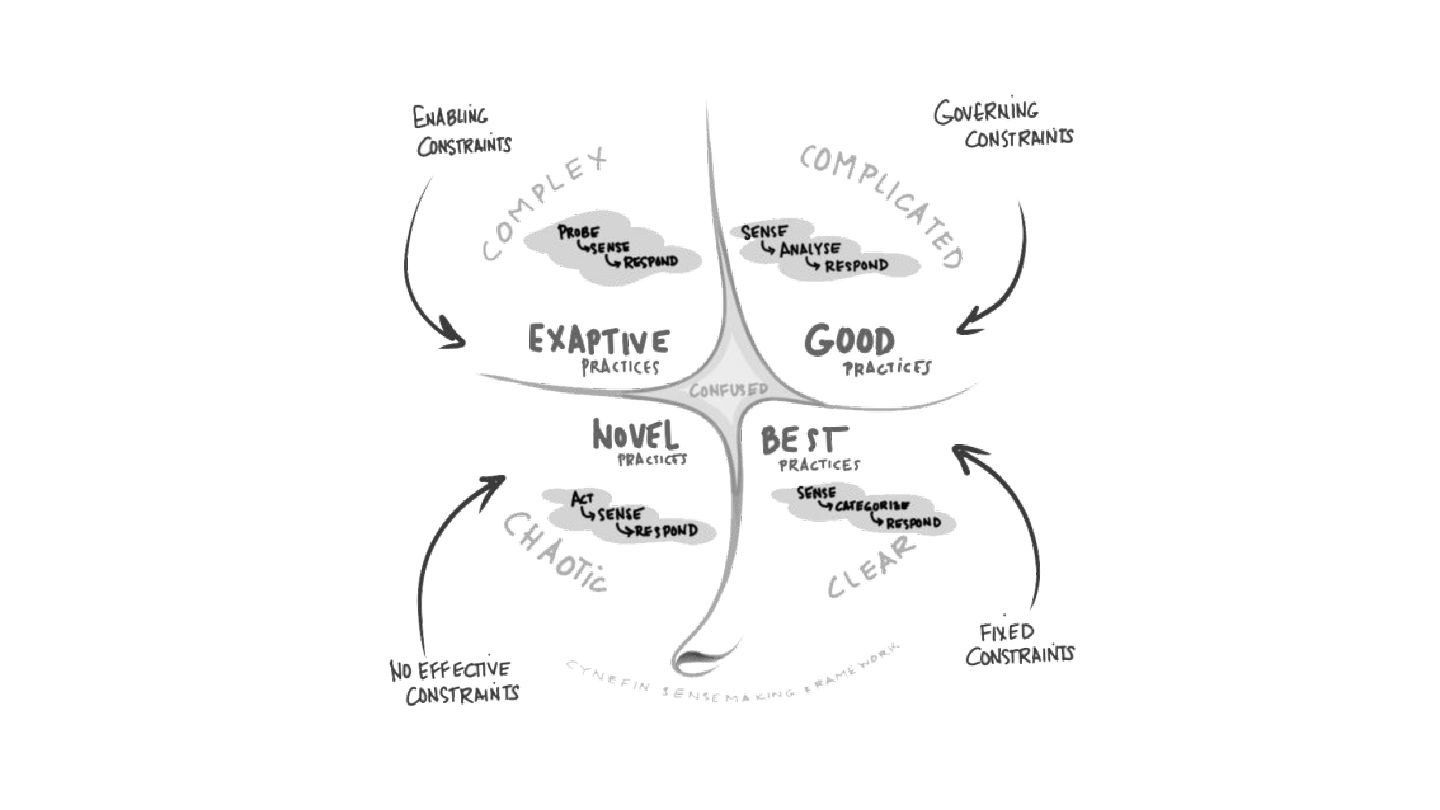
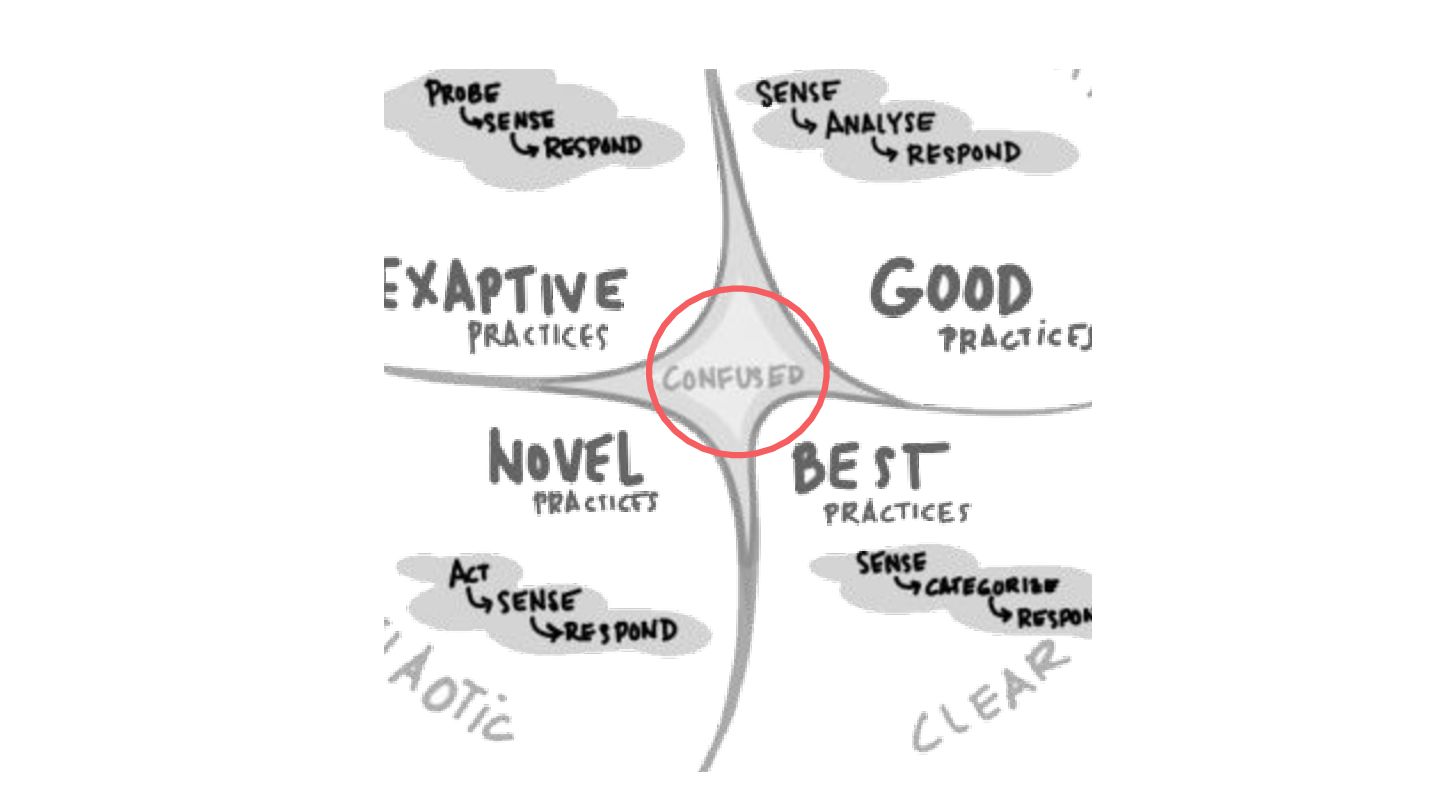
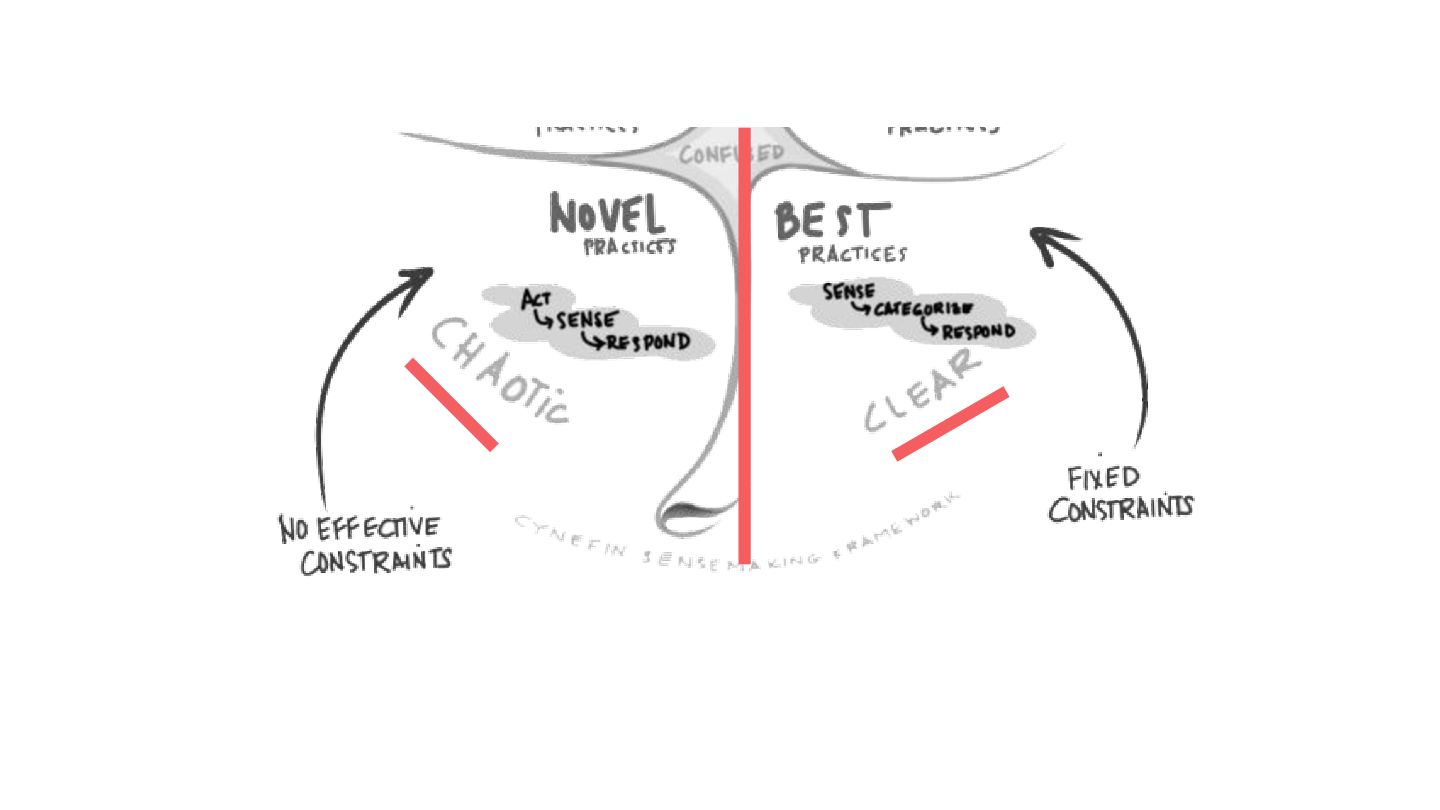
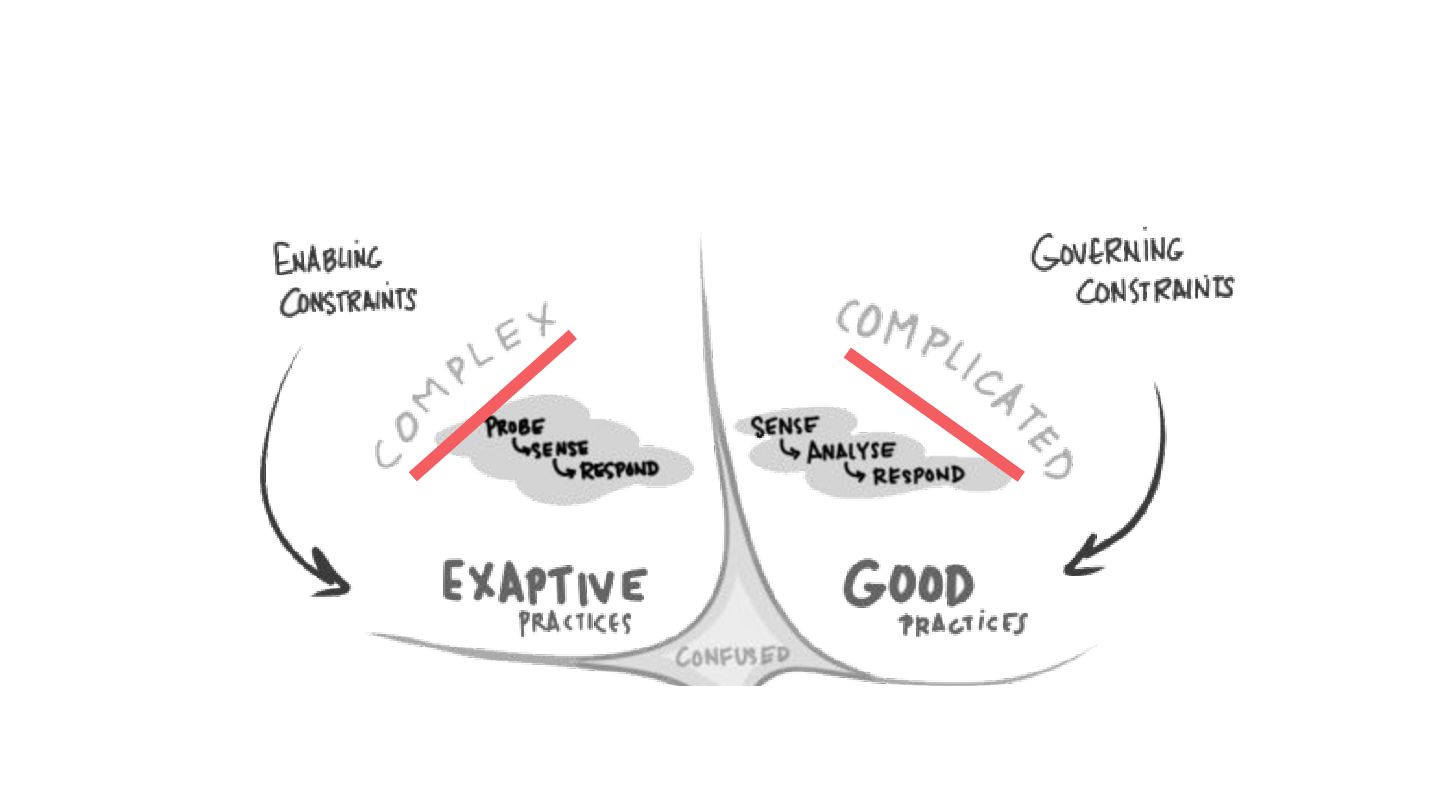
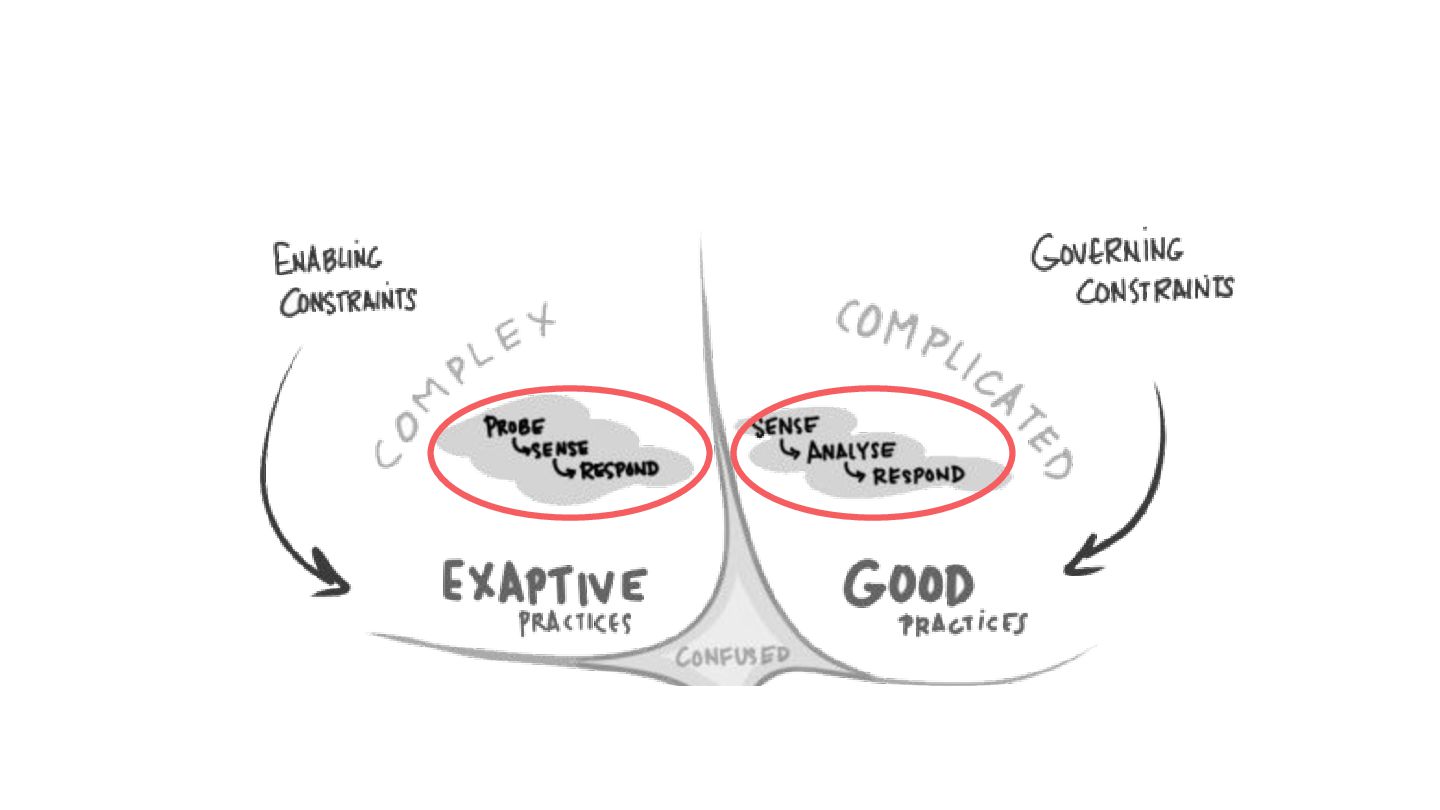
The talk will start with a brief overview of the Cynefin framework https://en.m.wikipedia.org/wiki/Cynefin_framework and translate its learnings into a set of practices that we can use in operating production systems at scale, plus a set of tools that everyone can use to improve their systems resilience and teams well-being.
We will use concrete examples of systems that have strict uptime requirements, mostly from the banking industry.
You will leave this talk with a better understanding of how to scale your system operations sustainably, and what the things that will let you deploy in production with confidence and then go to bed are"
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}