Kubernetes presents it's own language that can be difficult at first to grok. This talk introduces the audience to some basic concepts around Kubernetes and then presents pods and pod types as an object hierarchy.
about: ◦ Why Kubernetes exists. ◦ How Kubernetes works. ◦ The challenges of container orchestration at scale. ◦ How you can use Kubernetes. • Most importantly, I want you guys and gals to have a good time with some like minded folks and learn something new in a fun way.
best software has a vision. The best software takes sides. When someone uses software, they're not just looking for features, they're looking for an approach. They're looking for a vision. Decide what your vision is and run with it.
actually a Greek term for “ship master”. • Developed at Google. The third iteration of container management. ◦ Daddy was Omega. ◦ Grandaddy was Borg. • Kubernetes is not a PaaS, but you can build one with it. • Google says that Kubernetes is planet scale.
Master • 1,009 Nodes over 4 Regions • 8,072 Cores. The master used 24, minion nodes used the rest • 1,009 IP addresses • 1,009 routes setup by Kubernetes on Google Cloud Platform • 100,510 GB persistent disk used by the Minions and the Master • 380,020 GB SSD disk persistent disk. 20 GB for the master and 340 GB per Cassandra Pet. • 1,000 deployed instances of Cassandra
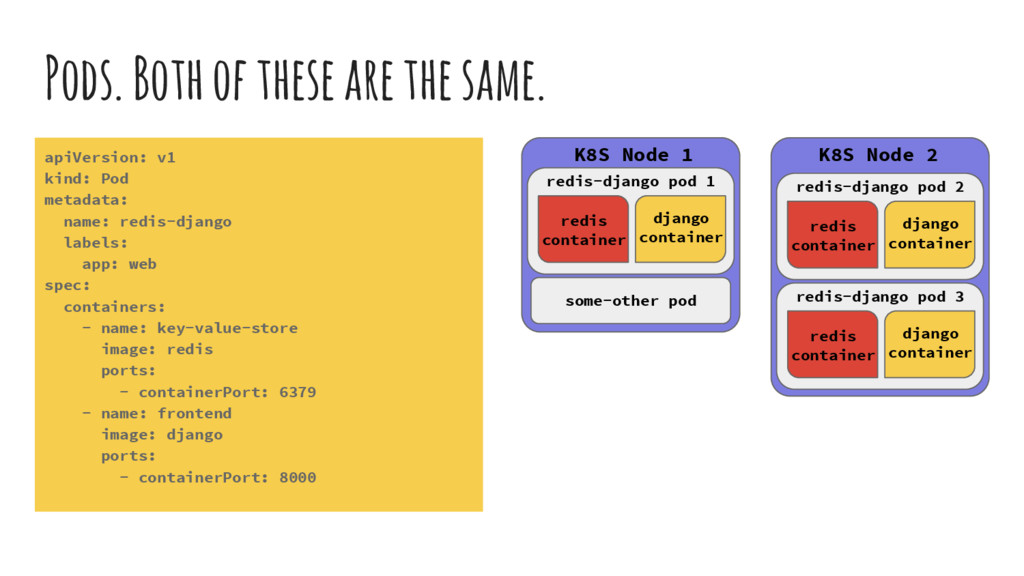
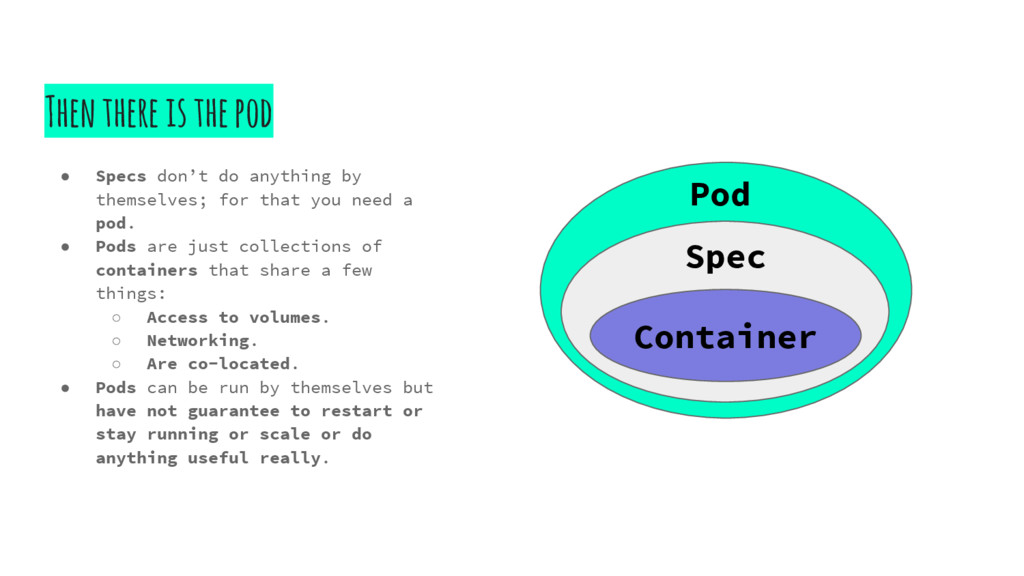
one or more containers. • The containers in a pod are scheduled on the same node. • Everything in Kubernetes is some flavor of of pod or an extension of the pod spec. • Remember this for now, we’ll get back to it in a second. A pod is a collection of containers.
(boo*). apiVersion: v1 kind: Pod metadata: name: "" labels: name: "" namespace: "" annotations: [] generateName: "" spec: ? "// See 'The spec schema' for details." : ~ { "kind": "Pod", "apiVersion": "v1", "metadata": { "name": "", "labels": { "name": "" }, "generateName": "", "namespace": "", "annotations": [] }, "spec": { // See 'The spec schema' for details. } } *Font size 14 vs font size 10, YAML is the clear winner. Especially in the context of Shannon’s Information Theory. The same density of information can be transmitted in less lines with YAML.
A label is a key-value pair that is assigned to objects in k8s. ◦ Pods, services, lots of things can have labels. • A selector is a way to filter for labels that match a certain criteria or logic. ◦ There are two types of selectors: ▪ Equality based ▪ Set based
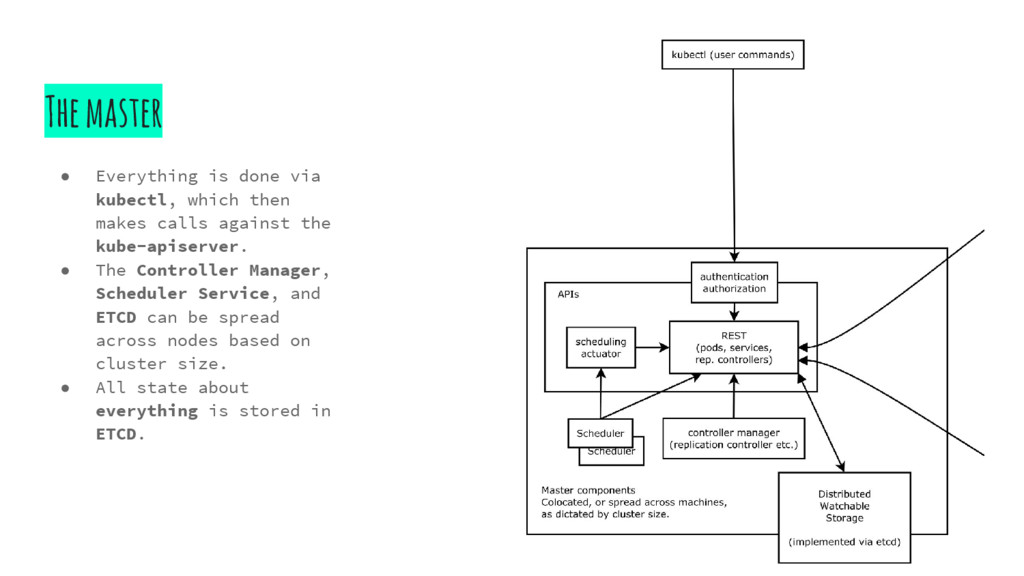
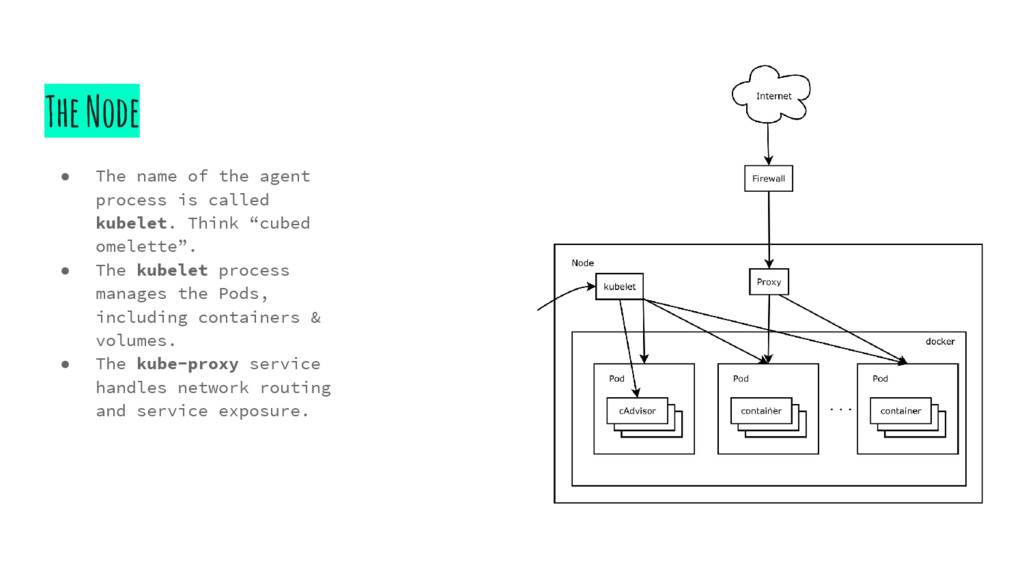
ears of the operation. Handles requests from clients to make changes to state. • kube-scheduler: Scheduler for ods. Probably the most advanced component. • kube-controller-manager: Handles control loop services in k8s. • *etcd: Used to store state. Node • kubelet: This is the k8s client service that runs on nodes. It functions as a job scheduler, taking calls from the master and ensuring state. • kube-proxy: Handles networking among the containers in a pod, including load balancing and exposing the containers externally. *etcd is used to handle state for the cluster, but is not exclusive to k8s.
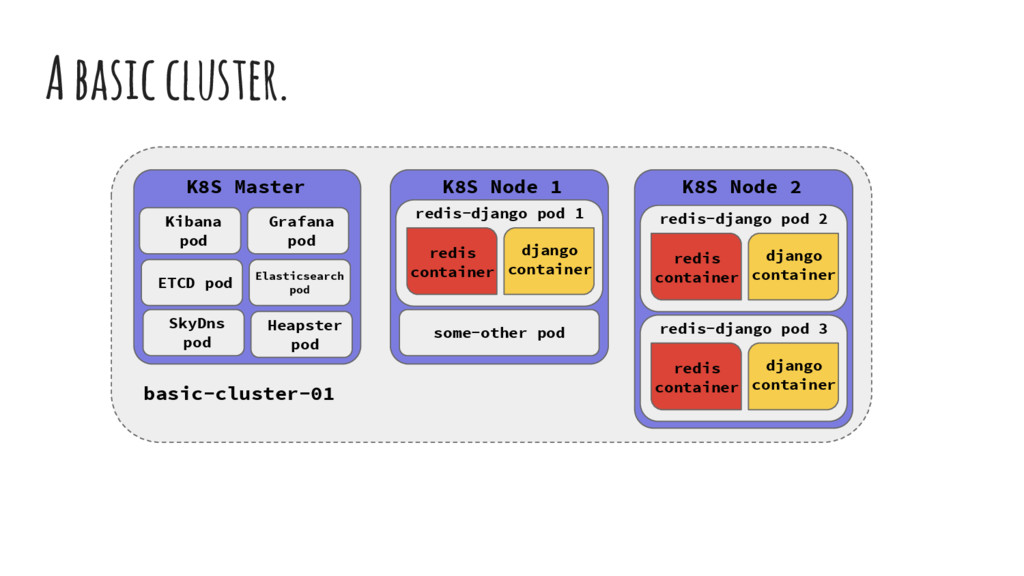
a cluster, you get some built in services. • Each one of these has their own endpoints and / or UIs. • They run on the master directly though you could schedule them across the cluster or other masters. • To find the endpoints type: kubectl cluster-info Heapster
container django container some-other pod K8S Node 2 redis-django pod 2 redis container django container redis-django pod 3 redis container django container K8S Master SkyDns pod ETCD pod Kibana pod Grafana pod Elasticsearch pod Heapster pod basic-cluster-01
of a cluster. • It’s a virtual cluster in your cluster. • Each cluster can have multiple namespaces. • The root services have their own. • Namespaces are in network isolation from each other and can are (normally) used to house different environments on the same cluster.
many, many, many options. • It is a direct mapping of the API. • The commands are essentially shortcuts for interacting with the master server and figuring out what’s going on with your cluster. • This is probably why people have spent time building PaaS offerings on top of it. #bashishard
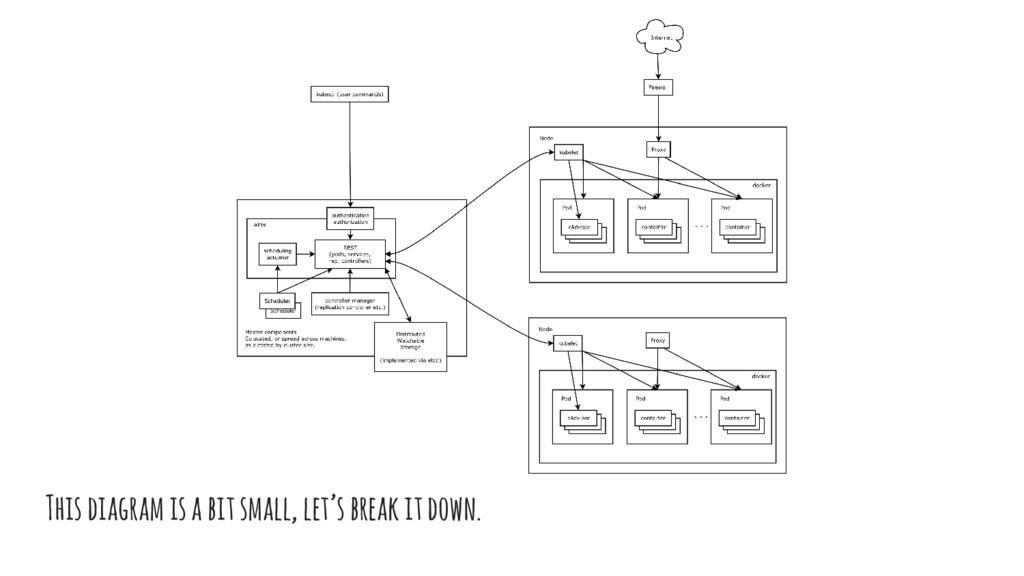
to fire up a pod. With kubectl you would: 1. Make a Pod request to the API server using a local pod definition file. 2. The API server saves the info for the pod in ETCD. 3. The scheduler finds the unscheduled pod and schedules it to a node. 4. Kubelet sees the pod scheduled and fires up docker. 5. Docker runs the container. The entire lifecycle state of the pod is stored in ETCD.
makes calls against the kube-apiserver. • The Controller Manager, Scheduler Service, and ETCD can be spread across nodes based on cluster size. • All state about everything is stored in ETCD.
called kubelet. Think “cubed omelette”. • The kubelet process manages the Pods, including containers & volumes. • The kube-proxy service handles network routing and service exposure.
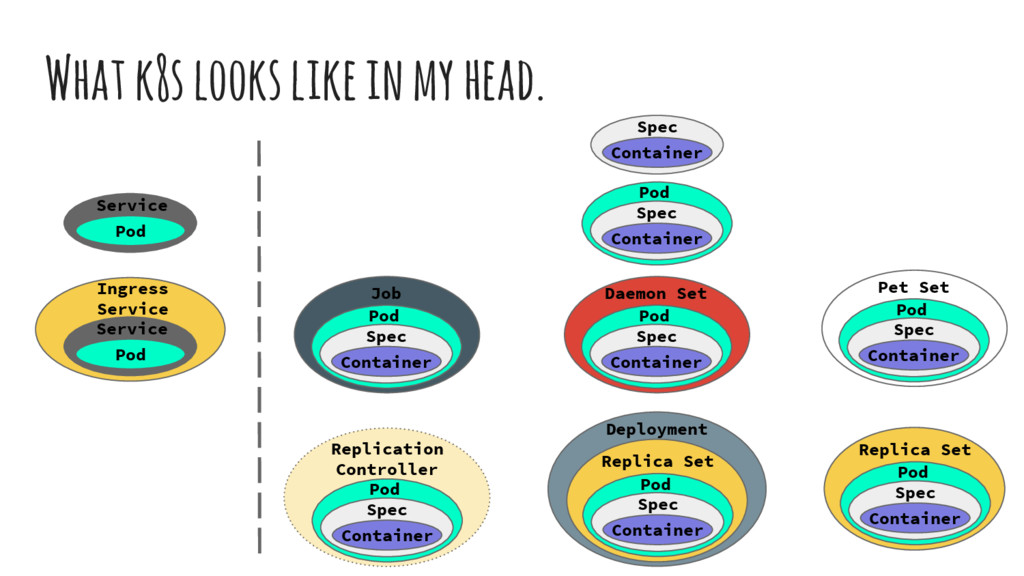
it easiest to think of everything as a variation of a Pod or another object. • Google has done a very good job at extending base objects to add flexibility or support new features. • This also means that the Pod spec is relatively stable given the massive list of features that is dropped every release.
Replica Set Pod Spec Container Replication Controller Pod Spec Container Daemon Set Pod Spec Container Pet Set Pod Spec Container Deployment Replica Set Pod Spec Container Service Pod Service Pod Ingress Service Spec Container Job Pod Spec Container
spec: containers: - args: - "" command: - "" env: - name: "" value: "" image: "" imagePullPolicy: "" name: "" ports: - containerPort: 0 name: "" protocol: "" resources: cpu: "" memory: "" restartPolicy: "" volumes: - emptyDir: medium: "" name: "" secret: secretName: "" • The only required field is containers. ◦ And it requires two entries ▪ name ▪ image • restarPolicy is for all containers in a pod. • volumes are volumes (duh) that any container in a pod can mount. • The spec is very extensible by design.
by themselves; for that you need a pod. • Pods are just collections of containers that share a few things: ◦ Access to volumes. ◦ Networking. ◦ Are co-located. • Pods can be run by themselves but have not guarantee to restart or stay running or scale or do anything useful really. Pod Spec Container
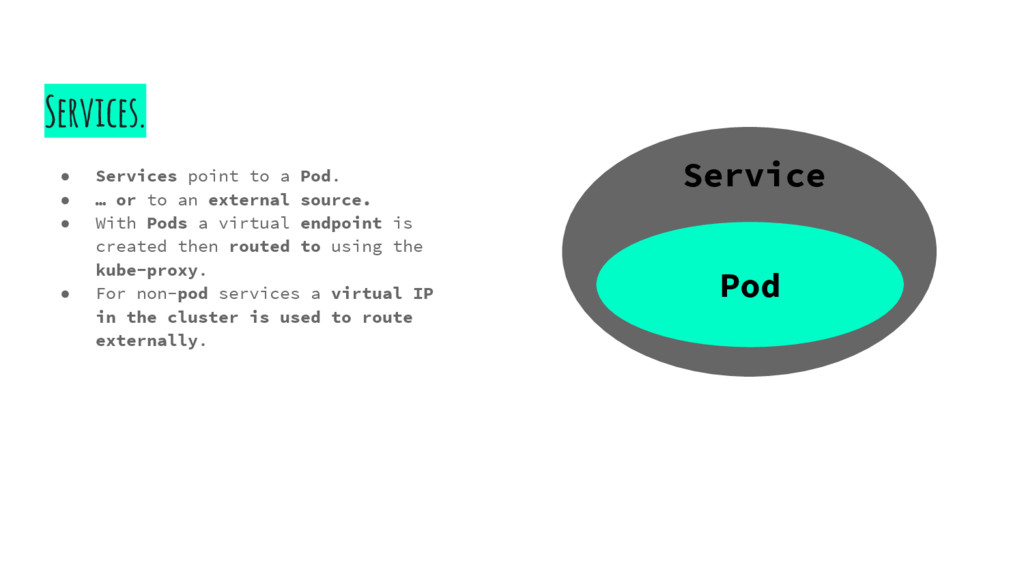
to an external source. • With Pods a virtual endpoint is created then routed to using the kube-proxy. • For non-pod services a virtual IP in the cluster is used to route externally. Service Pod
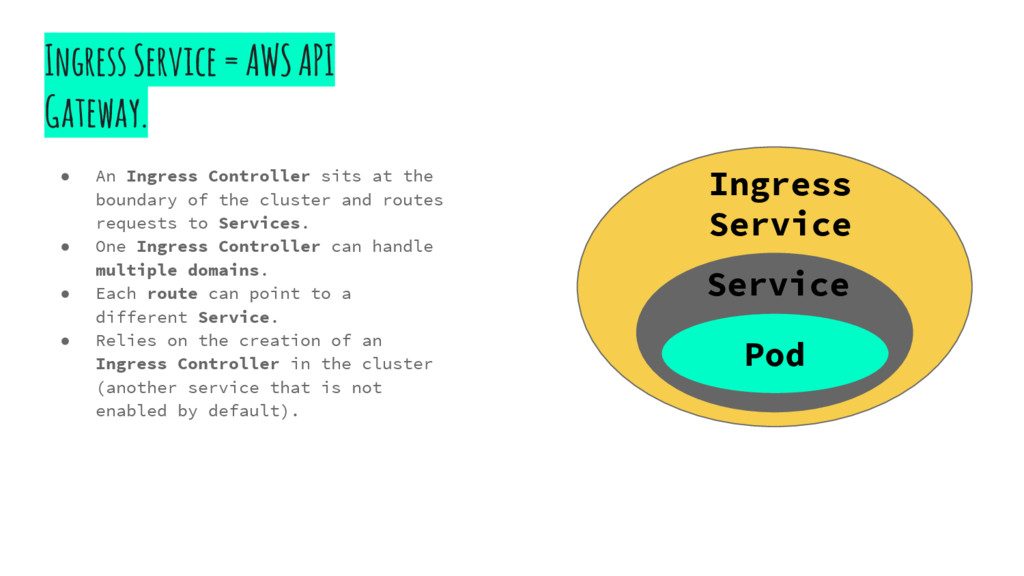
sits at the boundary of the cluster and routes requests to Services. • One Ingress Controller can handle multiple domains. • Each route can point to a different Service. • Relies on the creation of an Ingress Controller in the cluster (another service that is not enabled by default). Service Pod Ingress Service
that a copy of each Pod runs on each node. • This is commonly used to make sure side-car containers are running across the cluster. • If new nodes come up they’ll get a copy of the daemon set and will come up. • Daemon sets don’t have scaling rules. Daemon Set Pod Spec Container
Sets allow you to create complex microservices across the cluster. • They have the ability to set dependency on other containers. • They require: ◦ A stable hostname, available in DNS ◦ An ordinal index ◦ Stable storage: linked to the ordinal & hostname • It’s for launching a cluster in your cluster. Pet Set Pod Spec Container
Sets allow you to create complex microservices across the cluster. • They have the ability to set dependency on other containers. • They require: ◦ A stable hostname, available in DNS ◦ An ordinal index ◦ Stable storage: linked to the ordinal & hostname • It’s for launching a cluster in your cluster. Pet Set Pod Spec Container
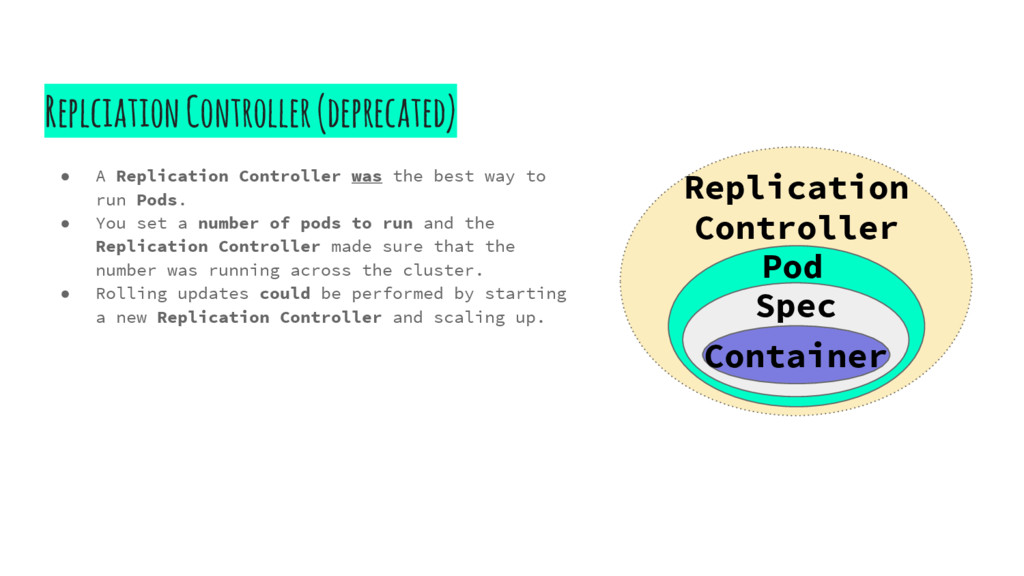
way to run Pods. • You set a number of pods to run and the Replication Controller made sure that the number was running across the cluster. • Rolling updates could be performed by starting a new Replication Controller and scaling up. Replication Controller Pod Spec Container
from the Replication Controller because it can be updated. • If you update the Replica Set template you can fire and update and automatically roll changes. • Roll backs are also built in. • These are not designed to use directly. For that you need ... Pod Spec Container Replica Set
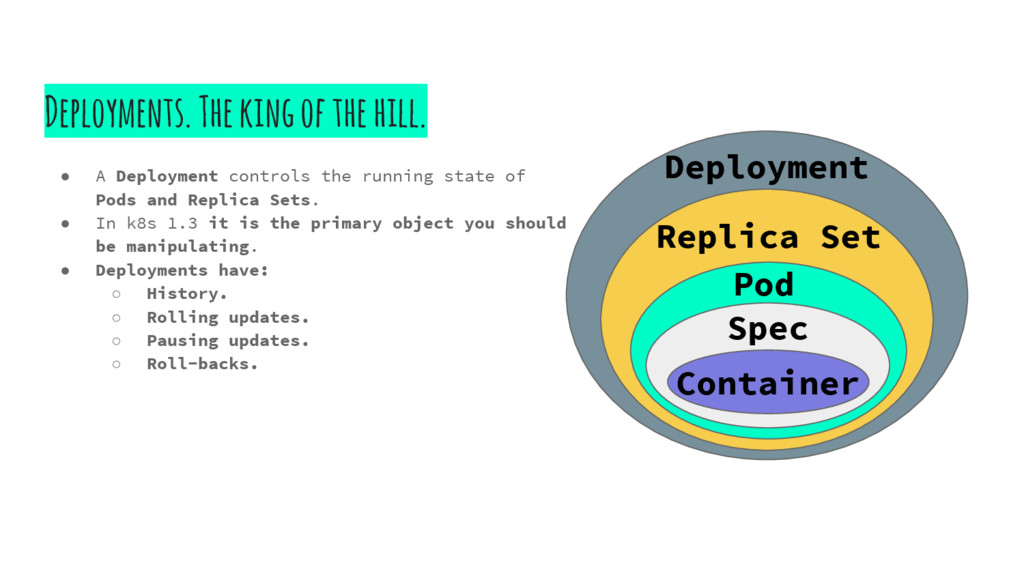
the running state of Pods and Replica Sets. • In k8s 1.3 it is the primary object you should be manipulating. • Deployments have: ◦ History. ◦ Rolling updates. ◦ Pausing updates. ◦ Roll-backs. Deployment Replica Set Pod Spec Container
secret store that is namespaced and uses labels to control pod read access. • Network Policies: ◦ You can use labels to define whitelist rules between pods. • Persistent Volumes: ◦ These live outside of normal pod volumes and can be used for shared storage for things like databases. Yes, databases in containers.
switch and go 100% container by the end of Q3. • We have an existing solution in place that uses Troposphere and ECS. • Looking 12 months out we will outgrow this solution. • I am betting on Kubernetes.
Our “tool” that spits out CloudFormation templates creates: ◦ A CloudFormation stack that spawns: ▪ A 45 node ECS cluster that has: • 120 different ECS tasks running on it ◦ With ELBs ▪ With Route53 entries • Several RDS databases, an ElasticSearch Cluster, and a MemCache Cluster that the containers talk to ◦ And the template it spits out is actually a main template with four sub-templates because more than 4000 lines makes Werner Vogels head a’splode.
Engineer @Civitas Learning • Believer in the healing power of DevOps • I don’t work for Google • I don’t believe in silver bullets • I do believe that if you’re thinking about cluster management for containers you need to find the right tool for you
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contact me! [email protected] @richardboydii on twitter www.richardboydii.com www.coutnzer0.com https://keybase.io/richardboydii](https://files.speakerdeck.com/presentations/7406f4ebd871425f84db689ad96b3ead/slide_55.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}