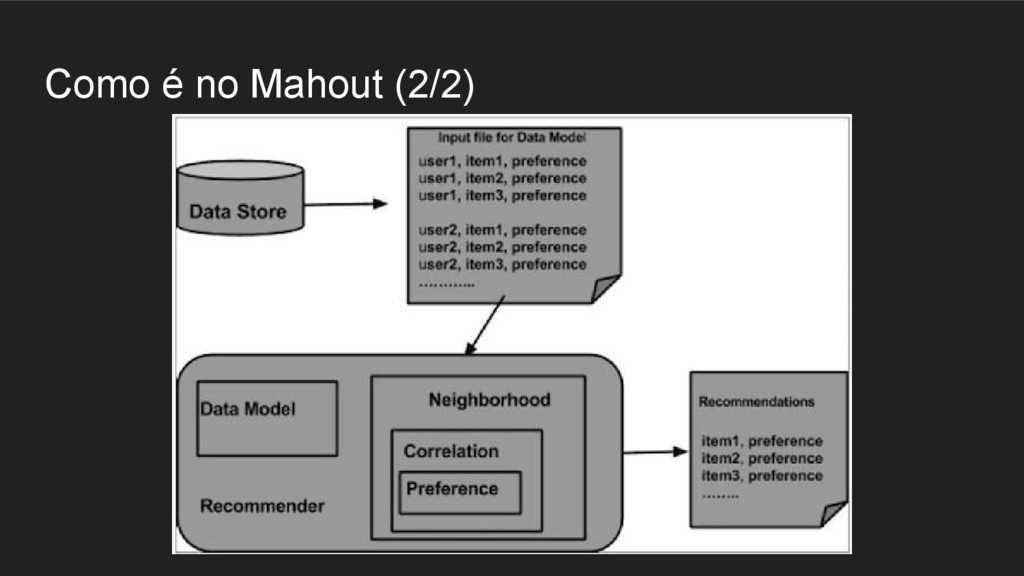
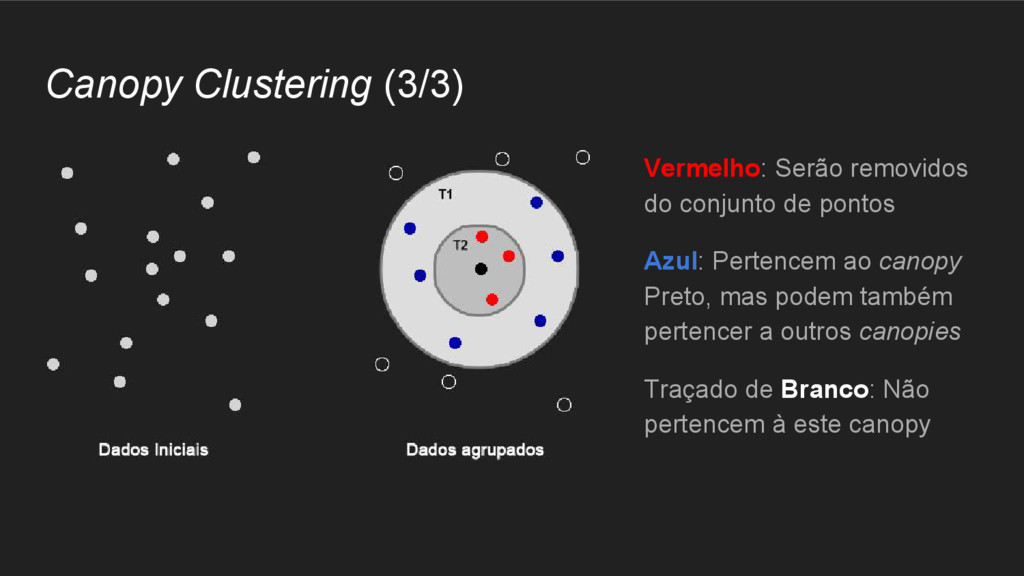
objeto DataModel ira receber um arquivo de entrada com as informações do usuário: Itens, preferências ou detalhes dos produtos. • data.txt: 1,00,1.0 2,00,1.0 3,01,2.5 4,00,5.0 1,01,2.0 2,01,2.0 3,02,5.0 4,01,5.0 1,02,5.0 2,05,5.0 3,03,4.0 4,02,5.0 1,03,5.0 2,06,4.5 3,04,3.0 4,03,0.0 1,04,5.0 2,02,5.0 DataModel datamodel = new FileDataModel(new File(“data.txt”));
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Referências [1] Chu, Cheng, et al. "Map-reduce for machine learning](https://files.speakerdeck.com/presentations/6afe111edf3641b293687774be3068e3/slide_38.jpg){kind=link}