that make a positive impact on people's lives. Obsessed with AI, talking about it, writing blog, and now open-source Radamés Roriz Senior Software Engineer @ Knowbe4 https://roriz.dev https://github.com/roriz https://www.linkedin.com/in/radames-roriz/
can be specified in terms of the count of words Sometimes we get better results when we explicitly instruct the model to reason Some cases providing examples may be easier 1 Some tasks are best specified as sequence of steps 18 relative rules 18+7 relative rules
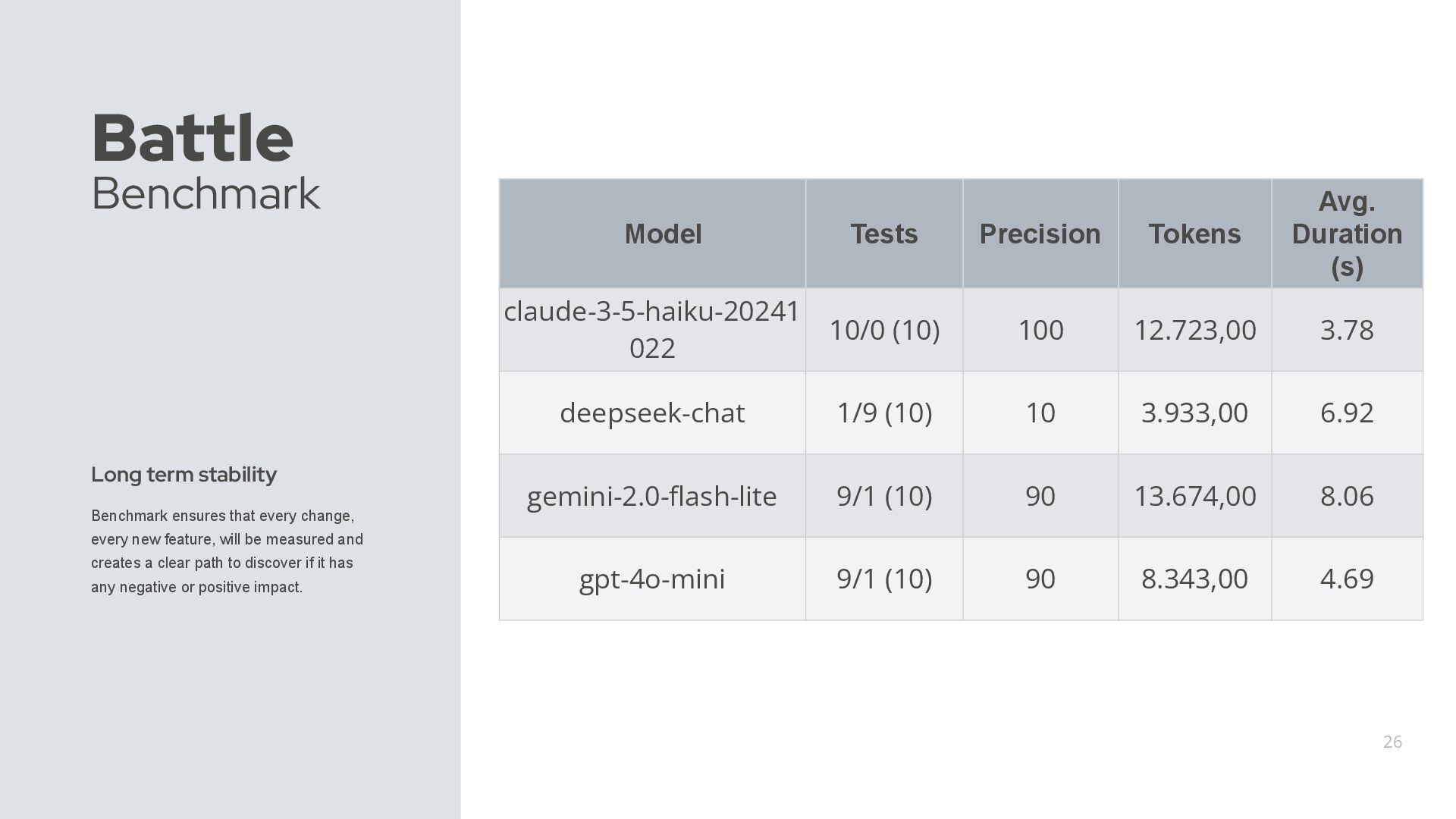
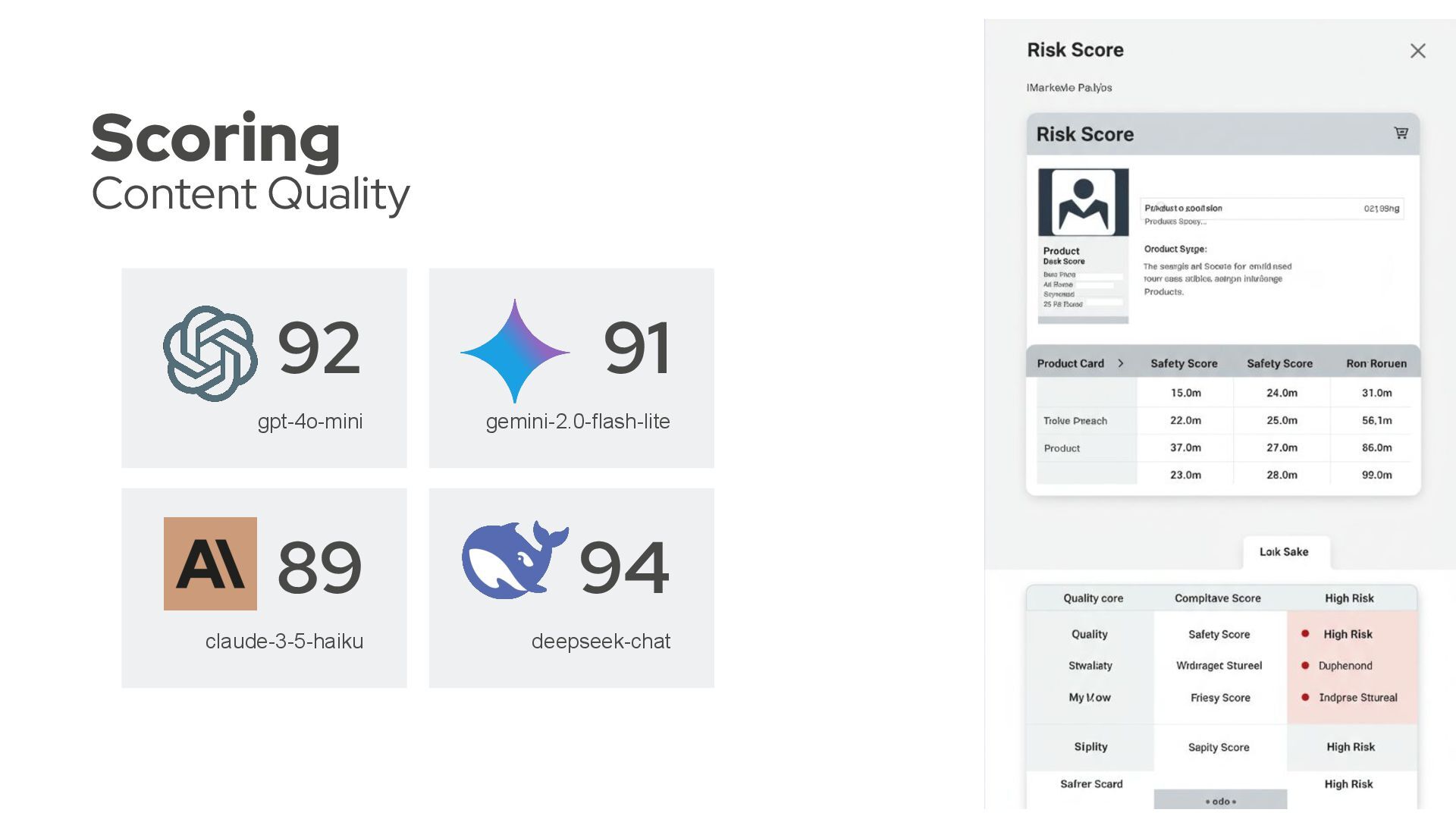
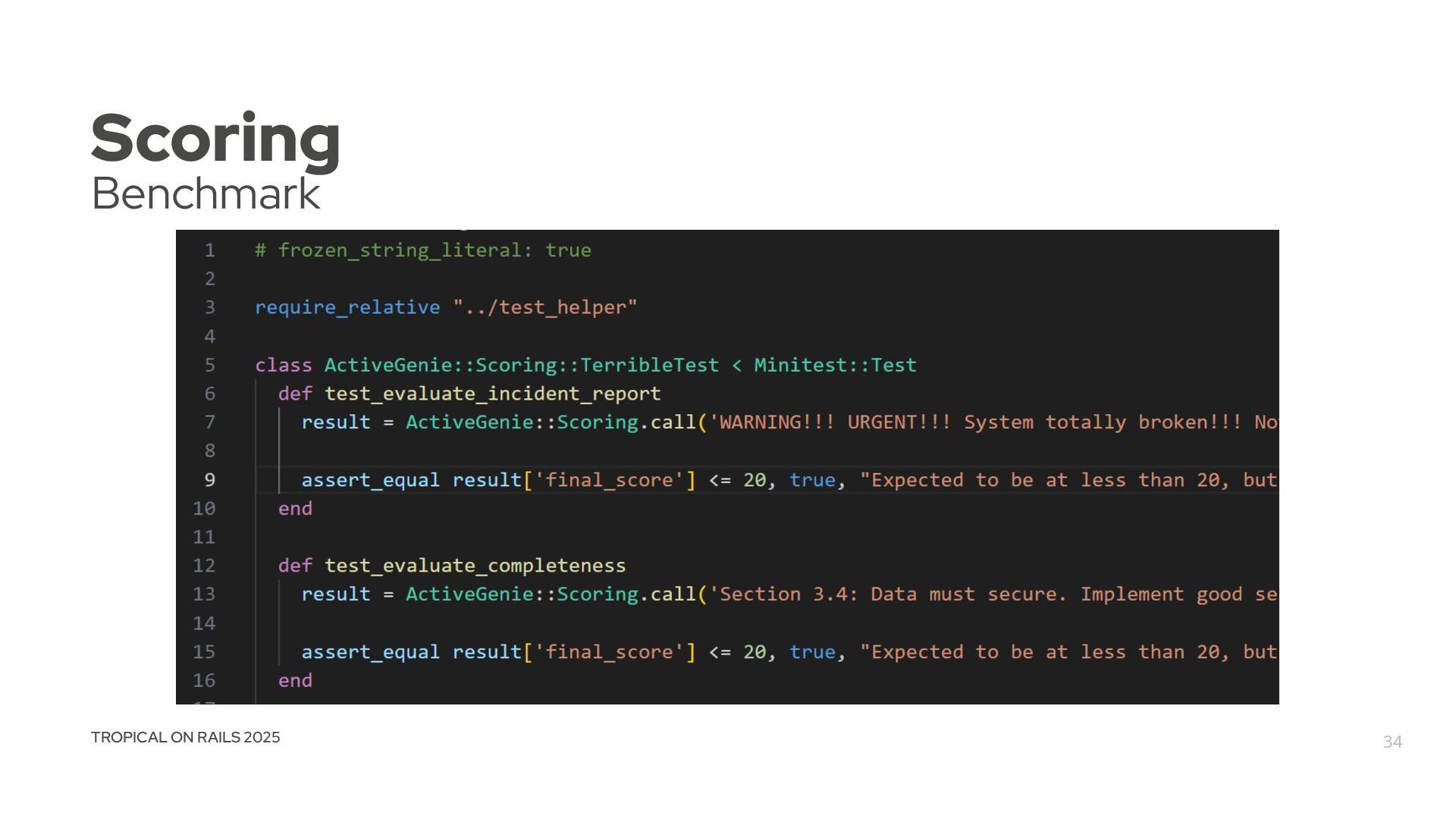
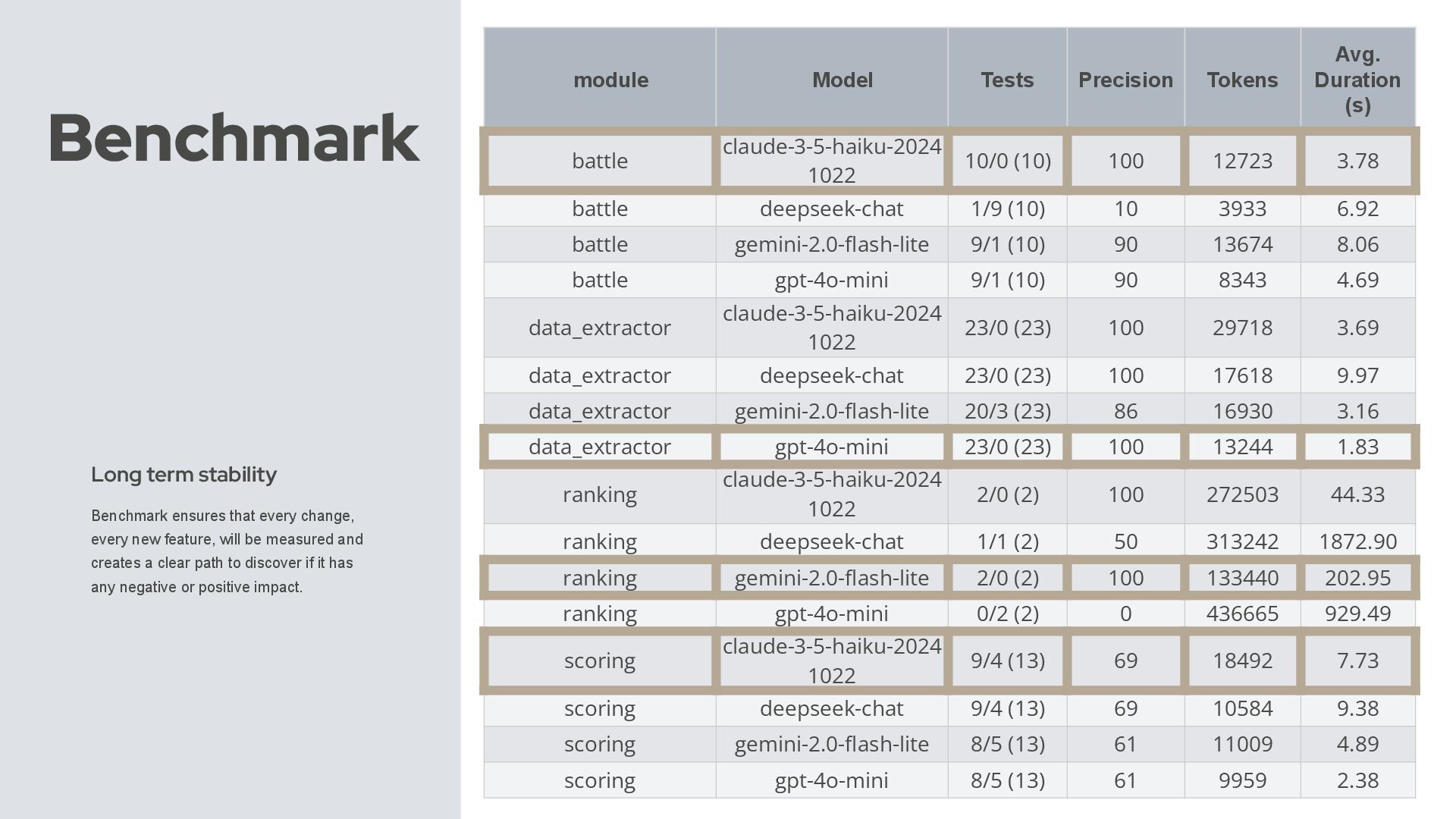
change, every new feature, will be measured and creates a clear path to discover if it has any negative or positive impact. Model Tests Precision Tokens Avg. Duration (s) claude-3-5-haiku-20241 022 10/0 (10) 100 12.723,00 3.78 deepseek-chat 1/9 (10) 10 3.933,00 6.92 gemini-2.0-flash-lite 9/1 (10) 90 13.674,00 8.06 gpt-4o-mini 9/1 (10) 90 8.343,00 4.69
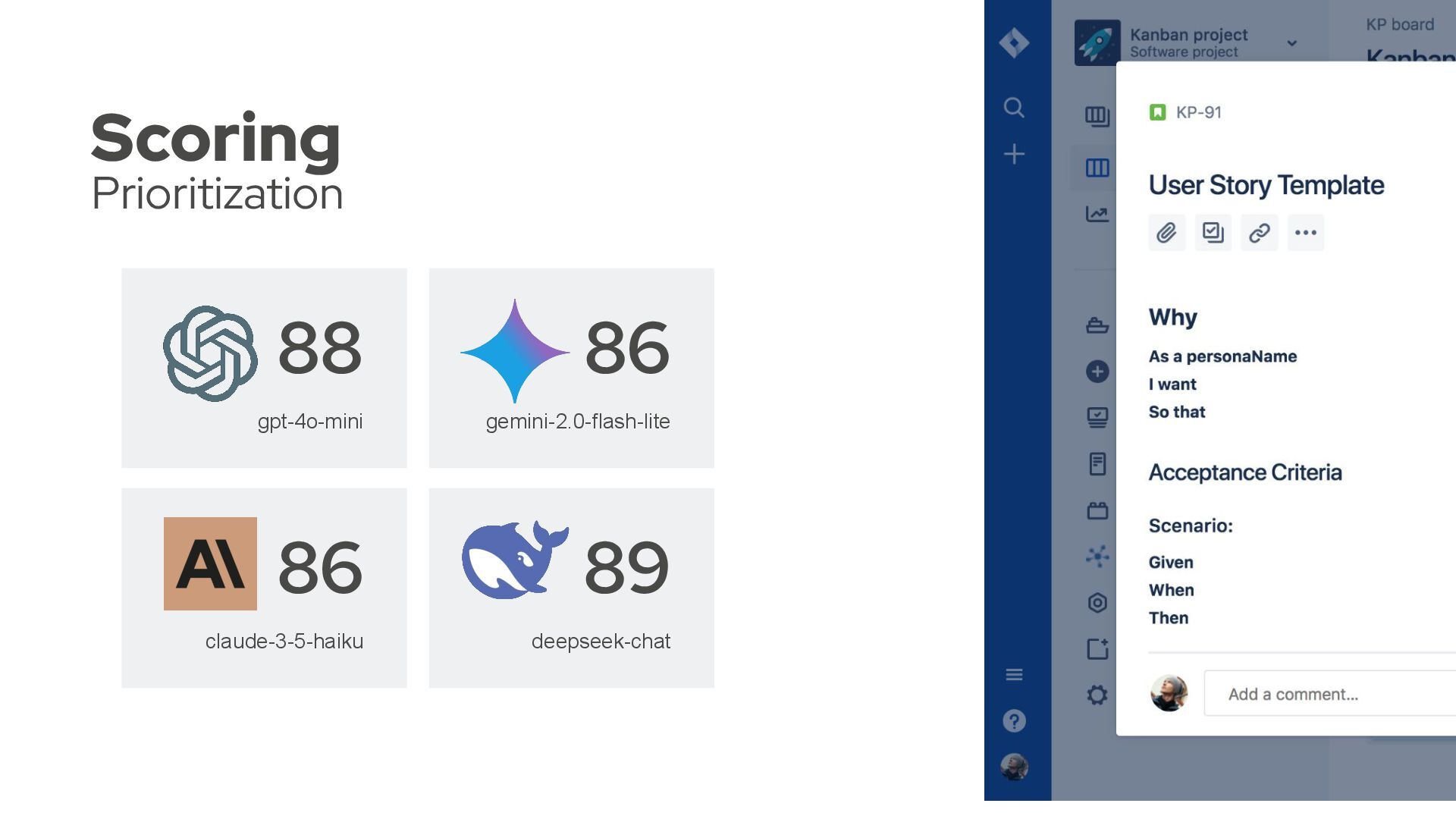
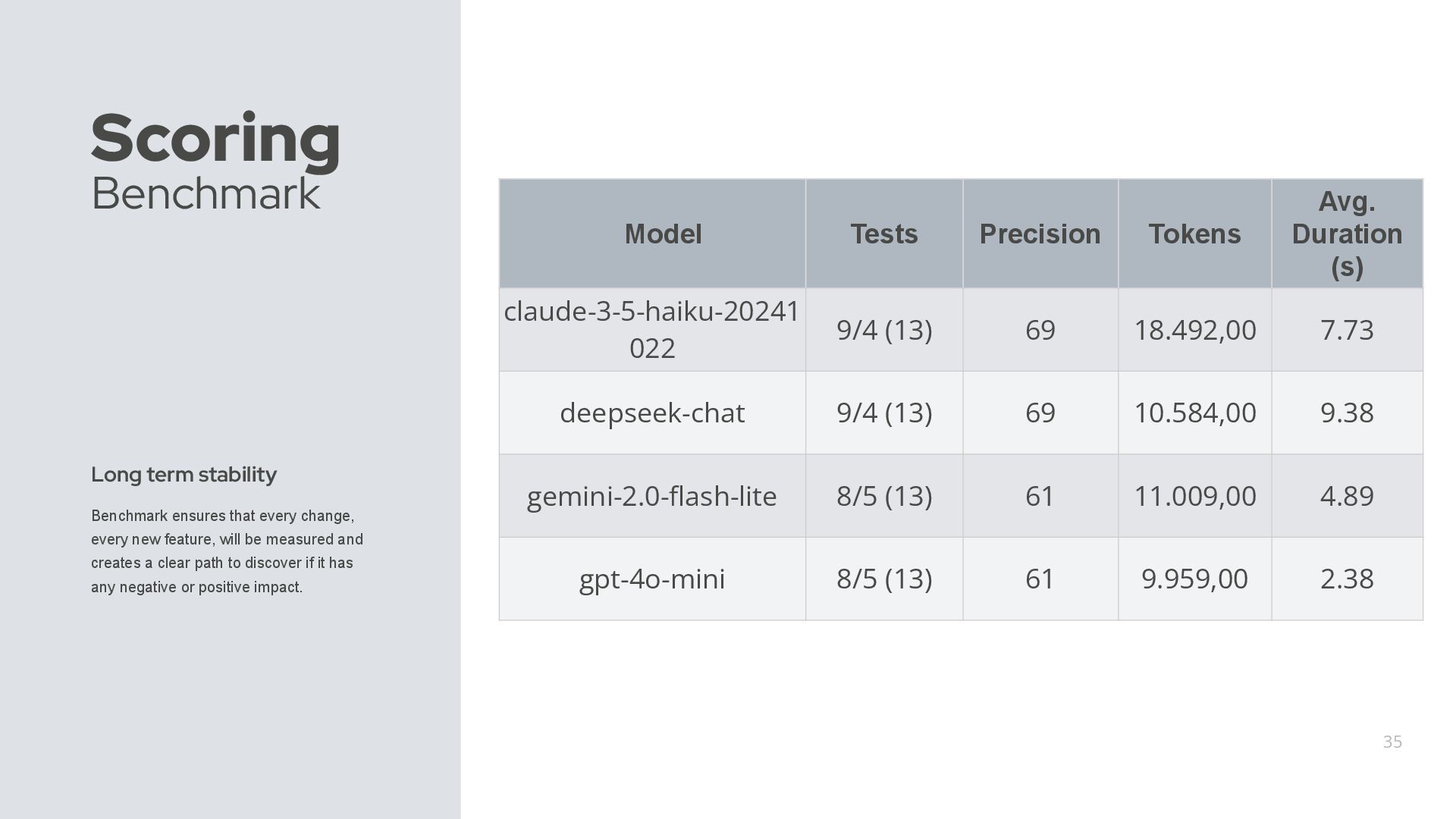
change, every new feature, will be measured and creates a clear path to discover if it has any negative or positive impact. Model Tests Precision Tokens Avg. Duration (s) claude-3-5-haiku-20241 022 9/4 (13) 69 18.492,00 7.73 deepseek-chat 9/4 (13) 69 10.584,00 9.38 gemini-2.0-flash-lite 8/5 (13) 61 11.009,00 4.89 gpt-4o-mini 8/5 (13) 61 9.959,00 2.38
are just tools . They mimic existing knowledge, while we build the future https://roriz.dev https://github.com/Roriz/active_genie https://www.linkedin.com/in/radames-roriz/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
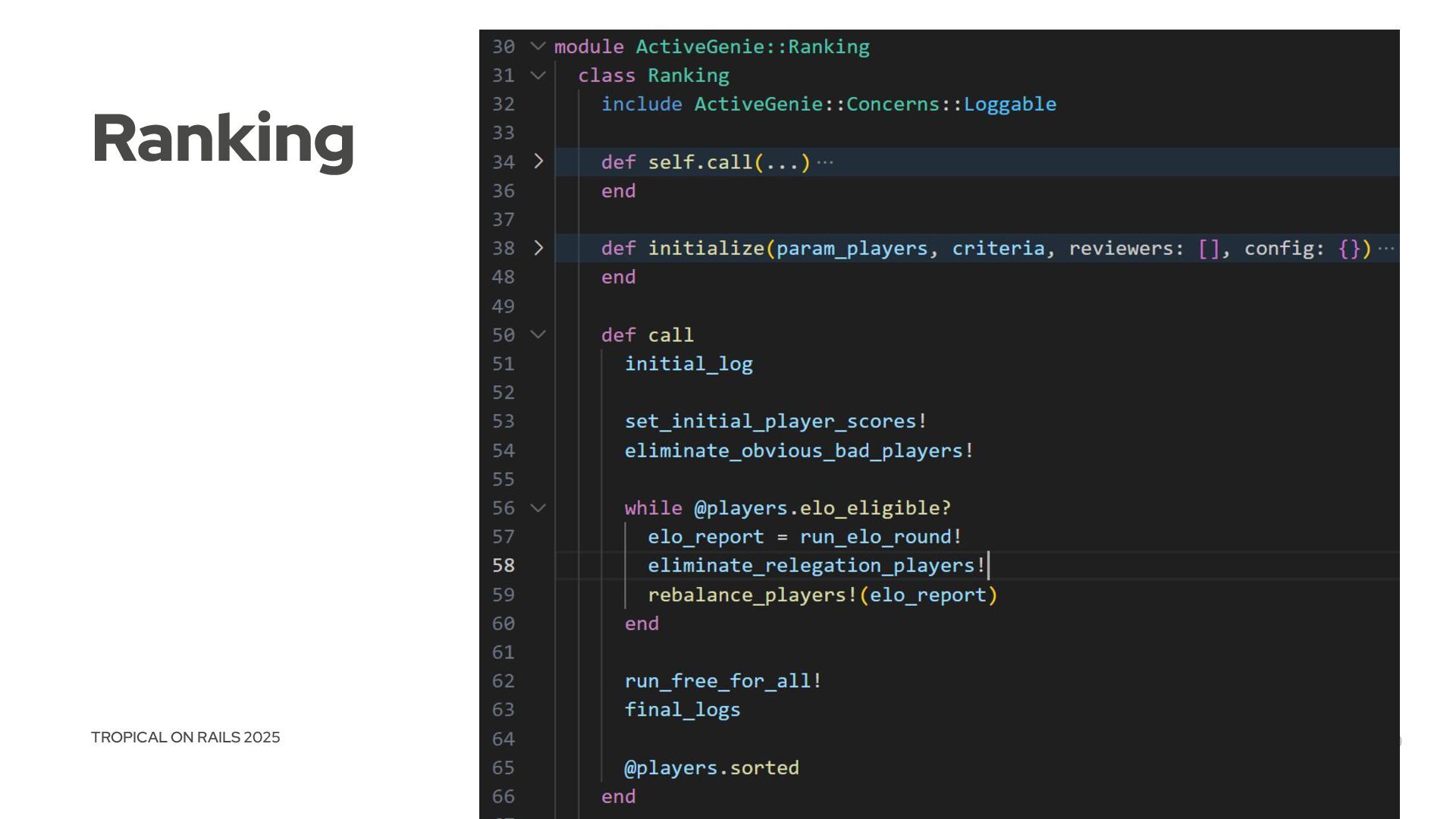{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
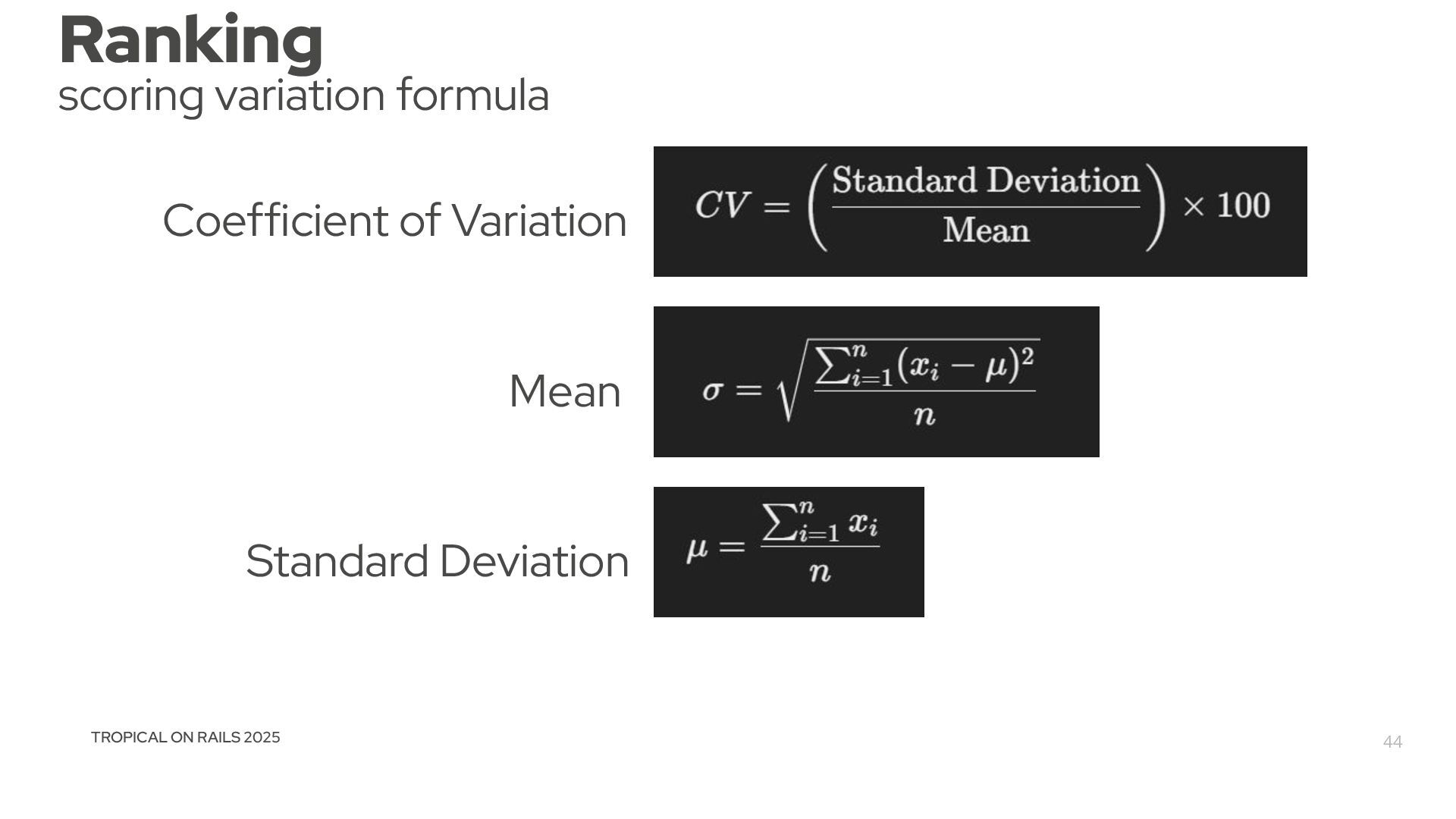{kind=link}
{kind=link}
{kind=link}
{kind=link}
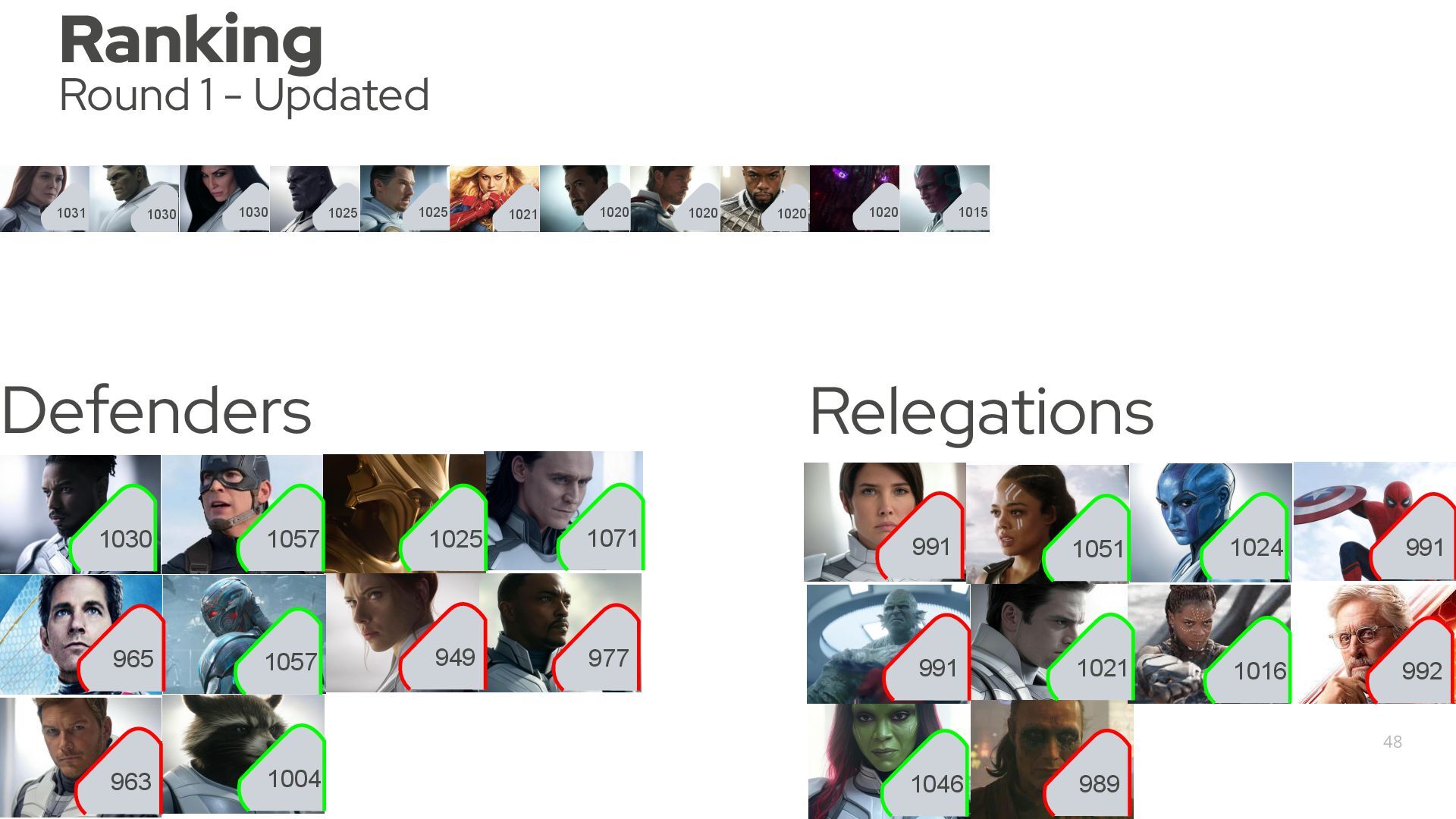{kind=link}
{kind=link}
{kind=link}
{kind=link}
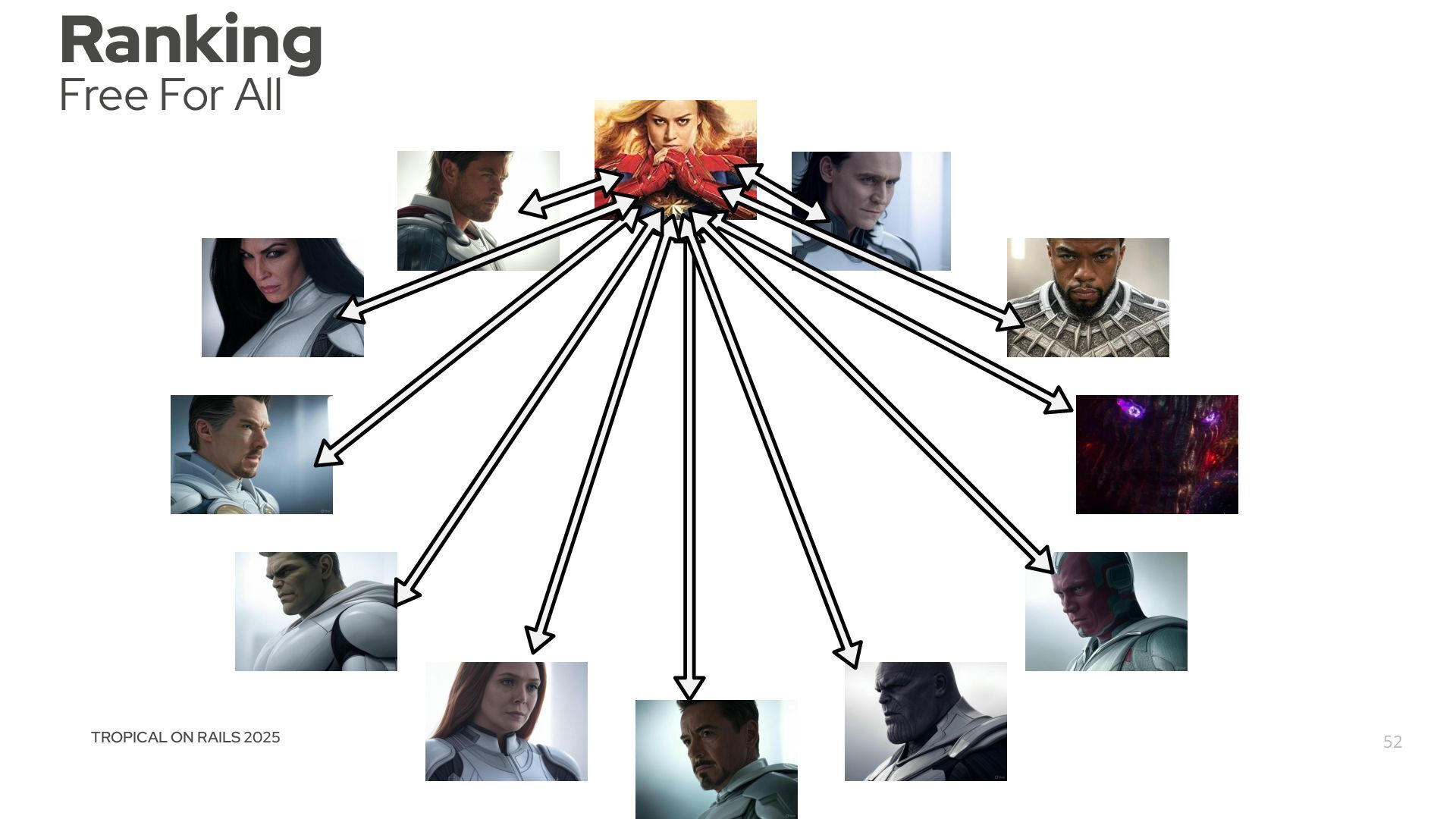{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}