Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Data Science Osaka Autumn 2024 -16th Place solu...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Ryushi
November 07, 2024
400
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Data Science Osaka Autumn 2024 -16th Place solution-
Ryushi
November 07, 2024
More Decks by Ryushi
See All by Ryushi
なぜ俺は銀メダルなのか 25th solutionから⾦メダルへとの差分考える「BirdCLEF2025振り返り」
ryushi496
2
950
ざっくりTabMを知る
ryushi496
1
650
UM - Game-Playing Strength of MCTS Variants 11th. Place solution
ryushi496
1
290
Featured
See All Featured
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Visualization
eitanlees
152
17k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
How to build a perfect <img>
jonoalderson
1
5.8k
Deep Space Network (abreviated)
tonyrice
0
220
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
870
Site-Speed That Sticks
csswizardry
13
1.2k
The SEO Collaboration Effect
kristinabergwall1
1
500
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Transcript
16th Place Solution Data Science Osaka Autumn 2024 Team :
H社
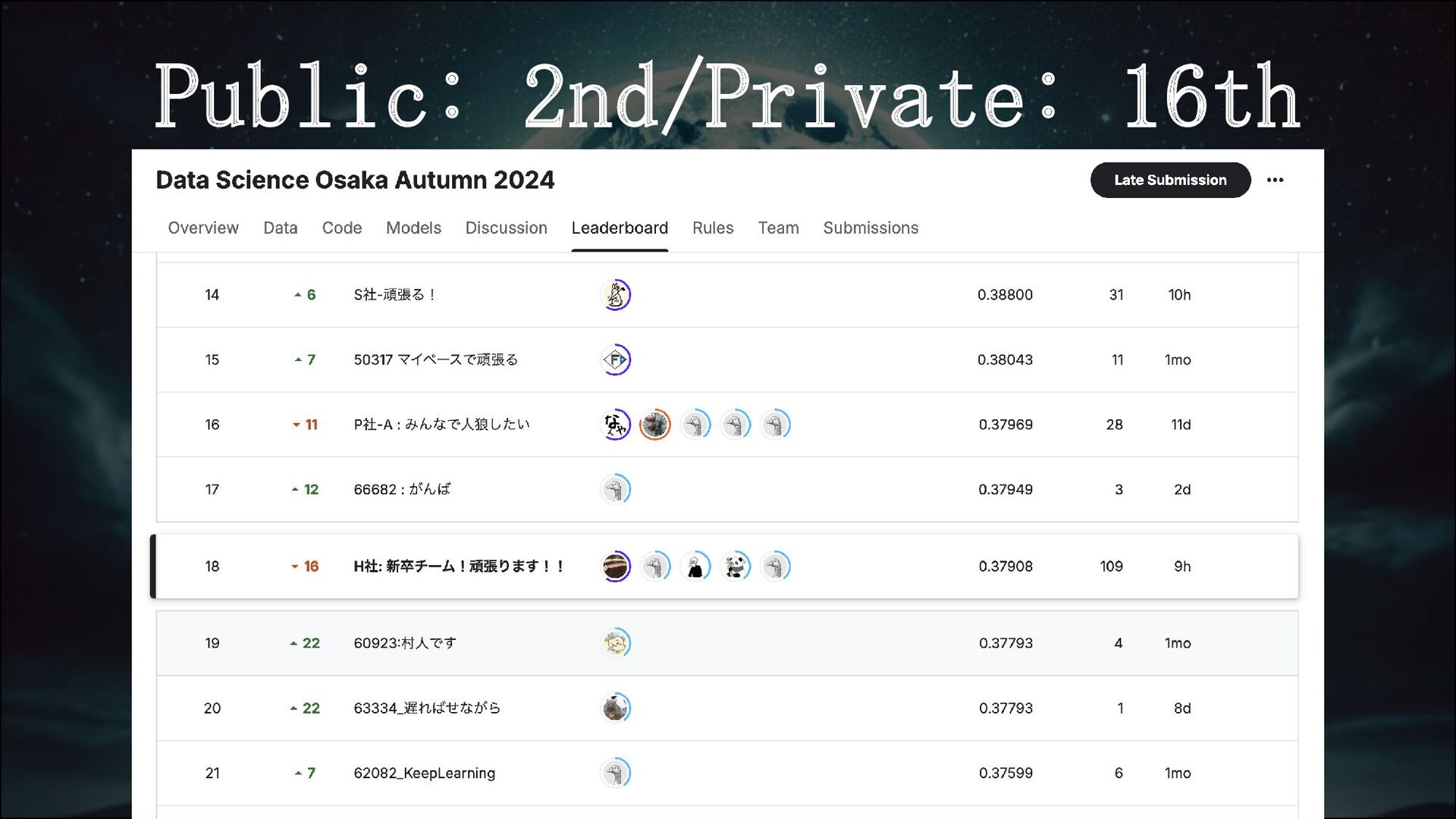
Public: 2nd/Private: 16th
概 要
LLMたちに人狼をプレイしてもらい “人狼のプレイヤー” と “勝利陣営(人狼チーム or 村人チーム)” を当てる
Data train/*. json 学習データ、各キャラクターの役職やその他内部情報、ゲームの結末まで含む。 test/*. json テストデータ、各キャラクターの役職やその他内部情報は含まず、ゲーム中の公 開情報のみ含む。また、4日目以降のデータは含まない 全部で150episodeあり、 train/public/privateで50episodeずつ
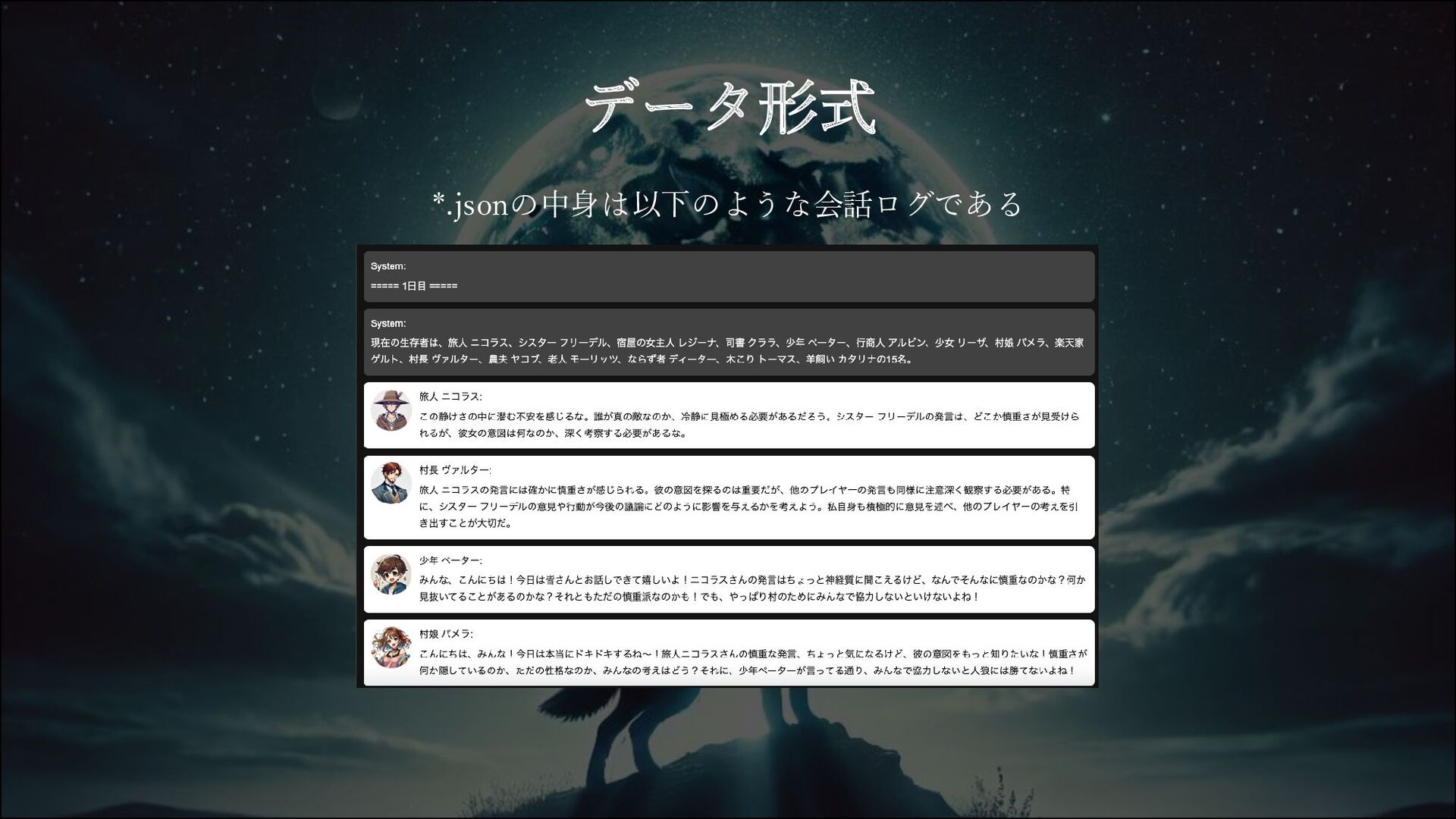
データ形式 *.jsonの中身は以下のような会話ログである
個性豊かなプレイヤー(LLM) 全員が日本語を話すわけではない アラビア語 …ヘブライ語… python… 他にも複数言語が存在 https://www.kaggle.com/competitions/data-science-osaka-autumn-2024/discussion/535420
Task 1. 人狼特定 2. 勝利陣営予測 “人狼陣営”か”村人陣営”のどちらが勝利したか予測 15名のプレイヤーの中に潜む3人の人狼を特定する 2つのTaskがある
評価方法 1. 人狼特定 正解率をスコア化 2つのTaskがある 2. 勝利陣営予測 実際の結果と予測確率の間の 正規化ジニ係数 3人正解
: 1.0 2人正解 : 0.66667 1人正解 : 0.33333 0人正解 : 0.0
評価方法 1. 人狼特定 正解率をスコア化 2つのTaskがある 2. 勝利陣営予測 実際の結果と予測確率の間の 正規化ジニ係数 3人正解
: 1.0 2人正解 : 0.66667 1人正解 : 0.33333 0人正解 : 0.0
16th Place Solution
Task1 : 人狼特定
概 要 ルールベース Logistic Regression
概 要 ルールベース Logistic Regression
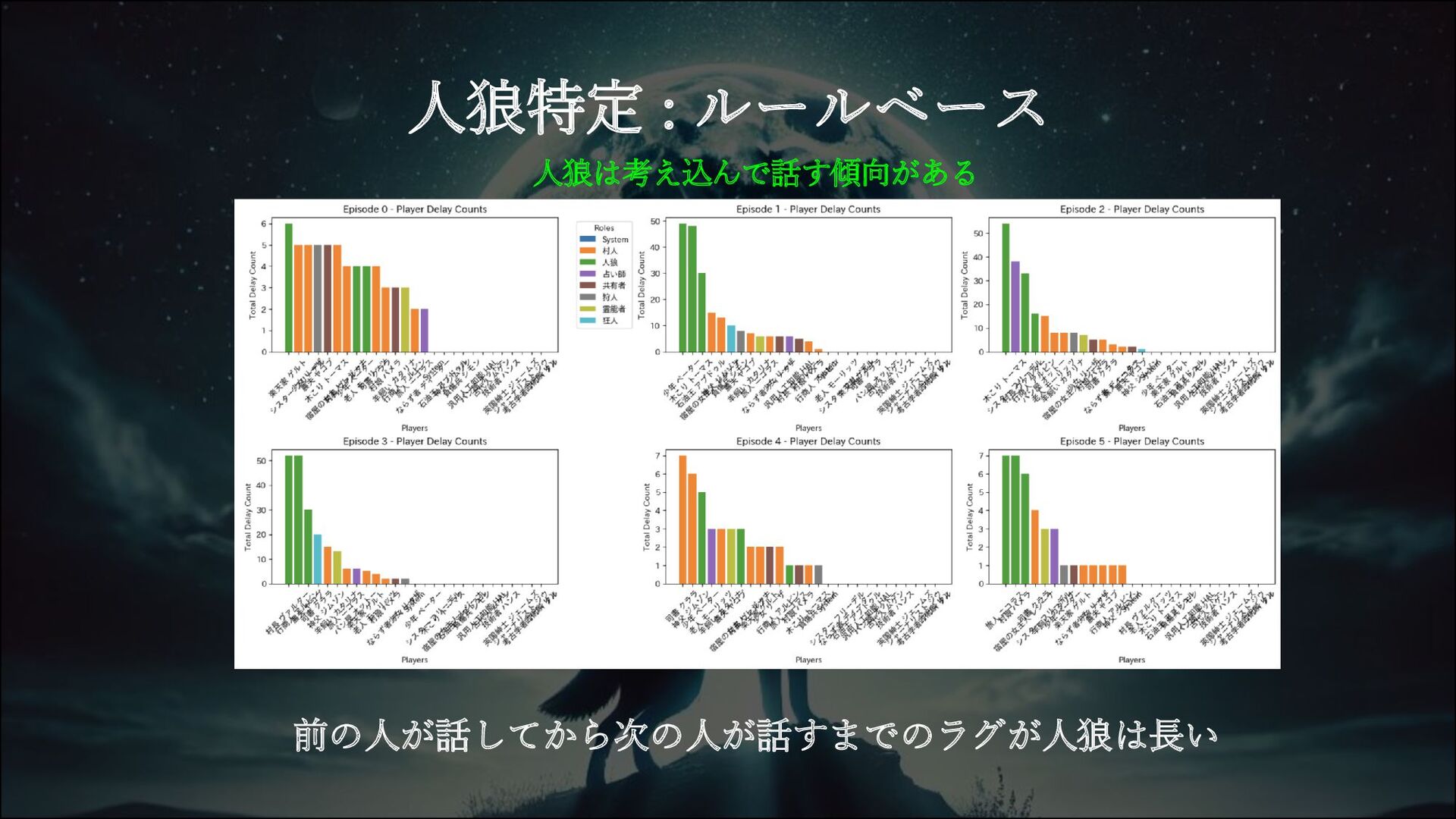
人狼特定 : ルールベース 人狼は考え込んで話す傾向がある 前の人が話してから次の人が話すまでのラグが人狼は長い
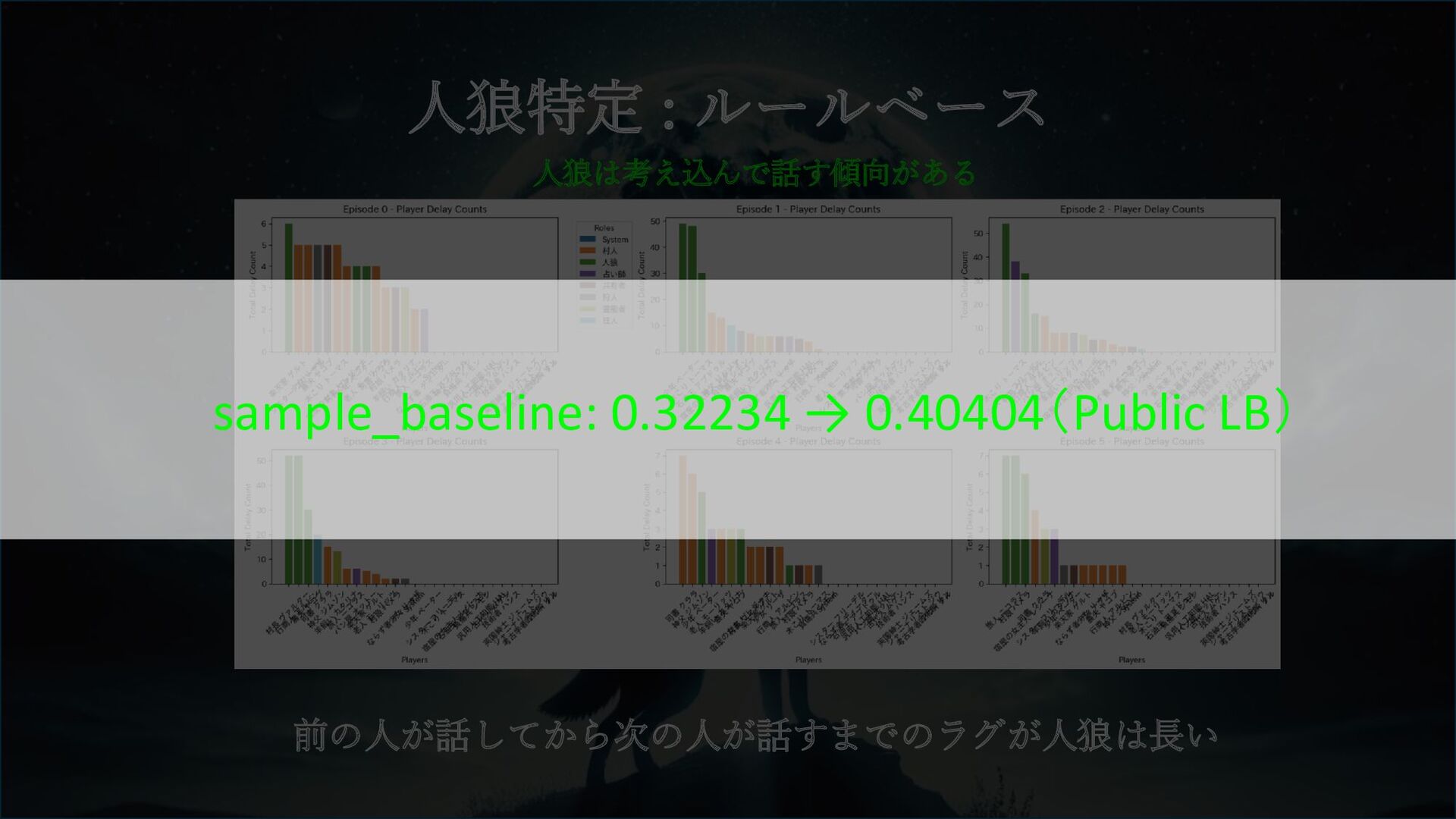
人狼特定 : ルールベース 人狼は考え込んで話す傾向がある 前の人が話してから次の人が話すまでのラグが人狼は長い sample_baseline: 0.32234 → 0.40404(Public LB)
概 要 ルールベース Logistic Regression
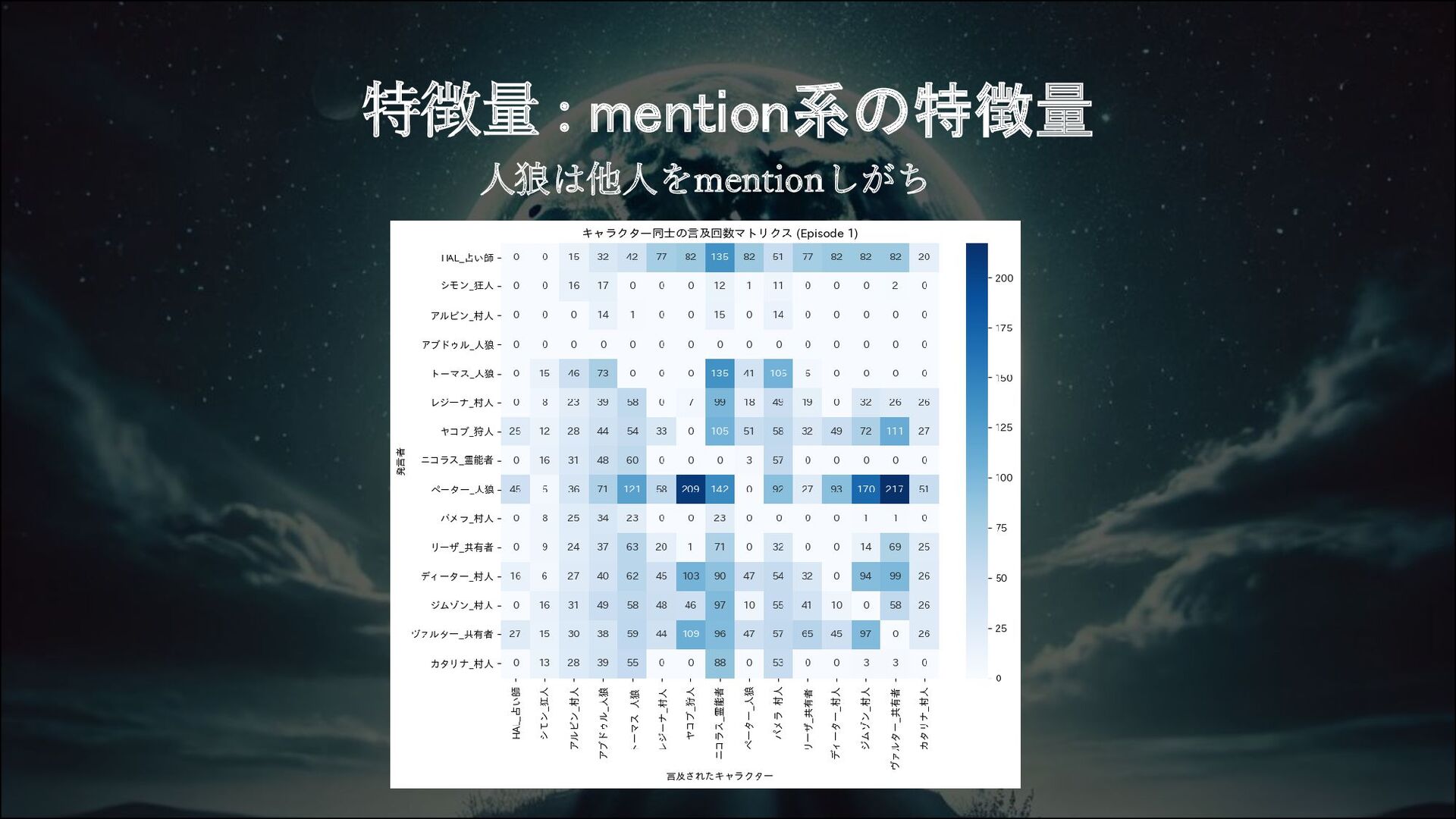
特徴量 mention系の特徴量 Multilingual-E5-largeによる埋め込み特徴量 Player label Qwen2 32Bによる予測値特徴
特徴量 : mention系の特徴量 人狼は他人をmentionしがち
特徴量 : mention系の特徴量 mentionを使った複数の特徴量を生成 1. Player名をカタカナで代表させる 2. publicのそれぞれのセリフ中のPlayer名をカウント この結果を特徴量として加える (例)老人
モーリッツ -> モーリッツ 3. uniqueな”episode_number” ,“player”ごとに2.を合計 Publicデータに対して適応し、この結果を特徴量として加える
特徴量 Multilingual-E5-largeによる埋め込み特徴量 Player label Qwen2 32Bによる予測値特徴 tfidfを多言語対応のMultilingual-E5-largeに変更した - 文頭に「query: 」をつけ、モデル用のinputに揃えて入力
- 出力された1024次元のベクトルを1次元ずつ特徴量として追加 playerごとにセリフの傾向があったので、単純な識別としてlabel encoding追加 vLLMの公開ノートブックの結果をpseude labelingとして使用 し、以下2つを特徴量とした - それぞれのセリフの人狼らしさ評価最大値を人狼予測としたもの - それぞれのセリフの人狼らしさ評価平均値を人狼予測としたもの
学習 CV戦略 学習データ 5fold stratified k-fold - episode_numberでfold cut Testに合わせて3日目まで使用
Loss function roc-auc score
人狼特定 : その他 “ムゲン”は人狼固定 夜中に襲撃されたキャラは含めない 様々なdiscussionに書いてありましたが、”ムゲン”は人狼率100%だったので 固定した - 終了後のネタバラシで正しい仮説だったことがわかった 3日目までに襲撃されたキャラは確実に人狼ではないので除外
Task2 : 勝利陣営予測
Model 学習データ LightGBM + optuna CV戦略 5fold stratified k-fold -
勝利陣営でfold cut Testに合わせて3日目まで使用 勝利陣営予測 : 概要 人狼が完全にわかっていることを前提に勝率予測モデルを構築
特徴量 死んでいる人狼の数 処刑回数 人狼に襲撃された回数 人狼が日中の議論で言及された回数 人狼以外が、日中の議論で言及された回数
反省
上位との差 : 多言語対応 Ours : Multilingual-E5-largeによる埋め込み特徴量 4th :直接の翻訳が上手くいかなかったため、英語を経由した。 (韓国語→英語→日本語) 3rd
:日本語でないメッセージは英語に翻訳、ほぼ日本語→tfidf vectorizer 多言語対応の丁寧さの差
上位との差 : 勝率予測のpublic overfit publicでは精度が下がる全件予測が、 privateでは大幅に精度が上がっていた 全件適用した場合 private 2nd相当 Last
subで信用した予測値
16th Place Solution Data Science Osaka Autumn 2024 Team :
H社
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}