Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Yokozuna: Scaling Solr With Riak
Search
Ryan Zezeski
June 04, 2013
Programming
1.7k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Yokozuna: Scaling Solr With Riak
Ryan Zezeski
June 04, 2013
More Decks by Ryan Zezeski
See All by Ryan Zezeski
Yokozuna, Distributed Search You Don't Think About
rzezeski
4
870
Other Decks in Programming
See All in Programming
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
120
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
霧の中の代数的エフェクト
funnyycat
1
260
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
0
130
これからAgentCoreを触る方へ トレンドはGatewayです
har1101
6
480
Signal Forms: Details & Live Coding @enterJS 2026 in Mannheim
manfredsteyer
PRO
0
220
Contextとはなにか
chiroruxx
1
390
そのテスト、説明できますか?~LWテスト戦略FW~のご紹介
nakahara
0
200
使用 Meilisearch 建立新聞搜尋工具
johnroyer
0
100
フィードバックで育てるAI開発
kotaminato
1
100
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
0
400
Go1.27で導入されるジェネリクスメソッドでできること
mackee
0
250
Featured
See All Featured
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
460
The untapped power of vector embeddings
frankvandijk
2
1.8k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
A Soul's Torment
seathinner
6
3k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Designing Powerful Visuals for Engaging Learning
tmiket
1
440
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.3k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
Transcript
Yokozuna, Scaling Solr With Riak Ryan Zezeski Berlin Buzzwords -
June 4th 2013 1
WHO AM I? • DEVELOPER @ BASHO TECHNOLOGIES • PREVIOUS
@ AOL FOR ADVERTISING.COM • MOST EXPERIENCE IN JAVA & ERLANG • 2+ YEARS WORKING ON SEARCH • @RZEZESKI ON TWITTER 2
NOT TALKING ABOUT SEARCH 3
AGENDA • OVERVIEW OF RIAK & YOKOZUNA • DATA PARTITIONING
& OWNERSHIP • HIGH AVAILABILITY & CONSISTENCY • SELF HEALING (ANTI ENTROPY) • DEMOS 4
WHAT IS RIAK? • KEY-VALUE STORE (+ SOME EXTRAS) •
DISTRIBUTED • HIGHLY AVAILABLE • MASTERLESS • EVENTUALLY CONSISTENT • SCALE UP/DOWN 5
DATABASE • KEY/VALUE MODEL • BASIC SECONDARY INDEX SUPPORT •
MAP/REDUCE (NOT LIKE HADOOP) • SEARCH (YOKOZUNA/SOLR) 6
DISTRIBUTED • MANY NODES IN LAN • RECOMMEND STARTING WITH
5 • ENTERPRISE REPLICATION CAN SPAN WAN 7
HIGH AVAILABILITY • ALWAYS TAKE WRITES • ALWAYS SERVICE READS
• FAVORS YIELD OVER HARVEST • IMPLIES EVENTUAL CONSISTENCY 8
MASTERLESS • NO NOTION OF MASTER OR SLAVE • ANY
NODE MAY SERVICE READ/WRITE/ QUERY 9
EVENTUALLY CONSISTENT • READS CAN BE STALE • CONCURRENT WRITES
CAN CAUSE SIBLINGS • EVENTUALLY VALUES CONVERGES 10
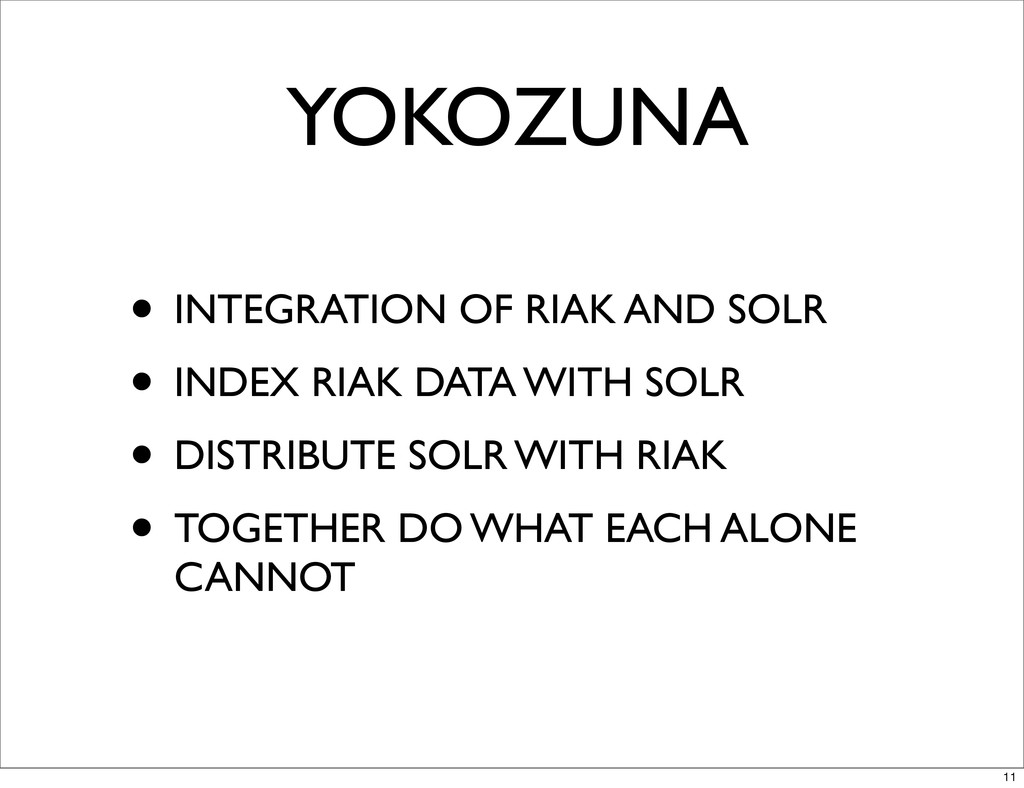
YOKOZUNA • INTEGRATION OF RIAK AND SOLR • INDEX RIAK
DATA WITH SOLR • DISTRIBUTE SOLR WITH RIAK • TOGETHER DO WHAT EACH ALONE CANNOT 11
YOKOZUNA • EACH NODE RUN A LOCAL SOLR INSTANCE •
CREATE AN INDEX SAME AS BUCKET NAME • DOCUMENT IS “EXTRACTED” FROM VALUE • SUPPORTS PLAIN TEXT, XML, AND JSON • SOLR CELL SUPPORT COMING SOON 12
YOKOZUNA • SUPPORTS “TAGGING” • USE SOLR QUERY SYNTAX •
PARAMETERS PASSED VERBATIM • IF DISTRIBUTED SEARCH SUPPORTS IT - YOKOZUNA SUPPORTS IT • NO SOLR CLOUD INVOLVED 13
PARTITIONING & OWNERSHIP Aufteilen & Eigentum 14
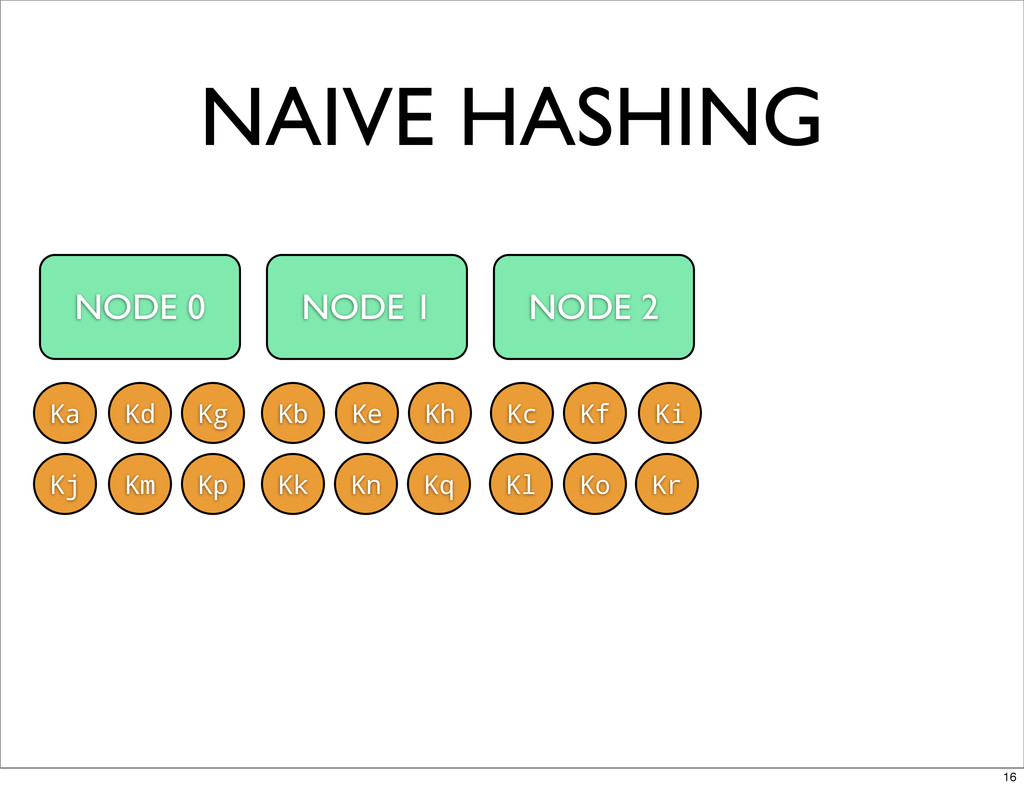
NAIVE HASHING NODE # = HASH(KEY) % NUM_NODES NH(Ka) =
0 NH(Kb) = 1 NH(Kc) = 2 NH(Kd) = 0 ... 15
NAIVE HASHING NODE 0 NODE 1 NODE 2 Ka Kb
Kc Kd Ke Kf Kg Kh Ki Kj Kk Km Kl Kp Kn Ko Kq Kr 16
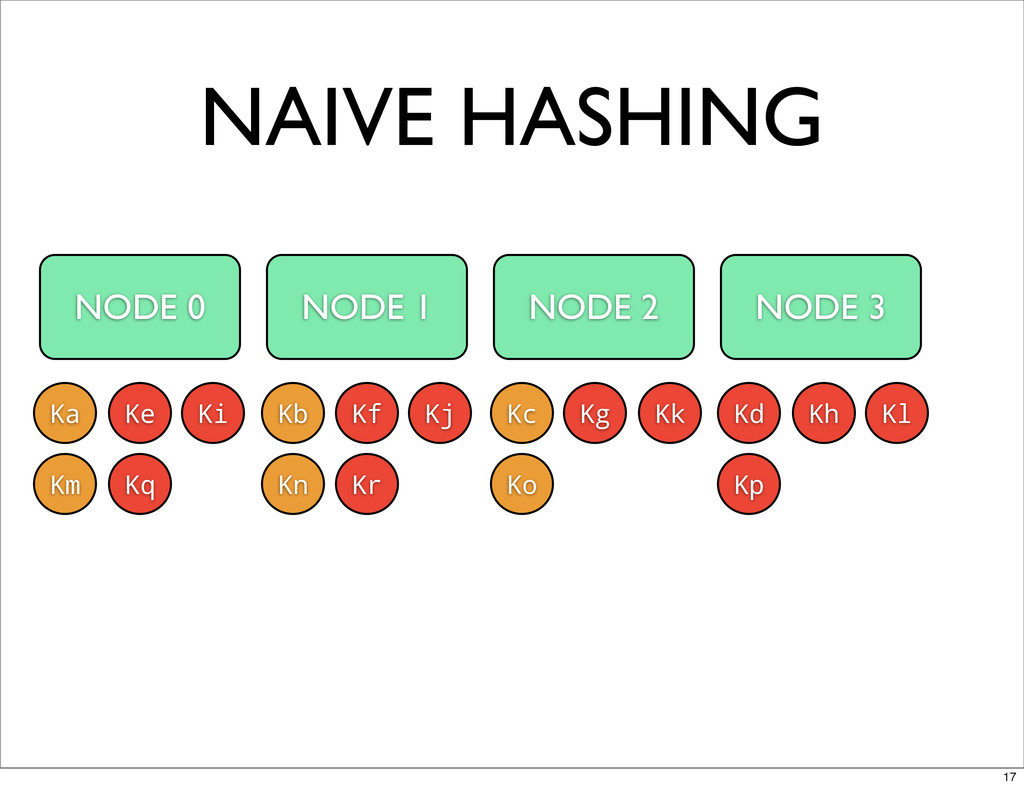
NAIVE HASHING NODE 0 NODE 1 NODE 2 Ka Kb
Kc Kd Kg Ki NODE 3 Ke Kf Kh Kj Kk Kl Km Kn Ko Kp Kq Kr 17
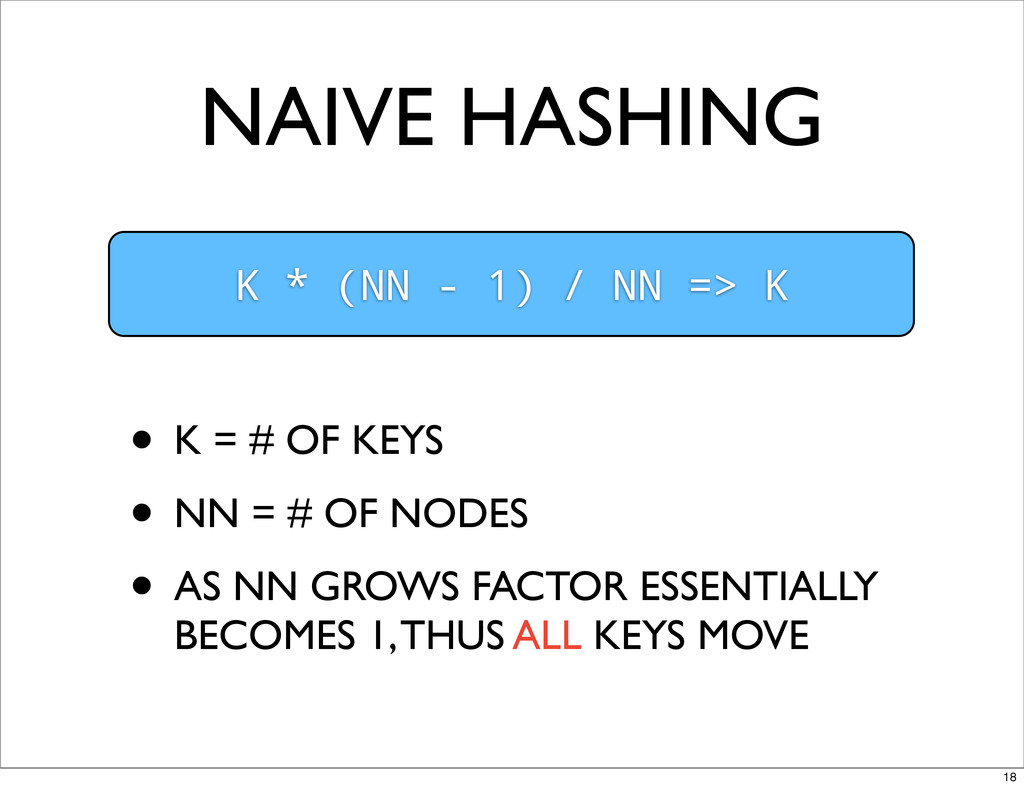
NAIVE HASHING K * (NN - 1) / NN =>
K • K = # OF KEYS • NN = # OF NODES • AS NN GROWS FACTOR ESSENTIALLY BECOMES 1, THUS ALL KEYS MOVE 18
CONSISTENT HASHING PARTITION # = HASH(KEY) % PARTITIONS • #
PARTITIONS REMAINS CONSTANT • KEY ALWAYS MAPS TO SAME PARTITION • NODES OWN PARTITIONS • PARTITIONS CONTAIN KEYS • EXTRA LEVEL OF INDIRECTION 19
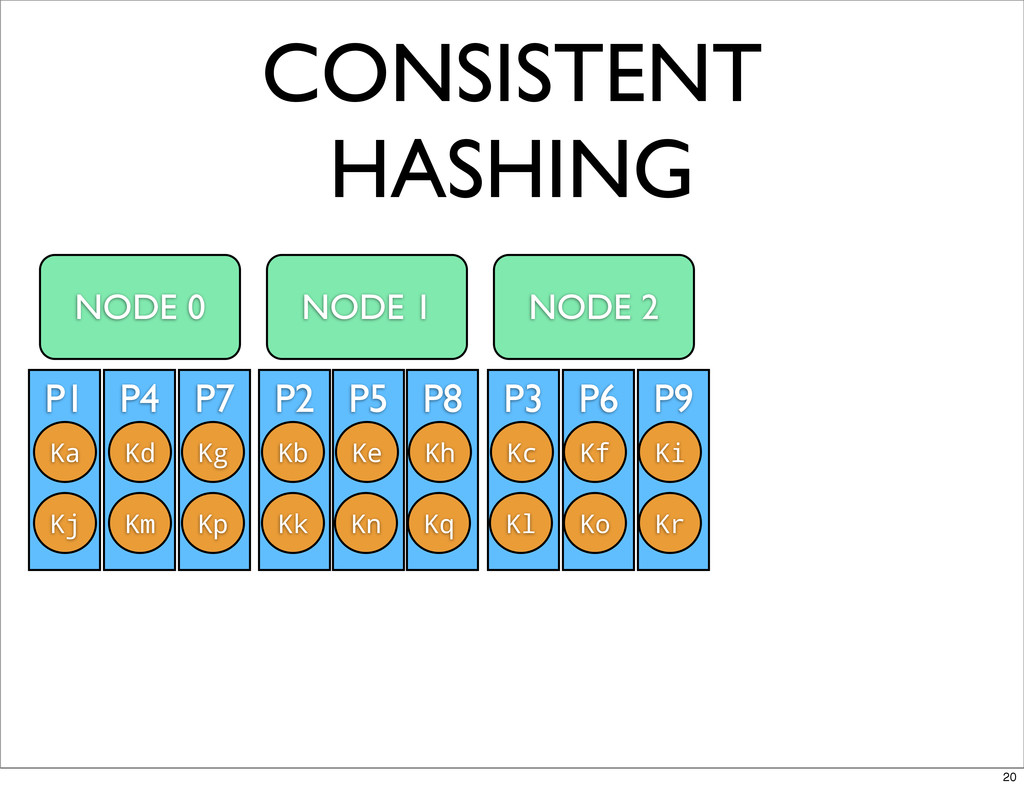
P9 P6 P3 P8 P5 P2 P7 P4 P1 CONSISTENT
HASHING NODE 0 NODE 1 NODE 2 Ka Kb Kc Kd Ke Kf Kg Kh Ki Kj Kk Km Kl Kp Kn Ko Kq Kr 20
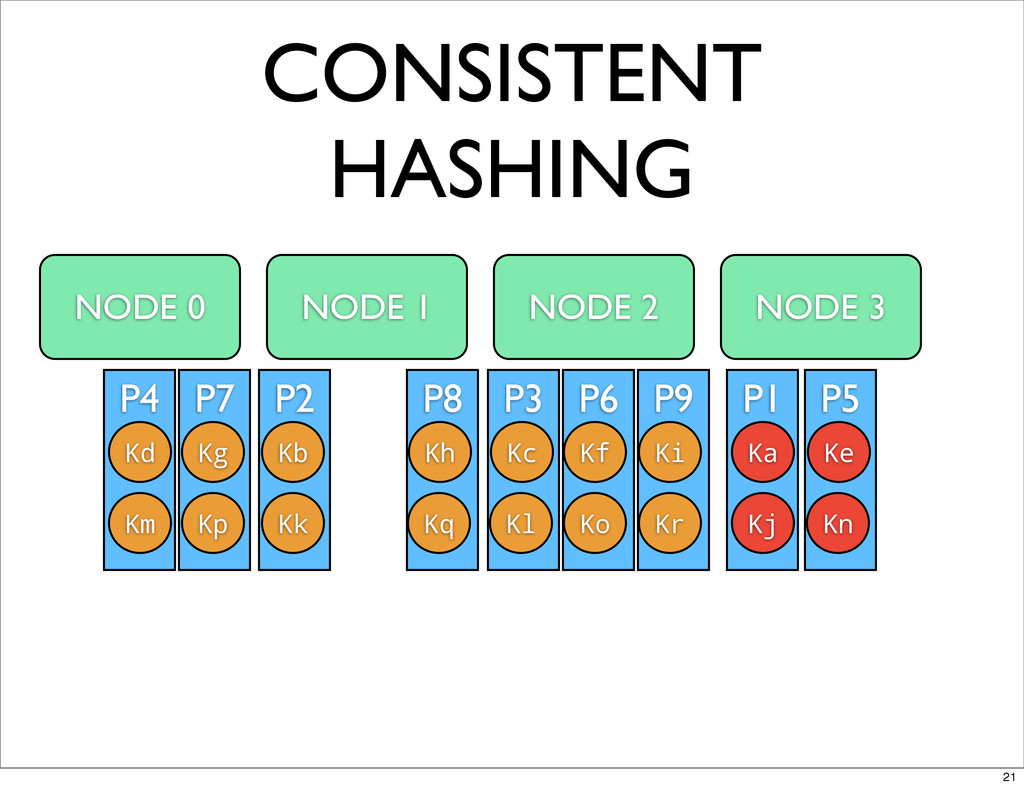
P9 P6 P3 P8 P5 P2 P7 P4 P1 CONSISTENT
HASHING NODE 0 NODE 1 NODE 2 Ka Kb Kc Kd Ke Kf Kg Kh Ki Kj Kk Km Kl Kp Kn Ko Kq Kr NODE 3 21
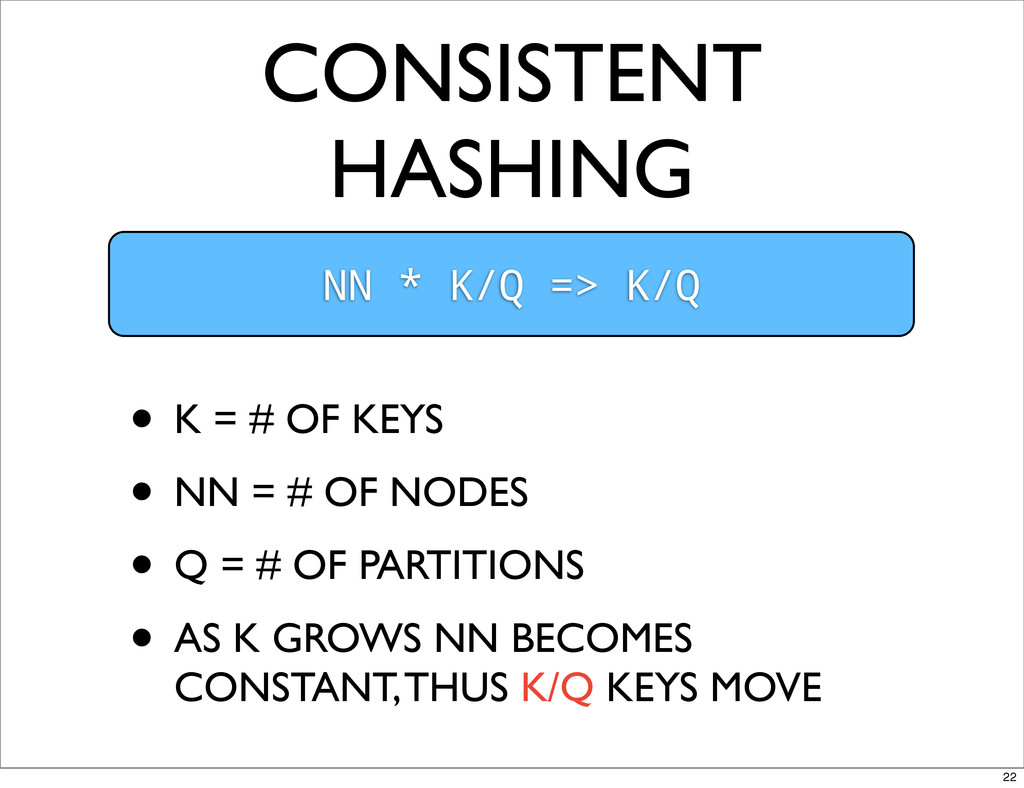
CONSISTENT HASHING NN * K/Q => K/Q • K =
# OF KEYS • NN = # OF NODES • Q = # OF PARTITIONS • AS K GROWS NN BECOMES CONSTANT, THUS K/Q KEYS MOVE 22
CONSISTENT HASHING • EVENLY DIVIDES KEYSPACE • LOGICAL PARTITIONING SEPARATED
FROM PHYSICAL PARTITIONING • UNIFORM HASH GIVES UNIFORM DISTRIBUTION 23
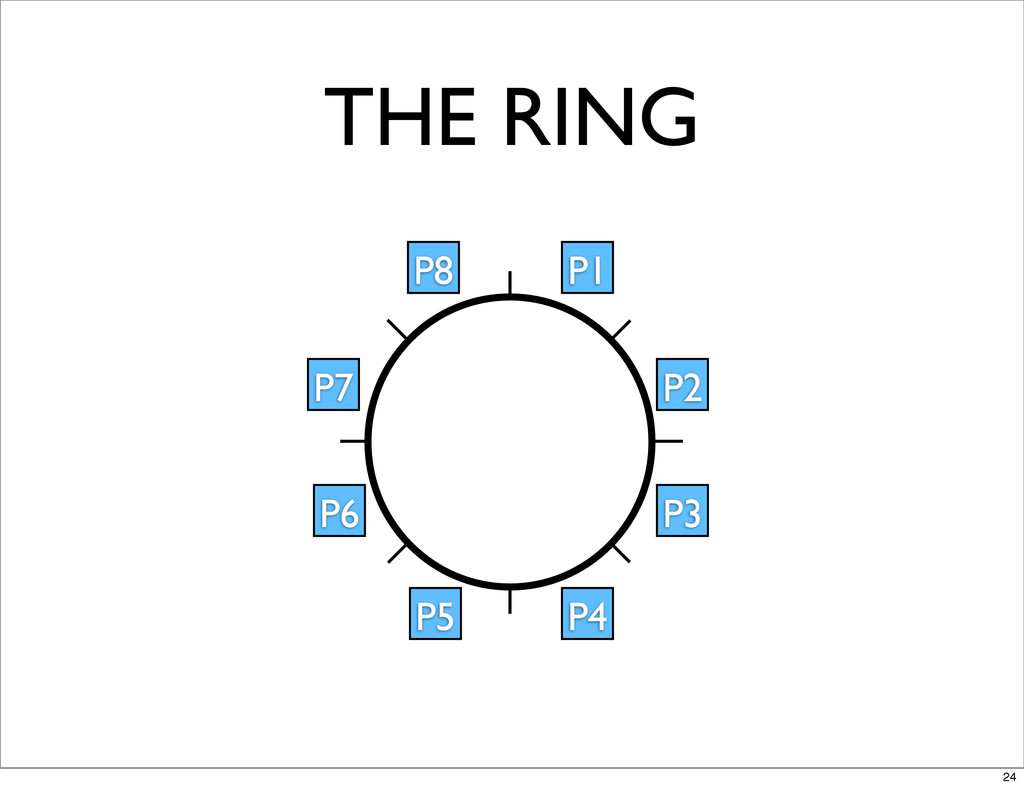
THE RING P1 P2 P3 P4 P5 P6 P7 P8
24
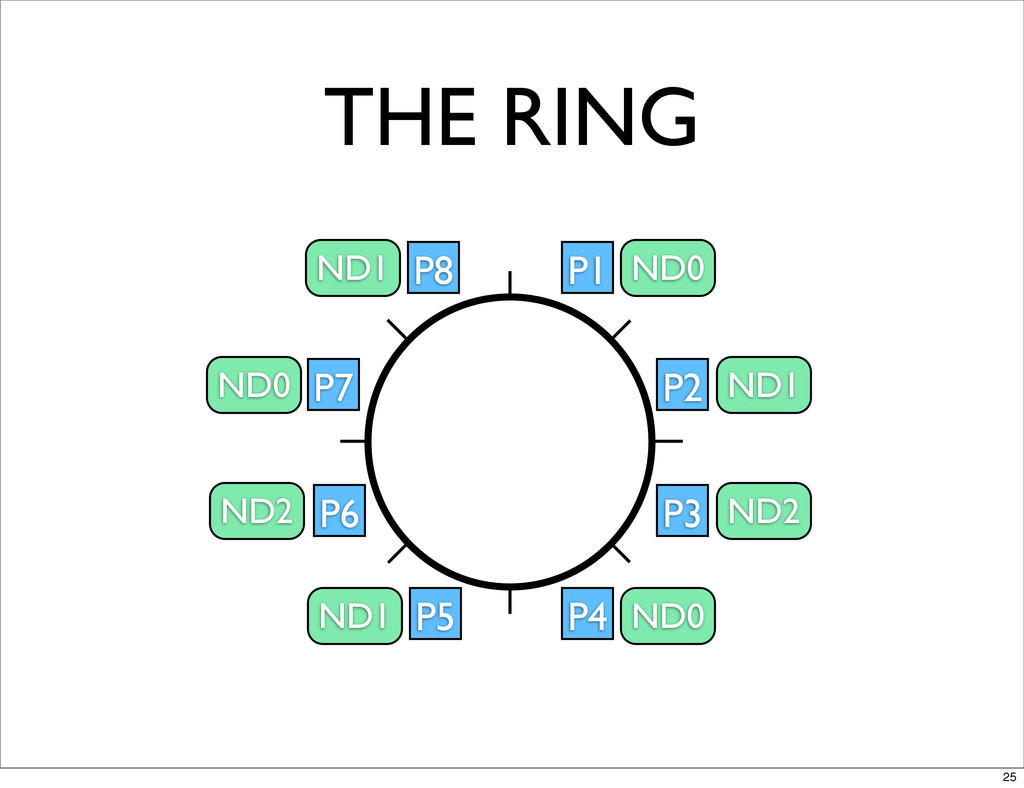
THE RING P1 P2 P3 P4 P5 P6 P7 P8
ND0 ND1 ND2 ND0 ND1 ND2 ND0 ND1 25
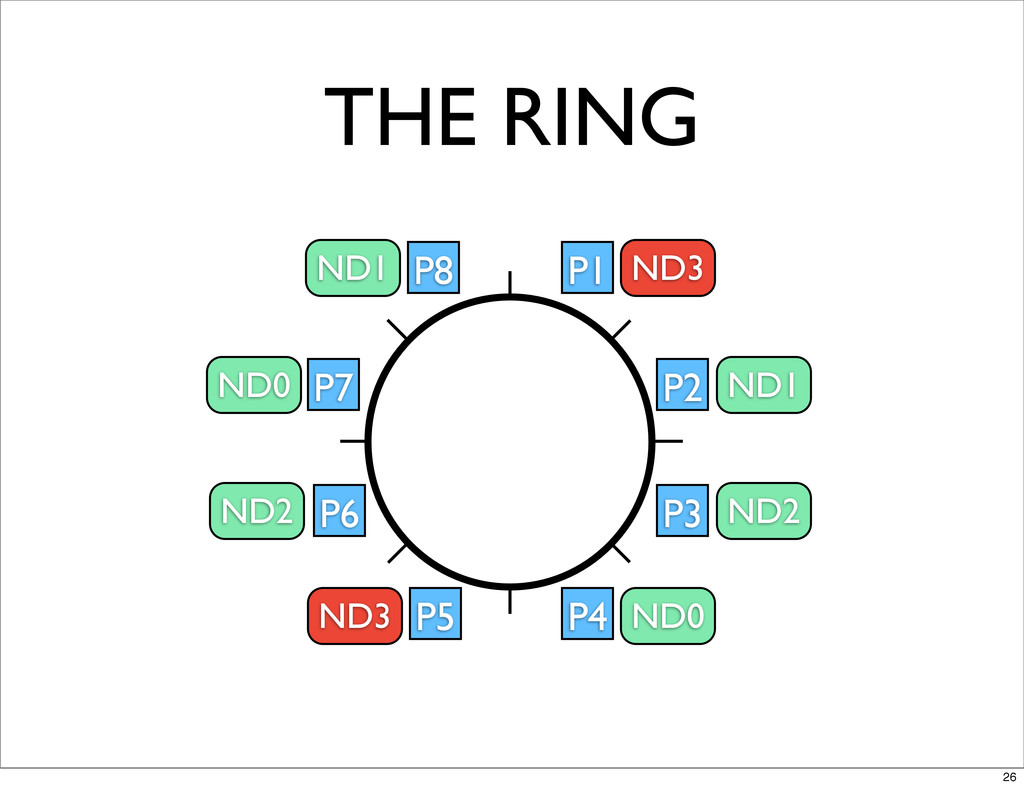
THE RING P1 P2 P3 P4 P5 P6 P7 P8
ND3 ND1 ND2 ND0 ND3 ND2 ND0 ND1 26
THE RING • GOSSIPED BETWEEN NODES • EPOCH CONSENSUS BASED
• MASTERLESS - ANY NODE CAN SERVICE ANY REQUEST 27
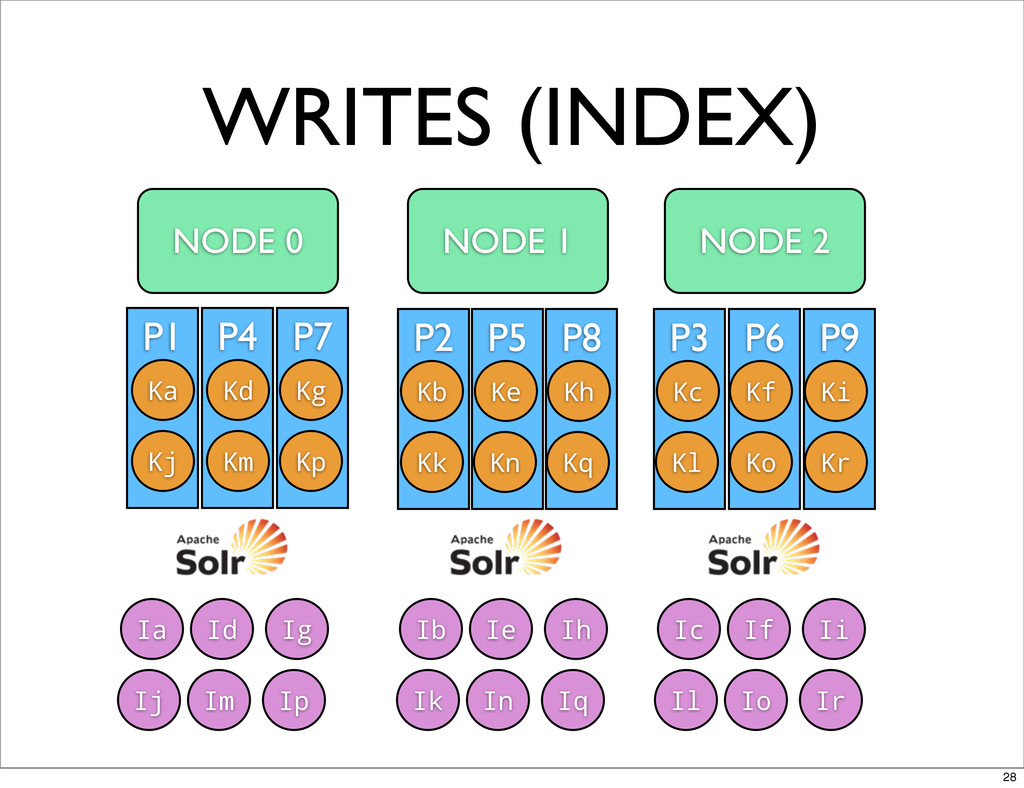
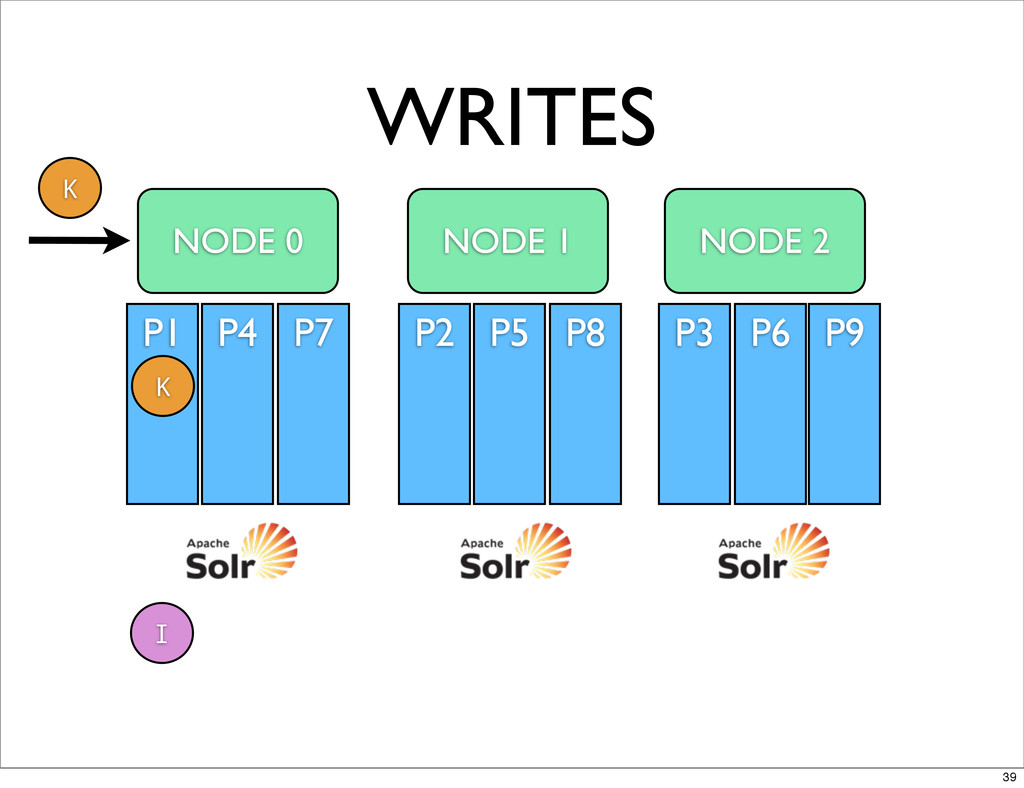
WRITES (INDEX) NODE 0 NODE 1 NODE 2 Ia Id
Ig Ij Im Ip Ib Ie Ih Ik In Iq Ic If Ii Il Io Ir P7 P4 P1 Ka Kd Kg Kj Km Kp P8 P5 P2 Kb Ke Kh Kk Kn Kq P9 P6 P3 Kc Kf Ki Kl Ko Kr 28
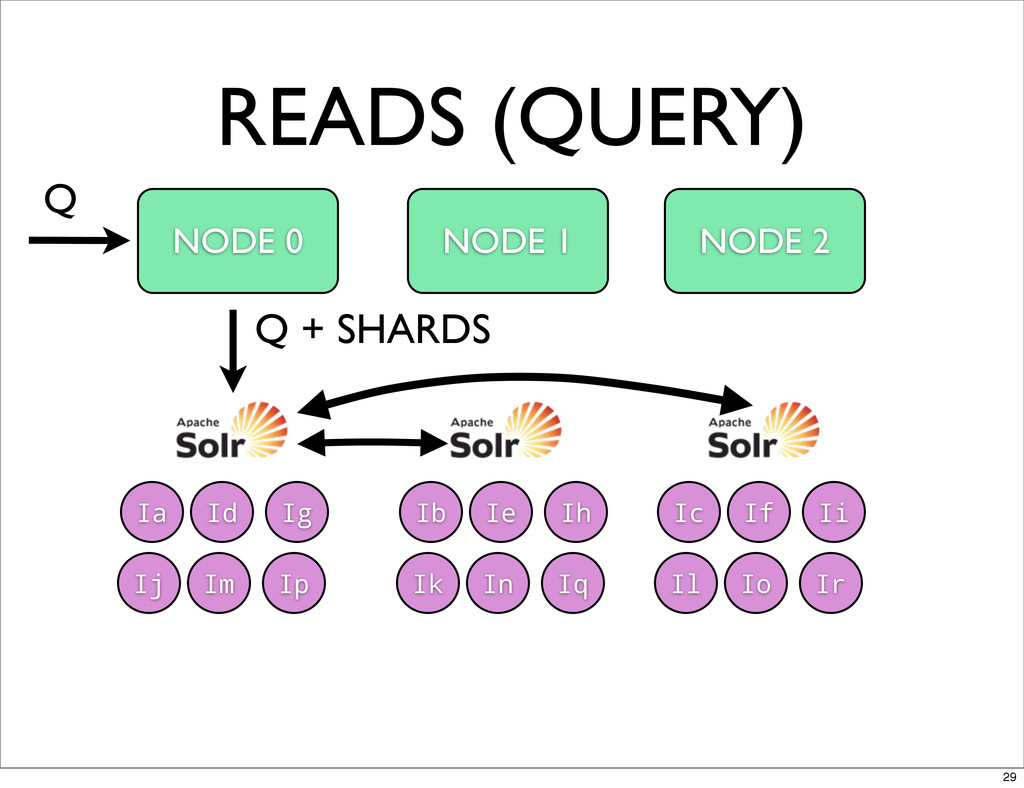
READS (QUERY) NODE 0 NODE 1 NODE 2 Ia Id
Ig Ij Im Ip Ib Ie Ih Ik In Iq Ic If Ii Il Io Ir Q Q + SHARDS 29
HIGH AVAILABILITY Hochverfügbarkeit 30
UPTIME IS A POOR METRIC 31
“IF THE SYSTEM IS ‘DOWN’ AND NO ONE MAKES A
REQUEST, IS IT REALLY DOWN?” ~ ME 32
HARVEST VS YIELD 33
YIELD QUERIES COMPLETED QUERIES OFFERED 34
HARVEST DATA AVAILABLE COMPLETE DATA 35
DURING FAILURE OR OVERLOAD - FOR A GIVEN QUERY -
YOU MUST DECIDE BETWEEN HARVEST OR YIELD 36
MAINTAIN HARVEST VIA REPLICATION 37
REPLICATION • N VALUE - # OF REPLICAS TO STORE
• DEFAULT OF 3 • MORE REPLICAS TRADES IOPS + SPACE FOR MORE HARVEST 38
P9 P8 P7 P6 P5 P4 P3 P2 P1 WRITES
NODE 0 NODE 1 NODE 2 K I K 39
P9 P8 P7 P6 P5 P4 P3 P2 P1 REPLICATED
WRITES NODE 0 NODE 1 NODE 2 K1 K2 K3 I1 I2 I3 K 40
QUERY + REPLICATION • NOT ALL NODES NEED TO BE
QUERIED • FIND COVERING SUBSET OF PARTITIONS/NODES • YOKOZUNA BUILDS THE COVERAGE PLAN - SOLR EXECUTES THE DISTRIBUTED QUERY • NO USE OF SOLR CLOUD 41
SLOPPY QUORUM • N REPLICAS IMPLIES IDEA OF “PREFERENCE LIST”
• SOME PARTITIONS ARE THE “PRIMARIES” - OTHERS ARE “SECONDARY” • SLOPPY = ALLOW NON-PRIMARY TO STORE REPLICAS • 100% YIELD - BUT POTENTIALLY DEGRADED HARVEST 42
TUNABLE QUORUM • R - # OF PARTITIONS TO VERIFYREAD
• W - # OF PARTITIONS TO VERIFY WRITE • PR/PW - # OF PARTITIONS WHICH MUST BE PRIMARY • ALLOWS YOU TO TRADE YIELD FOR HARVEST - PER REQUEST 43
SIBLINGS • NO MASTER TO SERIALIZE OPS • CONCURRENT ACTORS
ON SAME KEY • OPERATIONS CAN INTERLEAVE • USE VCLOCKS TO DETECT CONFLICT • CREATE SIBLINGS - LET CLIENT FIX • INDEX ALL SIBLINGS 44
SELF HEALING Selbstheilung 45
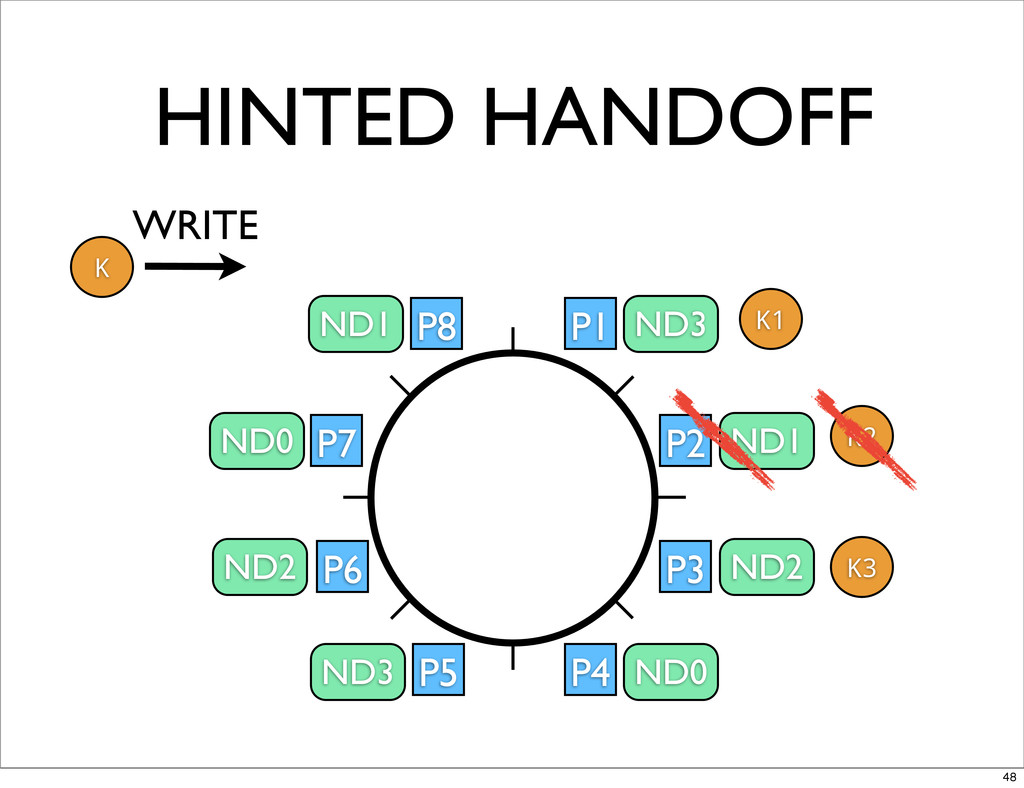
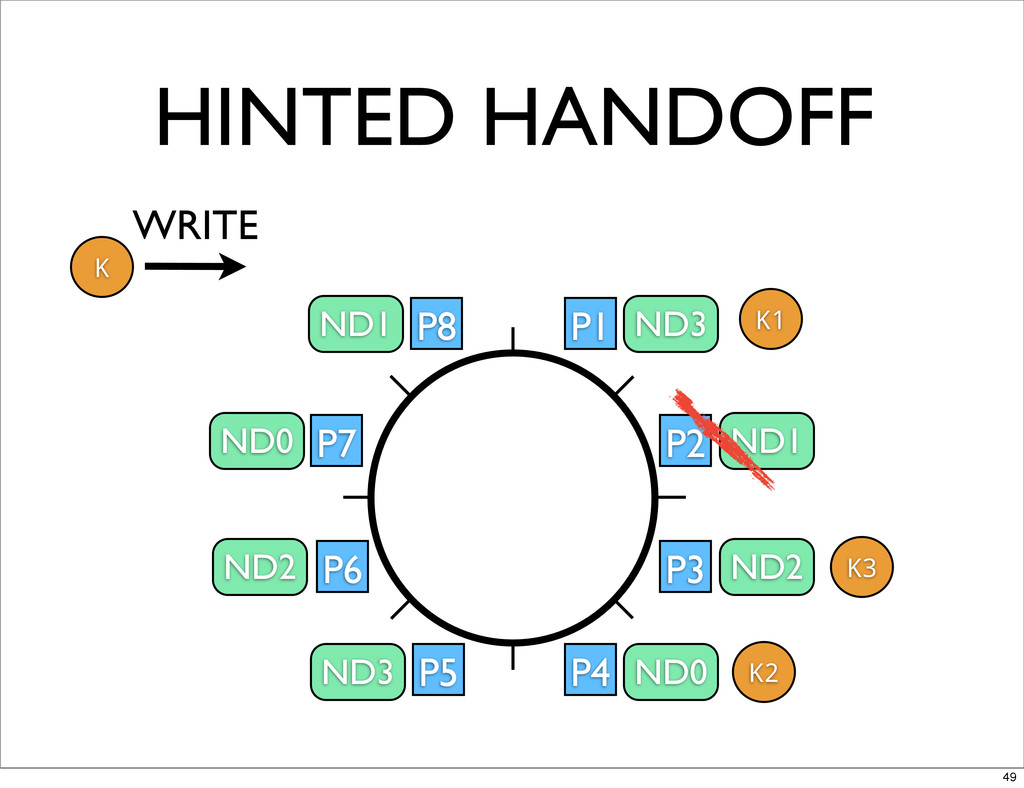
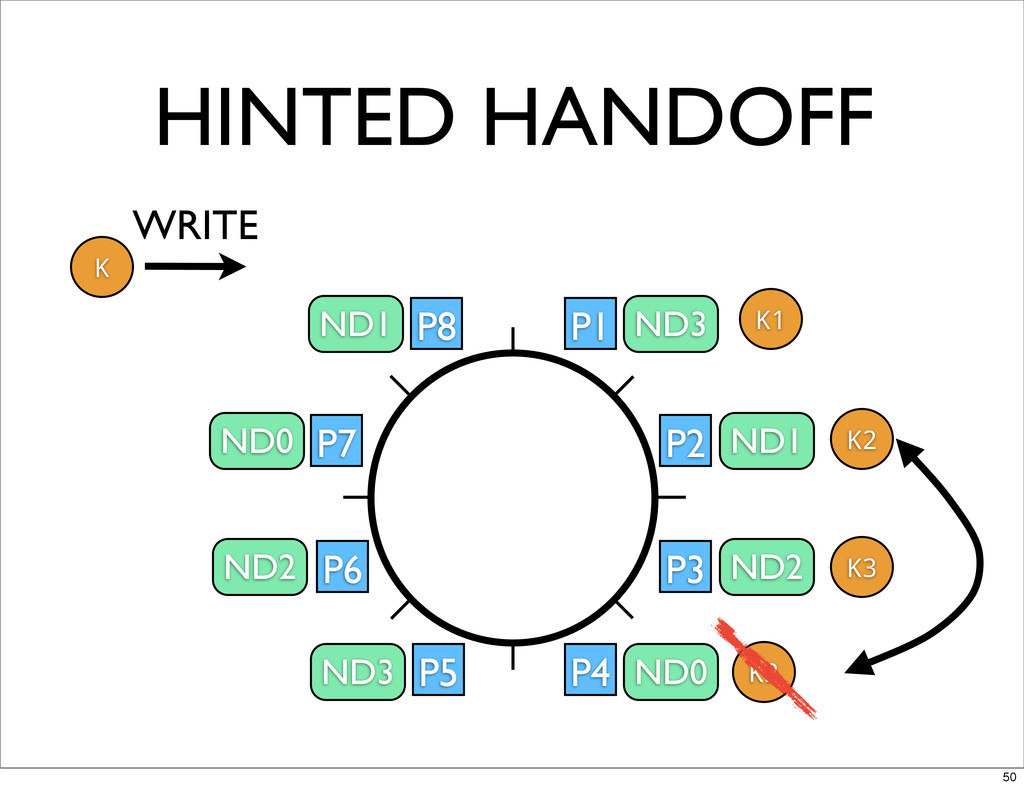
HINTED HANDOFF • WHEN NODES GO DOWN DATA WRITTEN TO
SECONDARY PARTITIONS • WHEN NODES COMES BACK NEED TO GIVE THE DATA TO PRIMARY OWNER • AS DATA IS HANDED OFF INDEX IT ON DESTINATION NODE 46
P1 P2 P3 P4 P5 P6 P7 P8 ND3 ND1
ND2 ND0 ND3 ND2 ND0 ND1 K K1 K2 K3 WRITE HINTED HANDOFF 47
P1 P2 P3 P4 P5 P6 P7 P8 ND3 ND1
ND2 ND0 ND3 ND2 ND0 ND1 K K1 K2 K3 WRITE HINTED HANDOFF 48
P1 P2 P3 P4 P5 P6 P7 P8 ND3 ND1
ND2 ND0 ND3 ND2 ND0 ND1 K K1 K2 K3 WRITE HINTED HANDOFF 49
P1 P2 P3 P4 P5 P6 P7 P8 ND3 ND1
ND2 ND0 ND3 ND2 ND0 ND1 K K1 K2 K3 WRITE K2 HINTED HANDOFF 50
READ REPAIR • REPLICAS MAY NOT AGREE • REPLICAS MAY
BE LOST • CHECK REPLICA VALUES DURING READ • FIX IF THEY DISAGREE • SEND NEW VALUE TO EACH REPLICA 51
ACTIVE ANTI- ENTROPY • 2 SYSTEMS (RIAK & SOLR) -
GREATER CHANCE FOR INCONSISTENCY • FILES CAN BECOME TRUNCATED/ CORRUPTED • ACCIDENTAL RM -RF • SEGFAULT AT THE RIGHT TIME • ETC 52
MYRAID OF FAILURE SCENARIOS - FROM OBVIOUS TO NEARLY INVISIBLE
53
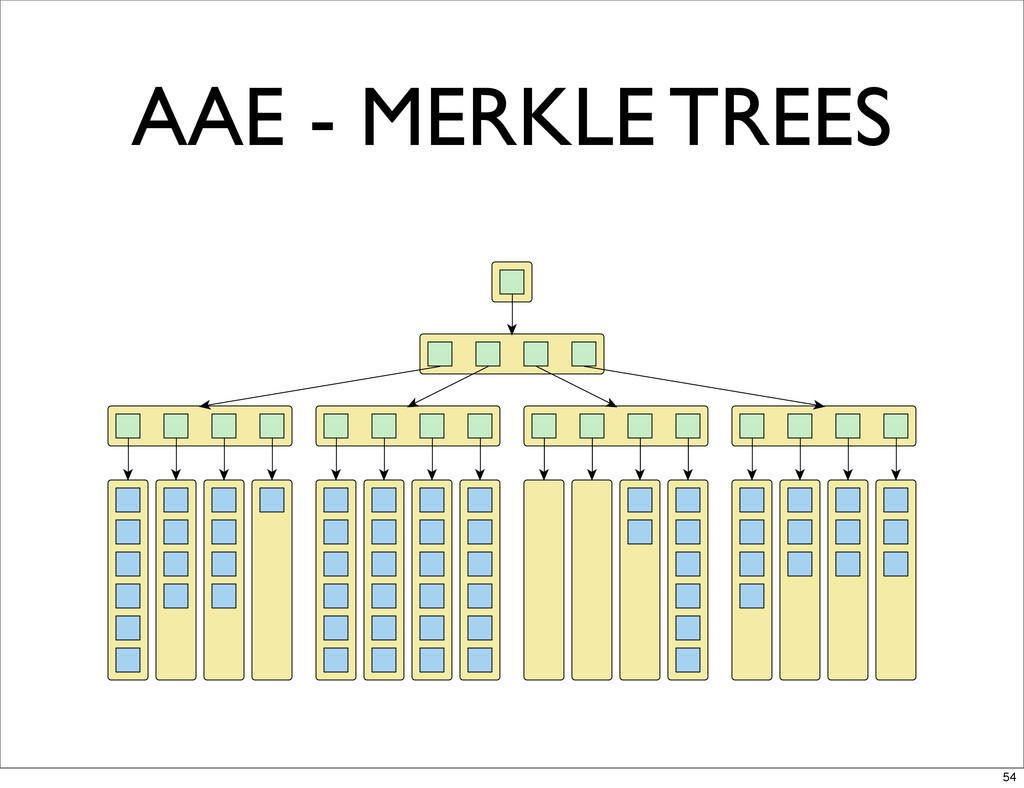
AAE - MERKLE TREES 54
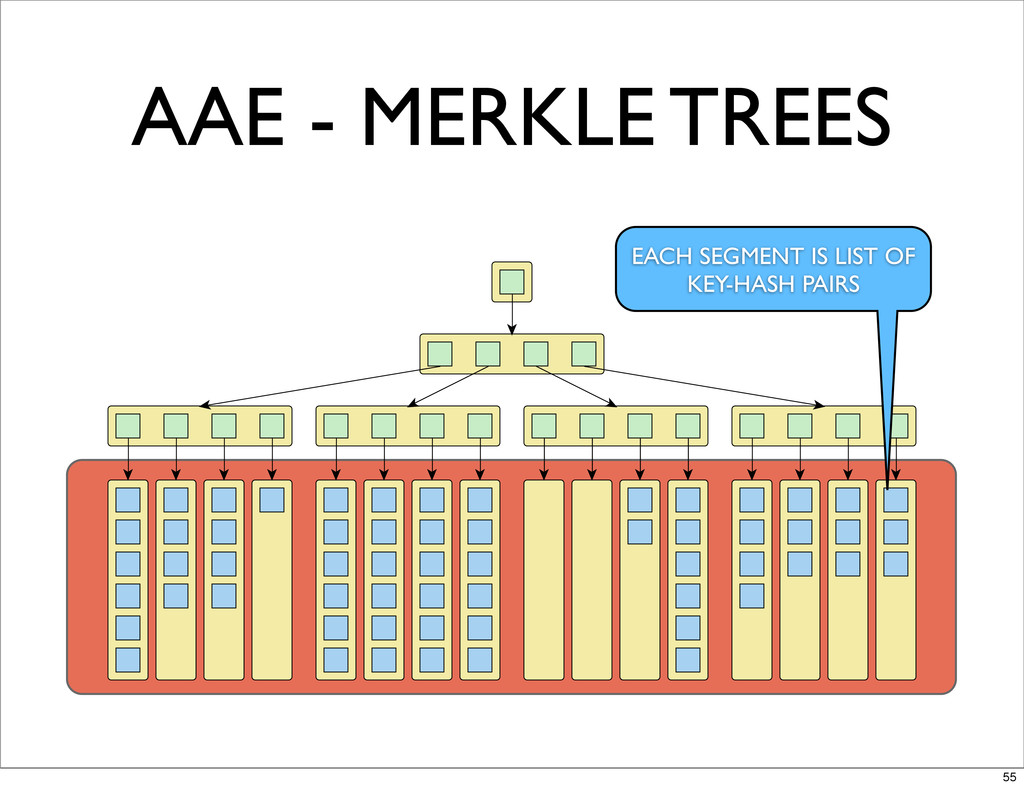
AAE - MERKLE TREES EACH SEGMENT IS LIST OF KEY-HASH
PAIRS 55
AAE - MERKLE TREES HASH OF HASHES IN SEGMENT 56
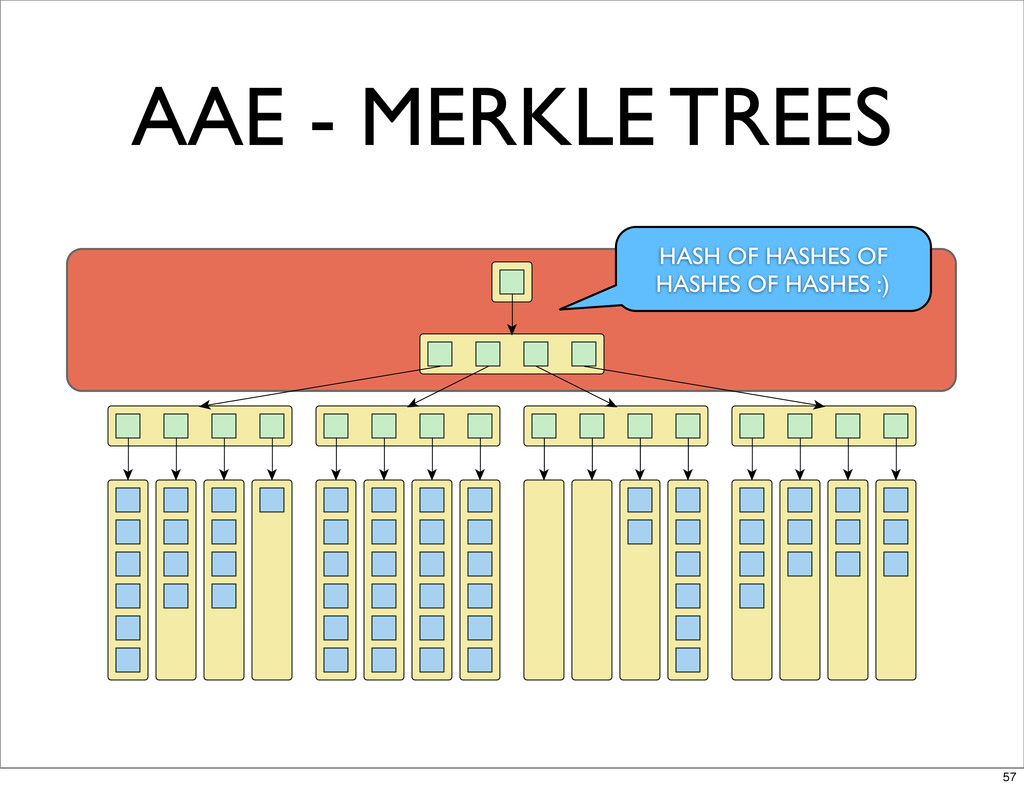
AAE - MERKLE TREES HASH OF HASHES OF HASHES OF
HASHES :) 57
AAE - MERKLE TREES • IT’S A HASH TREE •
IT’S ABOUT EFFICIENCY • BILLIONS OF OBJECTS CAN BE COMPARED AT COST OF COMPARING 2 HASHES (WIN!) 58
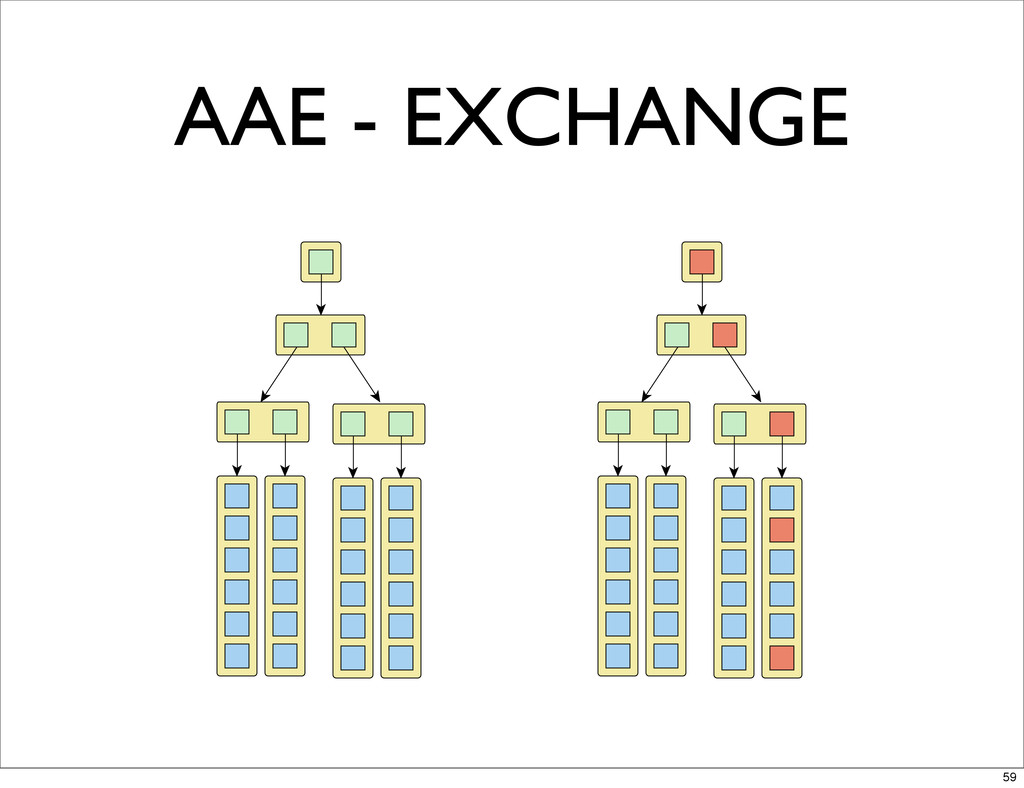
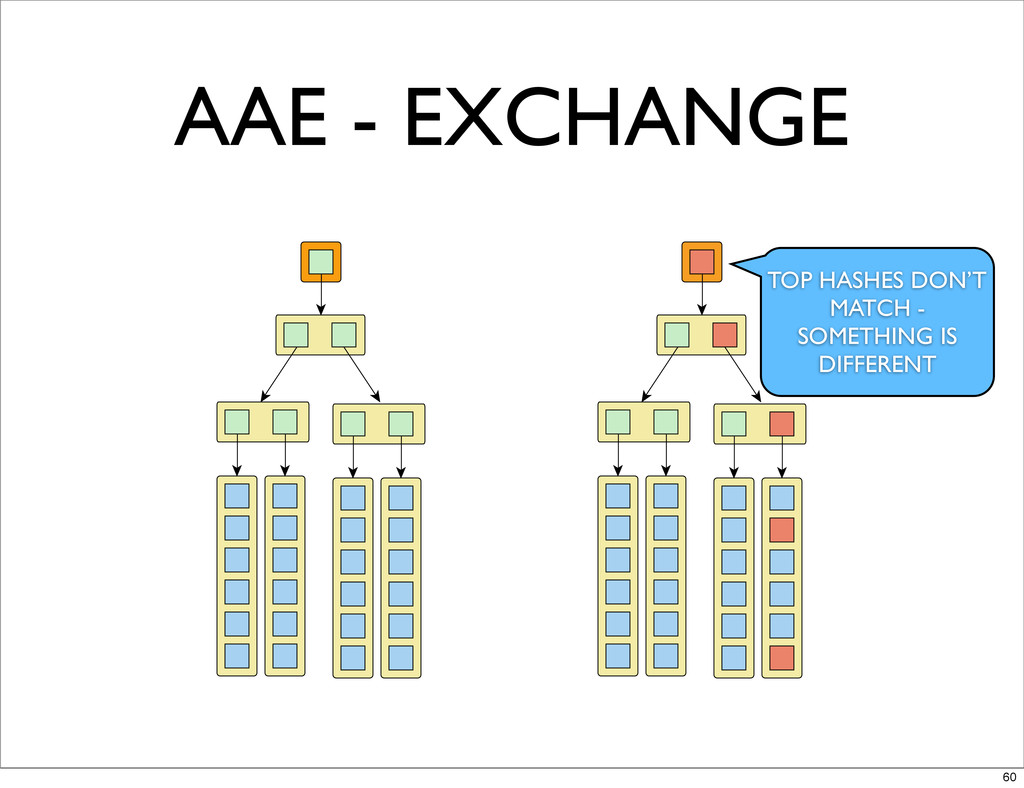
AAE - EXCHANGE 59
AAE - EXCHANGE TOP HASHES DON’T MATCH - SOMETHING IS
DIFFERENT 60
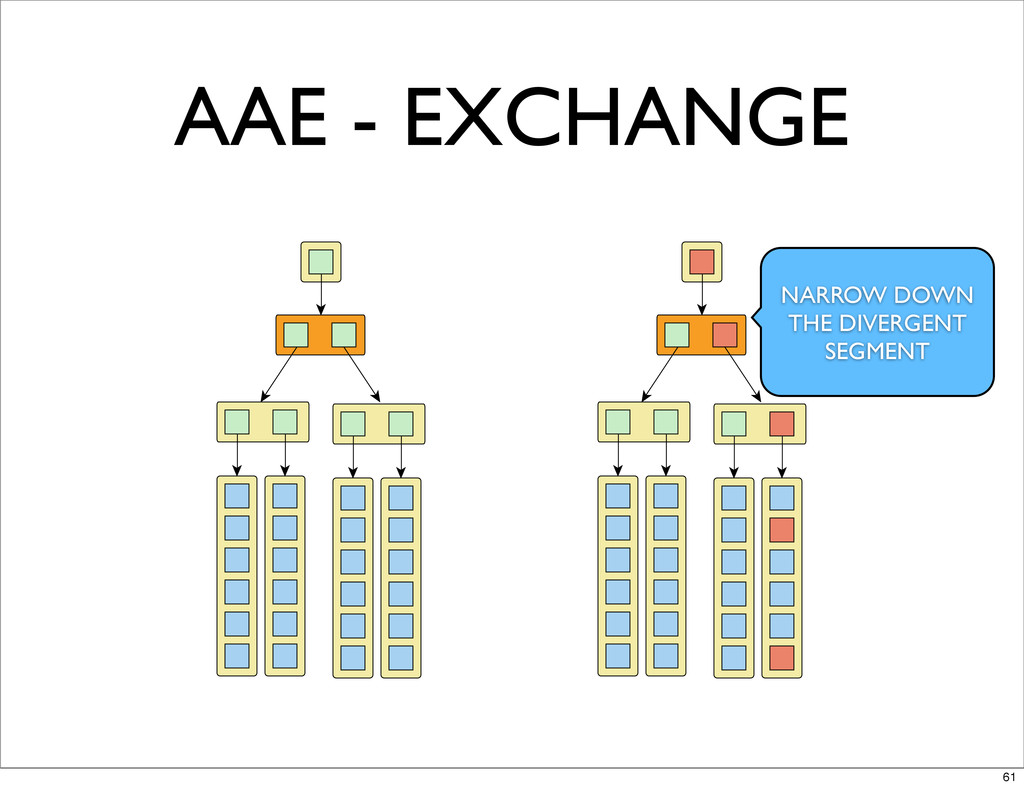
AAE - EXCHANGE NARROW DOWN THE DIVERGENT SEGMENT 61
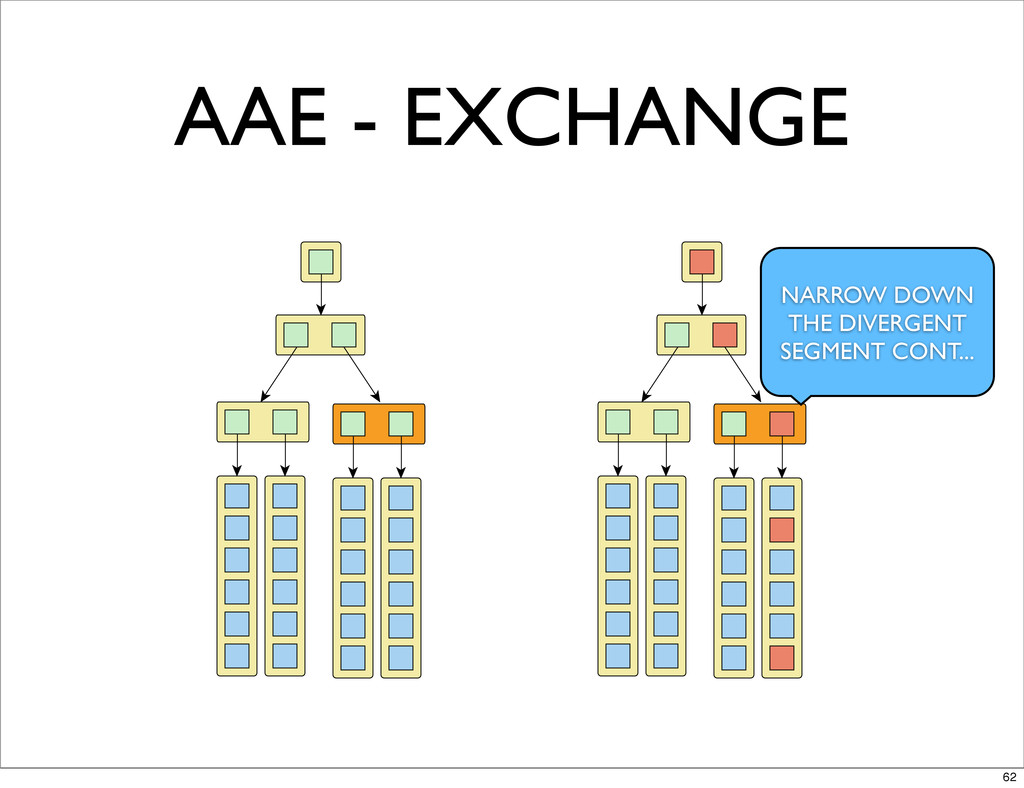
AAE - EXCHANGE NARROW DOWN THE DIVERGENT SEGMENT CONT... 62
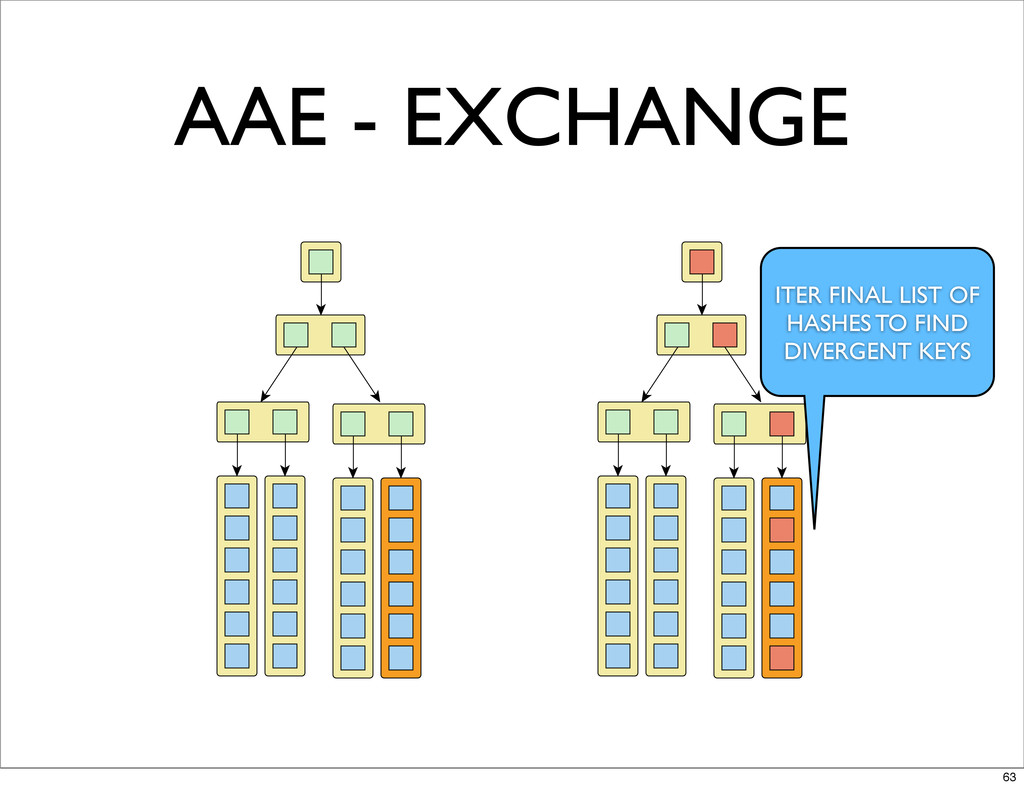
AAE - EXCHANGE ITER FINAL LIST OF HASHES TO FIND
DIVERGENT KEYS 63
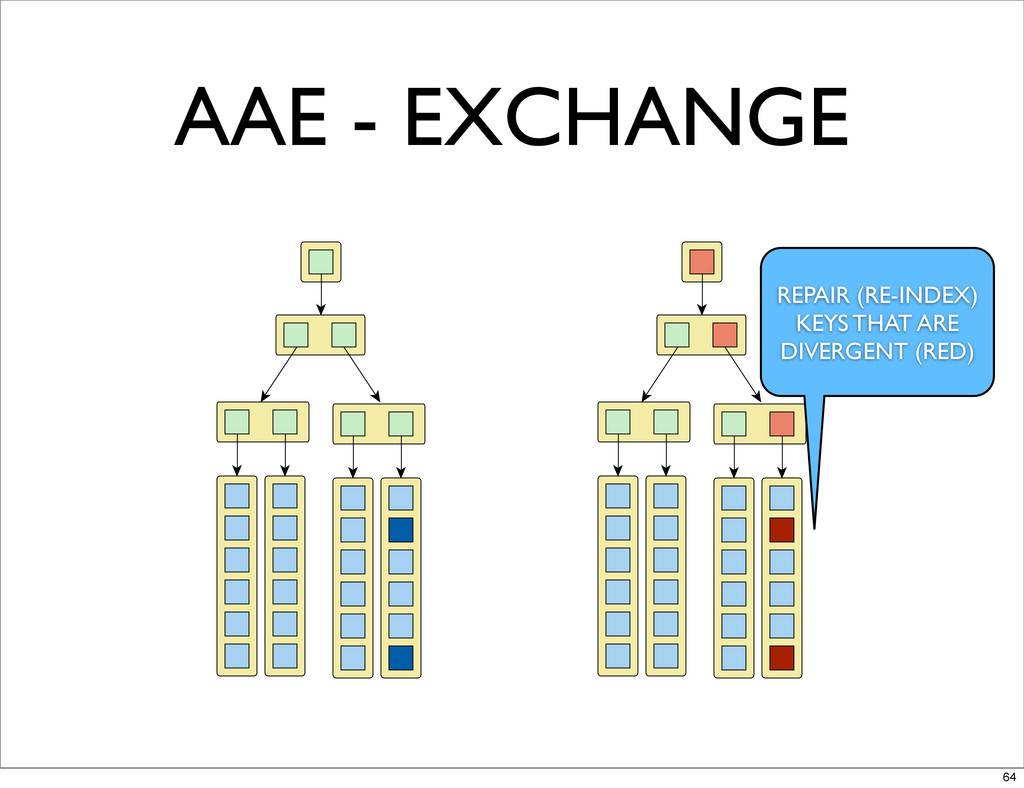
AAE - EXCHANGE REPAIR (RE-INDEX) KEYS THAT ARE DIVERGENT (RED)
64
AAE • DURABLE TREES • UPDATED IN REAL TIME •
NON-BLOCKING • PERIODICALLY EXCHANGED • INVOKE READ-REPAIR AND RE-INDEX ON DIVERGENCE • PERIODICALLY REBUILT 65
CODE FOR DETECTION AND REPAIR - NOT PREVENTION 66
DEMONSTRATION Vorführung 67
CREATE CLUSTER 68
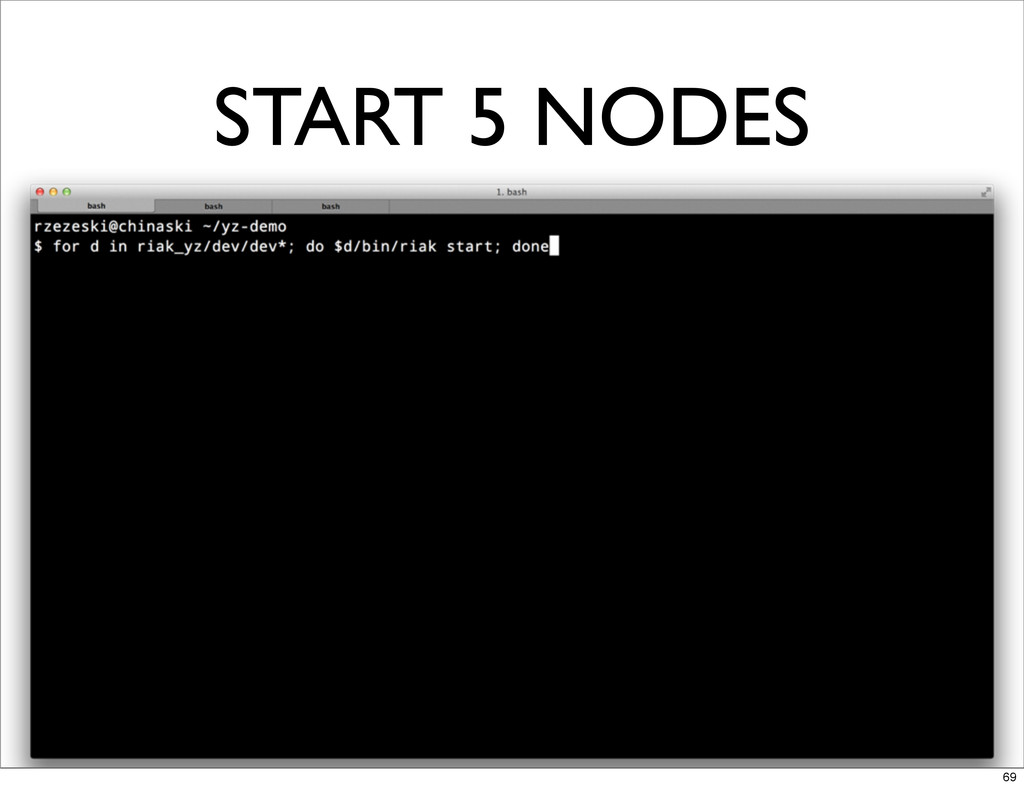
START 5 NODES 69
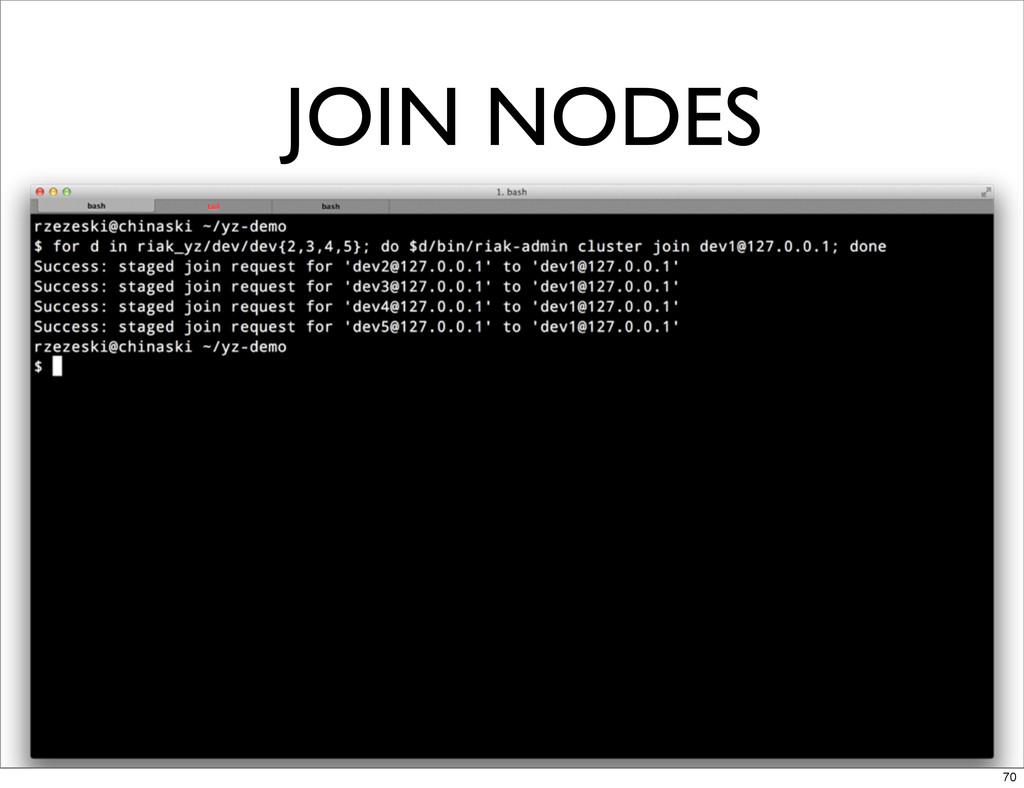
JOIN NODES 70
CREATE PLAN 71
COMMIT PLAN 72
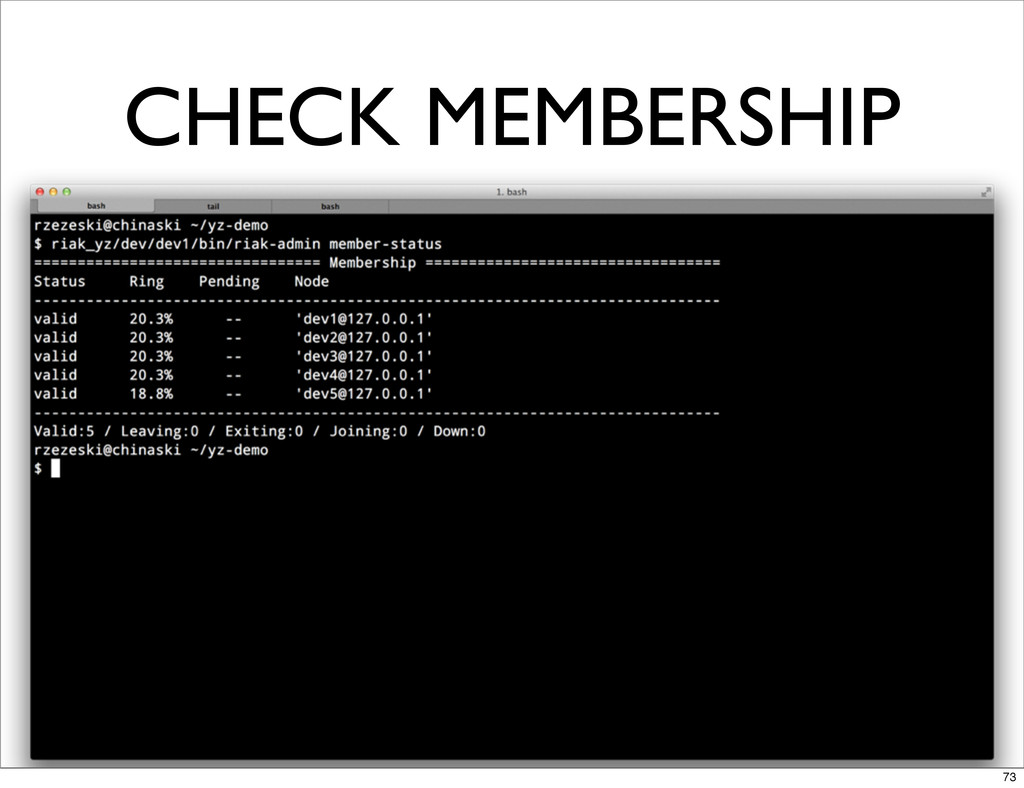
CHECK MEMBERSHIP 73
STORE SCHEMA 74
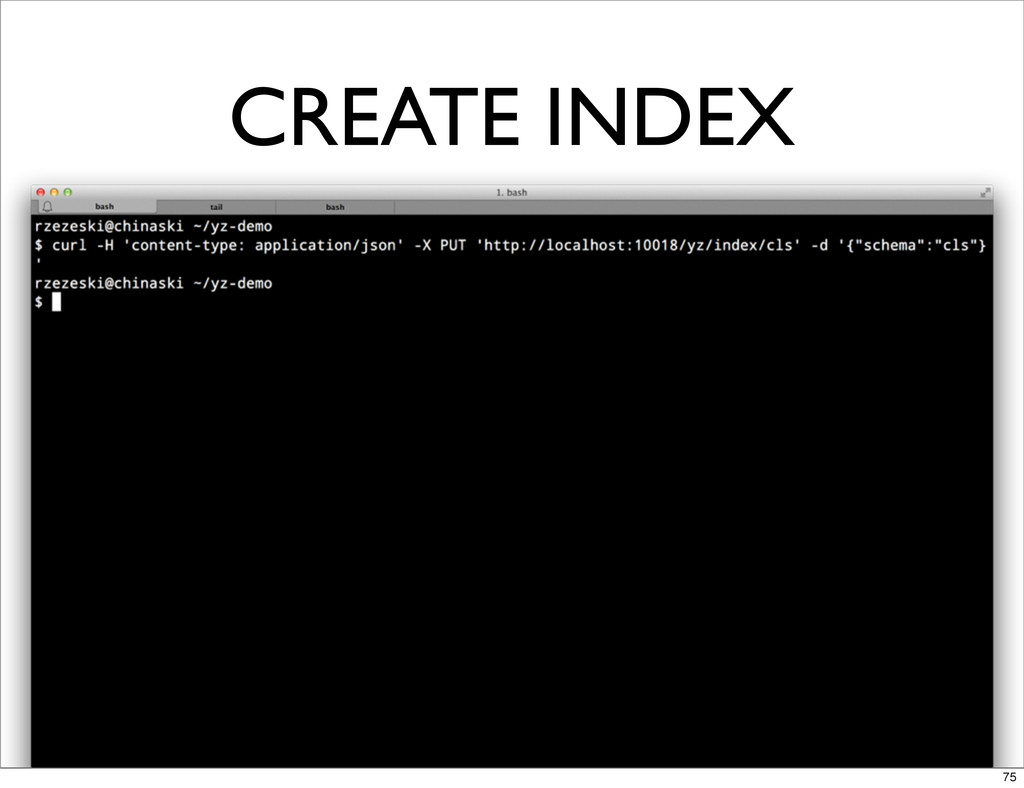
CREATE INDEX 75
INDEX SOME DATA • COMMIT LOG HISTORY OF VARIOUS BASHO
REPOS • INDEX REPO NAME AND COMMIT AUTHOR, DATE, SUBJECT, BODY • USED BASHO BENCH TO LOAD DATA 76
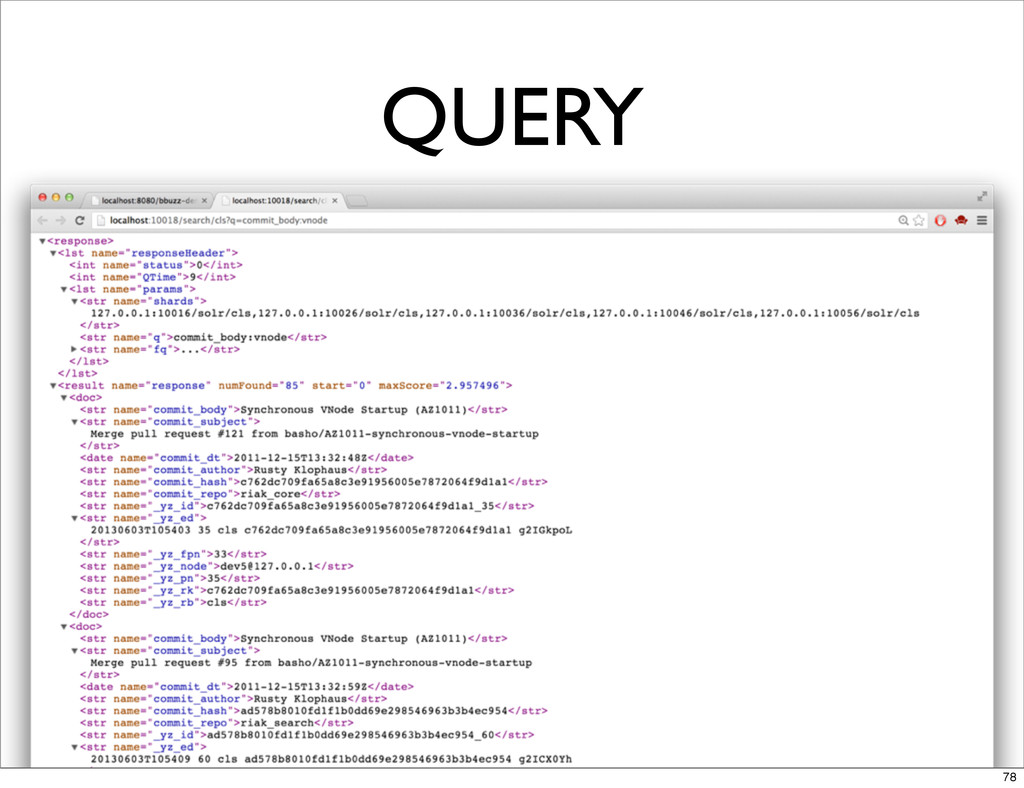
QUERY 77
QUERY 78
QUERY • QUERY FROM ANY NODE • USE SOLR SYNTAX
• RETURN SOLR RESULT VERBATIM • CAN USE EXISTING SOLR CLIENTS (FOR QUERY, NOT WRITE) 79
WHAT HAPPENS IF YOU TAKE 2 NODES DOWN? 80
DOWN 2 NODES 81
VERIFY DOWN 82
QUERY (DOWN) 83
QUERY (DOWN) • INDEX REPLICATION ALLOWS FOR QUERY AVAILABILITY •
JUST NEED 1 REPLICA OF INDEX • IF TOO MANY NODES GO DOWN YOKOZUNA WILL REFUSE QUERY • PREFERS 100% HARVEST 84
WHAT HAPPENS IF YOU WRITE DATA WHILE NODES ARE DOWN?
85
VERIFY 0 RESULTS 86
ADD NEW DATA 87
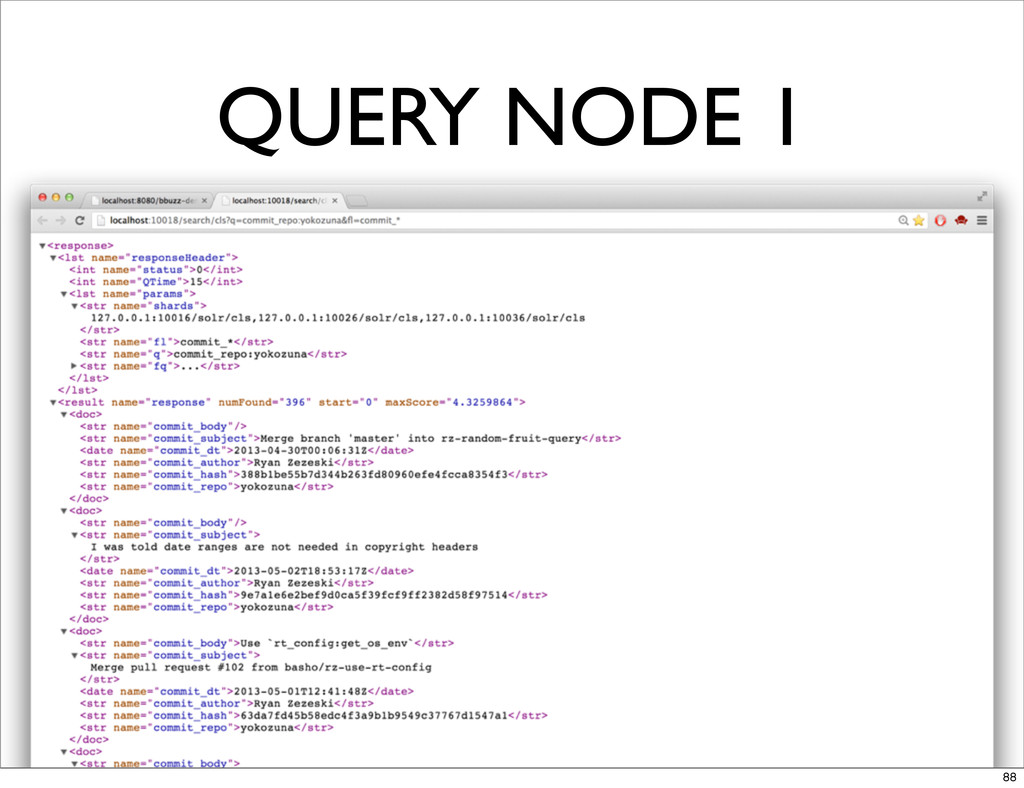
QUERY NODE 1 88
DISABLE HANDOFF 89
START NODE 4 & 5 90
QUERY SOLR NODE 4 91
ENABLE HANDOFF 92
TAIL LOGS 93
QUERY SOLR NODE 4 94
QUERY NODE 4 95
WHAT HAPPENS IF YOU LOSE YOUR INDEX DATA? 96
QUERY SOLR NODE 4 NOTICE NUM FOUND IS 6747 97
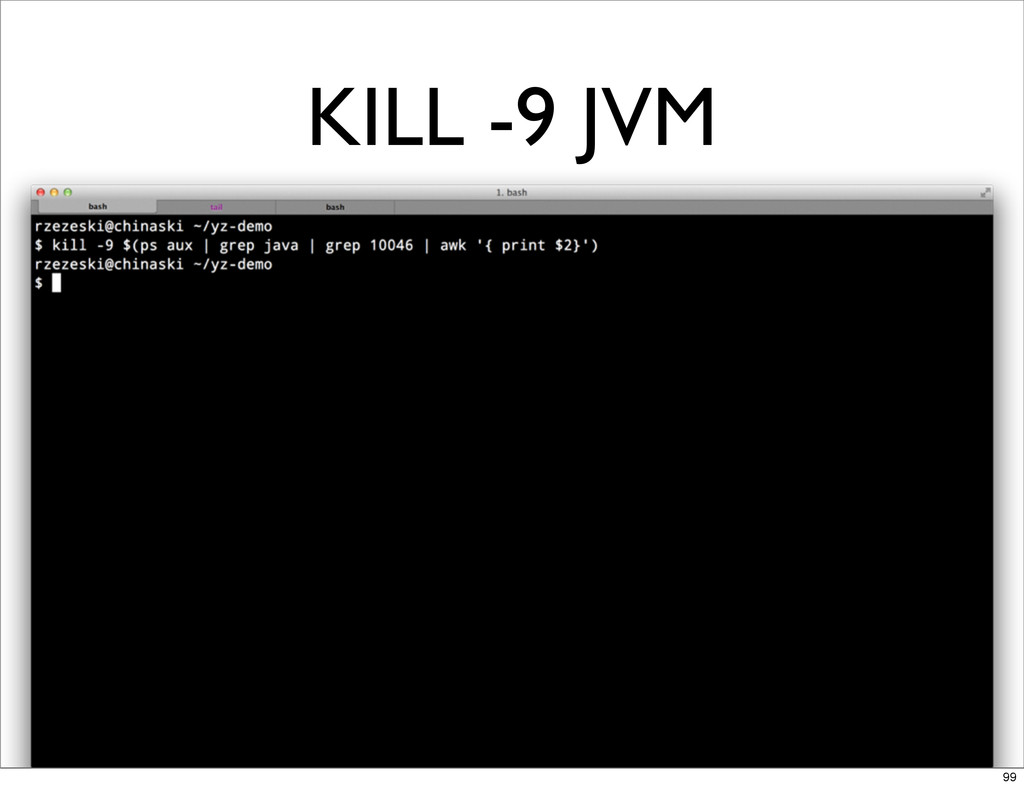
RM -RF THE INDEX 98
KILL -9 JVM 99
YOKO RESTART JVM 100
QUERY SOLR NODE 4 NUM FOUND 0 BECAUSE INDEX WAS
DELETED 101
AAE DETECT/REPAIR 102
QUERY SOLR NODE 4 NUM FOUND IS 6747 AGAIN THANKS
TO AAE 103
Danke sehr! HTTP://GITHUB.COM/BASHO/YOKOZUNA 104
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}