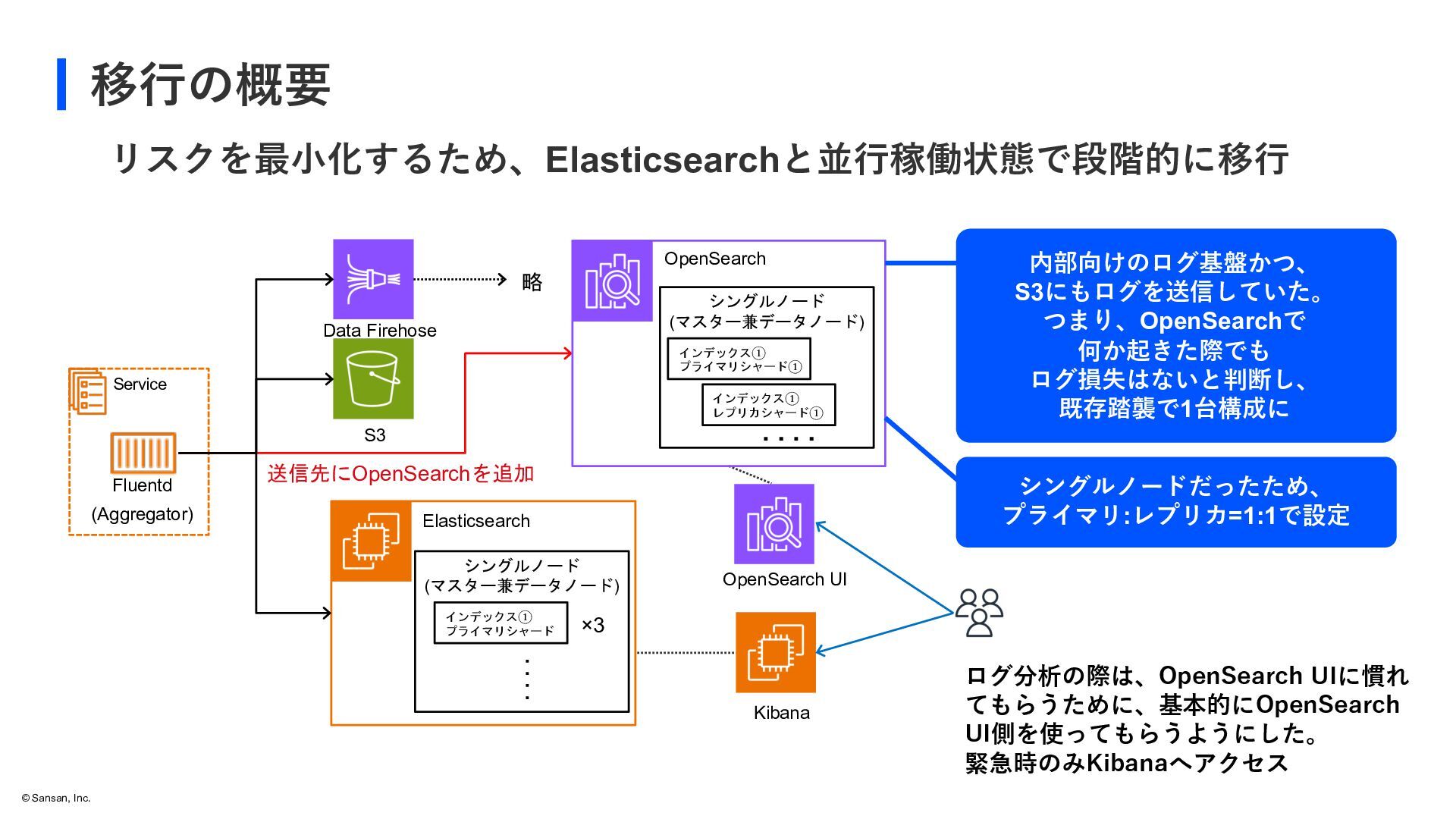
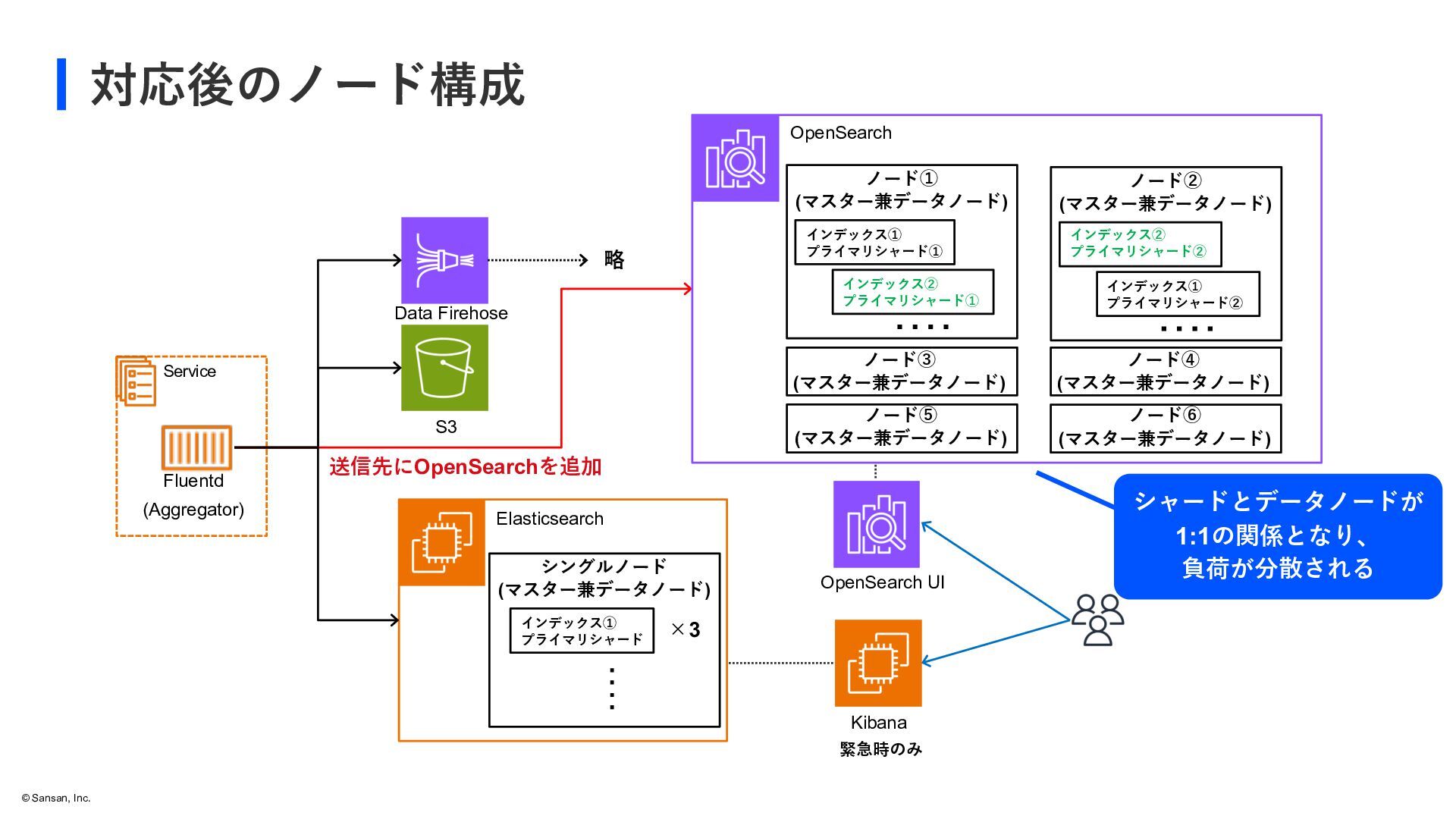
status means the primary shards for all indexes are allocated to nodes in a cluster, but the replica shards for at least one index aren't. Single-node clusters always initialize with a yellow cluster status because there's no other node to which OpenSearch Service can assign a replica. To achieve green cluster status, increase your node count. レプリカシャードをプライマリシャードが置かれているノードとは 別のノードにおけない場合に常にYellowステータスとなる シングルノード構成だったことが原因
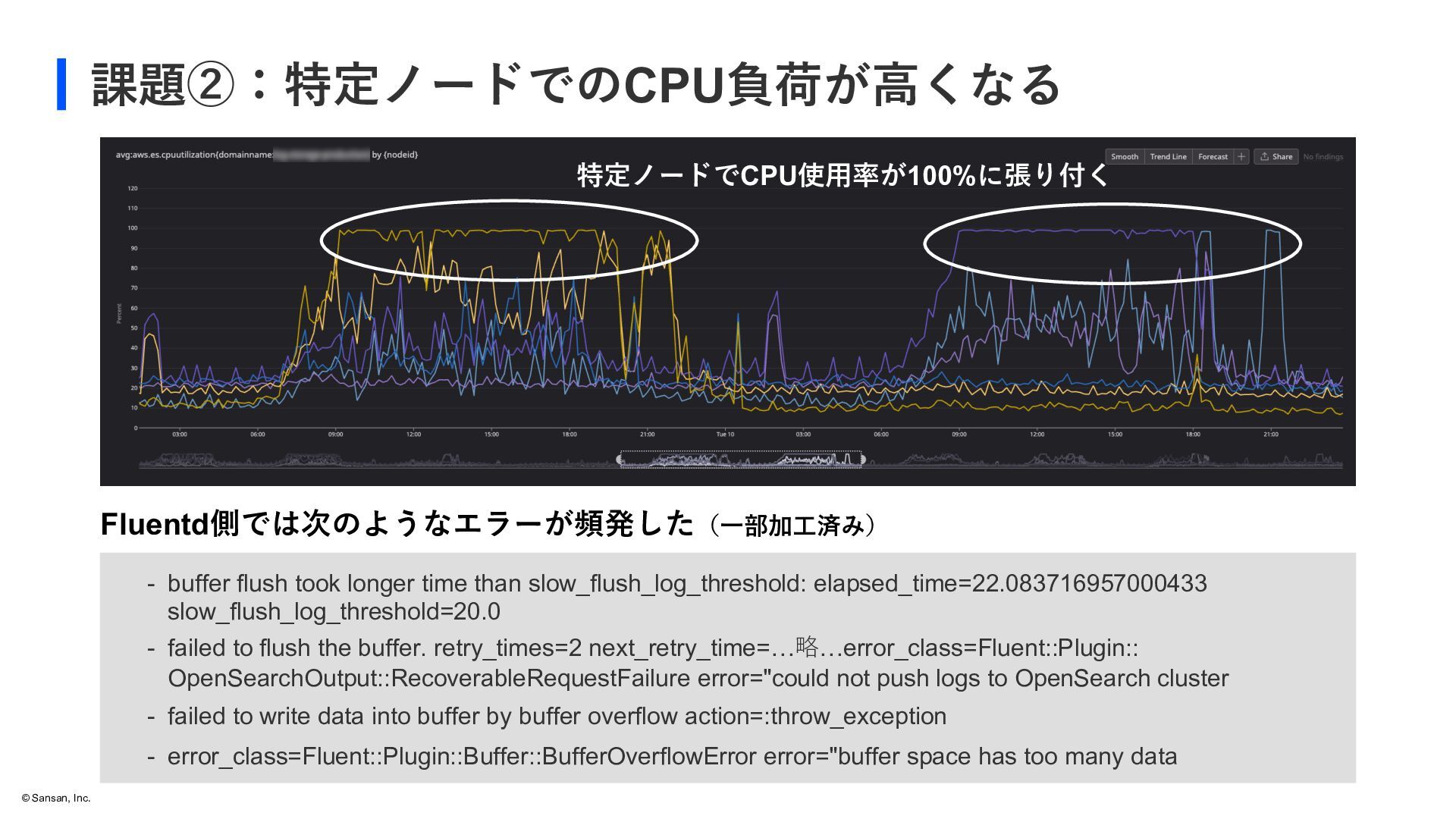
longer time than slow_flush_log_threshold: elapsed_time=22.083716957000433 slow_flush_log_threshold=20.0 - failed to flush the buffer. retry_times=2 next_retry_time=…略…error_class=Fluent::Plugin:: OpenSearchOutput::RecoverableRequestFailure error="could not push logs to OpenSearch cluster - failed to write data into buffer by buffer overflow action=:throw_exception - error_class=Fluent::Plugin::Buffer::BufferOverflowError error="buffer space has too many data
1時間ごとに⾃動的にスナップショットが取得されるので、 対応⽅法①よりもOpenSearch上でのログ⽋損を抑えられる ü インデックスを⼀時的にClose ü スナップショットからの復元 (ログ量が多いもので1〜2時間くらい復旧に時間を要する) *インデックスを削除すると、そのエイリアスも削除されるので、直後の書き込みリクエストによりエイリアスと同じ名前で新しいインデックスが作成されてしまう。 そのため、各インデックスに対して時間を空けずに作業を実施しなければいけない。 ü 割り当てられていないシャードを持つインデックス削除 ü 書き込みインデックス作成 ü エイリアスの作成と紐付け POST /access-log-recommendation-000010/_close POST /_snapshot/cs-automated/<Snapshot ID>/_restore { "indices": ”logA-huga-000001” } 対応⽅法②:⾃動スナップショットから復元(対応時間:約2〜3時間)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}