at Mobility Technologies / DeNA AI R&D Group 2 Previous Job: AI Research Engineer at Konica Minolta Education: NAIST Information Science (Master’s degree) Self-Introduction 2
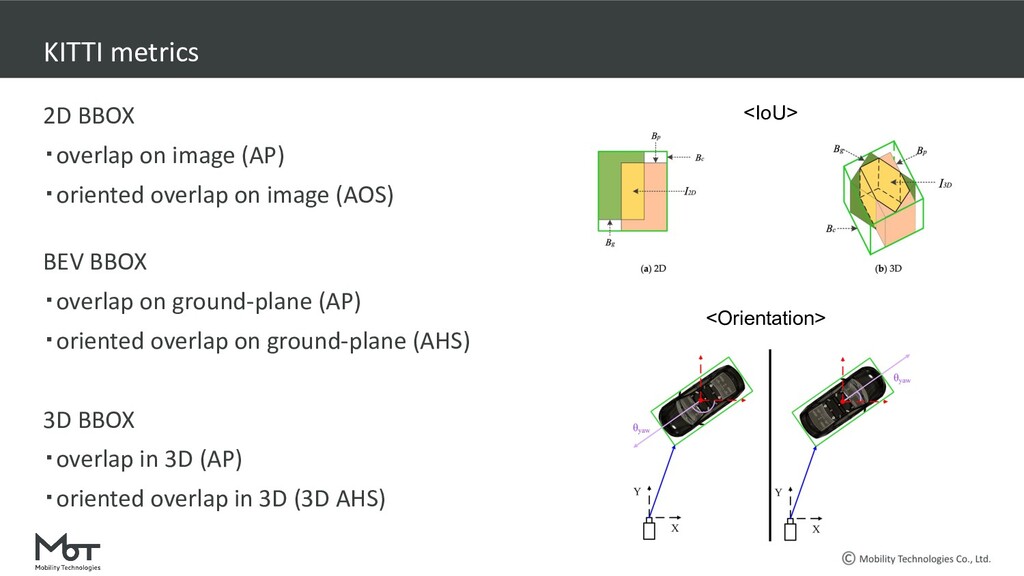
on image (AP) ・oriented overlap on image (AOS) BEV BBOX ・overlap on ground-plane (AP) ・oriented overlap on ground-plane (AHS) 3D BBOX ・overlap in 3D (AP) ・oriented overlap in 3D (3D AHS) <IoU> <Orientation>
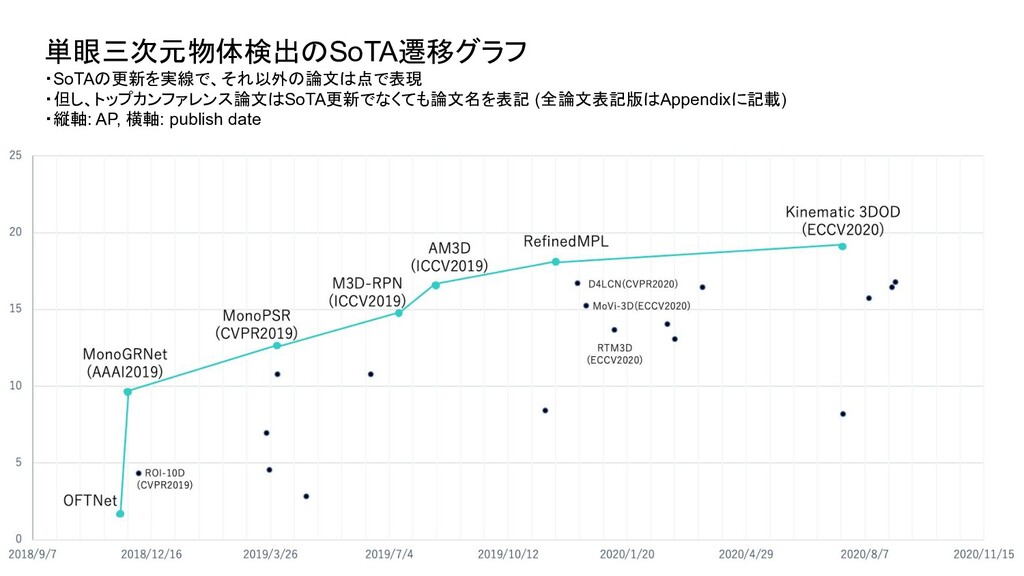
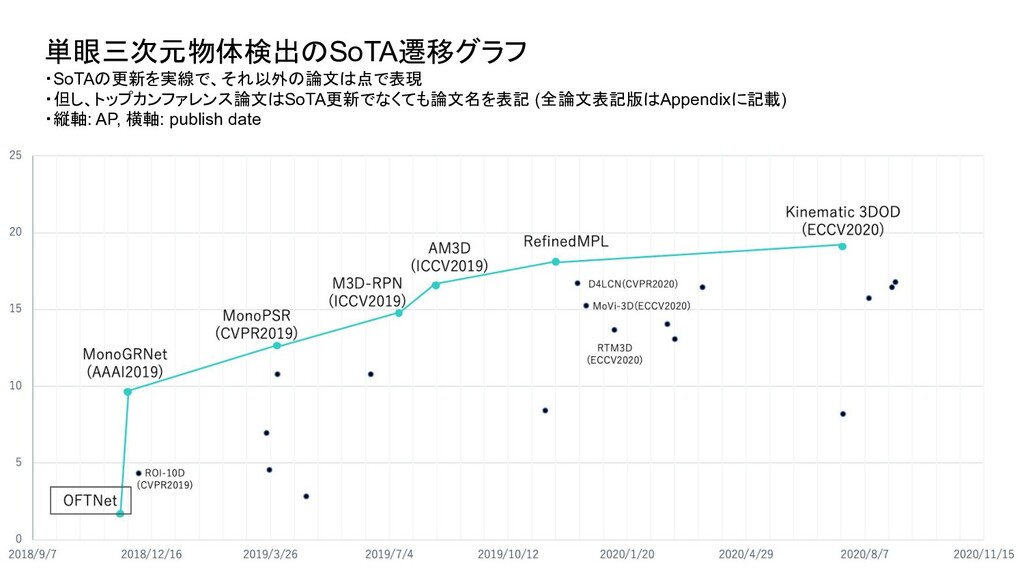
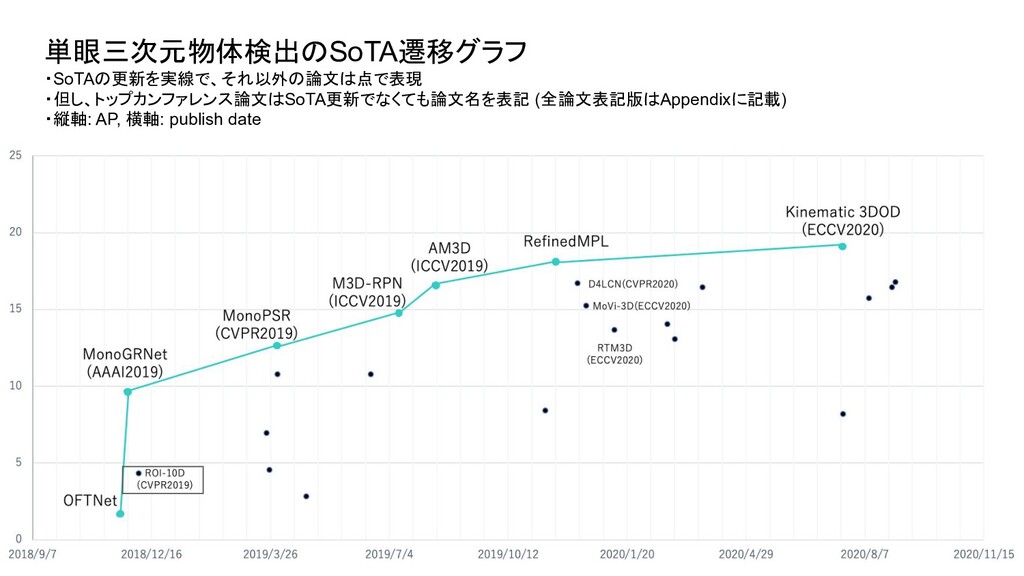
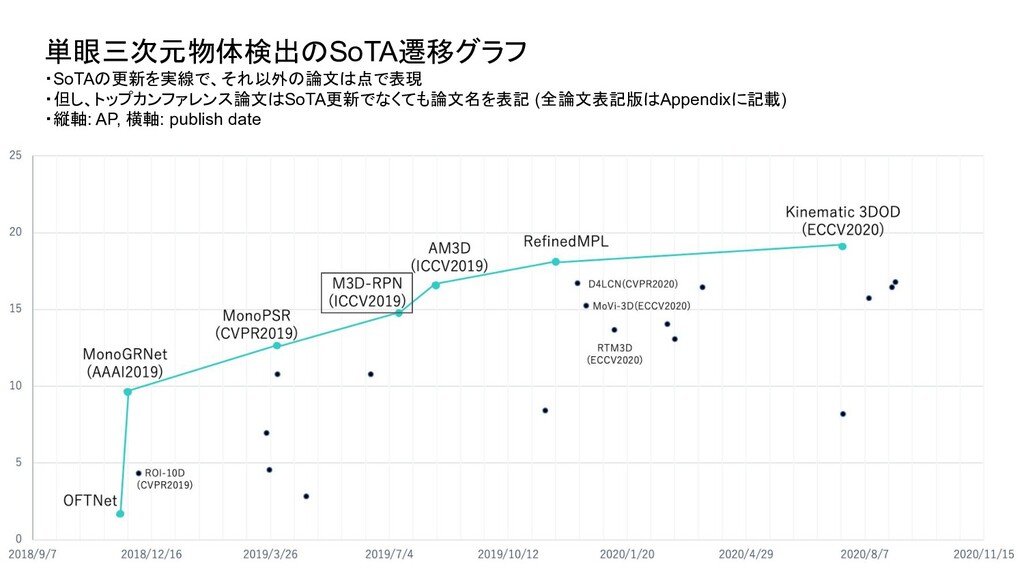
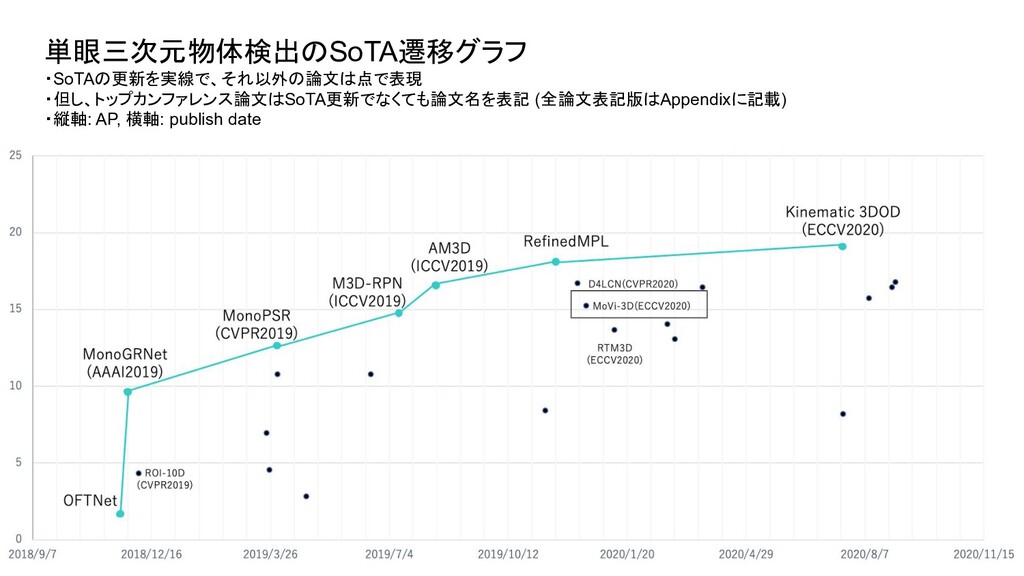
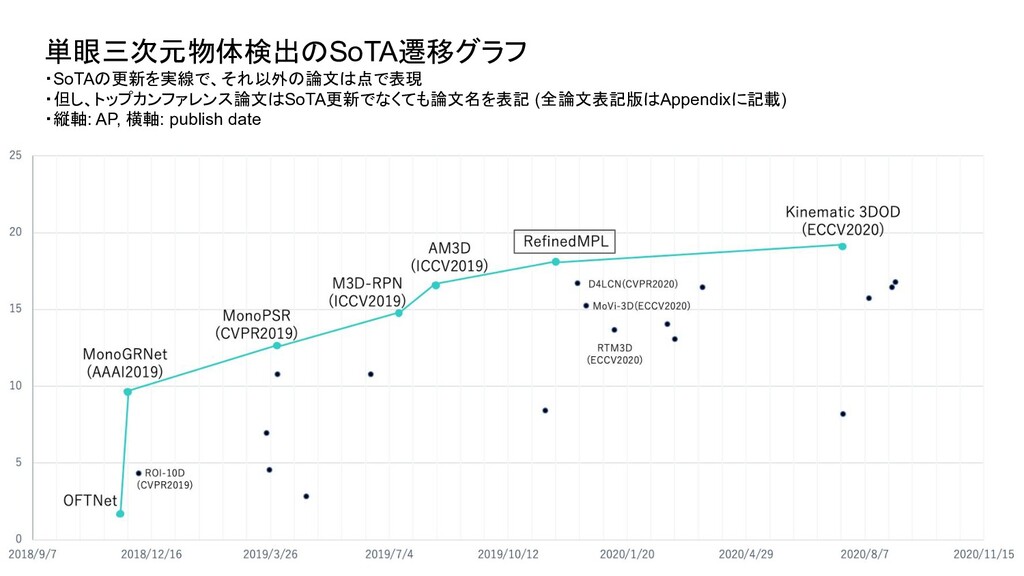
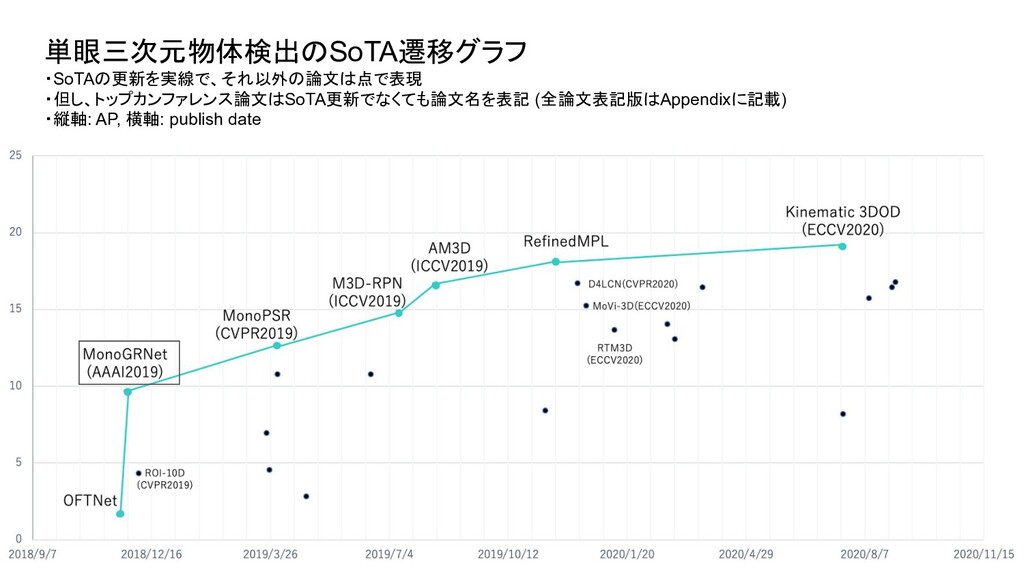
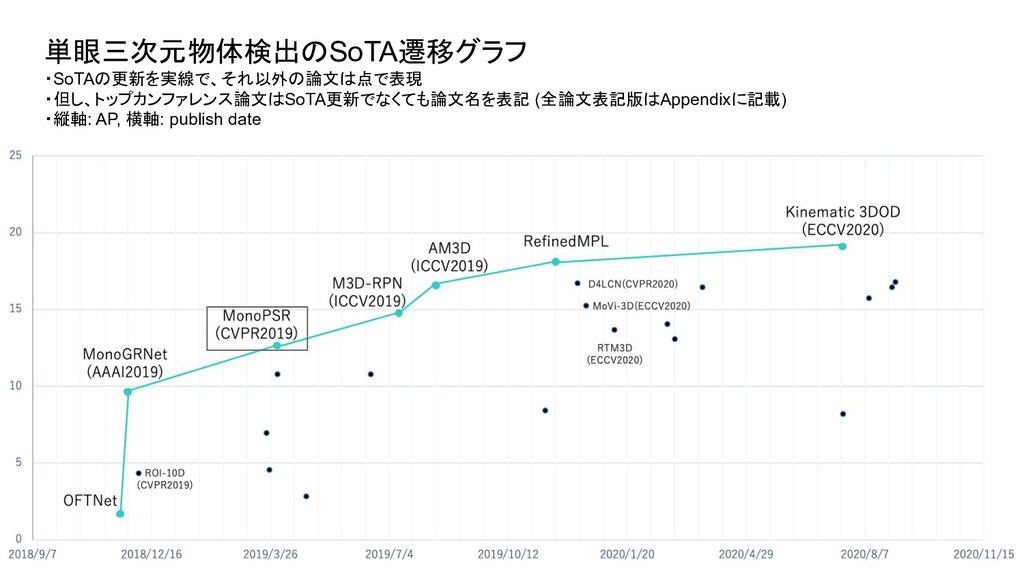
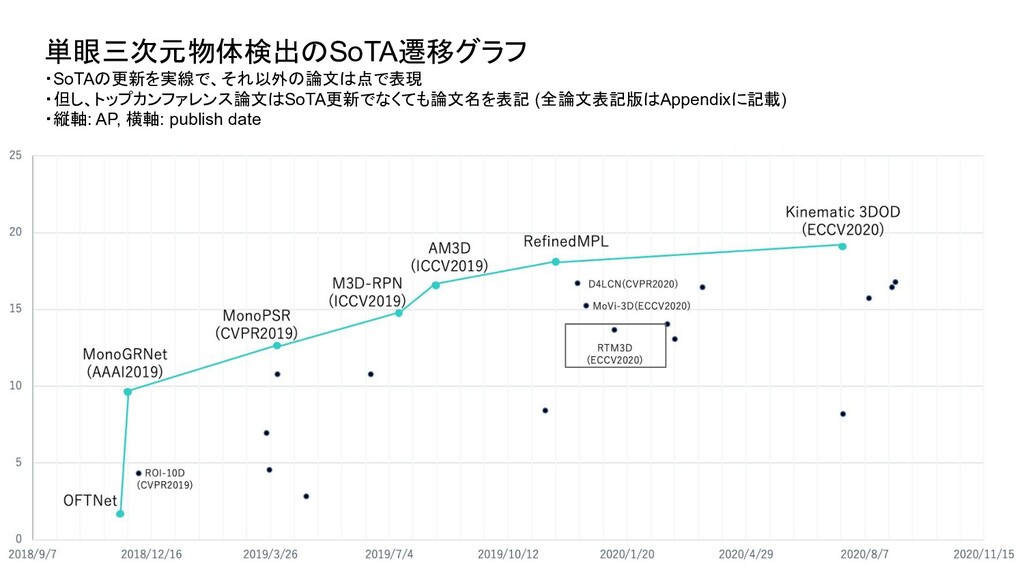
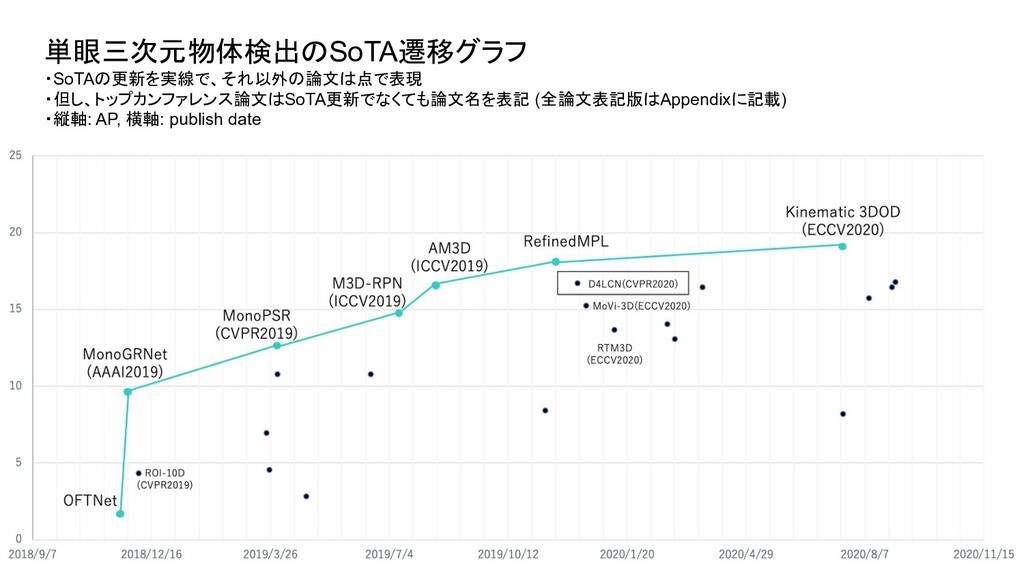
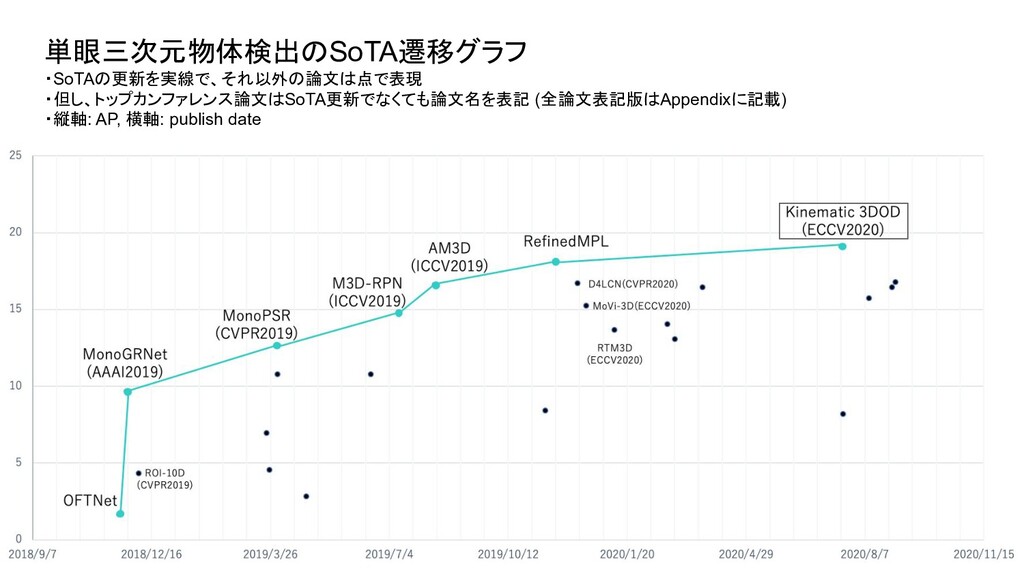
ベンチマーク条件 評価セット test or val test test 評価方法 3D BBOX or BEV (or AHS) - それぞれ独立したものとして存在 3D BBOX (比較時の分かりやすさを優先し3D BBOXに限定) IoU 0.5 or 0.7 0.7 0.7 AP interpolate R11 or R40 (初期は11点補間が主流だったが最近は 40が主流) R40 R40 対象クラス Single or Multi (Car onlyかそれ以外のクラスも含むかどうか ) - multi 難易度 easy or moderate or hard - 全パターン報告が通例になっている easy (比較時の分かりやすさを優先しeasyに限定) ・単眼3次元物体検出は、論文毎に評価条件がばらついており統一されていなかったため、 本調査では、視覚的に性能を比較できるように以下の条件で SoTAのグラフを新たに作成
pseudo-lidar) 2. Key points and Shapes 3. Distance estimation through 2D/3D constraints 4. Direct Generation of 3D proposal Surveyでは上記4つのカテゴリからそれぞれ代表的な論文を2~5本程度紹介 単眼三次元物体検出のカテゴリ 17 *source
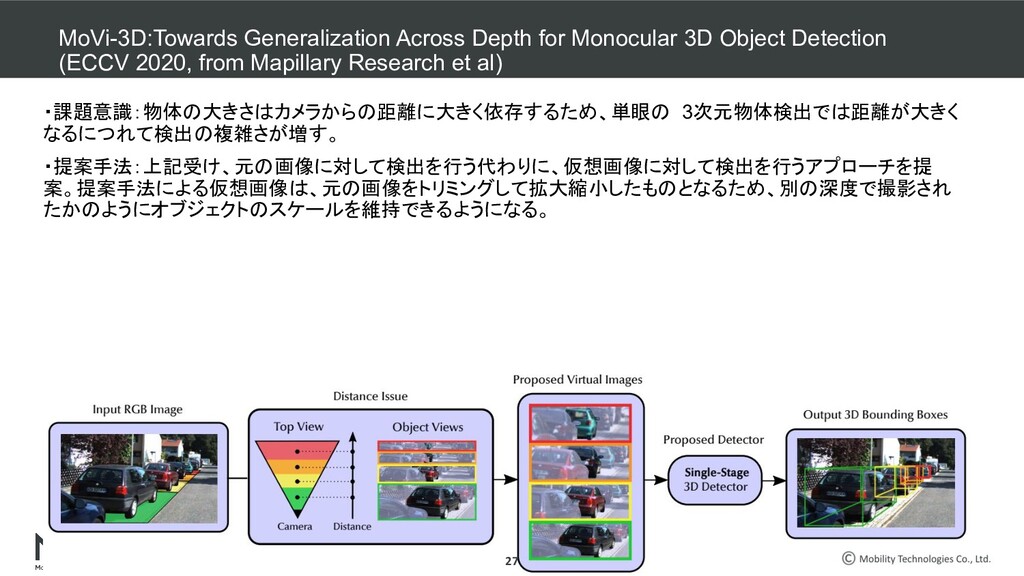
Monocular 3D Object Detection (ECCV 2020, from Mapillary Research et al) ・課題意識:物体の大きさはカメラからの距離に大きく依存するため、単眼の 3次元物体検出では距離が大きく なるにつれて検出の複雑さが増す。 ・提案手法:上記受け、元の画像に対して検出を行う代わりに、仮想画像に対して検出を行うアプローチを提 案。提案手法による仮想画像は、元の画像をトリミングして拡大縮小したものとなるため、別の深度で撮影され たかのようにオブジェクトのスケールを維持できるようになる。 27
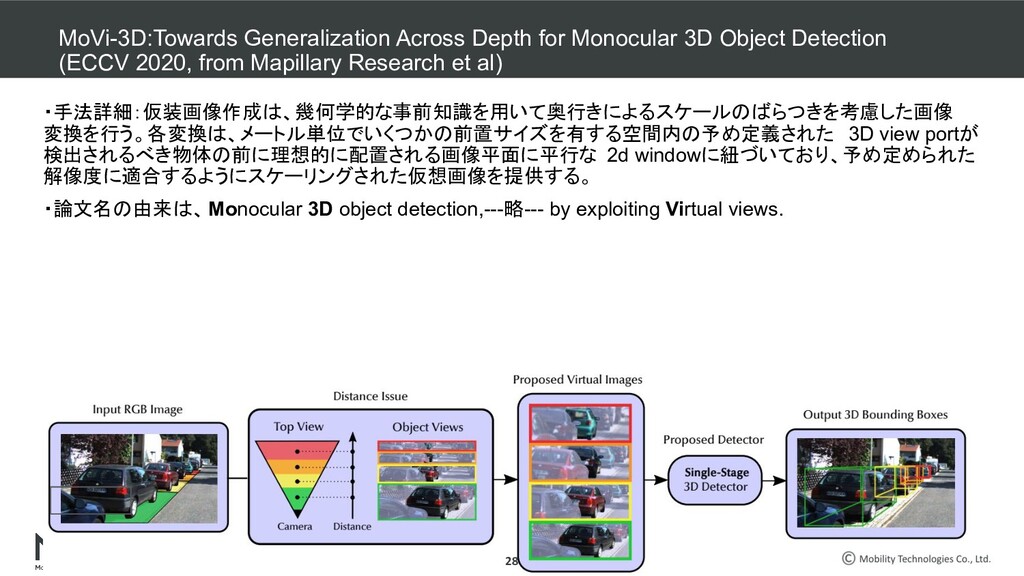
Monocular 3D Object Detection (ECCV 2020, from Mapillary Research et al) ・手法詳細:仮装画像作成は、幾何学的な事前知識を用いて奥行きによるスケールのばらつきを考慮した画像 変換を行う。各変換は、メートル単位でいくつかの前置サイズを有する空間内の予め定義された 3D view portが 検出されるべき物体の前に理想的に配置される画像平面に平行な 2d windowに紐づいており、予め定められた 解像度に適合するようにスケーリングされた仮想画像を提供する。 ・論文名の由来は、Monocular 3D object detection,---略--- by exploiting Virtual views. 28
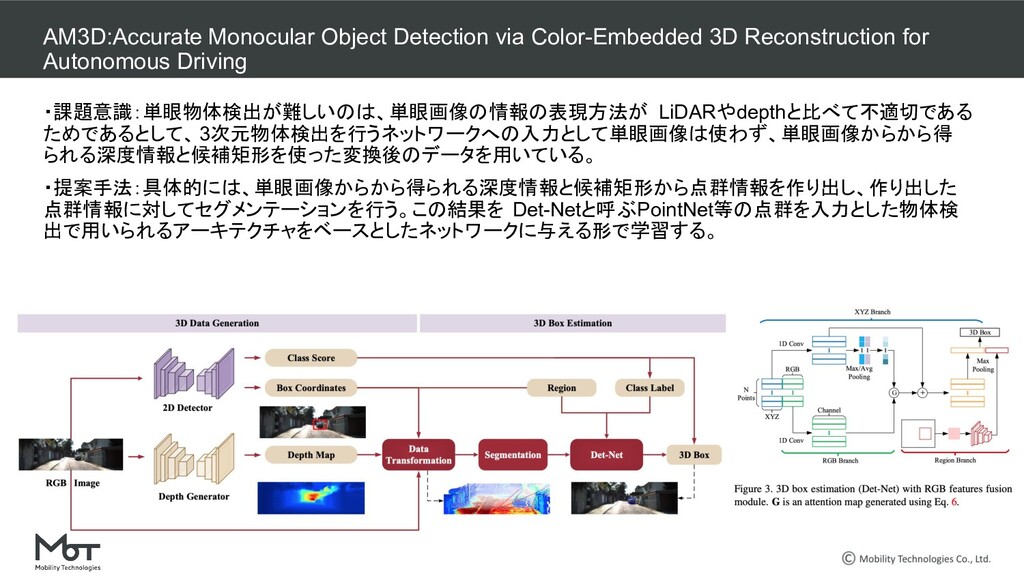
点群情報に対してセグメンテーションを行う。この結果を Det-Netと呼ぶPointNet等の点群を入力とした物体検 出で用いられるアーキテクチャをベースとしたネットワークに与える形で学習する。 AM3D:Accurate Monocular Object Detection via Color-Embedded 3D Reconstruction for Autonomous Driving
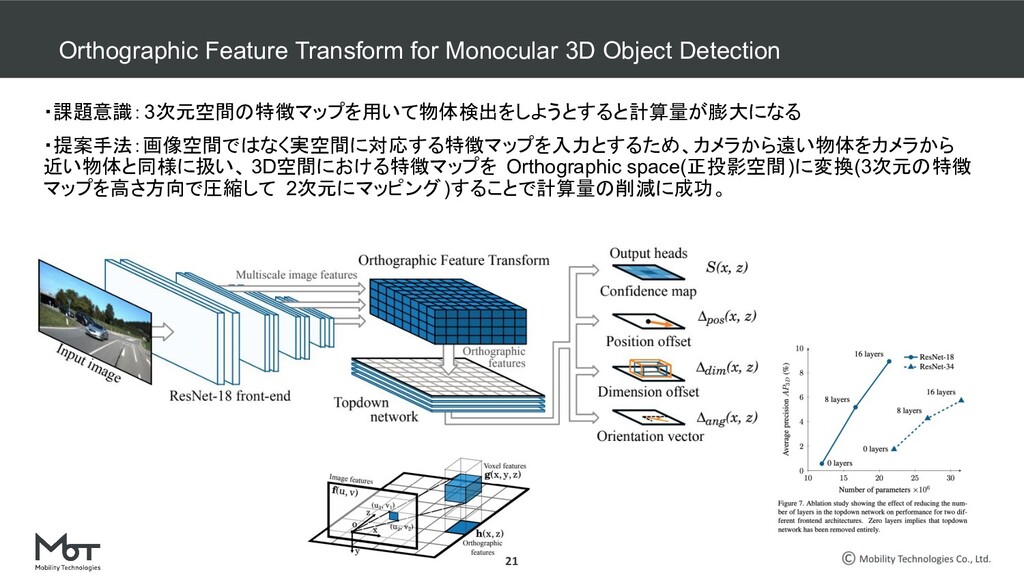
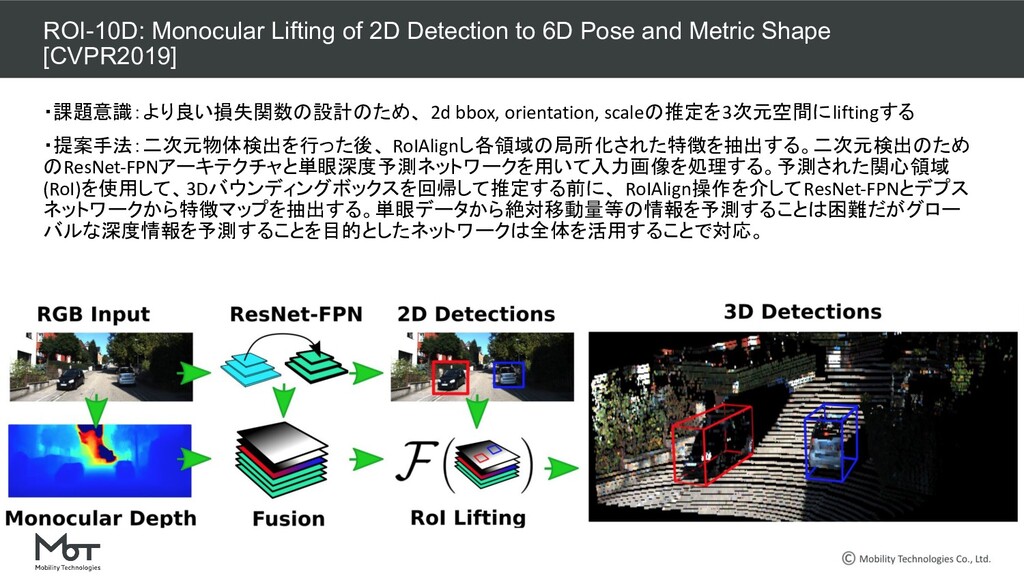
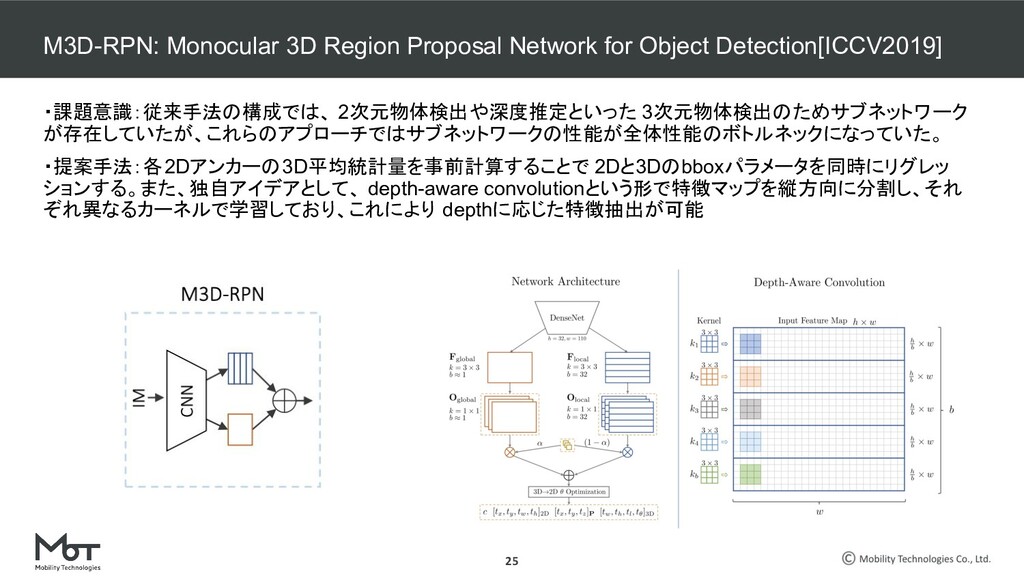
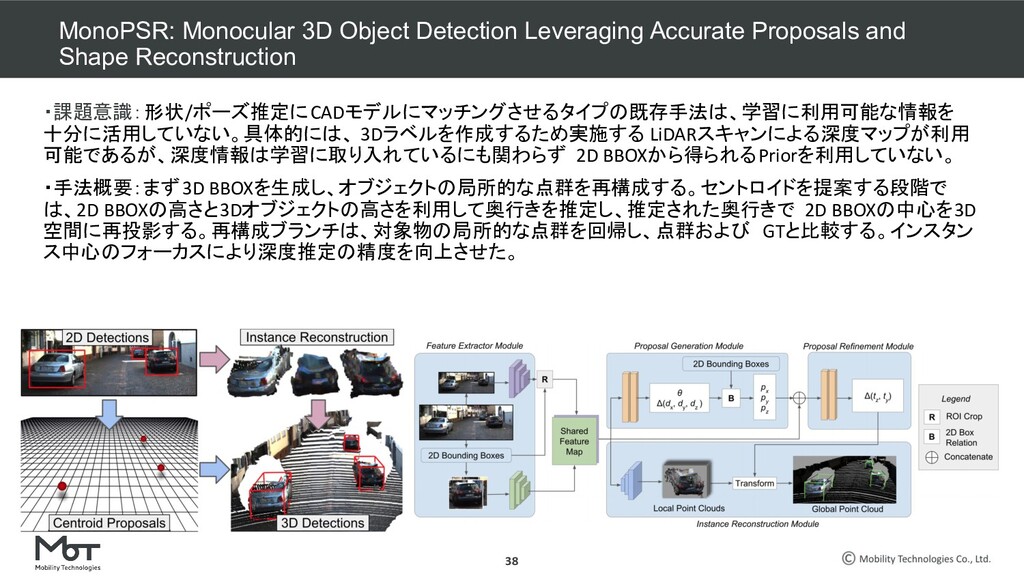
Transform for Monocular 3D Object Detection ROI-10D: Monocular Lifting of 2D Detection to 6D Pose and Metric Shape M3D-RPN: Monocular 3D Region Proposal Network for Object Detection MoVi-3D:Towards Generalization Across Depth for Monocular 3D Object Detection AM3D:Accurate Monocular Object Detection via Color-Embedded 3D Reconstruction for Autonomous Driving RefinedMPL: Refined Monocular PseudoLiDAR for 3D Object Detection in Autonomous Driving MonoGRNet: A Geometric Reasoning Network for Monocular 3D Object Localization MonoPSR: Monocular 3D Object Detection Leveraging Accurate Proposals and Shape Reconstruction RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving Learning Depth-Guided Convolutions for Monocular 3D Object Detection Kinematic 3D Object Detection in Monocular Video
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}