This talk will introduce students to parallel programming. Topics include a survey of parallel programming paradigms and some sample parallel programs in OpenMP and MPI.
unported license; license terms on last slide. Big Problems?...Time to Get Parallel A brief foray into the world of parallel computing Scott Michael [email protected] Presented at XSEDE 12 Conference, 16 Jul 2012 Available from: https://speakerdeck.com/u/scamicha/
important? • How do I design a parallel program? – Challenges • What are the tools that enable parallel programming? – Shared vs. Distributed memory • Demonstrations
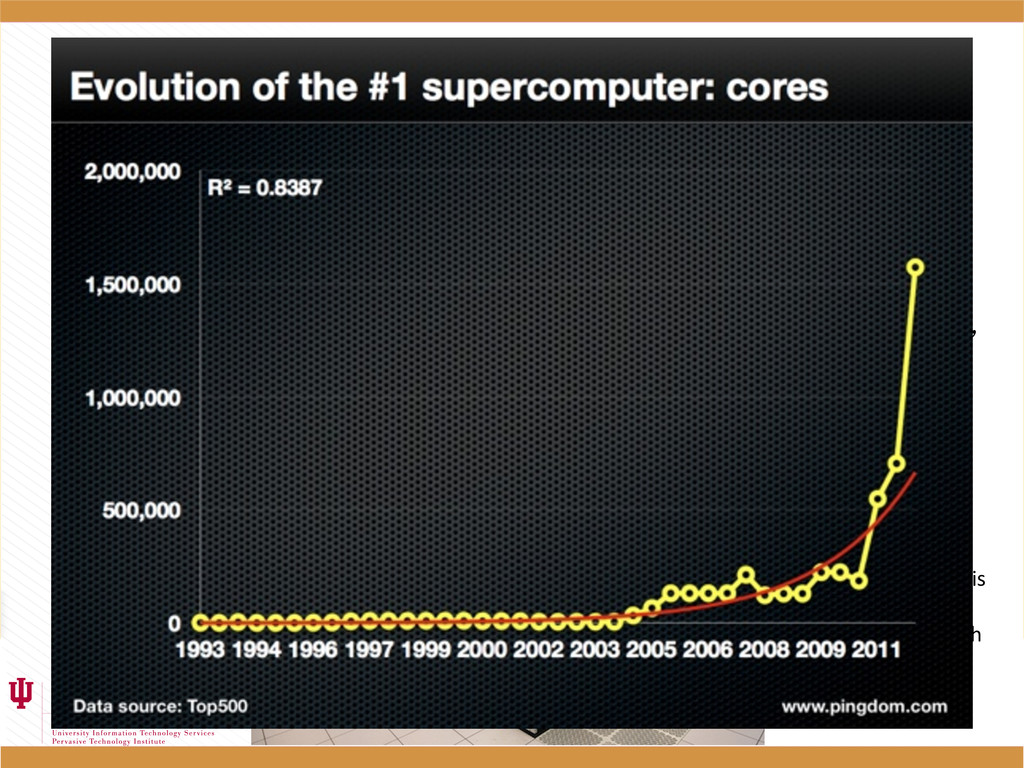
• Wikipedia says: “Parallel computing is a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently ("in parallel").” • Supercomputers = massive numbers of cores • Everyday computers = many/multi-core Sequoia: LLNL’s BlueGene Q is the world’s fastest supercomputer with 20 PFLOPs and 1.6 million cores
• Wikipedia says: “Parallel computing is a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently ("in parallel").” • Supercomputers = massive numbers of cores • Everyday computers = many/multi-core Sequoia: LLNL’s BlueGene Q is the world’s fastest supercomputer with 20 PFLOPs and 1.6 million cores
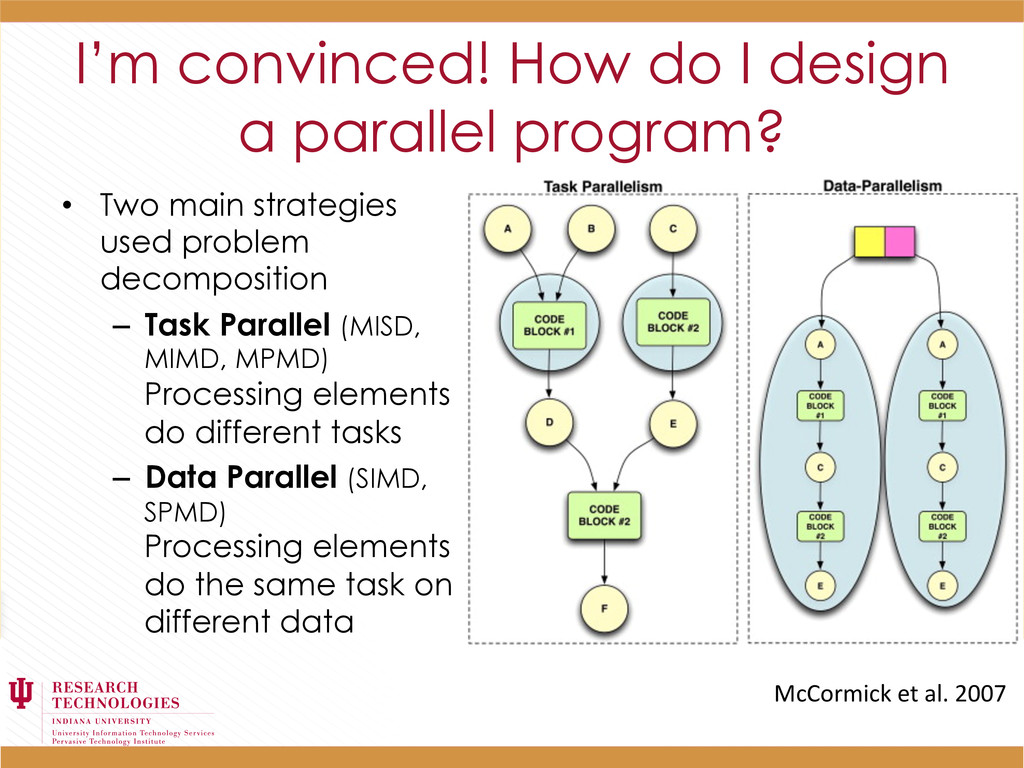
Two main strategies used problem decomposition – Task Parallel (MISD, MIMD, MPMD) Processing elements do different tasks – Data Parallel (SIMD, SPMD) Processing elements do the same task on different data McCormick et al. 2007
a variety of challenges in designing and implementing parallel algorithms – Amdhal’s law – Load balance – Interprocess communication/Data locality – Fault tolerance
• Determine the best type of parallel implementation for your work – Embarrassingly parallel • Many unrelated tasks that don’t require communication – Shared memory parallel • Processing elements require access to shared global memory – Distributed memory parallel • Processing elements only require access to local memory
tasks that can be executed completely independently, but need some organizing infrastructure • There are many high throughput frameworks that address embarrassingly parallel problems – Condor, BigJob, etc.
tasks (threads) to access the same global memory • Useful within a single node or on large shared-memory machines • Can be implemented with – POSIX threads (Pthreads): low level system access – OpenMP: compiler pragmas – PGAS languages: semantics in the language itself
explicit message passing to coordinate tasks • MPI (Message Passing Interface) is a series of tools that allows you to write code that coordinates the efforts of many nodes with distributed memory
are: – Simultaneous execution: all ranks perform the exact same tasks – Master/worker: one rank acts as the controlling node and orchestrates and distributes work to the other nodes
the two types of parallelism • A combined OpenMP/MPI program is commonly referred to as a hybrid program • There are several reasons you might want to do this – Performance – Memory
int main (int argc, char *argv[]) { omp_set_num_threads(6); // Fork a team of threads #pragma omp parallel { printf("Hello World! \n"); } } This goes in every OpenMP program
int main (int argc, char *argv[]) { omp_set_num_threads(6); // Fork a team of threads #pragma omp parallel { printf("Hello World! \n"); } } This goes in every OpenMP program This funcIon or the environment variable OMP_NUM_THREADS sets the number of threads
int main (int argc, char *argv[]) { omp_set_num_threads(6); // Fork a team of threads #pragma omp parallel { printf("Hello World! \n"); } } This goes in every OpenMP program The magic sauce…
or pragmas to enable parallelism in compiled code • Some of the most important pragmas are: #pragma omp parallel! #pragma omp for! #pragma omp sections! #pragma omp single! #pragma omp task! #pragma omp critical! #pragma omp barrier! #pragma omp master! • Check OpenMP.org for a full list of pragmas and functions
#PBS -N hello_omp #PBS -q batch #PBS -j oe cd $PBS_O_WORKDIR if [ ! -x hello_omp_v1 ]; then gcc -O3 -o hello_omp_v1 -fopenmp hello_omp_v1.c fi ./hello_omp_v1 > hello_v1.out Specify resources… The compiler flag that makes it all happen Execute and redirect the output
int main (int argc, char *argv[]) { int nthreads, tid, maxthreads; omp_set_num_threads(6); // Fork a team of threads and give a private copy of their thread number #pragma omp parallel private(tid) { #pragma omp master { maxthreads = omp_get_max_threads(); nthreads = omp_get_num_threads(); printf("There are %d threads available. %d of these threads are currently active. \n", ! maxthreads, nthreads); } // Obtain thread number tid = omp_get_thread_num(); printf("Hello World from thread = %d\n", tid); } } Create a ‘thread private’ variable
main (int argc, char *argv[]) { int nthreads, tid, maxthreads; omp_set_num_threads(6); // Fork a team of threads and give a private copy of their thread number #pragma omp parallel private(tid) { #pragma omp master { maxthreads = omp_get_max_threads(); nthreads = omp_get_num_threads(); printf("There are %d threads available. %d of these threads are currently active. \n", ! maxthreads, nthreads); } // Obtain thread number tid = omp_get_thread_num(); printf("Hello World from thread = %d\n", tid); } } Only the ‘master’ thread executes this block
(int argc, char *argv[]) { int nthreads, tid, maxthreads; omp_set_num_threads(6); // Fork a team of threads and give a private copy of their thread number #pragma omp parallel private(tid) { #pragma omp master { maxthreads = omp_get_max_threads(); nthreads = omp_get_num_threads(); printf("There are %d threads available. %d of these threads are currently active. \n", ! maxthreads, nthreads); } // Obtain thread number tid = omp_get_thread_num(); printf("Hello World from thread = %d\n", tid); } } More OpenMP funcIons
(int argc, char *argv[]) { int nthreads, tid, maxthreads; omp_set_num_threads(6); // Fork a team of threads and give a private copy of their thread number #pragma omp parallel private(tid) { #pragma omp master { maxthreads = omp_get_max_threads(); nthreads = omp_get_num_threads(); printf("There are %d threads available. %d of these threads are currently active. \n", ! maxthreads, nthreads); } // Obtain thread number tid = omp_get_thread_num(); printf("Hello World from thread = %d\n", tid); } } Remember, every thread has its own ‘private’ copy of this variable
argc, char *argv[]) { ... #pragma omp parallel private(tid) { #pragma omp master { maxthreads = omp_get_max_threads(); nthreads = omp_get_num_threads(); printf("There are %d threads available. %d of these threads are currently active. \n", ! maxthreads, nthreads); } #pragma omp barrier // Obtain thread number tid = omp_get_thread_num(); printf("Hello World from thread = %d\n", tid); } } Threads wait here unIl they’ve all reached this point
<mpi.h> int main (argc, argv) int argc; char *argv[]; { MPI_Init (&argc, &argv); !/* starts MPI */ printf( "Hello world!"); MPI_Finalize(); /* ends MPI */ return 0; } ! This goes in every MPI program
of functions to enable inter-process communication and parallelism in compiled code • Some of the most important functions are: int MPI_Init(int *argc, char **argv) int MPI_Comm_size(MPI_Comm comm, int *size) int MPI_Comm_rank(MPI_Comm comm, int *rank) int MPI_Finalize()! int MPI_Send (void *buf,int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) int MPI_Recv (void *buf,int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status) • Check mpi-forum.org for the official MPI specification
(argc, argv) int argc; char *argv[]; { int rank, size; MPI_Init (&argc, &argv); !/* starts MPI */ MPI_Comm_rank (MPI_COMM_WORLD, &rank); !/* get current process id */ MPI_Comm_size (MPI_COMM_WORLD, &size); !/* get number of processes */ printf( "Hello world from process %d of %d\n", rank, size ); MPI_Finalize(); return 0; }
(argc, argv) int argc; char *argv[]; { int rank, size; MPI_Init (&argc, &argv); !/* starts MPI */ MPI_Comm_rank (MPI_COMM_WORLD, &rank); !/* get current process id */ MPI_Comm_size (MPI_COMM_WORLD, &size); !/* get number of processes */ printf( "Hello world from process %d of %d\n", rank, size ); MPI_Finalize(); return 0; }
<mpi.h>! int main (argc, argv) ... if (rank == 0) { /*Rank 0 is the master process */ ... for (x = 1; x < size; x++) { /* Receive messages in for loop order */ MPI_Recv(msg, 50, MPI_CHARACTER, x, tag, MPI_COMM_WORLD, &status); printf("From worker %d: %s”,status.MPI_SOURCE, msg); }
<mpi.h>! int main (argc, argv) ... if (rank == 0) { /*Rank 0 is the master process */ ... for (x = 1; x < size; x++) { /* Receive messages in for loop order */ MPI_Recv(msg, 50, MPI_CHARACTER, x, tag, ! ! ! !MPI_COMM_WORLD, &status); printf("From worker %d: %s”,status.MPI_SOURCE, msg); }
student session • See if you can extend hybrid_v1 to versions 2 and 3 • For version 2 have each process report it’s thread and rank number • For version 3 set up MPI master/worker and serialize by rank • Experiment with different mixes of ranks, threads, nodes, etc. • Feel free to fork on github and submit pull requests
and is affiliated with the Pervasive Technology Institute Acknowledgements & disclaimer • Many thanks to Robert Henschel and Jennet Tillotson • Patrick McCormick, Jeff Inman, James Ahrens, Jamaludin Mohd-Yusof, Greg Roth, Sharen Cummins, Scout: a data-parallel programming language for graphics processors, Parallel Computing, Volume 33, Issues 10–11, November 2007, Pages 648-662 • Any opinions presented here are those of the presenter(s) and do not necessarily represent the opinions of the National Science Foundation or any other funding agencies
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}