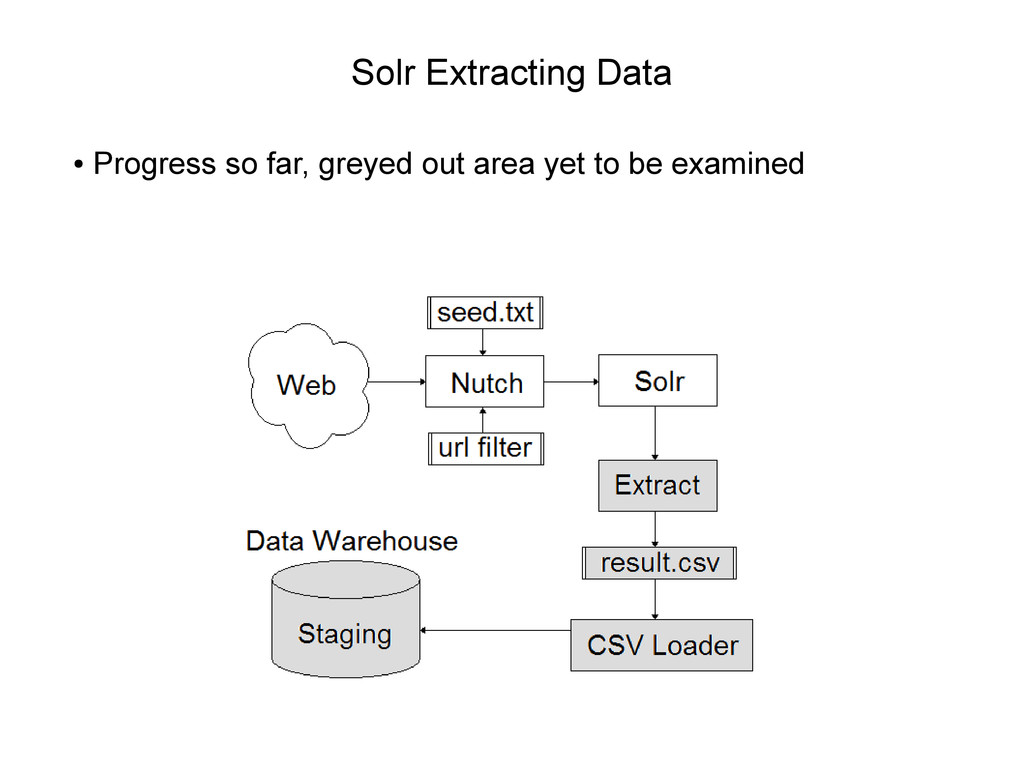
Solr indexed repository – Movie cAiYBD4BQeE showed installation – Movie Th5Scvlyt-E showed Nutch web crawl • This movie will show how to – Extract data from Solr – Extract to xml or csv – Show aim to load into data warehouse • This movie assumes you know Linux
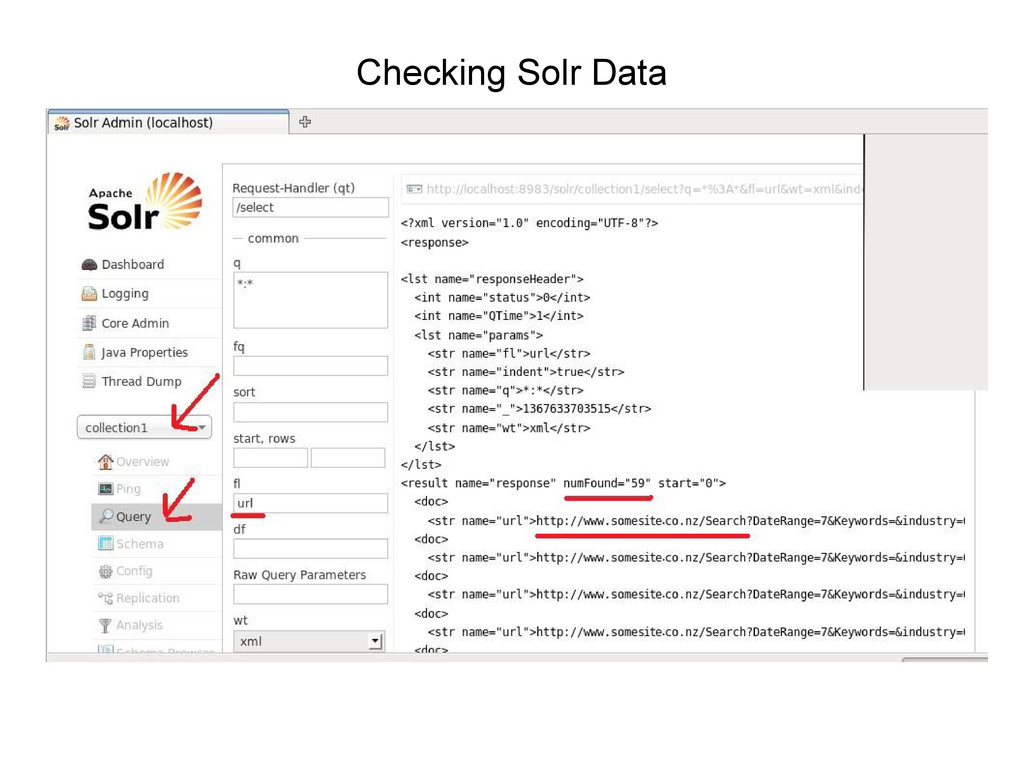
Solr • In Solr Admin window – Set 'Core Selector' = collection1 – Click 'Query' – In Query window set fl field = url – Click Execute Query • The result ( next ) shows the filtered list of urls in Solr
data ? – In admin console via query – Via http solr select – Via curl -o call using solr http select • What format of data – that suits this purpose – Xml – Comma separated variable (csv)
from Solr – tstamp, url • We want to extract as csv ( csv in call below could be xml ) • We want to extract to a file • So we will use an http call – http://localhost:8983/solr/select?q=*:*&fl=tstamp,url&wt=csv • We will also use a curl call – curl -o <csv file> '<http call>'
• ls -l shows – result.csv.20130506.124857 • Check the content , wc -l shows 11 lines • Check the content , head -2 shows – tstamp, url – 2013-05-04T01:56:58.157Z,http://www.mysite.co.nz/Search? DateRange=7& ... • Congratulations, you have extracted data from Solr • It's in CSV format ready to be loaded into a data warehouse
data • Allow Nutch crawl to go deeper • Allow Nutch crawl to collect a lot more data • Look at facets in Solr data • Load CSV files into Data Warehouse Staging schema • Next movie will show next step in progress
www.semtech-solutions.co.nz – [email protected] • We offer IT project consultancy • We are happy to hear about your problems • You can just pay for those hours that you need • To solve your problems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}