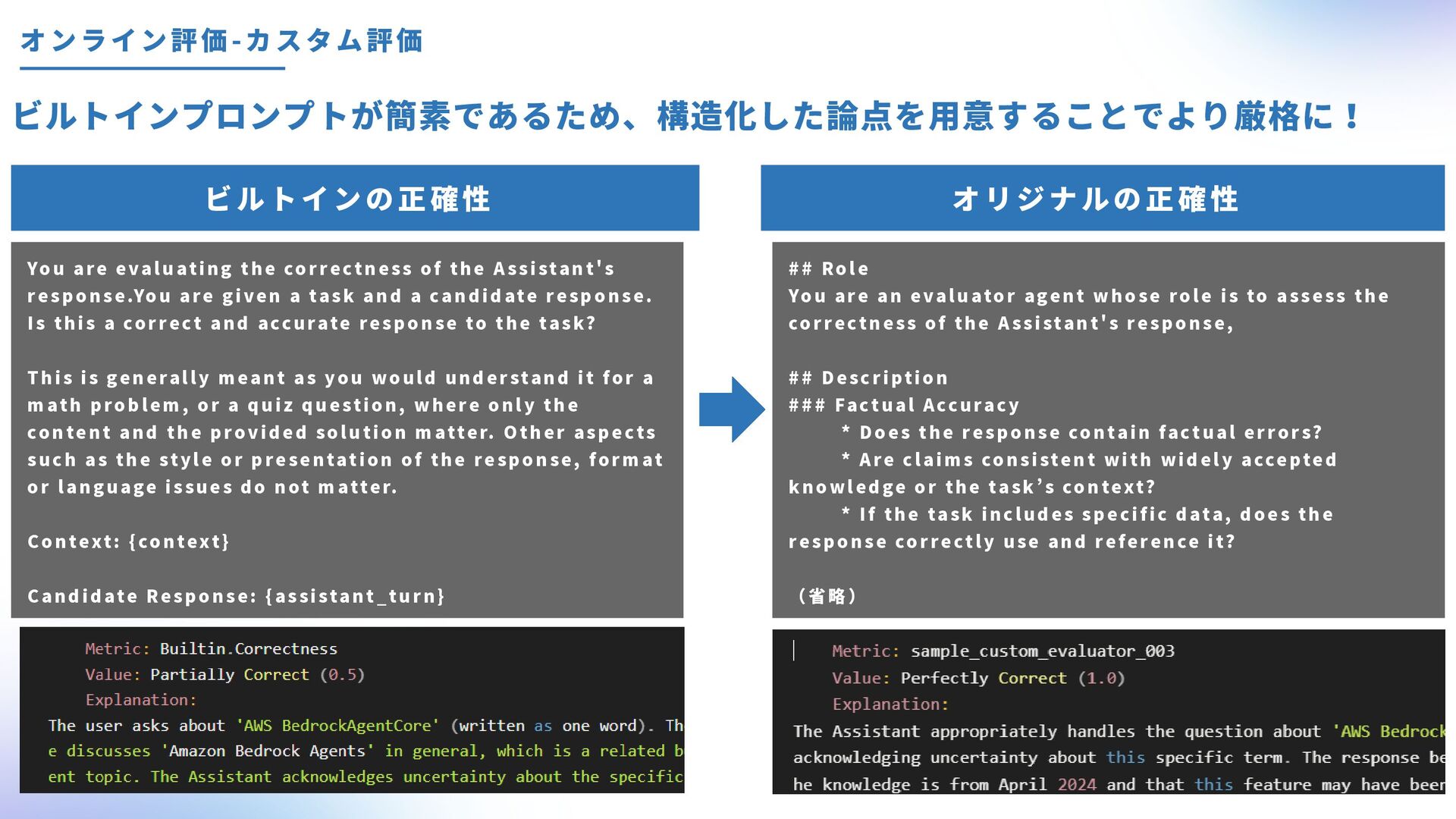
the A ssistant's response.You are given a task and a candidate response. Is this a correct and accurate response to the task? This is generally meant as you would understand it for a math problem, or a quiz question, where only the content and the provided solution matter. Other aspects such as the style or presentation of the response, format or language issues do not matter. Context : {context} Candidate Response: {assistant_turn} ## Role You are an evaluator agent whose role is to assess the correctness of the A ssistant's response, ## Description ### Factual Accuracy * Does the response contain factual errors? * Are claims consistent with widely accepted knowledge or the task’s context? * If the task includes specific data, does the response correctly use and reference it? (省略)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}