Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
小売データを対象とした需要予測モデル構築
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
shimakimi
December 21, 2025
0
2
小売データを対象とした需要予測モデル構築
shimakimi
December 21, 2025
Tweet
Share
More Decks by shimakimi
See All by shimakimi
地方中小企業オンプレ環境からクラウドAIを導入するチュートリアル
shimakimi
0
16
Featured
See All Featured
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
66
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
A Soul's Torment
seathinner
5
2.3k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
90
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
100
How to make the Groovebox
asonas
2
1.9k
Agile that works and the tools we love
rasmusluckow
331
21k
Unsuck your backbone
ammeep
671
58k
From π to Pie charts
rasagy
0
130
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
200
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
0
440
30 Presentation Tips
portentint
PRO
1
230
Transcript
小売データを対象とした 需要予測モデル構築
プロジェクトの背景と目的 • 在庫のミスマッチ : 毎年、ボーナス商戦期(6月・7月・12月)において、特定商品の 欠品による機会損失と、予測外れによる過剰在庫(廃棄ロス)が同時に発生してい る。 • 適当な予測 :
現在の発注業務は店長の経験と勘(KKD)に依存しており、精度にバ ラつきがあるほか、業務負荷が高い • リードタイムの制約 : 発注から納品までのリードタイムを考慮すると、「明日」ではな く「1週間後から1ヶ月先」の予測が必要である。
エグゼクティブサマリ • 目的: ボーナス商戦期(6月・7月・12月)における在庫切れと過剰在庫を防 ぐため、1週間後〜4週間後の売上を予測する。 • 成果: 過去の販売実績とカレンダー情報を活用し、LightGBMを用いたマ ルチステップ予測モデル を構築。
• 目的: ボーナス商戦期(6月・7月・12月)における在庫切れと過剰在庫を防 ぐため、1週間後〜4週間後の売上を予測する。
データ概要 • 規模: 10店舗 × 50商品(計500時系列) • 規模: 10店舗 ×
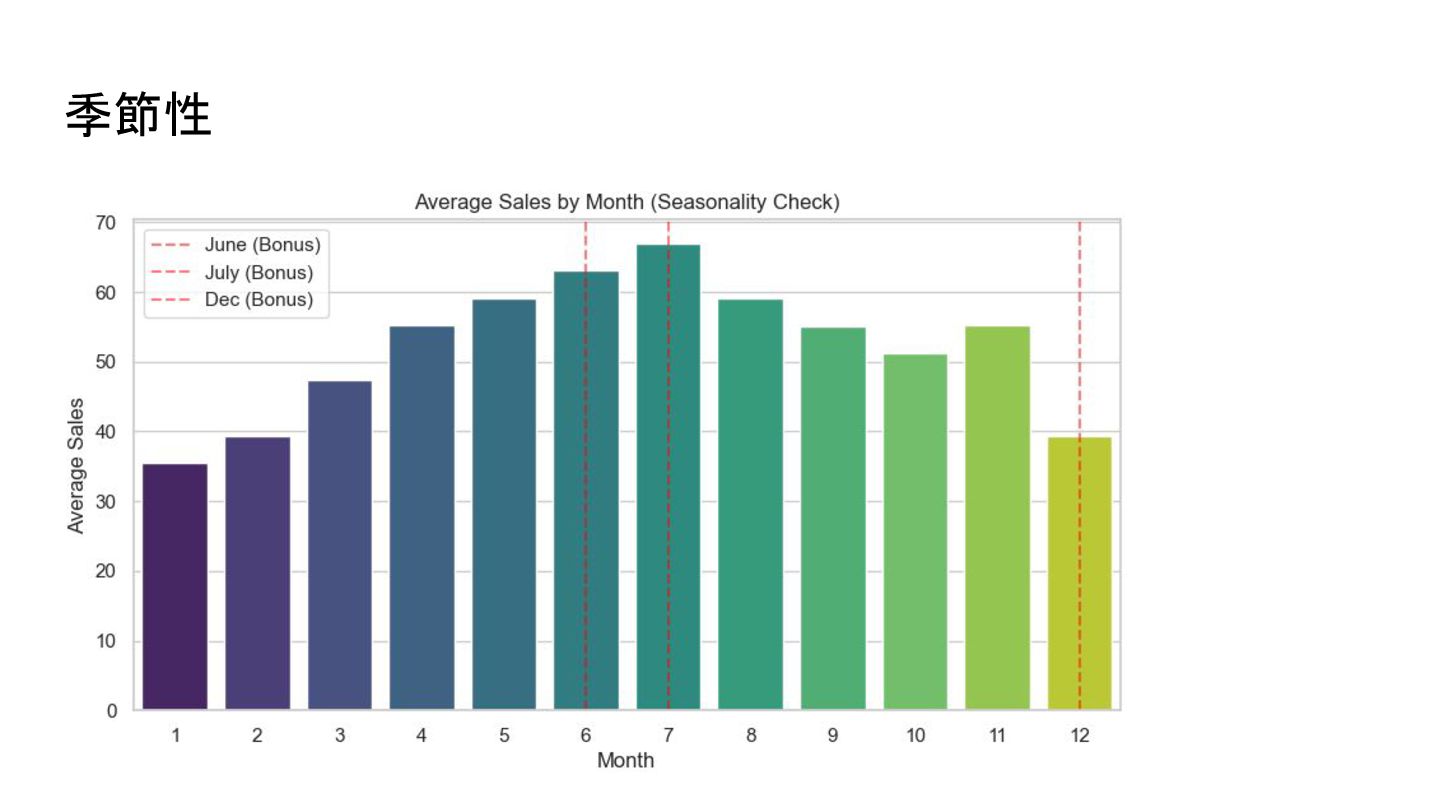
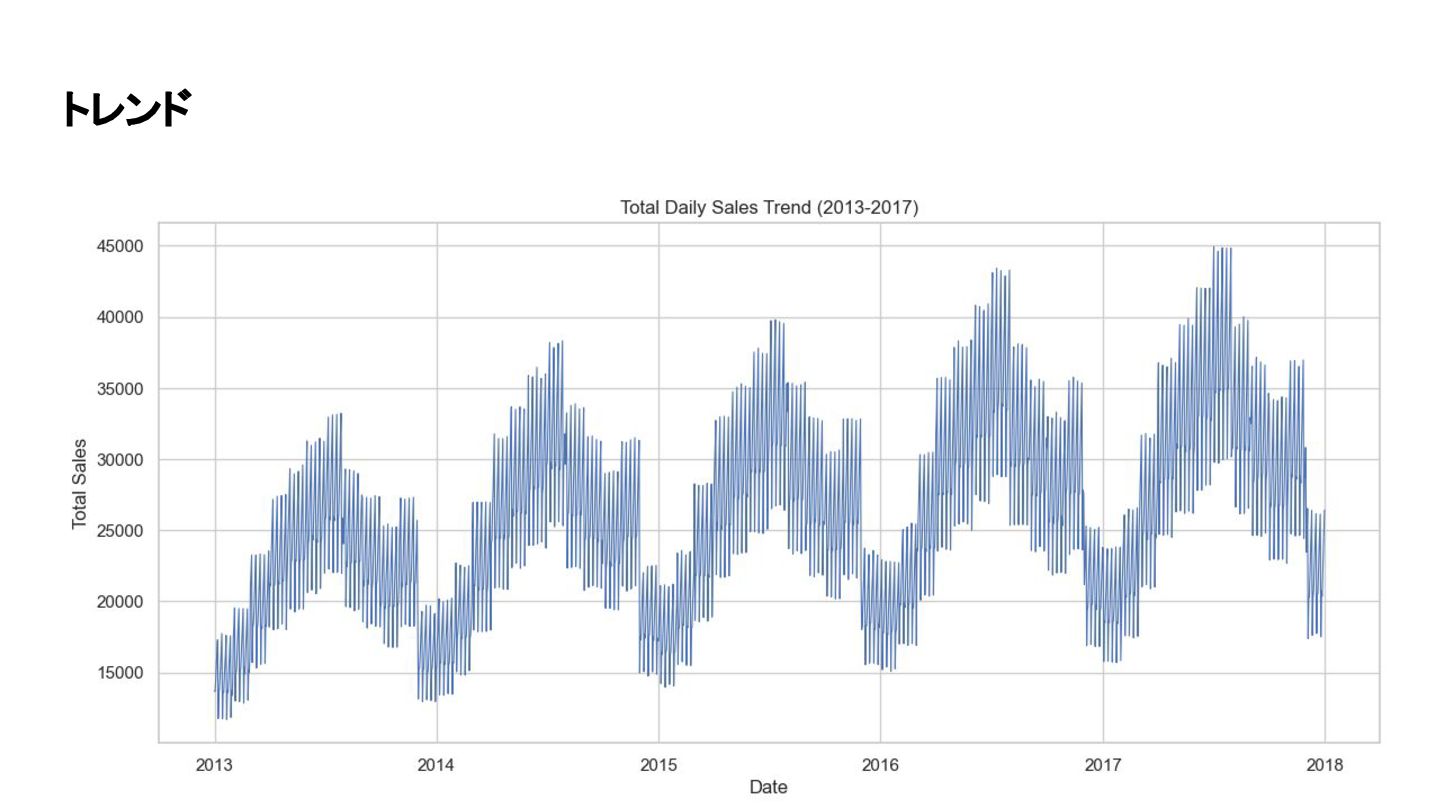
50商品(計500時系列) • データの特徴 (EDAより): • 季節性: 毎年6月・7月・12月に明確な売上スパイクが存在(ボーナス 商戦)。 • 週次周期: 曜日による変動(週末のピーク等)が顕著。 • トレンド: 全体として年々緩やかな成長傾向にある。
季節性
トレンド
モデリングアプローチ • 予測スキーム • $T+7$日後、$T+8$日後……$T+28$日後の売上を、それぞれ独立した22個のモ デルで直接予測する手法を採用。 • 理由: 1日ずつ予測を積み重ねる手法に比べ、誤差が累積せず、特定日のイベント(セール等)をピンポイントで捉えるのに優れてい るため。
アルゴリズムと特徴量 • 採用アルゴリズム : LightGBM (勾配ブースティング決定木 ) • 理由: 高速かつ高精度であり、複雑な季節性や非線形なトレンドを学習できるため。
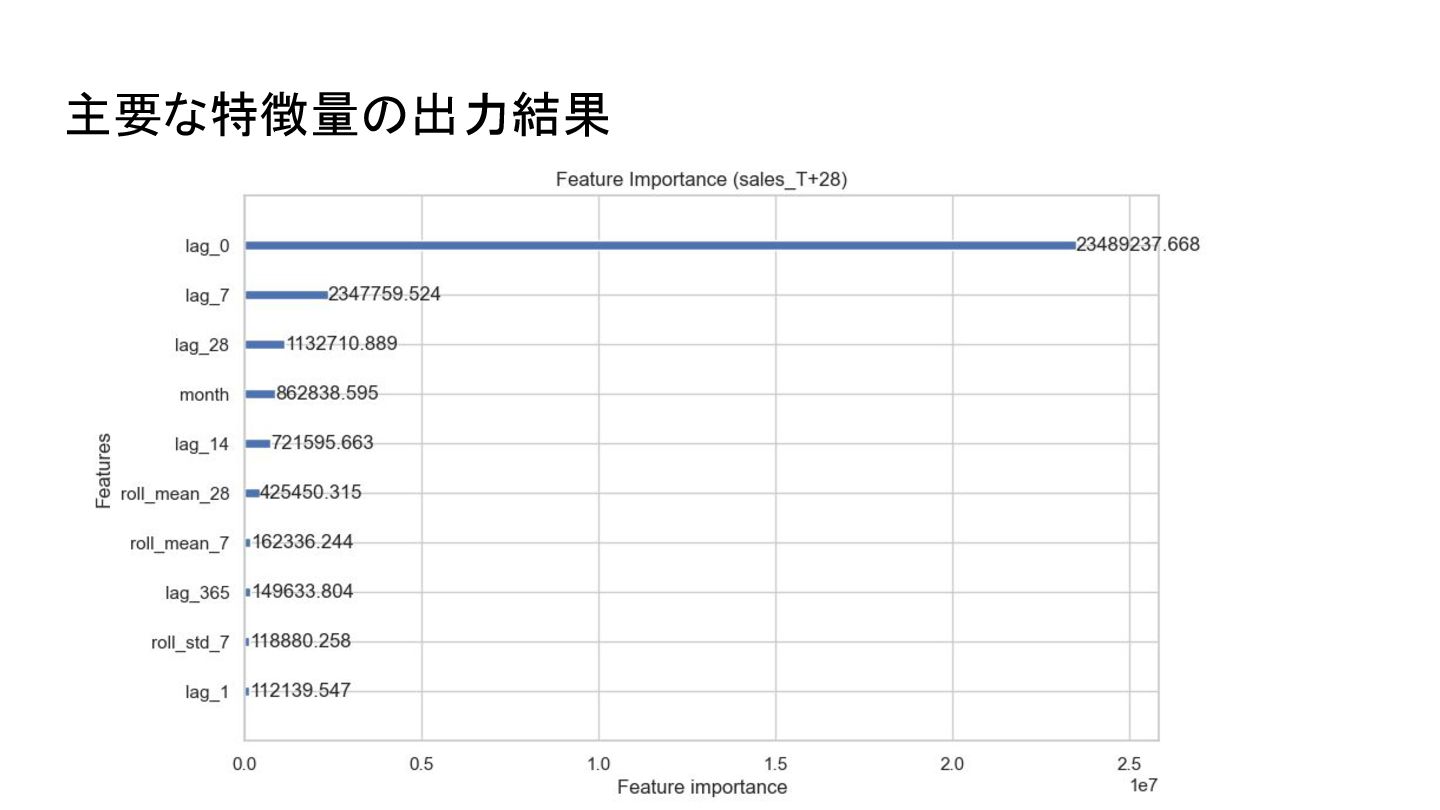
• 主要な特徴量 : • ラグ特徴量 (lag_7等): 「先週の同じ曜日は何個売れたか?」を重視。 • 移動平均 (roll_mean_7): 「直近1週間の売上規模(勢い)」を捉える。 • カレンダー情報: 月、曜日、年。
主要な特徴量の出力結果
結果サマリ 精度検証(2017年テストデータ) 指標 結果 評価 RMSE (二乗平均平方根誤差 ) 9.47 大きな外れ値を出さず、安定して予測できてい
る。 MAE (平均絶対誤差) 7.22 1日あたり平均28個の誤差範囲に収まってお り、発注実務において許容範囲内である。
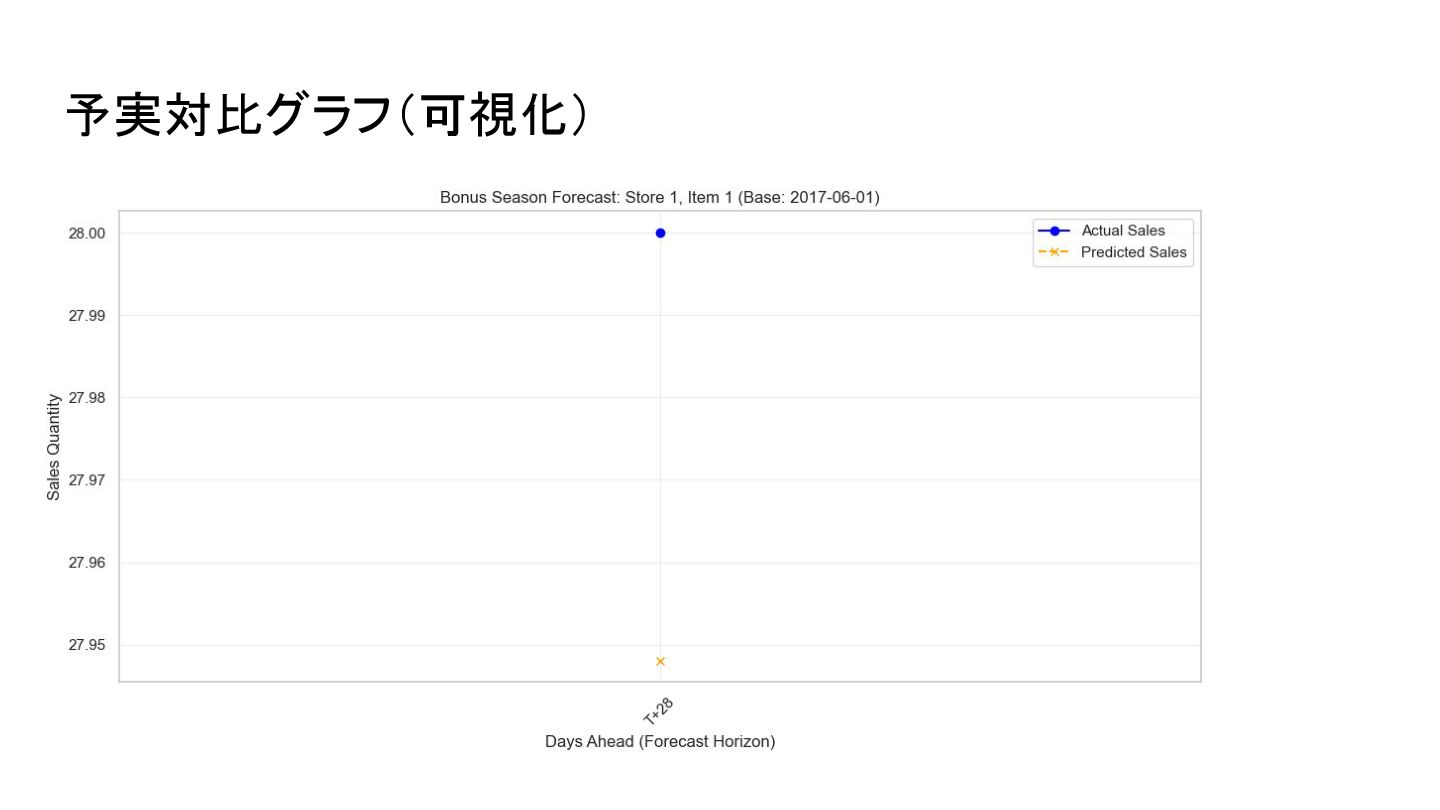
予実対比グラフ 予実対比グラフ(可視化) • 対象: Store 1, Item 1(定常需要商品) • 結果:
予測値が約28個前後で安定して推移している。 • 考察: • モデルは、突発的な変動が少ない商品に対しては 過剰な反応をせず、ベースライン(平均的 な需要)を堅実に予測 している。 • このような商品については、AI予測値を「安全在庫基準」として自動設定することで、発注業務 の完全自動化が可能である。
予実対比グラフ(可視化)
ビジネス上の示唆と今後の展望 • 従来の発注方式(移動平均法)と比較シミュレーションを行った結果、欠品リスク(機会損失量)を 28.5% 削減できる見込み。 • シミュレーション活用 : 開発したデモアプリ(Streamlit)により、「もし直前の売上が急増したら?」と いったWhat-If分析が可能になり、リスク管理ができるようになった。
今後の展望 • 一部店舗でのテスト運用開始(AI予測値を参考値として提示)。 • 天候データやキャンペーン情報の追加による更なる精度向上。
参考 デプロイアプリ https://retailstore-forecast-htjhzbb6yvkappnenejbjj2.streamlit.app/ github https://github.com/shimakimi/retail_store-_forecast
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}